Esperti al tavolo: Semiconductor Engineering si è seduto per parlare del percorso da seguire per la memoria in sistemi sempre più eterogenei, con Frank Ferro, direttore del gruppo, gestione del prodotto presso Cadenza; Steven Woo, collega e illustre inventore presso Rambus; Jongsin Yun, esperto di tecnologie della memoria presso SiemensEDA; Randy White, responsabile del programma soluzioni di memoria presso Keysight; e Frank Schirrmeister, vicepresidente delle soluzioni e dello sviluppo aziendale presso arteris. Quelli che seguono sono estratti di quella conversazione. La prima parte di questa discussione può essere trovata qui.
![[L-R]: Frank Ferro, Cadenza; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; e Frank Schirrmeister, Arteris.](https://platoaistream.com/wp-content/uploads/2024/01/rethinking-memory.png)
[L-R]: Frank Ferro, Cadenza; Steven Woo, Rambus; Jongsin Yun, Siemens EDA; Randy White, Keysight; e Frank Schirrmeister, Arteris
SE: Mentre lottiamo con AI/ML e richieste di potenza, quali configurazioni devono essere ripensate? Vedremo un allontanamento dall’architettura di Von Neumann?
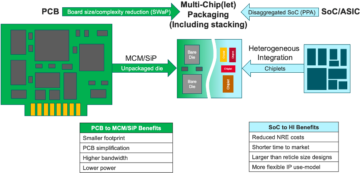
Corteggiare: In termini di architetture di sistema, è in corso una biforcazione nel settore. Le applicazioni tradizionali che rappresentano i cavalli di battaglia dominanti, che eseguiamo nel cloud su server basati su x86, non scompariranno. Esistono decenni di software che sono stati creati ed evoluti e che faranno affidamento su quell'architettura per funzionare bene. Al contrario, AI/ML è una nuova classe. Le persone hanno ripensato le architetture e costruito processori molto specifici del dominio. Abbiamo notato che circa due terzi dell'energia vengono spesi semplicemente spostando i dati tra un processore e un dispositivo HBM, mentre solo circa un terzo viene speso per accedere effettivamente ai bit nei core DRAM. Lo spostamento dei dati è ora molto più impegnativo e costoso. Non ci libereremo della memoria. Ne abbiamo bisogno perché i set di dati stanno diventando più grandi. Quindi la domanda è: “Qual è la strada giusta da seguire?” Si è discusso molto sullo stacking. Se prendessimo quella memoria e la mettessimo direttamente sopra il processore, fa due cose per te. Innanzitutto, la larghezza di banda oggi è limitata dalla costa o dal perimetro del chip. È lì che vanno gli I/O. Ma se lo impilassi direttamente sopra il processore, ora puoi utilizzare l'intera area del chip per interconnessioni distribuite, e puoi ottenere più larghezza di banda nella memoria stessa, e può alimentare direttamente in il processore. I collegamenti diventano molto più brevi e l'efficienza energetica probabilmente aumenta nell'ordine di 5X-6X. In secondo luogo, anche la quantità di larghezza di banda che è possibile ottenere grazie alla maggiore interconnessione dell'array di area con la memoria aumenta di diversi fattori interi. Fare queste due cose insieme può fornire più larghezza di banda e renderlo più efficiente dal punto di vista energetico. Il settore si evolve in base a qualunque siano le esigenze, e questo è sicuramente un modo in cui vedremo i sistemi di memoria iniziare ad evolversi in futuro per diventare più efficienti dal punto di vista energetico e fornire più larghezza di banda.
Ferro da stiro: Quando ho iniziato a lavorare sulla HBM intorno al 2016, alcuni dei clienti più avanzati mi hanno chiesto se poteva essere impilabile. Stanno cercando da tempo come impilare la DRAM sopra perché ci sono chiari vantaggi. Dal livello fisico, il PHY diventa sostanzialmente trascurabile, il che consente di risparmiare molta energia ed efficienza. Ma ora hai un processore da diversi 100 W con sopra una memoria. La memoria non può sopportare il calore. È probabilmente l’anello più debole della catena del calore, il che crea un’altra sfida. Ci sono dei vantaggi, ma devono ancora capire come affrontare le temperature. Ora ci sono più incentivi per portare avanti questo tipo di architettura, perché ti fa davvero risparmiare complessivamente in termini di prestazioni e potenza e migliorerà la tua efficienza di elaborazione. Ma ci sono alcune sfide di progettazione fisica che devono essere affrontate. Come diceva Steve, vediamo che stanno emergendo tutti i tipi di architetture. Sono totalmente d’accordo sul fatto che le architetture GPU/CPU non andranno da nessuna parte, continueranno a essere dominanti. Allo stesso tempo, ogni azienda del pianeta sta cercando di inventare una trappola per topi migliore per gestire la propria intelligenza artificiale. Vediamo SRAM su chip e combinazioni di memoria a larghezza di banda elevata. LPDDR ha alzato un po' la testa in questi giorni in termini di come sfruttare l'LPDDR nel data center a causa della sua potenza. Abbiamo anche visto GDDR utilizzato in alcune applicazioni di inferenza AI, così come in tutti i vecchi sistemi di memoria. Ora stanno cercando di comprimere il maggior numero possibile di DDR5 in un ingombro. Ho visto ogni architettura a cui puoi pensare, che si tratti di DDR, HBM, GDDR o altre. Dipende dal core del tuo processore in termini di valore aggiunto complessivo e quindi di come puoi superare la tua particolare architettura. Il sistema di memoria che lo accompagna, così puoi scolpire la tua CPU e l'architettura della tua memoria, a seconda di ciò che è disponibile.
Yun: Un altro problema è la non volatilità. Se l'IA deve gestire l'intervallo di alimentazione tra l'esecuzione di un'IA basata sull'IoT, ad esempio, allora abbiamo bisogno di molta energia e tutte queste informazioni per l'addestramento dell'IA devono ruotare ancora e ancora. Se disponiamo di un qualche tipo di soluzione in cui possiamo memorizzare tali pesi nel chip in modo da non dover spostarci sempre avanti e indietro per lo stesso peso, allora si otterrà un notevole risparmio energetico, soprattutto per l’intelligenza artificiale basata sull’IoT. Ci sarà un’altra soluzione per aiutare queste richieste di potere.
Schirrmeister: Ciò che trovo affascinante, dal punto di vista NoC, è il modo in cui devi ottimizzare questi percorsi da un processore che passa attraverso un NoC, accedendo a un'interfaccia di memoria con un controller che potenzialmente passa attraverso UCIe per passare un chiplet a un altro chiplet, che quindi ha memoria in Esso. Non è che le architetture di Von Neumann siano morte. Ma ora ci sono così tante varianti, a seconda del carico di lavoro che vorresti calcolare. Devono essere considerati nel contesto della memoria, e la memoria è solo un aspetto. Dove prendi i dati dalla località dei dati, come sono organizzati in questa DRAM? Stiamo lavorando su tutte queste cose, come l'analisi delle prestazioni delle memorie e quindi l'ottimizzazione dell'architettura del sistema su di esse. Sta stimolando molta innovazione per le nuove architetture, a cui non avevo mai pensato quando ero all'università e stavo imparando a conoscere Von Neumann. All'estremo opposto ci sono cose come le mesh. Ci sono molte più architetture intermedie da prendere in considerazione, ed è guidato dalla larghezza di banda della memoria, dalle capacità di elaborazione e così via, che non crescono allo stesso ritmo.
Bianco: C’è una tendenza che coinvolge il calcolo disaggregato o il calcolo distribuito, il che significa che l’architetto deve avere più strumenti a propria disposizione. La gerarchia della memoria si è ampliata. Sono incluse la semantica, nonché CXL e diverse memorie ibride, disponibili per flash e DRAM. Un'applicazione parallela al data center è quella automobilistica. Il settore automobilistico ha sempre utilizzato questo sensore per il calcolo con le ECU (unità di controllo elettroniche). Sono affascinato da come si è evoluto nel data center. Avanti veloce e oggi abbiamo nodi di elaborazione distribuiti, chiamati controller di dominio. È la stessa cosa. Sta cercando di affrontare il fatto che forse il potere non è un grosso problema perché la scala dei computer non è così grande, ma la latenza è sicuramente un grosso problema nel settore automobilistico. Gli ADAS necessitano di una larghezza di banda estremamente elevata e ci sono diversi compromessi. E poi ci sono più sensori meccanici, ma vincoli simili in un data center. Hai una memoria fredda che non deve necessariamente essere a bassa latenza, e poi hai altre applicazioni a larghezza di banda elevata. È affascinante vedere quanto si siano evoluti gli strumenti e le opzioni a disposizione dell’architetto. L’industria ha fatto davvero un ottimo lavoro nel rispondere e tutti noi forniamo varie soluzioni che alimentano il mercato.
