By David Wendt ed Gregorio Kimball
L'elaborazione efficiente dei dati delle stringhe è vitale per molte applicazioni di data science. Per estrarre informazioni preziose dai dati delle stringhe, RAPIDSlibcudf fornisce potenti strumenti per accelerare le trasformazioni dei dati delle stringhe. libcudf è una libreria DataFrame GPU C++ utilizzata per caricare, unire, aggregare e filtrare i dati.
Nella scienza dei dati, i dati delle stringhe rappresentano il parlato, il testo, le sequenze genetiche, la registrazione e molti altri tipi di informazioni. Quando si lavora con i dati delle stringhe per l'apprendimento automatico e la progettazione delle funzionalità, i dati devono essere spesso normalizzati e trasformati prima di poter essere applicati a casi d'uso specifici. libcudf fornisce sia API generiche che utilità lato dispositivo per abilitare un'ampia gamma di operazioni di stringhe personalizzate.
Questo post mostra come trasformare abilmente le colonne di stringhe con l'API generica libcudf. Acquisirai nuove conoscenze su come sbloccare le massime prestazioni utilizzando kernel personalizzati e utilità lato dispositivo libcudf. Questo post ti guida anche attraverso esempi su come gestire al meglio la memoria della GPU e costruire in modo efficiente colonne libcudf per accelerare le trasformazioni delle stringhe.
libcudf memorizza i dati delle stringhe nella memoria del dispositivo utilizzando Formato freccia, che rappresenta le colonne delle stringhe come due colonne figlie: chars and offsets (Figura 1).
I chars La colonna contiene i dati della stringa come byte di caratteri con codifica UTF-8 archiviati in modo contiguo nella memoria.
I offsets La colonna contiene una sequenza crescente di numeri interi che sono posizioni di byte che identificano l'inizio di ogni singola stringa all'interno dell'array di dati chars. L'ultimo elemento offset è il numero totale di byte nella colonna chars. Ciò significa la dimensione di una singola stringa alla riga i è definito come (offsets[i+1]-offsets[i]).
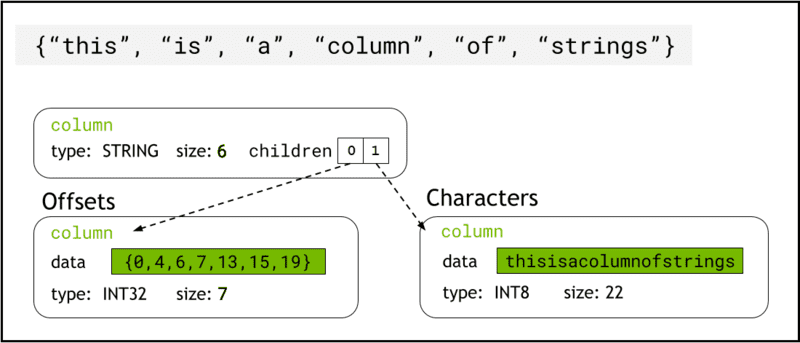 Figura 1. Schema che mostra come il formato freccia rappresenta le colonne di stringhe con
Figura 1. Schema che mostra come il formato freccia rappresenta le colonne di stringhe con chars ed offsets colonne figlie
Per illustrare un esempio di trasformazione di stringhe, si consideri una funzione che riceve due colonne di stringhe di input e produce una colonna di stringhe di output oscurate.
I dati di input hanno la seguente forma: una colonna “nomi” contenente nomi e cognomi separati da uno spazio e una colonna “visibilità” contenente lo stato di “pubblico” o “privato”.
Proponiamo la funzione “redact” che opera sui dati di input per produrre dati di output costituiti dall'iniziale del cognome seguita da uno spazio e dal nome intero. Tuttavia, se la colonna di visibilità corrispondente è "privata", la stringa di output deve essere completamente redatta come "X X".
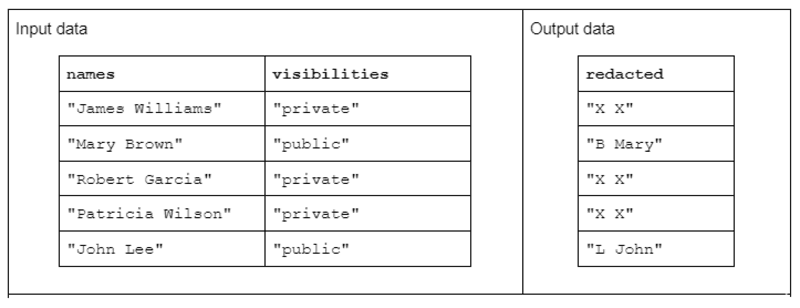 Tabella 1. Esempio di una trasformazione di stringhe di "redazione" che riceve colonne di stringhe di nomi e visibilità come input e dati parzialmente o completamente oscurati come output
Tabella 1. Esempio di una trasformazione di stringhe di "redazione" che riceve colonne di stringhe di nomi e visibilità come input e dati parzialmente o completamente oscurati come output
Innanzitutto, la trasformazione delle stringhe può essere eseguita utilizzando il file API delle stringhe libcudf. L'API per uso generale è un ottimo punto di partenza e una buona base per confrontare le prestazioni.
Le funzioni API operano su un'intera colonna di stringhe, avviando almeno un kernel per funzione e assegnando un thread per stringa. Ogni thread gestisce una singola riga di dati in parallelo attraverso la GPU e restituisce una singola riga come parte di una nuova colonna di output.
Per completare la funzione di esempio redact utilizzando l'API generica, procedi nel seguente modo:
- Converti la colonna delle stringhe "visibilità" in una colonna booleana usando
contains - Crea una nuova colonna di stringhe dalla colonna dei nomi copiando "XX" ogni volta che la voce di riga corrispondente nella colonna booleana è "falsa"
- Dividi la colonna "redatta" nelle colonne del nome e del cognome
- Taglia il primo carattere dei cognomi come iniziali del cognome
- Costruisci la colonna di output concatenando la colonna delle iniziali dell'ultimo e la colonna dei nomi con il separatore spazio (" ").
// convert the visibility label into a boolean
auto const visible = cudf::string_scalar(std::string("public"));
auto const allowed = cudf::strings::contains(visibilities, visible); // redact names auto const redaction = cudf::string_scalar(std::string("X X"));
auto const redacted = cudf::copy_if_else(names, redaction, allowed->view()); // split the first name and last initial into two columns
auto const sv = cudf::strings_column_view(redacted->view())
auto const first_last = cudf::strings::split(sv);
auto const first = first_last->view().column(0);
auto const last = first_last->view().column(1);
auto const last_initial = cudf::strings::slice_strings(last, 0, 1); // assemble a result column
auto const tv = cudf::table_view({last_initial->view(), first});
auto result = cudf::strings::concatenate(tv, std::string(" "));
Questo approccio richiede circa 3.5 ms su un A6000 con 600 righe di dati. Questo esempio usa contains, copy_if_else, split, slice_strings ed concatenate per eseguire una trasformazione di stringa personalizzata. Un'analisi di profilazione con Sistemi di visione mostra che la split la funzione richiede il tempo più lungo, seguita da slice_strings ed concatenate.
La Figura 2 mostra i dati di profilazione di Nsight Systems dell'esempio redact, mostrando l'elaborazione di stringhe end-to-end fino a ~600 milioni di elementi al secondo. Le regioni corrispondono agli intervalli NVTX associati a ciascuna funzione. Gli intervalli azzurri corrispondono ai periodi in cui i kernel CUDA sono in esecuzione.
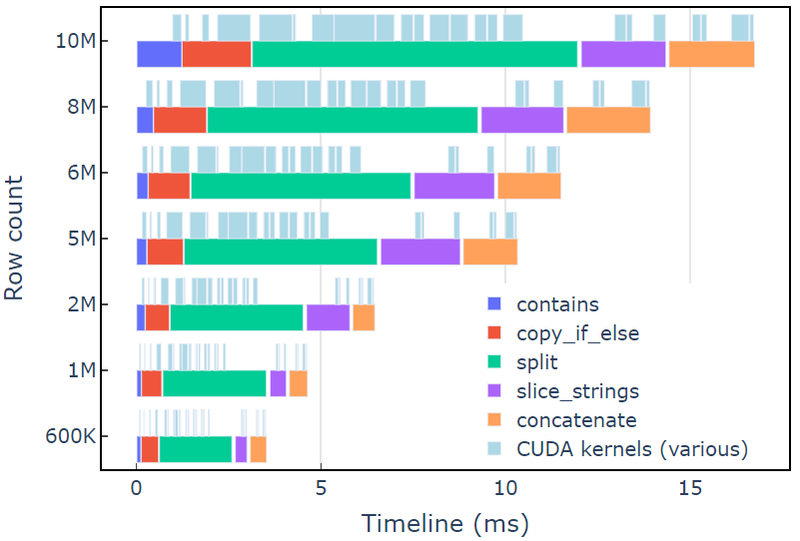 Figura 2. Profiling dei dati da Nsight Systems dell'esempio redact
Figura 2. Profiling dei dati da Nsight Systems dell'esempio redact
L'API delle stringhe libcudf è un toolkit veloce ed efficiente per trasformare le stringhe, ma a volte le funzioni critiche per le prestazioni devono essere eseguite ancora più velocemente. Una fonte chiave di lavoro extra nell'API delle stringhe libcudf è la creazione di almeno una nuova colonna di stringhe nella memoria globale del dispositivo per ogni chiamata API, aprendo l'opportunità di combinare più chiamate API in un kernel personalizzato.
Limitazioni delle prestazioni nelle chiamate malloc del kernel
Innanzitutto, creeremo un kernel personalizzato per implementare la trasformazione dell'esempio redact. Durante la progettazione di questo kernel, dobbiamo tenere presente che le colonne delle stringhe libcudf sono immutabili.
Le colonne delle stringhe non possono essere modificate sul posto perché i byte dei caratteri vengono archiviati in modo contiguo e qualsiasi modifica alla lunghezza di una stringa invaliderebbe i dati di offset. Quindi, il redact_kernel il kernel personalizzato genera una nuova colonna di stringhe utilizzando una factory di colonne libcudf per creare entrambe offsets ed chars colonne figlie.
In questo primo approccio, viene creata la stringa di output per ogni riga memoria dinamica del dispositivo usando una chiamata malloc all'interno del kernel. L'output del kernel personalizzato è un vettore di puntatori di dispositivo a ciascun output di riga e questo vettore funge da input per una factory di colonne di stringhe.
Il kernel personalizzato accetta a cudf::column_device_view per accedere ai dati della colonna delle stringhe e usa il file element metodo per restituire a cudf::string_view che rappresenta i dati della stringa in corrispondenza dell'indice di riga specificato. L'output del kernel è un vettore di tipo cudf::string_view che contiene i puntatori alla memoria del dispositivo contenente la stringa di output e la dimensione di tale stringa in byte.
I cudf::string_view class è simile alla classe std::string_view ma è implementata in modo specifico per libcudf e avvolge una lunghezza fissa di dati carattere nella memoria del dispositivo codificata come UTF-8. Ha molte delle stesse caratteristiche (find ed substr funzioni, ad esempio) e limitazioni (nessun terminatore nullo) come il std controparte. UN cudf::string_view rappresenta una sequenza di caratteri archiviata nella memoria del dispositivo e quindi possiamo usarla qui per registrare la memoria malloc per un vettore di output.
Kernel di Malloc
// note the column_device_view inputs to the kernel __global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, cudf::string_view* d_output)
{ // get index for this thread auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; char* output_ptr = static_cast(malloc(output_size)); // build output string d_output[index] = cudf::string_view{output_ptr, output_size}; memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
} __global__ void free_kernel(cudf::string_view redaction, cudf::string_view* d_output, int count)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= count) return; auto ptr = const_cast(d_output[index].data()); if (ptr != redaction.data()) free(ptr); // free everything that does match the redaction string
}
Questo potrebbe sembrare un approccio ragionevole, fino a quando non vengono misurate le prestazioni del kernel. Questo approccio richiede circa 108 ms su un A6000 con 600 righe di dati, più di 30 volte più lento della soluzione fornita in precedenza utilizzando l'API delle stringhe libcudf.
redact_kernel 60.3ms
free_kernel 45.5ms
make_strings_column 0.5ms
Il principale collo di bottiglia è il malloc/free chiamate all'interno dei due kernel qui. La memoria del dispositivo dinamico CUDA richiede malloc/free chiama un kernel per essere sincronizzato, causando la degenerazione dell'esecuzione parallela in esecuzione sequenziale.
Pre-allocazione della memoria di lavoro per eliminare i colli di bottiglia
Elimina il malloc/free collo di bottiglia sostituendo il malloc/free chiama il kernel con memoria di lavoro pre-allocata prima di avviare il kernel.
Per l'esempio redact, la dimensione di output di ciascuna stringa in questo esempio non dovrebbe essere maggiore della stringa di input stessa, poiché la logica rimuove solo i caratteri. Pertanto, è possibile utilizzare un singolo buffer di memoria del dispositivo con le stesse dimensioni del buffer di input. Utilizzare gli offset di input per individuare ogni posizione di riga.
L'accesso agli offset della colonna delle stringhe comporta il wrapping del file cudf::column_view con una cudf::strings_column_view e chiamandola offsets_begin metodo. La dimensione del chars è possibile accedere alla colonna figlio anche utilizzando il file chars_size metodo. Poi un rmm::device_uvector è pre-allocato prima di chiamare il kernel per memorizzare i dati di output dei caratteri.
auto const scv = cudf::strings_column_view(names);
auto const offsets = scv.offsets_begin();
auto working_memory = rmm::device_uvector(scv.chars_size(), stream);Kernel preallocato
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::string_view redaction, char* working_memory, cudf::offset_type const* d_offsets, cudf::string_view* d_output)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // resolve output string location char* output_ptr = working_memory + d_offsets[index]; d_output[index] = cudf::string_view{output_ptr, output_size}; // build output string into output_ptr memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { d_output[index] = cudf::string_view{redaction.data(), redaction.size_bytes()}; }
}
Il kernel emette un vettore di cudf::string_view oggetti che viene passato al cudf::make_strings_column funzione di fabbrica. Il secondo parametro di questa funzione viene utilizzato per identificare voci nulle nella colonna di output. Gli esempi in questo post non hanno voci nulle, quindi un segnaposto nullptr cudf::string_view{nullptr,0} viene utilizzato.
auto str_ptrs = rmm::device_uvector(names.size(), stream); redact_kernel>>(*d_names, *d_visibilities, d_redaction.value(), working_memory.data(), offsets, str_ptrs.data()); auto result = cudf::make_strings_column(str_ptrs, cudf::string_view{nullptr,0}, stream);
Questo approccio richiede circa 1.1 ms su un A6000 con 600 righe di dati e quindi supera la linea di base di oltre 2 volte. La ripartizione approssimativa è mostrata di seguito:
redact_kernel 66us make_strings_column 400us
Il tempo rimanente è trascorso in cudaMalloc, cudaFree, cudaMemcpy, che è tipico dell'overhead per la gestione delle istanze temporanee di rmm::device_uvector. Questo metodo funziona bene se è garantito che tutte le stringhe di output abbiano la stessa dimensione o meno delle stringhe di input.
Nel complesso, il passaggio a un'allocazione di massa della memoria di lavoro con RAPIDS RMM è un miglioramento significativo e una buona soluzione per una funzione di stringhe personalizzate.
Ottimizzazione della creazione di colonne per tempi di calcolo più rapidi
C'è un modo per migliorare ulteriormente questo aspetto? Il collo di bottiglia è ora il cudf::make_strings_column funzione factory che costruisce i due componenti della colonna di stringhe, offsets ed chars, dal vettore di cudf::string_view oggetti.
In libcudf sono incluse molte funzioni factory per la creazione di colonne di stringhe. La funzione factory utilizzata negli esempi precedenti accetta a cudf::device_span of cudf::string_view oggetti e quindi costruisce la colonna eseguendo a gather sui dati carattere sottostanti per creare gli offset e le colonne figlio carattere. UN rmm::device_uvector è automaticamente convertibile in a cudf::device_span senza copiare alcun dato.
Tuttavia, se il vettore di caratteri e il vettore di offset vengono costruiti direttamente, è possibile utilizzare una funzione factory diversa, che crea semplicemente la colonna delle stringhe senza richiedere una raccolta per copiare i dati.
I sizes_kernel esegue un primo passaggio sui dati di input per calcolare l'esatta dimensione di output di ciascuna riga di output:
Kernel ottimizzato: parte 1
__global__ void sizes_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type* d_sizes)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); cudf::size_type result = redaction.size_bytes(); // init to redaction size if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); result = first.size_bytes() + last_initial.size_bytes() + 1; } d_sizes[index] = result;
}
Le dimensioni dell'output vengono quindi convertite in offset eseguendo un'operazione sul posto exclusive_scan. Si noti che il offsets vettore è stato creato con names.size()+1 elementi. L'ultima voce sarà il numero totale di byte (tutte le dimensioni sommate insieme) mentre la prima voce sarà 0. Entrambi sono gestiti dal exclusive_scan chiamata. La dimensione del chars la colonna viene recuperata dall'ultima voce del file offsets colonna per costruire il vettore di caratteri.
// create offsets vector
auto offsets = rmm::device_uvector(names.size() + 1, stream); // compute output sizes
sizes_kernel>>( *d_names, *d_visibilities, offsets.data()); thrust::exclusive_scan(rmm::exec_policy(stream), offsets.begin(), offsets.end(), offsets.begin());
I redact_kernel la logica è ancora praticamente la stessa, tranne per il fatto che accetta l'output d_offsets vettore per risolvere la posizione di output di ogni riga:
Kernel ottimizzato: parte 2
__global__ void redact_kernel(cudf::column_device_view const d_names, cudf::column_device_view const d_visibilities, cudf::size_type const* d_offsets, char* d_chars)
{ auto index = threadIdx.x + blockIdx.x * blockDim.x; if (index >= d_names.size()) return; auto const visible = cudf::string_view("public", 6); auto const redaction = cudf::string_view("X X", 3); // resolve output_ptr using the offsets vector char* output_ptr = d_chars + d_offsets[index]; auto const name = d_names.element(index); auto const vis = d_visibilities.element(index); if (vis == visible) { auto const space_idx = name.find(' '); auto const first = name.substr(0, space_idx); auto const last_initial = name.substr(space_idx + 1, 1); auto const output_size = first.size_bytes() + last_initial.size_bytes() + 1; // build output string memcpy(output_ptr, last_initial.data(), last_initial.size_bytes()); output_ptr += last_initial.size_bytes(); *output_ptr++ = ' '; memcpy(output_ptr, first.data(), first.size_bytes()); } else { memcpy(output_ptr, redaction.data(), redaction.size_bytes()); }
}
La dimensione dell'output d_chars la colonna viene recuperata dall'ultima voce del file d_offsets colonna per allocare il vettore di caratteri. Il kernel si avvia con il vettore di offset precalcolato e restituisce il vettore di caratteri popolati. Infine, il factory di colonne di stringhe libcudf crea le colonne di stringhe di output.
La sezione cudf::make_strings_column La funzione factory crea la colonna delle stringhe senza fare una copia dei dati. Il offsets dati e chars i dati sono già nel formato corretto e previsto e questa fabbrica sposta semplicemente i dati da ciascun vettore e crea la struttura a colonne attorno ad esso. Una volta completato, il rmm::device_uvectors per offsets ed chars sono vuoti, i loro dati sono stati spostati nella colonna di output.
cudf::size_type output_size = offsets.back_element(stream);
auto chars = rmm::device_uvector(output_size, stream); redact_kernel>>( *d_names, *d_visibilities, offsets.data(), chars.data()); // from pre-assembled offsets and character buffers
auto result = cudf::make_strings_column(names.size(), std::move(offsets), std::move(chars));
Questo approccio impiega circa 300 us (0.3 ms) su un A6000 con 600 righe di dati e migliora rispetto all'approccio precedente di oltre il doppio. Potresti notarlo sizes_kernel ed redact_kernel condividono gran parte della stessa logica: una volta per misurare la dimensione dell'output e poi di nuovo per popolare l'output.
Dal punto di vista della qualità del codice, è vantaggioso eseguire il refactoring della trasformazione come una funzione del dispositivo chiamata sia dalle dimensioni che dai kernel redatti. Dal punto di vista delle prestazioni, potresti essere sorpreso di vedere che il costo computazionale della trasformazione viene pagato due volte.
I vantaggi per la gestione della memoria e la creazione di colonne più efficiente spesso superano il costo di calcolo dell'esecuzione della trasformazione due volte.
La tabella 2 mostra il tempo di calcolo, il conteggio del kernel e i byte elaborati per le quattro soluzioni discusse in questo post. "Lanci totali del kernel" riflette il numero totale di kernel lanciati, inclusi i kernel di calcolo e di supporto. "Byte totali elaborati" è il throughput cumulativo di lettura e scrittura della DRAM e "byte minimi elaborati" è una media di 37.9 byte per riga per i nostri input e output di test. Il caso ideale di "larghezza di banda della memoria limitata" presuppone una larghezza di banda di 768 GB/s, il throughput di picco teorico dell'A6000.
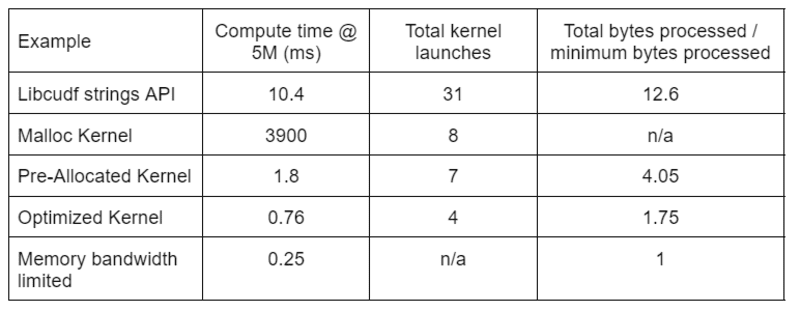 Tabella 2. Tempo di calcolo, conteggio del kernel e byte elaborati per le quattro soluzioni discusse in questo post
Tabella 2. Tempo di calcolo, conteggio del kernel e byte elaborati per le quattro soluzioni discusse in questo post
Il "kernel ottimizzato" fornisce il throughput più elevato grazie al numero ridotto di avvii del kernel e al minor numero di byte totali elaborati. Con kernel personalizzati efficienti, i lanci totali del kernel scendono da 31 a 4 e i byte totali elaborati da 12.6x a 1.75x della dimensione di input più output.
Di conseguenza, il kernel personalizzato raggiunge un throughput >10 volte superiore rispetto all'API delle stringhe per uso generico per la trasformazione redact.
La risorsa di memoria del pool in Gestore memoria RAPIDS (RMM) è un altro strumento che puoi utilizzare per aumentare le prestazioni. Gli esempi precedenti utilizzano la "risorsa di memoria CUDA" predefinita per allocare e liberare la memoria globale del dispositivo. Tuttavia, il tempo necessario per allocare la memoria di lavoro aggiunge una latenza significativa tra i passaggi delle trasformazioni delle stringhe. La "risorsa di memoria del pool" in RMM riduce la latenza allocando un ampio pool di memoria in anticipo e assegnando sottoallocazioni secondo necessità durante l'elaborazione.
Con la risorsa di memoria CUDA, "Kernel ottimizzato" mostra un aumento della velocità di 10x-15x che inizia a diminuire con un numero di righe più elevato a causa dell'aumento delle dimensioni di allocazione (Figura 3). L'utilizzo della risorsa di memoria del pool mitiga questo effetto e mantiene accelerazioni di 15x-25x rispetto all'approccio API delle stringhe libcudf.
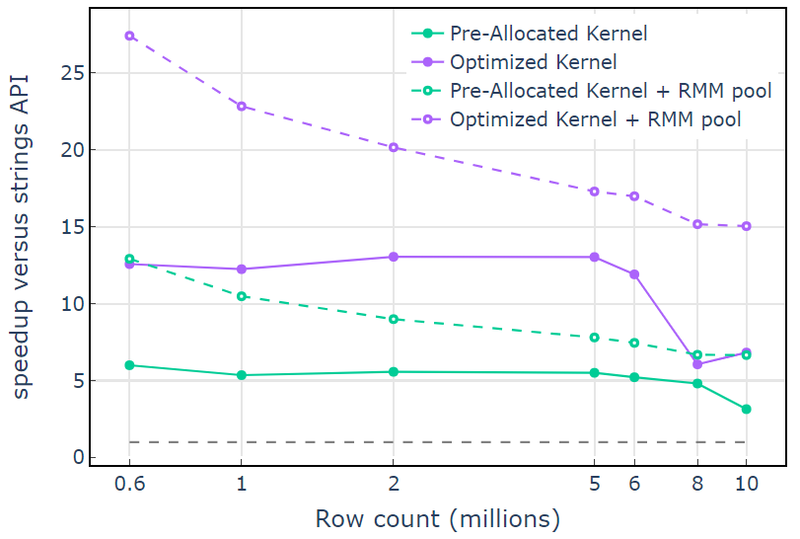 Figura 3. Accelerazione dai kernel personalizzati "Kernel pre-allocato" e "Kernel ottimizzato" con la risorsa di memoria CUDA predefinita (solida) e la risorsa di memoria del pool (tratteggiata), rispetto all'API della stringa libcudf che utilizza la risorsa di memoria CUDA predefinita
Figura 3. Accelerazione dai kernel personalizzati "Kernel pre-allocato" e "Kernel ottimizzato" con la risorsa di memoria CUDA predefinita (solida) e la risorsa di memoria del pool (tratteggiata), rispetto all'API della stringa libcudf che utilizza la risorsa di memoria CUDA predefinita
Con la risorsa di memoria del pool, viene dimostrato un throughput di memoria end-to-end che si avvicina al limite teorico per un algoritmo a due passaggi. Il "kernel ottimizzato" raggiunge un throughput di 320-340 GB/s, misurato utilizzando la dimensione degli input più la dimensione degli output e il tempo di elaborazione (Figura 4).
L'approccio a due passaggi misura innanzitutto le dimensioni degli elementi di output, alloca la memoria e quindi imposta la memoria con gli output. Dato un algoritmo di elaborazione a due passaggi, l'implementazione in "Kernel ottimizzato" si avvicina al limite della larghezza di banda della memoria. Il "throughput di memoria end-to-end" è definito come la dimensione di input più output in GB divisa per il tempo di calcolo. *Larghezza di banda della memoria RTX A6000 (768 GB/s).
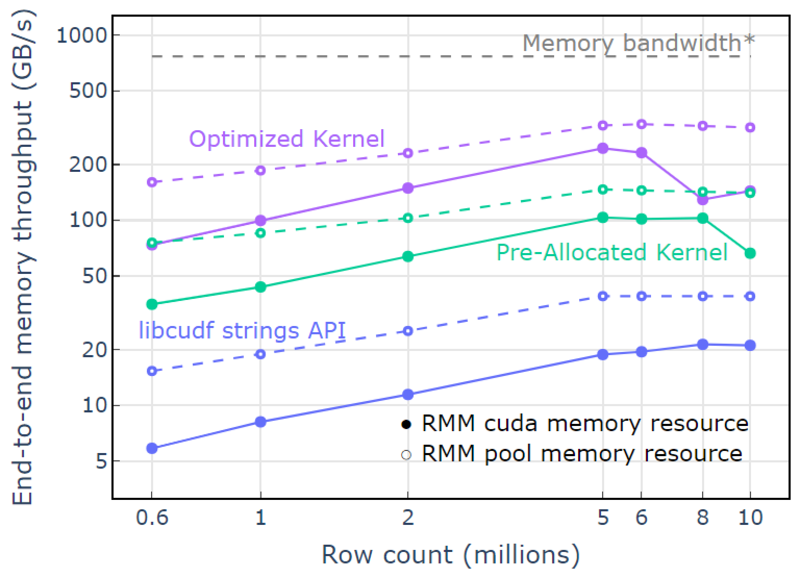 Figura 4. Throughput di memoria per "Kernel ottimizzato", "Kernel pre-allocato" e "API stringhe libcudf" in funzione del conteggio delle righe di input/output
Figura 4. Throughput di memoria per "Kernel ottimizzato", "Kernel pre-allocato" e "API stringhe libcudf" in funzione del conteggio delle righe di input/output
Questo post mostra due approcci per scrivere trasformazioni di dati di stringhe efficienti in libcudf. L'API generica libcudf è veloce e semplice per gli sviluppatori e offre buone prestazioni. libcudf fornisce anche utilità lato dispositivo progettate per l'uso con kernel personalizzati, in questo esempio sbloccando prestazioni >10 volte più veloci.
Applica le tue conoscenze
Per iniziare con RAPIDS cuDF, visita il rapidsai/cudf Repository GitHub. Se non hai ancora provato cuDF e libcudf per i tuoi carichi di lavoro di elaborazione delle stringhe, ti invitiamo a testare l'ultima versione. Contenitori Docker sono forniti per i rilasci e per le build notturne. Conda pacchetti sono disponibili anche per semplificare il test e la distribuzione. Se stai già utilizzando cuDF, ti invitiamo a eseguire il nuovo esempio di trasformazione delle stringhe visitando rapidsai/cudf/tree/HEAD/cpp/examples/strings su GitHub.
David Wendt è un ingegnere software di sistemi senior presso NVIDIA che sviluppa codice C++/CUDA per RAPIDS. David ha conseguito un master in ingegneria elettrica presso la Johns Hopkins University.
Gregorio Kimball è un responsabile dell'ingegneria del software presso NVIDIA che lavora nel team RAPIDS. Gregory guida lo sviluppo di libcudf, la libreria CUDA/C++ per l'elaborazione di dati a colonne che alimenta RAPIDS cuDF. Gregory ha conseguito un dottorato di ricerca in fisica applicata presso il California Institute of Technology.
Originale. Ripubblicato con il permesso.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/01/mastering-string-transformations-rapids-libcudf.html?utm_source=rss&utm_medium=rss&utm_campaign=mastering-string-transformations-in-rapids-libcudf
- 1
- 7
- 9
- a
- Chi siamo
- sopra
- accelerando
- accetta
- accesso
- accessibile
- compiuto
- operanti in
- aggiunto
- Aggiunge
- algoritmo
- Tutti
- alloca
- assegnazione
- già
- quantità
- .
- ed
- Un altro
- Apache
- api
- API
- applicazioni
- applicato
- approccio
- approcci
- si avvicina
- in giro
- Italia
- associato
- auto
- automaticamente
- disponibile
- media
- Larghezza di banda
- Linea di base
- perché
- prima
- essendo
- sotto
- benefico
- vantaggi
- MIGLIORE
- fra
- Blu
- Guasto
- bufferizzare
- costruire
- Costruzione
- costruisce
- costruito
- C++
- California
- chiamata
- detto
- chiamata
- Bandi
- non può
- Custodie
- casi
- causando
- Modifiche
- carattere
- caratteri
- bambino
- classe
- Chiudi
- codice
- Colonna
- colonne
- combinare
- confronto
- completamento di una
- Completato
- componenti
- calcolo
- Calcolare
- Prendere in considerazione
- Consistente
- costruire
- contiene
- convertire
- convertito
- copiatura
- Corrispondente
- Costo
- creare
- creato
- crea
- creazione
- costume
- dati
- elaborazione dati
- scienza dei dati
- David
- Predefinito
- Laurea
- fornisce un monitoraggio
- dimostrato
- deployment
- progettato
- progettazione
- sviluppatori
- in via di sviluppo
- Mercato
- dispositivo
- diverso
- direttamente
- discusso
- Diviso
- docker
- Cadere
- durante
- dinamico
- ogni
- più facile
- effetto
- efficiente
- in modo efficiente
- Ingegneria Elettrica
- elementi
- eliminato
- enable
- incoraggiare
- da un capo all'altro
- ingegnere
- Ingegneria
- Intero
- iscrizione
- Etere (ETH)
- Anche
- qualunque cosa
- esempio
- Esempi
- eccellente
- Tranne
- esecuzione
- previsto
- esterno
- extra
- estratto
- fabbrica
- FAST
- più veloce
- caratteristica
- Caratteristiche
- figura
- filtraggio
- finale
- Infine
- Nome
- fisso
- seguire
- seguito
- i seguenti
- modulo
- formato
- Gratis
- frequentemente
- da
- anteriore
- completamente
- function
- funzioni
- ulteriormente
- Guadagno
- Generale
- genera
- ottenere
- GitHub
- dato
- globali
- buono
- GPU
- garantito
- Maniglie
- avendo
- qui
- superiore
- massimo
- detiene
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- ideale
- identificazione
- immutabile
- realizzare
- implementazione
- implementato
- competenze
- miglioramento
- migliora
- in
- incluso
- Compreso
- Aumento
- crescente
- Index
- individuale
- informazioni
- inizialmente
- ingresso
- Istituto
- interno
- IT
- stessa
- Johns Hopkins
- Johns Hopkins University
- accoppiamento
- KDnuggets
- mantenere
- Le
- conoscenze
- Discografica
- grandi
- superiore, se assunto singolarmente.
- Cognome
- Latenza
- con i più recenti
- ultima uscita
- lanciato
- lancia
- lancio
- Leads
- apprendimento
- Lunghezza
- Biblioteca
- leggera
- LIMITE
- limiti
- Caricamento in corso
- località
- macchina
- machine learning
- Principale
- mantiene
- make
- FA
- Fare
- gestire
- gestione
- direttore
- gestione
- molti
- Mastercard
- La padronanza della
- partita
- si intende
- misurare
- analisi
- Memorie
- metodo
- forza
- milione
- mente
- Scopri di più
- più efficiente
- si muove
- MS
- multiplo
- Nome
- nomi
- Bisogno
- di applicazione
- New
- numero
- Nvidia
- oggetti
- offset
- ONE
- apertura
- operare
- opera
- Operazioni
- Opportunità
- Altro
- pagato
- Parallel
- parametro
- parte
- Passato
- Corrente di
- performance
- esecuzione
- esegue
- periodi
- autorizzazione
- prospettiva
- Fisica
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- più
- punto
- pool
- popolata
- posizione
- posizioni
- Post
- potente
- potenze
- precedente
- lavorazione
- produrre
- profiling
- offre
- purché
- fornisce
- la percezione
- scopo
- qualità
- gamma
- raggiunge
- Leggi
- ragionevole
- riceve
- record
- Ridotto
- riduce
- Refactoring
- riflette
- regioni
- rilasciare
- Uscite
- rimanente
- che rappresenta
- rappresenta
- risorsa
- colpevole
- ritorno
- problemi
- RIGA
- Correre
- running
- stesso
- Scienze
- Secondo
- anziano
- Sequenza
- serve
- Set
- Condividi
- dovrebbero
- mostrato
- Spettacoli
- significativa
- simile
- semplicemente
- da
- singolo
- Taglia
- Dimensioni
- inferiore
- So
- Software
- Software Engineer
- Ingegneria del software
- solido
- soluzione
- Soluzioni
- Fonte
- lo spazio
- specifico
- in particolare
- specificato
- discorso
- velocità
- esaurito
- dividere
- inizia a
- iniziato
- Di partenza
- Stato dei servizi
- Passi
- Ancora
- Tornare al suo account
- memorizzati
- negozi
- lineare
- ruscello
- La struttura
- sorpreso
- SISTEMI DI TRATTAMENTO
- prende
- team
- Tecnologia
- temporaneo
- test
- Testing
- I
- loro
- teorico
- perciò
- Attraverso
- portata
- tempo
- a
- insieme
- toolkit
- strumenti
- Totale
- Trasformare
- Trasformazione
- trasformazioni
- trasformato
- trasformazione
- tv
- Tipi di
- tipico
- sottostante
- Università
- sbloccare
- sblocco
- us
- uso
- utilità
- Prezioso
- Informazione preziosa
- contro
- visibilità
- visibile
- importantissima
- quale
- while
- largo
- Vasta gamma
- volere
- entro
- senza
- Lavora
- lavoro
- lavori
- sarebbe
- scrivere
- scrittura
- X
- Trasferimento da aeroporto a Sharm
- zefiro










