Gli endpoint multimodello (MME) sono una potente funzionalità di Amazon Sage Maker progettato per semplificare l'implementazione e il funzionamento dei modelli di machine learning (ML). Con gli MME, puoi ospitare più modelli su un unico contenitore di servizio e ospitare tutti i modelli dietro un singolo endpoint. La piattaforma SageMaker gestisce automaticamente il carico e lo scarico dei modelli e dimensiona le risorse in base ai modelli di traffico, riducendo l'onere operativo derivante dalla gestione di una grande quantità di modelli. Questa funzionalità è particolarmente utile per il deep learning e i modelli di intelligenza artificiale generativa che richiedono elaborazione accelerata. Il risparmio sui costi ottenuto attraverso la condivisione delle risorse e la gestione semplificata dei modelli rende gli MME SageMaker una scelta eccellente per ospitare modelli su larga scala su AWS.
Recentemente, le applicazioni di intelligenza artificiale generativa hanno catturato l’attenzione e l’immaginazione diffuse. I clienti desiderano implementare modelli di intelligenza artificiale generativa sulle GPU ma allo stesso tempo sono consapevoli dei costi. Gli MME SageMaker supportano le istanze GPU e rappresentano un'ottima opzione per questi tipi di applicazioni. Oggi siamo lieti di annunciare il supporto TorchServe per gli MME SageMaker. Questo nuovo modello di supporto server ti offre il vantaggio di tutti i vantaggi degli MME pur utilizzando lo stack di servizio con cui i clienti TorchServe hanno più familiarità. In questo post, dimostriamo come ospitare modelli di intelligenza artificiale generativa, come Stable Diffusion e Segment Anything Model, su MME SageMaker utilizzando TorchServe e creare una soluzione di editing guidata dal linguaggio che può aiutare artisti e creatori di contenuti a sviluppare e iterare le loro opere d'arte più velocemente.
Panoramica della soluzione
La modifica guidata dal linguaggio è un caso d'uso comune dell'intelligenza artificiale generativa in tutti i settori. Può aiutare gli artisti e i creatori di contenuti a lavorare in modo più efficiente per soddisfare la domanda di contenuti automatizzando le attività ripetitive, ottimizzando le campagne e fornendo un'esperienza iper-personalizzata per il cliente finale. Le aziende possono trarre vantaggio da una maggiore produzione di contenuti, risparmi sui costi, migliore personalizzazione e migliore esperienza del cliente. In questo post, dimostriamo come creare funzionalità di modifica assistita dal linguaggio utilizzando MME TorchServe che ti consentono di cancellare qualsiasi oggetto indesiderato da un'immagine e modificare o sostituire qualsiasi oggetto in un'immagine fornendo un'istruzione di testo.
Il flusso dell'esperienza utente per ciascun caso d'uso è il seguente:
- Per rimuovere un oggetto indesiderato, seleziona l'oggetto dall'immagine per evidenziarlo. Questa azione invia le coordinate dei pixel e l'immagine originale a un modello di intelligenza artificiale generativa, che genera una maschera di segmentazione per l'oggetto. Dopo aver confermato la corretta selezione dell'oggetto, è possibile inviare le immagini originali e mascherate a un secondo modello per la rimozione. L'illustrazione dettagliata di questo flusso utente è illustrata di seguito.
 |
 |
 |
|
Passo 1: Seleziona un oggetto ("cane") dall'immagine |
Passo 2: Confermare che sia evidenziato l'oggetto corretto |
Passo 3: Cancella l'oggetto dall'immagine |
- Per modificare o sostituire un oggetto, selezionare ed evidenziare l'oggetto desiderato, seguendo lo stesso procedimento descritto sopra. Una volta confermata la corretta selezione dell'oggetto, è possibile modificare l'oggetto fornendo l'immagine originale, la maschera e un messaggio di testo. Il modello modificherà quindi l'oggetto evidenziato in base alle istruzioni fornite. Un'illustrazione dettagliata di questo secondo flusso utente è la seguente.
