Nel mondo di oggi, i clienti gestiscono grandi quantità di dati nei loro Servizio di archiviazione semplice Amazon (Amazon S3) data lake, che richiedono pipeline di dati complesse per comprendere continuamente i cambiamenti nel layout dei dati e renderli disponibili ai sistemi di consumo. Colla AWS I crawler forniscono un modo semplice per catalogare i dati nel catalogo dati di AWS Glue, eliminando il lavoro pesante quando si tratta di gestione dello schema e classificazione dei dati. I crawler di AWS Glue estraggono lo schema dei dati e le partizioni da Amazon S3 per popolare automaticamente il Catalogo dati, mantenendo aggiornati i metadati.
Tuttavia, con la crescita esponenziale dei dati nel tempo, il numero di partizioni in una determinata tabella può aumentare in modo significativo. Perché i servizi di analisi come Amazzone Atena eseguire una query su una tabella contenente milioni di partizioni, il tempo necessario per recuperare la partizione aumenta e può causare un aumento del tempo di esecuzione delle query.
Oggi, il supporto del crawler di AWS Glue è stato ampliato per aggiungere automaticamente indici di partizione per le nuove tabelle scoperte per ottimizzare l'elaborazione delle query sul set di dati partizionato. Ora, quando il crawler crea una nuova tabella Data Catalog durante un'esecuzione del crawler, crea anche un indice di partizione per impostazione predefinita, con la permutazione più grande di tutte le colonne di partizione di tipo numerico e stringa come chiavi. Il Data Catalog crea quindi un indice ricercabile basato su queste chiavi, riducendo il tempo necessario per recuperare e filtrare i metadati delle partizioni su tabelle con milioni di partizioni. La creazione di indici di partizione avvantaggia i carichi di lavoro di analisi in esecuzione su Athena, Amazon EMR, Spettro Amazon Redshifte AWS Glue.
In questo post, descriviamo come creare indici di partizione con un crawler AWS Glue e confrontiamo il miglioramento delle prestazioni delle query durante l'accesso ai dati sottoposti a scansione con e senza un indice di partizione da Athena.
Panoramica della soluzione
Usiamo un file AWS CloudFormazione modello per creare le nostre risorse di soluzione. Nelle fasi seguenti, dimostriamo come configurare il crawler AWS Glue per creare un indice di partizione utilizzando la console AWS Glue o il Interfaccia della riga di comando di AWS (interfaccia a riga di comando dell'AWS). Quindi confrontiamo i miglioramenti delle prestazioni delle query utilizzando Athena.
Prerequisiti
Per seguire questo post, devi avere accesso a un file Gestione dell'identità e dell'accesso di AWS Ruolo di amministratore (IAM) per creare risorse utilizzando AWS CloudFormation.
Imposta le risorse della tua soluzione
Il modello CloudFormation genera le seguenti risorse:
- Ruoli e politiche IAM
- Un database AWS Glue per contenere lo schema
- Un crawler AWS Glue che punta a un set di dati altamente partizionato
- Un gruppo di lavoro e un bucket Athena per archiviare i risultati delle query
Completare i passaggi seguenti per configurare le risorse della soluzione:
- Accedere al Console di gestione AWS come amministratore IAM.
- Scegli Avvia Stack per distribuire il modello CloudFormation:

- Nel DatabaseName, mantieni il valore predefinito
blog_partition_index_crawlerdb.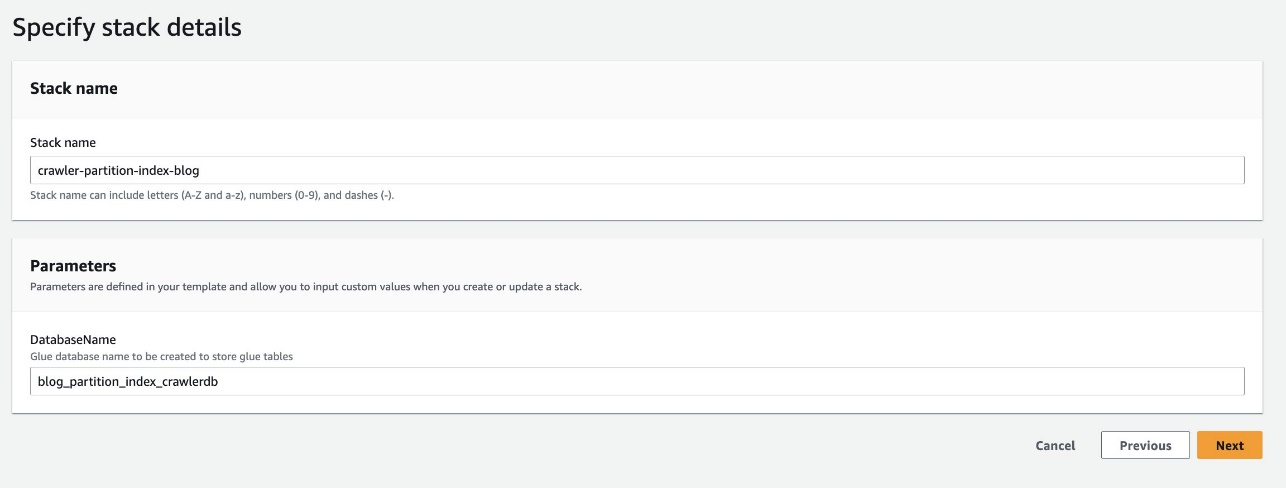
- Scegli Avanti.
- Rivedere i dettagli nella pagina finale e selezionare Riconosco che AWS CloudFormation potrebbe creare risorse IAM.
- Scegli Crea stack.
- Quando lo stack è completo, nella console AWS CloudFormation, vai al file Uscite scheda dello stack.
- Annotare i valori di
DatabaseNameedGlueCrawlerName.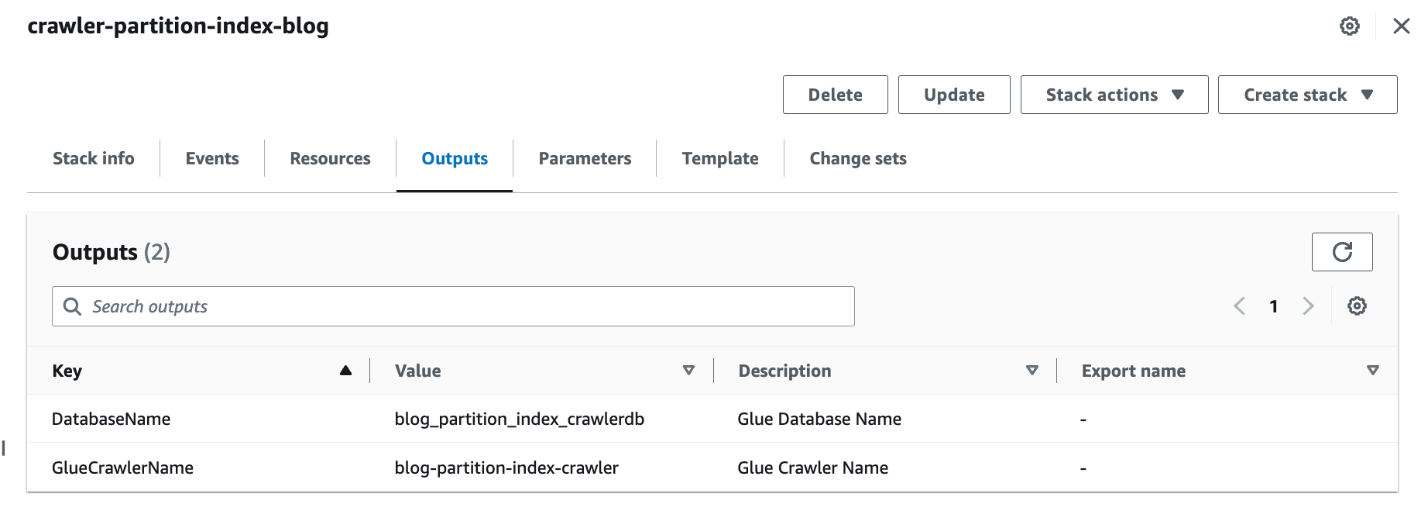
Alcune delle risorse distribuite da questo stack comportano costi quando sono in uso.
Modifica ed esegui il crawler di AWS Glue
Per configurare ed eseguire il crawler di AWS Glue, completa i seguenti passaggi:
- Nella console AWS Glue, scegli Crawlers nel pannello di navigazione.
- individuare il
crawler blog-partition-index-crawlere scegli Modifica.
- Nel Imposta output e pianificazione sezione, sotto Opzioni avanzate, selezionare Crea automaticamente gli indici delle partizioni.
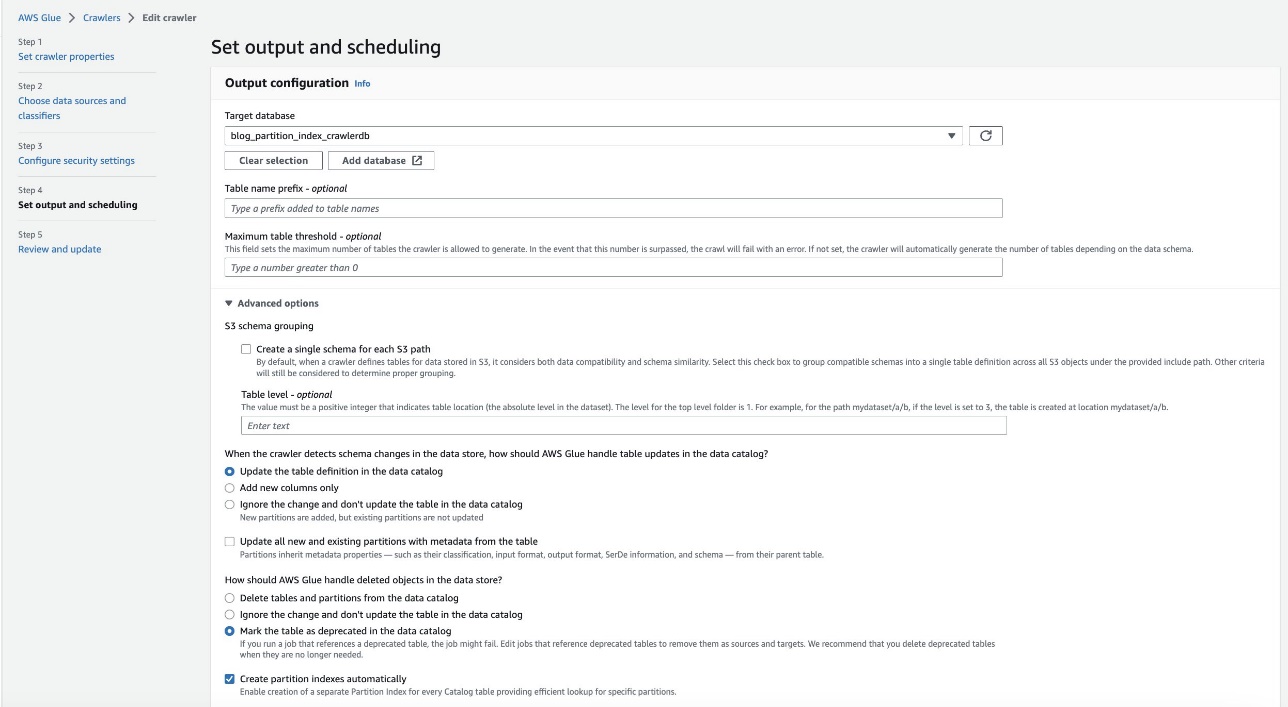
- Esamina e aggiorna le impostazioni del crawler.
In alternativa, puoi configurare il tuo crawler utilizzando l'AWS CLI (fornisci il tuo ruolo IAM e la tua regione):
- Ora esegui il crawler e verifica che l'esecuzione del crawler sia completa.
Si tratta di un set di dati altamente partizionato e il completamento richiederà circa 90 minuti.
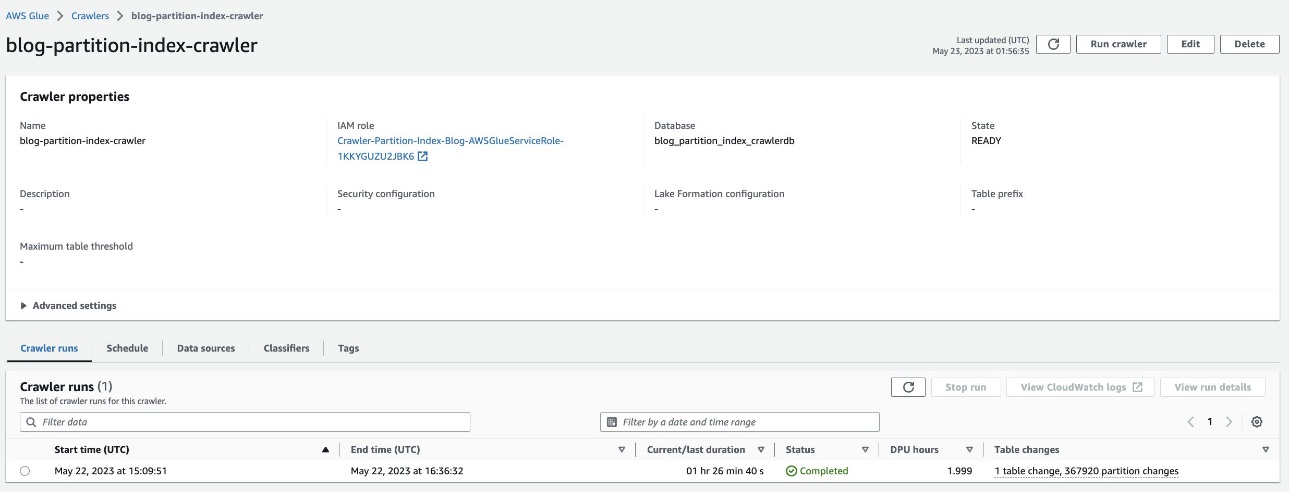
Verificare la tabella partizionata
Nel database AWS Glue blog_partition_index_crawlerdb, verificare che la tabella highly_partitioned_table è creato.
Per impostazione predefinita, il crawler determina un indice basato sulla più grande permutazione di colonne di partizione di tipi di colonna validi nello stesso ordine di colonne di partizione, che sono numeriche o stringhe. Per la tabella creata dal crawler (highly_partitioned_table), abbiamo colonne di partizione year (corda), month (corda), day (stringa), e hour (corda).
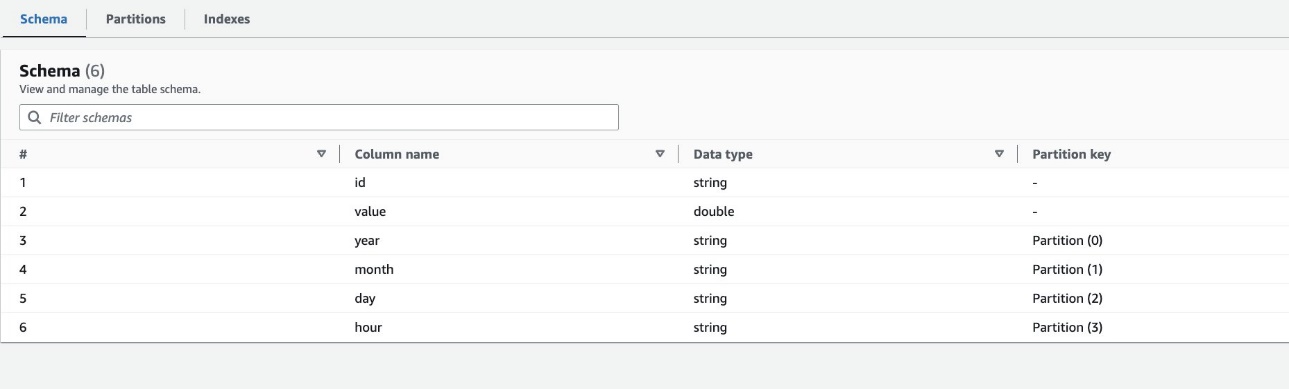
In base a questa definizione, il crawler ha creato un indice sulla permutazione di anno, mese, giorno e ora. Il crawler ha creato gli indici con il prefisso crawler_ su qualsiasi indice di partizione creato per impostazione predefinita.
Verifica lo stesso navigando nella tabella highly_partitioned_table sulla console AWS Glue e scegliendo il file Indici scheda.
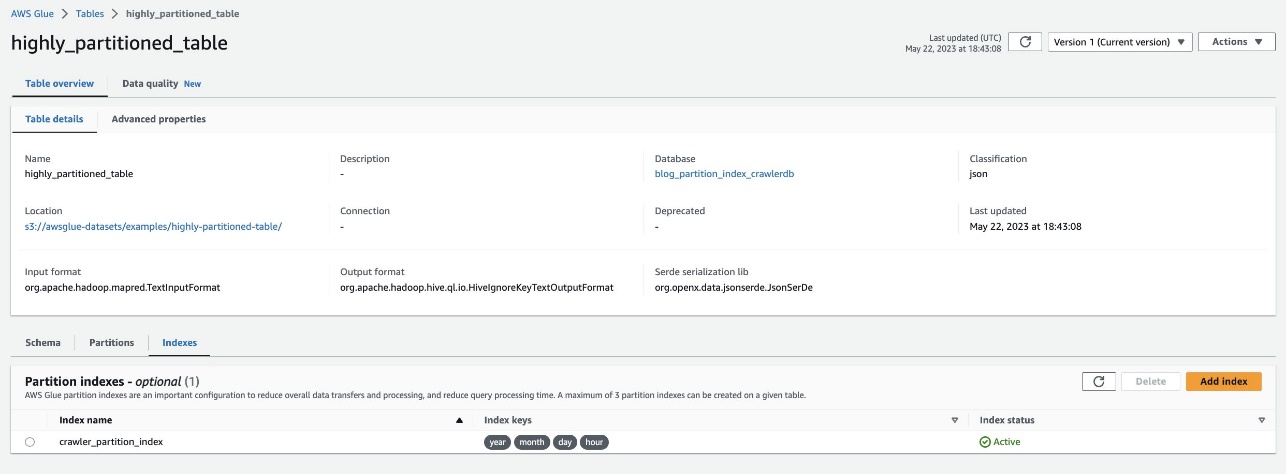
Il crawler è stato in grado di eseguire la scansione dell'origine dati S3 e di popolare correttamente gli indici di partizione per la tabella.
Confronta i miglioramenti delle prestazioni delle query utilizzando Athena
Innanzitutto, interroghiamo la tabella in Athena senza utilizzare l'indice di partizione. Per verificare le tabelle utilizzando Athena, completare i seguenti passaggi:
- Sulla console Athena, scegli
crawler-primary-workgroupcome gruppo di lavoro Athena e scegliere Riconoscere.
- Esegui la seguente query:
Lo screenshot seguente mostra che la query ha impiegato circa 32 secondi senza che il filtro fosse abilitato usando l'indice di partizione.
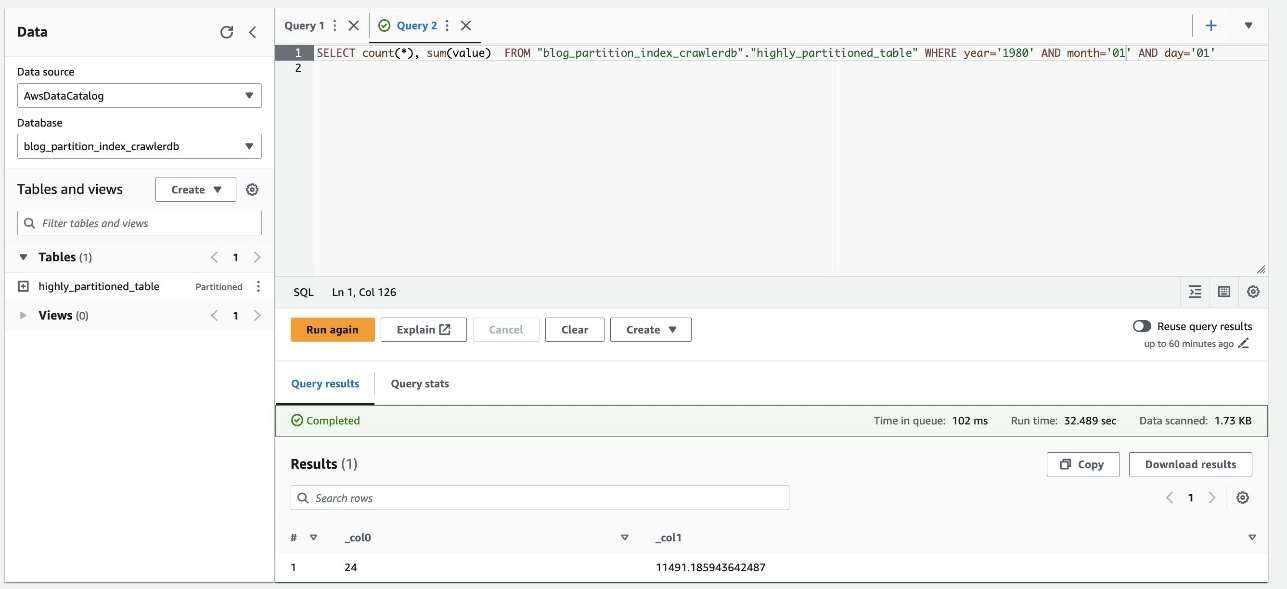
- Ora abilitiamo l'indice di partizione sulla query Athena:
- Esegui di nuovo la seguente query e prendi nota del runtime:
Lo screenshot seguente mostra che la query ha impiegato solo 700 millisecondi, che è molto più veloce con il filtro abilitato usando l'indice di partizione.
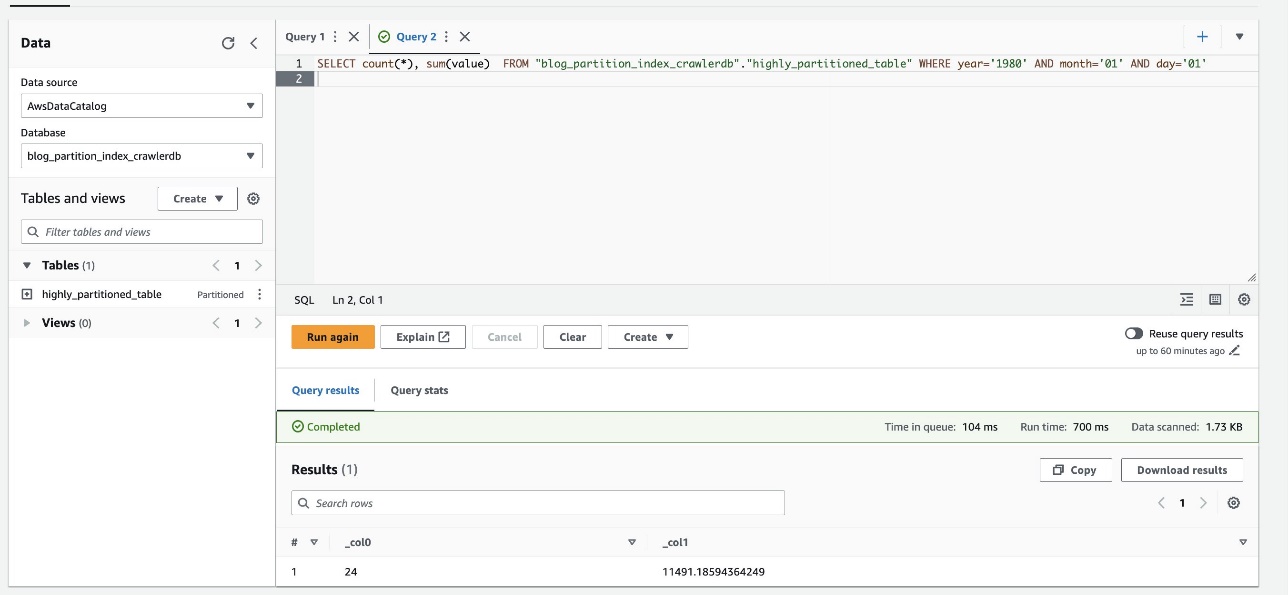
ripulire
Per evitare addebiti indesiderati sul tuo account AWS, puoi eliminare le risorse AWS:
- Accedi alla console CloudFormation come amministratore IAM utilizzato per creare lo stack CloudFormation.
- Elimina lo stack CloudFormation che hai creato.
Conclusione
In questo post, abbiamo spiegato come configurare un crawler AWS per creare indici di partizione e abbiamo confrontato le prestazioni delle query durante l'accesso ai dati con gli indici di Athena.
Se sulla tabella non sono presenti indici di partizione, AWS Glue carica tutte le partizioni della tabella, quindi filtra le partizioni caricate, con conseguente recupero inefficiente dei metadati. I servizi di analisi come Redshift Spectrum, Amazon EMR e AWS Glue ETL Spark DataFrames ora possono utilizzare gli indici per il recupero delle partizioni, con conseguenti prestazioni di query significative.
Per ulteriori informazioni sugli indici delle partizioni e sulle prestazioni delle query nei vari motori analitici, fare riferimento a Migliora le prestazioni delle query di Amazon Athena utilizzando gli indici di partizione del catalogo dati di AWS Glue ed Migliora le prestazioni delle query utilizzando gli indici di partizione di AWS Glue.
Un ringraziamento speciale a tutti coloro che hanno contribuito al lancio di questa funzione crawler: Yuhang Chen, Kyle Duong e Mita Gavade.
Circa gli autori
 Srividya Parthasarathy è Senior Big Data Architect nel team AWS Lake Formation. Le piace creare soluzioni di data mesh e condividerle con la community.
Srividya Parthasarathy è Senior Big Data Architect nel team AWS Lake Formation. Le piace creare soluzioni di data mesh e condividerle con la community.
 Sandep Adwankar è Senior Technical Product Manager presso AWS. Con sede nella California Bay Area, lavora con clienti in tutto il mondo per tradurre i requisiti tecnici e aziendali in prodotti che consentono ai clienti di migliorare il modo in cui gestiscono, proteggono e accedono ai dati.
Sandep Adwankar è Senior Technical Product Manager presso AWS. Con sede nella California Bay Area, lavora con clienti in tutto il mondo per tradurre i requisiti tecnici e aziendali in prodotti che consentono ai clienti di migliorare il modo in cui gestiscono, proteggono e accedono ai dati.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- EVM Finance. Interfaccia unificata per la finanza decentralizzata. Accedi qui.
- Quantum Media Group. IR/PR amplificato. Accedi qui.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/efficiently-crawl-your-data-lake-and-improve-data-access-with-aws-glue-crawler-using-partition-indexes/
- :ha
- :È
- :Dove
- $ SU
- 1
- 100
- 11
- 27
- 32
- 8
- 9
- 90
- a
- capace
- accesso
- Accedendo
- Il mio account
- riconoscere
- operanti in
- aggiungere
- Admin
- ancora
- Tutti
- lungo
- anche
- Amazon
- Amazzone Atena
- Amazon EMR
- Amazon Web Services
- importi
- an
- Analitico
- analitica
- ed
- in qualsiasi
- circa
- SONO
- RISERVATA
- in giro
- AS
- At
- automaticamente
- disponibile
- evitare
- AWS
- AWS CloudFormazione
- Colla AWS
- Formazione AWS Lake
- basato
- Baia
- perché
- stato
- vantaggi
- Big
- Big Data
- Costruzione
- affari
- by
- California
- Materiale
- catalogo
- Causare
- Modifiche
- oneri
- chen
- Scegli
- la scelta
- classificazione
- Colonna
- colonne
- viene
- comunità
- confrontare
- rispetto
- completamento di una
- consolle
- continuamente
- contribuito
- Costi
- crawler
- creare
- creato
- crea
- Creazione
- creazione
- Corrente
- Clienti
- dati
- l'accesso ai dati
- Lago di dati
- Banca Dati
- giorno
- Predefinito
- dimostrare
- schierare
- Distribuisce
- descrivere
- dettagli
- determina
- scoperto
- giù
- durante
- in modo efficiente
- o
- enable
- abilitato
- Motori
- Etere (ETH)
- tutti
- ampliato
- ha spiegato
- in modo esponenziale
- estratto
- estrarre i dati
- più veloce
- caratteristica
- filtro
- filtraggio
- filtri
- finale
- seguire
- i seguenti
- Nel
- formazione
- da
- genera
- dato
- globo
- Crescere
- Crescita
- Avere
- he
- pesante
- sollevamento pesante
- vivamente
- tenere
- ora
- Come
- Tutorial
- HTML
- http
- HTTPS
- IAM
- Identità
- competenze
- miglioramento
- miglioramenti
- in
- Aumento
- Aumenta
- Index
- indici
- inefficiente
- informazioni
- ai miglioramenti
- IT
- jpg
- mantenere
- conservazione
- Tasti
- lago
- maggiore
- lanciare
- disposizione
- di sollevamento
- piace
- linea
- carichi
- make
- gestire
- gestione
- direttore
- maglia
- Metadati
- forza
- milioni
- verbale
- Mese
- Scopri di più
- molti
- devono obbligatoriamente:
- Navigare
- navigazione
- Navigazione
- di applicazione
- New
- recentemente
- no
- adesso
- numero
- of
- on
- esclusivamente
- OTTIMIZZA
- or
- minimo
- nostro
- produzione
- ancora
- pagina
- vetro
- sentiero
- performance
- Platone
- Platone Data Intelligence
- PlatoneDati
- Post
- presenti
- lavorazione
- Prodotto
- product manager
- Prodotti
- fornire
- riducendo
- regione
- necessario
- Requisiti
- richiede
- Risorse
- risultante
- Risultati
- Ruolo
- ruoli
- Correre
- running
- stesso
- secondo
- Sezione
- sicuro
- anziano
- Servizi
- set
- impostazioni
- compartecipazione
- lei
- Spettacoli
- significativa
- significativamente
- Un'espansione
- soluzione
- Soluzioni
- Fonte
- Scintilla
- Spettro
- pila
- Passi
- conservazione
- Tornare al suo account
- lineare
- Corda
- Con successo
- supporto
- SISTEMI DI TRATTAMENTO
- tavolo
- Fai
- team
- Consulenza
- modello
- Grazie
- che
- Il
- loro
- Li
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- tempo
- a
- di oggi
- ha preso
- tradurre
- vero
- Digitare
- Tipi di
- per
- capire
- non desiderato
- Aggiornanento
- uso
- utilizzato
- utilizzando
- utilizzare
- APPREZZIAMO
- Valori
- vario
- Fisso
- verificare
- versione
- Prima
- Modo..
- we
- sito web
- servizi web
- quando
- quale
- OMS
- volere
- con
- senza
- Gruppo di lavoro
- lavori
- mondo
- YAML
- anno
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro