
Man mano che l’intelligenza artificiale migra dal cloud all’Edge, vediamo la tecnologia utilizzata in una varietà di casi d’uso in continua espansione, che vanno dal rilevamento di anomalie ad applicazioni tra cui acquisti intelligenti, sorveglianza, robotica e automazione di fabbrica. Pertanto, non esiste una soluzione valida per tutti. Ma con la rapida crescita dei dispositivi abilitati alla fotocamera, l’intelligenza artificiale è stata ampiamente adottata per analizzare i dati video in tempo reale per automatizzare il monitoraggio video per migliorare la sicurezza, migliorare l’efficienza operativa e fornire migliori esperienze ai clienti, ottenendo in definitiva un vantaggio competitivo nei loro settori. . Per supportare meglio l'analisi video, è necessario comprendere le strategie per ottimizzare le prestazioni del sistema nelle distribuzioni di IA edge.
- Selezione dei motori di calcolo delle giuste dimensioni per soddisfare o superare i livelli di prestazioni richiesti. Per un'applicazione AI, questi motori di calcolo devono eseguire le funzioni dell'intera pipeline di visione (ad esempio, pre e post-elaborazione video, inferenza sulla rete neurale).
Potrebbe essere necessario un acceleratore AI dedicato, sia esso discreto o integrato in un SoC (invece di eseguire l'inferenza AI su una CPU o GPU).
- Comprendere la differenza tra throughput e latenza; dove il throughput è la velocità con cui i dati possono essere elaborati in un sistema e la latenza misura il ritardo di elaborazione dei dati attraverso il sistema ed è spesso associata alla reattività in tempo reale. Ad esempio, un sistema può generare dati di immagine a 100 fotogrammi al secondo (velocità effettiva), ma sono necessari 100 ms (latenza) affinché un'immagine attraversi il sistema.
- Considerando la capacità di scalare facilmente le prestazioni dell’intelligenza artificiale in futuro per soddisfare esigenze crescenti, requisiti in evoluzione e tecnologie in evoluzione (ad esempio, modelli di intelligenza artificiale più avanzati per maggiore funzionalità e precisione). Puoi ottenere il ridimensionamento delle prestazioni utilizzando acceleratori AI in formato modulo o con chip acceleratori AI aggiuntivi.
I requisiti prestazionali effettivi dipendono dall'applicazione. In genere, ci si può aspettare che per l'analisi video, il sistema debba elaborare i flussi di dati provenienti dalle telecamere a 30-60 fotogrammi al secondo e con una risoluzione di 1080p o 4k. Una fotocamera abilitata all’intelligenza artificiale elaborerebbe un singolo flusso; un'appliance edge elaborerebbe più flussi in parallelo. In entrambi i casi, il sistema Edge AI deve supportare le funzioni di pre-elaborazione per trasformare i dati del sensore della fotocamera in un formato che corrisponda ai requisiti di input della sezione di inferenza AI (Figura 1).
Le funzioni di pre-elaborazione acquisiscono i dati grezzi ed eseguono attività come ridimensionamento, normalizzazione e conversione dello spazio colore, prima di inserire l'input nel modello in esecuzione sull'acceleratore AI. La pre-elaborazione può utilizzare efficienti librerie di elaborazione delle immagini come OpenCV per ridurre i tempi di pre-elaborazione. La postelaborazione implica l'analisi dell'output dell'inferenza. Utilizza attività come la soppressione non massima (NMS interpreta l'output della maggior parte dei modelli di rilevamento degli oggetti) e la visualizzazione di immagini per generare informazioni utili, come riquadri di delimitazione, etichette di classi o punteggi di confidenza.

Figura 1. Per l'inferenza del modello AI, le funzioni di pre e post-elaborazione vengono generalmente eseguite su un processore applicativo.
L’inferenza del modello AI può comportare l’ulteriore sfida di elaborare più modelli di rete neurale per frame, a seconda delle capacità dell’applicazione. Le applicazioni di visione artificiale di solito coinvolgono più attività di intelligenza artificiale che richiedono una pipeline di più modelli. Inoltre, l’output di un modello è spesso l’input del modello successivo. In altre parole, i modelli di un'applicazione spesso dipendono l'uno dall'altro e devono essere eseguiti in sequenza. L'insieme esatto di modelli da eseguire potrebbe non essere statico e potrebbe variare dinamicamente, anche fotogramma per fotogramma.
La sfida di eseguire più modelli in modo dinamico richiede un acceleratore AI esterno con memoria dedicata e sufficientemente grande per archiviare i modelli. Spesso l'acceleratore AI integrato all'interno di un SoC non è in grado di gestire il carico di lavoro multimodello a causa dei vincoli imposti dal sottosistema di memoria condivisa e da altre risorse nel SoC.
Ad esempio, il tracciamento degli oggetti basato sulla previsione del movimento si basa su rilevamenti continui per determinare un vettore che viene utilizzato per identificare l'oggetto tracciato in una posizione futura. L’efficacia di questo approccio è limitata perché manca una reale capacità di reidentificazione. Con la previsione del movimento, è possibile perdere la traccia di un oggetto a causa di mancati rilevamenti, occlusioni o dell'uscita dell'oggetto dal campo visivo, anche momentaneo. Una volta perso, non è possibile riassociare la traccia dell’oggetto. L'aggiunta della reidentificazione risolve questa limitazione ma richiede l'incorporamento dell'aspetto visivo (ad esempio, un'impronta digitale dell'immagine). Gli incorporamenti di aspetti richiedono che una seconda rete generi un vettore di caratteristiche elaborando l'immagine contenuta all'interno del riquadro di delimitazione dell'oggetto rilevato dalla prima rete. Questo incorporamento può essere utilizzato per identificare nuovamente l'oggetto, indipendentemente dal tempo o dallo spazio. Poiché è necessario generare incorporamenti per ciascun oggetto rilevato nel campo visivo, i requisiti di elaborazione aumentano man mano che la scena diventa più affollata. Il tracciamento degli oggetti con la reidentificazione richiede un'attenta considerazione tra l'esecuzione di un rilevamento ad alta precisione/alta risoluzione/frequenza fotogrammi elevata e la riservazione di un sovraccarico sufficiente per la scalabilità degli incorporamenti. Un modo per risolvere i requisiti di elaborazione è utilizzare un acceleratore AI dedicato. Come accennato in precedenza, il motore AI del SoC può soffrire della mancanza di risorse di memoria condivise. L'ottimizzazione del modello può essere utilizzata anche per ridurre i requisiti di elaborazione, ma potrebbe influire sulle prestazioni e/o sulla precisione.
In una fotocamera intelligente o in un dispositivo edge, il SoC integrato (ovvero il processore host) acquisisce i fotogrammi video ed esegue le fasi di pre-elaborazione descritte in precedenza. Queste funzioni possono essere eseguite con i core della CPU o la GPU del SoC (se disponibile), ma possono anche essere eseguite da acceleratori hardware dedicati nel SoC (ad esempio, processore del segnale di immagine). Una volta completate queste fasi di pre-elaborazione, l'acceleratore AI integrato nel SoC può quindi accedere direttamente a questo input quantizzato dalla memoria di sistema o, nel caso di un acceleratore AI discreto, l'input viene quindi fornito per l'inferenza, in genere tramite il Interfaccia USB o PCIe.
Un SoC integrato può contenere una gamma di unità di calcolo, tra cui CPU, GPU, acceleratore AI, processori di visione, codificatori/decodificatori video, processore di segnali di immagine (ISP) e altro ancora. Queste unità di calcolo condividono tutte lo stesso bus di memoria e di conseguenza accedono alla stessa memoria. Inoltre, anche la CPU e la GPU potrebbero dover svolgere un ruolo nell'inferenza e queste unità saranno impegnate nell'esecuzione di altre attività in un sistema distribuito. Questo è ciò che intendiamo per sovraccarico a livello di sistema (Figura 2).
Molti sviluppatori valutano erroneamente le prestazioni dell'acceleratore AI integrato nel SoC senza considerare l'effetto del sovraccarico a livello di sistema sulle prestazioni totali. Ad esempio, considera l'esecuzione di un benchmark YOLO su un acceleratore AI da 50 TOPS integrato in un SoC, che potrebbe ottenere un risultato del benchmark di 100 inferenze/secondo (IPS). Ma in un sistema distribuito con tutte le altre unità computazionali attive, quei 50 TOPS potrebbero ridursi a qualcosa come 12 TOPS e le prestazioni complessive produrrebbero solo 25 IPS, assumendo un generoso fattore di utilizzo del 25%. Il sovraccarico del sistema è sempre un fattore se la piattaforma elabora continuamente flussi video. In alternativa, con un acceleratore AI discreto (ad esempio Kinara Ara-1, Hailo-8, Intel Myriad X), l'utilizzo a livello di sistema potrebbe essere superiore al 90% perché una volta che il SoC host avvia la funzione di inferenza e trasferisce l'input del modello AI dati, l'acceleratore funziona in modo autonomo utilizzando la memoria dedicata per accedere ai pesi e ai parametri del modello.
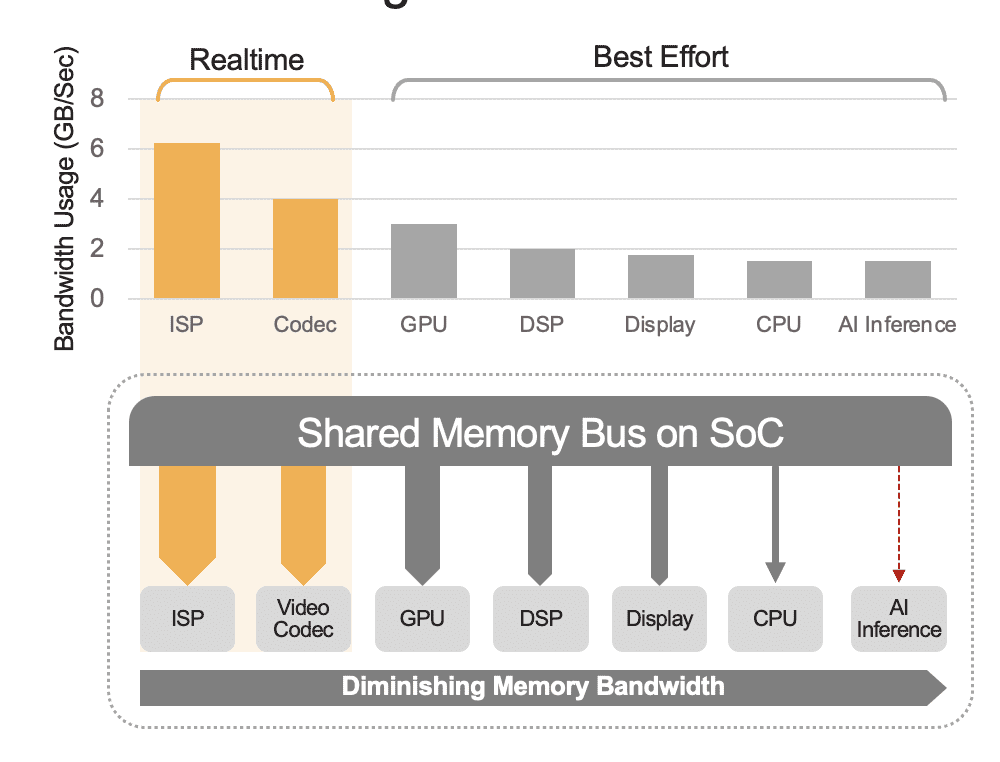
Figura 2. Il bus di memoria condivisa governerà le prestazioni a livello di sistema, mostrate qui con valori stimati. I valori reali varieranno in base al modello di utilizzo dell'applicazione e alla configurazione dell'unità di calcolo del SoC.
Fino a questo punto, abbiamo discusso delle prestazioni dell’intelligenza artificiale in termini di fotogrammi al secondo e TOPS. Ma la bassa latenza è un altro requisito importante per garantire la reattività in tempo reale di un sistema. Ad esempio, nei giochi, una bassa latenza è fondamentale per un'esperienza di gioco fluida e reattiva, in particolare nei giochi controllati dal movimento e nei sistemi di realtà virtuale (VR). Nei sistemi di guida autonoma, una bassa latenza è vitale per il rilevamento di oggetti in tempo reale, il riconoscimento dei pedoni, il rilevamento della corsia e il riconoscimento dei segnali stradali per evitare di compromettere la sicurezza. I sistemi di guida autonoma richiedono in genere una latenza end-to-end inferiore a 150 ms dal rilevamento all’azione effettiva. Allo stesso modo, nella produzione, una bassa latenza è essenziale per il rilevamento dei difetti in tempo reale, il riconoscimento delle anomalie e la guida robotica dipende dall’analisi video a bassa latenza per garantire un funzionamento efficiente e ridurre al minimo i tempi di fermo della produzione.
In generale, esistono tre componenti della latenza in un'applicazione di analisi video (Figura 3):
- La latenza di acquisizione dei dati è il tempo che intercorre tra l'acquisizione di un fotogramma video da parte del sensore della fotocamera e la disponibilità del fotogramma al sistema di analisi per l'elaborazione. Puoi ottimizzare questa latenza scegliendo una fotocamera con un sensore veloce e un processore a bassa latenza, selezionando frame rate ottimali e utilizzando formati di compressione video efficienti.
- La latenza del trasferimento dati è il tempo impiegato dai dati video acquisiti e compressi per viaggiare dalla telecamera ai dispositivi periferici o ai server locali. Ciò include i ritardi di elaborazione della rete che si verificano in ciascun punto finale.
- La latenza di elaborazione dei dati si riferisce al tempo impiegato dai dispositivi edge per eseguire attività di elaborazione video come la decompressione dei fotogrammi e algoritmi di analisi (ad esempio, tracciamento di oggetti basato sulla previsione del movimento, riconoscimento facciale). Come sottolineato in precedenza, la latenza di elaborazione è ancora più importante per le applicazioni che devono eseguire più modelli IA per ciascun fotogramma video.
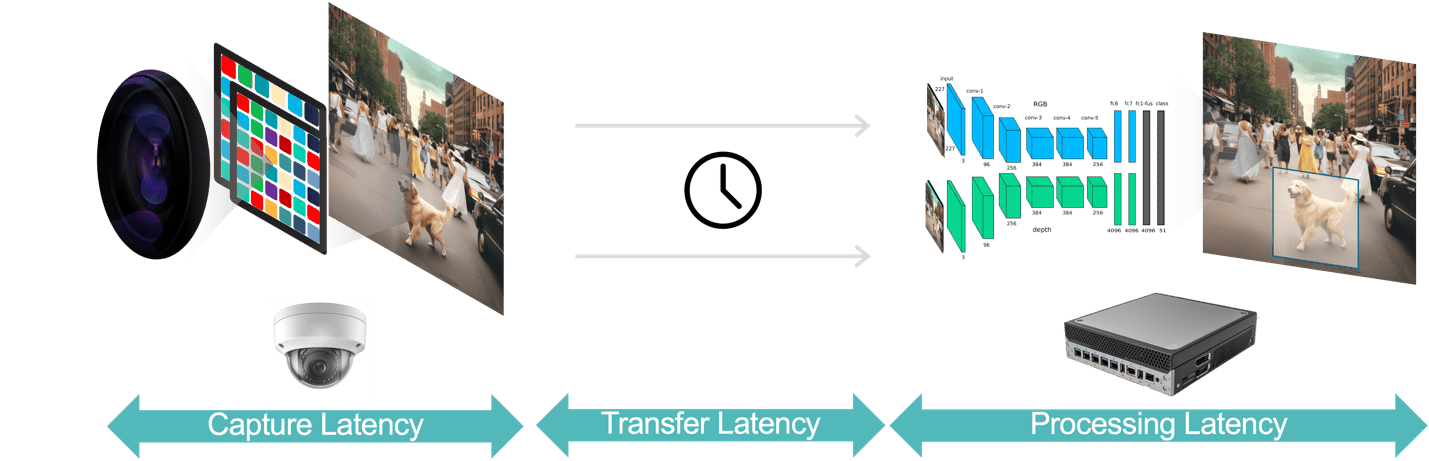
Figura 3. La pipeline di analisi video consiste nell'acquisizione, nel trasferimento e nell'elaborazione dei dati.
La latenza di elaborazione dei dati può essere ottimizzata utilizzando un acceleratore AI con un'architettura progettata per ridurre al minimo lo spostamento dei dati attraverso il chip e tra il calcolo e i vari livelli della gerarchia di memoria. Inoltre, per migliorare la latenza e l'efficienza a livello di sistema, l'architettura deve supportare un tempo di commutazione pari a zero (o quasi zero) tra i modelli, per supportare meglio le applicazioni multi-modello di cui abbiamo discusso in precedenza. Un altro fattore che determina sia il miglioramento delle prestazioni che della latenza riguarda la flessibilità algoritmica. In altre parole, alcune architetture sono progettate per un comportamento ottimale solo su specifici modelli di intelligenza artificiale, ma con l’ambiente di intelligenza artificiale in rapida evoluzione, nuovi modelli per prestazioni più elevate e migliore precisione appaiono a giorni alterni. Pertanto, seleziona un processore AI edge senza restrizioni pratiche sulla topologia del modello, sugli operatori e sulle dimensioni.
Ci sono molti fattori da considerare per massimizzare le prestazioni in un dispositivo IA edge, inclusi i requisiti di prestazioni e latenza e il sovraccarico del sistema. Una strategia di successo dovrebbe prendere in considerazione un acceleratore AI esterno per superare i limiti di memoria e prestazioni nel motore AI del SoC.
CH Chee è un esperto dirigente di marketing e gestione dei prodotti, Chee ha una vasta esperienza nella promozione di prodotti e soluzioni nel settore dei semiconduttori, concentrandosi su intelligenza artificiale basata sulla visione, connettività e interfacce video per più mercati, tra cui quello aziendale e quello consumer. In qualità di imprenditore, Chee ha co-fondato due start-up di semiconduttori video che sono state acquisite da una società pubblica di semiconduttori. Chee ha guidato i team di marketing del prodotto e ama lavorare con un piccolo team che si concentra sul raggiungimento di grandi risultati.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :ha
- :È
- :non
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- capacità
- acceleratore
- acceleratori
- accesso
- Accedendo
- ospitare
- realizzare
- precisione
- il raggiungimento
- acquisito
- Acquisisce
- operanti in
- Action
- attivo
- presenti
- l'aggiunta di
- aggiuntivo
- adottato
- Avanzate
- Dopo shavasana, sedersi in silenzio; saluti;
- ancora
- AI
- motore di intelligenza artificiale
- Modelli AI
- algoritmica
- Algoritmi
- Tutti
- anche
- sempre
- an
- .
- analitica
- l'analisi
- ed
- rilevamento anomalie
- Un altro
- Applicazioni
- applicazioni
- approccio
- architettura
- SONO
- AS
- associato
- At
- automatizzare
- Automazione
- autonomo
- autonomamente
- disponibilità
- disponibile
- evitare
- basato
- base
- BE
- perché
- diventa
- stato
- prima
- essendo
- Segno di riferimento
- Meglio
- fra
- entrambi
- Scatola
- scatole
- incassato
- autobus
- occupato
- ma
- by
- stanza
- telecamere
- Materiale
- funzionalità
- capacità
- catturare
- catturato
- Catturare
- attento
- Custodie
- casi
- Challenge
- cambiando
- patata fritta
- Chips
- la scelta
- classe
- Cloud
- colore
- arrivo
- azienda
- competitivo
- Completato
- componenti
- compromettendo
- calcolo
- computazionale
- Calcolare
- computer
- Visione computerizzata
- Applicazioni di visione artificiale
- fiducia
- Configurazione
- Connettività
- conseguentemente
- Prendere in considerazione
- considerazione
- considerato
- considerando
- consiste
- vincoli
- Consumer
- contenere
- contenute
- continuo
- continuamente
- Conversione
- potuto
- CPU
- critico
- cliente
- dati
- elaborazione dati
- giorno
- dedicato
- ritardo
- ritardi
- consegnare
- consegnato
- dipendente
- Dipendente
- schierato
- implementazioni
- descritta
- progettato
- rilevato
- rivelazione
- Determinare
- sviluppatori
- dispositivi
- differenza
- direttamente
- discusso
- Dsiplay
- i tempi di inattività
- guida
- dovuto
- dinamicamente
- e
- ogni
- In precedenza
- facilmente
- bordo
- effetto
- efficacia
- efficienze
- efficienza
- efficiente
- o
- incorporamento
- fine
- da un capo all'altro
- motore
- Motori
- accrescere
- garantire
- Impresa
- Intero
- Imprenditore
- Ambiente
- essential
- stimato
- valutare
- Anche
- Ogni
- evoluzione
- esempio
- superare
- eseguire
- eseguito
- esecutivo
- attenderti
- esperienza
- Esperienze
- estensivo
- Conclamata Esperienza
- esterno
- Faccia
- riconoscimento facciale
- fattore
- Fattori
- fabbrica
- FAST
- caratteristica
- alimentazione
- campo
- figura
- impronta
- Nome
- Flessibilità
- si concentra
- messa a fuoco
- Nel
- formato
- TELAIO
- da
- function
- funzionalità
- funzioni
- Inoltre
- futuro
- guadagnando
- Giochi
- gaming
- esperienza di gioco
- Generale
- generare
- generato
- generoso
- Go
- GPU
- GPU
- grande
- maggiore
- Crescita
- Crescita
- guida
- Hardware
- Avere
- quindi
- qui
- gerarchia
- Alta
- superiore
- host
- HTTPS
- i
- identificare
- if
- Immagine
- Impact
- importante
- imposto
- competenze
- migliorata
- in
- In altre
- inclusi
- Compreso
- Aumento
- è aumentato
- industrie
- industria
- iniziati
- ingresso
- interno
- intuizioni
- integrato
- Intel
- Interfaccia
- interfacce
- ai miglioramenti
- coinvolgere
- comporta
- indipendentemente
- ISP
- IT
- SUO
- KDnuggets
- per il tuo brand
- Dipingere
- Corsia
- grandi
- Latenza
- partenza
- Guidato
- meno
- livelli
- biblioteche
- piace
- limitazione
- limiti
- Limitato
- locale
- perso
- Basso
- inferiore
- gestire
- gestione
- consigliato per la
- molti
- Marketing
- Mercati
- Massimizzare
- massimizzando
- Maggio..
- significare
- analisi
- Soddisfare
- Memorie
- menzionato
- forza
- perse
- modello
- modelli
- modulo
- monitoraggio
- Scopri di più
- maggior parte
- movimento
- movimento
- multiplo
- devono obbligatoriamente:
- miriade
- Vicino
- esigenze
- Rete
- Neurale
- rete neurale
- New
- GENERAZIONE
- no
- oggetto
- Rilevazione dell'oggetto
- verificarsi
- of
- di frequente
- on
- una volta
- ONE
- esclusivamente
- OpenCV
- operazione
- operativa
- Operatori
- opposto
- ottimale
- ottimizzazione
- OTTIMIZZA
- ottimizzati
- ottimizzazione
- or
- Altro
- su
- produzione
- ancora
- complessivo
- Superare
- Parallel
- parametri
- particolarmente
- per
- eseguire
- performance
- eseguita
- esecuzione
- esegue
- conduttura
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- Giocare
- punto
- posizione
- post produzione
- Pratico
- predizione
- processi
- elaborati
- lavorazione
- Processore
- processori
- Prodotto
- Produzione
- Prodotti
- promuovere
- fornire
- la percezione
- gamma
- che vanno
- veloce
- rapidamente
- tasso
- Crudo
- dati grezzi
- di rose
- tempo reale
- Realtà
- riconoscimento
- ridurre
- si riferisce
- richiedere
- necessario
- requisito
- Requisiti
- richiede
- Risoluzione
- Risorse
- di risposta
- restrizioni
- colpevole
- Risultati
- robotica
- Ruolo
- Correre
- running
- corre
- Sicurezza
- stesso
- Scalabilità
- Scala
- scala ai
- scala
- scena
- punteggi
- senza soluzione di continuità
- Secondo
- Sezione
- vedere
- sembra
- Selezione
- semiconduttore
- set
- Condividi
- condiviso
- Shopping
- dovrebbero
- mostrato
- segno
- Signal
- Allo stesso modo
- da
- singolo
- Taglia
- piccole
- smart
- soluzione
- Soluzioni
- RISOLVERE
- risolve
- alcuni
- qualcosa
- lo spazio
- specifico
- start-up
- Passi
- Tornare al suo account
- strategie
- Strategia
- ruscello
- flussi
- di successo
- tale
- sufficiente
- supporto
- repressione
- sorveglianza
- sistema
- SISTEMI DI TRATTAMENTO
- Fai
- prende
- task
- team
- le squadre
- Tecnologie
- Tecnologia
- condizioni
- di
- che
- Il
- Il futuro
- loro
- poi
- Là.
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- quelli
- tre
- Attraverso
- portata
- tempo
- volte
- a
- Tops, Cardigan & Pullover
- Totale
- pista
- Tracking
- traffico
- trasferimento
- trasferimenti
- Trasformare
- viaggiare
- vero
- seconda
- tipicamente
- in definitiva
- incapace
- capire
- unità
- unità
- Impiego
- usb
- uso
- utilizzato
- usa
- utilizzando
- generalmente
- Utilizzando
- Valori
- varietà
- vario
- Video
- Visualizza
- virtuale
- La realtà virtuale
- visione
- importantissima
- vr
- Modo..
- we
- sono stati
- Che
- se
- quale
- ampiamente
- volere
- con
- senza
- parole
- lavoro
- sarebbe
- X
- dare la precedenza
- Yolo
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- zero