 |
 |
 |
|
Passo 1: Seleziona un oggetto ("vaso") dall'immagine |
Passo 2: Confermare che sia evidenziato l'oggetto corretto |
Passo 3: Fornire un messaggio di testo ("vaso futuristico") per modificare l'oggetto |
Per alimentare questa soluzione, utilizziamo tre modelli di intelligenza artificiale generativa: Segment Anything Model (SAM), Large Mask Inpainting Model (LaMa) e Stable Diffusion Inpaint (SD). Ecco come questi modelli sono stati utilizzati nel flusso di lavoro dell'esperienza utente:
| Per rimuovere un oggetto indesiderato | Per modificare o sostituire un oggetto |
 |
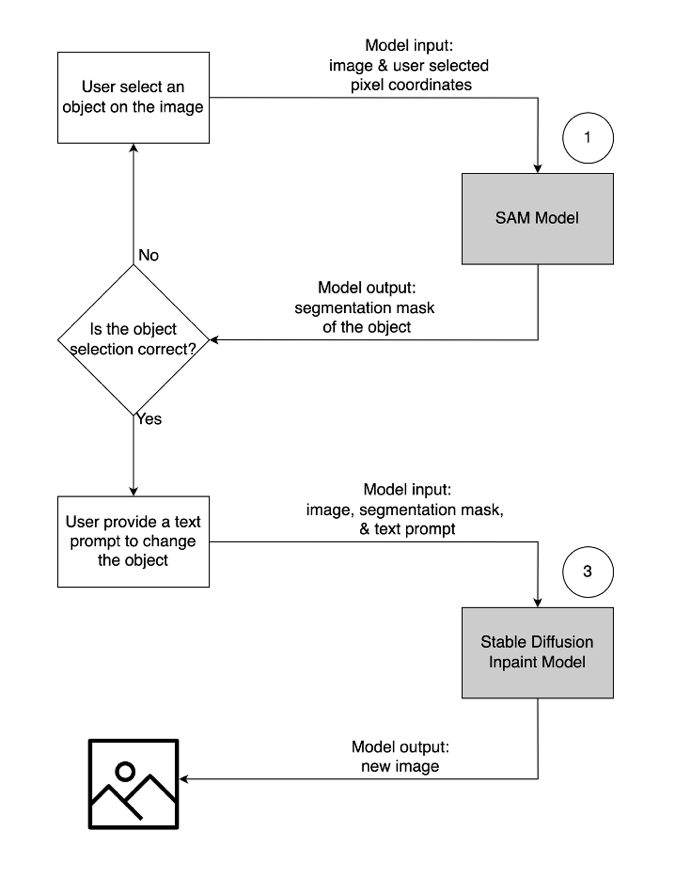 |
- Segment Anything Model (SAM) viene utilizzato per generare una maschera di segmenti dell'oggetto di interesse. Sviluppato da Meta Research, SAM è un modello open source in grado di segmentare qualsiasi oggetto in un'immagine. Questo modello è stato addestrato su un enorme set di dati noto come SA-1B, che comprende oltre 11 milioni di immagini e 1.1 miliardi di maschere di segmentazione. Per ulteriori informazioni su SAM, fare riferimento al loro sito web ed documento di ricerca.
- LaMa viene utilizzato per rimuovere eventuali oggetti indesiderati da un'immagine. LaMa è un modello GAN (Generative Adversarial Network) specializzato nel riempire parti mancanti di immagini utilizzando maschere irregolari. L'architettura del modello incorpora un contesto globale a livello di immagine e un'architettura a passaggio singolo che utilizza le convoluzioni di Fourier, consentendo di ottenere risultati all'avanguardia a una velocità maggiore. Per maggiori dettagli su LaMa, visita il loro sito web ed documento di ricerca.
- Il modello inpaint SD 2 di Stability AI viene utilizzato per modificare o sostituire oggetti in un'immagine. Questo modello ci consente di modificare l'oggetto nell'area della maschera fornendo un messaggio di testo. Il modello inpaint si basa sul modello SD da testo a immagine, che può creare immagini di alta qualità con un semplice messaggio di testo. Fornisce argomenti aggiuntivi come immagini originali e maschere, consentendo una rapida modifica e ripristino del contenuto esistente. Per ulteriori informazioni sui modelli di diffusione stabile su AWS, fare riferimento a Crea immagini di alta qualità con modelli di diffusione stabile e distribuiscile in modo conveniente con Amazon SageMaker.
Tutti e tre i modelli sono ospitati su MME SageMaker, il che riduce il carico operativo derivante dalla gestione di più endpoint. In aggiunta a ciò, l’utilizzo di MME elimina le preoccupazioni relative al sottoutilizzo di alcuni modelli perché le risorse sono condivise. Puoi osservare il vantaggio derivante da una migliore saturazione delle istanze, che in definitiva porta a un risparmio sui costi. Il seguente diagramma dell'architettura illustra come vengono serviti tutti e tre i modelli utilizzando gli MME SageMaker con TorchServe.
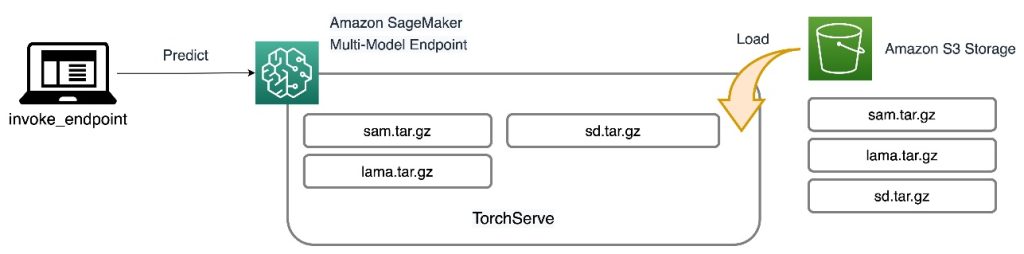
Abbiamo pubblicato il codice per implementare questa architettura di soluzione nel ns Repository GitHub. Per seguire il resto del post, utilizzare il file notebook. Si consiglia di eseguire questo esempio su un'istanza notebook SageMaker utilizzando il file conda_python3 (Python 3.10.10).
Estendi il contenitore TorchServe
Il primo passaggio consiste nel preparare il contenitore di hosting del modello. SageMaker fornisce un PyTorch Deep Learning Container (DLC) gestito che puoi recuperare utilizzando il seguente snippet di codice:
Poiché i modelli richiedono risorse e pacchetti aggiuntivi che non sono presenti nel DLC PyTorch di base, è necessario creare un'immagine Docker. Questa immagine viene quindi caricata su Registro dei contenitori Amazon Elastic (Amazon ECR) in modo da poter accedere direttamente da SageMaker. Le librerie installate personalizzate sono elencate nel file Docker:
Esegui il file di comandi della shell per creare l'immagine personalizzata localmente ed inviarla ad Amazon ECR:
Preparare gli artefatti del modello
La differenza principale per i nuovi MME con supporto TorchServe è il modo in cui prepari gli artefatti del modello. Il repository del codice fornisce una cartella scheletro per ciascun modello (cartella models) per ospitare i file richiesti per TorchServe. Seguiamo lo stesso processo in quattro fasi per preparare ciascun modello .tar file. Il codice seguente è un esempio della cartella scheletro per il modello SD:
Il primo passaggio consiste nel scaricare i checkpoint del modello preaddestrato nella cartella dei modelli:
Il passo successivo è definire a custom_handler.py file. Ciò è necessario per definire il comportamento del modello quando riceve una richiesta, ad esempio il caricamento del modello, la preelaborazione dell'input e la postelaborazione dell'output. IL handle Il metodo è il punto di ingresso principale per le richieste e accetta un oggetto richiesta e restituisce un oggetto risposta. Carica i checkpoint del modello preaddestrato e applica il file preprocess ed postprocess metodi per i dati di input e di output. Il seguente frammento di codice illustra una struttura semplice del file custom_handler.py file. Per maggiori dettagli, fare riferimento a API del gestore TorchServe.
L'ultimo file richiesto per TorchServe è model-config.yaml. Il file definisce la configurazione del server modello, come il numero di lavoratori e la dimensione del batch. La configurazione è a livello di modello e un file di configurazione di esempio è mostrato nel codice seguente. Per un elenco completo dei parametri, fare riferimento a Repository GitHub.
