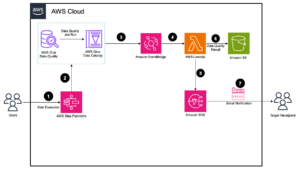
Servizio Amazon OpenSearch è un servizio gestito che semplifica la protezione, la distribuzione e il funzionamento dei cluster OpenSearch su larga scala nel cloud AWS. L'anno scorso, abbiamo introdotto Contropressione dell'indicizzazione dello shard ed controllo di ammissione, che monitora le risorse del cluster e il traffico in entrata per rifiutare in modo selettivo le richieste che altrimenti porrebbero rischi di stabilità come memoria insufficiente e impatto sulle prestazioni del cluster a causa di conflitti di memoria, saturazione della CPU e sovraccarico del GC e altro ancora.
Ora siamo entusiasti di introdurre la contropressione della ricerca e il controllo di ammissione basato sulla CPU per OpenSearch Service, che migliora ulteriormente la resilienza dei cluster. Questi miglioramenti sono disponibili per tutte le versioni di OpenSearch 1.3 o successive.
Cerca contropressione
La contropressione impedisce a un sistema di essere sopraffatto dal lavoro. Lo fa controllando la velocità del traffico o riducendo il carico eccessivo al fine di prevenire arresti anomali e perdite di dati, migliorare le prestazioni ed evitare il fallimento totale del sistema.
Search Backpressure è un meccanismo per identificare e annullare le richieste di ricerca ad alta intensità di risorse in corso quando un nodo è sotto costrizione. È efficace contro i carichi di lavoro di ricerca con un utilizzo anomalo delle risorse (come query complesse, query lente, molti hit o aggregazioni pesanti), che potrebbero altrimenti causare arresti anomali del nodo e influire sull'integrità del cluster.
Search Backpressure si basa sul framework di monitoraggio delle risorse delle attività, che fornisce un'API di facile utilizzo per monitorare l'utilizzo delle risorse di ogni attività. Search Backpressure utilizza un thread in background che misura periodicamente l'utilizzo delle risorse del nodo e assegna un punteggio di annullamento a ciascuna attività di ricerca in corso in base a fattori come il tempo della CPU, le allocazioni dell'heap e il tempo trascorso. Un punteggio di annullamento più elevato corrisponde a una richiesta di ricerca più dispendiosa in termini di risorse. Le richieste di ricerca vengono annullate in ordine decrescente rispetto al punteggio di annullamento per recuperare rapidamente i nodi, ma il numero di annullamenti è limitato in base alla frequenza per evitare lavoro dispendioso.
Il seguente diagramma illustra il flusso di lavoro Search Backpressure.
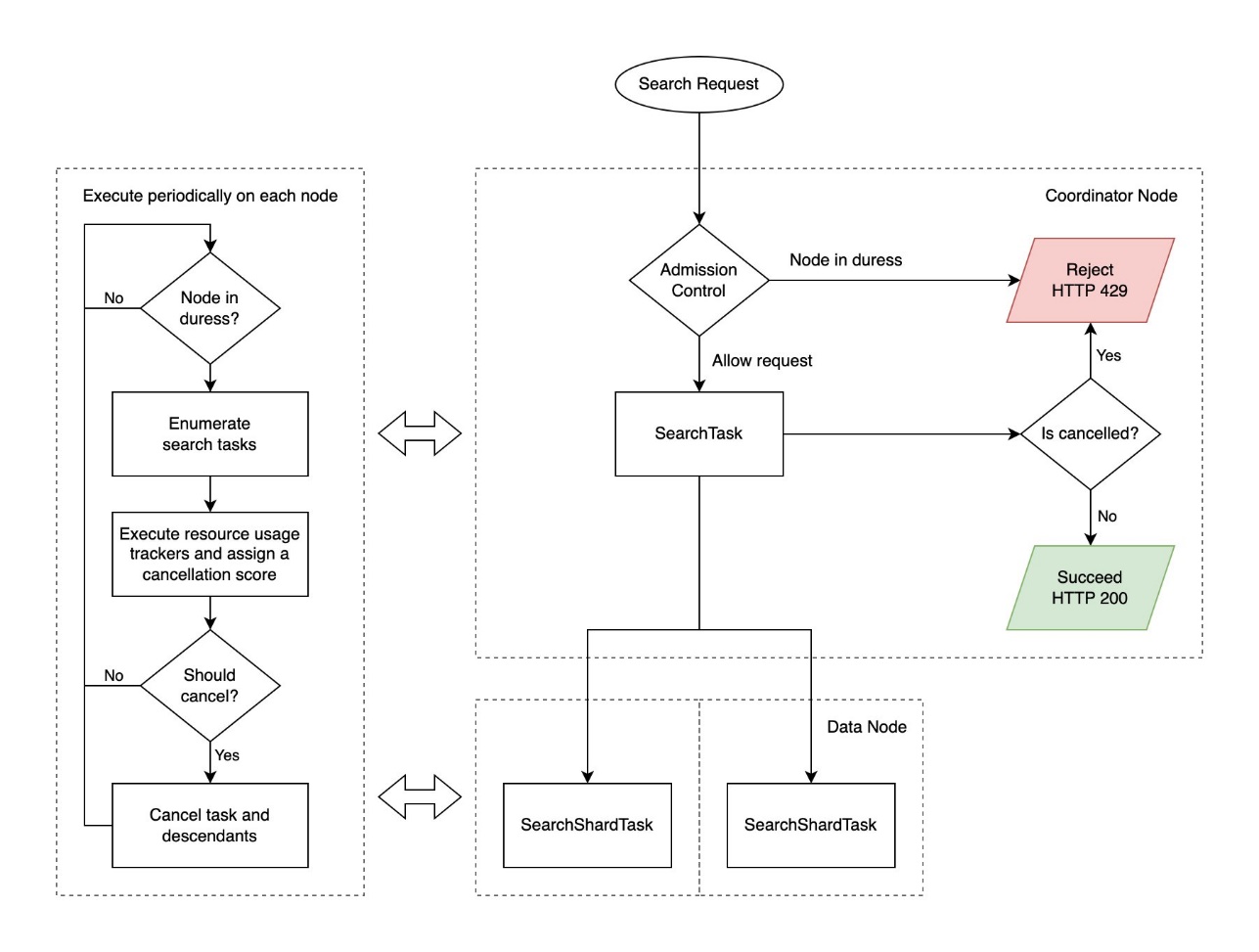
Le richieste di ricerca restituiscono un codice di stato HTTP 429 "Troppe richieste" al momento dell'annullamento. OpenSearch restituisce risultati parziali se solo alcuni shard hanno esito negativo e sono consentiti risultati parziali. Vedere il seguente codice:
Monitoraggio della contropressione della ricerca
È possibile monitorare lo stato dettagliato della contropressione della ricerca utilizzando l'API delle statistiche del nodo:
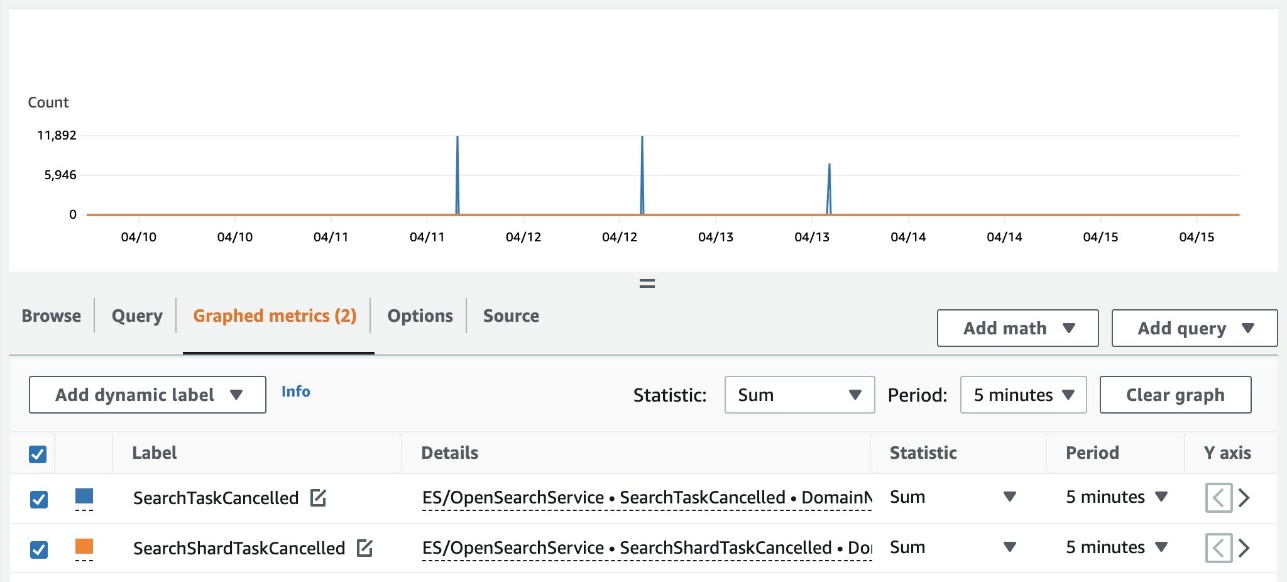
Puoi anche visualizzare il riepilogo degli annullamenti a livello di cluster utilizzando Amazon Cloud Watch. Le seguenti metriche sono ora disponibili in ES/OpenSearchService spazio dei nomi:
- SearchTaskAnnullato – Il numero di annullamenti del nodo coordinatore
- SearchShardTaskAnnullato – Il numero di cancellazioni del nodo dati
Lo screenshot seguente mostra un esempio di monitoraggio di questi parametri sulla console CloudWatch.
Controllo di ammissione basato sulla CPU
Il controllo di ammissione è un meccanismo di gatekeeping che limita in modo proattivo il numero di richieste a un nodo in base alla sua capacità attuale, sia per aumenti organici che per picchi di traffico.
Oltre alla pressione della memoria JVM e alle soglie delle dimensioni delle richieste, ora monitora anche l'utilizzo medio continuo della CPU di ciascun nodo per rifiutare i dati in entrata _search ed _bulk richieste. Impedisce ai nodi di essere sopraffatti da troppe richieste che portano a hot spot, problemi di prestazioni, timeout delle richieste e altri errori a cascata. Le richieste eccessive restituiscono un codice di stato HTTP 429 "Troppe richieste" in caso di rifiuto.
Gestione degli errori HTTP 429
Riceverai errori HTTP 429 se invii traffico eccessivo a un nodo. Indica risorse cluster insufficienti, richieste di ricerca ad alta intensità di risorse o un picco imprevisto nel carico di lavoro.
Search Backpressure fornisce il motivo del rifiuto, che può aiutare a mettere a punto le richieste di ricerca ad alta intensità di risorse. Per i picchi di traffico, consigliamo di ripetere i tentativi lato client con backoff esponenziale e jitter.
Puoi anche seguire queste guide alla risoluzione dei problemi per eseguire il debug di rifiuti eccessivi:
Conclusione
Search Backpressure è un meccanismo reattivo per ridurre il carico eccessivo, mentre il controllo di ammissione è un meccanismo proattivo per limitare il numero di richieste a un nodo oltre la sua capacità. Entrambi lavorano in tandem per migliorare la resilienza complessiva di un cluster OpenSearch.
Cerca La contropressione è disponibile in OpenSearch, e siamo sempre alla ricerca contributi esterni. Puoi fare riferimento al RFC per iniziare.
Circa gli autori
 Ketan Verma è un Senior SDE che lavora su Amazon OpenSearch Service. È appassionato di costruire sistemi distribuiti su larga scala, migliorare le prestazioni e semplificare idee complesse con semplici astrazioni. Al di fuori del lavoro, gli piace leggere e migliorare le sue capacità di barista domestico.
Ketan Verma è un Senior SDE che lavora su Amazon OpenSearch Service. È appassionato di costruire sistemi distribuiti su larga scala, migliorare le prestazioni e semplificare idee complesse con semplici astrazioni. Al di fuori del lavoro, gli piace leggere e migliorare le sue capacità di barista domestico.
 Suresh NS è un Senior SDE che lavora su Amazon OpenSearch Service. È appassionato di risolvere problemi in sistemi distribuiti su larga scala.
Suresh NS è un Senior SDE che lavora su Amazon OpenSearch Service. È appassionato di risolvere problemi in sistemi distribuiti su larga scala.
 Pritkumar Ladani è un SDE-2 che lavora su Amazon OpenSearch Service. Gli piace contribuire allo sviluppo di software open source ed è appassionato di sistemi distribuiti. È un giocatore amatoriale di badminton e ama il trekking.
Pritkumar Ladani è un SDE-2 che lavora su Amazon OpenSearch Service. Gli piace contribuire allo sviluppo di software open source ed è appassionato di sistemi distribuiti. È un giocatore amatoriale di badminton e ama il trekking.
 Bukhtawar Khan è un Principal Engineer che lavora su Amazon OpenSearch Service. È interessato alla costruzione di sistemi distribuiti e autonomi. È un manutentore e un collaboratore attivo di OpenSearch.
Bukhtawar Khan è un Principal Engineer che lavora su Amazon OpenSearch Service. È interessato alla costruzione di sistemi distribuiti e autonomi. È un manutentore e un collaboratore attivo di OpenSearch.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- EVM Finance. Interfaccia unificata per la finanza decentralizzata. Accedi qui.
- Quantum Media Group. IR/PR amplificato. Accedi qui.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/improved-resiliency-with-backpressure-and-admission-control-for-amazon-opensearch-service/
- :È
- 1
- 1.3
- 100
- 26
- 7
- 77
- a
- WRI
- attivo
- aggiunta
- contro
- Tutti
- allocazioni
- anche
- sempre
- dilettante
- Amazon
- Amazon Web Services
- an
- ed
- api
- SONO
- AS
- At
- autonomo
- sistemi autonomi
- disponibile
- media
- evitare
- AWS
- sfondo
- barista
- basato
- essendo
- Al di là di
- entrambi
- Costruzione
- costruito
- ma
- by
- Materiale
- Ultra-Grande
- Causare
- Cloud
- Cluster
- codice
- complesso
- consolle
- contribuire
- collaboratore
- di controllo
- controllo
- dell'esame
- corrisponde
- potuto
- CPU
- Corrente
- dati
- Perdita di dati
- schierare
- dettagliati
- Mercato
- distribuito
- sistemi distribuiti
- effettua
- dovuto
- ogni
- facile da usare
- Efficace
- o
- ingegnere
- Migliora
- errore
- errori
- Etere (ETH)
- esempio
- superato
- eccitato
- esponenziale
- Fattori
- FAIL
- Fallimento
- seguire
- i seguenti
- Nel
- Contesto
- da
- ulteriormente
- portineria
- ottenere
- Guide
- he
- Salute e benessere
- pesante
- Aiuto
- Alta
- superiore
- il suo
- Visualizzazioni
- Casa
- HOT
- http
- HTTPS
- idee
- identificare
- if
- illustra
- Impact
- competenze
- migliorata
- miglioramenti
- miglioramento
- in
- In arrivo
- Aumenta
- Index
- indica
- interessato
- introdurre
- introdotto
- IT
- SUO
- jpg
- grandi
- larga scala
- Cognome
- L'anno scorso
- principale
- piace
- LIMITE
- limiti
- caricare
- cerca
- spento
- FA
- gestito
- molti
- analisi
- meccanismo
- Memorie
- Metrica
- Monitorare
- monitor
- Scopri di più
- nodo
- nodi
- adesso
- numero
- of
- on
- esclusivamente
- aprire
- open source
- operare
- or
- minimo
- biologico
- Altro
- altrimenti
- su
- al di fuori
- complessivo
- sopraffatti
- appassionato
- performance
- fase
- Platone
- Platone Data Intelligence
- PlatoneDati
- giocatore
- pressione
- prevenire
- impedisce
- Direttore
- Proactive
- problemi
- fornisce
- query
- rapidamente
- tasso
- Leggi
- ragione
- ricevere
- raccomandare
- Recuperare
- richiesta
- richieste
- risorsa
- risorsa intensiva
- Risorse
- Risultati
- ritorno
- problemi
- rischi
- rotolamento
- Scala
- Punto
- Cerca
- sicuro
- vedere
- inviare
- anziano
- servizio
- Servizi
- capannone
- Spettacoli
- Un'espansione
- semplificando
- Taglia
- abilità
- rallentare
- So
- Software
- lo sviluppo del software
- Soluzione
- alcuni
- Fonte
- spuntone
- picchi
- Stabilità
- iniziato
- Regione / Stato
- stats
- Stato dei servizi
- tale
- SOMMARIO
- sistema
- SISTEMI DI TRATTAMENTO
- Tandem
- Task
- che
- Il
- loro
- Strumenti Bowman per analizzare le seguenti finiture:
- tempo
- a
- pure
- top
- Totale
- verso
- Tracking
- traffico
- vero
- Digitare
- per
- su
- Impiego
- usa
- utilizzando
- Visualizza
- Prima
- we
- sito web
- servizi web
- quando
- quale
- while
- con
- Lavora
- flusso di lavoro
- lavoro
- sarebbe
- anno
- Tu
- zefiro