Amazon RedShift è un data warehouse veloce, completamente gestito, su scala petabyte che offre la flessibilità necessaria per utilizzare l'elaborazione con provisioning o senza server per i carichi di lavoro analitici. Usando Amazon Redshift senza server ed Editor di query v2, puoi caricare e interrogare set di dati di grandi dimensioni in pochi clic e pagare solo per ciò che utilizzi. L'architettura di calcolo e storage disaccoppiata di Amazon Redshift ti consente di creare carichi di lavoro altamente scalabili, resilienti e convenienti. Molti clienti migrano i loro carichi di lavoro di data warehousing su Amazon Redshift e beneficiano delle ricche funzionalità che offre. Le seguenti sono solo alcune delle notevoli capacità:
- Amazon Redshift si integra perfettamente con più ampio servizi di analisi su AWS. Ciò consente di scegliere lo strumento giusto per il lavoro giusto. L'analisi moderna è molto più ampia del data warehousing basato su SQL. Amazon Redshift ti consente di creare architetture delle case sul lago e quindi eseguire qualsiasi tipo di analisi, ad esempio analisi interattiva, analisi operativa, elaborazione dati di grandi dimensioni, preparazione dei dati visivi, analisi predittiva, apprendimento automatico (ML) e altro ancora.
- Non devi preoccuparti che i carichi di lavoro, come ETL, dashboard, query ad hoc e così via, interferiscano tra loro. Puoi isolare i carichi di lavoro utilizzando la condivisione dei dati, mentre si utilizzano gli stessi set di dati sottostanti.
- Quando gli utenti eseguono molte query nelle ore di punta, l'elaborazione si ridimensiona senza soluzione di continuità in pochi secondi per fornire prestazioni coerenti con un'elevata simultaneità. Ottieni un'ora di capacità di scalabilità simultanea gratuita per 24 ore di utilizzo. Questo credito gratuito soddisfa la domanda di concorrenza del 97% della base clienti di Amazon Redshift.
- Amazon Redshift è facile da usare autoregolazione e autoottimizzazione capacità. Puoi ottenere informazioni più rapide senza spendere tempo prezioso nella gestione del tuo data warehouse.
- Fault Tolerance è integrato. Tutti i dati scritti su Amazon Redshift vengono replicati automaticamente e continuamente Servizio di archiviazione semplice Amazon (Amazon S3). Eventuali guasti hardware vengono sostituiti automaticamente.
- Amazon Redshift lo è semplice da interagire con. Puoi accedere ai dati con applicazioni basate su servizi Web tradizionali, native del cloud, containerizzate e serverless o basate su eventi e così via.
- Spostamento verso il rosso ML rende facile per i data scientist creare, addestrare e distribuire modelli ML utilizzando SQL familiare. Possono anche eseguire previsioni utilizzando SQL.
- Amazon Redshift fornisce completa sicurezza dei dati senza costi aggiuntivi. È possibile configurare la crittografia dei dati end-to-end, configurare le regole del firewall, definire controlli di sicurezza granulari a livello di riga e colonna sui dati sensibili e così via.
- Amazon RedShift si integra perfettamente con altri servizi AWS e strumenti di terze parti. Puoi spostare, trasformare, caricare ed eseguire query su set di dati di grandi dimensioni in modo rapido e affidabile.
In questo post, forniamo una procedura dettagliata per la migrazione di un data warehouse da Google BigQuery ad Amazon Redshift utilizzando Strumento di conversione dello schema AWS (AWS SCT) ed Agenti di estrazione dati AWS SCT. AWS SCT è un servizio che rende prevedibili le migrazioni di database eterogenei convertendo automaticamente la maggior parte del codice del database e degli oggetti di archiviazione in un formato compatibile con il database di destinazione. Tutti gli oggetti che non possono essere convertiti automaticamente sono chiaramente contrassegnati in modo che possano essere convertiti manualmente per completare la migrazione. Inoltre, AWS SCT può eseguire la scansione del codice dell'applicazione alla ricerca di istruzioni SQL incorporate e convertirle.
Panoramica della soluzione
AWS SCT utilizza un account di servizio per connettersi al tuo progetto BigQuery. Innanzitutto, creiamo un database Amazon Redshift in cui vengono migrati i dati di BigQuery. Successivamente, creiamo un bucket S3. Quindi, utilizziamo AWS SCT per convertire gli schemi BigQuery e applicarli ad Amazon Redshift. Infine, per migrare i dati, utilizziamo gli agenti di estrazione dei dati AWS SCT, che estraggono i dati da BigQuery, li caricano nel bucket S3 e quindi li copiano in Amazon Redshift.

Prerequisiti
Prima di iniziare questa procedura dettagliata, è necessario disporre dei seguenti prerequisiti:
- Una workstation con AWS SCT, Amazon Corretto 11e driver Amazon Redshift.
- È possibile utilizzare un Amazon Elastic Compute Cloud (Amazon EC2) o il desktop locale come workstation. In questa procedura dettagliata, stiamo usando Istanza Amazon EC2 Windows. Per crearlo, usa questa guida.
- Per scaricare e installare AWS SCT sull'istanza EC2 creata in precedenza, utilizza questa guida.
- Scarica il driver JDBC di Amazon Redshift da questa posizione.
- Scarica e installa Amazon Corretto 11.
- Un account di servizio GCP che AWS SCT può utilizzare per connettersi al progetto BigQuery di origine.
- Grant Amministratore BigQuery ed Amministratore archiviazione ruoli all'account di servizio.
- Copia il file della chiave dell'account di servizio, che è stato creato nella console di gestione del cloud di Google, nell'istanza EC2 con AWS SCT.
- Crea un bucket Cloud Storage in GCP per archiviare i dati di origine durante la migrazione.
Questa procedura dettagliata copre i passaggi seguenti:
- Crea un gruppo di lavoro e uno spazio dei nomi Amazon Redshift Serverless
- Crea il bucket e la cartella AWS S3
- Converti e applica lo schema BigQuery ad Amazon Redshift utilizzando AWS SCT
- Connessione a Google BigQuery Source
- Connettiti all'obiettivo Amazon Redshift
- Converti lo schema BigQuery in un Amazon Redshift
- Analizzare il rapporto di valutazione e affrontare gli elementi di azione
- Applica lo schema convertito per indirizzare Amazon Redshift
- Migra i dati utilizzando gli agenti di estrazione dei dati AWS SCT
- Generazione di archivi di fiducia e chiavi (facoltativo)
- Installa e avvia l'agente di estrazione dati
- Registra l'agente di estrazione dei dati
- Aggiungi partizioni virtuali per tabelle di grandi dimensioni (facoltativo)
- Crea un'attività di migrazione locale
- Avviare l'attività di migrazione dei dati locali
- Visualizza i dati in Amazon Redshift
Crea un gruppo di lavoro e uno spazio dei nomi Amazon Redshift Serverless
In questa fase creiamo un gruppo di lavoro e uno spazio dei nomi Amazon Redshift Serverless. Il gruppo di lavoro è una raccolta di risorse di calcolo e lo spazio dei nomi è una raccolta di oggetti e utenti del database. Per isolare i carichi di lavoro e gestire diverse risorse in Amazon Redshift Serverless, puoi creare spazi dei nomi e gruppi di lavoro e gestire le risorse di storage e di calcolo separatamente.
Segui questi passaggi per creare un gruppo di lavoro e uno spazio dei nomi Amazon Redshift Serverless:
- Passare alla Console Amazon Redshift.
- In alto a destra, scegli la regione AWS che desideri utilizzare.
- Espandi il riquadro Amazon Redshift a sinistra e scegli Redshift senza server.
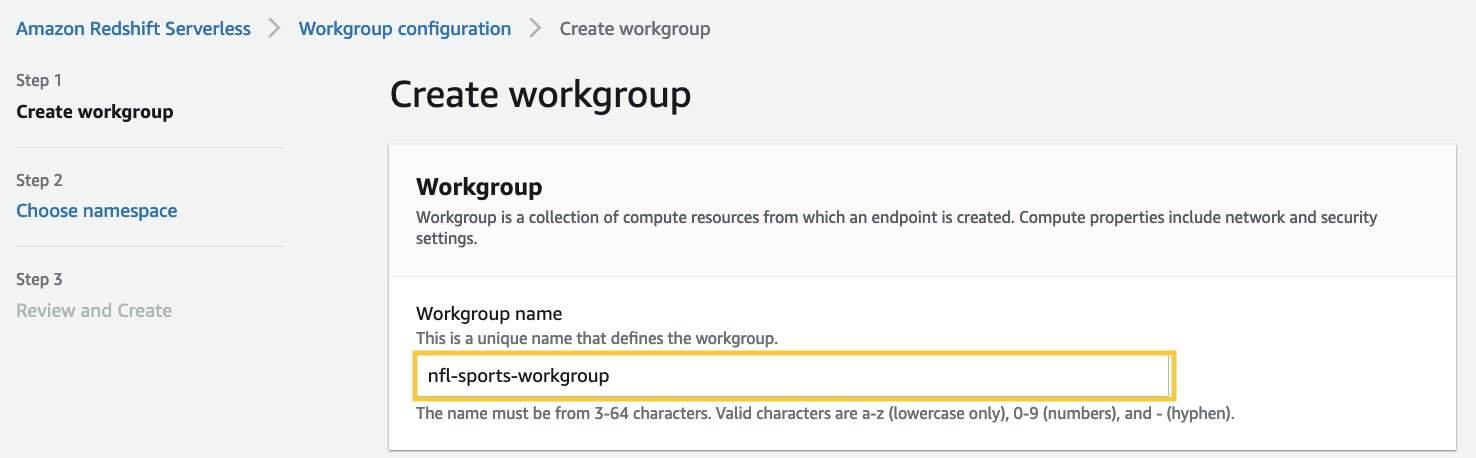
- Scegli Crea gruppo di lavoro.
- Nel Nome del gruppo di lavoro, immettere un nome che descriva le risorse di calcolo.
- Verifica che il VPC sia uguale al VPC dell'istanza EC2 con AWS SCT.
- Scegli Avanti.
- Nel Nome dello spazio dei nomi, inserisci un nome che descriva il tuo set di dati.
- In Nome e password del database selezionare la casella di controllo Personalizza le credenziali dell'utente amministratore.
- Nel Nome utente amministratore, inserisci un nome utente a tua scelta, ad esempio awsuser.
- Nel Password utente amministratore: inserisci una password a tua scelta, ad esempio MyRedShiftPW2022.
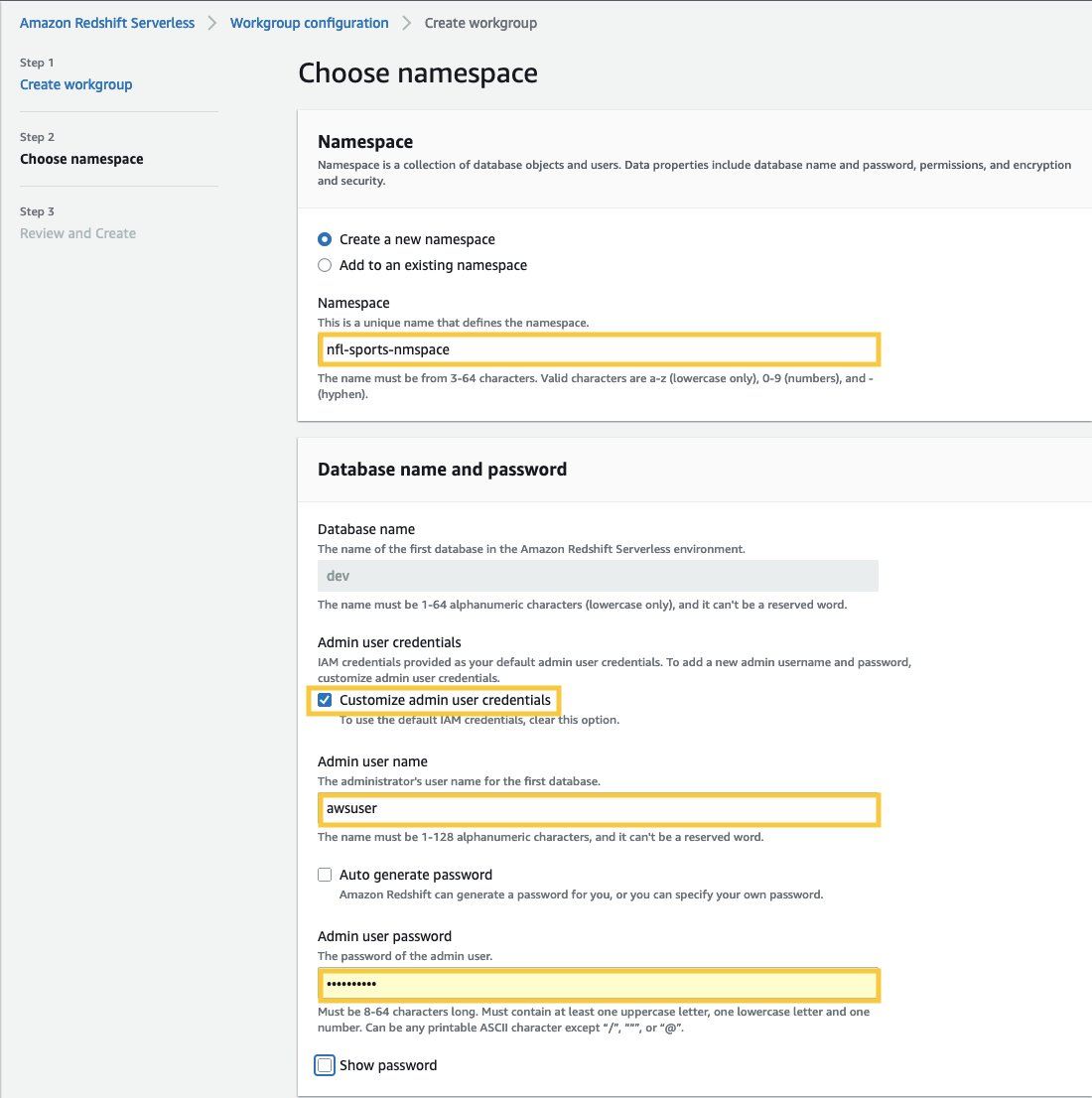
- Scegli Avanti. Tieni presente che i dati nello spazio dei nomi Amazon Redshift Serverless sono crittografati per impostazione predefinita.
- Nel Rivedi e crea pagina, scegli Creare.
- Creare un AWS Identity and Access Management (IAM) e impostalo come predefinito nel tuo spazio dei nomi, come descritto di seguito. Tieni presente che può esistere un solo ruolo IAM predefinito.
- Passare alla Dashboard serverless di Amazon Redshift.
- Sotto Spazi dei nomi/gruppi di lavoro, scegli lo spazio dei nomi appena creato.
- SpostarsiSicurezza e crittografia.
- Sotto Permessiscegli Gestire i ruoli IAM.
- Spostarsi Gestire i ruoli IAM. Quindi, scegli Gestire i ruoli IAM menu a discesa e scegliere Crea ruolo IAM.
- Sotto Specifica un bucket Amazon S3 per il ruolo IAM a cui accedere, scegli uno dei seguenti metodi:
- Scegli Nessun bucket Amazon S3 aggiuntivo per consentire al ruolo IAM creato di accedere solo ai bucket S3 con un nome che inizia con redshift.
- Scegli Qualsiasi bucket Amazon S3 per consentire al ruolo IAM creato di accedere a tutti i bucket S3.
- Scegli Bucket Amazon S3 specifici per specificare uno o più bucket S3 a cui accedere per il ruolo IAM creato. Quindi scegli uno o più bucket S3 dalla tabella.
- Scegli Crea ruolo IAM come predefinito. Amazon Redshift crea e imposta automaticamente il ruolo IAM come predefinito.
- Acquisisci l'endpoint per il gruppo di lavoro Amazon Redshift Serverless che hai appena creato.
Crea il bucket e la cartella S3
Durante il processo di migrazione dei dati, AWS SCT utilizza Amazon S3 come area di staging per i dati estratti. Segui questi passaggi per creare il bucket S3:
- Passare alla Console Amazon S3
- Scegli Crea un secchio. Crea un secchio si apre la procedura guidata.
- Nel Nome del secchio, inserisci un nome univoco conforme al DNS per il tuo bucket (ad es. nome-univoco-bq-rs). Consulta le regole per la denominazione dei bucket quando si sceglie un nome.
- Per Regione AWS, scegli la regione in cui hai creato il gruppo di lavoro Amazon Redshift Serverless.
- Seleziona Crea secchio.
- Nel Console Amazon S3, passa al bucket S3 che hai appena creato (ad es. nome-univoco-bq-rs).
- Scegli "Creare una cartella" per creare una nuova cartella.
- Nel Nome della cartella, entrare in arrivo e scegli Creare una cartella.
Converti e applica lo schema BigQuery ad Amazon Redshift utilizzando AWS SCT
Per convertire lo schema BigQuery nel formato Amazon Redshift, utilizziamo AWS SCT. Inizia accedendo all'istanza EC2 che abbiamo creato in precedenza, quindi avvia AWS SCT.
Segui questi passaggi utilizzando AWS SCT:
Connettiti all'origine BigQuery
- Dal Menu File scegliere Crea un nuovo progetto.
- Scegli una posizione in cui archiviare i file e i dati del progetto.
- Fornisci un nome significativo ma memorabile per il tuo progetto, ad esempio BigQuery ad Amazon Redshift.
- Per connetterti al data warehouse di origine BigQuery, scegli Aggiungere fonte dal menu principale.
- Scegli BigQuery e scegli Avanti. Il Aggiungere fonte appare la finestra di dialogo.
- Nel Nome della connessione, inserisci un nome per descrivere la connessione BigQuery. AWS SCT visualizza questo nome nella struttura ad albero nel pannello di sinistra.
- Nel Percorso chiave, fornire il percorso del file della chiave dell'account di servizio creato in precedenza nella console di gestione di Google Cloud.
- Scegli Test di connessione per verificare che AWS SCT possa connettersi al tuo progetto BigQuery di origine.
- Una volta che la connessione è stata convalidata correttamente, scegli Connettiti.