Il passaggio finale consiste nel comprimere tutti gli artefatti del modello in un singolo file .tar.gz utilizzando il file .tar.gz torch-model-archiver modulo:
Creare l'endpoint multimodello
I passaggi per creare un MME SageMaker sono gli stessi di prima. In questo esempio particolare, avvii un endpoint utilizzando SageMaker SDK. Inizia definendo un Servizio di archiviazione semplice Amazon (Amazon S3) e il contenitore di hosting. Questa posizione S3 è dove SageMaker caricherà dinamicamente i modelli in base ai modelli di invocazione. Il contenitore di hosting è il contenitore personalizzato che hai creato e inviato ad Amazon ECR nella fase precedente. Vedere il seguente codice:
Quindi vuoi definire a MulitDataModel che cattura tutti gli attributi come la posizione del modello, il contenitore di hosting e l'accesso alle autorizzazioni:
Il deploy() la funzione crea una configurazione di endpoint e ospita l'endpoint:
Nell'esempio fornito mostriamo anche come elencare i modelli e aggiungere dinamicamente nuovi modelli utilizzando l'SDK. IL add_model() la funzione copia il modello locale .tar file nella posizione MME S3:
Invocare i modelli
Ora che abbiamo tutti e tre i modelli ospitati su un MME, possiamo richiamare ciascun modello in sequenza per creare le nostre funzionalità di modifica assistita dal linguaggio. Per richiamare ciascun modello, fornire a target_model parametro nel predictor.predict() funzione. Il nome del modello è solo il nome del modello .tar file che abbiamo caricato. Quello che segue è un frammento di codice di esempio per il modello SAM che accetta una coordinata di pixel, un'etichetta di punto e una dimensione del kernel dilatata e genera una maschera di segmentazione dell'oggetto nella posizione del pixel:
Per rimuovere un oggetto indesiderato da un'immagine, prendi la maschera di segmentazione generata da SAM e inseriscila nel modello LaMa con l'immagine originale. Le immagini seguenti mostrano un esempio.
 |
 |
|
|
Sample image |
Maschera di segmentazione da SAM |
Cancella il cane usando LaMa |
Per modificare o sostituire qualsiasi oggetto in un'immagine con un messaggio di testo, prendi la maschera di segmentazione da SAM e inseriscila nel modello SD con l'immagine originale e il messaggio di testo, come mostrato nell'esempio seguente.
|
|
 |
|
Sample image |
Maschera di segmentazione da SAM |
Sostituisci utilizzando il modello SD con un messaggio di testo “un criceto su una panchina” |
Risparmio sui costi
I vantaggi degli MME SageMaker aumentano in base alla portata del consolidamento del modello. La tabella seguente mostra l'utilizzo della memoria della GPU dei tre modelli in questo post. Sono schierati su uno g5.2xlarge esempio utilizzando un SageMaker MME.
| Modello | Memoria GPU (MiB) |
| Segmenta qualsiasi modello | 3,362 |
| Diffusione stabile nella vernice | 3,910 |
| Lama | 852 |
Puoi notare un risparmio sui costi quando si ospitano i tre modelli con un unico endpoint e, per i casi d'uso con centinaia o migliaia di modelli, il risparmio è molto maggiore.
Ad esempio, considera 100 modelli di diffusione stabile. Ciascuno dei modelli da solo potrebbe essere servito da un ml.g5.2xlarge endpoint (4 GiB di memoria), con un costo di $ 1.52 per istanza all'ora nella regione degli Stati Uniti orientali (Virginia settentrionale). Fornire tutti i 100 modelli utilizzando il proprio endpoint costerebbe 218,880 dollari al mese. Con un MME SageMaker, un singolo endpoint utilizzando ml.g5.2xlarge le istanze possono ospitare quattro modelli contemporaneamente. Ciò riduce i costi di inferenza della produzione del 75% a soli $ 54,720 al mese. La tabella seguente riepiloga le differenze tra endpoint a modello singolo e multimodello per questo esempio. Data una configurazione dell'endpoint con memoria sufficiente per i modelli di destinazione, la latenza di chiamata allo stato stazionario dopo che tutti i modelli sono stati caricati sarà simile a quella di un endpoint a modello singolo.
