Nell'era digitale di oggi, i dati sono al centro del successo di ogni organizzazione. Uno dei formati più comunemente utilizzati per lo scambio di dati è XML. L'analisi dei file XML è fondamentale per diversi motivi. Innanzitutto, i file XML vengono utilizzati in molti settori, tra cui finanza, sanità e governo. L'analisi dei file XML può aiutare le organizzazioni a ottenere informazioni dettagliate sui propri dati, consentendo loro di prendere decisioni migliori e migliorare le proprie operazioni. L'analisi dei file XML può anche aiutare nell'integrazione dei dati, poiché molte applicazioni e sistemi utilizzano XML come formato dati standard. Analizzando i file XML, le organizzazioni possono facilmente integrare dati provenienti da fonti diverse e garantire la coerenza tra i loro sistemi. Tuttavia, i file XML contengono dati semistrutturati e altamente nidificati, rendendo difficile l'accesso e l'analisi delle informazioni, soprattutto se il file è di grandi dimensioni e ha schema complesso e altamente annidato.
I file XML sono adatti per le applicazioni, ma potrebbero non essere ottimali per i motori di analisi. Al fine di migliorare le prestazioni delle query e consentire un facile accesso ai motori di analisi downstream come Amazzone Atena, è fondamentale preelaborare i file XML in un formato colonnare come Parquet. Questa trasformazione consente una migliore efficienza e usabilità nei flussi di lavoro di analisi. In questo post, mostriamo come elaborare i dati XML utilizzando Colla AWS e Atena.
Panoramica della soluzione
Esploriamo due tecniche distinte che possono semplificare il flusso di lavoro di elaborazione dei file XML:
- Tecnica 1: utilizzare un crawler AWS Glue e l'editor visivo AWS Glue – Puoi utilizzare l'interfaccia utente di AWS Glue insieme a un crawler per definire la struttura della tabella per i file XML. Questo approccio fornisce un'interfaccia intuitiva ed è particolarmente adatto per le persone che preferiscono un approccio grafico alla gestione dei propri dati.
- Tecnica 2: utilizzare AWS Glue DynamicFrames con schemi dedotti e fissi – Il crawler presenta una limitazione quando si tratta di elaborare una singola riga in file XML più grandi di 1 MB. Per superare questa limitazione, utilizziamo un notebook AWS Glue per costruire AWS Glue
DynamicFrames, utilizzando sia schemi dedotti che fissi. Questo metodo garantisce una gestione efficiente dei file XML con righe di dimensioni superiori a 1 MB.
In entrambi gli approcci, il nostro obiettivo finale è convertire i file XML nel formato Apache Parquet, rendendoli immediatamente disponibili per l'esecuzione di query utilizzando Athena. Con queste tecniche, puoi migliorare la velocità di elaborazione e l'accessibilità dei tuoi dati XML, consentendoti di ottenere facilmente informazioni preziose.
Prerequisiti
Prima di iniziare questo tutorial, completa i seguenti prerequisiti (si applicano a entrambe le tecniche):
- Scarica i file XML tecnica1.xml ed tecnica2.xml.
- Carica i file su un file Servizio di archiviazione semplice Amazon (Amazon S3) secchio. Puoi caricarli nello stesso bucket S3 in cartelle diverse o in bucket S3 diversi.
- Creare un Gestione dell'identità e dell'accesso di AWS (IAM) per il tuo lavoro o notebook ETL come indicato in Configura le autorizzazioni IAM per AWS Glue Studio.
- Aggiungi una policy in linea al tuo ruolo con già: PassRole azione:
- Aggiungi una policy di autorizzazione al ruolo con accesso al tuo bucket S3.
Ora che abbiamo terminato con i prerequisiti, passiamo all'implementazione della prima tecnica.
Tecnica 1: utilizzare un crawler AWS Glue e l'editor visivo
Nel diagramma seguente viene illustrata la semplice architettura che è possibile utilizzare per implementare la soluzione.
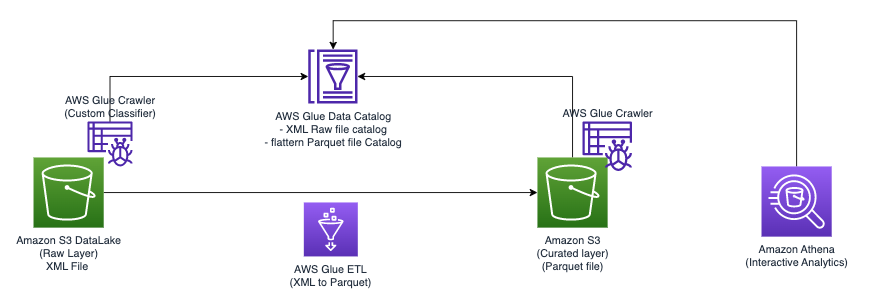
Per analizzare i file XML archiviati in Amazon S3 utilizzando AWS Glue e Athena, completiamo i seguenti passaggi di alto livello:
- Crea un crawler AWS Glue per estrarre metadati XML e creare una tabella nel catalogo dati di AWS Glue.
- Elabora e trasforma i dati XML in un formato (come Parquet) adatto ad Athena utilizzando un processo di estrazione, trasformazione e caricamento (ETL) di AWS Glue.
- Configura ed esegui un processo AWS Glue tramite la console AWS Glue o il Interfaccia della riga di comando di AWS (interfaccia a riga di comando dell'AWS).
- Utilizza i dati elaborati (in formato Parquet) con tabelle Athena, abilitando query SQL.
- Utilizza l'interfaccia intuitiva di Athena per analizzare i dati XML con query SQL sui dati archiviati in Amazon S3.
Questa architettura è una soluzione scalabile ed economica per analizzare i dati XML su Amazon S3 utilizzando AWS Glue e Athena. Puoi analizzare set di dati di grandi dimensioni senza una gestione complessa dell'infrastruttura.
Utilizziamo il crawler AWS Glue per estrarre i metadati dei file XML. Puoi scegliere il classificatore AWS Glue predefinito per la classificazione XML per scopi generici. Rileva automaticamente la struttura e lo schema dei dati XML, utile per i formati comuni.
In questa soluzione utilizziamo anche un classificatore XML personalizzato. È progettato per schemi o formati XML specifici, consentendo un'estrazione precisa dei metadati. Questo è l'ideale per i formati XML non standard o quando è necessario un controllo dettagliato sulla classificazione. Un classificatore personalizzato garantisce che vengano estratti solo i metadati necessari, semplificando le attività di elaborazione e analisi a valle. Questo approccio ottimizza l'uso dei file XML.