Connettiti all'obiettivo Amazon Redshift
Segui questi passaggi per connetterti ad Amazon Redshift:
- In AWS SCT, scegli Aggiungi obiettivo dal menu principale.
- Scegli Amazon RedShift, Quindi scegliere Avanti. Il Aggiungi obiettivo appare la finestra di dialogo.
- Nel Nome della connessione, inserisci un nome per descrivere la connessione Amazon Redshift. AWS SCT visualizza questo nome nella struttura ad albero nel pannello di destra.
- Nel Nome del server, inserisci l'endpoint del gruppo di lavoro Amazon Redshift Serverless acquisito in precedenza.
- Nel Porta del server, entrare 5439.
- Nel Database, entrare dev.
- Nel Nome utente, immetti il nome utente scelto durante la creazione del gruppo di lavoro Amazon Redshift Serverless.
- Nel Password, immetti la password scelta durante la creazione del gruppo di lavoro Amazon Redshift Serverless.
- Deseleziona la casella "Usa AWS Glue".
- Scegli Test di connessione per verificare che AWS SCT possa connettersi al tuo gruppo di lavoro Amazon Redshift di destinazione.
- Scegli Connettiti per connettersi alla destinazione Amazon Redshift.
Si noti che in alternativa è possibile utilizzare i valori di connessione archiviati in Gestore dei segreti di AWS.

Converti lo schema BigQuery in un Amazon Redshift
Dopo che le connessioni di origine e destinazione sono state effettuate correttamente, vedrai l'albero degli oggetti BigQuery di origine nel riquadro a sinistra e l'albero degli oggetti Amazon Redshift di destinazione nel riquadro a destra.
Segui questi passaggi per convertire lo schema BigQuery nel formato Amazon Redshift:
- Nel riquadro di sinistra, fai clic con il pulsante destro del mouse sullo schema che desideri convertire.
- Scegli Converti schema.
- Viene visualizzata una finestra di dialogo con una domanda, Gli oggetti potrebbero già esistere nel database di destinazione. Sostituire?. Scegli Sì.
Una volta completata la conversione, vedrai un nuovo schema creato nel riquadro Amazon Redshift (riquadro a destra) con lo stesso nome del tuo schema BigQuery.

Lo schema di esempio che abbiamo usato ha 16 tabelle, 3 viste e 3 procedure. Puoi visualizzare questi oggetti nel formato Amazon Redshift nel riquadro a destra. AWS SCT converte tutto il codice BigQuery e gli oggetti dati nel formato Amazon Redshift. Inoltre, puoi utilizzare AWS SCT per convertire script SQL esterni, codice dell'applicazione o file aggiuntivi con SQL incorporato.
Analizzare il rapporto di valutazione e affrontare gli elementi di azione
AWS SCT crea un rapporto di valutazione per valutare la complessità della migrazione. AWS SCT può convertire la maggior parte del codice e degli oggetti di database. Tuttavia, alcuni degli oggetti potrebbero richiedere la conversione manuale. AWS SCT evidenzia questi oggetti in blu nel diagramma delle statistiche di conversione e crea elementi di azione a cui è associata una complessità.
Per visualizzare il rapporto di valutazione, passare da Vista principale Vai all’email Visualizzazione Rapporto di valutazione come segue:
Il Sommario La scheda mostra gli oggetti che sono stati convertiti automaticamente e gli oggetti che non sono stati convertiti automaticamente. Il verde rappresenta convertito automaticamente o con elementi di azione semplici. Il blu rappresenta elementi di azione medi e complessi che richiedono un intervento manuale.
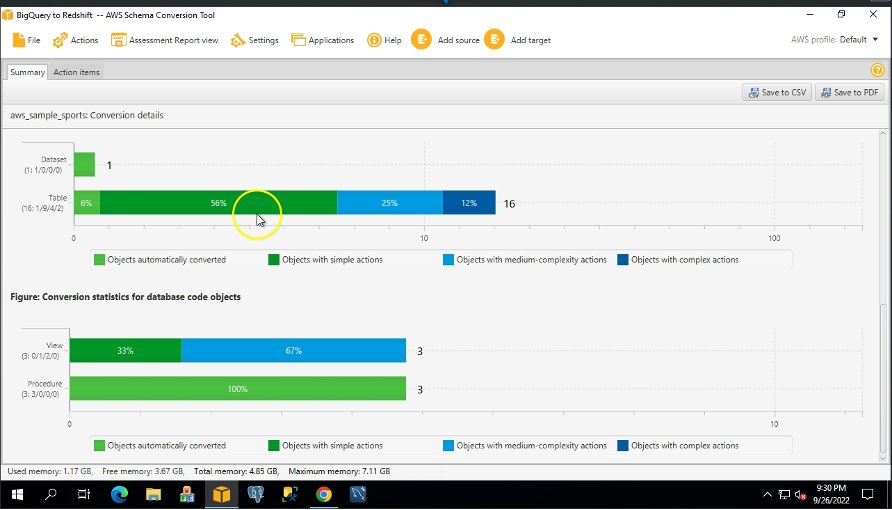
Il Elementi di azione scheda mostra le azioni consigliate per ogni problema di conversione. Se selezioni un'azione dall'elenco, AWS SCT evidenzia l'oggetto a cui si applica l'azione.
Il report contiene anche consigli su come convertire manualmente l'elemento dello schema. Ad esempio, dopo l'esecuzione della valutazione, report dettagliati per il database/schema mostrano lo sforzo necessario per progettare e implementare i suggerimenti per la conversione degli elementi di azione. Per ulteriori informazioni su come decidere come gestire le conversioni manuali, vedere Gestione delle conversioni manuali in AWS SCT. Amazon Redshift esegue automaticamente alcune azioni durante la conversione dello schema in Amazon Redshift. Gli oggetti con queste azioni sono contrassegnati da un segnale di avvertimento rosso.

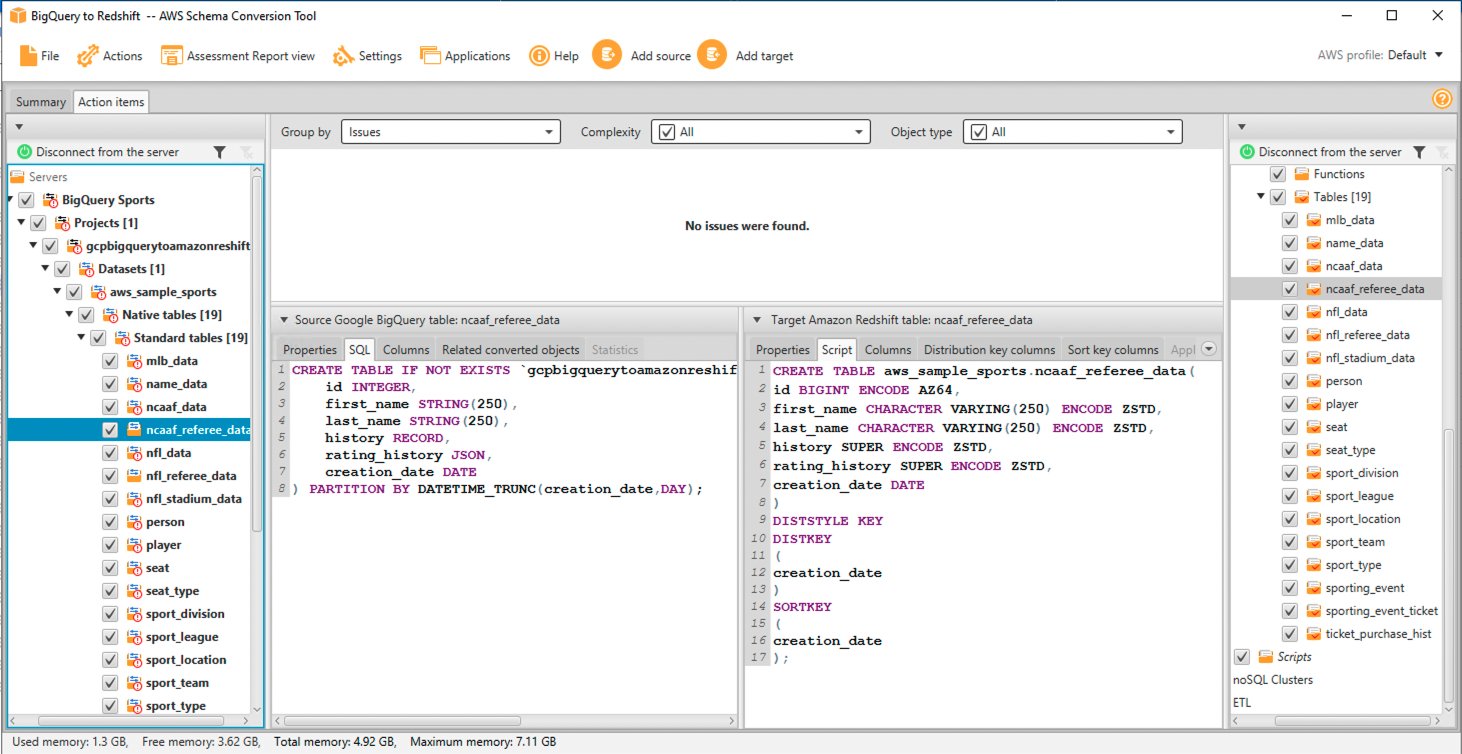
È possibile valutare e ispezionare il singolo oggetto DDL selezionandolo dal riquadro di destra e modificarlo in base alle esigenze. Nell'esempio seguente, AWS SCT modifica le colonne del tipo di dati RECORD e JSON nella tabella BigQuery ncaaf_referee_data nel tipo di dati SUPER in Amazon Redshift. La chiave di partizione nella tabella ncaaf_referee_data viene convertita nella chiave di distribuzione e nella chiave di ordinamento in Amazon Redshift.
Applica lo schema convertito per indirizzare Amazon Redshift
Per applicare lo schema convertito ad Amazon Redshift, seleziona lo schema convertito nel riquadro a destra, fai clic con il pulsante destro del mouse e scegli Applica al database.
Migra i dati da BigQuery ad Amazon Redshift utilizzando gli agenti di estrazione dei dati AWS SCT
Gli agenti di estrazione AWS SCT estraggono i dati dal database di origine e li migrano nel cloud AWS. In questa procedura dettagliata, mostriamo come configurare gli agenti di estrazione AWS SCT per estrarre i dati da BigQuery ed eseguire la migrazione ad Amazon Redshift.
Innanzitutto, installa l'agente di estrazione AWS SCT sulla stessa istanza Windows in cui è installato AWS SCT. Per prestazioni migliori, ti consigliamo di utilizzare un'istanza Linux separata per installare gli agenti di estrazione, se possibile. Per set di dati di grandi dimensioni, puoi utilizzare diversi agenti di estrazione dei dati per aumentare la velocità di migrazione dei dati.
Generazione di archivi di fiducia e chiavi (facoltativo)
Puoi utilizzare la comunicazione crittografata Secure Socket Layer (SSL) con gli estrattori di dati AWS SCT. Quando utilizzi SSL, tutti i dati trasmessi tra le applicazioni rimangono privati e integrali. Per utilizzare la comunicazione SSL, devi generare trust e archivi di chiavi utilizzando AWS SCT. Puoi saltare questo passaggio se non desideri utilizzare SSL. Si consiglia di utilizzare SSL per i carichi di lavoro di produzione.
Segui questi passaggi per generare trust e key store:
- In AWS SCT, vai a Impostazioni → Impostazioni globali → Sicurezza.
- Scegli Genera fiducia e archivio chiavi.

- Inserisci il nome e la password per gli archivi di trust e chiavi e scegli una posizione in cui desideri memorizzarli.

- Scegli Generare.
Installa e configura l'agente di estrazione dati
Nel pacchetto di installazione per AWS SCT, trovi un agente di sottocartella (aws-schema-conversion-tool-1.0.latest.zipagents). Individua e installa il file eseguibile con un nome come aws-schema-conversion-tool-extractor-xxxxxxxx.msi.
Nel processo di installazione, segui questi passaggi per configurare AWS SCT Data Extractor:
- Nel Porta di ascolto, immettere il numero di porta su cui l'agente è in ascolto. È 8192 per impostazione predefinita.
- Nel Aggiungi un fornitore di origine, accedere no, poiché non hai bisogno di driver per connetterti a BigQuery.
- Nel Aggiungi il driver Amazon Redshift, accedere SI.
- Nel Immettere il file o i file del driver JDBC Redshift, inserisci il percorso in cui hai scaricato i driver JDBC di Amazon Redshift.
- Nel Cartella di lavoro, inserisci il percorso in cui l'agente di estrazione dei dati AWS SCT memorizzerà i dati estratti. La cartella di lavoro può trovarsi su un computer diverso dall'agente e una singola cartella di lavoro può essere condivisa da più agenti su computer diversi.
- Nel Abilita la comunicazione SSL, accedere sì. Scegli No qui se non vuoi usare SSL.
- Nel Negozio di chiavi, immettere la posizione di archiviazione scelta durante la creazione dell'archivio di trust e chiavi.
- Nel Password dell'archivio chiavi, immettere la password per l'archivio chiavi.
- Nel Abilita l'autenticazione SSL del client, accedere sì.
- Nel Negozio di fiducia, immettere la posizione di archiviazione scelta durante la creazione dell'archivio di trust e chiavi.
- Nel Fidati della password dell'archivio, immettere la password per il truststore.
Avvio degli agenti di estrazione dati
Utilizzare la seguente procedura per avviare gli agenti di estrazione. Ripetere questa procedura su ogni computer in cui è installato un agente di estrazione.
Gli agenti di estrazione fungono da ascoltatori. Quando si avvia un agente con questa procedura, l'agente inizia ad ascoltare le istruzioni. Invierai agli agenti le istruzioni per estrarre i dati dal tuo data warehouse in una sezione successiva.
Per avviare l'agente di estrazione, vai alla directory dell'agente di estrazione dati AWS SCT. Ad esempio, in Microsoft Windows, fare doppio clic C:Program FilesAWS SCT Data Extractor AgentStartAgent.bat.
- Sul computer in cui è installato l'agente di estrazione, da un prompt dei comandi o da una finestra di terminale, esegui il comando elencato dopo il tuo sistema operativo.
- Per verificare lo stato dell'agente, eseguire lo stesso comando ma sostituire start con status.
- Per arrestare un agente, esegui lo stesso comando ma sostituisci start con stop.
- Per riavviare un agente, eseguire lo stesso file RestartAgent.bat.
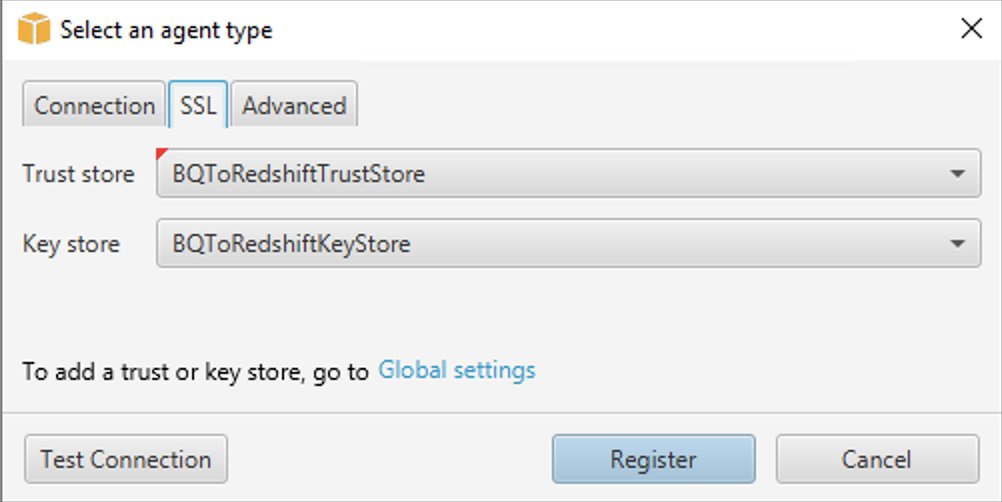
Registra l'agente di estrazione dati
Segui questi passaggi per registrare l'agente di estrazione dati:
- In AWS SCT, modifica la vista in Vista Migrazione dati (altro) e scegli + Registrati.
- Nella scheda Connessione:

- Nel Descrizione, immettere un nome per identificare l'agente di estrazione dati.
- Nel Nome host, se hai installato l'agente di estrazione dati sulla stessa workstation di AWS SCT, inserisci 0.0.0.0 per indicare l'host locale. In caso contrario, immetti il nome host della macchina su cui è installato AWS SCT Data Extraction Agent. Si consiglia di installare gli agenti di estrazione dati su Linux per prestazioni migliori.
- Nel Porto, inserire il numero inserito per il Porta di ascolto durante l'installazione di AWS SCT Data Extraction Agent.
- Selezionare la casella di controllo per utilizzare SSL (se si utilizza SSL) per crittografare la connessione AWS SCT all'agente di estrazione dati.
- Se utilizzi SSL, nella scheda SSL:
- Nel Negozio di fiducia, scegli il nome del truststore creato quando generazione di Trust e Key Store (facoltativamente, puoi ignorare questa operazione se la connettività SSL non è necessaria).
- Nel Negozio di chiavi, scegliere il nome dell'archivio chiavi creato quando generazione di Trust e Key Store (facoltativamente, puoi ignorare questa operazione se la connettività SSL non è necessaria).

- Scegli Test di connessione.
- Una volta che la connessione è stata convalidata correttamente, scegli Registrati.
Aggiungi partizioni virtuali per tabelle di grandi dimensioni (facoltativo)
Puoi utilizzare AWS SCT per creare partizioni virtuali per ottimizzare le prestazioni di migrazione. Quando vengono create le partizioni virtuali, AWS SCT estrae i dati in parallelo per le partizioni. Si consiglia di creare partizioni virtuali per tabelle di grandi dimensioni.
Segui questi passaggi per creare partizioni virtuali:
- Deseleziona tutti gli oggetti nella vista del database di origine in AWS SCT.
- Scegli la tabella per la quale desideri aggiungere il partizionamento virtuale.
- Fai clic con il pulsante destro del mouse sulla tabella e scegli Aggiungi il partizionamento virtuale.

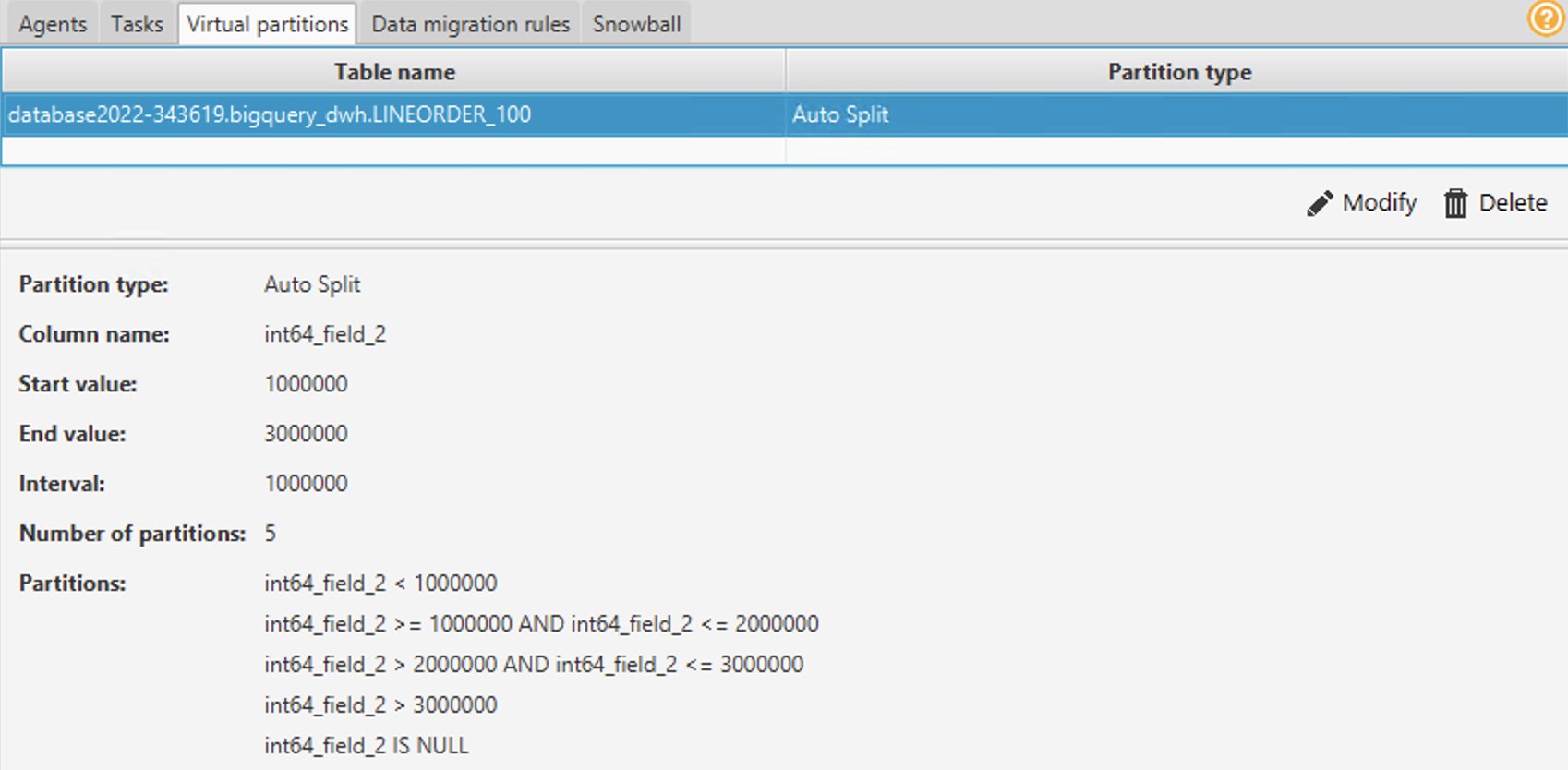
- È possibile utilizzare le partizioni Elenco, Intervallo o Divisione automatica. Per ulteriori informazioni sul partizionamento virtuale, fare riferimento a Utilizza il partizionamento virtuale in AWS SCT. In questo esempio, utilizziamo il partizionamento automatico suddiviso, che genera automaticamente partizioni di intervallo. Dovresti specificare il valore iniziale, il valore finale e quanto dovrebbe essere grande la partizione. AWS SCT determina automaticamente le partizioni. Per una dimostrazione, sulla tabella Lineorder:
- Nel Valore iniziale, inserisci 1000000.
- Nel Valore finale, inserisci 3000000.
- Nel Intervallo, immettere 1000000 per indicare la dimensione della partizione.
- Scegli Ok.

Puoi vedere le partizioni generate automaticamente sotto il file Partizioni virtuali scheda. In questo esempio, AWS SCT ha creato automaticamente le seguenti cinque partizioni per il campo:
-
- <1000000
- >=1000000 e <=2000000
- >2000000 e <=3000000
- > 3000000
- È ZERO
Crea un'attività di migrazione locale
Per migrare i dati da BigQuery ad Amazon Redshift, crea, esegui e monitora l'attività di migrazione locale da AWS SCT. Questo passaggio utilizza l'agente di estrazione dati per migrare i dati creando un'attività.
Segui questi passaggi per creare un'attività di migrazione locale:
- In AWS SCT, sotto il nome dello schema nel riquadro a sinistra, fai clic con il pulsante destro del mouse su Tabelle standard.
- Scegli Crea attività locale.

- Ci sono tre modalità di migrazione tra cui puoi scegliere:
- Estrai i dati di origine e archiviali su un PC locale/macchina virtuale (VM) in cui viene eseguito l'agente.
- Estrai i dati e caricali su un bucket S3.
- Scegli Extract upload and copy, che estrae i dati in un bucket S3 e li copia in Amazon Redshift.

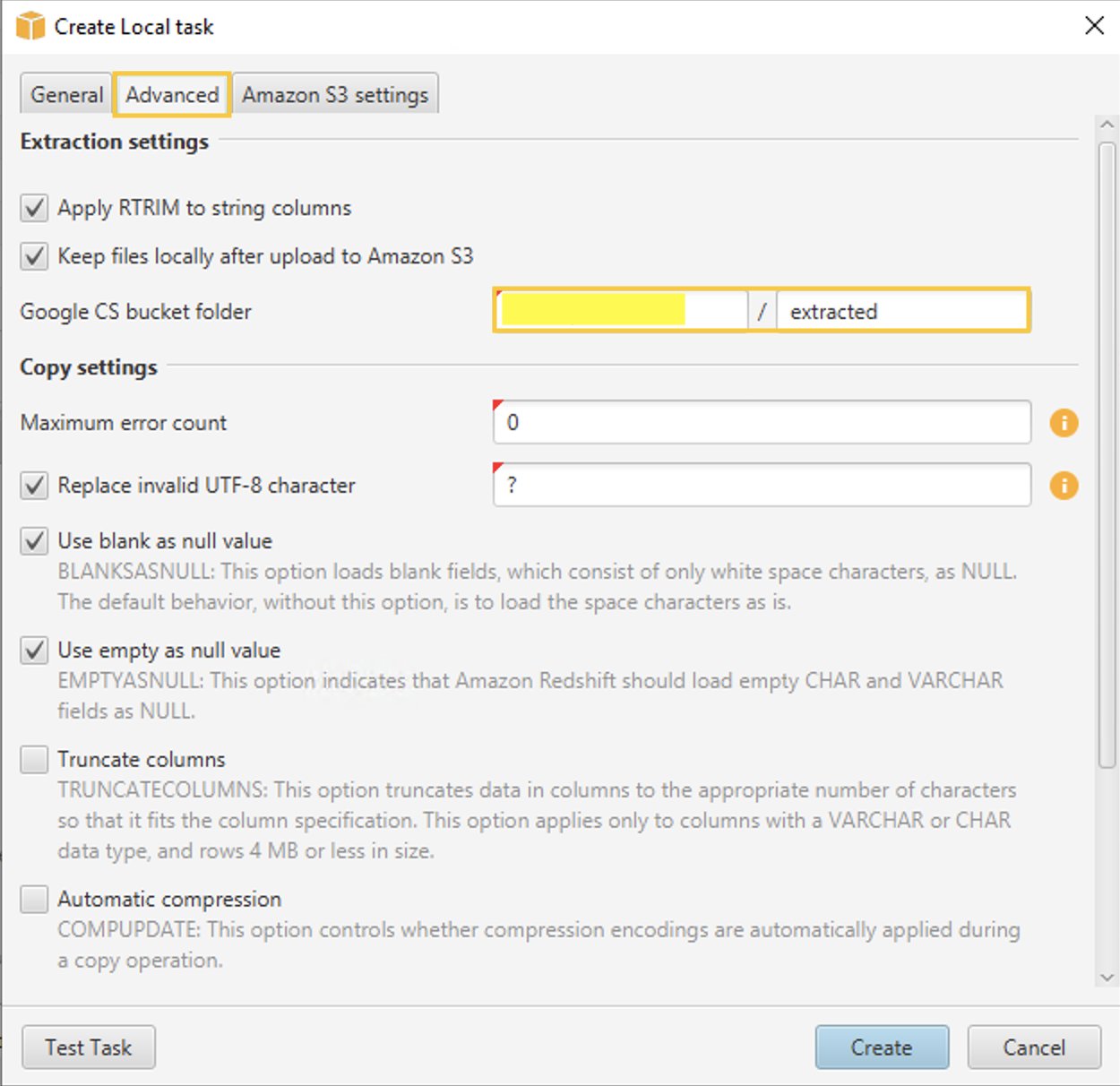
- Nel Tecnologia scheda, per Cartella del secchio di Google CS inserisci il bucket o la cartella di Google Cloud Storage che hai creato in precedenza nella console di gestione di GCP. AWS SCT memorizza i dati estratti in questa posizione.
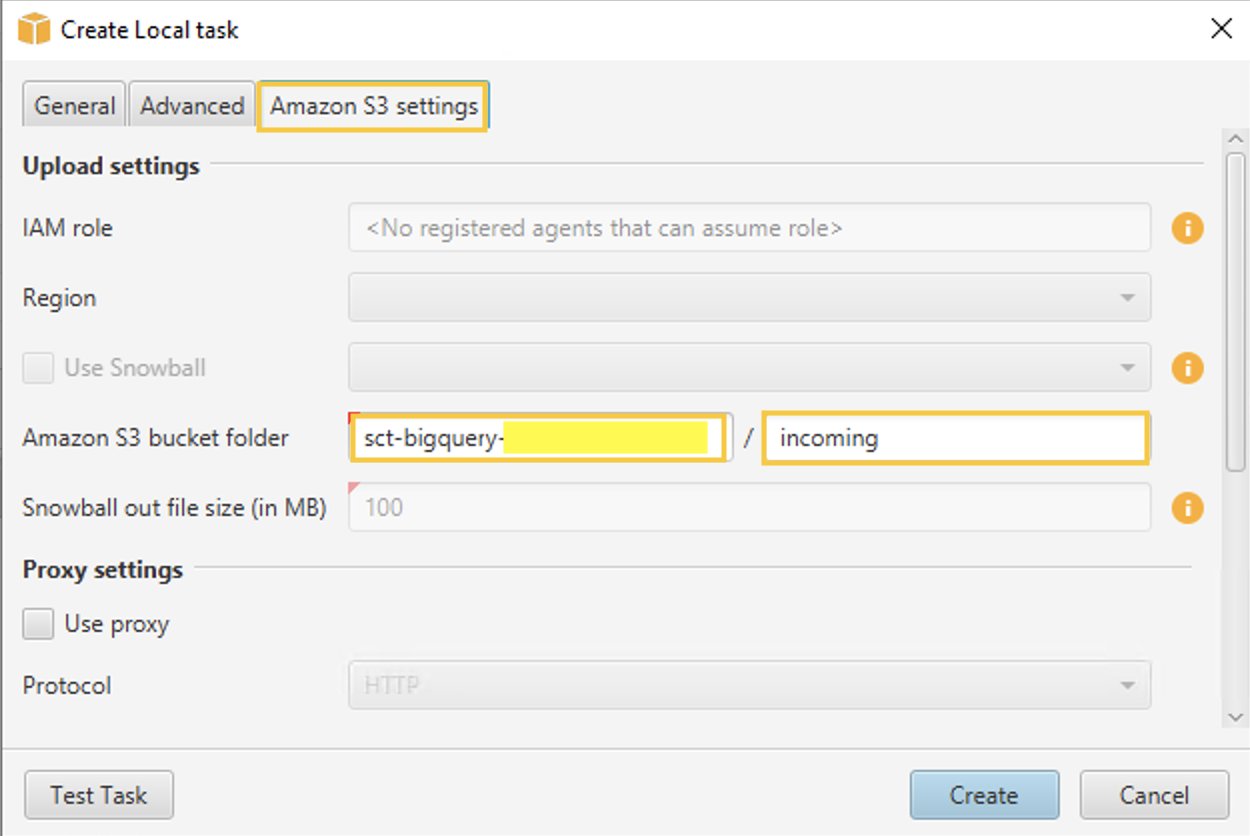
- Nel Impostazioni Amazon S3 scheda, per Cartella del secchio Amazon S3, fornire i nomi del bucket e della cartella del bucket S3 creato in precedenza. L'agente di estrazione dati AWS SCT carica i dati nel bucket/cartella S3 prima di copiarli in Amazon Redshift.
- Scegli Attività di prova.
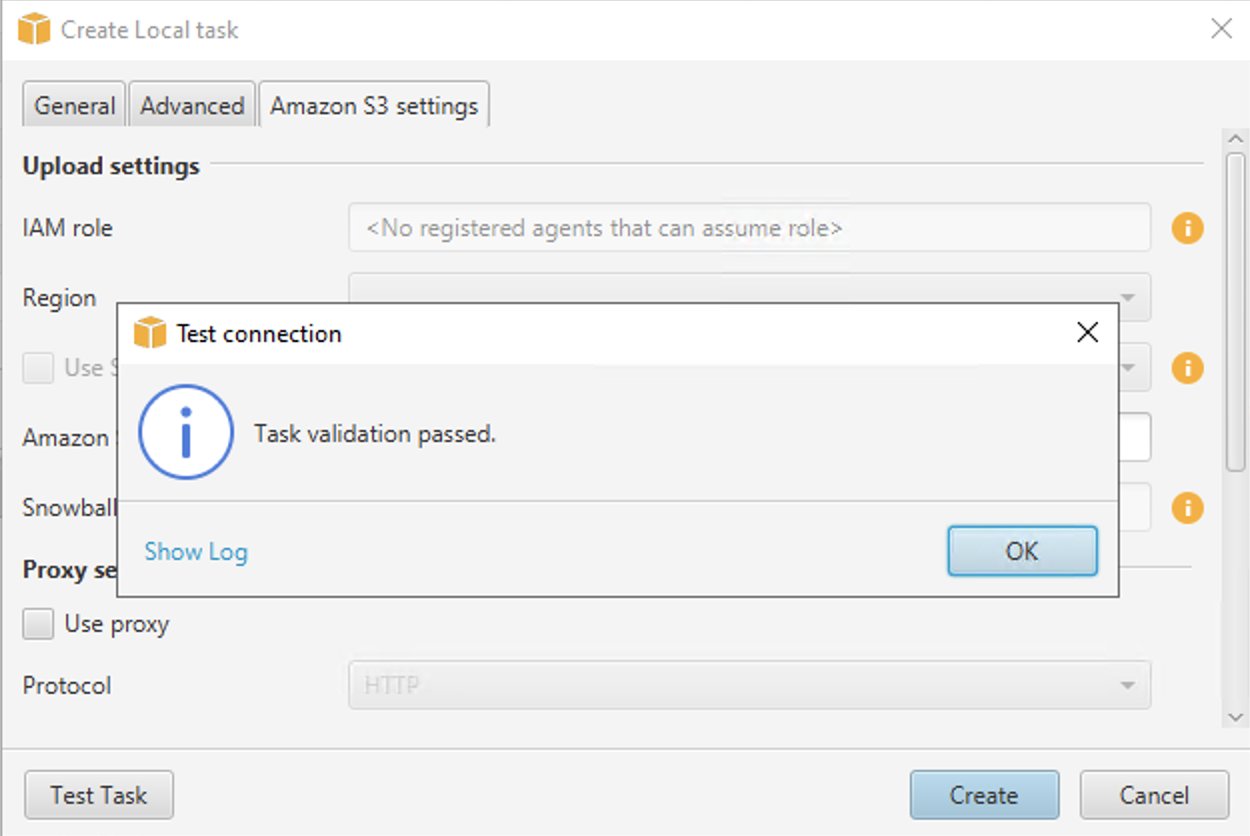
- Una volta che l'attività è stata convalidata correttamente, scegli Creare.
Avviare l'attività di migrazione dei dati locali
Per avviare l'attività, scegli il file Inizio nel pulsante Compiti scheda.

- Innanzitutto, l'agente di estrazione dati estrae i dati da BigQuery nel bucket di archiviazione GCP.
- Quindi, l'agente carica i dati su Amazon S3 e avvia un comando di copia per spostare i dati su Amazon Redshift.
- A questo punto, AWS SCT ha eseguito correttamente la migrazione dei dati dalla tabella BigQuery di origine alla tabella Amazon Redshift.
Visualizza i dati in Amazon Redshift
Dopo che l'attività di migrazione dei dati è stata eseguita correttamente, puoi connetterti ad Amazon Redshift e convalidare i dati.
Segui questi passaggi per convalidare i dati in Amazon Redshift:
- Passare alla Editor di query di Amazon Redshift V2.
- Fai doppio clic sul nome del gruppo di lavoro Amazon Redshift Serverless che hai creato.
- Scegliere il Utente federato opzione sotto Autenticazione.
- Scegli Crea connessione.
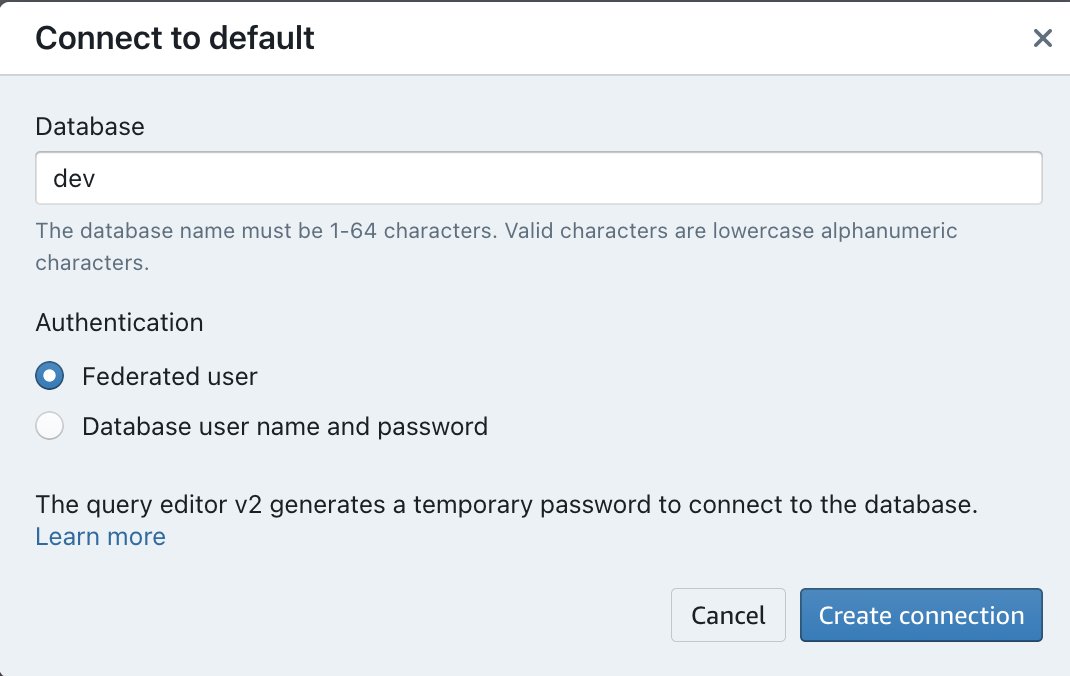
- Crea un nuovo editor scegliendo il file + icona.
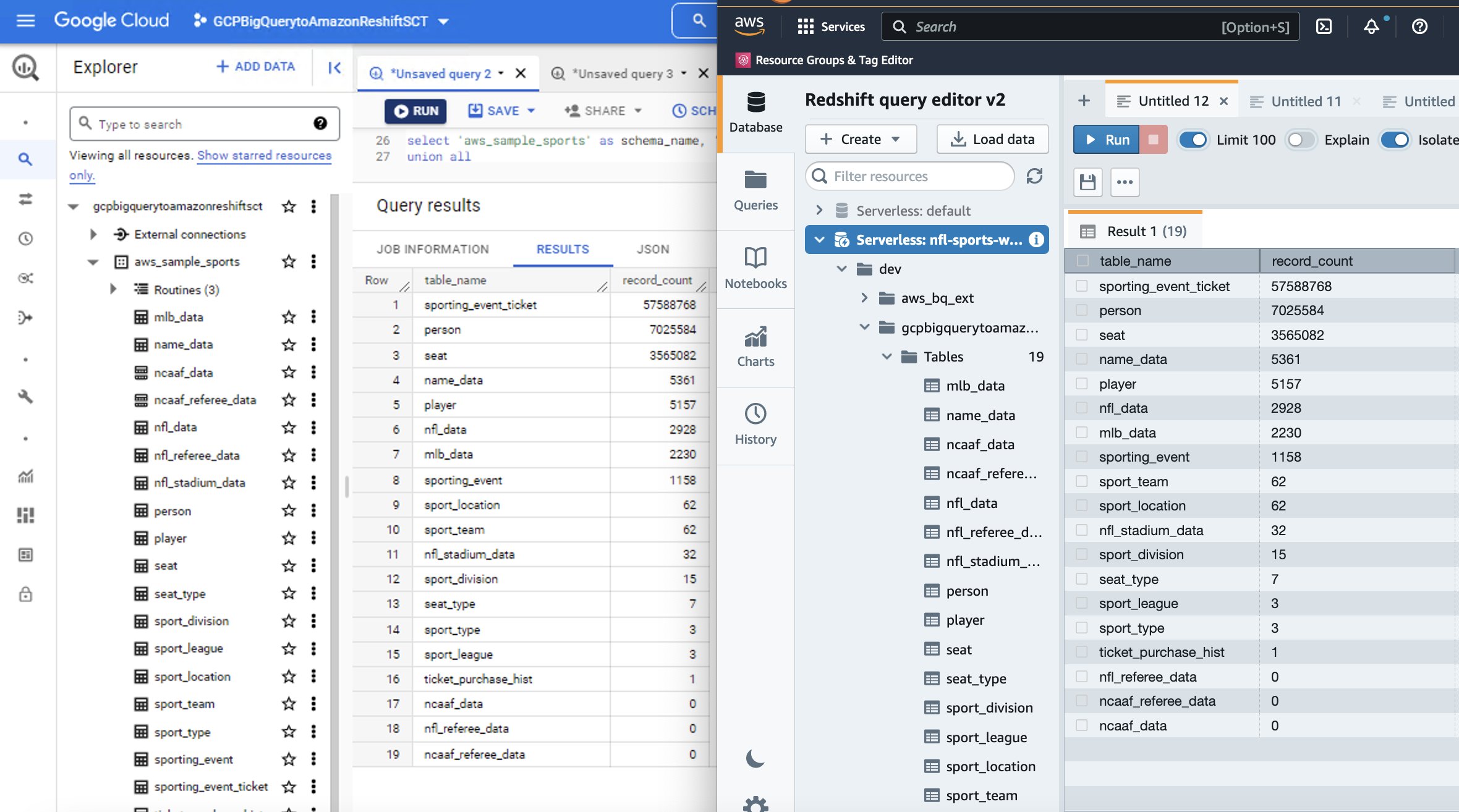
- Nell'editor, scrivi una query per selezionare tra il nome dello schema e il nome della tabella/nome della vista che desideri verificare. Esplora i dati, esegui query ad hoc e crea visualizzazioni, grafici e visualizzazioni.

Di seguito è riportato un confronto affiancato tra BigQuery di origine e Amazon Redshift di destinazione per il set di dati sportivi utilizzato in questa procedura dettagliata.
Pulisci tutte le risorse AWS che hai creato per questo esercizio
Segui questi passaggi per terminare l'istanza EC2:
- Passare alla Console Amazon EC2.
- Nel pannello di navigazione, scegli Istanze.
- Seleziona la casella di controllo per l'istanza EC2 che hai creato.
- Scegli Stato dell'istanza, e poi Termina istanza.
- Scegli Terminare quando viene richiesta la conferma.
Segui questi passaggi per eliminare il gruppo di lavoro e lo spazio dei nomi Amazon Redshift Serverless
- Spostarsi Dashboard serverless di Amazon Redshift.
- Sotto Spazi dei nomi/gruppi di lavoro, scegli l'area di lavoro che hai creato.
- Sotto Azioniscegli Elimina gruppo di lavoro.
- Seleziona la casella di controllo Elimina lo spazio dei nomi associato.
- Deseleziona Crea un'istantanea finale.
- entrare delete nella casella di testo di conferma dell'eliminazione e scegliere Elimina.

Segui questi passaggi per eliminare il bucket S3
- Spostarsi Console Amazon S3.
- Scegli il bucket che hai creato.
- Scegli Elimina.
- Per confermare l'eliminazione, inserisci il nome del bucket nel campo di immissione del testo.
- Scegli Elimina secchio.
Conclusione
La migrazione di un data warehouse può essere un progetto impegnativo, complesso e tuttavia gratificante. AWS SCT riduce la complessità delle migrazioni del data warehouse. Seguendo questa procedura dettagliata, puoi capire in che modo un'attività di migrazione dei dati estrae, scarica e quindi migra i dati da BigQuery ad Amazon Redshift. La soluzione che abbiamo presentato in questo post esegue una migrazione una tantum di oggetti e dati del database. Le modifiche ai dati apportate in BigQuery quando la migrazione è in corso non si rifletteranno in Amazon Redshift. Quando la migrazione dei dati è in corso, sospendi i processi ETL in BigQuery o riproduci gli ETL puntando su Amazon Redshift dopo la migrazione. Prendi in considerazione l'utilizzo di best practice per AWS SCT.
AWS SCT presenta alcune limitazioni quando si utilizza BigQuery come origine. Ad esempio, AWS SCT non può convertire sottoquery in funzioni analitiche, funzioni geografiche, funzioni di aggregazione statistica e così via. Trovi l'elenco completo delle limitazioni nel Guida per l'utente di AWS SCT. Abbiamo in programma di affrontare queste limitazioni nelle versioni future. Nonostante queste limitazioni, puoi utilizzare AWS SCT per convertire automaticamente la maggior parte del codice BigQuery e degli oggetti di storage.
Scarica e installa AWS SCT, accedi al Console AWS, controlla Amazon Redshift Serverless e avvia la migrazione!
Circa gli autori
 Felpa con cappuccio Cedrick è un architetto di soluzioni con particolare attenzione alle migrazioni di database utilizzando AWS Database Migration Service (DMS) e AWS Schema Conversion Tool (SCT) presso AWS. Si occupa delle sfide relative alle migrazioni di DB. Lavora a stretto contatto con i clienti del settore EdTech, Energia e ISV per aiutarli a realizzare il vero potenziale del servizio DMS. Ha aiutato a migrare centinaia di database nel cloud AWS utilizzando DMS e SCT.
Felpa con cappuccio Cedrick è un architetto di soluzioni con particolare attenzione alle migrazioni di database utilizzando AWS Database Migration Service (DMS) e AWS Schema Conversion Tool (SCT) presso AWS. Si occupa delle sfide relative alle migrazioni di DB. Lavora a stretto contatto con i clienti del settore EdTech, Energia e ISV per aiutarli a realizzare il vero potenziale del servizio DMS. Ha aiutato a migrare centinaia di database nel cloud AWS utilizzando DMS e SCT.
 Amit Arora è un Solutions Architect specializzato in database e analisi in AWS. Lavora con i nostri clienti di tecnologia finanziaria e Global Energy e partner certificati AWS per fornire assistenza tecnica e progettare soluzioni per i clienti su progetti di migrazione al cloud, aiutando i clienti a migrare e modernizzare i loro database esistenti nel cloud AWS.
Amit Arora è un Solutions Architect specializzato in database e analisi in AWS. Lavora con i nostri clienti di tecnologia finanziaria e Global Energy e partner certificati AWS per fornire assistenza tecnica e progettare soluzioni per i clienti su progetti di migrazione al cloud, aiutando i clienti a migrare e modernizzare i loro database esistenti nel cloud AWS.
 Jagadish Kumar è un architetto di soluzioni specialista in analisi presso AWS specializzato in Amazon Redshift. È profondamente appassionato di architettura dei dati e aiuta i clienti a creare soluzioni di analisi su larga scala su AWS.
Jagadish Kumar è un architetto di soluzioni specialista in analisi presso AWS specializzato in Amazon Redshift. È profondamente appassionato di architettura dei dati e aiuta i clienti a creare soluzioni di analisi su larga scala su AWS.
 Anuscha Challa è un Senior Analytics Specialist Solution Architect presso AWS specializzato in Amazon Redshift. Ha aiutato molti clienti a creare soluzioni di data warehouse su larga scala nel cloud e in locale. Anusha è appassionata di analisi dei dati e scienza dei dati e consente ai clienti di raggiungere il successo con i loro progetti di dati su larga scala.
Anuscha Challa è un Senior Analytics Specialist Solution Architect presso AWS specializzato in Amazon Redshift. Ha aiutato molti clienti a creare soluzioni di data warehouse su larga scala nel cloud e in locale. Anusha è appassionata di analisi dei dati e scienza dei dati e consente ai clienti di raggiungere il successo con i loro progetti di dati su larga scala.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/migrate-google-bigquery-to-amazon-redshift-using-aws-schema-conversion-tool-sct/
- 1
- 10
- 100
- 9
- a
- Chi siamo
- accesso
- Il mio account
- Raggiungere
- Legge
- Action
- azioni
- aggiuntivo
- indirizzo
- Admin
- Dopo shavasana, sedersi in silenzio; saluti;
- Agente
- agenti
- Tutti
- già
- Amazon
- Analitico
- Analitico
- analitica
- ed
- Applicazioni
- applicazioni
- APPLICA
- architettura
- RISERVATA
- valutazione
- Assistenza
- associato
- Autenticazione
- auto
- automaticamente
- AWS
- base
- BAT
- prima
- beneficio
- Meglio
- fra
- Big
- Blu
- Scatola
- costruire
- affari
- pulsante
- Può ottenere
- non può
- funzionalità
- Ultra-Grande
- Certificato
- sfide
- impegnativo
- il cambiamento
- Modifiche
- Grafici
- dai un'occhiata
- Procedi all'acquisto
- scegliere
- Scegli
- la scelta
- scelto
- chiaramente
- cliente
- strettamente
- Cloud
- Cloud Storage
- codice
- collezione
- Colonna
- colonne
- Comunicazione
- confronto
- compatibile
- completamento di una
- complesso
- complessità
- Calcolare
- computer
- computer
- Configurazione
- Confermare
- Connettiti
- veloce
- Connessioni
- Connettività
- Prendere in considerazione
- coerente
- consolle
- contiene
- controlli
- Conversione
- conversioni
- convertire
- convertito
- copiatura
- Costo
- costo effettivo
- creare
- creato
- crea
- Creazione
- credito
- cliente
- Soluzioni per i clienti
- Clienti
- dati
- Dati Analytics
- scienza dei dati
- condivisione dei dati
- Banca Dati
- banche dati
- dataset
- Decidere
- Predefinito
- Richiesta
- schierare
- descrivere
- descritta
- Design
- tavolo
- Nonostante
- dettagliati
- determina
- dialogo
- diverso
- display
- distribuzione
- Dont
- scaricare
- download
- autista
- driver
- durante
- ogni
- In precedenza
- facile da usare
- editore
- sforzo
- incorporato
- enable
- Abilita
- consentendo
- crittografato
- crittografia
- da un capo all'altro
- endpoint
- energia
- entrare
- inserito
- Ambiente
- Etere (ETH)
- valutare
- esempio
- esegue
- esistente
- esplora
- esterno
- extra
- estratto
- estratti
- familiare
- FAST
- più veloce
- pochi
- campo
- Compila il
- File
- finale
- Infine
- finanziario
- tecnologia finanziaria
- Trovare
- firewall
- Nome
- Flessibilità
- Focus
- concentrato
- seguire
- i seguenti
- segue
- formato
- Gratis
- da
- pieno
- funzioni
- Inoltre
- futuro
- generare
- generato
- genera
- geografia
- ottenere
- globali
- Google cloud
- Green
- maniglia
- Hardware
- Aiuto
- aiutato
- aiutare
- aiuta
- qui
- Alta
- evidenzia
- vivamente
- tenere
- Casa
- host
- ORE
- Casa
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- ICON
- identificare
- Identità
- realizzare
- in
- Aumento
- indicare
- individuale
- informazioni
- ingresso
- intuizioni
- install
- installazione
- esempio
- istruzioni
- integrale
- Integra
- interagire
- interferire
- intervento
- problema
- IT
- elementi
- Lavoro
- Offerte di lavoro
- json
- Le
- Genere
- grandi
- larga scala
- con i più recenti
- lanciare
- lancia
- strato
- IMPARARE
- Consente di
- Livello
- limiti
- linux
- Lista
- elencati
- Ascolto
- caricare
- locale
- località
- macchina
- fatto
- Principale
- Maggioranza
- make
- FA
- gestire
- gestione
- direttore
- gestione
- Manuale
- manualmente
- molti
- significativo
- medie
- Soddisfa
- Menu
- metodi
- Microsoft
- Microsoft Windows
- forza
- migrare
- migrazione
- ML
- modelli
- moderno
- modernizzare
- Monitorare
- Scopri di più
- maggior parte
- cambiano
- msi
- multiplo
- Nome
- nomi
- di denominazione
- Navigare
- Navigazione
- Bisogno
- New
- GENERAZIONE
- notevole
- numero
- oggetto
- oggetti
- Offerte
- ONE
- apre
- operativo
- sistema operativo
- OTTIMIZZA
- Altro
- altrimenti
- pacchetto
- vetro
- pannello di eventi
- Parallel
- partner
- Passato
- appassionato
- Password
- sentiero
- Paga le
- Corrente di
- eseguire
- performance
- esegue
- piano
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- possibile
- Post
- potenziale
- pratiche
- Prevedibile
- Previsioni
- prerequisiti
- presentata
- in precedenza
- un bagno
- procedure
- processi
- Produzione
- Programma
- Progressi
- progetto
- progetti
- fornire
- fornisce
- metti
- domanda
- rapidamente
- gamma
- rendersi conto
- raccomandare
- raccomandazioni
- raccomandato
- record
- Rosso
- riduce
- riflette
- regione
- registro
- relazionato
- Uscite
- resti
- ripetere
- sostituire
- sostituito
- replicato
- rapporto
- Report
- rappresenta
- richieste
- richiedere
- necessario
- elastico
- Risorse
- gratificante
- Ricco
- Fare clic con
- Ruolo
- ruoli
- RIGA
- norme
- Correre
- stesso
- scalabile
- Scala
- bilancia
- scala
- scansione
- Scienze
- scienziati
- script
- senza soluzione di continuità
- secondo
- Sezione
- settore
- sicuro
- problemi di
- Selezione
- delicata
- serverless
- servizio
- Servizi
- set
- Set
- regolazione
- impostazioni
- alcuni
- condiviso
- compartecipazione
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- segno
- Un'espansione
- singolo
- Taglia
- Istantanea
- So
- soluzione
- Soluzioni
- alcuni
- Fonte
- specialista
- velocità
- Spendere
- dividere
- Sports
- SSL
- messa in scena
- inizia a
- Di partenza
- inizio
- dichiarazioni
- statistiche
- statistica
- Stato dei servizi
- step
- Passi
- Fermare
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- il successo
- Con successo
- tale
- Super
- Interruttore
- sistema
- tavolo
- Fai
- prende
- Target
- Task
- Consulenza
- Tecnologia
- terminal
- Il
- L’ORIGINE
- loro
- di parti terze standard
- tre
- tempo
- volte
- a
- tolleranza
- strumenti
- tradizionale
- Treni
- Trasformare
- vero
- Affidati ad
- per
- sottostante
- capire
- unico
- Impiego
- uso
- Utente
- utenti
- CONVALIDARE
- convalidato
- Prezioso
- APPREZZIAMO
- Valori
- venditore
- fornitori
- verificare
- versione
- Visualizza
- visualizzazioni
- virtuale
- walkthrough
- identificazione dei warning
- sito web
- Che
- quale
- while
- più ampia
- volere
- finestre
- entro
- senza
- Gruppo di lavoro
- lavoro
- lavori
- stazione di lavoro
- sarebbe
- scrivere
- scritto
- Trasferimento da aeroporto a Sharm
- zefiro