Apache Hudi è un formato di tabella aperto che offre funzionalità di database e data warehouse ai data Lake. Apache Hudi aiuta gli ingegneri dei dati a gestire sfide complesse, come la gestione di set di dati in continua evoluzione con transazioni mantenendo le prestazioni delle query. Gli ingegneri dei dati utilizzano Apache Hudi per lo streaming di carichi di lavoro e per creare pipeline di dati incrementali efficienti. Hudi fornisce con tabelle, Transazioni, upsert ed eliminazioni efficienti, indici avanzati, servizi di ingestione di streaming, dati il clustering ed compattazione ottimizzazioni, e controllo della concorrenza, il tutto mantenendo i tuoi dati in formati di file open source. Le ottimizzazioni avanzate delle prestazioni di Hudi rendono i carichi di lavoro analitici più veloci con tutti i motori di query più diffusi, tra cui Apache Spark, Presto, Trino, Hive e così via.
Molti clienti AWS hanno adottato Apache Hudi sui propri data Lake basati su Amazon S3 Colla AWS, un servizio di integrazione dei dati serverless che semplifica la scoperta, la preparazione, lo spostamento e l'integrazione dei dati da più fonti per analisi, machine learning (ML) e sviluppo di applicazioni. Crawler di colla AWS è un componente di AWS Glue che consente di creare automaticamente metadati di tabelle dal contenuto dei dati senza richiedere la definizione manuale dei metadati.
I crawler AWS Glue ora supportano le tabelle Apache Hudi, semplificando l'adozione di Catalogo dati di AWS Glue come il catalogo dei tavoli Hudi. Un caso d'uso tipico è la registrazione delle tabelle Hudi, che non dispone di una definizione di tabella di catalogo. Un altro caso d'uso tipico è la migrazione da altri cataloghi Hudi, come Hive metastore. Durante la migrazione da altri cataloghi Hudi, puoi creare e pianificare un crawler AWS Glue e fornire uno o più percorsi Amazon S3 in cui si trovano i file della tabella Hudi. Hai la possibilità di fornire la profondità massima dei percorsi Amazon S3 che il crawler AWS Glue può attraversare. A ogni esecuzione, i crawler di AWS Glue estrarranno le informazioni sullo schema e sulla partizione e aggiorneranno il catalogo dati di AWS Glue con le modifiche allo schema e alla partizione. I crawler di AWS Glue aggiornano la posizione del file di metadati più recente nel catalogo dati di AWS Glue che i motori analitici AWS possono utilizzare direttamente.
Con questo lancio, puoi creare e pianificare un crawler AWS Glue per registrare le tabelle Hudi nel Catalogo dati di AWS Glue. Puoi quindi fornire uno o più percorsi Amazon S3 in cui si trovano le tabelle Hudi. Hai la possibilità di fornire la profondità massima dei percorsi Amazon S3 che i crawler possono attraversare. Con ogni esecuzione del crawler, il crawler ispeziona ciascuno dei percorsi S3 e cataloga le informazioni sullo schema, come nuove tabelle, eliminazioni e aggiornamenti agli schemi nel Catalogo dati di AWS Glue. I crawler controllano le informazioni sulle partizioni e aggiungono le partizioni appena aggiunte al catalogo dati di AWS Glue. I crawler aggiornano inoltre la posizione più recente del file di metadati nel catalogo dati di AWS Glue che i motori analitici AWS possono utilizzare direttamente.
Questo post dimostra come funziona questa nuova funzionalità per eseguire la scansione delle tabelle Hudi.
Come funziona il crawler AWS Glue con le tabelle Hudi
Le tabelle Hudi hanno due categorie, con implicazioni specifiche per ciascuna:
- Copia su scrittura (CoW) – I dati vengono archiviati in un formato colonnare (Parquet) e ogni aggiornamento crea una nuova versione dei file durante una scrittura.
- Unisci in lettura (MoR) – I dati vengono archiviati utilizzando una combinazione di formati colonnari (Parquet) e basati su righe (Avro). Gli aggiornamenti vengono registrati in base alle righe
deltafile e vengono compattati secondo necessità per creare nuove versioni dei file colonnari.
Con i set di dati CoW, ogni volta che si verifica un aggiornamento di un record, il file che contiene il record viene riscritto con i valori aggiornati. Con un dataset MoR, ogni volta che c'è un aggiornamento, Hudi scrive solo la riga per il record modificato. MoR è più adatto per carichi di lavoro pesanti di scrittura o modifica con meno letture. CoW è più adatto per carichi di lavoro pesanti in lettura su dati che cambiano meno frequentemente.
Hudi fornisce tre tipi di query per l'accesso ai dati:
- Query istantanee – Query che visualizzano l'ultima istantanea della tabella a partire da una determinata azione di commit o compattazione. Per le tabelle MoR, le query snapshot espongono lo stato più recente della tabella unendo i file base e delta dell'ultima sezione di file al momento della query.
- Query incrementali – Le query vedono solo i nuovi dati scritti nella tabella, a partire da un determinato commit o compattazione. Ciò fornisce effettivamente flussi di modifiche per abilitare pipeline di dati incrementali.
- Leggi query ottimizzate – Per le tabelle MoR, le query vedono gli ultimi dati compattati. Per le tabelle CoW, le query visualizzano gli ultimi dati impegnati.
Per le tabelle copy-on-write, i crawler creano una singola tabella nel catalogo dati di AWS Glue con il servizio ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
Per le tabelle merge-on-read, i crawler creano due tabelle nel Catalogo dati di AWS Glue per la stessa posizione della tabella:
- Una tabella con suffisso
_ro, che utilizza ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - Una tabella con suffisso
_rt, che utilizza RealTime Serde consentendo le query Snapshot:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Durante ogni scansione, per ogni percorso Hudi fornito, i crawler effettuano una chiamata API dell'elenco Amazon S3, filtrando in base al file .hoodie cartelle e trova il file di metadati più recente nella cartella dei metadati della tabella Hudi.
Scansione di una tabella Hudi CoW utilizzando il crawler AWS Glue
In questa sezione, esaminiamo come eseguire la scansione di un Hudi CoW utilizzando i crawler AWS Glue.
Prerequisiti
Ecco i prerequisiti per questo tutorial:
- Installa e configura Interfaccia a riga di comando AWS (AWS CLI).
- Crea il tuo bucket S3 se non lo possiedi.
- Crea il tuo ruolo IAM per AWS Glue se non ce l'hai. Hai bisogno
s3:GetObjectpers3://your_s3_bucket/data/sample_hudi_cow_table/. - Esegui il comando seguente per copiare la tabella Hudi di esempio nel tuo bucket S3. (Sostituire
your_s3_bucketcon il nome del tuo bucket S3.)
Queste istruzioni ti guidano a copiare i dati di esempio, ma puoi creare facilmente qualsiasi tabella Hudi utilizzando AWS Glue. Scopri di più in Presentazione del supporto nativo per Apache Hudi, Delta Lake e Apache Iceberg su AWS Glue per Apache Spark, parte 2: Editor visivo di AWS Glue Studio.
Crea un crawler Hudi
In queste istruzioni, crea il crawler tramite la console. Completa i seguenti passaggi per creare un crawler Hudi:
- Nella console AWS Glue, scegli Crawlers.
- Scegli Crea cingolato.
- Nel Nome, accedere
hudi_cow_crawler. Scegliere Avanti. - Sotto Configurazione dell'origine dati, scegliere Aggiungi origine dati.
- Nel Fonte di datiscegli hudi.
- Nel Includi percorsi di tabelle hudi, accedere
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Sostituireyour_s3_bucketcon il nome del tuo bucket S3.) - Scegli Aggiungi l'origine dati Hudi.
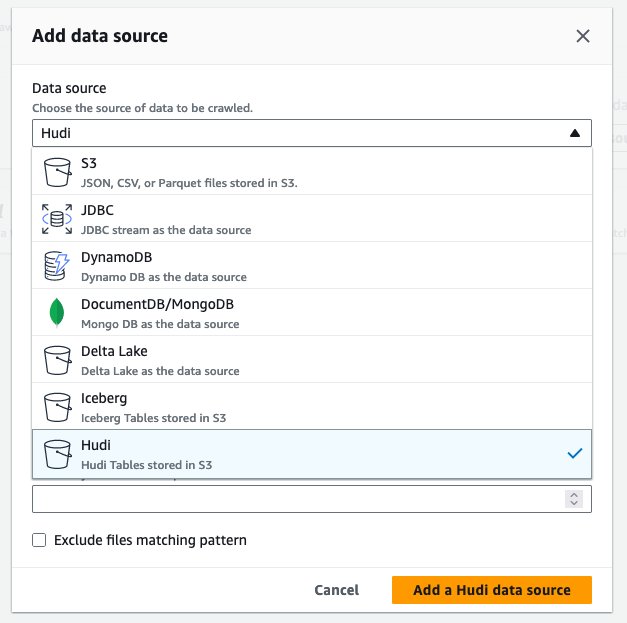
- Scegli Avanti.
- Nel Ruolo IAM esistente, scegli il tuo ruolo IAM, quindi scegli Avanti.
- Nel Database di destinazionescegli Aggiungi database, Allora l' Aggiungi database viene visualizzata la finestra di dialogo. Per Nome del database, accedere
hudi_crawler_blog, Quindi scegliere Creare. Scegliere Avanti. - Scegli Crea cingolato.
Ora un nuovo crawler Hudi è stato creato con successo. È possibile attivare il crawler per l'esecuzione tramite la console o tramite SDK o AWS CLI utilizzando il file StartCrawl API. Potrebbe anche essere pianificato tramite la console per attivare i crawler in orari specifici. In questa istruzione, esegui il crawler attraverso la console.
- Scegli Esegui crawler.
- Attendi il completamento del crawler.
Dopo l'esecuzione del crawler, puoi visualizzare la definizione della tabella Hudi nella console AWS Glue:
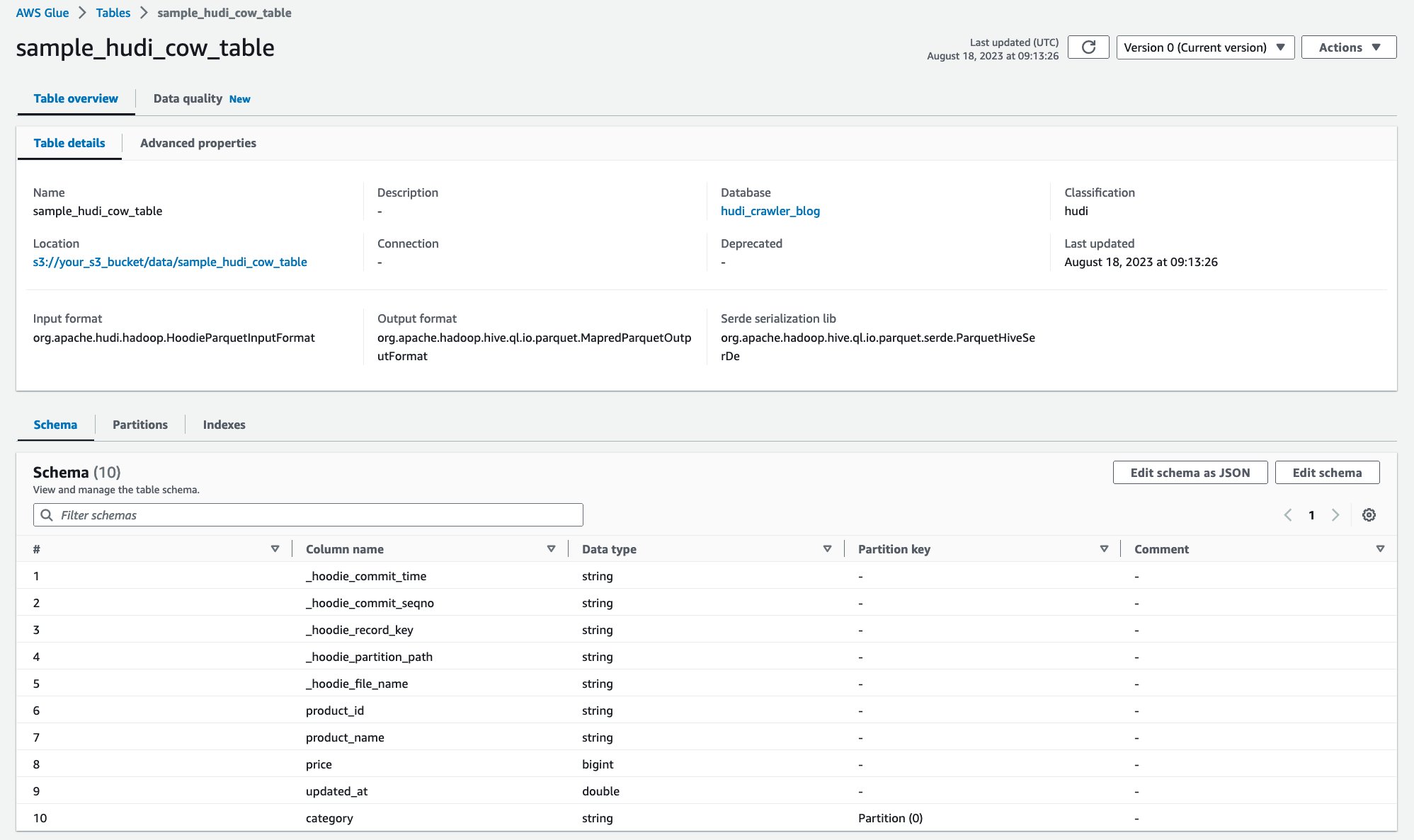
Hai eseguito correttamente la scansione della tabella Hudi CoR con i dati su Amazon S3 e creato una tabella del catalogo dati di AWS Glue con lo schema popolato. Dopo aver creato la definizione della tabella su AWS Glue Data Catalog, i servizi di analisi AWS come Amazon Athena sono in grado di eseguire query sulla tabella Hudi.
Completa i seguenti passaggi per avviare le query su Athena:
- Apri la console Amazon Athena.
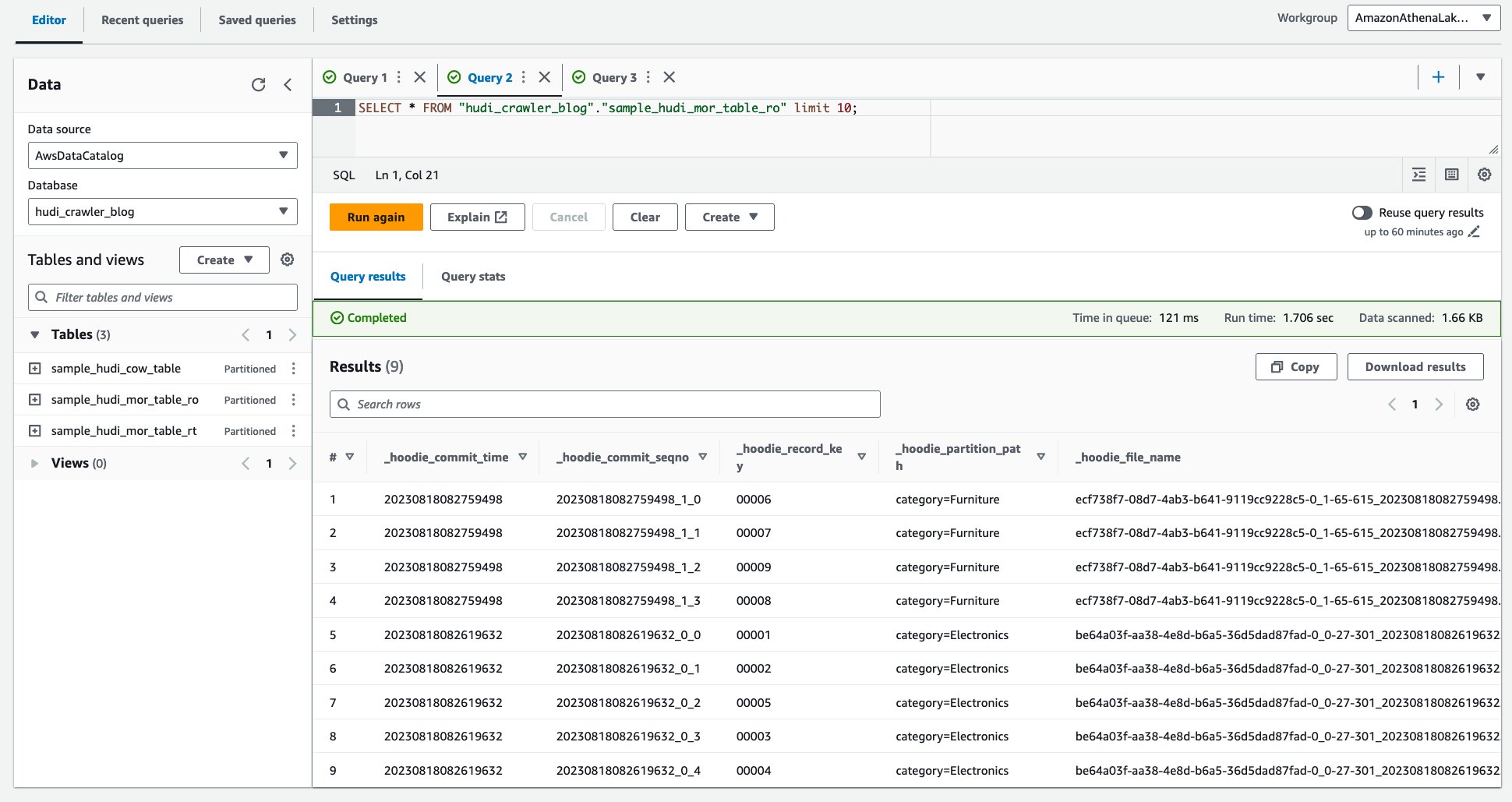
- Eseguire la query seguente.
Lo screenshot seguente mostra il nostro output:
Scansione di una tabella Hudi MoR utilizzando il crawler AWS Glue con autorizzazioni dati AWS Lake Formation
In questa sezione, esaminiamo come eseguire la scansione di una tabella Hudi MoR utilizzando AWS Glue. Questa volta, utilizzi l'autorizzazione dati AWS Lake Formation per la scansione delle origini dati Amazon S3 anziché l'autorizzazione IAM e Amazon S3. Questo è facoltativo, ma semplifica le configurazioni delle autorizzazioni quando il tuo data Lake è gestito dalle autorizzazioni AWS Lake Formation.
Prerequisiti
Ecco i prerequisiti per questo tutorial:
- Installa e configura Interfaccia a riga di comando AWS (AWS CLI).
- Crea il tuo bucket S3 se non lo possiedi.
- Crea il tuo ruolo IAM per AWS Glue se non ce l'hai. Hai bisogno
lakeformation:GetDataAccess. Ma non ne hai bisognos3:GetObjectpers3://your_s3_bucket/data/sample_hudi_mor_table/perché utilizziamo l'autorizzazione dei dati di Lake Formation per accedere ai file. - Esegui il comando seguente per copiare la tabella Hudi di esempio nel tuo bucket S3. (Sostituire
your_s3_bucketcon il nome del tuo bucket S3.)
Oltre alle fasi di elaborazione, completa le fasi seguenti per aggiornare le impostazioni del catalogo dati di AWS Glue per utilizzare le autorizzazioni Lake Formation per controllare le risorse del catalogo anziché il controllo degli accessi basato su IAM:
- Accedi alla console Lake Formation come amministratore del data Lake.
- Se è la prima volta che accedi alla console Lake Formation, aggiungiti come amministratore del data lake.
- Sotto Amministrazionescegli Impostazioni del catalogo dati.
- Nel Autorizzazioni predefinite per database e tabelle appena creati, deseleziona Utilizza solo il controllo degli accessi IAM per i nuovi database ed Utilizza solo il controllo degli accessi IAM per le nuove tabelle nei nuovi database.
- Nel Impostazione della versione di più accountscegli Versione: 3.
- Scegli Risparmi.
Il passaggio successivo consiste nel registrare il bucket S3 nelle posizioni dei data Lake Lake Formation:
- Sulla console Lake Formation, scegli Posizioni del data lakee scegli Registra posizione.
- Nel Percorso Amazon S3, accedere
s3://your_s3_bucket/. (Sostituireyour_s3_bucketcon il nome del tuo bucket S3.) - Scegli Registra posizione.
Quindi, concedi al ruolo del crawler Glue l'accesso alla posizione dei dati in modo che il crawler possa utilizzare l'autorizzazione Lake Formation per accedere ai dati e creare tabelle nella posizione:
- Sulla console Lake Formation, scegli Posizioni dei dati e scegli Grant.
- Nel Utenti e ruoli IAM, seleziona il ruolo IAM utilizzato per il crawler.
- Nel Posizione di archiviazione, accedere
s3://your_s3_bucket/data/. (Sostituireyour_s3_bucketcon il nome del tuo bucket S3.) - Scegli Grant.
Quindi, concedi il ruolo del crawler per creare tabelle nel database hudi_crawler_blog:
- Sulla console Lake Formation, scegli Autorizzazioni del data lake.
- Scegli Grant.
- Nel Principalsscegli Utenti e ruoli IAMe scegli il ruolo del crawler.
- Nel Tag LF o risorse del catalogoscegli Risorse del catalogo dati con nome.
- Nel Banca Dati, scegli il database
hudi_crawler_blog. - Sotto Permessi del database, selezionare Crea una tabella.
- Scegli Grant.
Crea un crawler Hudi con autorizzazioni per i dati di Lake Formation
Completa i seguenti passaggi per creare un crawler Hudi:
- Nella console AWS Glue, scegli Crawlers.
- Scegli Crea cingolato.
- Nel Nome, accedere
hudi_mor_crawler. Scegliere Avanti. - Sotto Configurazione dell'origine dati, scegliere Aggiungi origine dati.
- Nel Fonte di datiscegli hudi.
- Nel Includi percorsi di tabelle hudi, accedere
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Sostituireyour_s3_bucketcon il nome del tuo bucket S3.) - Scegli Aggiungi l'origine dati Hudi.
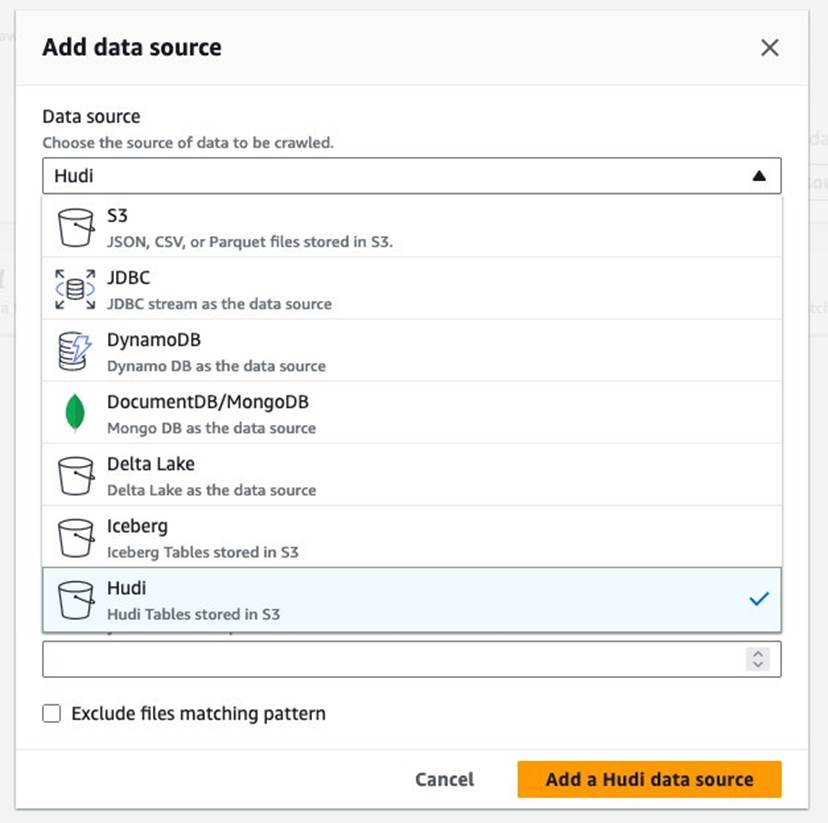
- Scegli Avanti.
- Nel Ruolo IAM esistente, scegli il tuo ruolo IAM.
- Sotto Configurazione Lake Formation – opzionale, selezionare Utilizza le credenziali di Lake Formation per la scansione dell'origine dati S3.
- Scegli Avanti.
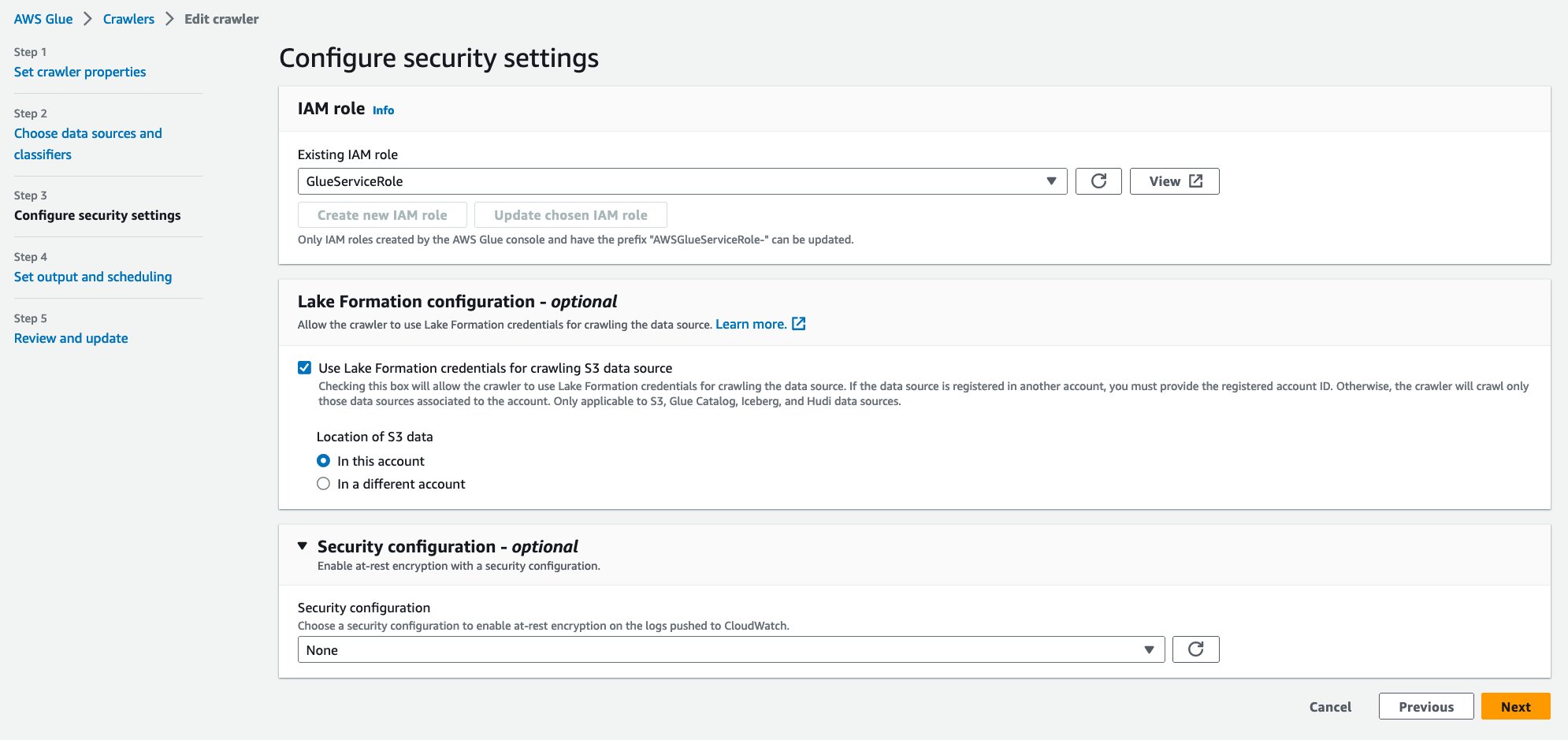
- Nel Database di destinazionescegli
hudi_crawler_blog. Scegliere Avanti. - Scegli Crea cingolato.
Ora un nuovo crawler Hudi è stato creato con successo. Il crawler utilizza le credenziali Lake Formation per eseguire la scansione dei file Amazon S3. Eseguiamo il nuovo crawler:
- Scegli Esegui crawler.
- Attendi il completamento del crawler.
Dopo l'esecuzione del crawler, puoi visualizzare due tabelle della definizione della tabella Hudi nella console AWS Glue:
sample_hudi_mor_table_ro(leggi tabella ottimizzata)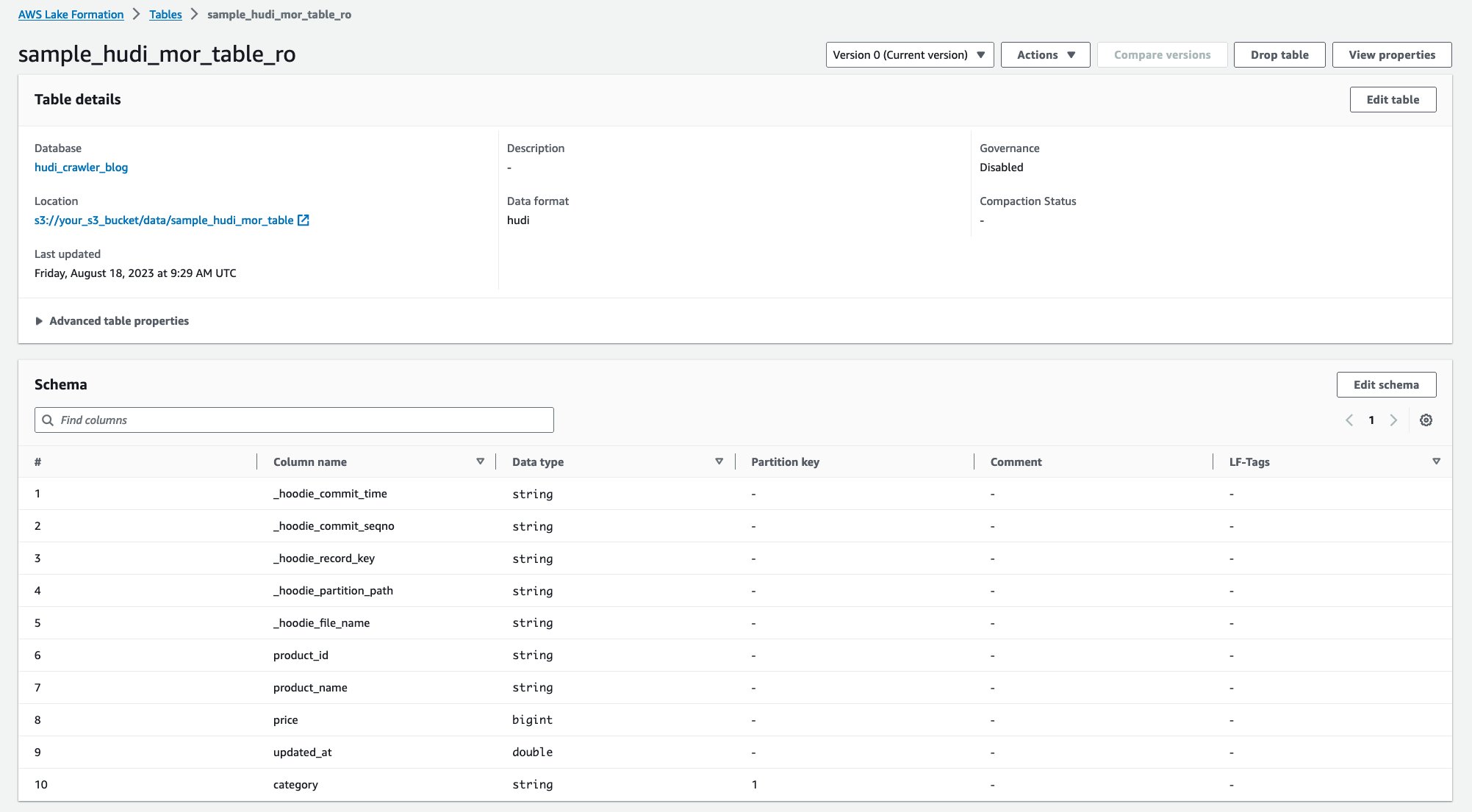
sample_hudi_mor_table_rt(tabella in tempo reale)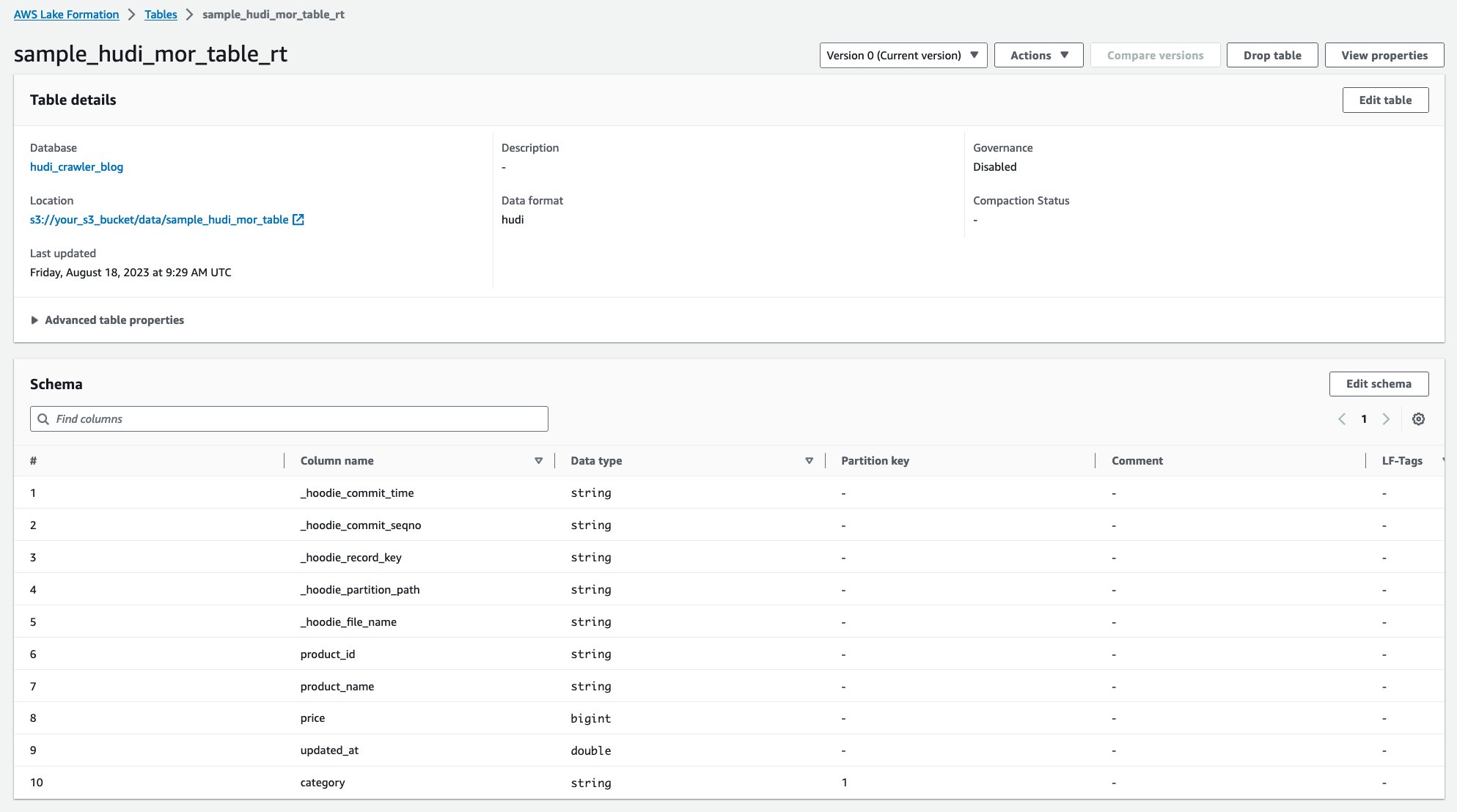
Hai registrato il bucket del data Lake con Lake Formation e hai abilitato l'accesso per la scansione al data Lake utilizzando le autorizzazioni di Lake Formation. Hai eseguito correttamente la scansione della tabella Hudi MoR con i dati su Amazon S3 e creato una tabella del catalogo dati di AWS Glue con lo schema popolato. Dopo aver creato le definizioni di tabella su AWS Glue Data Catalog, i servizi di analisi AWS come Amazon Athena sono in grado di eseguire query sulla tabella Hudi.
Completa i seguenti passaggi per avviare le query su Athena:
- Apri la console Amazon Athena.
- Eseguire la query seguente.
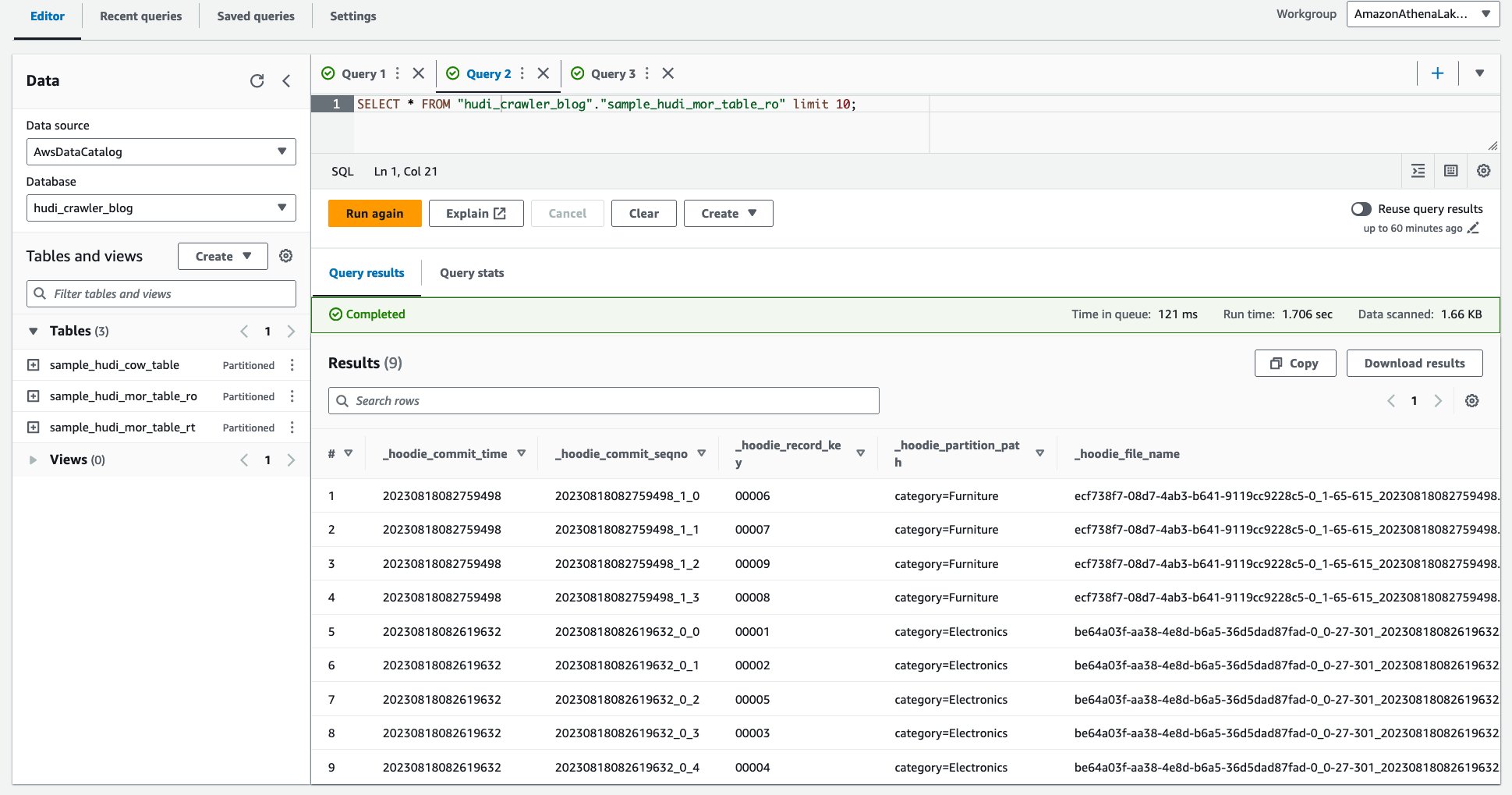
Lo screenshot seguente mostra il nostro output:
- Eseguire la query seguente.
Lo screenshot seguente mostra il nostro output:
Controllo degli accessi granulare utilizzando le autorizzazioni di AWS Lake Formation
Per applicare un controllo capillare degli accessi sulla tabella Hudi, puoi beneficiare delle autorizzazioni di AWS Lake Formation. Le autorizzazioni di Lake Formation ti consentono di limitare l'accesso a tabelle, colonne o righe specifiche e quindi eseguire query sulle tabelle Hudi tramite Amazon Athena con un controllo degli accessi granulare. Configuriamo l'autorizzazione Lake Formation per la tabella Hudi MoR.
Prerequisiti
Ecco i prerequisiti per questo tutorial:
- Completa la sezione precedente Scansione di una tabella Hudi MoR utilizzando il crawler AWS Glue con autorizzazioni dati AWS Lake Formation.
- Crea un utente IAM DataAnalyst, che dispone di policy gestite da AWS AmazonAthenaAccesso completo.
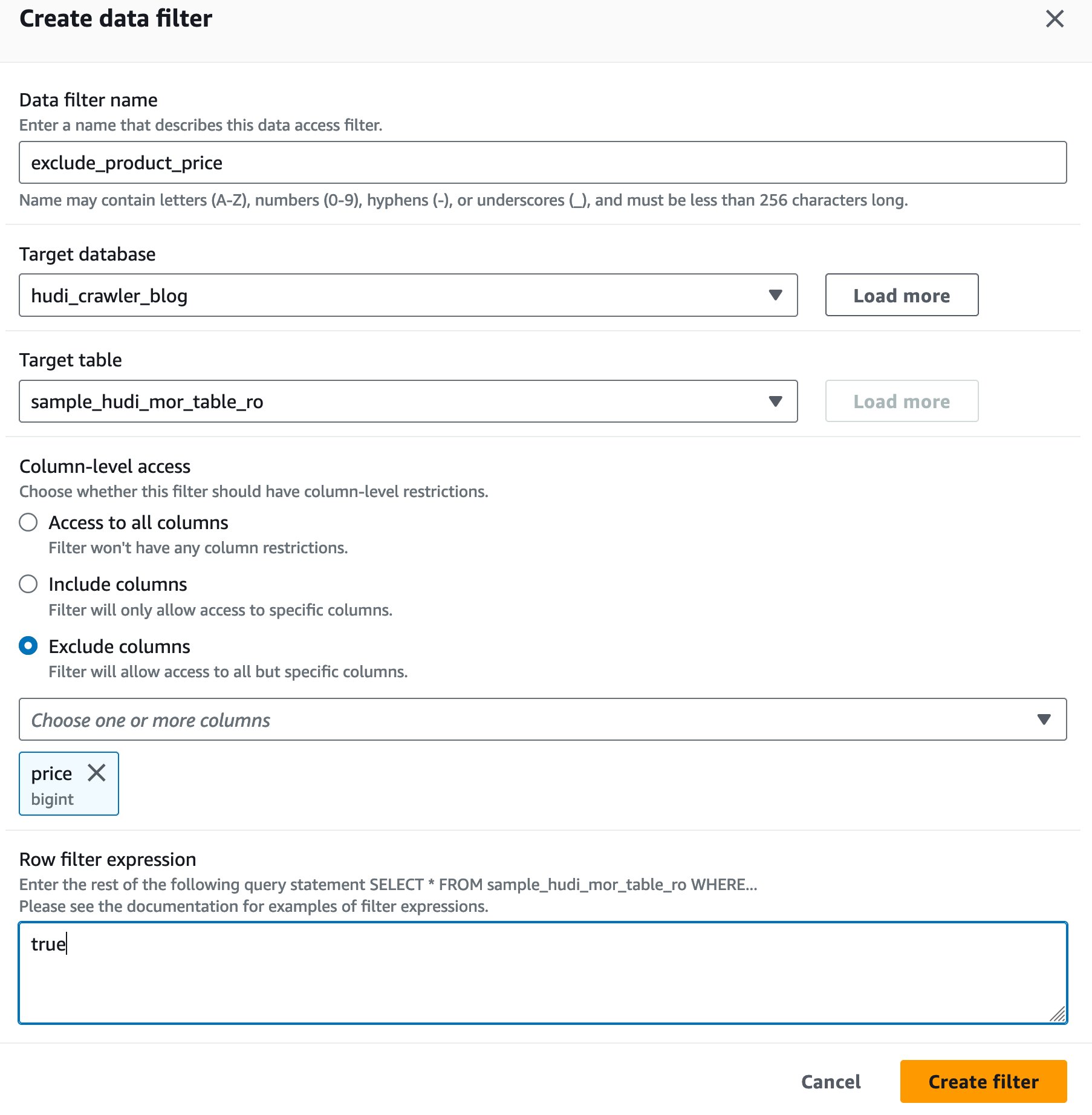
Creare un filtro della cella dati di Lake Formation
Per prima cosa impostiamo un filtro per la tabella ottimizzata per la lettura MoR.
- Accedi alla console Lake Formation come amministratore del data Lake.
- Scegli Filtri dati.
- Scegli Crea nuovo filtro.
- Nel Nome del filtro dati, accedere
exclude_product_price. - Nel Database di destinazione, scegli il database
hudi_crawler_blog. - Nel Tabella di destinazione, scegli il tavolo
sample_hudi_mor_table_ro. - Nel A livello di colonna accedere, selezionare Escludi colonnee scegli il prezzo della colonna.
- Nel Espressione del filtro di riga, accedere
true. - Scegli Crea un filtro.
Concedere le autorizzazioni Lake Formation all'utente DataAnalyst
Completa i seguenti passaggi per concedere l'autorizzazione Lake Formation a DataAnalyst Utente
- Sulla console Lake Formation, scegli Autorizzazioni del data lake.
- Scegli Grant.
- Nel Principalsscegli Utenti e ruoli IAMe scegli l'utente
DataAnalyst. - Nel Tag LF o risorse del catalogoscegli Risorse del catalogo dati con nome.
- Nel Banca Dati, scegli il database
hudi_crawler_blog. - Nel Tabella – facoltativo, scegli il tavolo
sample_hudi_mor_table_ro. - Nel Filtri dati – facoltativi, Selezionare
exclude_product_price. - Nel Autorizzazioni del filtro dati, selezionare Seleziona.
- Scegli Grant.
Hai concesso l'autorizzazione a Lake Formation sul database hudi_crawler_blog e il tavolo sample_hudi_mor_table_ro, esclusa la colonna price all'utente DataAnalyst. Ora convalidiamo l'accesso dell'utente ai dati utilizzando Athena.
- Accedi alla console Athena come utente DataAnalyst.
- Nell'editor di query, esegui la query seguente:
Lo screenshot seguente mostra il nostro output:
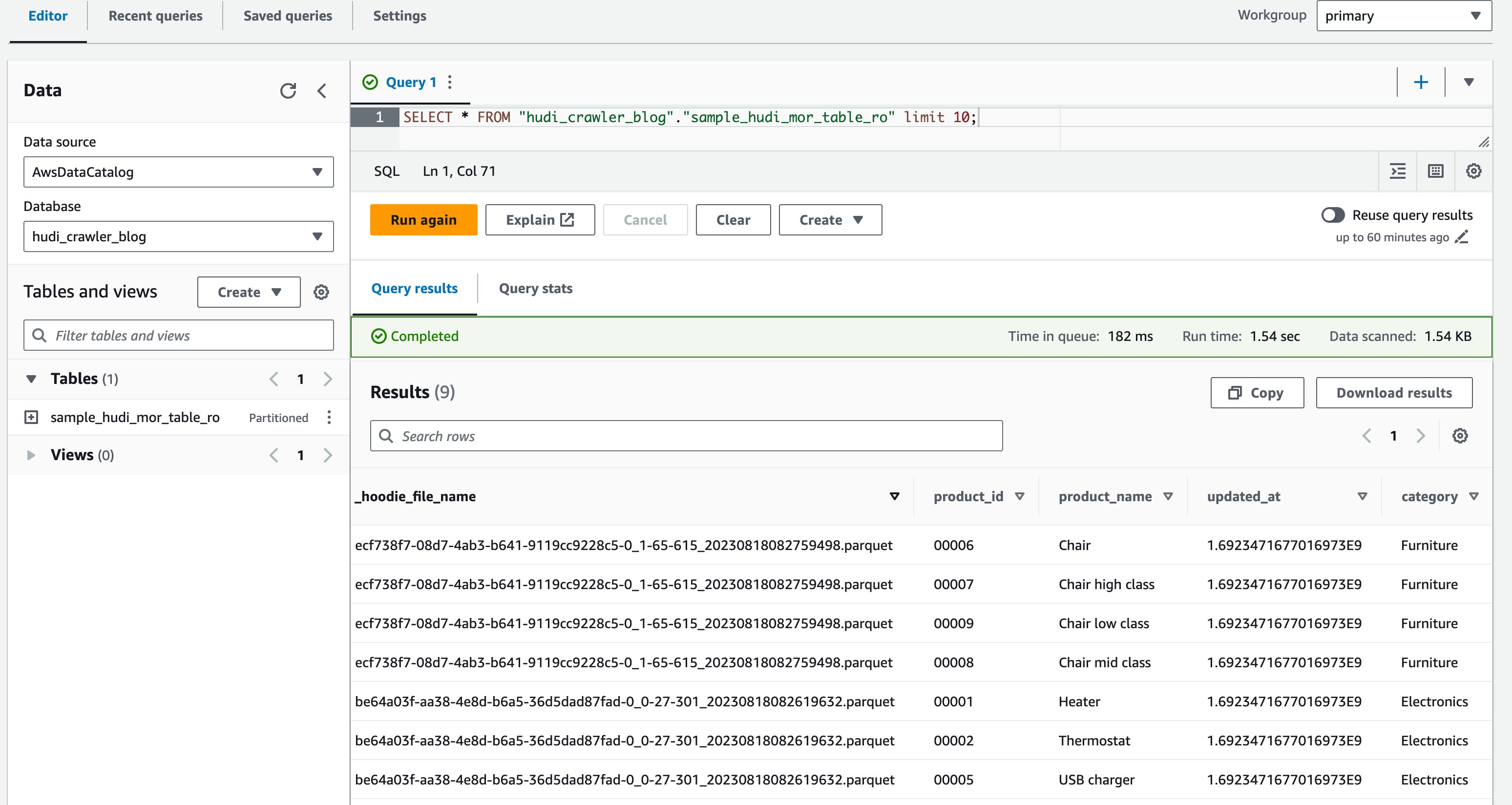
Ora hai convalidato che la colonna price non viene mostrata, ma le altre colonne product_id, product_name, update_ate category sono mostrati.
ripulire
Per evitare addebiti indesiderati sul tuo account AWS, elimina le seguenti risorse AWS:
- Elimina il database AWS Glue
hudi_crawler_blog. - Elimina i crawler di AWS Glue
hudi_cow_crawleredhudi_mor_crawler. - Elimina i file Amazon S3 in
s3://your_s3_bucket/data/sample_hudi_cow_table/eds3://your_s3_bucket/data/sample_hudi_mor_table/.
Conclusione
Questo post ha dimostrato come funzionano i crawler di AWS Glue per le tabelle Hudi. Con il supporto del crawler Hudi, puoi passare rapidamente all'utilizzo del catalogo dati di AWS Glue come catalogo di tabelle Hudi principale. Puoi iniziare a creare il tuo data Lake transazionale serverless utilizzando Hudi su AWS utilizzando AWS Glue, AWS Glue Data Catalog e i controlli di accesso granulari di Lake Formation per tabelle e formati supportati dai motori analitici AWS.
Circa gli autori
 Noritaka Sekiyama è Principal Big Data Architect nel team di AWS Glue. Lavora con sede a Tokyo, in Giappone. È responsabile della creazione di artefatti software per aiutare i clienti. Nel tempo libero ama andare in bicicletta con la sua bici da strada.
Noritaka Sekiyama è Principal Big Data Architect nel team di AWS Glue. Lavora con sede a Tokyo, in Giappone. È responsabile della creazione di artefatti software per aiutare i clienti. Nel tempo libero ama andare in bicicletta con la sua bici da strada.
 Kyle Duong è un ingegnere di sviluppo software nel team AWS Glue e Lake Formation. È appassionato di costruzione di tecnologie big data e sistemi distribuiti.
Kyle Duong è un ingegnere di sviluppo software nel team AWS Glue e Lake Formation. È appassionato di costruzione di tecnologie big data e sistemi distribuiti.
 Sandep Adwankar è Senior Technical Product Manager presso AWS. Con sede nella California Bay Area, lavora con clienti in tutto il mondo per tradurre i requisiti tecnici e aziendali in prodotti che consentono ai clienti di migliorare il modo in cui gestiscono, proteggono e accedono ai dati.
Sandep Adwankar è Senior Technical Product Manager presso AWS. Con sede nella California Bay Area, lavora con clienti in tutto il mondo per tradurre i requisiti tecnici e aziendali in prodotti che consentono ai clienti di migliorare il modo in cui gestiscono, proteggono e accedono ai dati.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :ha
- :È
- :non
- :Dove
- $ SU
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- capace
- WRI
- accesso
- Accesso ai dati
- Accedendo
- Il mio account
- Action
- aggiungere
- aggiunto
- aggiunta
- adottato
- Adozione
- Avanzate
- Dopo shavasana, sedersi in silenzio; saluti;
- Tutti
- consentire
- Consentire
- consente
- anche
- Amazon
- Amazzone Atena
- Amazon Web Services
- an
- Analitico
- analitica
- ed
- Un altro
- in qualsiasi
- Apache
- Apache Spark
- api
- appare
- Applicazioni
- Sviluppo di applicazioni
- APPLICA
- SONO
- RISERVATA
- in giro
- AS
- At
- automaticamente
- evitare
- AWS
- Colla AWS
- Formazione AWS Lake
- base
- basato
- Baia
- BE
- perché
- stato
- beneficio
- Meglio
- Big
- Big Data
- Porta
- Costruzione
- costruito
- affari
- ma
- by
- California
- chiamata
- Materiale
- funzionalità
- capacità
- Custodie
- catalogo
- cataloghi
- categoria
- cella
- sfide
- il cambiamento
- cambiato
- Modifiche
- oneri
- Scegli
- Colonna
- colonne
- combinazione
- commettere
- impegnata
- completamento di una
- complesso
- componente
- Configurazione
- consolle
- contiene
- contenuto
- continuamente
- di controllo
- controlli
- potuto
- crawler
- creare
- creato
- crea
- Credenziali
- Clienti
- dati
- integrazione dei dati
- Lago di dati
- data warehouse
- Banca Dati
- banche dati
- dataset
- definizione
- definizioni
- Delta
- dimostrato
- dimostra
- profondità
- Mercato
- direttamente
- scopri
- distribuito
- sistemi distribuiti
- do
- effettua
- durante
- ogni
- più facile
- facilmente
- editore
- in maniera efficace
- efficiente
- enable
- abilitato
- ingegnere
- Ingegneri
- Motori
- entrare
- Etere (ETH)
- evoluzione
- esclusa
- estratto
- più veloce
- meno
- Compila il
- File
- filtro
- filtri
- Trovate
- Nome
- prima volta
- i seguenti
- Nel
- formato
- formazione
- frequentemente
- da
- dato
- globo
- Go
- concedere
- concesso
- Guide
- Hadoop
- Avere
- he
- Aiuto
- aiuta
- il suo
- Alveare
- Come
- Tutorial
- HTML
- HTTPS
- IAM
- if
- implicazioni
- competenze
- in
- Compreso
- incrementale
- informazioni
- invece
- integrare
- integrazione
- Interfaccia
- ai miglioramenti
- l'introduzione di
- IT
- Giappone
- jpg
- conservazione
- lago
- laghi
- con i più recenti
- lanciare
- IMPARARE
- apprendimento
- meno
- LIMITE
- linea
- Lista
- collocato
- località
- posizioni
- registrati
- macchina
- machine learning
- mantenimento
- make
- FA
- gestire
- gestito
- direttore
- gestione
- Manuale
- massimo
- fusione
- Metadati
- la migrazione
- migrazione
- ML
- Scopri di più
- maggior parte
- cambiano
- multiplo
- Nome
- nativo
- Bisogno
- di applicazione
- New
- recentemente
- GENERAZIONE
- adesso
- of
- on
- ONE
- esclusivamente
- aprire
- open source
- ottimizzati
- Opzione
- or
- Altro
- nostro
- produzione
- parte
- appassionato
- sentiero
- percorsi
- performance
- autorizzazione
- permessi
- Platone
- Platone Data Intelligence
- PlatoneDati
- Popolare
- popolata
- Post
- Preparare
- prerequisiti
- precedente
- prezzo
- primario
- Direttore
- lavorazione
- Prodotto
- product manager
- Prodotti
- fornire
- purché
- fornisce
- query
- rapidamente
- Leggi
- di rose
- tempo reale
- in tempo reale
- recente
- record
- registro
- registrato
- sostituire
- Requisiti
- Risorse
- responsabile
- limitare
- strada
- Ruolo
- RIGA
- Correre
- stesso
- programma
- in programma
- sdk
- Sezione
- sicuro
- vedere
- select
- anziano
- serverless
- servizio
- Servizi
- set
- impostazioni
- mostrato
- Spettacoli
- semplifica
- da
- singolo
- Taglia
- Istantanea
- So
- Software
- lo sviluppo del software
- Fonte
- fonti
- Scintilla
- specifico
- inizia a
- Regione / Stato
- step
- Passi
- memorizzati
- Streaming
- flussi
- studio
- Con successo
- tale
- supporto
- supportato
- sync.
- SISTEMI DI TRATTAMENTO
- tavolo
- team
- Consulenza
- Tecnologie
- che
- Il
- loro
- poi
- Là.
- di
- questo
- tre
- Attraverso
- tempo
- volte
- a
- Tokyo
- top
- transazionale
- Le transazioni
- tradurre
- attraversare
- innescare
- innescato
- lezione
- seconda
- Tipi di
- tipico
- per
- non desiderato
- Aggiornanento
- aggiornato
- Aggiornamenti
- uso
- caso d'uso
- utilizzato
- Utente
- utenti
- usa
- utilizzando
- CONVALIDARE
- convalidato
- Valori
- versione
- visivo
- Magazzino
- we
- sito web
- servizi web
- WELL
- quando
- quale
- while
- OMS
- volere
- con
- senza
- Lavora
- lavori
- scrivere
- scritto
- Tu
- Trasferimento da aeroporto a Sharm
- te stesso
- zefiro