Un sistema di intelligenza artificiale (AI) di nuova creazione basato sull'apprendimento per rinforzo profondo (DRL) può reagire agli aggressori in un ambiente simulato e bloccare il 95% degli attacchi informatici prima che si intensifichino.
Questo secondo i ricercatori del Pacific Northwest National Laboratory del Department of Energy, che hanno costruito una simulazione astratta del conflitto digitale tra aggressori e difensori in una rete e addestrato quattro diverse reti neurali DRL per massimizzare le ricompense in base alla prevenzione delle compromissioni e alla riduzione al minimo delle interruzioni della rete.
Gli attaccanti simulati hanno utilizzato una serie di tattiche basate sul MITRE ATT & CK classificazione del framework per passare dalla fase iniziale di accesso e ricognizione ad altre fasi di attacco fino a raggiungere il loro obiettivo: la fase di impatto ed esfiltrazione.
Il successo dell'addestramento del sistema di intelligenza artificiale sull'ambiente di attacco semplificato dimostra che le risposte difensive agli attacchi in tempo reale potrebbero essere gestite da un modello di intelligenza artificiale, afferma Samrat Chatterjee, un data scientist che ha presentato il lavoro del team alla riunione annuale dell'Associazione per il Avanzamento dell'intelligenza artificiale a Washington, DC il 14 febbraio.
"Non vuoi entrare in architetture più complesse se non puoi nemmeno mostrare la promessa di queste tecniche", dice. "Volevamo innanzitutto dimostrare che possiamo effettivamente addestrare un DRL con successo e mostrare alcuni buoni risultati dei test, prima di andare avanti".
L'applicazione delle tecniche di apprendimento automatico e di intelligenza artificiale a diversi campi all'interno della sicurezza informatica è diventata una tendenza in voga negli ultimi dieci anni, dalla prima integrazione dell'apprendimento automatico nei gateway di sicurezza della posta elettronica nei primi 2010 agli sforzi più recenti per usa ChatGPT per analizzare il codice o condurre analisi forensi. Ora, la maggior parte dei prodotti di sicurezza - o affermare di avere - alcune funzionalità alimentate da algoritmi di apprendimento automatico addestrati su set di dati di grandi dimensioni.
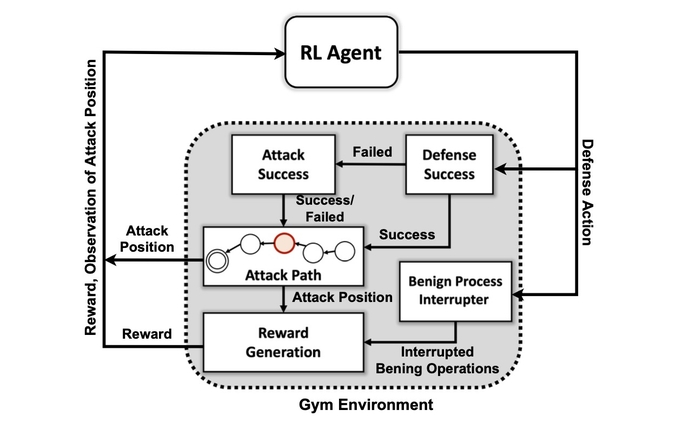
Tuttavia, la creazione di un sistema di intelligenza artificiale in grado di fornire una difesa proattiva continua a essere ambiziosa, piuttosto che pratica. Sebbene permangano una serie di ostacoli per i ricercatori, la ricerca del PNNL mostra che un difensore dell'IA potrebbe essere possibile in futuro.
"La valutazione di più algoritmi DRL addestrati in diverse impostazioni avversarie è un passo importante verso soluzioni pratiche di difesa informatica autonome", il team di ricerca PNNL dichiarato nel loro documento. "I nostri esperimenti suggeriscono che gli algoritmi DRL privi di modello possono essere efficacemente addestrati sotto profili di attacco a più fasi con diversi livelli di abilità e persistenza, ottenendo risultati di difesa favorevoli in contesti contestati".
