
Immagine dall'autore | Creatore di immagini Bing
carrello 2.0 è un modello di linguaggio di grandi dimensioni (LLM) open source, seguito da istruzioni, ottimizzato su un set di dati generato dall'uomo. Può essere utilizzato sia per scopi di ricerca che commerciali.
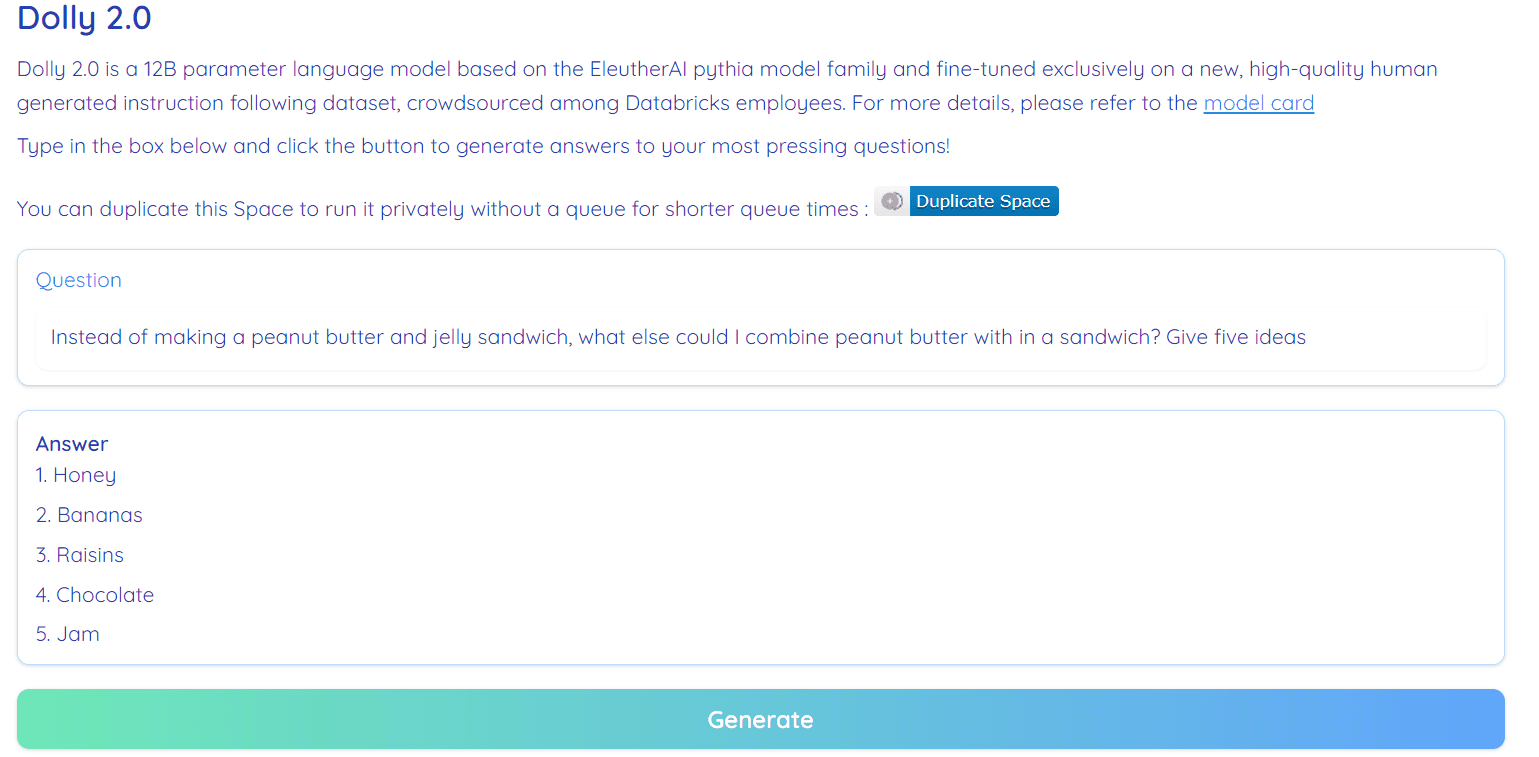
Immagine da Abbracciando Face Space di RamAnanth1
In precedenza, il team Databricks aveva rilasciato carrello 1.0, LLM, che offre istruzioni simili a ChatGPT seguendo le abilità e costa meno di $ 30 per la formazione. Stava utilizzando il set di dati del team Stanford Alpaca, che era soggetto a una licenza limitata (solo ricerca).
Dolly 2.0 ha risolto questo problema perfezionando il modello linguistico dei parametri 12B (Pythia) su un'istruzione di alta qualità generata dall'uomo nel seguente set di dati, che è stata etichettata da un dipendente di Datbricks. Sia il modello che il set di dati sono disponibili per uso commerciale.
Dolly 1.0 è stato addestrato su un set di dati Stanford Alpaca, creato utilizzando l'API OpenAI. Il set di dati contiene l'output di ChatGPT e impedisce a chiunque di utilizzarlo per competere con OpenAI. In breve, non è possibile creare un chatbot commerciale o un’applicazione linguistica basata su questo set di dati.
La maggior parte degli ultimi modelli rilasciati nelle ultime settimane soffrivano degli stessi problemi, modelli simili Alpaca, Koala, GPT4Tuttie Vicuna. Per aggirare il problema, dobbiamo creare nuovi set di dati di alta qualità che possano essere utilizzati per uso commerciale, ed è ciò che il team di Databricks ha fatto con il set di dati databricks-dolly-15k.
Il nuovo set di dati contiene 15,000 coppie prompt/risposta etichettate da esseri umani di alta qualità che possono essere utilizzate per progettare istruzioni che mettono a punto modelli linguistici di grandi dimensioni. IL databricks-dolly-15k il set di dati viene fornito con Licenza Creative Commons Attribuzione-Condividi allo stesso modo 3.0 Unported, che consente a chiunque di utilizzarlo, modificarlo e creare un'applicazione commerciale su di esso.
Come hanno creato il set di dati databricks-dolly-15k?
La ricerca OpenAI carta afferma che il modello InstructGPT originale è stato addestrato su 13,000 prompt e risposte. Utilizzando queste informazioni, il team di Databricks ha iniziato a lavorarci e si è scoperto che generare 13 domande e risposte era un compito difficile. Non possono utilizzare dati sintetici o dati generativi dell’intelligenza artificiale e devono generare risposte originali a ogni domanda. È qui che hanno deciso di utilizzare 5,000 dipendenti di Databricks per creare dati generati dall'uomo.
I Databricks hanno organizzato un concorso in cui i migliori 20 etichettatori riceveranno un grande premio. A questo concorso hanno partecipato 5,000 dipendenti Databricks molto interessati ai LLM
Il dolly-v2-12b non è un modello all'avanguardia. Ha prestazioni inferiori a dolly-v1-6b in alcuni benchmark di valutazione. Potrebbe essere dovuto alla composizione e alle dimensioni dei set di dati di ottimizzazione sottostanti. La famiglia di modelli Dolly è in fase di sviluppo attivo, quindi in futuro potresti vedere una versione aggiornata con prestazioni migliori.
In breve, il modello dolly-v2-12b ha funzionato meglio di EleutherAI/gpt-neox-20b e EleutherAI/pythia-6.9b.

Immagine da Dolly gratis
Dolly 2.0 è open source al 100%. Viene fornito con codice di addestramento, set di dati, pesi del modello e pipeline di inferenza. Tutti i componenti sono adatti per l'uso commerciale. Puoi provare il modello su Hugging Face Spaces Dolly V2 di RamAnanth1.
Immagine da Abbracciare il viso
Risorsa:
Dimostrazione del carrello 2.0: Dolly V2 di RamAnanth1
Abid Ali Awan (@1abidaliawan) è un professionista di data scientist certificato che ama creare modelli di machine learning. Attualmente si sta concentrando sulla creazione di contenuti e sulla scrittura di blog tecnici sulle tecnologie di apprendimento automatico e scienza dei dati. Abid ha conseguito un Master in Technology Management e una laurea in Ingegneria delle Telecomunicazioni. La sua visione è quella di costruire un prodotto di intelligenza artificiale utilizzando una rete neurale grafica per studenti alle prese con malattie mentali.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Coniare il futuro con Adryenn Ashley. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :ha
- :È
- :non
- $ SU
- 000
- 1
- 20
- a
- capacità
- attivo
- AI
- Tutti
- consente
- alternativa
- an
- ed
- risposte
- chiunque
- api
- Applicazioni
- SONO
- in giro
- autore
- disponibile
- premio
- basato
- BE
- parametri di riferimento
- Berkeley
- Meglio
- Big
- Bing
- blog
- entrambi
- costruire
- Costruzione
- by
- Materiale
- non può
- Certificato
- chatbot
- ChatGPT
- codice
- Popolo
- competere
- componenti
- contiene
- contenuto
- creazione di contenuti
- concorso
- Costi
- creare
- creato
- creazione
- Attualmente
- dati
- scienza dei dati
- scienziato di dati
- Databricks
- dataset
- deciso
- Laurea
- Dimo
- Design
- Mercato
- DID
- difficile
- bambola
- Dipendente
- dipendenti
- Ingegneria
- valutazione
- Ogni
- mostre
- Faccia
- famiglia
- pochi
- messa a fuoco
- i seguenti
- Nel
- da
- futuro
- generare
- la generazione di
- generativo
- ottenere
- grafico
- Grafico rete neurale
- Avere
- he
- alta qualità
- detiene
- HTML
- HTTPS
- malattia
- Immagine
- in
- informazioni
- interessato
- problema
- sicurezza
- IT
- jpg
- KDnuggets
- Lingua
- grandi
- Cognome
- con i più recenti
- apprendimento
- Licenza
- piace
- macchina
- machine learning
- gestione
- Mastercard
- mentale
- Malattia mentale
- forza
- modello
- modelli
- modificare
- Bisogno
- Rete
- Neurale
- rete neurale
- New
- of
- on
- esclusivamente
- aprire
- open source
- OpenAI
- or
- i
- produzione
- coppie
- parametro
- partecipato
- performance
- conduttura
- Platone
- Platone Data Intelligence
- PlatoneDati
- Prodotto
- professionale
- fini
- domanda
- Domande
- rilasciato
- riparazioni
- risoluto
- limitato
- s
- stesso
- Scienze
- Scienziato
- set
- Corti
- Taglia
- So
- alcuni
- Fonte
- lo spazio
- spazi
- stanford
- iniziato
- state-of-the-art
- stati
- Lottando
- Gli studenti
- adatto
- sintetico
- dati sintetici
- Task
- team
- Consulenza
- Tecnologie
- Tecnologia
- telecomunicazione
- di
- che
- I
- Il futuro
- di
- questo
- a
- top
- Treni
- allenato
- Training
- per
- sottostante
- aggiornato
- uso
- utilizzato
- utilizzando
- versione
- visione
- Prima
- we
- Settimane
- sono stati
- Che
- quale
- OMS
- con
- Lavora
- sarebbe
- scrittura
- Tu
- zefiro










