Il riconoscimento ottico dei caratteri (OCR), il metodo di conversione di testi scritti a mano/stampati in testo codificato a macchina, è sempre stato un'importante area di ricerca nella visione artificiale grazie alle sue numerose applicazioni in vari domini: le banche utilizzano l'OCR per confrontare le dichiarazioni; I governi utilizzano l'OCR per raccogliere feedback sui sondaggi.

A causa della diversità nella scrittura a mano e negli stili di testo stampato, i recenti approcci dell'OCR incorporano il deep learning per ottenere una maggiore precisione. Poiché il deep learning richiede grandi quantità di dati per l'addestramento del modello, aziende come Google hanno un vantaggio nel produrre risultati promettenti con i loro servizi OCR.
Questo articolo approfondisce i dettagli di Google Vision OCR, incluso un semplice tutorial in Python, la gamma di applicazioni, i prezzi e altre alternative.
- Che cos'è l'OCR di Google Cloud Vision?
- Un semplice tutorial
- Perché l'OCR?
- Esempi di casi d'uso
- Prezzi
- Caratteristiche salienti di Google Cloud Vision OCR
- Alternative
- Problemi comuni
Che cos'è Google Cloud Vision?

Google Cloud Vision OCR fa parte dell'API di Google Cloud Vision per estrarre il testo dalle immagini. Nello specifico, ci sono due annotazioni per aiutare con il riconoscimento dei caratteri:
- Testo_Annotazione: Estrae ed emette testi codificati a macchina da qualsiasi immagine (ad esempio, foto di viste stradali o scenari). Poiché inizialmente è stato progettato per essere utilizzabile in diverse situazioni di illuminazione, il modello è in un certo senso più robusto nella lettura di parole di stili diversi, ma solo a un livello più sparso. Il file JSON restituito include le intere stringhe, nonché le singole parole e le relative caselle di delimitazione.
- Documento_Testo_Annotazione: Questo è particolarmente progettato per documenti di testo ad alta densità (ad es. libri scansionati). Pertanto, mentre supporta la lettura di testi più piccoli e più concentrati, è meno adattabile alle immagini selvagge. Informazioni come paragrafi, blocchi e interruzioni sono incluse nel file JSON di output.
Alla ricerca di una soluzione OCR che superi le carenze di Google Cloud Vision o OCR zonale? Dai Nanonet™ una rotazione per una maggiore precisione, una maggiore flessibilità e tipi di documenti più ampi!
Un semplice tutorial
La sezione seguente introduce un semplice tutorial per iniziare con l'API di Google Vision, in particolare su come utilizzarla per il servizio OCR di Google Cloud Vision.
Panoramica semplice
L'idea alla base di questo è molto intuitiva e semplice.
1) In sostanza, invii un'immagine (remota o dalla tua memoria locale) all'API di Google Cloud Vision.
2) L'immagine viene elaborata da remoto su Google Cloud e produce i corrispondenti formati JSON rispetto alla funzione che hai richiamato.
3) Il file JSON viene restituito come output dopo la chiamata della funzione.
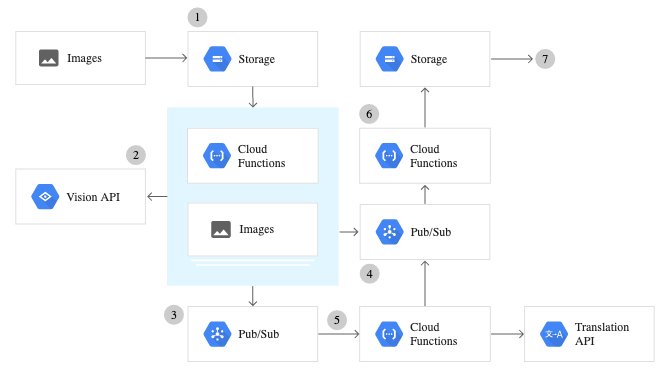
Configurazione dell'API di Google Cloud Vision
Per utilizzare eventuali servizi forniti dall'API di Google Vision, è necessario configurare la Google Cloud Console ed eseguire una serie di passaggi per l'autenticazione. Di seguito è riportata una panoramica dettagliata di come configurare l'intero servizio API Vision.
- Crea un progetto in Google Cloud Console: è necessario creare un progetto per iniziare a utilizzare qualsiasi servizio Vision. Il progetto organizza risorse come collaboratori, API e informazioni sui prezzi.
- Abilita fatturazione: per abilitare l'API Vision, devi prima abilitare la fatturazione per il tuo progetto. I dettagli dei prezzi verranno affrontati nelle sezioni successive.
- Abilita API Vision
- Crea account di servizio: crea un account di servizio e collegalo al progetto creato, quindi crea una chiave dell'account di servizio. La chiave verrà generata e scaricata come file JSON sul tuo computer.
- Imposta la variabile d'ambiente GOOGLE_APPLICATION_CREDENTIALS; Per impostare questa variabile di ambiente, eseguila su Mac/Linux o Windows.
- Blocchi di codice per Mac/Linux
- Blocchi di codice per Windows
Una procedura più dettagliata dei suddetti passaggi è reperibile dalla documentazione ufficiale fornita da Google Cloud da qui:
https://cloud.google.com/vision/docs/quickstart-client-libraries
Semplice funzione OCR di Google Vision in Python
L'API di Google Cloud Vision funziona con numerosi linguaggi popolari, che vanno da Java, Node.js, Python, al linguaggio di Google Go. Per semplicità, introduciamo un semplice metodo di chiamata in Python.
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) In altre parole, il metodo chiama di conseguenza la funzione text_annotation, quindi estrarre ulteriormente le risposte e stampare le informazioni. annotazione_testo_documento può anche essere chiamato usando lo stesso modo per recuperare testi densi. Si possono anche rilevare le immagini da remoto impostando l'immagine tramite:
image.source.image_uri = uridove uri è l'uri dell'immagine.
Maggiori dettagli sui codici possono essere recuperati qui:
https://cloud.google.com/vision
Cerchi una soluzione OCR che superi le carenze di Google Cloud Vision? Dai Nanonet™ una rotazione per una maggiore precisione, una maggiore flessibilità e tipi di documenti più ampi!
Livello di output offerto
Per facilitare l'ulteriore analisi dei dati del testo, le due funzioni di Google OCR forniscono vari livelli di output che gli utenti possono utilizzare: for text_annotation, sia le intere stringhe (se considerate da Google come una frase o frase) sia le singole parole all'interno; per annotazione_testo_documento, poiché il modello è ottimizzato per testo denso, pagina, blocco, paragrafo, parola e interruzione vengono tutti offerti come parte dell'output.
Quanto bene funziona però?
Quanto sono robusti i modelli?
Come accennato in precedenza, Google offre due funzioni per l'OCR in due diverse situazioni. Di seguito viene descritta la capacità di due funzioni di recuperare diversi tipi di dati.
Dati stampati
Il tipo di dati più semplice da interpretare sono i dati di testo stampati, ovvero il testo scritto da computer, stampato e scansionato. L'OCR è richiesto quando abbiamo solo la copia stampata di questi dati invece dei testi originali codificati dalla macchina. Poiché la maggior parte di questi testi sono stretti e pieni di pagine, annotazione_testo_documento sarebbe una soluzione migliore.
Dati scritti a mano
Il contenuto può contenere testo scritto a mano e gli stili dei dati scritti a mano possono variare drasticamente. Tuttavia, Google Vision OCR fornisce una discreta precisione purché le note scritte a mano non siano troppo disordinate. A seconda di come viene presentato il supporto dei dati scritti a mano, utilizziamo una delle due funzioni caso per caso.
Dati ruotati/in-the-wild
Quando le immagini o le foto scansionate sono presentate con angolazioni non ortodosse o non allineate, le consideriamo dati in natura. I testi potrebbero essere potenzialmente più difficili da rilevare in primo luogo, e quindi di solito utilizziamo il text_annotation funzione che è stata progettata in primo luogo per elaborare dati in natura. Sulla base di alcuni esperimenti di passaggio attraverso testi verticali e segnali stradali catturati da diverse angolazioni, mostriamo che Google Vision OCR funziona effettivamente in modo decente sui dati provenienti da vari ambienti.
Perché l'OCR?
Molti dei dati che abbiamo oggi sono in formato non strutturato. Ad esempio, data un'immagine, un documento scansionato o una fotografia, mentre gli esseri umani possono riconoscere rapidamente i testi e interpretare ulteriormente i significati, tutti i dati del testo sono semplicemente pixel con colori, che non forniscono alcun significato reale alle macchine.

Quando le aziende o le grandi aziende hanno a che fare con enormi quantità di documenti, l’ampio volume di dati renderebbe impossibile che qualsiasi classificazione o elaborazione dei dati venga eseguita con il solo sforzo umano: è allora che il testo codificato dalla macchina diventa utile.
Dopo la conversione OCR, le informazioni possono quindi essere analizzate con più metodi diversi a seconda della natura dei dati:
- Per i dati numerici, i metodi statistici potrebbero essere applicati direttamente per analizzare eventuali correlazioni. Potremmo anche adottare metodi di machine learning tradizionali (ad es. KNN, K-Means, Linear Regression) o approcci di deep learning per creare modelli predittivi per la regressione e/o la classificazione.
- Per i dati di testo potrebbero essere necessarie più fasi di elaborazione. Il processo di analisi e interpretazione dei dati di testo in statistiche significative viene spesso definito elaborazione del linguaggio naturale (PNL). In particolare, potremmo estrarre numeri o anche semantica/atmosfera in base a un dato contenuto.
Tutte queste analisi potrebbero consentire alle aziende, in particolare a quelle con grandi quantità di nuovi dati ogni giorno, di creare modelli robusti e persino automatizzare molti processi e sostituire i tradizionali approcci laboriosi e pieni di errori. La sezione seguente esamina alcuni esempi dettagliati di come è possibile utilizzare l'OCR.
Cerchi una soluzione OCR che superi le carenze di Google Cloud Vision? Dai Nanonet™ una rotazione per una maggiore precisione, una maggiore flessibilità e tipi di documenti più ampi!
Esempi di casi d'uso
Lettura targa

Forse uno degli usi più comuni dell'OCR al giorno d'oggi è l'applicazione nella lettura delle targhe. Nei paesi sviluppati, i parcheggi sono spesso accompagnati da modelli di lettura delle targhe per determinare l'orario di ingresso, l'orario di uscita e persino l'esatta posizione di parcheggio per auto. Alcuni parcheggi sono addirittura collegati alla rete governativa per addebitare le tariffe di parcheggio direttamente alle famiglie, il che allevia gli sforzi umani ridondanti.
I modelli OCR targati possono essere adottati anche per rilevamenti in violazioni del codice della strada, alleggerendo il tempo per la polizia di inserire manualmente i dati dell'auto in violazione.
Scansione scontrino e fattura

Le proiezioni finanziarie e il bilanciamento delle attività e delle passività delle società sono attività importanti per qualsiasi impresa. Poiché le grandi aziende effettuano acquisti di grandi quantità da più settori durante tutto l'anno, sono tenute a raccogliere ed elaborare meticolosamente tutte le fatture e le ricevute durante la creazione dei rendiconti finanziari.
Con l'aiuto dell'OCR, possiamo creare pipeline automatizzate che riconoscere una serie di formati di fattura e convertirli in numeri. Gli sforzi del lavoro sono richiesti solo per il controllo e i dati e i numeri strutturati possono consentire all'azienda di bilanciare rapidamente gli afflussi e i deflussi, creare proiezioni finanziarie e fare attenzione a eventuali manipolazioni dannose delle finanze dell'azienda.
Cartelle mediche elettriche

I dati dei pazienti sono spesso sparsi in una regione, in un paese o anche tra paesi, a seconda dello stile di vita degli individui. A causa dei diversi stili di cliniche e ospedali (gli ospedali di grandi dimensioni possono disporre di database organizzati mentre i medici di cliniche più piccole possono semplicemente annotare i record a mano), l'età dei pazienti (i pazienti più anziani possono essere inseriti in un database particolare prima del rinnovamento e dell'incorporazione di computer) e l'ubicazione delle persone (le persone possono trasferirsi in una città diversa o addirittura all'estero), mantenere un medico universale può effettivamente essere molto difficile.
Un OCR ben addestrato diventa quindi utile quando si trasferisce l’EMR da un ospedale a un altro o si trasformano i dati scritti a mano in testo automatico, entrambi i quali possono accelerare il processo di comprensione della storia medica dei pazienti in modo rapido e conciso.
Moduli e sondaggi

Le organizzazioni (governative o non governative) possono spesso richiedere il feedback di clienti o cittadini per migliorare i loro attuali piani e prodotti promozionali. Poiché i moduli sono generalmente scritti a mano, sarebbe potenzialmente difficile eseguire qualsiasi analisi statistica diretta. Pertanto, il processo di conversione di dati non strutturati e rilevamenti scritti a mano in cifre numeriche per facilitare i calcoli potrebbe essere assistito e accelerato dall'OCR.
Cerchi una soluzione OCR che superi le carenze di Google Cloud Vision? Dai Nanonet™ una rotazione per una maggiore precisione, una maggiore flessibilità e tipi di documenti più ampi!
Prezzi di Cloud Vision
Secondo Google sito web, Sia text_annotation ed annotazione_testo_documento sono offerti allo stesso livello di prezzo dei seguenti:
Per ogni mese, le prime 1000 unità vengono fornite gratuitamente, con le 1000-5000000 addebitate a $ 1.5 per 1000 unità. Dopo aver raggiunto la soglia di 5000000, il prezzo scende a $ 0.6 per 1000 unità (ogni immagine inviata tramite l'API di Google Vision è considerata come un'unità).
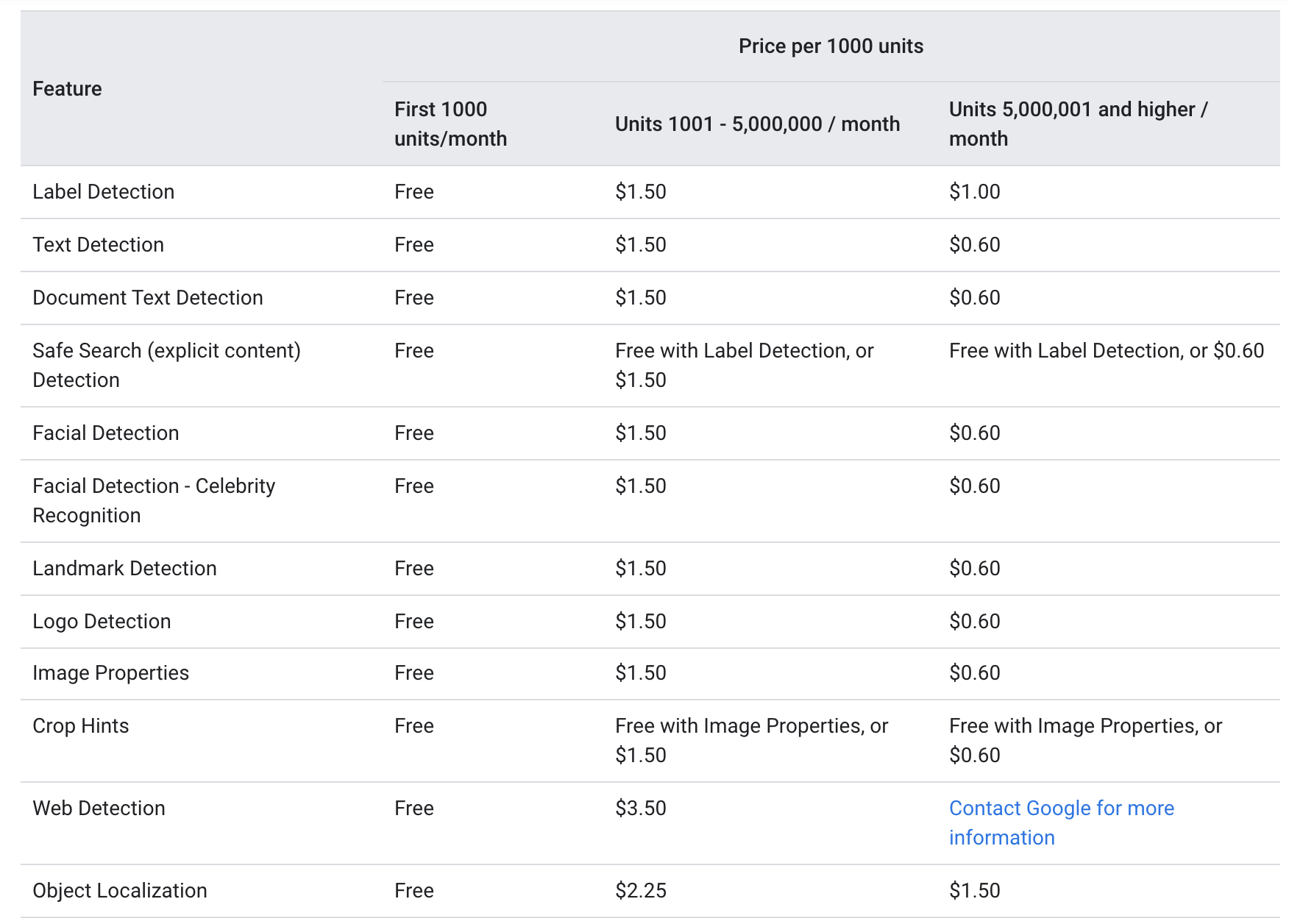
Il prezzo di cui sopra suggerisce che il servizio OCR è relativamente conveniente sia per le piccole aziende con usi meno frequenti che per le grandi aziende in cui il servizio è richiesto molto più di 5000000 volte al mese.
Caratteristiche salienti di Google Cloud Vision OCR
Google OCR ha vari vantaggi, qui descriviamo alcuni dei vantaggi più significativi:
- Robusto - Le due funzioni, che servono due tipi di documenti di testo dipendenti dalla decisione degli utenti, rendono Google Vision OCR relativamente più robusto dei motori OCR a modello singolo.
- Supporto linguistico - Con forse il database linguistico più grande, Google ha consigliato che il suo OCR è applicabile a più di 60 lingue, sperimentandone alcune dozzine in più, e mappa molte delle altre su un altro codice di lingua o un riconoscitore di lingua generale.
- Facilità d'uso — Il modello stesso fa parte della libreria integrata di Google Vision. Dopo il processo leggermente più fastidioso di configurazione della chiave API (richiesto da quasi tutti i motori OCR), il metodo di chiamata di funzione può essere utilizzato in numerosi linguaggi in modo molto semplice.
- Scalabilità - La strategia dei prezzi di Google incoraggia gli utenti ad aumentare l'utilizzo dell'API, poiché un maggiore utilizzo porta a un prezzo medio più basso.
- Velocità - La piattaforma di archiviazione di Google Cloud accompagna meravigliosamente l'utilizzo dell'API. Caricando le immagini nell'unità, il tempo di risposta dell'API può essere molto veloce e scalabile.

Cerchi una soluzione OCR che superi le carenze di Google Cloud Vision? Dai Nanonet™ una rotazione per una maggiore precisione, una maggiore flessibilità e tipi di documenti più ampi!
Alternative
Di seguito sono riportati alcuni servizi OCR alternativi diversi dall'API di Google Vision, insieme ai vantaggi e agli svantaggi di ciascun servizio.
ABBYY
ABBYY FineReader PDF è un OCR sviluppato da ABBYY, che si concentra in particolare sulla lettura di pdf.
- PRO: ABBYY è molto più conveniente per i singoli utenti poiché i prezzi sono segmentati in settori più piccoli (1000, 2000 pagine, ecc.). È anche rivolto a clienti non ingegneristici in quanto è un'app commercializzata.
- Contro: Il software si concentra solo sul formato PDF e il prezzo diventa molto costoso quando si esegue l'OCR su larga scala.
- Quando usare: Per i singoli utenti che desiderano semplicemente gestire rapidamente i PDF, ABBYY potrebbe essere un'opzione più praticabile rispetto all'API di Google Vision che offre maggiore flessibilità ma richiede codici aggiuntivi.
Microsoft
Microsoft Azure offre anche Read API per OCR.
- PRO: Microsoft offre un prezzo più conveniente per un numero ancora maggiore di dati da utilizzare. Archiviazione cloud di Azure offre servizi simili a Google Cloud.
- Contro: Non esiste un livello gratuito, mentre altre opzioni forniscono chiamate API gratuite per un utilizzo ridotto.
- Quando usare: Le pipeline di produzione OCR su larga scala potrebbero trarre vantaggio dai prezzi di Microsoft.
Kofax
Simile ad ABBYY, Kofax offre anche la lettura OCR dei PDF
- PRO: Il prezzo è fisso per l'utilizzo individuale e vengono offerti sconti per le aziende. Viene fornita anche assistenza clienti 24 ore su 7, XNUMX giorni su XNUMX.
- Contro: Si dice che la qualità non sia alta come quella di ABBYY.
- Quando usare: Piccole imprese con requisiti di utilizzo ridotti.
Testo AWS
AWS Texttract svolge un ruolo molto simile rispetto all'API di Google Vision. I loro servizi e prezzi sono molto simili, quindi quale adottare è completamente basato sulle preferenze del cliente.
nanonet
A differenza dei servizi discussi in precedenza, gli OCR di Nanonets sono ulteriormente classificati in categorie specifiche, con modelli robusti addestrati su ciascun tipo di dati (ad es. ricevute, fatture, patenti di guida).
- PRO: OCR specifici per categoria, fornendo quindi risultati ancora migliori in termini di accuratezza quando le aziende richiedono l'OCR per applicazioni specifiche per target.
- Contro: L'OCR di Nanonets potrebbe essere meno applicabile alle impostazioni in natura a causa dei modelli altamente specifici e personalizzati
- Quando usare: Se le aziende richiedono l'OCR per un tipo specifico di dati come le fatture, Nanonets può essere un'opzione economica e altamente accurata.
Puoi prova Nanonets Online OCR qui.
Problemi comuni con Cloud Vision
In questa sezione finale, miriamo a rispondere ad alcune domande di Stackoverflow riguardanti la scansione dei documenti e l'OCR
Riconoscimento di documenti tramite reti neurali
Questo è l'esatto utilizzo di Google OCR! Seguire i passaggi precedenti per eseguire la scansione di documenti ed eseguire il recupero del testo.
Afferrare i dettagli più importanti dopo l'OCR
L'idea di analizzare i contenuti più significativi all'interno di qualsiasi documento è chiamata elaborazione del linguaggio naturale. Poiché ogni documento contiene tali informazioni in formati diversi, si consiglia di adottare alcuni approcci ML per farlo. Naturalmente, se tutte le carte sono nello stesso formato, anche i metodi basati su regole per recuperare i testi con determinati caratteri chiave (ad esempio, se contiene @ è un'e-mail) dovrebbero funzionare.
Può funzionare offline?
link: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
Sfortunatamente no. L'API chiama Google Cloud OCR in remoto e non puoi lavorare offline poiché l'API costa denaro.
Può rilevare se un testo è in grassetto o corsivo?
No. Molto probabilmente Google OCR rileverà il contenuto del testo anche quando è in grassetto o in corsivo, ma il modello OCR non è progettato per comprendere i tipi di carattere.
Aggiornare: Aggiunte ulteriori informazioni in base alle domande dei lettori.
- &
- a
- accelerata
- Il mio account
- preciso
- operanti in
- attività
- indirizzo
- vantaggi
- Tutti
- alternativa
- alternative
- sempre
- importi
- .
- analizzare
- Un altro
- api
- API
- App
- applicabile
- Applicazioni
- applicazioni
- applicato
- approcci
- RISERVATA
- in giro
- articolo
- Attività
- Autenticazione
- automatizzare
- Automatizzata
- media
- azzurro
- Cloud azzurro
- sfondo
- Banche
- base
- prima
- beneficio
- vantaggi
- fatturazione
- Bloccare
- perno
- Libri
- sistema
- pause
- auto
- Carte
- certo
- caratteri
- carica
- carico
- più economico
- verifica
- Città
- classificazione
- Cloud
- Cloud Storage
- codice
- Uncommon
- Aziende
- azienda
- rispetto
- completamente
- computer
- computer
- collegato
- Prendere in considerazione
- consolle
- contiene
- contenuto
- testuali
- Conversione
- Corporazioni
- Corrispondente
- Costi
- potuto
- paesi
- nazione
- creare
- creato
- Creazione
- Corrente
- cliente
- Assistenza clienti
- Clienti
- dati
- analisi dei dati
- elaborazione dati
- Banca Dati
- banche dati
- giorno
- trattare
- decisione
- deep
- dipendente
- Dipendente
- descrivere
- progettato
- dettagliati
- dettagli
- rilevato
- Determinare
- sviluppato
- diverso
- difficile
- dirette
- direttamente
- Diversità
- Dottori
- documenti
- domini
- giù
- guidare
- guida
- ogni
- facilitando
- bordo
- sforzo
- sforzi
- emerse
- enable
- incoraggia
- aziende
- Ambiente
- particolarmente
- essenzialmente
- eccetera
- Esempi
- uscita
- estratti
- famiglie
- FAST
- Caratteristiche
- feedback
- Costi
- finanza
- finanziario
- Impresa
- Nome
- fisso
- Flessibilità
- si concentra
- seguire
- i seguenti
- formato
- forme
- essere trovato
- Gratis
- da
- function
- funzioni
- ulteriormente
- Generale
- ottenere
- governo
- I governi
- maggiore
- maniglia
- Aiuto
- qui
- Alta
- superiore
- vivamente
- storia
- ospedali
- Come
- Tutorial
- HTTPS
- umano
- Gli esseri umani
- idea
- Immagine
- immagini
- importante
- impossibile
- competenze
- incluso
- inclusi
- Compreso
- individuale
- individui
- info
- informazioni
- esempio
- intuitivo
- sicurezza
- IT
- stessa
- Java
- conservazione
- Le
- lavoro
- Lingua
- Le Lingue
- grandi
- superiore, se assunto singolarmente.
- maggiore
- Leads
- apprendimento
- Livello
- livelli
- Biblioteca
- Licenza
- licenze
- stile di vita
- probabile
- LINK
- locale
- località
- posizioni
- Lunghi
- macchina
- machine learning
- macchine
- maggiore
- make
- modo
- manualmente
- Maps
- marchio
- massiccio
- significato
- significativo
- medicale
- medie
- menzionato
- metodi
- Microsoft
- ML
- modello
- modelli
- soldi
- Mese
- Scopri di più
- maggior parte
- cambiano
- multiplo
- Naturale
- Natura
- esigenze
- Rete
- tuttavia
- Note
- numero
- numeri
- numerose
- offerto
- Offerte
- ufficiale
- offline
- online
- ottimizzati
- Opzione
- Opzioni
- minimo
- Organizzato
- Altro
- proprio
- imballato
- parcheggio
- parte
- particolare
- particolarmente
- Di passaggio
- Persone
- Forse
- piani
- piattaforma
- Polizia
- Popolare
- potente
- prezzo
- prezzi
- processi
- i processi
- lavorazione
- Produzione
- Prodotti
- progetto
- proiezioni
- promettente
- promozionale
- fornire
- purché
- fornisce
- fornitura
- acquisti
- qualità
- rapidamente
- gamma
- che vanno
- RE
- lettori
- Lettura
- recente
- riconoscere
- record
- per quanto riguarda
- regione
- a distanza
- richiedere
- necessario
- Requisiti
- richiede
- riparazioni
- Risorse
- risposta
- REST
- Risultati
- strada
- Ruolo
- Correre
- stesso
- scalabile
- Scala
- scansione
- scansione
- Settori
- senso
- Serie
- servizio
- Servizi
- servizio
- set
- regolazione
- significativa
- Segni
- simile
- Un'espansione
- da
- piccole
- So
- Software
- solido
- soluzione
- alcuni
- specifico
- in particolare
- Spin
- tappe
- iniziato
- dichiarazioni
- statistiche
- statistica
- conservazione
- Strategia
- strada
- strutturato
- supporto
- supporti
- Indagine
- condizioni
- I
- perciò
- Attraverso
- per tutto
- tempo
- volte
- oggi
- verso
- tradizionale
- traffico
- Training
- Trasferimento
- trasformazione
- Tipi di
- per
- capire
- e una comprensione reciproca
- unità
- universale
- uso
- utenti
- generalmente
- vario
- visione
- volume
- Orologio
- se
- while
- OMS
- più ampia
- finestre
- entro
- parole
- Lavora
- lavori
- sarebbe
- X
- anno
- Trasferimento da aeroporto a Sharm