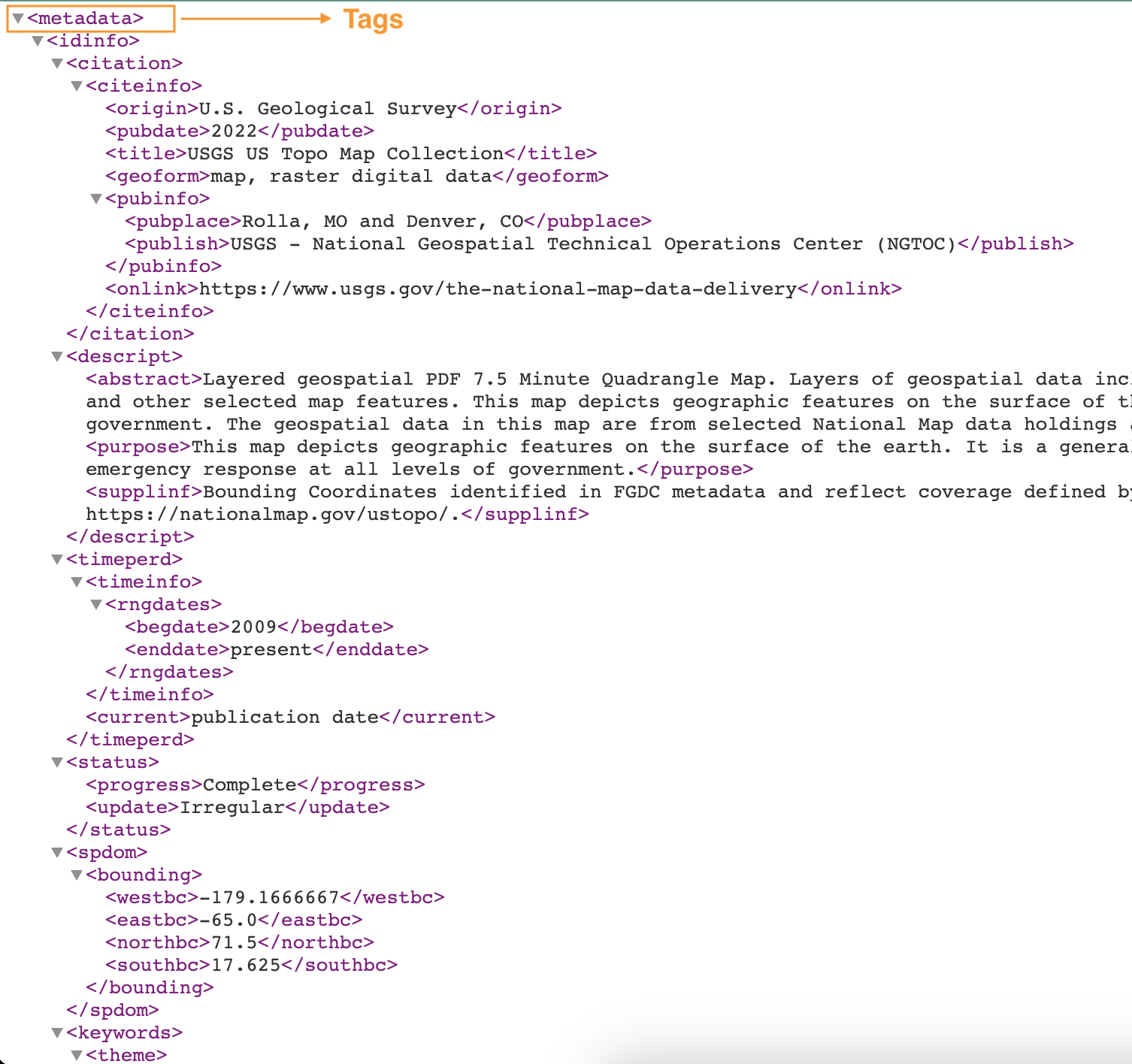
Lo screenshot seguente mostra un esempio di un file XML con tag.
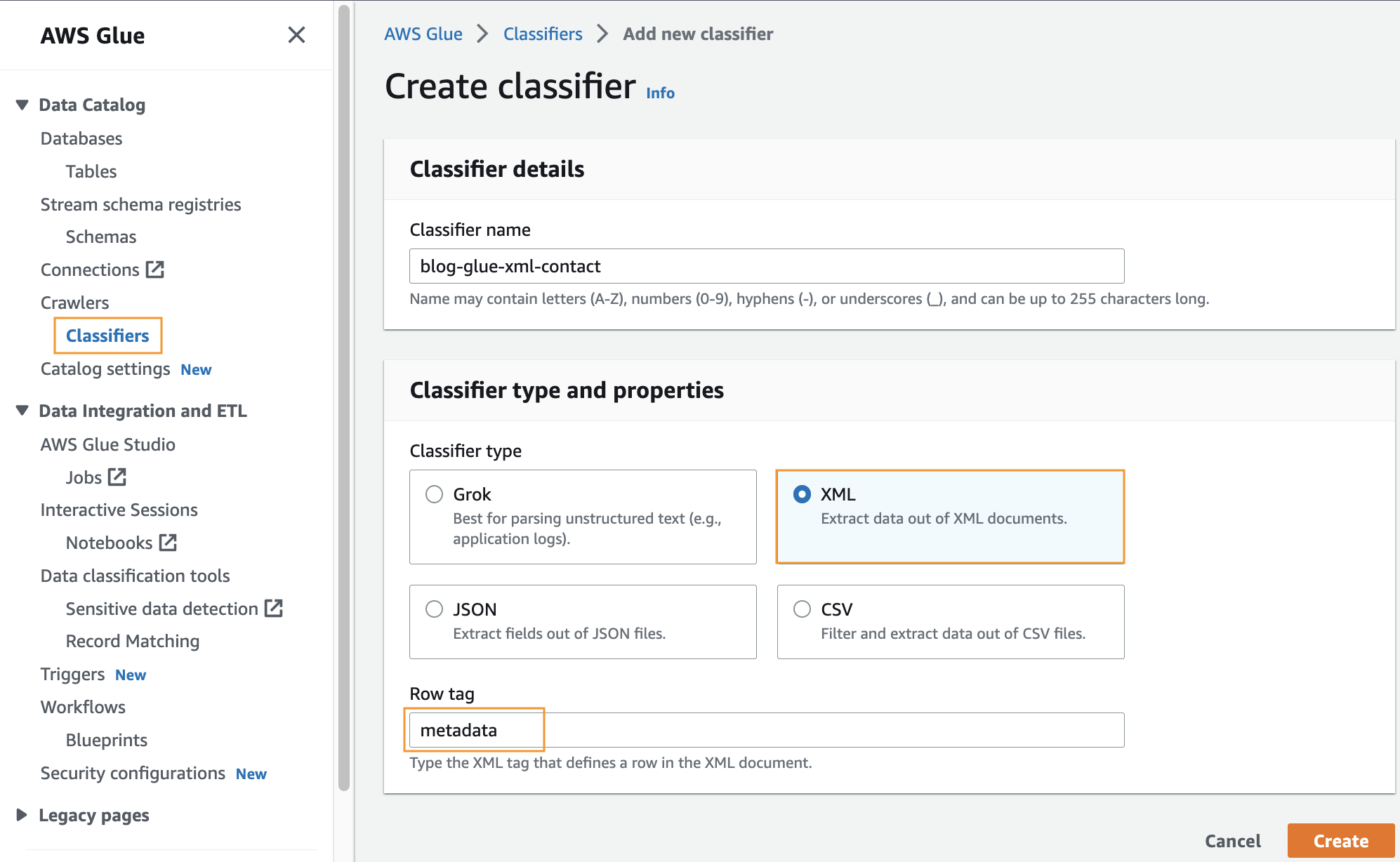
Crea un classificatore personalizzato
In questa fase creerai un classificatore AWS Glue personalizzato per estrarre i metadati da un file XML. Completa i seguenti passaggi:
- Sulla console AWS Glue, sotto Crawlers nel pannello di navigazione, scegli Classificatori.
- Scegli Aggiungi classificatore.
- Seleziona XML come tipo di classificatore.
- Inserisci un nome per il classificatore, ad esempio
blog-glue-xml-contact. - Nel Etichetta di riga, inserisci il nome del tag root che contiene i metadati (ad esempio,
metadata). - Scegli Creare.
Crea un crawler AWS Glue per eseguire la scansione del file xml
In questa sezione, stiamo creando un Glue Crawler per estrarre i metadati dal file XML utilizzando il classificatore del cliente creato nel passaggio precedente.
Crea un database
- Vai Console AWS Gluescegli Database nel pannello di navigazione.
- Fare clic su Aggiungi banca dati.
- Fornire un nome come
blog_glue_xml - Scegli Creare Banca Dati
Crea un crawler
Completa i seguenti passaggi per creare il tuo primo crawler:
- Nella console AWS Glue, scegli Crawlers nel pannello di navigazione.
- Scegli Crea cingolato.
- Sulla Imposta le proprietà del crawler pagina, fornisci un nome per il nuovo crawler (ad esempio
blog-glue-parquet), quindi scegliere Avanti. - Sulla Scegli origini dati e classificatori pagina, selezionare Non ancora per Configurazione dell'origine dati.
- Scegli Aggiungi un archivio dati.
- Nel Percorso S3, vai a
s3://${BUCKET_NAME}/input/geologicalsurvey/.
Assicurati di scegliere la cartella XML anziché il file all'interno della cartella.
- Lascia il resto delle opzioni come predefinite e scegli Aggiungi un'origine dati S3.