| . | Endpoint a modello singolo | Endpoint multimodello |
| Prezzo totale dell'endpoint al mese | $218,880 | $54,720 |
| Tipo di istanza dell'endpoint | ml.g5.2xgrande | ml.g5.2xgrande |
| Capacità di memoria della CPU (GiB) | 32 | 32 |
| Capacità di memoria della GPU (GiB) | 24 | 24 |
| Prezzo dell'endpoint all'ora | $1.52 | $1.52 |
| Numero di istanze per endpoint | 2 | 2 |
| Endpoint necessari per 100 modelli | 100 | 25 |
ripulire
Al termine, seguire le istruzioni nella sezione di pulizia del notebook per eliminare le risorse fornite in questo post per evitare addebiti non necessari. Fare riferimento a Prezzi di Amazon SageMaker per i dettagli sul costo delle istanze di inferenza.
Conclusione
Questo post dimostra le funzionalità di modifica assistita dal linguaggio rese possibili attraverso l'uso di modelli di intelligenza artificiale generativa ospitati su MME SageMaker con TorchServe. L'esempio che abbiamo condiviso illustra come possiamo utilizzare la condivisione delle risorse e la gestione semplificata dei modelli con gli MME SageMaker continuando a utilizzare TorchServe come stack di presentazione dei modelli. Abbiamo utilizzato tre modelli di base del deep learning: SAM, SD 2 Inpainting e LaMa. Questi modelli ci consentono di sviluppare potenti funzionalità, come cancellare qualsiasi oggetto indesiderato da un'immagine e modificare o sostituire qualsiasi oggetto in un'immagine fornendo un'istruzione testuale. Queste funzionalità possono aiutare gli artisti e i creatori di contenuti a lavorare in modo più efficiente e a soddisfare le loro richieste di contenuti automatizzando attività ripetitive, ottimizzando le campagne e fornendo un'esperienza iper-personalizzata. Ti invitiamo a esplorare l'esempio fornito in questo post e a creare la tua esperienza di interfaccia utente utilizzando TorchServe su un MME SageMaker.
Per iniziare, vedi Algoritmi, framework e istanze supportati per endpoint multimodello che utilizzano istanze supportate da GPU.
Circa gli autori
 Giacomo Wu è un Senior AI/ML Specialist Solution Architect presso AWS. aiutare i clienti a progettare e realizzare soluzioni AI/ML. Il lavoro di James copre un'ampia gamma di casi d'uso di ML, con un interesse primario per la visione artificiale, il deep learning e la scalabilità del ML in tutta l'azienda. Prima di entrare in AWS, James è stato architetto, sviluppatore e leader tecnologico per oltre 10 anni, di cui 6 in ingegneria e 4 anni nei settori del marketing e della pubblicità.
Giacomo Wu è un Senior AI/ML Specialist Solution Architect presso AWS. aiutare i clienti a progettare e realizzare soluzioni AI/ML. Il lavoro di James copre un'ampia gamma di casi d'uso di ML, con un interesse primario per la visione artificiale, il deep learning e la scalabilità del ML in tutta l'azienda. Prima di entrare in AWS, James è stato architetto, sviluppatore e leader tecnologico per oltre 10 anni, di cui 6 in ingegneria e 4 anni nei settori del marketing e della pubblicità.
 Li Ning è un ingegnere informatico senior presso AWS con una specializzazione nella creazione di soluzioni AI su larga scala. In qualità di responsabile tecnologico per TorchServe, un progetto sviluppato congiuntamente da AWS e Meta, la sua passione risiede nello sfruttare PyTorch e AWS SageMaker per aiutare i clienti ad abbracciare l'intelligenza artificiale per il bene comune. Al di fuori dei suoi impegni professionali, a Li piace nuotare, viaggiare, seguire gli ultimi progressi tecnologici e trascorrere del tempo di qualità con la sua famiglia.
Li Ning è un ingegnere informatico senior presso AWS con una specializzazione nella creazione di soluzioni AI su larga scala. In qualità di responsabile tecnologico per TorchServe, un progetto sviluppato congiuntamente da AWS e Meta, la sua passione risiede nello sfruttare PyTorch e AWS SageMaker per aiutare i clienti ad abbracciare l'intelligenza artificiale per il bene comune. Al di fuori dei suoi impegni professionali, a Li piace nuotare, viaggiare, seguire gli ultimi progressi tecnologici e trascorrere del tempo di qualità con la sua famiglia.
 Ankith Gunapal è un ingegnere partner AI presso Meta (PyTorch). È appassionato di ottimizzazione dei modelli e di model service, con un'esperienza che spazia dalla verifica RTL, al software incorporato, alla visione artificiale, a PyTorch. Ha conseguito un Master in Data Science e un Master in Telecomunicazioni. Al di fuori del lavoro, Ankith è anche un produttore di musica dance elettronica.
Ankith Gunapal è un ingegnere partner AI presso Meta (PyTorch). È appassionato di ottimizzazione dei modelli e di model service, con un'esperienza che spazia dalla verifica RTL, al software incorporato, alla visione artificiale, a PyTorch. Ha conseguito un Master in Data Science e un Master in Telecomunicazioni. Al di fuori del lavoro, Ankith è anche un produttore di musica dance elettronica.
 Saurabh Trikande è un Senior Product Manager per Amazon SageMaker Inference. È appassionato di lavorare con i clienti ed è motivato dall'obiettivo di democratizzare l'apprendimento automatico. Si concentra sulle sfide principali relative all'implementazione di applicazioni ML complesse, modelli ML multi-tenant, ottimizzazioni dei costi e rendere più accessibile l'implementazione di modelli di deep learning. Nel tempo libero, Saurabh ama fare escursioni, conoscere tecnologie innovative, seguire TechCrunch e trascorrere del tempo con la sua famiglia.
Saurabh Trikande è un Senior Product Manager per Amazon SageMaker Inference. È appassionato di lavorare con i clienti ed è motivato dall'obiettivo di democratizzare l'apprendimento automatico. Si concentra sulle sfide principali relative all'implementazione di applicazioni ML complesse, modelli ML multi-tenant, ottimizzazioni dei costi e rendere più accessibile l'implementazione di modelli di deep learning. Nel tempo libero, Saurabh ama fare escursioni, conoscere tecnologie innovative, seguire TechCrunch e trascorrere del tempo con la sua famiglia.
 Subhash Talluri è un architetto capo delle soluzioni AI/ML della business unit Telecom Industry di Amazon Web Services. È stato alla guida dello sviluppo di soluzioni AI/ML innovative per clienti e partner di telecomunicazioni in tutto il mondo. Porta competenze interdisciplinari in ingegneria e informatica per contribuire a creare soluzioni AI/ML scalabili, sicure e conformi tramite architetture ottimizzate per il cloud su AWS.
Subhash Talluri è un architetto capo delle soluzioni AI/ML della business unit Telecom Industry di Amazon Web Services. È stato alla guida dello sviluppo di soluzioni AI/ML innovative per clienti e partner di telecomunicazioni in tutto il mondo. Porta competenze interdisciplinari in ingegneria e informatica per contribuire a creare soluzioni AI/ML scalabili, sicure e conformi tramite architetture ottimizzate per il cloud su AWS.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Automobilistico/VE, Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Grafico Prime. Migliora il tuo gioco di trading con ChartPrime. Accedi qui.