Come il sistema utilizza MITRE ATT&CK
Il primo obiettivo del team di ricerca era creare un ambiente di simulazione personalizzato basato su un toolkit open source noto come Apri la palestra AI. Utilizzando tale ambiente, i ricercatori hanno creato entità attaccanti con diversi livelli di abilità e persistenza con la possibilità di utilizzare un sottoinsieme di 7 tattiche e 15 tecniche dal framework MITRE ATT&CK.
Gli obiettivi degli agenti attaccanti sono di muoversi attraverso le sette fasi della catena di attacco, dall'accesso iniziale all'esecuzione, dalla persistenza al comando e controllo e dalla raccolta all'impatto.
Per l'attaccante, adattare le proprie tattiche allo stato dell'ambiente e alle azioni attuali del difensore può essere complesso, afferma Chatterjee del PNNL.
"L'avversario deve farsi strada da uno stato di ricognizione iniziale fino a uno stato di esfiltrazione o impatto", afferma. "Non stiamo cercando di creare una sorta di modello per fermare un avversario prima che entri nell'ambiente: presumiamo che il sistema sia già compromesso".
I ricercatori hanno utilizzato quattro approcci alle reti neurali basati sull'apprendimento per rinforzo. L'apprendimento per rinforzo (RL) è un approccio di apprendimento automatico che emula il sistema di ricompensa del cervello umano. Una rete neurale apprende rafforzando o indebolendo determinati parametri per i singoli neuroni per premiare le soluzioni migliori, come misurato da un punteggio che indica le prestazioni del sistema.
L'apprendimento per rinforzo consente essenzialmente al computer di creare un approccio buono, ma non perfetto, al problema in questione, afferma Mahantesh Halappanavar, ricercatore del PNNL e autore dell'articolo.
"Senza utilizzare alcun apprendimento per rinforzo, potremmo ancora farlo, ma sarebbe davvero un grosso problema che non avrebbe abbastanza tempo per trovare effettivamente un buon meccanismo", afferma. "La nostra ricerca... ci fornisce questo meccanismo in cui l'apprendimento per rinforzo profondo imita in una certa misura parte del comportamento umano stesso, e può esplorare questo spazio molto vasto in modo molto efficiente".
Non pronto per il Prime Time
Gli esperimenti hanno scoperto che uno specifico metodo di apprendimento per rinforzo, noto come Deep Q Network, ha creato una forte soluzione al problema difensivo, catturare il 97% degli aggressori nel set di dati di test. Eppure la ricerca è solo l'inizio. I professionisti della sicurezza non dovrebbero cercare un compagno di intelligenza artificiale che li aiuti a rispondere agli incidenti e alle indagini forensi in qualunque momento presto.
Tra i molti problemi che restano da risolvere c'è l'ottenere l'apprendimento per rinforzo e le reti neurali profonde per spiegare i fattori che hanno influenzato le loro decisioni, un'area di ricerca chiamata apprendimento per rinforzo spiegabile (XRL).
Inoltre, la robustezza degli algoritmi di intelligenza artificiale e la ricerca di modi efficienti per addestrare le reti neurali sono entrambi problemi che devono essere risolti, afferma Chatterjee di PNNL.
"Creare un prodotto: non era questa la motivazione principale di questa ricerca", afferma. "Si trattava più di sperimentazione scientifica e scoperta algoritmica".
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.darkreading.com/emerging-tech/researchers-create-ai-cyber-defender-that-reacts-to-attackers
- 7
- 95%
- a
- capacità
- WRI
- ABSTRACT
- accesso
- Secondo
- azioni
- effettivamente
- aggiunta
- avanzamento
- contraddittorio
- agenti
- AI
- AI-alimentato
- algoritmica
- Algoritmi
- Tutti
- consente
- già
- .
- analizzare
- ed
- annuale
- Applicazioni
- approccio
- approcci
- RISERVATA
- artificiale
- intelligenza artificiale
- Intelligenza artificiale (AI)
- Associazione
- attacco
- attacchi
- autore
- autonomo
- basato
- diventare
- prima
- Meglio
- fra
- Big
- Bloccare
- Cervello
- costruito
- detto
- non può
- capace
- certo
- catena
- ChatGPT
- rivendicare
- classificazione
- collezione
- Venire
- complesso
- Compromissione
- computer
- Segui il codice di Condotta
- conflitto
- continua
- di controllo
- potuto
- creare
- creato
- Creazione
- Corrente
- costume
- Cyber
- attacchi informatici
- Cybersecurity
- dati
- scienziato di dati
- set di dati
- dataset
- dc
- decennio
- decisione
- decisioni
- deep
- reti neurali profonde
- Difensori
- Difesa
- difensiva
- dimostrare
- dimostra
- Shirts Department
- Dipartimento di Energia
- diverso
- digitale
- scoperta
- Rottura
- paesaggio differenziato
- DOE
- Presto
- in maniera efficace
- efficiente
- in modo efficiente
- sforzi
- sicurezza della posta elettronica
- energia
- abbastanza
- entità
- Ambiente
- essenzialmente
- Etere (ETH)
- la valutazione
- Anche
- esecuzione
- esfiltrazione
- Spiegare
- esplora
- Fattori
- Caratteristiche
- pochi
- campi
- ricerca
- Nome
- flusso
- Legale
- forense
- Avanti
- essere trovato
- Contesto
- da
- futuro
- ottenere
- ottenere
- dà
- scopo
- Obiettivi
- buono
- cura
- Aiuto
- HOT
- Come
- HTTPS
- umano
- ostacoli
- Impact
- importante
- in
- incidente
- risposta agli incidenti
- indicando
- individuale
- influenzato
- inizialmente
- integrazione
- Intelligence
- IT
- stessa
- Genere
- conosciuto
- di laboratorio
- grandi
- apprendimento
- livelli
- Guarda
- macchina
- machine learning
- Principale
- molti
- max-width
- Massimizzare
- meccanismo
- incontro
- metodo
- minimizzando
- modello
- Scopri di più
- Motivazione
- cambiano
- in movimento
- multiplo
- il
- Navigare
- Bisogno
- Rete
- reti
- Neurale
- rete neurale
- reti neurali
- neuroni
- aprire
- open source
- Altro
- Pacifico
- Carta
- parametri
- passato
- perfetta
- esegue
- persistenza
- fase
- Platone
- Platone Data Intelligence
- PlatoneDati
- possibile
- alimentato
- Pratico
- presentata
- prevenzione
- premio
- Proactive
- Problema
- problemi
- Prodotti
- Scelto dai professionisti
- Profili
- PROMETTIAMO
- RE
- a raggiunto
- Reagire
- reagisce
- pronto
- di rose
- tempo reale
- recente
- insegnamento rafforzativo
- rimanere
- riparazioni
- ricercatore
- ricercatori
- risposta
- Premiare
- Rewards
- robustezza
- dice
- Scienziato
- problemi di
- Serie
- set
- impostazioni
- Sette
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- semplificata
- simulazione
- abilità
- soluzione
- Soluzioni
- alcuni
- Arrivo
- Fonte
- lo spazio
- specifico
- inizia a
- Regione / Stato
- step
- Passi
- Ancora
- Fermare
- potenziamento
- forte
- di successo
- Con successo
- sistema
- tattica
- team
- tecniche
- Testing
- Il
- Il futuro
- Lo Stato
- loro
- Attraverso
- tempo
- a
- toolkit
- verso
- Treni
- allenato
- Training
- Trend
- per
- us
- uso
- varietà
- Fisso
- ricercato
- Washington
- modi
- while
- OMS
- volere
- entro
- senza
- Lavora
- sarebbe
- cedevole
- zefiro