- Espandere Classificatori personalizzati: facoltativi, scegli blog-glue-xml-contact, quindi scegli Avanti e mantieni il resto delle opzioni come predefinite.
- Scegli il tuo ruolo IAM o scegli Crea un nuovo ruolo IAM, aggiungi il suffisso
glue-xml-contact(per esempio,AWSGlueServiceNotebookRoleBlog) e scegli Avanti. - Sulla Imposta output e pianificazione pagina, sotto Configurazione delle uscitescegli
blog_glue_xmlper Database di destinazione. - entrare
console_come prefisso aggiunto alle tabelle (facoltativo) e sotto Programma del crawler, mantenere la frequenza impostata su Su richiesta. - Scegli Avanti.
- Rivedi tutti i parametri e scegli Crea cingolato.
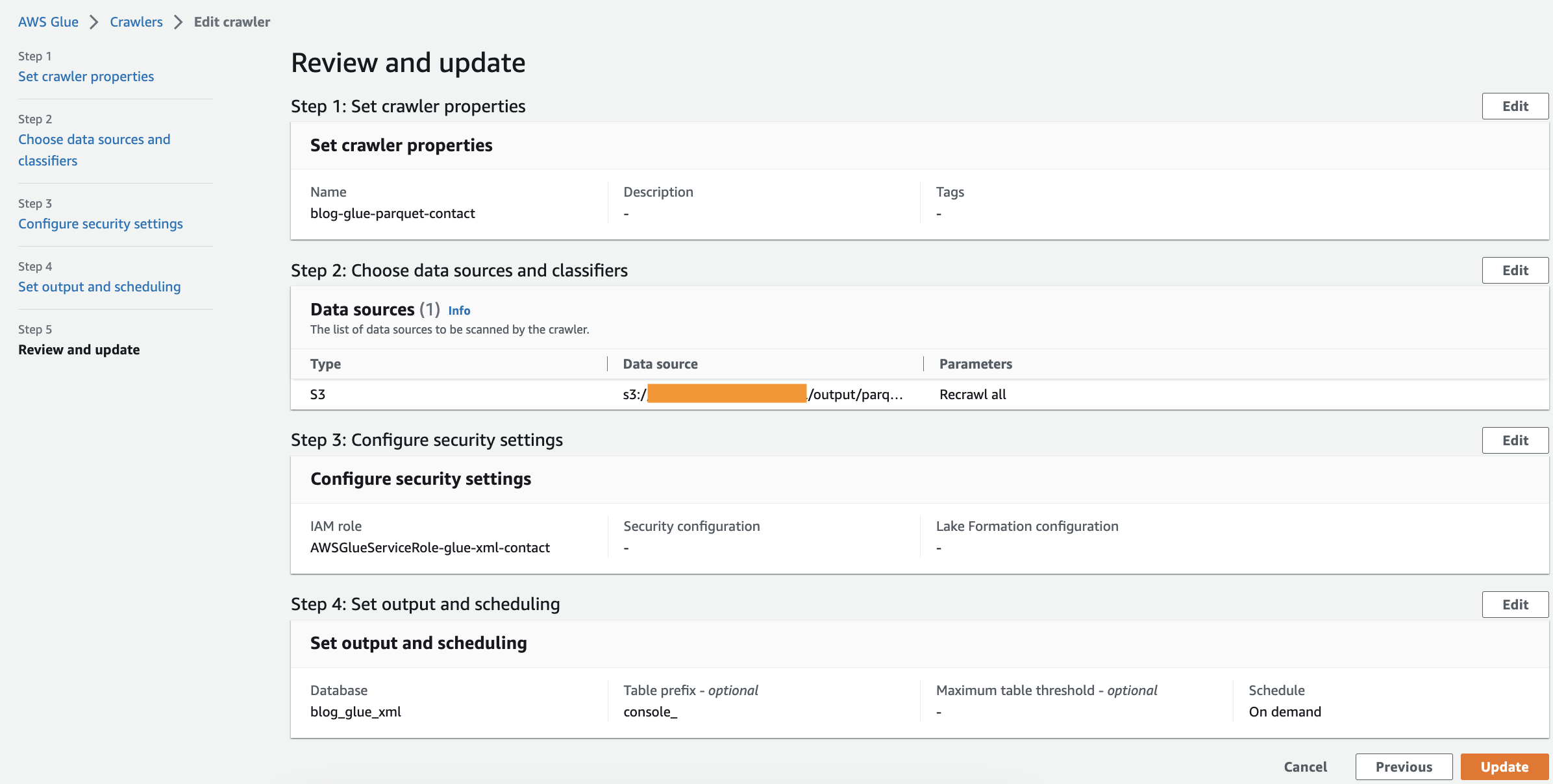
Esegui il crawler
Dopo aver creato il crawler, completa i seguenti passaggi per eseguirlo:
- Nella console AWS Glue, scegli Crawlers nel pannello di navigazione.
- Apri il crawler che hai creato e scegli Correre.
Il completamento del crawler richiederà 1-2 minuti.
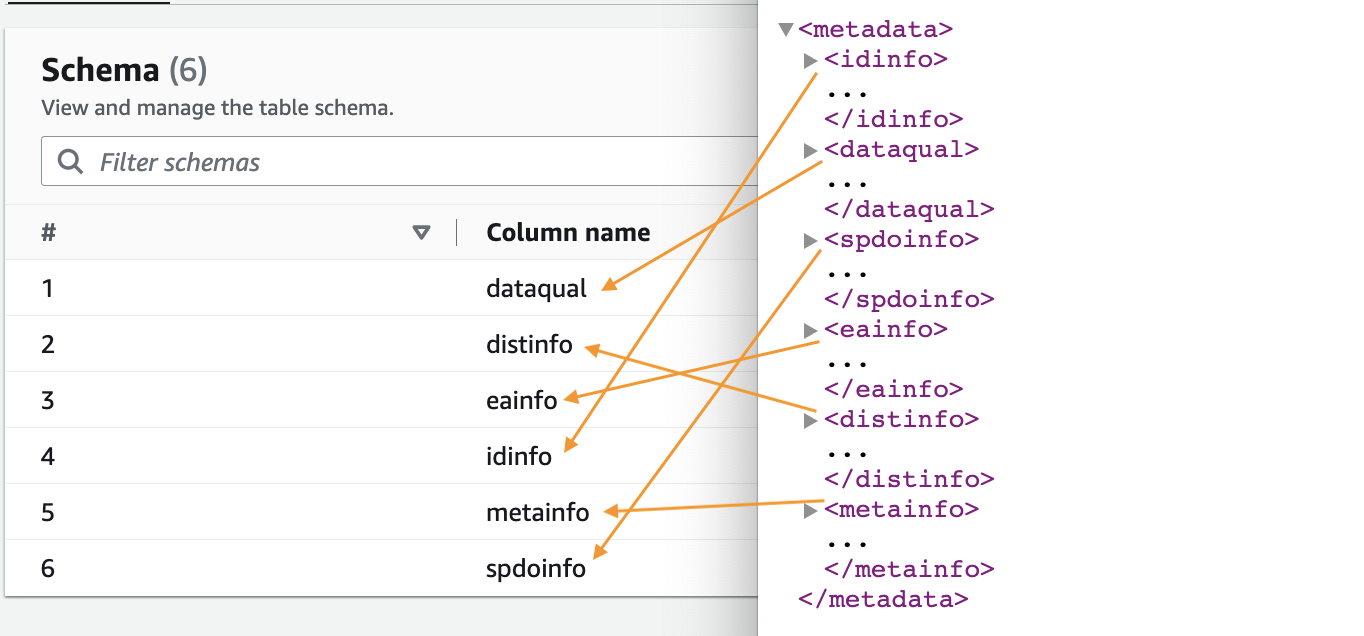
- Quando il crawler è completo, scegli Database nel pannello di navigazione.
- Scegli il database che hai creato e scegli il nome della tabella per vedere lo schema estratto dal crawler.
Crea un processo AWS Glue per convertire il formato XML in Parquet
In questa fase creerai un lavoro AWS Glue Studio per convertire il file XML in un file Parquet. Completa i seguenti passaggi:
- Nella console AWS Glue, scegli Offerte di lavoro nel pannello di navigazione.