- BlockOffset. Modernizzare la proprietà della compensazione ambientale. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/run-multiple-generative-ai-models-on-gpu-using-amazon-sagemaker-multi-model-endpoints-with-torchserve-and-save-up-to-75-in-inference-costs/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 19
- 200
- 28
- 300
- 500
- 52
- 7
- 8
- 9
- a
- WRI
- sopra
- accelerare
- accelerata
- accetta
- accesso
- accessibile
- Raggiungere
- raggiunto
- operanti in
- Action
- aggiungere
- aggiunta
- aggiuntivo
- avanzamenti
- Vantaggio
- contraddittorio
- Pubblicità
- Dopo shavasana, sedersi in silenzio; saluti;
- AI
- Modelli AI
- AI / ML
- Algoritmi
- Tutti
- consentire
- Consentire
- consente
- lungo
- anche
- Amazon
- Amazon Sage Maker
- Amazon Web Services
- an
- ed
- Annunciare
- in qualsiasi
- nulla
- api
- applicazioni
- architettura
- SONO
- RISERVATA
- argomenti
- Artisti
- opere d'arte
- AS
- At
- attenzione
- gli attributi
- automaticamente
- Automatizzare
- evitare
- AWS
- Backed
- base
- basato
- BE
- perché
- stato
- prima
- dietro
- essendo
- sotto
- benefico
- beneficio
- vantaggi
- fra
- Miliardo
- Porta
- costruire
- Costruzione
- costruito
- onere
- affari
- aziende
- ma
- by
- Responsabile Campagne
- Materiale
- funzionalità
- Ultra-Grande
- catturato
- cattura
- Custodie
- casi
- certo
- sfide
- il cambiamento
- oneri
- scegliere
- codice
- Uncommon
- completamento di una
- complesso
- compiacente
- incluso
- Calcolare
- computer
- Informatica
- Visione computerizzata
- preoccupazioni
- Configurazione
- Confermare
- consapevole
- Prendere in considerazione
- consolidamento
- Contenitore
- contenuto
- creatori di contenuti
- contesto
- coordinare
- copie
- Nucleo
- correggere
- Costo
- risparmi
- Costi
- potuto
- copre
- creare
- crea
- creatori
- costume
- cliente
- esperienza del cliente
- Clienti
- danza
- dati
- scienza dei dati
- datetime
- deep
- apprendimento profondo
- definire
- definisce
- definizione
- Richiesta
- richieste
- democratizzare
- dimostrare
- dimostrato
- dimostra
- schierare
- schierato
- distribuzione
- deployment
- descritta
- Design
- progettato
- desiderato
- dettaglio
- dettagliati
- dettagli
- sviluppare
- sviluppato
- Costruttori
- Mercato
- differenza
- differenze
- Emittente
- direttamente
- docker
- Cane
- fatto
- scaricare
- dinamicamente
- ogni
- In precedenza
- est
- montaggio
- in modo efficiente
- Elettronico
- elimina
- incorporato
- abbraccio
- enable
- consentendo
- fine
- sforzi
- endpoint
- endpoint
- ingegnere
- Ingegneria
- migliorata
- Impresa
- iscrizione
- Etere (ETH)
- esempio
- eccellente
- eccitato
- esistente
- esperienza
- competenza
- esplora
- familiare
- famiglia
- più veloce
- caratteristica
- Caratteristiche
- Compila il
- File
- riempire
- finale
- Nome
- flusso
- si concentra
- seguire
- i seguenti
- segue
- Nel
- Fondazione
- quattro
- quadri
- da
- function
- generare
- generato
- genera
- generativo
- AI generativa
- ottenere
- GitHub
- dato
- dà
- globali
- contesto globale
- scopo
- buono
- GPU
- GPU
- grande
- maggiore
- Criceto
- Avere
- he
- Aiuto
- aiutare
- suo
- qui
- alta qualità
- Highlight
- Evidenziato
- escursionismo
- il suo
- detiene
- host
- ospitato
- di hosting
- padroni di casa
- ora
- Casa
- Come
- Tutorial
- http
- HTTPS
- centinaia
- illustra
- Immagine
- immagini
- immaginazione
- realizzare
- importare
- migliorata
- in
- Compreso
- incorpora
- Aumento
- è aumentato
- industrie
- industria
- informazioni
- creativi e originali
- tecnologie innovative
- ingresso
- install
- esempio
- istruzioni
- interesse
- ai miglioramenti
- invitare
- IT
- SUO
- Giacomo
- accoppiamento
- jpg
- json
- ad appena
- conosciuto
- Discografica
- grandi
- larga scala
- Cognome
- Latenza
- con i più recenti
- portare
- leader
- principale
- Leads
- IMPARARE
- apprendimento
- Livello
- leveraging
- li
- biblioteche
- si trova
- piace
- Lista
- elencati
- caricare
- Caricamento in corso
- carichi
- locale
- a livello locale
- località
- macchina
- machine learning
- fatto
- Principale
- FA
- Fare
- gestito
- gestione
- direttore
- gestisce
- gestione
- Marketing
- Marketing e pubblicità
- mask
- Mascherine
- massiccio
- master
- matplotlib
- Soddisfare
- Memorie
- Meta
- metaricerca
- metodo
- metodi
- milione
- mancante
- ML
- modello
- modelli
- modificare
- modulo
- Mese
- Scopri di più
- maggior parte
- motivato
- molti
- multiplo
- Musica
- Nome
- Bisogno
- di applicazione
- Rete
- New
- GENERAZIONE
- Nessuna
- taccuino
- numero
- oggetto
- oggetti
- osservare
- of
- on
- una volta
- ONE
- esclusivamente
- open source
- operazione
- operativa
- ottimizzazione
- ottimizzazione
- Opzione
- or
- i
- nostro
- produzione
- al di fuori
- ancora
- proprio
- pacchetto
- Packages
- parametro
- parametri
- particolare
- particolarmente
- partner
- partner
- Ricambi
- passione
- appassionato
- modelli
- per
- autorizzazione
- personalizzazione
- conduttura
- pixel
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- per favore
- punto
- possibile
- Post
- energia
- potente
- Predictor
- Preparare
- prezzo
- primario
- Precedente
- processi
- produttore
- Prodotto
- product manager
- Produzione
- professionale
- progetto
- fornire
- purché
- fornisce
- fornitura
- pubblicato
- Spingi
- spinto
- Python
- pytorch
- qualità
- quantità
- Presto
- gamma
- che vanno
- Leggi
- riceve
- raccomandato
- riduce
- riducendo
- regione
- relazionato
- rimozione
- rimuovere
- ripetitivo
- sostituire
- richiesta
- richieste
- richiedere
- necessario
- riparazioni
- risorsa
- Risorse
- risposta
- risposte
- REST
- restauro
- Risultati
- ritorno
- problemi
- RGB
- Correre
- sagemaker
- Inferenza di SageMaker
- Sam
- stesso
- Risparmi
- Risparmio
- scalabile
- Scala
- bilancia
- scala
- Scienze
- SD
- sdk
- Secondo
- Sezione
- sicuro
- vedere
- segmento
- segmentazione
- prodotti
- AUTO
- inviare
- invia
- anziano
- Sequenza
- Servizi
- servizio
- condiviso
- compartecipazione
- Conchiglia
- mostrare attraverso le sue creazioni
- mostrato
- Spettacoli
- simile
- Un'espansione
- semplificata
- semplificare
- contemporaneamente
- singolo
- Taglia
- frammento
- So
- Software
- Software Engineer
- soluzione
- Soluzioni
- specialista
- specializzata
- velocità
- Spendere
- Spin
- Stabilità
- stabile
- pila
- inizia a
- iniziato
- Regione / Stato
- state-of-the-art
- costante
- step
- Passi
- Ancora
- conservazione
- La struttura
- tale
- sufficiente
- fornitura
- supporto
- nuoto
- tavolo
- Fai
- prende
- Target
- task
- Tech
- TechCrunch
- Tecnologie
- Tecnologia
- telecom
- telecomunicazioni
- tensorflow
- testo
- che
- Il
- loro
- Li
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- migliaia
- tre
- Attraverso
- tempo
- a
- oggi
- torcia
- traffico
- allenato
- trasformatori
- Di viaggio
- Tipi di
- ui
- in definitiva
- unità
- non desiderato
- caricato
- us
- Impiego
- uso
- caso d'uso
- utilizzato
- Utente
- Esperienza da Utente
- usa
- utilizzando
- utilizzati
- Utilizzando
- Convalida
- via
- Virginia
- visione
- Visita
- volere
- Prima
- we
- sito web
- servizi web
- quando
- quale
- while
- largo
- Vasta gamma
- molto diffuso
- volere
- con
- Lavora
- lavoratori
- flusso di lavoro
- lavoro
- In tutto il mondo
- sarebbe
- anni
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro