Due recenti tecnologie algoritmiche basate su software – la guida autonoma (ADAS/AD) e l’intelligenza artificiale generativa (GenAI) – tengono sveglia la comunità degli ingegneri dei semiconduttori.
Mentre gli ADAS ai livelli 2 e 3 sono sulla buona strada, gli AD ai livelli 4 e 5 sono lontani dalla realtà, causando un calo dell’entusiasmo e del denaro del capitale di rischio. Oggi, GenAI attira l’attenzione e i VC investono con entusiasmo miliardi di dollari.
Entrambe le tecnologie si basano su algoritmi moderni e complessi. L'elaborazione della loro formazione e inferenza condivide alcuni attributi, alcuni critici, altri importanti ma non essenziali: vedere la tabella I.

Il notevole progresso software in queste tecnologie fino ad ora non è stato replicato dai progressi nell’hardware algoritmico per accelerarne l’esecuzione. Ad esempio, i processori algoritmici all'avanguardia non hanno le prestazioni per rispondere alle query ChatGPT-4 in uno o due secondi al costo di ¢ 2 per query, il punto di riferimento stabilito dalla ricerca di Google, o per elaborare l'enorme quantità di dati raccolti dai sensori AD in meno di 20 millisecondi.
Questo fino a quando la startup francese VSORA non ha investito le sue capacità intellettuali per affrontare il collo di bottiglia della memoria noto come muro della memoria.
Il Muro della Memoria
Il muro di memoria della CPU è stato descritto per la prima volta da Wulf e McKee nel 1994. Da allora, gli accessi alla memoria sono diventati il collo di bottiglia delle prestazioni di elaborazione. I progressi nelle prestazioni dei processori non si sono rispecchiati nei progressi nell’accesso alla memoria, costringendo i processori ad attendere sempre più a lungo i dati forniti dalle memorie. Alla fine, l'efficienza del processore scende ben al di sotto del 100% di utilizzo.
Per risolvere il problema, l'industria dei semiconduttori ha creato una struttura di memoria gerarchica multilivello con più livelli di cache più vicini al processore che riduce la quantità di traffico con le memorie principali ed esterne più lente.
Le prestazioni dei processori AD e GenAI dipendono più di altri tipi di dispositivi informatici dall'ampia larghezza di banda della memoria.
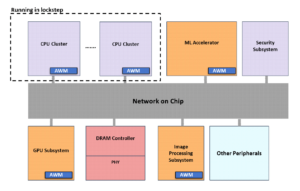
VSORA, fondata nel 2015 per indirizzare le applicazioni 5G, ha inventato un'architettura brevettata che collassa la struttura gerarchica della memoria in una memoria TCM (Tightly Coupled Memory) a larghezza di banda elevata, a cui si accede in un ciclo di clock.
Dal punto di vista dei core del processore, il TCM appare e si comporta come un mare di registri nella quantità di MByte rispetto ai kByte dei registri fisici effettivi. La possibilità di accedere a qualsiasi cella di memoria nel TMC in un ciclo garantisce un'elevata velocità di esecuzione, una bassa latenza e un basso consumo energetico. Richiede anche meno area di silicio. Il caricamento di nuovi dati dalla memoria esterna nel TCM mentre i dati correnti vengono elaborati non influisce sulla velocità effettiva del sistema. Fondamentalmente, l'architettura consente un utilizzo superiore all'80% delle unità di elaborazione attraverso il suo design. Tuttavia, esiste la possibilità di aggiungere cache e memoria per gli appunti se il progettista del sistema lo desidera. Vedere la figura 1.
")
Attraverso una struttura di memoria a registro implementata praticamente in tutte le memorie di tutte le applicazioni, il vantaggio dell'approccio alla memoria VSORA non può essere sopravvalutato. In genere, i processori GenAI all'avanguardia offrono un'efficienza percentuale a una cifra. Ad esempio, un processore GenAI con un throughput nominale di un Petaflop di prestazioni nominali ma con un'efficienza inferiore al 5% offre prestazioni utilizzabili inferiori a 50 Teraflop. Invece, l’architettura VSORA raggiunge un’efficienza oltre 10 volte maggiore.
Gli acceleratori algoritmici di VSORA
VSORA ha introdotto due classi di acceleratori algoritmici: la famiglia Tyr per applicazioni AD e la famiglia Jotunn per l'accelerazione GenAI. Entrambi offrono throughput stellare, latenza minima, basso consumo energetico in un ingombro ridotto di silicio.
Con prestazioni nominali fino a tre Petaflop, vantano un'efficienza di implementazione tipica del 50-80% indipendentemente dal tipo di algoritmo e un consumo energetico di picco di 30 Watt/Petaflop. Questi sono attributi stellari, non ancora segnalati da nessun acceleratore IA competitivo.
Tyr e Jotunn sono completamente programmabili e integrano funzionalità AI e DSP, anche se in quantità diverse, e supportano la selezione al volo dell'aritmetica da 8 bit a 64 bit basata su numeri interi o in virgola mobile. La loro programmabilità accoglie un universo di algoritmi, rendendoli indipendenti dagli algoritmi. Sono supportati anche diversi tipi di scarsità.
Le caratteristiche dei processori VSORA li spingono in prima linea nel panorama competitivo dell'elaborazione algoritmica.
Software di supporto VSORA
VSORA ha progettato un'esclusiva piattaforma di compilazione/convalida su misura per la sua architettura hardware per garantire che i suoi dispositivi SoC complessi e ad alte prestazioni dispongano di ampio supporto software.
Pensati per mettere il progettista algoritmico nella cabina di pilotaggio, una serie di livelli gerarchici di verifica/convalida – ESL, ibrido, RTL e gate – forniscono feedback tramite pulsante all'ingegnere algoritmico in risposta alle esplorazioni dello spazio di progettazione. Questo lo aiuta a selezionare il miglior compromesso tra prestazioni, latenza, potenza e area. Il codice di programmazione scritto ad un alto livello di astrazione può essere mappato mirando a diversi core di elaborazione in modo trasparente per l'utente.
L'interfaccia tra core può essere implementata all'interno dello stesso silicio, tra chip sullo stesso PCB o tramite una connessione IP. La sincronizzazione tra i core viene gestita automaticamente in fase di compilazione e non richiede operazioni software in tempo reale.
Blocco stradale alla guida autonoma L4/L5 e all'inferenza dell'intelligenza artificiale generativa sull'edge
Una soluzione di successo dovrebbe includere anche la programmabilità sul campo. Gli algoritmi si evolvono rapidamente, guidati da nuove idee che rendono obsoleto da un giorno all'altro lo stato dell'arte di ieri. La capacità di aggiornare un algoritmo sul campo è un vantaggio degno di nota.
Sebbene le aziende su vasta scala stiano assemblando enormi aziende di calcolo con una moltitudine di processori dalle prestazioni più elevate per gestire algoritmi software avanzati, l’approccio è pratico solo per la formazione, non per l’inferenza all’edge.
L'addestramento è in genere basato sull'aritmetica in virgola mobile a 32 o 64 bit che genera grandi volumi di dati. Non impone una latenza rigorosa e tollera un consumo energetico elevato e costi sostanziali.
L'inferenza al limite viene generalmente eseguita su un'aritmetica in virgola mobile a 8 bit che genera quantità di dati leggermente inferiori, ma impone una latenza senza compromessi, un basso consumo energetico e un basso costo.
Impatto del consumo energetico su latenza ed efficienza
Il consumo energetico nei circuiti integrati CMOS è dominato dal movimento dei dati e non dall'elaborazione dei dati.
Uno studio dell’Università di Stanford condotto dal professor Mark Horowitz ha dimostrato che il consumo energetico dell’accesso alla memoria consuma ordini di grandezza in più di energia rispetto ai calcoli logici digitali di base. Vedi tabella II.

Gli acceleratori AD e GenAI sono ottimi esempi di dispositivi dominati dal movimento dei dati che rappresentano una sfida per contenere il consumo energetico.
Conclusione
L'inferenza di AD e GenAI pone sfide non banali per ottenere implementazioni di successo. VSORA è in grado di fornire una soluzione hardware completa e un software di supporto per soddisfare tutti i requisiti critici per gestire AD L4/L5 e GenAI come l'accelerazione GPT-4 a costi commercialmente sostenibili.
Maggiori dettagli su VSORA e i suoi Tyr e Jotunn possono essere trovati su www.vsora.com.
A proposito di Lauro Rizzatti
Lauro Rizzatti è consulente aziendale di VSORA, una startup innovativa che offre soluzioni IP in silicio e chip in silicio, nonché un noto consulente di verifica ed esperto del settore in emulazione hardware. In precedenza, ha ricoperto incarichi nel management, nel marketing di prodotto, nel marketing tecnico e nell'ingegneria.
Leggi anche:
Soitec sta progettando il futuro dell'industria dei semiconduttori
ISO 21434 per lo sviluppo di SoC sensibili alla sicurezza informatica
Manutenzione predittiva nel contesto della sicurezza funzionale automobilistica
Condividi questo post tramite:
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://semiwiki.com/automotive/336201-long-standing-roadblock-to-viable-l4-l5-autonomous-driving-and-generative-ai-inference-at-the-edge/
- :ha
- :È
- :non
- $ SU
- 000
- 1
- 10
- 1800
- 1994
- 20
- 30
- 50
- 5G
- a
- capacità
- Chi siamo
- astrazione
- accelerare
- accelerazione
- acceleratore
- acceleratori
- accesso
- accessibile
- Accedendo
- Raggiungere
- Realizza
- operanti in
- atti
- presenti
- Ad
- ADA
- aggiungere
- indirizzo
- Avanzate
- avanzamenti
- Vantaggio
- consulente
- influenzare
- AI
- algoritmo
- algoritmica
- Algoritmi
- Tutti
- consente
- anche
- quantità
- importi
- an
- ed
- rispondere
- in qualsiasi
- applicazioni
- approccio
- architettura
- SONO
- RISERVATA
- Arte
- AS
- At
- attenzione
- gli attributi
- automaticamente
- settore automobilistico
- autonomo
- Larghezza di banda
- basato
- basic
- fondamentalmente
- BE
- diventare
- stato
- sotto
- Segno di riferimento
- MIGLIORE
- fra
- miliardi
- entrambi
- affari
- ma
- by
- nascondiglio
- Materiale
- non può
- funzionalità
- capitale
- causando
- cella
- Challenge
- sfide
- Chips
- classi
- Orologio
- Cabina di pilotaggio
- codice
- crolli
- commercialmente
- comunità
- Aziende
- competitivo
- complesso
- complicato
- globale
- compromesso
- calcoli
- Calcolare
- informatica
- veloce
- consulente
- consumo
- contenere
- contesto
- Costo
- Costi
- accoppiato
- CPU
- creato
- critico
- Corrente
- bordo tagliente
- ciclo
- dati
- elaborazione dati
- consegnare
- consegnato
- fornisce un monitoraggio
- denso
- dipende
- descritta
- Design
- progettato
- Designer
- dettagli
- dispositivi
- diverso
- digitale
- cifre
- do
- effettua
- dollari
- spinto
- guida
- Cadere
- Gocce
- avidamente
- bordo
- efficienza
- o
- fine
- energia
- Consumo di energia
- ingegnere
- Ingegneria
- garantire
- entusiasmo
- ESL
- essential
- sviluppate
- EVER
- evolvere
- esempio
- Esempi
- esecuzione
- esperto
- esterno
- famiglia
- lontano
- Farms
- feedback
- pochi
- campo
- figura
- Nome
- galleggiante
- Orma
- Nel
- prima linea
- essere trovato
- Fondato
- Francese
- da
- completamente
- funzionale
- futuro
- genera
- generativo
- AI generativa
- Google Search
- maggiore
- maniglia
- Hardware
- Avere
- he
- Eroe
- aiuta
- suo
- Alta
- Alte prestazioni
- massimo
- lui
- Horowitz
- http
- HTTPS
- Enorme
- IBRIDO
- i
- ICS
- idee
- if
- ii
- implementazione
- implementazioni
- implementato
- importante
- imporre
- in
- includere
- industria
- Esperto del settore
- creativi e originali
- esempio
- invece
- integrare
- ai miglioramenti
- introdotto
- Inventato
- Investire
- investito
- IP
- IT
- SUO
- jpg
- salti
- conservazione
- conosciuto
- paesaggio
- grandi
- Latenza
- Guidato
- meno
- Livello
- livelli
- piace
- Caricamento in corso
- logica
- Di vecchia data
- più a lungo
- SEMBRA
- Basso
- Principale
- manutenzione
- Fare
- gestito
- gestione
- mandati
- marchio
- Marketing
- massiccio
- max-width
- Soddisfare
- memorie
- Memorie
- millisecondi
- minimo
- moderno
- soldi
- Scopri di più
- movimento
- multiplo
- moltitudini
- New
- notte
- noto
- degno di nota
- adesso
- obsoleto
- of
- offerta
- on
- ONE
- esclusivamente
- Operazioni
- or
- minimo
- ordini
- Altro
- Altri
- ancora
- per una notte
- sopravvalutato
- brevettato
- Corrente di
- per
- percentuale
- performance
- eseguita
- prospettiva
- Fisico
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- Abbondanza
- punto
- posizioni
- possibilità
- Post
- energia
- Pratico
- in precedenza
- premio
- Problema
- processi
- elaborati
- lavorazione
- Processore
- processori
- Prodotto
- Insegnante
- programmabile
- Programmazione
- Progressi
- Spingere
- metti
- query
- gamma
- rapidamente
- Leggi
- tempo reale
- Realtà
- recente
- riduce
- Indipendentemente
- registri
- notevole
- replicato
- Segnalati
- richiedere
- Requisiti
- richiede
- risposta
- stesso
- MARE
- Cerca
- secondo
- vedere
- prodotti
- semiconduttore
- sensore
- alcuni
- Condividi
- azioni
- dovrebbero
- ha mostrato
- Silicio
- da
- singolo
- piccole
- So
- Software
- soluzione
- Soluzioni
- RISOLVERE
- alcuni
- piuttosto
- Fonte
- lo spazio
- velocità
- esaurito
- stanford
- Università di Stanford
- startup
- Regione / Stato
- state-of-the-art
- Stellar
- Ancora
- aerodinamico
- rigoroso
- La struttura
- Studio
- sostanziale
- di successo
- supporto
- supportato
- Supporto
- dati
- sistema
- tavolo
- su misura
- Target
- mira
- Consulenza
- Tecnologie
- di
- che
- I
- Il futuro
- loro
- Li
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- tre
- Attraverso
- portata
- strettamente
- tempo
- volte
- a
- oggi
- pista
- tradizionale
- traffico
- Training
- in modo trasparente
- seconda
- Digitare
- Tipi di
- tipico
- tipicamente
- unico
- unità
- Universo
- Università
- fino a quando
- upgrade
- utilizzabile
- Utente
- utilizzando
- VC
- impresa
- capitale di rischio
- Convalida
- contro
- via
- vitale
- potenzialmente
- volumi
- aspettare
- Muro
- Prima
- Modo..
- WELL
- quando
- while
- largo
- auguri
- con
- entro
- scritto
- ancora
- i rendimenti
- zefiro