- Sotto Crea lavoro, selezionare Visual con una tela bianca.
- Scegli Creare.
- Rinominare il lavoro in
blog_glue_xml_job.
Ora disponi di un editor di processi visivi AWS Glue Studio vuoto. Nella parte superiore dell'editor ci sono le schede per le diverse visualizzazioni.
- Scegliere il Copione scheda per visualizzare una shell vuota dello script ETL di AWS Glue.
Man mano che aggiungiamo nuovi passaggi nell'editor visivo, lo script verrà aggiornato automaticamente.
- Scegliere il Dettagli di lavoro scheda per vedere tutte le configurazioni del lavoro.
- Nel Ruolo IAMscegli
AWSGlueServiceNotebookRoleBlog. - Nel Versione a collascegli Colla 4.0 – Supporta Spark 3.3, Scala 2, Python 3.
- Impostato Numero di lavoratori richiesto a 2.
- Impostato Numero di tentativi a 0.
- Scegliere il Visivo scheda per tornare all'editor visivo.
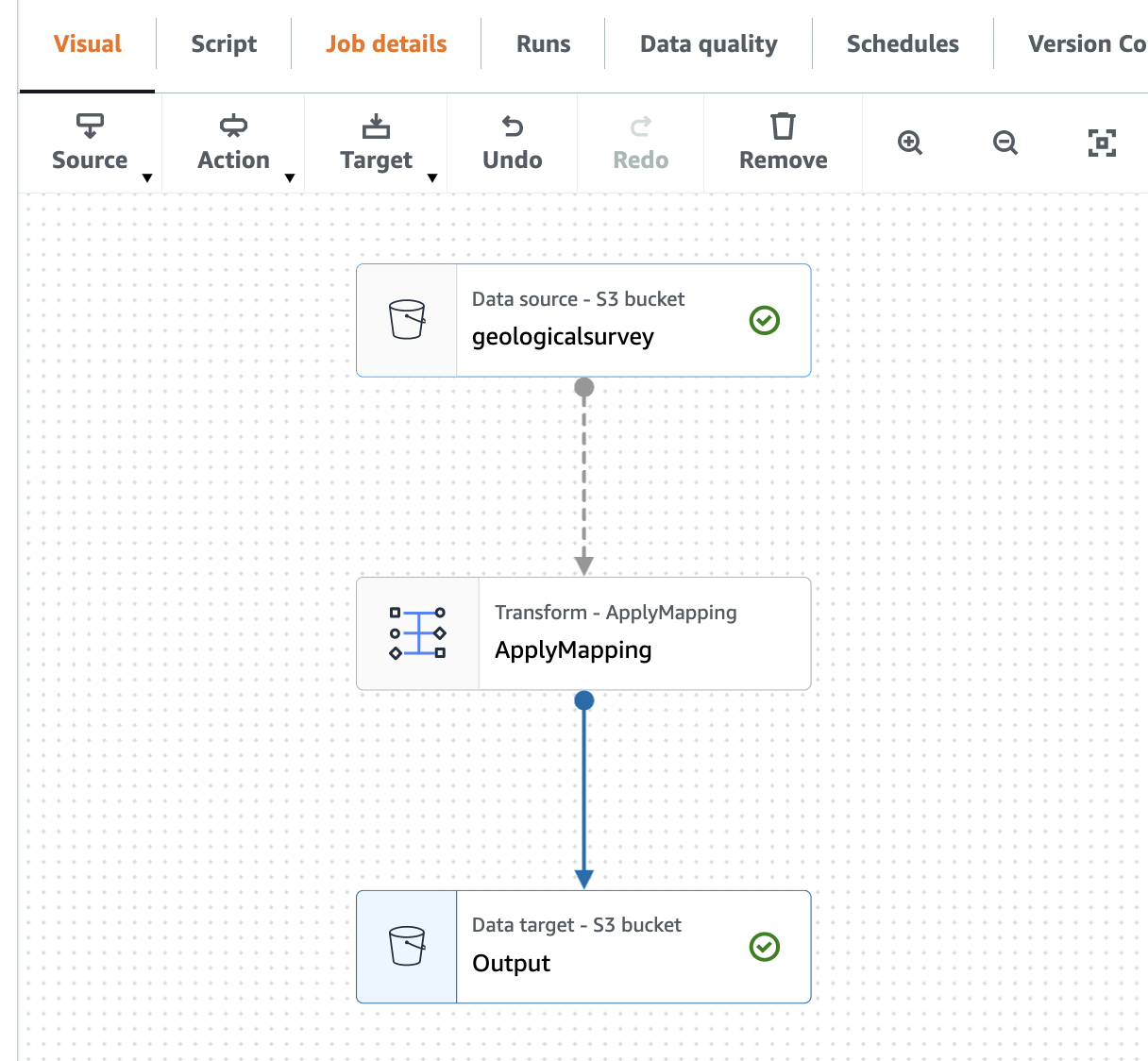
- Sulla Fonte menu a discesa, selezionare Catalogo dati di AWS Glue.
- Sulla Proprietà dell'origine dati: Catalogo dati scheda, fornire le seguenti informazioni:
- Nel Banca Datiscegli
blog_glue_xml. - Nel Table, scegli la tabella che inizia con il nome console_ creata dal crawler (ad esempio,
console_geologicalsurvey).
- Nel Banca Datiscegli
- Sulla Proprietà dei nodi scheda, fornire le seguenti informazioni:
- Cambiamento di Nome a
geologicalsurveyset di dati. - Scegli Action e la trasformazione Modifica schema (Applica mappatura).
- Scegli Proprietà dei nodi e modificare il nome della trasformazione da Modifica schema (Applica mappatura) a
ApplyMapping. - Sulla Target menù, scegliere S3.
- Cambiamento di Nome a
- Sulla Proprietà dell'origine dati - S3 scheda, fornire le seguenti informazioni:
- Nel Formato, selezionare Parquet.
- Nel Tipo di compressione, selezionare Non compresso.
- Nel Tipo di sorgente S3, selezionare Posizione S3.
- Nel URL S3, accedere
s3://${BUCKET_NAME}/output/parquet/. - Scegli Proprietà del nodo e cambia il nome in
Output.
- Scegli Risparmi per salvare il lavoro.
- Scegli Correre per eseguire il lavoro.
Lo screenshot seguente mostra il lavoro nell'editor visivo.
Crea un AWS Gue Crawler per eseguire la scansione del file Parquet
In questa fase creerai un crawler AWS Glue per estrarre i metadati dal file Parquet creato utilizzando un lavoro AWS Glue Studio. Questa volta utilizzi il classificatore predefinito. Completa i seguenti passaggi:
- Nella console AWS Glue, scegli Crawlers nel pannello di navigazione.
- Scegli Crea cingolato.
- Sulla Imposta le proprietà del crawler pagina, fornisci un nome per il nuovo crawler, ad esempio blog-colla-parquet-contatto, quindi scegli Avanti.
- Sulla Scegli origini dati e classificatori pagina, selezionare Non ancora per Configurazione dell'origine dati.
- Scegli Aggiungi un archivio dati.
- Nel Percorso S3, vai a
s3://${BUCKET_NAME}/output/parquet/.
Assicurati di scegliere il parquet cartella anziché il file all'interno della cartella.
- Scegli il tuo ruolo IAM creato durante la sezione dei prerequisiti oppure scegli Crea un nuovo ruolo IAM (per esempio,
AWSGlueServiceNotebookRoleBlog) e scegli Avanti. - Sulla Imposta output e pianificazione pagina, sotto Configurazione delle uscitescegli
blog_glue_xmlper Banca Dati. - entrare
parquet_come prefisso aggiunto alle tabelle (facoltativo) e sotto Programma del crawler, mantenere la frequenza impostata su Su richiesta. - Scegli Avanti.
- Rivedi tutti i parametri e scegli Crea cingolato.
Ora puoi eseguire il crawler, il cui completamento richiede 1-2 minuti.

Puoi visualizzare in anteprima lo schema appena creato per il file Parquet nel Catalogo dati di AWS Glue, che è simile allo schema del file XML.
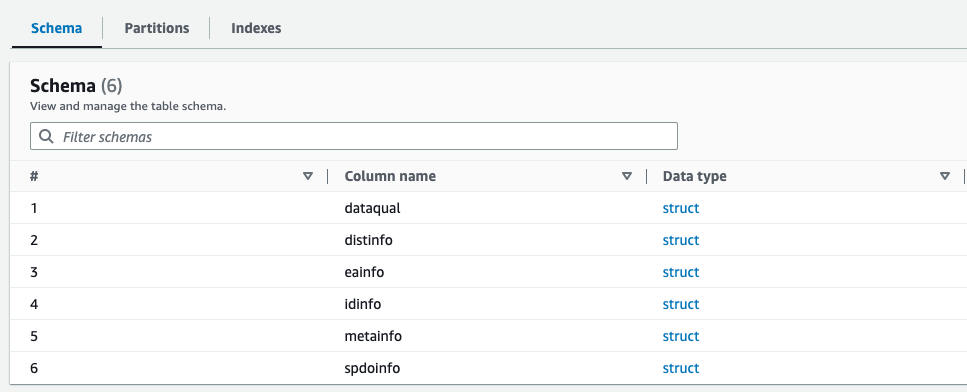
Ora possediamo dati adatti all'uso con Athena. Nella sezione successiva, eseguiamo query sui dati utilizzando Athena.
Interroga il file Parquet utilizzando Athena
Athena non supporta l'esecuzione di query sul file Formato file XML, motivo per cui hai convertito il file XML in Parquet per un'interrogazione e un utilizzo dei dati più efficienti notazione punto per interrogare tipi complessi e strutture nidificate.
Il seguente codice di esempio utilizza la notazione punto per eseguire query sui dati nidificati:
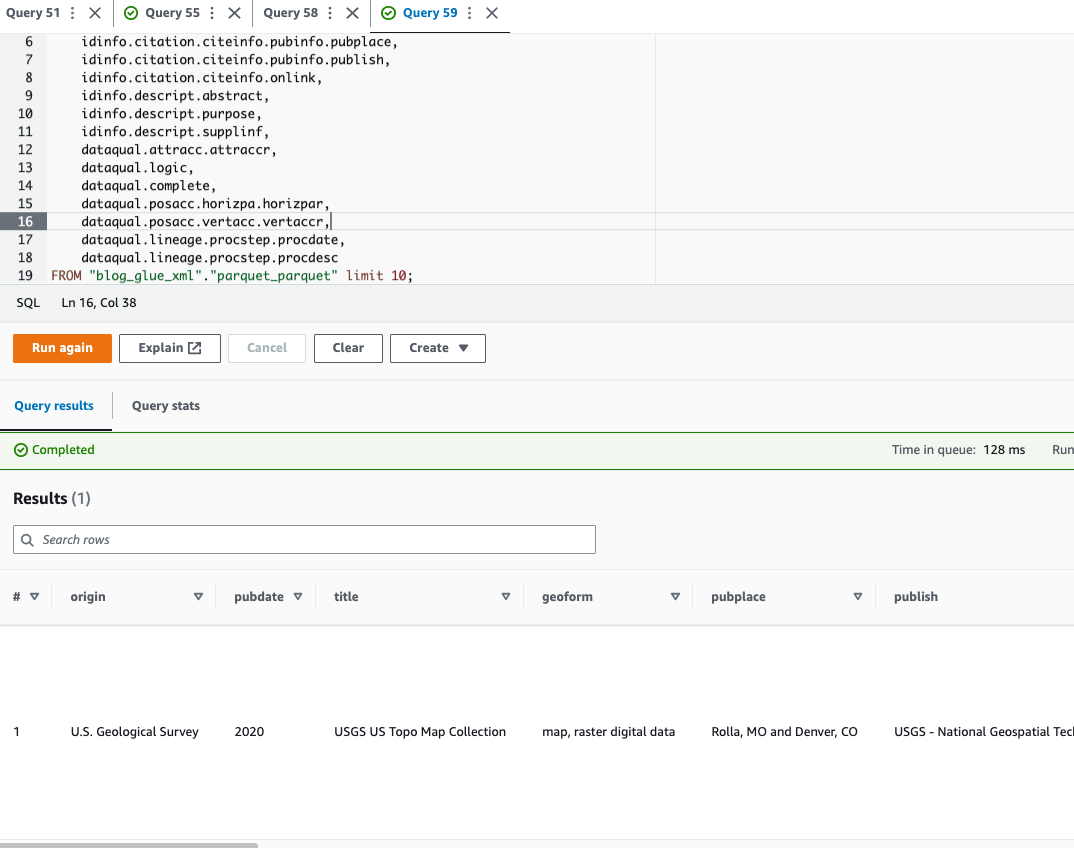
Ora che abbiamo completato la tecnica 1, passiamo alla tecnica 2.
Tecnica 2: utilizzare AWS Glue DynamicFrames con schemi dedotti e fissi
Nella sezione precedente, abbiamo trattato il processo di gestione di un piccolo file XML utilizzando un crawler AWS Glue per generare una tabella, un lavoro AWS Glue per convertire il file nel formato Parquet e Athena per accedere ai dati Parquet. Tuttavia, il crawler incontra limitazioni quando si tratta di elaborare file XML che superano i limiti 1 MB di dimensione. In questa sezione, approfondiamo il tema dell'elaborazione batch di file XML di grandi dimensioni, che richiedono un'ulteriore analisi per estrarre singoli eventi e condurre analisi utilizzando Athena.
Il nostro approccio prevede la lettura dei file XML tramite AWS Glue Cornici dinamiche, utilizzando sia schemi dedotti che fissi. Successivamente estraiamo i singoli eventi in formato Parquet utilizzando il file relazionalizzare trasformazione, consentendoci di interrogarli e analizzarli senza problemi utilizzando Athena.
Per implementare questa soluzione, completare i seguenti passaggi di alto livello:
- Crea un notebook AWS Glue per leggere e analizzare il file XML.
- Usa il
DynamicFramesconInferSchemaper leggere il file XML. - Utilizzare la funzione relazionalizza per annullare l'annidamento di eventuali array.
- Converti i dati nel formato Parquet.
- Interroga i dati del parquet utilizzando Athena.
- Ripeti i passaggi precedenti, ma questa volta passa uno schema a
DynamicFramesinvece di usareInferSchema.
Il file XML dei dati sulla popolazione dei veicoli elettrici ha un file response tag al suo livello di root. Questo tag contiene un array di row tag, che sono nidificati al suo interno. Il tag di riga è un array che contiene un insieme di altri tag di riga, che forniscono informazioni su un veicolo, inclusi marca, modello e altri dettagli rilevanti. La schermata seguente mostra un esempio.

Crea un notebook AWS Glue
Per creare un notebook AWS Glue, completa i seguenti passaggi:
- Aprire il AWS Colla Studio console, scegli Offerte di lavoro nel pannello di navigazione.
- Seleziona Notebook Jupyter e scegli Creare.
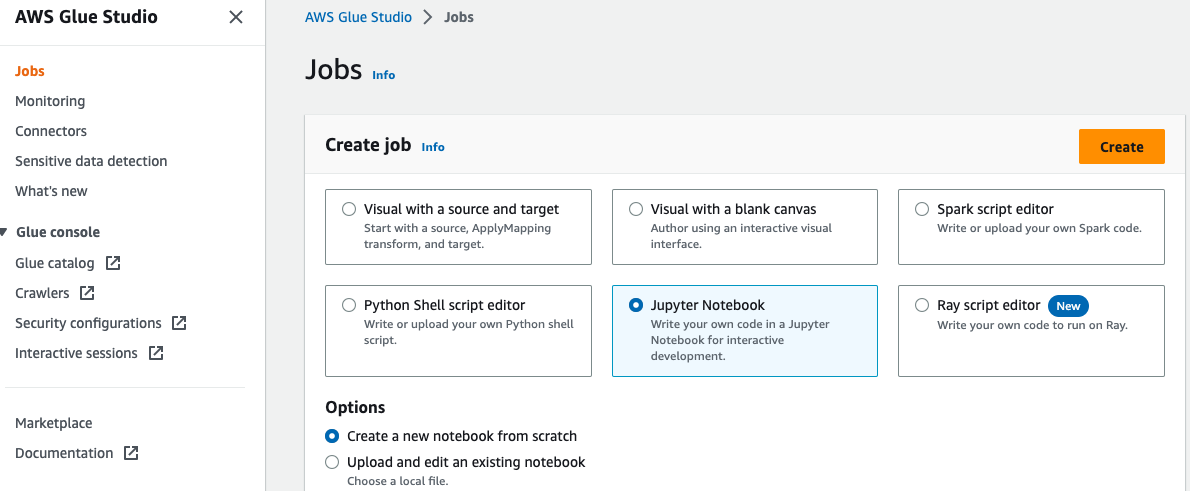
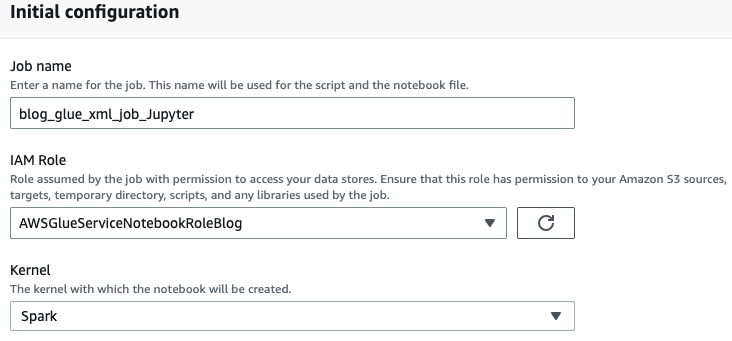
- Inserisci un nome per il tuo lavoro AWS Glue, ad esempio
blog_glue_xml_job_Jupyter. - Scegli il ruolo che hai creato nei prerequisiti (
AWSGlueServiceNotebookRoleBlog).
Il notebook AWS Glue viene fornito con un esempio preesistente che dimostra come eseguire query su un database e scrivere l'output su Amazon S3.
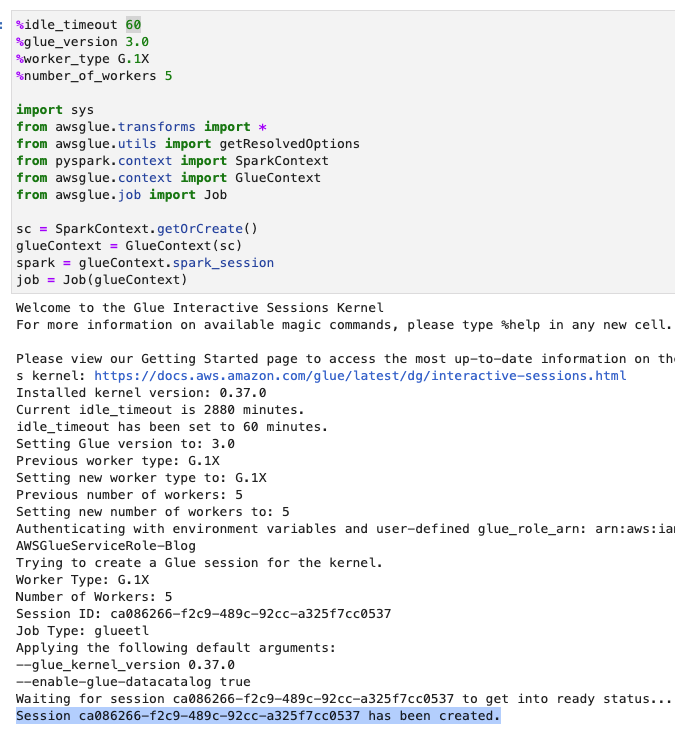
- Regola il timeout (in minuti) come mostrato nello screenshot seguente ed esegui la cella per creare la sessione interattiva AWS Glue.
Crea variabili di base
Dopo aver creato la sessione interattiva, alla fine del notebook, crea una nuova cella con le seguenti variabili (fornisci il nome del tuo bucket):
Leggere il file XML deducendo lo schema
Se non passi uno schema al file DynamicFrame, dedurrà lo schema dei file. Per leggere i dati utilizzando un frame dinamico, è possibile utilizzare il seguente comando:
Stampa lo schema DynamicFrame
Stampa lo schema con il seguente codice:
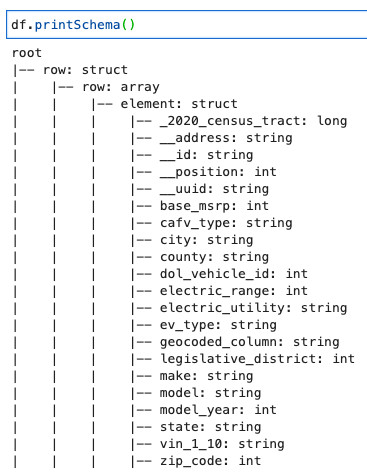
Lo schema mostra una struttura nidificata con a row array contenente più elementi. Per separare questa struttura in linee, puoi utilizzare AWS Glue relazionalizzare trasformazione:
A noi interessano solo le informazioni contenute all'interno dell'array di righe e possiamo visualizzare lo schema utilizzando il seguente comando:
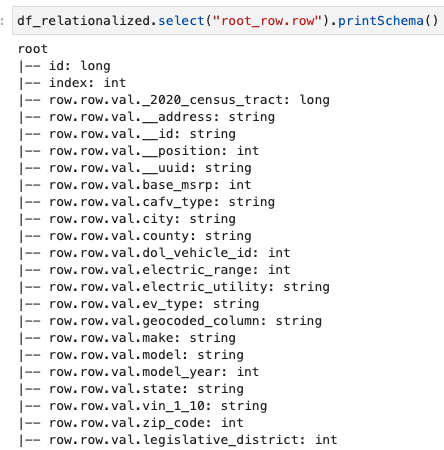
I nomi delle colonne contengono row.row, che corrispondono alla struttura dell'array e alla colonna dell'array nel set di dati. Non rinominiamo le colonne in questo post; per istruzioni su come farlo, fare riferimento a Automatizza la mappatura dinamica e la ridenominazione dei nomi delle colonne nei file di dati utilizzando AWS Glue: Parte 1. Quindi puoi convertire i dati nel formato Parquet e creare la tabella AWS Glue utilizzando il comando seguente:
Colla AWS DynamicFrame fornisce funzionalità che puoi utilizzare nello script ETL per creare e aggiornare uno schema nel Data Catalog. Noi usiamo il updateBehavior parametro per creare la tabella direttamente nel Data Catalog. Con questo approccio, non è necessario eseguire un crawler AWS Glue una volta completato il lavoro AWS Glue.

Leggere il file XML impostando uno schema
Un modo alternativo per leggere il file è predefinire uno schema. A tale scopo, completare i seguenti passaggi:
- Importa i tipi di dati AWS Glue:
- Crea uno schema per il file XML:
- Passa lo schema durante la lettura del file XML:
- Annulla l'annidamento del set di dati come prima:
- Converti il set di dati in Parquet e crea la tabella AWS Glue:
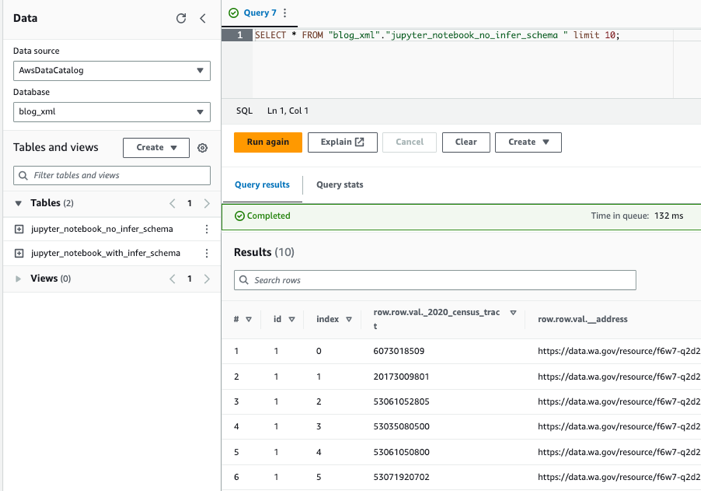
Interroga le tabelle utilizzando Athena
Ora che abbiamo creato entrambe le tabelle, possiamo interrogarle utilizzando Athena. Ad esempio, possiamo utilizzare la seguente query:
Ripulire
In questo post abbiamo creato un ruolo IAM, un notebook AWS Glue Jupyter e due tabelle nel Catalogo dati di AWS Glue. Abbiamo anche caricato alcuni file su un bucket S3. Per ripulire questi oggetti, completare i seguenti passaggi:
- Nella console IAM, elimina il ruolo che hai creato.
- Nella console AWS Glue Studio, elimina il classificatore personalizzato, il crawler, i processi ETL e il notebook Jupyter.
- Passa al Catalogo dati di AWS Glue ed elimina le tabelle create.
- Nella console Amazon S3, vai al bucket che hai creato ed elimina le cartelle denominate
temp,infer_schemaeno_infer_schema.
Punti chiave
In AWS Glue esiste una funzionalità chiamata InferSchema in AWS Glue DynamicFrames. Capisce automaticamente la struttura di un frame di dati in base ai dati in esso contenuti. Al contrario, definire uno schema significa dichiarare esplicitamente come dovrebbe essere la struttura del frame di dati prima di caricare i dati.
XML, essendo un formato basato su testo, non limita i tipi di dati delle sue colonne. Ciò può causare problemi con la funzione InferSchema. Ad esempio, nella prima esecuzione, un file con la colonna A avente un valore pari a 2 risulta in un file Parquet con la colonna A come numero intero. Nella seconda esecuzione, un nuovo file ha la colonna A con il valore C, che porta a un file Parquet con la colonna A come stringa. Ora ci sono due file su S3, ciascuno con una colonna A di tipi di dati diversi, il che può creare problemi a valle.
Lo stesso accade con tipi di dati complessi come strutture annidate o array. Ad esempio, se un file ha una voce di tag chiamata transaction, viene dedotto come una struttura. Ma se un altro file ha lo stesso tag, viene dedotto come un array
Nonostante questi problemi relativi al tipo di dati, InferSchema è utile quando non si conosce lo schema o definirne uno manualmente non è pratico. Tuttavia, non è l'ideale per set di dati di grandi dimensioni o in continua evoluzione. La definizione di uno schema è più precisa, soprattutto con tipi di dati complessi, ma presenta i suoi problemi, come la richiesta di intervento manuale e l'inflessibilità alle modifiche dei dati.
InferSchema presenta limitazioni, come l'inferenza errata del tipo di dati e problemi con la gestione dei valori null. La definizione di uno schema presenta anche dei limiti, come lo sforzo manuale e potenziali errori.
La scelta tra inferire e definire uno schema dipende dalle esigenze del progetto. InferSchema è ottimo per l'esplorazione rapida di set di dati di piccole dimensioni, mentre la definizione di uno schema è migliore per set di dati più grandi e complessi che richiedono precisione e coerenza. Considera i compromessi e i vincoli di ciascun metodo per scegliere quello che meglio si adatta al tuo progetto.
Conclusione
In questo post, abbiamo esplorato due tecniche per la gestione dei dati XML utilizzando AWS Glue, ciascuna su misura per soddisfare le esigenze e le sfide specifiche che potresti incontrare.
La Tecnica 1 offre un percorso user-friendly per coloro che preferiscono un'interfaccia grafica. Puoi utilizzare un crawler AWS Glue e l'editor visivo per definire facilmente la struttura della tabella per i tuoi file XML. Questo approccio semplifica il processo di gestione dei dati ed è particolarmente interessante per coloro che cercano un modo semplice per gestire i propri dati.
Tuttavia, riconosciamo che il crawler ha i suoi limiti, in particolare quando si tratta di file XML con righe più grandi di 1 MB. È qui che la tecnica 2 viene in soccorso. Sfruttando AWS Glue DynamicFrames con schemi sia dedotti che fissi e utilizzando un notebook AWS Glue, puoi gestire in modo efficiente file XML di qualsiasi dimensione. Questo metodo fornisce una soluzione affidabile che garantisce un'elaborazione fluida anche per i file XML con righe che superano il limite di 1 MB.
Mentre esplori il mondo della gestione dei dati, avere queste tecniche nel tuo kit di strumenti ti consente di prendere decisioni informate in base ai requisiti specifici del tuo progetto. Che tu preferisca la semplicità della tecnica 1 o la scalabilità della tecnica 2, AWS Glue offre la flessibilità necessaria per gestire i dati XML in modo efficace.
Informazioni sugli autori
 Navnit Shuklafunge da AWS Specialist Solution Architect con particolare attenzione all'analisi. Possiede un forte entusiasmo nell'aiutare i clienti a scoprire informazioni preziose dai loro dati. Attraverso la sua esperienza, costruisce soluzioni innovative che consentono alle aziende di arrivare a scelte informate e basate sui dati. In particolare, Navnit Shukla è l'autore esperto del libro intitolato "Data Wrangling on AWS.
Navnit Shuklafunge da AWS Specialist Solution Architect con particolare attenzione all'analisi. Possiede un forte entusiasmo nell'aiutare i clienti a scoprire informazioni preziose dai loro dati. Attraverso la sua esperienza, costruisce soluzioni innovative che consentono alle aziende di arrivare a scelte informate e basate sui dati. In particolare, Navnit Shukla è l'autore esperto del libro intitolato "Data Wrangling on AWS.
 Patrick Müller lavora come Senior Data Lab Architect presso AWS. La sua responsabilità principale è assistere i clienti nel trasformare le loro idee in un prodotto dati pronto per la produzione. Nel tempo libero, Patrick ama giocare a calcio, guardare film e viaggiare.
Patrick Müller lavora come Senior Data Lab Architect presso AWS. La sua responsabilità principale è assistere i clienti nel trasformare le loro idee in un prodotto dati pronto per la produzione. Nel tempo libero, Patrick ama giocare a calcio, guardare film e viaggiare.
 Tra Gaikwad è uno sviluppatore di soluzioni senior presso Amazon Web Services. Aiuta i clienti globali a creare e distribuire soluzioni AI/ML su AWS. Il suo lavoro si concentra principalmente sulla visione artificiale e sull'elaborazione del linguaggio naturale e sull'aiutare i clienti a ottimizzare i carichi di lavoro AI/ML per la sostenibilità. Amogh ha conseguito il master in Informatica specializzandosi in Machine Learning.
Tra Gaikwad è uno sviluppatore di soluzioni senior presso Amazon Web Services. Aiuta i clienti globali a creare e distribuire soluzioni AI/ML su AWS. Il suo lavoro si concentra principalmente sulla visione artificiale e sull'elaborazione del linguaggio naturale e sull'aiutare i clienti a ottimizzare i carichi di lavoro AI/ML per la sostenibilità. Amogh ha conseguito il master in Informatica specializzandosi in Machine Learning.
 Sheela Sonone è un architetto residente senior presso AWS. Aiuta i clienti AWS a fare scelte informate e a scendere a compromessi sull'accelerazione dei dati, delle analisi e dei carichi di lavoro e delle implementazioni di AI/ML. Nel tempo libero le piace trascorrere del tempo con la sua famiglia, di solito sui campi da tennis.
Sheela Sonone è un architetto residente senior presso AWS. Aiuta i clienti AWS a fare scelte informate e a scendere a compromessi sull'accelerazione dei dati, delle analisi e dei carichi di lavoro e delle implementazioni di AI/ML. Nel tempo libero le piace trascorrere del tempo con la sua famiglia, di solito sui campi da tennis.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- WRI
- ABSTRACT
- accelerando
- accesso
- accessibilità
- compiuto
- precisione
- operanti in
- Action
- aggiungere
- aggiunto
- aggiuntivo
- indirizzo
- Dopo shavasana, sedersi in silenzio; saluti;
- AI / ML
- Tutti
- consentire
- Consentire
- consente
- anche
- alternativa
- Amazon
- Amazzone Atena
- Amazon Web Services
- an
- .
- analitica
- analizzare
- l'analisi
- ed
- Un altro
- in qualsiasi
- Apache
- attraente
- applicazioni
- APPLICA
- approccio
- approcci
- architettura
- SONO
- Italia
- AS
- assistere
- assistere
- At
- autore
- automaticamente
- disponibile
- AWS
- Colla AWS
- precedente
- basato
- basic
- BE
- perché
- prima
- iniziare
- essendo
- MIGLIORE
- Meglio
- fra
- vuoto
- libro
- entrambi
- costruire
- aziende
- ma
- by
- detto
- Materiale
- catalogo
- Causare
- cella
- sfide
- il cambiamento
- Modifiche
- cambiando
- scelte
- Scegli
- Città
- classificazione
- clienti
- codice
- Colonna
- colonne
- COM
- viene
- Uncommon
- comunemente
- completamento di una
- Completato
- complesso
- computer
- Informatica
- Visione computerizzata
- condizione
- Segui il codice di Condotta
- congiunzione
- Prendere in considerazione
- consolle
- costantemente
- vincoli
- costruire
- contenere
- contenute
- contiene
- contrasto
- di controllo
- convertire
- convertito
- costo effettivo
- soluzione conveniente
- contea
- Corti
- coperto
- crawler
- creare
- creato
- Creazione
- cruciale
- costume
- cliente
- Clienti
- dati
- integrazione dei dati
- gestione dei dati
- data-driven
- Banca Dati
- dataset
- trattare
- decisioni
- Predefinito
- definire
- definizione
- scavare
- dimostra
- dipende
- schierare
- progettato
- dettagliati
- dettagli
- Costruttori
- diverso
- difficile
- digitale
- era digitale
- direttamente
- scoprire
- distinto
- do
- non
- fatto
- Dont
- DOT
- durante
- dinamico
- ogni
- alleviare
- facilmente
- facile
- editore
- effetto
- in maniera efficace
- efficienza
- efficiente
- in modo efficiente
- sforzo
- senza sforzo
- Elettrico
- veicolo elettrico
- elementi
- impiegando
- e potenza
- Potenzia
- vuoto
- enable
- consentendo
- incontrare
- fine
- Motori
- accrescere
- garantire
- assicura
- entrare
- entusiasmo
- iscrizione
- errori
- particolarmente
- Etere (ETH)
- Anche
- eventi
- Ogni
- esempio
- superare
- scambio
- competenza
- esplorazione
- esplora
- Esplorazione
- estratto
- estrazione
- famiglia
- caratteristica
- Caratteristiche
- Cifre
- Compila il
- File
- finanziare
- Nome
- fisso
- Flessibilità
- Focus
- concentrato
- i seguenti
- Nel
- formato
- TELAIO
- Gratis
- Frequenza
- da
- function
- Guadagno
- scopo generale
- generare
- globali
- Go
- scopo
- Enti Pubblici
- grande
- maniglia
- Manovrabilità
- accade
- Sfruttamento
- Avere
- avendo
- he
- assistenza sanitaria
- Cuore
- Aiuto
- aiutare
- aiuta
- suo
- alto livello
- vivamente
- il suo
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- IAM
- ideale
- idee
- Identità
- if
- illustra
- realizzare
- implementazioni
- Implementazione
- importare
- competenze
- migliorata
- in
- Compreso
- individuale
- individui
- industrie
- informazioni
- informati
- Infrastruttura
- creativi e originali
- interno
- intuizioni
- invece
- istruzioni
- integrare
- integrazione
- interattivo
- interessato
- Interfaccia
- ai miglioramenti
- comporta
- sicurezza
- IT
- SUO
- Lavoro
- Offerte di lavoro
- jpg
- json
- Notebook Jupyter
- mantenere
- Sapere
- laboratorio
- Lingua
- grandi
- superiore, se assunto singolarmente.
- principale
- IMPARARE
- apprendimento
- Livello
- piace
- LIMITE
- limitazione
- limiti
- linea
- Linee
- caricare
- Caricamento in corso
- logica
- cerca
- macchina
- machine learning
- Principale
- principalmente
- make
- Fare
- gestione
- gestione
- Manuale
- manualmente
- molti
- mappatura
- master
- Maggio..
- si intende
- Menu
- Metadati
- metodo
- verbale
- modello
- Scopri di più
- più efficiente
- maggior parte
- cambiano
- Film
- multiplo
- Nome
- Detto
- nomi
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- Navigare
- Navigazione
- necessaria
- Bisogno
- esigenze
- New
- recentemente
- GENERAZIONE
- segnatamente
- taccuino
- adesso
- numero
- oggetti
- of
- Offerte
- on
- ONE
- esclusivamente
- Operazioni
- ottimale
- OTTIMIZZA
- Ottimizza
- Opzioni
- or
- minimo
- organizzazioni
- Origin
- Altro
- nostro
- su
- produzione
- ancora
- Superare
- proprio
- pagina
- vetro
- parametro
- parametri
- parte
- particolarmente
- passare
- sentiero
- patrick
- eseguire
- performance
- permessi
- scegliere
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- politica
- popolazione
- possedere
- Post
- potenziale
- bisogno
- preferire
- prerequisiti
- Anteprima
- precedente
- problemi
- processi
- elaborati
- lavorazione
- Prodotto
- progetto
- progetti
- proprietà
- fornire
- fornisce
- pubblicare
- scopo
- Python
- query
- Presto
- piuttosto
- Leggi
- prontamente
- Lettura
- motivi
- ricevuto
- riconoscere
- riferimento
- pertinente
- Requisiti
- salvataggio
- risorsa
- risposta
- responsabilità
- REST
- limitare
- restrizione
- Risultati
- robusto
- Ruolo
- radice
- RIGA
- Correre
- stesso
- Risparmi
- Scala
- Scalabilità
- scalabile
- Scienze
- copione
- senza soluzione di continuità
- senza soluzione di continuità
- Secondo
- Sezione
- vedere
- anziano
- Servizi
- Sessione
- set
- regolazione
- alcuni
- lei
- Conchiglia
- dovrebbero
- mostrare attraverso le sue creazioni
- mostrato
- Spettacoli
- simile
- Un'espansione
- semplicità
- semplificando
- singolo
- Taglia
- piccole
- So
- Calcio
- soluzione
- Soluzioni
- alcuni
- Fonte
- fonti
- Scintilla
- specialista
- specializzata
- specifico
- in particolare
- velocità
- Spendere
- SQL
- Standard
- inizio
- Regione / Stato
- dichiarazione
- affermando
- step
- Passi
- conservazione
- memorizzati
- lineare
- snellire
- Corda
- forte
- La struttura
- strutture
- studio
- il successo
- tale
- adatto
- supporto
- sicuro
- Sostenibilità
- SISTEMI DI TRATTAMENTO
- tavolo
- TAG
- su misura
- Fai
- prende
- task
- tecniche
- tennis
- di
- che
- Il
- le informazioni
- il mondo
- loro
- Li
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- quelli
- Attraverso
- tempo
- Titolo
- titolato
- a
- di oggi
- toolkit
- top
- argomento
- Trasformare
- Trasformazione
- Di viaggio
- Svolta
- lezione
- seconda
- Digitare
- Tipi di
- ultimo
- per
- Aggiornanento
- aggiornato
- caricato
- us
- usabilità
- uso
- utilizzato
- Utente
- Interfaccia utente
- user-friendly
- usa
- utilizzando
- generalmente
- Utilizzando
- Prezioso
- APPREZZIAMO
- Valori
- veicolo
- versione
- via
- Visualizza
- visualizzazioni
- visione
- guardare
- Modo..
- we
- sito web
- servizi web
- Che
- quando
- mentre
- se
- quale
- OMS
- perché
- volere
- con
- entro
- senza
- Lavora
- flusso di lavoro
- flussi di lavoro
- lavori
- mondo
- scrivere
- XML
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro