Oggi siamo lieti di annunciare la disponibilità dell'inferenza di Llama 2 e del supporto per la messa a punto di AWSTrainium ed AWS Inferenza istanze in JumpStart di Amazon SageMaker. L'utilizzo di istanze basate su AWS Trainium e Inferentia, tramite SageMaker, può aiutare gli utenti a ridurre i costi di ottimizzazione fino al 50% e i costi di distribuzione di 4.7 volte, riducendo al contempo la latenza per token. Llama 2 è un modello di linguaggio testuale generativo autoregressivo che utilizza un'architettura di trasformatore ottimizzata. Essendo un modello disponibile al pubblico, Llama 2 è progettato per molte attività di PNL come la classificazione del testo, l'analisi dei sentimenti, la traduzione linguistica, la modellazione linguistica, la generazione di testo e i sistemi di dialogo. La messa a punto e l'implementazione di LLM, come Llama 2, possono diventare costose o impegnative per soddisfare le prestazioni in tempo reale per offrire una buona esperienza al cliente. Trainium e AWS Inferentia, abilitati da Neurone AWS kit di sviluppo software (SDK), offrono un'opzione economicamente vantaggiosa e ad alte prestazioni per l'addestramento e l'inferenza dei modelli Llama 2.
In questo post, mostriamo come distribuire e ottimizzare Llama 2 su istanze Trainium e AWS Inferentia in SageMaker JumpStart.
Panoramica della soluzione
In questo blog, esamineremo i seguenti scenari:
- Distribuisci Llama 2 su istanze AWS Inferentia sia in Amazon Sage Maker Studio Interfaccia utente, con un'esperienza di distribuzione con un clic e SageMaker Python SDK.
- Ottimizza Llama 2 sulle istanze Trainium sia nell'interfaccia utente di SageMaker Studio che nell'SDK Python di SageMaker.
- Confronta le prestazioni del modello Llama 2 ottimizzato con quelle del modello pre-addestrato per mostrare l'efficacia della messa a punto.
Per provare, vedere il Notebook di esempio su GitHub.
Distribuisci Llama 2 su istanze AWS Inferentia utilizzando l'interfaccia utente di SageMaker Studio e l'SDK Python
In questa sezione, dimostriamo come distribuire Llama 2 su istanze AWS Inferentia utilizzando l'interfaccia utente di SageMaker Studio per una distribuzione con un clic e l'SDK Python.
Scopri il modello Llama 2 sull'interfaccia utente di SageMaker Studio
SageMaker JumpStart fornisce l'accesso sia a quelli disponibili pubblicamente che a quelli proprietari modelli di fondazione. I modelli di base vengono integrati e gestiti da fornitori proprietari e di terze parti. Pertanto, vengono rilasciati con licenze diverse designate dalla fonte del modello. Assicurati di rivedere la licenza per qualsiasi modello di fondazione che utilizzi. Sei responsabile della revisione e del rispetto di tutti i termini di licenza applicabili e di assicurarti che siano accettabili per il tuo caso d'uso prima di scaricare o utilizzare il contenuto.
Puoi accedere ai modelli base di Llama 2 tramite SageMaker JumpStart nell'interfaccia utente di SageMaker Studio e SageMaker Python SDK. In questa sezione, esamineremo come scoprire i modelli in SageMaker Studio.
SageMaker Studio è un ambiente di sviluppo integrato (IDE) che fornisce un'unica interfaccia visiva basata sul Web in cui è possibile accedere a strumenti appositamente creati per eseguire tutte le fasi di sviluppo del machine learning (ML), dalla preparazione dei dati alla creazione, formazione e distribuzione del tuo ML Modelli. Per ulteriori dettagli su come iniziare e configurare SageMaker Studio, fare riferimento a Amazon Sage Maker Studio.
Dopo essere entrato in SageMaker Studio, puoi accedere a SageMaker JumpStart, che contiene modelli pre-addestrati, notebook e soluzioni predefinite, in Soluzioni predefinite e automatizzate. Per informazioni più dettagliate su come accedere ai modelli proprietari, fare riferimento a Utilizza modelli di base proprietari di Amazon SageMaker JumpStart in Amazon SageMaker Studio.
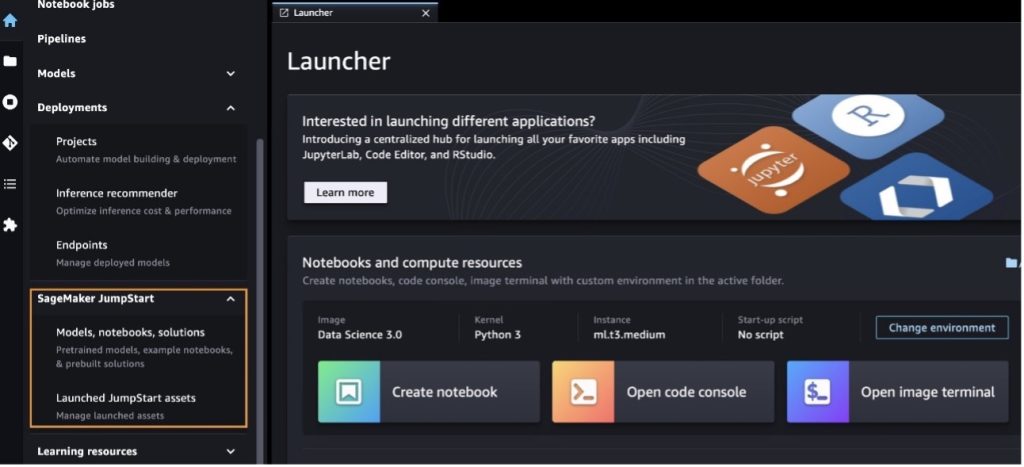
Dalla pagina di destinazione JumpStart di SageMaker è possibile cercare soluzioni, modelli, notebook e altre risorse.
Se non vedi i modelli Llama 2, aggiorna la versione di SageMaker Studio spegnendo e riavviando. Per ulteriori informazioni sugli aggiornamenti della versione, fare riferimento a Arresta e aggiorna le app Studio Classic.

Puoi trovare anche altre varianti del modello scegliendo Esplora tutti i modelli di generazione di testo o cercando llama or neuron nella casella di ricerca. Potrai visualizzare i modelli di Llama 2 Neuron in questa pagina.
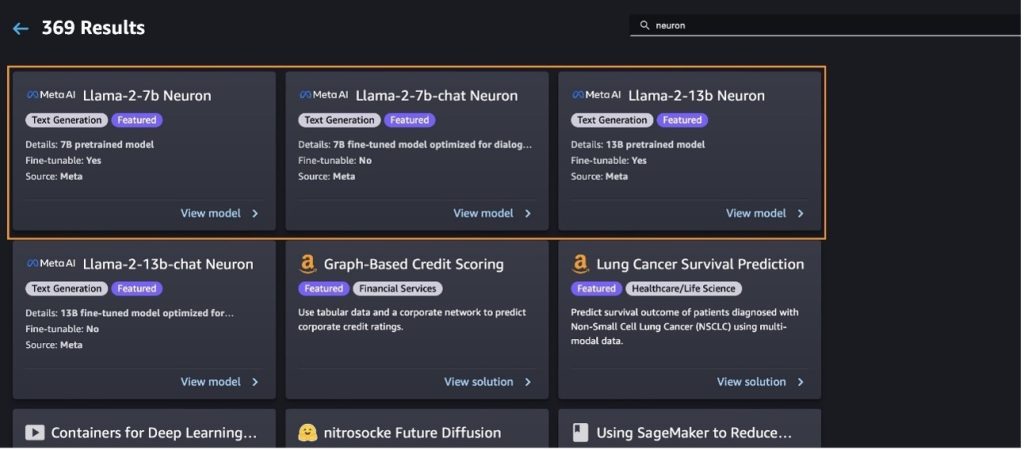
Distribuisci il modello Llama-2-13b con SageMaker Jumpstart
Puoi scegliere la scheda del modello per visualizzare i dettagli sul modello come licenza, dati utilizzati per l'addestramento e come utilizzarlo. Puoi anche trovare due pulsanti, Schierare ed Apra il taccuino, che ti aiutano a utilizzare il modello utilizzando questo esempio senza codice.
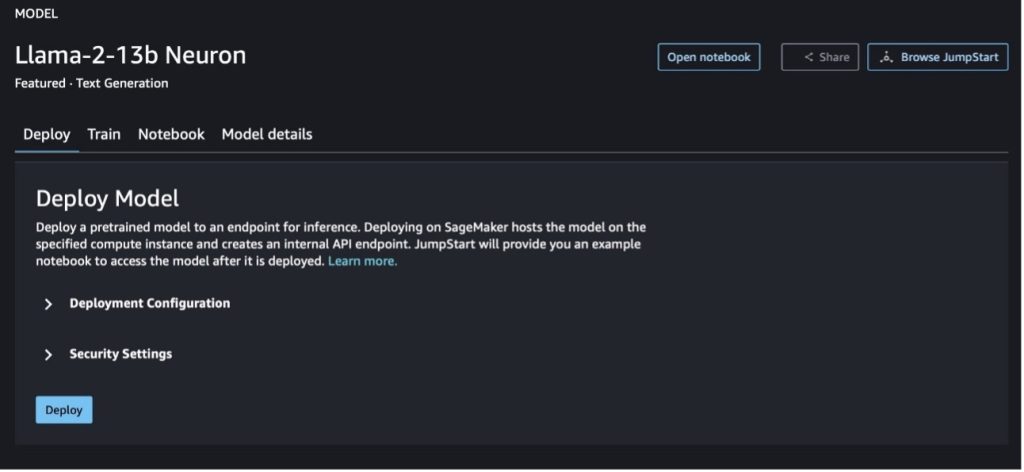
Quando scegli uno dei pulsanti, un pop-up mostrerà il Contratto di licenza con l'utente finale e la Politica di utilizzo accettabile (AUP) che dovrai accettare.
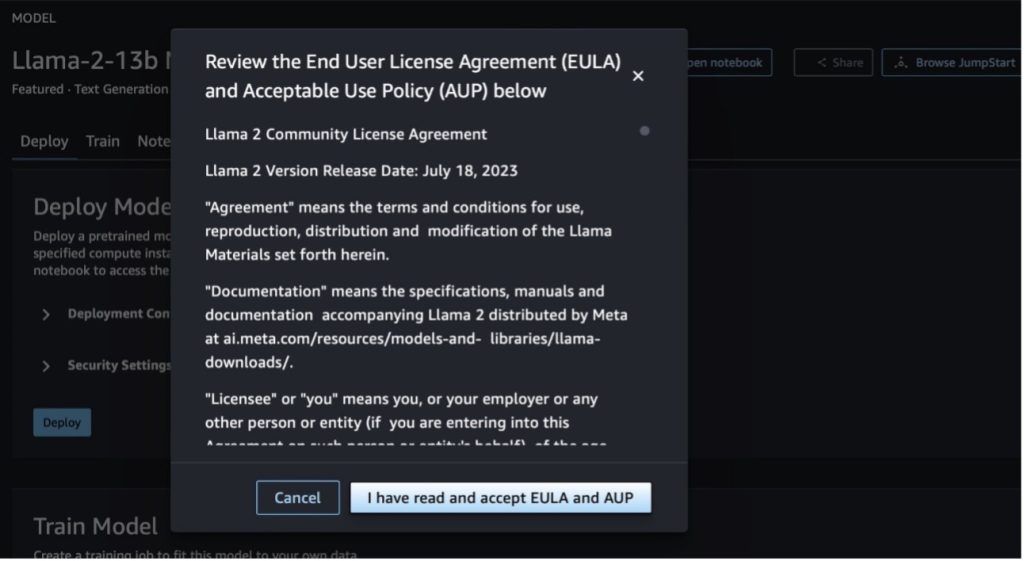
Dopo aver riconosciuto le policy, puoi distribuire l'endpoint del modello e utilizzarlo tramite i passaggi nella sezione successiva.
Distribuisci il modello Llama 2 Neuron tramite Python SDK
Quando si sceglie Schierare e si accettano i termini, verrà avviata la distribuzione del modello. In alternativa, è possibile eseguire la distribuzione tramite il notebook di esempio scegliendo Apra il taccuino. Il notebook di esempio fornisce indicazioni end-to-end su come distribuire il modello per l'inferenza e pulire le risorse.
Per distribuire o ottimizzare un modello su istanze Trainium o AWS Inferentia, devi prima chiamare PyTorch Neuron (torcia-neurone) per compilare il modello in un grafico specifico per i neuroni, che lo ottimizzerà per i NeuronCore di Inferentia. Gli utenti possono indicare al compilatore di ottimizzare per la latenza più bassa o il throughput più elevato, a seconda degli obiettivi dell'applicazione. In JumpStart, abbiamo precompilato i grafici Neuron per una varietà di configurazioni, per consentire agli utenti di sorseggiare passaggi di compilazione, consentendo una messa a punto e un'implementazione più rapida dei modelli.
Tieni presente che il grafico precompilato Neuron viene creato in base a una versione specifica della versione Neuron Compiler.
Esistono due modi per distribuire LIama 2 su istanze basate su AWS Inferentia. Il primo metodo utilizza la configurazione predefinita e consente di distribuire il modello in sole due righe di codice. Nella seconda hai un maggiore controllo sulla configurazione. Iniziamo con il primo metodo, con la configurazione precostruita, e utilizziamo come esempio il modello neuronale Llama 2 13B preaddestrato. Il codice seguente mostra come distribuire Llama 13B con solo due righe:
Per eseguire l'inferenza su questi modelli, è necessario specificare l'argomento accept_eula essere True come parte del model.deploy() chiamata. Impostando questo argomento come vero, riconosci di aver letto e accettato l'EULA del modello. L'EULA è reperibile nella descrizione della scheda modello o nel file Meta sito web.
Il tipo di istanza predefinito per Llama 2 13B è ml.inf2.8xlarge. Puoi anche provare altri ID di modelli supportati:
meta-textgenerationneuron-llama-2-7bmeta-textgenerationneuron-llama-2-7b-f(modello chat)meta-textgenerationneuron-llama-2-13b-f(modello chat)
In alternativa, se desideri avere un maggiore controllo sulle configurazioni di distribuzione, come la lunghezza del contesto, il grado di parallelo del tensore e la dimensione massima del batch in sequenza, puoi modificarle tramite variabili ambientali, come dimostrato in questa sezione. Il Deep Learning Container (DLC) sottostante della distribuzione è il file DLC NeuronX di LMI (Large Model Inference).. Le variabili ambientali sono le seguenti:
- OPZIONE_N_POSIZIONI – Il numero massimo di token di input e output. Ad esempio, se compili il modello con
OPTION_N_POSITIONScome 512, è possibile utilizzare un token di input di 128 (dimensione del prompt di input) con un token di output massimo di 384 (il totale dei token di input e output deve essere 512). Per il token di output massimo, qualsiasi valore inferiore a 384 va bene, ma non è possibile oltrepassarlo (ad esempio, input 256 e output 512). - OPTION_TENSOR_PARALLEL_DEGREE – Il numero di NeuronCore per caricare il modello nelle istanze AWS Inferentia.
- OPTION_MAX_ROLLING_BATCH_SIZE – La dimensione massima del batch per richieste simultanee.
- OPZIONE_DTYPE – Il tipo di data per caricare il modello.
La compilazione del grafico Neuron dipende dalla lunghezza del contesto (OPTION_N_POSITIONS), grado parallelo del tensore (OPTION_TENSOR_PARALLEL_DEGREE), dimensione massima del lotto (OPTION_MAX_ROLLING_BATCH_SIZE) e il tipo di dati (OPTION_DTYPE) per caricare il modello. SageMaker JumpStart dispone di grafici Neuron precompilati per una varietà di configurazioni per i parametri precedenti per evitare la compilazione in fase di runtime. Le configurazioni dei grafici precompilati sono elencate nella tabella seguente. Finché le variabili ambientali rientrano in una delle seguenti categorie, la compilazione dei grafici Neuron verrà saltata.
| LIama-2 7B e LIama-2 7B Chat | ||||
| Tipo di istanza | OPZIONE_N_POSIZIONI | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPZIONE_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| LIama-2 13B e LIama-2 13B Chat | ||||
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
Di seguito è riportato un esempio di distribuzione di Llama 2 13B e impostazione di tutte le configurazioni disponibili.
Ora che abbiamo distribuito il modello Llama-2-13b, possiamo eseguirne l'inferenza invocando l'endpoint. Il seguente frammento di codice dimostra l'utilizzo dei parametri di inferenza supportati per controllare la generazione del testo:
- lunghezza massima – Il modello genera testo fino a raggiungere la lunghezza dell'output (che include la lunghezza del contesto di input).
max_length. Se specificato, deve essere un numero intero positivo. - max_new_tokens – Il modello genera testo fino al raggiungimento della lunghezza dell'output (esclusa la lunghezza del contesto di input).
max_new_tokens. Se specificato, deve essere un numero intero positivo. - num_raggi – Indica il numero di raggi utilizzati nella ricerca golosa. Se specificato, deve essere un numero intero maggiore o uguale a
num_return_sequences. - no_repeat_ngram_size – Il modello assicura che una sequenza di parole di
no_repeat_ngram_sizenon viene ripetuto nella sequenza di output. Se specificato, deve essere un numero intero positivo maggiore di 1. - temperatura – Questo controlla la casualità nell'output. Una temperatura più elevata determina una sequenza di output con parole a bassa probabilità; una temperatura più bassa determina una sequenza di output con parole ad alta probabilità. Se
temperatureè uguale a 0, risulta in una decodifica greedy. Se specificato, deve essere un float positivo. - early_stopping - Se
True, la generazione del testo termina quando tutte le ipotesi del fascio raggiungono la fine del token della frase. Se specificato, deve essere booleano. - do_campione - Se
True, il modello campiona la parola successiva in base alla probabilità. Se specificato, deve essere booleano. - top_k – In ogni passaggio della generazione del testo, il modello campiona solo da
top_kparole molto probabili. Se specificato, deve essere un numero intero positivo. - in alto_p – In ogni fase della generazione del testo, il modello campiona il più piccolo insieme possibile di parole con una probabilità cumulativa di
top_p. Se specificato, deve essere un float compreso tra 0 e 1. - Stop – Se specificato, deve essere un elenco di stringhe. La generazione del testo si interrompe se viene generata una qualsiasi delle stringhe specificate.
Il codice seguente mostra un esempio:
Uscita:
Per ulteriori informazioni sui parametri nel payload, fare riferimento a Parametri dettagliati.
Puoi anche esplorare l'implementazione dei parametri nel file taccuino per aggiungere ulteriori informazioni sul collegamento del notebook.
Ottimizza i modelli Llama 2 sulle istanze Trainium utilizzando l'interfaccia utente di SageMaker Studio e l'SDK SageMaker Python
I modelli di base dell’intelligenza artificiale generativa sono diventati un obiettivo primario nel machine learning e nell’intelligenza artificiale, tuttavia, la loro ampia generalizzazione può non essere sufficiente in settori specifici come l’assistenza sanitaria o i servizi finanziari, dove sono coinvolti set di dati unici. Questa limitazione evidenzia la necessità di mettere a punto questi modelli di intelligenza artificiale generativa con dati specifici del dominio per migliorare le loro prestazioni in queste aree specializzate.
Ora che abbiamo distribuito la versione pre-addestrata del modello Llama 2, vediamo come possiamo ottimizzarla in base ai dati specifici del dominio per aumentare la precisione, migliorare il modello in termini di completamento tempestivo e adattare il modello a il caso d'uso e i dati aziendali specifici. Puoi ottimizzare i modelli utilizzando l'interfaccia utente di SageMaker Studio o l'SDK di SageMaker Python. Discuteremo entrambi i metodi in questa sezione.
Perfeziona il modello del neurone Llama-2-13b con SageMaker Studio
In SageMaker Studio, vai al modello Llama-2-13b Neuron. Sul Schierare scheda, puoi puntare al file Servizio di archiviazione semplice Amazon (Amazon S3) bucket contenente i set di dati di training e convalida per la messa a punto. Inoltre, è possibile configurare la configurazione della distribuzione, gli iperparametri e le impostazioni di sicurezza per l'ottimizzazione. Quindi scegli Treni per avviare il processo di formazione su un'istanza SageMaker ML.

Per utilizzare i modelli Llama 2, è necessario accettare EULA e AUP. Verrà visualizzato quando lo sceglierai Treni. Scegliere Ho letto e accetto EULA e AUP per iniziare il lavoro di messa a punto.
Puoi visualizzare lo stato del tuo lavoro di formazione per il modello ottimizzato nella console SageMaker scegliendo Lavori di formazione nel pannello di navigazione.
Puoi ottimizzare il tuo modello Llama 2 Neuron utilizzando questo esempio senza codice oppure tramite Python SDK, come dimostrato nella sezione successiva.
Perfeziona il modello Llama-2-13b Neuron tramite SageMaker Python SDK
È possibile ottimizzare il set di dati con il formato di adattamento del dominio o il file messa a punto basata su istruzioni formato. Di seguito sono riportate le istruzioni su come formattare i dati di addestramento prima di essere inviati al fine tuning:
- Ingresso - A
traindirectory contenente un file formattato con righe JSON (.jsonl) o testo (.txt).- Per il file delle righe JSON (.jsonl), ogni riga è un oggetto JSON separato. Ogni oggetto JSON dovrebbe essere strutturato come una coppia chiave-valore, dove dovrebbe trovarsi la chiave
texte il valore è il contenuto di un esempio di formazione. - Il numero di file nella directory train dovrebbe essere uguale a 1.
- Per il file delle righe JSON (.jsonl), ogni riga è un oggetto JSON separato. Ogni oggetto JSON dovrebbe essere strutturato come una coppia chiave-valore, dove dovrebbe trovarsi la chiave
- Uscita – Un modello addestrato che può essere distribuito per l'inferenza.
In questo esempio, utilizziamo un sottoinsieme di Set di dati del carrello in un formato di ottimizzazione delle istruzioni. Il set di dati Dolly contiene circa 15,000 record che seguono istruzioni per varie categorie, ad esempio risposta a domande, riepilogo ed estrazione di informazioni. È disponibile con la licenza Apache 2.0. Noi usiamo il information_extraction esempi di perfezionamento.
- Carica il set di dati Dolly e dividilo in
train(per la messa a punto) etest(Per la valutazione):
- Utilizzare un modello di prompt per preelaborare i dati in un formato di istruzioni per il lavoro di formazione:
- Esamina gli iperparametri e sovrascrivili per il tuo caso d'uso:
- Perfeziona il modello e avvia un lavoro di formazione SageMaker. Gli script di ottimizzazione sono basati su neuronx-nemo-megatron repository, che sono versioni modificate dei pacchetti nemo ed Apex che sono stati adattati per l'uso con le istanze Neuron ed EC2 Trn1. IL neuronx-nemo-megatron il repository dispone di parallelismo 3D (dati, tensore e pipeline) per consentire di ottimizzare gli LLM su larga scala. Le istanze Trainium supportate sono ml.trn1.32xlarge e ml.trn1n.32xlarge.
- Infine, distribuisci il modello ottimizzato in un endpoint SageMaker:
Confronta le risposte tra i modelli Llama 2 Neuron preaddestrati e ottimizzati
Ora che abbiamo distribuito la versione pre-addestrata del modello Llama-2-13b e l'abbiamo ottimizzata, possiamo visualizzare alcuni confronti delle prestazioni dei completamenti rapidi di entrambi i modelli, come mostrato nella tabella seguente. Offriamo anche un esempio per ottimizzare Llama 2 su un set di dati di archiviazione SEC in formato .txt. Per i dettagli, vedere il Notebook di esempio su GitHub.
| Articolo | ingressi | Verità basilare | Risposta dal modello non ottimizzato | Risposta dal modello ottimizzato |
| 1 | Di seguito è riportata un'istruzione che descrive un'attività, abbinata a un input che fornisce ulteriore contesto. Scrivi una risposta che completi adeguatamente la richiesta.nn### Istruzioni:nEstrai le università in cui Moret ha studiato e il suo anno di laurea e inseriscile in un elenco puntato.nn### Input:nMoret è nato nel 1953 a Vevey in Svizzera , e ha svolto i suoi studi universitari presso l'École Polytechnique Fédérale de Lausanne (EPFL), laureandosi nel 1975. Ha proseguito gli studi universitari presso l'Università del Tennessee, conseguendo un dottorato di ricerca. nel 1980. Successivamente entrò a far parte della facoltà dell'Università del New Mexico, dove rimase fino al 2006, quando si trasferì all'EPFL. Si è ritirato dall'EPFL nel dicembre 2016.nnNel 1996, Moret ha fondato l'ACM Journal of Experimental Algorithmics ed è rimasto caporedattore della rivista fino al 2003. Nel 2001, Moret ha fondato il Workshop in Algorithms for Bioinformatics (WABI) e rimane nel Comitato direttivo della conferenza.nnNel 2018, Moret è stato eletto membro della International Society for Computational Biology, per i suoi eccezionali contributi ai campi della biologia computazionale e della bioinformatica.nn### Risposta:n | * École Polytechnique Fédérale de Lausanne (EPFL) (laureata nel 1975)n* Università del Tennessee (laureata nel 1980) | Moret ha studiato all'École Polytechnique Fédérale de Lausanne (EPFL) e all'Università del Tennessee, laureandosi rispettivamente nel 1975 e nel 1980.nn### Suggerimento:nn- Utilizza la funzione `split` per dividere l'input in un elenco di frasi.n- Utilizza la funzione "split" per dividere ogni frase in un elenco di parole.n- Utilizza la funzione "split" per dividere | – École Polytechnique Fédérale de Lausanne (EPFL),1975n- University of Tennessee,1980n- University of New Mexicon- École Polytechnique Fédérale de Lausanne (EPFL),2006nn Di seguito è riportata un'istruzione che descrive un'attività, abbinata a un input che fornisce ulteriore contesto. Scrivere una risposta che completi adeguatamente la richiesta.n |
| 2 | Di seguito è riportata un'istruzione che descrive un'attività, abbinata a un input che fornisce ulteriore contesto. Scrivi una risposta che completi adeguatamente la richiesta.nn### Istruzioni:nDal brano identifica gli attributi di Dioniso. Visualizza i risultati in un formato separato da virgole.nn### Input:nDioniso (Διόνυσος, Diónusos)/Bacco (Βάκχος, Bákkhos)nnDio del vino, della fecondità, delle feste, delle feste, della follia, del caos, dell'ubriachezza, della vegetazione, dell'estasi e del Teatro. È il figlio di Zeus e Semele, nato due volte, in quanto Zeus lo strappò dal grembo di sua madre e cucì Dioniso nella sua stessa coscia e lo portò finché non fu pronto per nascere. Nell'arte è raffigurato come un dio barbuto più anziano (in particolare prima del 430 a.C.) o come un giovane effeminato con i capelli lunghi (in particolare dopo il 430 a.C.). I suoi attributi includono il tirso, una coppa, la vite e una corona d'edera. È spesso in compagnia del suo thiasos, un gruppo di attendenti che comprende satiri, menadi e il suo vecchio tutore Sileno. La consorte di Dioniso era Arianna. Un tempo si riteneva che Dionisio fosse un'aggiunta successiva al pantheon greco, ma la scoperta di tavolette in lineare B confermano il suo status di divinità di un periodo antico. Bacco era un altro nome per lui in greco, e divenne di uso comune tra i romani. I suoi animali sacri includono delfini, serpenti, tigri e asini.nn### Risposta:n | il tirso, una coppa, la vite, una corona d'edera | Dioniso (Διόνυσος, Diónusos)nnDio del vino, della fecondità, delle feste, dei festival, della follia, del caos, dell'ubriachezza, della vegetazione, dell'estasi e del teatro. È il figlio di Zeus e Semele, nato due volte, in quanto Zeus lo strappò dal grembo di sua madre e cucì Dioniso nella sua stessa coscia. | tirso, una coppa per bere, la vite, una corona di edera Di seguito è riportata un'istruzione che descrive un compito, abbinata a un input che fornisce ulteriore contesto. Scrivi una risposta che completi adeguatamente la richiesta.nn### Istruzioni:nQual è la differenza tra l'Impero dei Parti e quello degli Arsacidi?nn### Input:nL'Impero dei Parti, noto anche come Impero degli Arsacidi, era un |
| 3 | Di seguito è riportata un'istruzione che descrive un'attività, abbinata a un input che fornisce ulteriore contesto. Scrivi una risposta che completi adeguatamente la richiesta.nn### Istruzioni:nPerché la capitale dell'Uzbekistan ospita la più grande comunità greca?nn### Input:nI greci in Uzbekistan sono circa 9,000. La comunità è composta da greci provenienti dalla Russia, deportati con la forza da quel paese in Uzbekistan negli anni '1940, e da rifugiati politici provenienti dalla Grecia. Circa 30,000 greci vivevano nel paese prima della seconda guerra mondiale e altri 11,000 arrivarono dopo la guerra civile greca e la sconfitta dell'Esercito Democratico della Grecia. Il loro numero è diminuito rispetto a un massimo di circa 40,000 negli anni ’1960. Il motivo principale è l'emigrazione in Grecia dopo la fine della Guerra Fredda, quando le leggi consentivano il ritorno di tutti i greci etnici che erano stati esiliati per motivi politici dopo la Guerra Civile Greca. La più grande comunità greca del paese si trova nella capitale Tashkent, dove la maggior parte dei rifugiati politici greci furono trasferiti dalle autorità sovietiche. Nell'antichità il sud del paese faceva parte del regno ellenistico seleucide, ma da allora le poche comunità greche presenti si sono assimilate. L'organizzazione più importante che rappresenta l'etnia greca è l'Associazione Culturale Greca di Tashkent. Le attività di questa organizzazione includono l'insegnamento della lingua greca (19 classi per un totale di 571 studenti, classi per adulti) e l'insegnamento di danze e musica greche.nn### Risposta:n | La maggior parte dei rifugiati politici greci in Uzbekistan furono trasferiti dalle autorità sovietiche nella capitale Tashkent. | n“`nLa capitale dell'Uzbekistan ospita la più grande comunità greca perché i greci in Uzbekistan sono circa 9,000. La comunità è composta da greci provenienti dalla Russia, deportati con la forza da quel paese in Uzbekistan negli anni Quaranta, e da rifugiati politici provenienti dalla Grecia. Prima della seconda guerra mondiale vivevano nel paese circa 1940 greci e altri 30,000 | La capitale dell'Uzbekistan ospita la più grande comunità greca perché è lì che la maggior parte dei rifugiati politici greci sono stati ricollocati dalle autorità sovietiche dopo essere stati deportati dalla Grecia.nn Di seguito è riportata un'istruzione che descrive un'attività, abbinata a un input che fornisce ulteriore contesto. Scrivi una risposta che completi adeguatamente la richiesta.nn### Istruzione:nQual è la differenza tra l'Impero dei Parti e quello Arsacide?nn### Input:n |
Possiamo vedere che le risposte del modello ottimizzato dimostrano un miglioramento significativo in termini di precisione, pertinenza e chiarezza rispetto a quelle del modello pre-addestrato. In alcuni casi, l'utilizzo del modello preaddestrato per il tuo caso d'uso potrebbe non essere sufficiente, quindi ottimizzarlo utilizzando questa tecnica renderà la soluzione più personalizzata per il tuo set di dati.
ripulire
Dopo aver completato il lavoro di formazione e non desideri più utilizzare le risorse esistenti, elimina le risorse utilizzando il seguente codice:
Conclusione
L'implementazione e la messa a punto dei modelli Llama 2 Neuron su SageMaker dimostrano un progresso significativo nella gestione e nell'ottimizzazione dei modelli di intelligenza artificiale generativa su larga scala. Questi modelli, incluse varianti come Llama-2-7b e Llama-2-13b, utilizzano Neuron per un addestramento e un'inferenza efficienti su istanze basate su AWS Inferentia e Trainium, migliorandone prestazioni e scalabilità.
La possibilità di distribuire questi modelli tramite l'interfaccia utente SageMaker JumpStart e l'SDK Python offre flessibilità e facilità d'uso. Neuron SDK, con il supporto dei framework ML più diffusi e funzionalità ad alte prestazioni, consente una gestione efficiente di questi modelli di grandi dimensioni.
La messa a punto di questi modelli su dati specifici del dominio è fondamentale per migliorarne la pertinenza e l’accuratezza in campi specializzati. Il processo, che puoi condurre tramite l'interfaccia utente di SageMaker Studio o l'SDK Python, consente la personalizzazione in base a esigenze specifiche, portando a prestazioni del modello migliorate in termini di completamento tempestivo e qualità della risposta.
In confronto, le versioni pre-addestrate di questi modelli, sebbene potenti, possono fornire risposte più generiche o ripetitive. La messa a punto adatta il modello a contesti specifici, ottenendo risposte più accurate, pertinenti e diversificate. Questa personalizzazione è particolarmente evidente quando si confrontano le risposte di modelli pre-addestrati e ottimizzati, dove questi ultimi dimostrano un notevole miglioramento nella qualità e nella specificità dell'output. In conclusione, l’implementazione e la messa a punto dei modelli Neuron Llama 2 su SageMaker rappresentano un solido quadro per la gestione di modelli di intelligenza artificiale avanzati, offrendo miglioramenti significativi in termini di prestazioni e applicabilità, soprattutto se adattati a domini o attività specifici.
Inizia oggi facendo riferimento all'esempio SageMaker taccuino.
Per ulteriori informazioni sulla distribuzione e la messa a punto dei modelli Llama 2 preaddestrati su istanze basate su GPU, fare riferimento a Ottimizza Llama 2 per la generazione di testo su Amazon SageMaker JumpStart ed I modelli di fondazione Llama 2 di Meta sono ora disponibili in Amazon SageMaker JumpStart.
Gli autori desiderano riconoscere i contributi tecnici di Evan Kravitz, Christopher Whitten, Adam Kozdrowicz, Manan Shah, Jonathan Guinegagne e Mike James.
Informazioni sugli autori
 Xin Huan è Senior Applied Scientist per gli algoritmi integrati di Amazon SageMaker JumpStart e Amazon SageMaker. Si concentra sullo sviluppo di algoritmi di apprendimento automatico scalabili. I suoi interessi di ricerca riguardano l'elaborazione del linguaggio naturale, il deep learning spiegabile su dati tabulari e l'analisi solida del clustering spazio-temporale non parametrico. Ha pubblicato molti articoli nelle conferenze ACL, ICDM, KDD e Royal Statistical Society: Series A.
Xin Huan è Senior Applied Scientist per gli algoritmi integrati di Amazon SageMaker JumpStart e Amazon SageMaker. Si concentra sullo sviluppo di algoritmi di apprendimento automatico scalabili. I suoi interessi di ricerca riguardano l'elaborazione del linguaggio naturale, il deep learning spiegabile su dati tabulari e l'analisi solida del clustering spazio-temporale non parametrico. Ha pubblicato molti articoli nelle conferenze ACL, ICDM, KDD e Royal Statistical Society: Series A.
 Nitin Eusebio è un Senior Enterprise Solutions Architect presso AWS, esperto in ingegneria del software, architettura aziendale e AI/ML. È profondamente appassionato nell’esplorare le possibilità dell’intelligenza artificiale generativa. Collabora con i clienti per aiutarli a creare applicazioni ben architettate sulla piattaforma AWS e si dedica alla risoluzione delle sfide tecnologiche e all'assistenza nel loro percorso verso il cloud.
Nitin Eusebio è un Senior Enterprise Solutions Architect presso AWS, esperto in ingegneria del software, architettura aziendale e AI/ML. È profondamente appassionato nell’esplorare le possibilità dell’intelligenza artificiale generativa. Collabora con i clienti per aiutarli a creare applicazioni ben architettate sulla piattaforma AWS e si dedica alla risoluzione delle sfide tecnologiche e all'assistenza nel loro percorso verso il cloud.
 Madhur Prashant lavora nello spazio dell'intelligenza artificiale generativa in AWS. È appassionato dell’intersezione tra pensiero umano e intelligenza artificiale generativa. I suoi interessi risiedono nell'intelligenza artificiale generativa, nello specifico nella creazione di soluzioni utili e innocue e, soprattutto, ottimali per i clienti. Al di fuori del lavoro, ama fare yoga, fare escursioni, passare il tempo con il suo gemello e suonare la chitarra.
Madhur Prashant lavora nello spazio dell'intelligenza artificiale generativa in AWS. È appassionato dell’intersezione tra pensiero umano e intelligenza artificiale generativa. I suoi interessi risiedono nell'intelligenza artificiale generativa, nello specifico nella creazione di soluzioni utili e innocue e, soprattutto, ottimali per i clienti. Al di fuori del lavoro, ama fare yoga, fare escursioni, passare il tempo con il suo gemello e suonare la chitarra.
 Dewan Choudhury è un Software Development Engineer con Amazon Web Services. Lavora sugli algoritmi di Amazon SageMaker e sulle offerte JumpStart. Oltre a costruire infrastrutture AI/ML, è anche appassionato di costruire sistemi distribuiti scalabili.
Dewan Choudhury è un Software Development Engineer con Amazon Web Services. Lavora sugli algoritmi di Amazon SageMaker e sulle offerte JumpStart. Oltre a costruire infrastrutture AI/ML, è anche appassionato di costruire sistemi distribuiti scalabili.
 HaoZhou è un ricercatore presso Amazon SageMaker. In precedenza, ha lavorato allo sviluppo di metodi di machine learning per il rilevamento delle frodi per Amazon Fraud Detector. La sua passione è l'applicazione di tecniche di machine learning, ottimizzazione e intelligenza artificiale generativa a vari problemi del mondo reale. Ha conseguito un dottorato in ingegneria elettrica presso la Northwestern University.
HaoZhou è un ricercatore presso Amazon SageMaker. In precedenza, ha lavorato allo sviluppo di metodi di machine learning per il rilevamento delle frodi per Amazon Fraud Detector. La sua passione è l'applicazione di tecniche di machine learning, ottimizzazione e intelligenza artificiale generativa a vari problemi del mondo reale. Ha conseguito un dottorato in ingegneria elettrica presso la Northwestern University.
 Qing Lan è un ingegnere di sviluppo software in AWS. Ha lavorato su diversi prodotti impegnativi in Amazon, tra cui soluzioni di inferenza ML ad alte prestazioni e sistema di registrazione ad alte prestazioni. Il team di Qing ha lanciato con successo il primo modello di miliardi di parametri in Amazon Advertising con una latenza molto bassa richiesta. Qing ha una conoscenza approfondita dell'ottimizzazione dell'infrastruttura e dell'accelerazione del Deep Learning.
Qing Lan è un ingegnere di sviluppo software in AWS. Ha lavorato su diversi prodotti impegnativi in Amazon, tra cui soluzioni di inferenza ML ad alte prestazioni e sistema di registrazione ad alte prestazioni. Il team di Qing ha lanciato con successo il primo modello di miliardi di parametri in Amazon Advertising con una latenza molto bassa richiesta. Qing ha una conoscenza approfondita dell'ottimizzazione dell'infrastruttura e dell'accelerazione del Deep Learning.
 Dottor Ashish Khetan è un Senior Applied Scientist con algoritmi integrati di Amazon SageMaker e aiuta a sviluppare algoritmi di machine learning. Ha conseguito il dottorato di ricerca presso l'Università dell'Illinois Urbana-Champaign. È un ricercatore attivo nell'apprendimento automatico e nell'inferenza statistica e ha pubblicato numerosi articoli nelle conferenze NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
Dottor Ashish Khetan è un Senior Applied Scientist con algoritmi integrati di Amazon SageMaker e aiuta a sviluppare algoritmi di machine learning. Ha conseguito il dottorato di ricerca presso l'Università dell'Illinois Urbana-Champaign. È un ricercatore attivo nell'apprendimento automatico e nell'inferenza statistica e ha pubblicato numerosi articoli nelle conferenze NeurIPS, ICML, ICLR, JMLR, ACL e EMNLP.
 Dott. Li Zhang è un Principal Product Manager-Technical per Amazon SageMaker JumpStart e gli algoritmi integrati di Amazon SageMaker, un servizio che aiuta i data scientist e i professionisti dell'apprendimento automatico a iniziare con la formazione e la distribuzione dei loro modelli e utilizza l'apprendimento per rinforzo con Amazon SageMaker. Il suo lavoro passato come membro principale dello staff di ricerca e inventore principale presso IBM Research ha vinto il premio Test of Time Paper presso IEEE INFOCOM.
Dott. Li Zhang è un Principal Product Manager-Technical per Amazon SageMaker JumpStart e gli algoritmi integrati di Amazon SageMaker, un servizio che aiuta i data scientist e i professionisti dell'apprendimento automatico a iniziare con la formazione e la distribuzione dei loro modelli e utilizza l'apprendimento per rinforzo con Amazon SageMaker. Il suo lavoro passato come membro principale dello staff di ricerca e inventore principale presso IBM Research ha vinto il premio Test of Time Paper presso IEEE INFOCOM.
 Kamran Khan, Responsabile tecnico senior dello sviluppo aziendale per AWS Inferentina/Trianium presso AWS. Ha oltre un decennio di esperienza nell'aiutare i clienti a distribuire e ottimizzare la formazione sul deep learning e i carichi di lavoro di inferenza utilizzando AWS Inferentia e AWS Trainium.
Kamran Khan, Responsabile tecnico senior dello sviluppo aziendale per AWS Inferentina/Trianium presso AWS. Ha oltre un decennio di esperienza nell'aiutare i clienti a distribuire e ottimizzare la formazione sul deep learning e i carichi di lavoro di inferenza utilizzando AWS Inferentia e AWS Trainium.
 Joe Senerchia è un Senior Product Manager presso AWS. Definisce e crea istanze Amazon EC2 per carichi di lavoro di deep learning, intelligenza artificiale e calcolo ad alte prestazioni.
Joe Senerchia è un Senior Product Manager presso AWS. Definisce e crea istanze Amazon EC2 per carichi di lavoro di deep learning, intelligenza artificiale e calcolo ad alte prestazioni.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/fine-tune-and-deploy-llama-2-models-cost-effectively-in-amazon-sagemaker-jumpstart-with-aws-inferentia-and-aws-trainium/
- :ha
- :È
- :non
- :Dove
- $ SU
- 000
- 1
- 10
- 100
- 11
- 12
- 121
- 13
- 15%
- 16
- 19
- 1996
- 2001
- 2006
- 2016
- 2018
- 25
- 30
- 36
- 3d
- 40
- 60
- 610
- 65
- 7
- 8
- 9
- a
- capacità
- capace
- WRI
- accelerazione
- Accetta
- accettabile
- accettato
- accesso
- precisione
- preciso
- riconoscere
- ACM
- attivo
- attività
- Adam
- adattare
- adattamento
- adattato
- aggiungere
- aggiunta
- adulti
- Avanzate
- avanzamento
- Pubblicità
- Dopo shavasana, sedersi in silenzio; saluti;
- Accordo
- AI
- Modelli AI
- AI / ML
- Algoritmi
- Tutti
- consentire
- permesso
- consente
- anche
- Amazon
- Amazon EC2
- Amazon Fraud Detector
- Amazon Sage Maker
- JumpStart di Amazon SageMaker
- Amazon Web Services
- tra
- an
- .
- Antico
- ed
- animali
- Annunciare
- Un altro
- in qualsiasi
- più
- Apache
- a parte
- applicabile
- Applicazioni
- applicazioni
- applicato
- AMMISSIONE
- appropriatamente
- circa
- architettura
- SONO
- RISERVATA
- aree
- argomento
- Army
- arrivato
- Arte
- artificiale
- intelligenza artificiale
- AS
- assistere
- Associazione
- At
- assistenti
- gli attributi
- Autorità
- gli autori
- Automatizzata
- disponibilità
- disponibile
- evitare
- AWS
- AWS Inferenza
- b
- basato
- BE
- Larghezza
- perché
- diventare
- stato
- prima
- essendo
- CREDIAMO
- sotto
- fra
- Al di là di
- Maggiore
- biologia
- Blog
- Dezen Dezen
- entrambi
- Scatola
- ampio
- costruire
- Costruzione
- costruisce
- incassato
- affari
- sviluppo commerciale
- ma
- pulsante
- pulsanti
- by
- chiamata
- è venuto
- Materiale
- funzionalità
- capitale
- carta
- svolta
- Custodie
- casi
- categoria
- Categoria
- sfide
- impegnativo
- il cambiamento
- Chaos
- chiacchierare
- capo
- scegliere
- Scegli
- la scelta
- Christopher
- Città
- civile
- chiarezza
- classi
- classico
- classificazione
- cavedano
- Cloud
- il clustering
- codice
- freddo
- comitato
- Uncommon
- Comunità
- comunità
- azienda
- rispetto
- confronto
- confronto
- Completato
- Completa
- computazionale
- informatica
- conclusione
- concorrente
- Segui il codice di Condotta
- Convegno
- conferenze
- Configurazione
- Confermare
- consolle
- contenere
- Contenitore
- contiene
- contenuto
- contesto
- contesti
- contributi
- di controllo
- controlli
- Costo
- costoso
- Costi
- nazione
- creato
- corona
- cruciale
- la cultura della
- Coppa
- cliente
- esperienza del cliente
- Clienti
- personalizzazione
- dati
- dataset
- Data
- de
- decennio
- Dicembre
- Decodifica
- dedicato
- deep
- apprendimento profondo
- profondamente
- Predefinito
- definisce
- Laurea
- consegnare
- democratico
- dimostrare
- dimostrato
- dimostra
- Dipendente
- dipende
- schierare
- schierato
- distribuzione
- deployment
- descrive
- descrizione
- designato
- progettato
- dettagliati
- dettagli
- rivelazione
- sviluppare
- in via di sviluppo
- Mercato
- Dialogo
- DID
- differenza
- diverso
- scopri
- scoperta
- discutere
- Dsiplay
- distribuito
- sistemi distribuiti
- paesaggio differenziato
- effettua
- fare
- bambola
- dominio
- domini
- Dont
- giù
- ogni
- Presto
- Guadagno
- alleviare
- facilità d'uso
- editore
- Efficace
- efficacia
- efficiente
- o
- eletto
- Ingegneria Elettrica
- Impero
- abilitato
- Abilita
- consentendo
- fine
- da un capo all'altro
- endpoint
- ingegnere
- Ingegneria
- accrescere
- migliorando
- abbastanza
- assicura
- Impresa
- Enterprise Solutions
- Ambiente
- ambientale
- pari
- Equivale
- particolarmente
- Etere (ETH)
- valutare
- valutazione
- evidente
- esempio
- Esempi
- eccitato
- esclusa
- esistente
- esperienza
- esperto
- sperimentale
- esplora
- Esplorare
- estrazione
- Autunno
- falso
- più veloce
- compagno
- feste
- pochi
- campi
- Compila il
- File
- Limatura
- finanziario
- servizi finanziari
- Trovate
- sottile
- Nome
- Flessibilità
- galleggiante
- Focus
- si concentra
- i seguenti
- segue
- Nel
- forza
- formato
- essere trovato
- Fondazione
- Fondato
- Contesto
- quadri
- frode
- rilevazione di frodi
- da
- function
- ulteriormente
- generato
- genera
- ELETTRICA
- generativo
- AI generativa
- ottenere
- Go
- Dio
- buono
- ha ottenuto
- laurea
- grafico
- grafici
- maggiore
- Grecia
- Avido
- greco
- Gruppo
- guida
- chitarra
- ha avuto
- Manovrabilità
- Mani
- contento
- Avere
- he
- assistenza sanitaria
- Eroe
- Aiuto
- utile
- aiutare
- aiuta
- Alta
- Alte prestazioni
- superiore
- massimo
- evidenzia
- escursionismo
- lui
- il suo
- detiene
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- umano
- i
- IBM
- ICLR
- identificare
- ids
- IEEE
- if
- ii
- Illinois
- implementazione
- importare
- importante
- competenze
- migliorata
- miglioramento
- miglioramenti
- in
- Uno sguardo approfondito sui miglioramenti dei pneumatici da corsa di Bridgestone.
- includere
- inclusi
- Compreso
- Aumento
- indica
- informazioni
- estrazione di informazioni
- Infrastruttura
- infrastruttura
- ingresso
- Ingressi
- esempio
- istanze
- istruzioni
- integrato
- Intelligence
- interessi
- Interfaccia
- Internazionale
- intersezione
- ai miglioramenti
- coinvolto
- IT
- SUO
- Giacomo
- Lavoro
- Offerte di lavoro
- congiunto
- Jonathan
- rivista
- viaggio
- jpg
- json
- ad appena
- Le
- Regno
- kit
- Corredo (SDK)
- conoscenze
- conosciuto
- atterraggio
- pagina di destinazione
- Lingua
- grandi
- larga scala
- Latenza
- dopo
- lanciato
- Legislazione
- principale
- apprendimento
- Lunghezza
- li
- Licenza
- licenze
- Bugia
- Vita
- piace
- probabilità
- probabile
- limitazione
- linea
- Linee
- LINK
- Lista
- elencati
- Lama
- caricare
- locale
- registrazione
- Lunghi
- Guarda
- ama
- Basso
- inferiore
- abbassamento
- minore
- macchina
- machine learning
- fatto
- Principale
- make
- Fare
- direttore
- gestione
- Manan Shah
- molti
- Mastercard
- massimo
- Maggio..
- significato
- Soddisfare
- membro
- Meta
- metodo
- metodi
- Messico
- forza
- microfono
- mente
- ML
- modello
- modellismo
- modelli
- modificato
- modificare
- Scopri di più
- maggior parte
- mosso
- Musica
- devono obbligatoriamente:
- Nome
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- Navigare
- Navigazione
- Bisogno
- esigenze
- NeuIPS
- New
- GENERAZIONE
- nlp
- Northwestern University
- taccuino
- computer portatili
- adesso
- numero
- numeri
- oggetto
- Obiettivi d'Esame
- of
- offrire
- offerta
- offerte
- Offerte
- di frequente
- Vecchio
- maggiore
- on
- una volta
- ONE
- esclusivamente
- ottimale
- ottimizzazione
- OTTIMIZZA
- ottimizzati
- ottimizzazione
- Opzione
- or
- organizzazione
- Altro
- produzione
- al di fuori
- eccezionale
- ancora
- proprio
- Packages
- pagina
- coppia
- accoppiato
- vetro
- Carta
- documenti
- Parallel
- parametri
- parte
- particolarmente
- parti
- passaggio
- appassionato
- passato
- per
- eseguire
- performance
- periodo
- Personalizzata
- phd
- conduttura
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- per favore
- punto
- Termini e Condizioni
- politica
- politico
- pop-up
- Popolare
- positivo
- possibilità
- possibile
- Post
- potente
- precedente
- Precisione
- preparazione
- primario
- Direttore
- probabilità
- problemi
- processi
- lavorazione
- Prodotto
- product manager
- Prodotti
- proprio
- fornire
- fornitori
- fornisce
- pubblicamente
- pubblicato
- metti
- Python
- pytorch
- qualità
- domanda
- casualità
- raggiungere
- raggiunge
- Leggi
- pronto
- di rose
- mondo reale
- tempo reale
- ragione
- motivi
- record
- riferimento
- riferimento
- rifugiati
- rilasciato
- rilevanza
- pertinente
- Trasferito
- è rimasta
- resti
- ripetuto
- ripetitivo
- sostituire
- deposito
- rappresentare
- che rappresenta
- richiesta
- richieste
- necessario
- riparazioni
- ricercatore
- Risorse
- rispettivamente
- risposta
- risposte
- responsabile
- risultante
- Risultati
- ritorno
- recensioni
- revisione
- robusto
- rotolamento
- reale
- Correre
- Russia
- sagemaker
- Scalabilità
- scalabile
- Scala
- Scenari
- Scienziato
- scienziati
- script
- sdk
- Cerca
- ricerca
- SEC
- Deposito SEC
- Secondo
- Sezione
- problemi di
- vedere
- anziano
- inviato
- condanna
- sentimento
- separato
- Sequenza
- Serie
- Serie A
- servizio
- Servizi
- set
- regolazione
- impostazioni
- alcuni
- Corti
- dovrebbero
- mostrare attraverso le sue creazioni
- mostrato
- Spettacoli
- significativa
- Un'espansione
- da
- singolo
- Taglia
- frammento
- So
- Società
- Software
- lo sviluppo del software
- kit di sviluppo software
- Ingegneria del software
- soluzione
- Soluzioni
- Soluzione
- alcuni
- è composta da
- Fonte
- Sud
- sovietico
- lo spazio
- specializzata
- specifico
- in particolare
- specificità
- specificato
- Spendere
- dividere
- STAFF
- inizia a
- iniziato
- Regione / Stato
- statistiche
- Stato dei servizi
- sterzo
- step
- Passi
- Interrompe
- conservazione
- strutturato
- Gli studenti
- studiato
- studi
- studio
- Con successo
- tale
- supporto
- supportato
- sicuro
- Svizzera
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- su misura
- Task
- task
- Insegnamento
- team
- Consulenza
- per l'esame
- tecniche
- Tecnologia
- modello
- Tennessee
- condizioni
- test
- testo
- Classificazione del testo
- generazione di testo
- di
- che
- Il
- L'area
- La capitale
- Teatro
- loro
- Li
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- Pensiero
- di parti terze standard
- questo
- quelli
- Attraverso
- portata
- tigri
- tempo
- volte
- a
- oggi
- token
- Tokens
- strumenti
- Totale
- Treni
- allenato
- Training
- trasformatore
- Traduzione
- vero
- prova
- gemello
- seconda
- Digitare
- ui
- per
- sottostante
- unico
- Università
- Università
- fino a quando
- Aggiornanento
- Aggiornamenti
- Impiego
- uso
- caso d'uso
- utilizzato
- Utente
- utenti
- usa
- utilizzando
- utilizza
- Uzbekistan
- convalida
- APPREZZIAMO
- varietà
- vario
- versione
- molto
- via
- Visualizza
- vite
- visivo
- camminare
- volere
- guerra
- Prima
- modi
- we
- sito web
- servizi web
- Web-basata
- è andato
- sono stati
- quando
- quale
- while
- OMS
- volere
- VINO
- con
- Ha vinto
- Word
- parole
- Lavora
- lavorato
- lavoro
- lavori
- laboratorio
- mondo
- sarebbe
- scrivere
- anno
- Yoga
- Tu
- Trasferimento da aeroporto a Sharm
- gioventù
- zefiro
- Zeus