SE: Come si sono evoluti gli strumenti di progettazione della memoria?
Schirrmeister: Quando ho iniziato con i miei primi chip negli anni ’90, lo strumento di sistema più utilizzato era Excel. Da allora, ho sempre sperato che a un certo punto potesse rompersi per le cose che facciamo a livello di sistema, memoria, analisi della larghezza di banda e così via. Ciò ha influenzato parecchio le mie squadre. All'epoca era roba molto avanzata. Ma secondo Randy, ora alcune cose complesse devono essere simulate a un livello di fedeltà che prima non era possibile senza il calcolo. Per fare un esempio, assumere una certa latenza per l'accesso alla DRAM può portare a decisioni sbagliate sull'architettura e alla progettazione potenzialmente errata di architetture di trasporto dati su chip. È vero anche il rovescio della medaglia. Se si assume sempre il caso peggiore, si progetterà eccessivamente l'architettura. Avere strumenti che eseguono l'analisi della DRAM e delle prestazioni e avere i modelli adeguati disponibili per i controller consente a un architetto di simulare tutto, è un ambiente affascinante in cui trovarsi. La mia speranza dagli anni '90 che Excel potesse a un certo punto rompersi come un strumento a livello di sistema potrebbe effettivamente diventare realtà, perché alcuni degli effetti dinamici che non puoi più eseguire in Excel perché devi simularli, specialmente quando inserisci un'interfaccia die-to-die con caratteristiche PHY e quindi colleghi il livello caratteristiche come il controllo se tutto era corretto e potenzialmente il reinvio dei dati. La mancata esecuzione di tali simulazioni risulterà in un'architettura non ottimale.
Ferro da stiro: Il primo passo nella maggior parte delle valutazioni che facciamo è fornire loro il banco di prova della memoria per iniziare a esaminare l'efficienza della DRAM. È un passo enorme, anche fare cose semplici come eseguire strumenti locali per eseguire la simulazione DRAM, ma poi passare a simulazioni in piena regola. Vediamo più clienti che richiedono questo tipo di simulazione. Assicurarsi che l'efficienza della DRAM sia negli anni '90 è un primo passo molto importante in qualsiasi valutazione.
Corteggiare: Parte del motivo per cui si vede l’ascesa degli strumenti di simulazione del sistema completo è che le DRAM sono diventate molto più complicate. Ora è molto difficile essere al bar per alcuni di questi carichi di lavoro complessi utilizzando strumenti semplici come Excel. Se guardi la scheda tecnica della DRAM negli anni '90, quelle schede tecniche erano circa 40 pagine. Ora sono centinaia di pagine. Questo parla solo della complessità del dispositivo per ottenere larghezze di banda elevate. A questo si aggiunge il fatto che la memoria è un fattore determinante nel costo del sistema, nonché nella larghezza di banda e nella latenza relative alle prestazioni del processore. È anche un grande driver in termini di potenza, quindi ora è necessario simulare a un livello molto più dettagliato. In termini di flusso degli strumenti, gli architetti di sistema comprendono che la memoria è un driver enorme. Pertanto gli strumenti devono essere più sofisticati e devono interfacciarsi molto bene con altri strumenti in modo che l'architetto del sistema abbia la migliore visione globale di ciò che sta accadendo, in particolare dell'impatto della memoria sul sistema.
Yun: Mentre passiamo all’era dell’intelligenza artificiale, vengono utilizzati molti sistemi multi-core, ma non sappiamo quali dati vanno dove. Inoltre, andrà più parallelamente al chip. La dimensione della memoria è molto più grande. Se utilizziamo il tipo di intelligenza artificiale ChatGPT, la gestione dei dati per i modelli richiede circa 350 MB di dati, che è un'enorme quantità di dati solo per un peso, e l'input/output effettivo è molto più grande. Questo aumento della quantità di dati richiesti significa che ci sono molti effetti probabilistici che non abbiamo mai visto prima. È un test estremamente impegnativo vedere tutti gli errori relativi a questa grande quantità di memoria. E l’ECC è utilizzato ovunque, anche nella SRAM, che tradizionalmente non utilizzava l’ECC, ma ora è molto comune per i sistemi più grandi. Testare tutto ciò è molto impegnativo e deve essere supportato da soluzioni EDA per testare tutte queste diverse condizioni.
SE: Quali sfide devono affrontare quotidianamente i team di ingegneri?
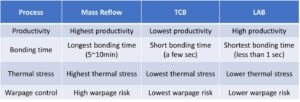
Bianco: Ogni giorno mi troverete nel laboratorio. Mi rimbocco le maniche e mi sporco le mani, ficcando fili, saldando e quant'altro. Penso molto alla convalida post-silicio. Abbiamo parlato delle prime simulazioni e degli strumenti on-die: BiST e cose del genere. In fin dei conti, prima della spedizione, vogliamo eseguire una qualche forma di convalida del sistema o test a livello di dispositivo. Abbiamo parlato di come superare il muro della memoria. Co-localizziamo la memoria, HBM, cose del genere. Se guardiamo all’evoluzione della tecnologia di imballaggio, abbiamo iniziato con imballaggi contenenti piombo. Non erano molto buoni per l’integrità del segnale. Decenni dopo, siamo passati a un'integrità del segnale ottimizzata, come i Ball Grid Array (BGA). Non siamo riusciti ad accedervi, il che significa che non potevi testarlo. Quindi abbiamo ideato questo concetto chiamato interposer di dispositivi - un interposer BGA - e questo ci ha permesso di inserire un dispositivo speciale che instradava i segnali. Quindi potremmo collegarlo all'apparecchiatura di prova. Avanti veloce fino ad oggi, e ora abbiamo HBM e chiplet. Come inserisco il mio dispositivo nell'interpositore in silicio? Non possiamo, e questa è la lotta. È una sfida che mi tiene sveglio la notte. Come possiamo eseguire l'analisi dei guasti sul campo con un OEM o un cliente di sistema, dove non ottengono l'efficienza del 90%. Sono presenti più errori nel collegamento, non è possibile inizializzarli correttamente e la formazione non funziona. È un problema di integrità del sistema?
Schirrmeister: Non preferiresti farlo da casa con un’interfaccia virtuale piuttosto che andare in laboratorio? La risposta non è più analisi integrate nel chip? Con i chiplet integriamo tutto ancora di più. Inserire il saldatore lì non è davvero un'opzione, quindi deve esserci un modo per l'analisi su chip. Abbiamo lo stesso problema per la NoC. Le persone guardano la NoC, tu invii i dati e poi spariscono. Abbiamo bisogno dell'analisi da inserire in modo che le persone possano eseguire il debug, e questo si estende al livello di produzione, in modo che tu possa finalmente lavorare da casa e fare tutto sulla base dell'analisi dei chip.
Ferro da stiro: Soprattutto con una memoria a larghezza di banda elevata, non puoi entrare fisicamente lì dentro. Quando concediamo in licenza il PHY abbiamo anche un prodotto che lo accompagna in modo che tu possa tenere d'occhio ognuno di quei 1,024 bit. Puoi iniziare a leggere e scrivere DRAM dallo strumento in modo da non dover entrare fisicamente lì. Mi piace l'idea dell'interpositore. Portiamo alcuni pin fuori dall'interpositore durante i test, cosa che non puoi fare nel sistema. È davvero una sfida entrare in questi sistemi 3D. Anche dal punto di vista del flusso degli strumenti di progettazione, sembra che la maggior parte delle aziende esegua il proprio flusso individuale su molti di questi strumenti 2.5D. Stiamo iniziando a mettere insieme un modo più standardizzato per costruire un sistema 2.5D, dall'integrità del segnale, alla potenza, all'intero flusso.
Bianco: Man mano che le cose vanno avanti, spero che riusciremo a mantenere lo stesso livello di precisione. Faccio parte del gruppo di conformità del fattore di forma UCIe. Sto cercando di caratterizzare un dado noto, un dado d'oro. Alla fine, ci vorrà molto più tempo, ma troveremo un giusto mezzo tra le prestazioni e l’accuratezza dei test di cui abbiamo bisogno e la flessibilità integrata.
Schirrmeister: Se esamino i chiplet e la loro adozione in un ambiente di produzione più aperto, i test rappresentano una delle sfide più grandi per farli funzionare correttamente. Se sono una grande azienda e ne controllo tutti gli aspetti, allora posso limitare le cose in modo appropriato in modo che i test e così via diventino fattibili. Se voglio riprendere lo slogan dell'UCIe secondo cui l'UCI è a una sola lettera di distanza dal PCI, e immagino un futuro in cui l'assemblaggio dell'UCIe diventi, dal punto di vista della produzione, come gli slot PCI di oggi in un PC, allora gli aspetti di test per questo sono davvero stimolante. Dobbiamo trovare una soluzione. C'è molto lavoro da fare.
Articoli Correlati
Il futuro della memoria (Parte 1 della tavola rotonda di cui sopra)
Dai tentativi di risolvere i problemi termici e energetici ai ruoli di CXL e UCIe, il futuro riserva una serie di opportunità per la memoria.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://semiengineering.com/rethinking-memory/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 2016
- 3d
- 40
- a
- WRI
- sopra
- accesso
- Accedendo
- precisione
- presenti
- effettivamente
- ADA
- aggiungere
- indirizzo
- Adozione
- Avanzate
- Vantaggio
- vantaggi
- ancora
- AI
- Addestramento AI
- AI / ML
- Tutti
- permesso
- consente
- anche
- sempre
- quantità
- an
- .
- analitica
- ed
- Un altro
- rispondere
- in qualsiasi
- più
- ovunque
- Applicazioni
- applicazioni
- appropriatamente
- architetti
- architettura
- SONO
- RISERVATA
- in giro
- disposte
- Italia
- AS
- chiedendo
- aspetto
- aspetti
- montaggio
- assumere
- At
- Tentativi
- settore automobilistico
- disponibile
- lontano
- precedente
- Vasca
- palla
- Larghezza di banda
- bar
- basato
- fondamentalmente
- base
- BE
- perché
- diventare
- diventa
- stato
- prima
- essendo
- vantaggi
- MIGLIORE
- Meglio
- fra
- Big
- maggiore
- Po
- Rompere
- portare
- costruire
- costruito
- affari
- sviluppo commerciale
- ma
- by
- Cadenza
- detto
- è venuto
- Materiale
- Può ottenere
- funzionalità
- Custodie
- centro
- certo
- certamente
- catena
- Challenge
- sfide
- impegnativo
- caratteristiche
- caratterizzare
- verifica
- patata fritta
- Chips
- classe
- pulire campo
- Cloud
- freddo
- Celle frigorifere
- combinazioni
- Venire
- arrivo
- Uncommon
- Aziende
- azienda
- complesso
- complessità
- conformità
- complicato
- Calcolare
- computer
- informatica
- concetto
- condizioni
- Connettiti
- considerato
- vincoli
- contesto
- contrasto
- di controllo
- controllore
- Conversazione
- Nucleo
- correggere
- Costo
- potuto
- Coppia
- CPU
- crea
- cliente
- Clienti
- dati
- Banca dati
- dataset
- giorno
- giorno per giorno
- Giorni
- morto
- affare
- decenni
- decisioni
- decisamente
- richieste
- Dipendente
- dipende
- Design
- progettazione
- dettagliati
- Mercato
- dispositivo
- *
- diverso
- difficile
- direttamente
- Direttore
- discussione
- smaltimento
- Distinto
- distribuito
- calcolo distribuito
- do
- effettua
- non
- fare
- dominio
- dominante
- fatto
- Dont
- giù
- spinto
- autista
- durante
- dinamico
- Presto
- effetti
- efficienza
- efficiente
- Elettronico
- fine
- energia
- Ingegneria
- Intero
- Ambiente
- usate
- epoca
- errori
- particolarmente
- Etere (ETH)
- valutazione
- valutazioni
- Anche
- alla fine
- Ogni
- qualunque cosa
- ovunque
- evoluzione
- evolvere
- si è evoluta
- si evolve
- esempio
- Excel
- ampliato
- costoso
- si estende
- estremo
- estremamente
- Occhi
- Faccia
- fatto
- fattore
- Fallimento
- affascinante
- FAST
- fattibile
- compagno
- fedeltà
- campo
- figura
- Infine
- Trovate
- Nome
- Cromatografia
- Flessibilità
- Capovolgere
- flusso
- segue
- Orma
- Nel
- modulo
- via
- Avanti
- essere trovato
- franco
- da
- pieno
- ulteriormente
- futuro
- ottenere
- ottenere
- Dare
- dato
- globali
- Go
- va
- andando
- d'oro
- andato
- buono
- buon lavoro
- ha ottenuto
- Griglia
- Gruppo
- Crescita
- ha avuto
- Manovrabilità
- Mani
- contento
- Avere
- avendo
- capo
- Aiuto
- gerarchia
- Alta
- detiene
- Casa
- speranza
- Come
- Tutorial
- HTML
- HTTPS
- Enorme
- centinaia
- IBRIDO
- i
- idea
- if
- immagine
- impattato
- impatto
- importante
- competenze
- in
- Incentivo
- incluso
- in modo non corretto
- Aumento
- sempre più
- individuale
- industria
- informazioni
- Innovazione
- interno
- integrare
- interezza
- interconnessioni
- Interfaccia
- ai miglioramenti
- coinvolgendo
- problema
- sicurezza
- IT
- SUO
- stessa
- Lavoro
- ad appena
- Sapere
- conosciuto
- laboratorio
- grandi
- superiore, se assunto singolarmente.
- maggiore
- Latenza
- dopo
- strato
- portare
- apprendimento
- lettera
- Livello
- Licenza
- piace
- Limitato
- LINK
- Collegamento
- locale
- Guarda
- cerca
- lotto
- lotti
- Basso
- mantenere
- make
- Fare
- gestione
- direttore
- consigliato per la
- molti
- Rappresentanza
- max-width
- può essere
- me
- si intende
- significava
- meccanico
- medie
- memorie
- Memorie
- forza
- modelli
- Scopri di più
- maggior parte
- cambiano
- mosso
- movimento
- in movimento
- molti
- my
- Bisogno
- esigenze
- mai
- New
- notte
- nodi
- adesso
- numero
- of
- MENO
- Vecchio
- on
- ONE
- esclusivamente
- aprire
- Opportunità
- OTTIMIZZA
- ottimizzati
- ottimizzazione
- Opzione
- Opzioni
- or
- minimo
- Altro
- Altri
- su
- complessivo
- Superare
- proprio
- Packages
- imballaggio
- pagine
- Parallel
- parte
- particolare
- passare
- sentiero
- percorsi
- PC
- Persone
- eseguire
- performance
- prospettiva
- Fisico
- Fisicamente
- pino
- pianeta
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- possibile
- potenzialmente
- energia
- Presidente
- in precedenza
- probabilmente
- Problema
- Processore
- processori
- Prodotto
- gestione del prodotto
- Produzione
- Programma
- corretto
- propriamente
- fornire
- metti
- domanda
- abbastanza
- raccolta
- tasso
- piuttosto
- Lettura
- veramente
- relazionato
- fare affidamento
- necessario
- richiede
- risolvere
- risponde
- colpevole
- Rid
- destra
- Aumento
- ruoli
- Rotolo
- Correre
- running
- stesso
- Risparmi
- Risparmio
- detto
- Scala
- Secondo
- vedere
- vedendo
- sembra
- visto
- semantica
- semiconduttore
- inviare
- sensore
- sensore
- server
- alcuni
- lenzuola
- spostamento
- nave
- lato
- lati
- Siemens
- Signal
- Segnali
- Silicio
- simile
- Un'espansione
- simulazione
- simulazioni
- da
- singolo
- Taglia
- slot
- So
- Software
- soluzione
- Soluzioni
- alcuni
- sofisticato
- Parla
- la nostra speciale
- esaurito
- Spremere
- pila
- impilato
- impilamento
- standardizzato
- punto di vista
- inizia a
- iniziato
- Di partenza
- step
- Steve
- steven
- Ancora
- conservazione
- Tornare al suo account
- Lotta
- tale
- supportato
- sicuro
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- Fai
- Parlare
- le squadre
- tecnologo
- Tecnologia
- condizioni
- test
- Testing
- test
- di
- che
- Il
- Il futuro
- loro
- Li
- poi
- Là.
- termico
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- cosa
- cose
- think
- Terza
- questo
- quelli
- pensiero
- Attraverso
- tempo
- a
- oggi
- insieme
- strumenti
- top
- COMPLETAMENTE
- compromessi
- tradizionale
- tradizionalmente
- Training
- trasporto
- Trend
- vero
- cerca
- seconda
- due terzi
- Digitare
- capire
- unità
- Università
- us
- uso
- utilizzato
- utilizzando
- convalida
- APPREZZIAMO
- variazioni
- vario
- molto
- vice
- Vicepresidente
- Visualizza
- virtuale
- di
- a piedi
- Muro
- volere
- Prima
- Modo..
- we
- peso
- WELL
- sono stati
- Che
- qualunque
- quando
- se
- quale
- while
- bianca
- tutto
- perché
- volere
- con
- senza
- Woo
- Lavora
- lavorare da casa
- lavoro
- Salsiccia di assorbimento
- scrittura
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro