Amazon RedShift è un data warehouse cloud completamente gestito e nell'ordine dei petabyte utilizzato da decine di migliaia di clienti per elaborare exabyte di dati ogni giorno per alimentare il proprio carico di lavoro di analisi. Puoi strutturare i tuoi dati, misurare i processi aziendali e ottenere rapidamente informazioni preziose utilizzando un modello dimensionale. Amazon Redshift offre funzionalità integrate per accelerare il processo di modellazione, orchestrazione e reporting da un modello dimensionale.
In questo post, discutiamo come implementare un modello dimensionale, in particolare il Metodologia di Kimball. Discutiamo l'implementazione di dimensioni e fatti all'interno di Amazon Redshift. Mostriamo come eseguire l'estrazione, la trasformazione e il caricamento (ELT), un processo di integrazione incentrato sull'ottenere i dati grezzi da un data lake in un livello di staging per eseguire la modellazione. Nel complesso, il post ti fornirà una chiara comprensione di come utilizzare la modellazione dimensionale in Amazon Redshift.
Panoramica della soluzione
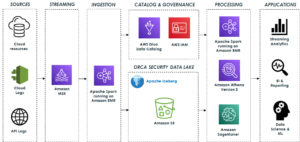
Il diagramma seguente illustra l'architettura della soluzione.

Nelle sezioni seguenti, per prima cosa discutiamo e dimostriamo gli aspetti chiave del modello dimensionale. Successivamente, creiamo un data mart utilizzando Amazon Redshift con un modello di dati dimensionale che include tabelle di dimensioni e fatti. I dati vengono caricati e messi in scena utilizzando il file COPIA comando, i dati nelle dimensioni vengono caricati utilizzando il MERGE dichiarazione, e i fatti saranno uniti alle dimensioni da cui derivano le intuizioni. Pianifichiamo il caricamento delle dimensioni e dei fatti utilizzando il file Editor di query Amazon Redshift V2. Usiamo infine Amazon QuickSight per ottenere informazioni dettagliate sui dati modellati sotto forma di dashboard QuickSight.
Per questa soluzione, utilizziamo un set di dati di esempio (normalizzato) fornito da Amazon Redshift per la vendita di biglietti per eventi. Per questo post, abbiamo ristretto il set di dati per semplicità e scopi dimostrativi. Le seguenti tabelle mostrano esempi di dati relativi alla vendita dei biglietti e alle sedi.


Secondo il Metodologia di modellazione dimensionale Kimball, ci sono quattro passaggi chiave nella progettazione di un modello dimensionale:
- Identificare il processo aziendale.
- Dichiara la grana dei tuoi dati.
- Identificare e implementare le dimensioni.
- Identificare e implementare i fatti.
Inoltre, aggiungiamo un quinto passaggio a scopo dimostrativo, che consiste nel segnalare e analizzare gli eventi aziendali.
Prerequisiti
Per questa procedura dettagliata, è necessario disporre dei seguenti prerequisiti:
Identificare il processo aziendale
In termini semplici, identificare il processo di business significa identificare un evento misurabile che genera dati all'interno di un'organizzazione. Di solito, le aziende dispongono di una sorta di sistema di origine operativo che genera i propri dati nel formato grezzo. Questo è un buon punto di partenza per identificare varie fonti per un processo aziendale.
Il processo aziendale viene quindi reso persistente come a datamart sotto forma di dimensioni e fatti. Guardando il nostro set di dati di esempio menzionato in precedenza, possiamo vedere chiaramente che il processo aziendale è costituito dalle vendite effettuate per un determinato evento.
Un errore comune è l'utilizzo dei reparti di un'azienda come processo aziendale. I dati (processo aziendale) devono essere integrati tra vari reparti, in questo caso il marketing può accedere ai dati di vendita. Identificare il processo aziendale corretto è fondamentale: sbagliare questo passaggio può avere un impatto sull'intero data mart (può causare la duplicazione della grana e metriche errate nei report finali).
Dichiara la grana dei tuoi dati
Dichiarare la grana è l'atto di identificare in modo univoco un record nell'origine dati. La granulosità viene utilizzata nella tabella dei fatti per misurare con precisione i dati e consentire un ulteriore roll up. Nel nostro esempio, potrebbe trattarsi di una voce nel processo aziendale di vendita.
Nel nostro caso d'uso, una vendita può essere identificata in modo univoco osservando il momento della transazione in cui è avvenuta la vendita; questo sarà il livello più atomico.

Identificare e implementare le dimensioni
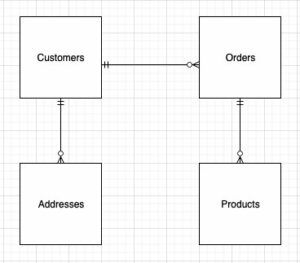
La tua tabella delle dimensioni descrive la tua tabella dei fatti e i suoi attributi. Quando identifichi il contesto descrittivo del tuo processo aziendale, memorizzi il testo in una tabella separata, tenendo presente la grana della tabella dei fatti. Quando si unisce la tabella delle dimensioni alla tabella dei fatti, dovrebbe esserci una sola riga associata alla tabella dei fatti. Nel nostro esempio, usiamo la seguente tabella per essere separata in una tabella delle dimensioni; questi campi descrivono i fatti che misureremo.
Quando si progetta la struttura del modello dimensionale (lo schema), è possibile creare un file stella or fiocco di neve schema. La struttura dovrebbe allinearsi strettamente con il processo aziendale; pertanto, uno schema a stella si adatta meglio al nostro esempio. La figura seguente mostra il nostro Entity Relationship Diagram (ERD).

Nelle sezioni seguenti, dettagliamo i passaggi per implementare le dimensioni.
Mettere in scena i dati di origine
Prima di poter creare e caricare la tabella delle dimensioni, abbiamo bisogno dei dati di origine. Pertanto, mettiamo in scena i dati di origine in una tabella di staging o temporanea. Questo è spesso indicato come il strato di stadiazione, ovvero la copia non elaborata dei dati di origine. Per fare ciò in Amazon Redshift, utilizziamo il file comando COPIA per caricare i dati dal bucket S3 pubblico di modellazione dimensionale-in-amazon-redshift che si trova in us-east-1 Regione. Si noti che il comando COPY utilizza un file Gestione dell'identità e dell'accesso di AWS (IAM) ruolo con accesso ad Amazon S3. Il ruolo deve essere associato al cluster. Completare i passaggi seguenti per mettere in scena i dati di origine:
- creare il
venuetabella di origine:
- Carica i dati della sede:
- creare il
salestabella di origine:
- Carica i dati della fonte di vendita:
- creare il
calendartabella:
- Carica i dati del calendario:
Crea la tabella delle dimensioni
La progettazione della tabella delle dimensioni può dipendere dai requisiti aziendali, ad esempio, è necessario tenere traccia delle modifiche ai dati nel tempo? Ci sono sette diversi tipi di dimensione. Per il nostro esempio, usiamo digitare 1 perché non abbiamo bisogno di tenere traccia dei cambiamenti storici. Per ulteriori informazioni sul tipo 2, fare riferimento a Semplifica il caricamento dei dati nel tipo 2 che cambia lentamente le dimensioni in Amazon Redshift. La tabella delle dimensioni verrà denormalizzata con una chiave primaria, una chiave surrogata e alcuni campi aggiunti per indicare le modifiche alla tabella. Vedere il seguente codice:
Alcune note sulla creazione della creazione della tabella delle dimensioni:
- I nomi dei campi vengono trasformati in nomi commerciali
- La nostra chiave primaria è
VenueID, che utilizziamo per identificare in modo univoco una sede in cui è avvenuta la vendita - Verranno aggiunte due righe aggiuntive, che indicano quando un record è stato inserito e aggiornato (per tenere traccia delle modifiche)
- Stiamo usando un Stile di distribuzione AUTO per dare ad Amazon Redshift la responsabilità di scegliere e adattare lo stile di distribuzione
Un altro fattore importante da considerare nella modellazione dimensionale è l'utilizzo di chiavi surrogate. Le chiavi surrogate sono chiavi artificiali utilizzate nella modellazione dimensionale per identificare in modo univoco ogni record in una tabella delle dimensioni. In genere vengono generati come numeri interi sequenziali e non hanno alcun significato nel dominio aziendale. Offrono diversi vantaggi, come garantire l'unicità e migliorare le prestazioni nei join, perché sono in genere più piccole delle chiavi naturali e come chiavi surrogate non cambiano nel tempo. Questo ci permette di essere coerenti e di unire più facilmente fatti e dimensioni.
In Amazon Redshift, le chiavi surrogate vengono in genere create utilizzando la parola chiave IDENTITY. Ad esempio, l'istruzione CREATE precedente crea una tabella delle dimensioni con a VenueSkey chiave surrogata. IL VenueSkey la colonna viene popolata automaticamente con valori univoci man mano che vengono aggiunte nuove righe alla tabella. Questa colonna può quindi essere utilizzata per unire il tavolo della sede al FactSaleTransactions tabella.
Alcuni suggerimenti per la progettazione di chiavi surrogate:
- Utilizzare un tipo di dati piccolo e a larghezza fissa per la chiave surrogata. Ciò migliorerà le prestazioni e ridurrà lo spazio di archiviazione.
- Utilizzare la parola chiave IDENTITY o generare la chiave surrogata utilizzando un valore sequenziale o GUID. Ciò assicurerà che la chiave surrogata sia univoca e non possa essere modificata.
Carica la tabella dim usando MERGE
Esistono numerosi modi per caricare il tuo tavolo dim. È necessario considerare alcuni fattori, ad esempio le prestazioni, il volume di dati e forse i tempi di caricamento degli SLA. Con il MERGE istruzione, eseguiamo un upsert senza la necessità di specificare più comandi di inserimento e aggiornamento. Puoi impostare il MERGE dichiarazione in a Stored procedure per popolare i dati. Quindi pianifichi la stored procedure per l'esecuzione a livello di codice tramite l'editor di query, che dimostreremo più avanti nel post. Il codice seguente crea una stored procedure chiamata SalesMart.DimVenueLoad:
Alcune note sul caricamento delle dimensioni:
- Quando un record viene inserito per la prima volta, verranno popolate la data inserita e la data aggiornata. Quando qualsiasi valore cambia, i dati vengono aggiornati e la data aggiornata riflette la data in cui è stata modificata. La data inserita rimane.
- Poiché i dati verranno utilizzati dagli utenti aziendali, è necessario sostituire i valori NULL, se presenti, con valori più appropriati per l'azienda.
Identificare e implementare i fatti
Ora che abbiamo dichiarato che il nostro grano è l'evento di una vendita avvenuta in un momento specifico, la nostra tabella dei fatti memorizzerà i fatti numerici per il nostro processo aziendale.
Abbiamo identificato i seguenti fatti numerici da misurare:
- Quantità di biglietti venduti per vendita
- Commissione per la vendita
Attuazione del fatto
Ci sono tre tipi di tabelle dei fatti (tabella dei fatti delle transazioni, tabella dei fatti dell'istantanea periodica e tabella dei fatti dell'istantanea accumulata). Ognuno offre una visione diversa del processo aziendale. Per il nostro esempio, utilizziamo una tabella dei fatti di transazione. Completa i seguenti passaggi:
- Crea la tabella dei fatti
Viene aggiunta una data inserita con un valore predefinito, che indica se e quando è stato caricato un record. Puoi usarlo quando ricarichi la tabella dei fatti per rimuovere i dati già caricati per evitare duplicati.
Il caricamento della tabella dei fatti consiste in una semplice dichiarazione di inserimento che unisce le dimensioni associate. Ci uniamo dal DimVenue tabella che è stata creata, che descrive i nostri fatti. È la migliore pratica ma facoltativa da avere data del calendario dimensioni, che consentono all'utente finale di navigare nella tabella dei fatti. I dati possono essere caricati quando c'è una nuova vendita o giornalmente; è qui che torna utile la data inserita o la data di caricamento.
Carichiamo la tabella dei fatti utilizzando una procedura memorizzata e utilizziamo un parametro di data.
- Creare la stored procedure con il codice seguente. Per mantenere la stessa integrità dei dati che abbiamo applicato nel caricamento della dimensione, sostituiamo i valori NULL, se presenti, con valori più appropriati per l'azienda:
- Caricare i dati chiamando la procedura con il seguente comando:
Pianifica il caricamento dei dati
Ora possiamo automatizzare il processo di modellazione pianificando le stored procedure in Amazon Redshift Query Editor V2. Completa i seguenti passaggi:
- Per prima cosa chiamiamo il carico della dimensione e dopo che il caricamento della dimensione viene eseguito correttamente, inizia il caricamento dei fatti:
Se il caricamento della dimensione fallisce, il caricamento dei fatti non verrà eseguito. Ciò garantisce la coerenza dei dati perché non vogliamo caricare la tabella dei fatti con dimensioni obsolete.
- Per programmare il carico, scegli Programma nell'editor di query V2.

- Pianifichiamo l'esecuzione della query ogni giorno alle 5:00.
- Facoltativamente, puoi aggiungere notifiche di errore abilitando Servizio di notifica semplice Amazon (Amazon SNS) notifiche.

Segnala e analizza i dati in Amazon Quicksight
QuickSight è un servizio di business intelligence che semplifica la fornitura di insight. In quanto servizio completamente gestito, QuickSight ti consente di creare e pubblicare facilmente dashboard interattivi a cui è possibile accedere da qualsiasi dispositivo e incorporarli nelle tue applicazioni, portali e siti web.
Utilizziamo il nostro data mart per presentare visivamente i fatti sotto forma di dashboard. Per iniziare e configurare QuickSight, fare riferimento a Creazione di un set di dati utilizzando un database non rilevato automaticamente.
Dopo aver creato l'origine dati in QuickSight, uniamo i dati modellati (data mart) in base alla nostra chiave surrogata skey. Utilizziamo questo set di dati per visualizzare il data mart.

La nostra dashboard finale conterrà gli approfondimenti del data mart e risponderà a domande aziendali critiche, come la commissione totale per sede e le date con le vendite più elevate. Lo screenshot seguente mostra il prodotto finale del data mart.

ripulire
Per evitare di incorrere in futuri addebiti, elimina tutte le risorse che hai creato come parte di questo post.
Conclusione
Ora abbiamo implementato con successo un data mart utilizzando il nostro DimVenue, DimCalendare FactSaleTransactions tabelle. Il nostro magazzino non è completo; man mano che possiamo espandere il data mart con più fatti e implementare più mart, e man mano che i processi aziendali e i requisiti crescono nel tempo, lo stesso farà il data warehouse. In questo post, abbiamo fornito una visione end-to-end sulla comprensione e l'implementazione della modellazione dimensionale in Amazon Redshift.
Inizia con il tuo Amazon RedShift modello dimensionale oggi.
Informazioni sugli autori
 Bernard Verster è un ingegnere cloud esperto con anni di esperienza nella creazione di modelli di dati scalabili ed efficienti, nella definizione di strategie di integrazione dei dati e nella garanzia di governance e sicurezza dei dati. È appassionato di utilizzare i dati per generare insight, allineandosi con i requisiti e gli obiettivi aziendali.
Bernard Verster è un ingegnere cloud esperto con anni di esperienza nella creazione di modelli di dati scalabili ed efficienti, nella definizione di strategie di integrazione dei dati e nella garanzia di governance e sicurezza dei dati. È appassionato di utilizzare i dati per generare insight, allineandosi con i requisiti e gli obiettivi aziendali.
 Abhishek Pan è uno specialista WWSO SA-Analytics che lavora con i clienti del settore pubblico di AWS India. Collabora con i clienti per definire una strategia basata sui dati, fornire sessioni di approfondimento sui casi d'uso dell'analisi e progettare applicazioni analitiche scalabili e performanti. Ha 12 anni di esperienza ed è appassionato di database, analisi e AI/ML. È un avido viaggiatore e cerca di catturare il mondo attraverso l'obiettivo della sua fotocamera.
Abhishek Pan è uno specialista WWSO SA-Analytics che lavora con i clienti del settore pubblico di AWS India. Collabora con i clienti per definire una strategia basata sui dati, fornire sessioni di approfondimento sui casi d'uso dell'analisi e progettare applicazioni analitiche scalabili e performanti. Ha 12 anni di esperienza ed è appassionato di database, analisi e AI/ML. È un avido viaggiatore e cerca di catturare il mondo attraverso l'obiettivo della sua fotocamera.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Automobilistico/VE, Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- BlockOffset. Modernizzare la proprietà della compensazione ambientale. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- WRI
- accelerare
- accesso
- accessibile
- con precisione
- operanti in
- Legge
- aggiungere
- aggiunto
- aggiuntivo
- Dopo shavasana, sedersi in silenzio; saluti;
- AI / ML
- allineare
- allineamento
- consentire
- consente
- già
- am
- Amazon
- Amazon Web Services
- an
- .
- Analitico
- analitica
- analizzare
- ed
- rispondere
- in qualsiasi
- applicazioni
- applicato
- opportuno
- architettura
- SONO
- artificiale
- AS
- aspetti
- associato
- At
- gli attributi
- auto
- automatizzare
- automaticamente
- evitare
- AWS
- b
- basato
- BE
- perché
- iniziare
- vantaggi
- MIGLIORE
- incassato
- affari
- business intelligence
- Processo Di Business
- i processi di business
- ma
- by
- Calendario
- chiamata
- detto
- chiamata
- stanza
- Materiale
- catturare
- Custodie
- casi
- Causare
- certo
- il cambiamento
- cambiato
- Modifiche
- cambiando
- carattere
- oneri
- Scegli
- pulire campo
- chiaramente
- strettamente
- Cloud
- codice
- Colonna
- viene
- commissione
- Uncommon
- Aziende
- azienda
- completamento di una
- Prendere in considerazione
- coerente
- consiste
- contesto
- correggere
- potuto
- creare
- creato
- crea
- Creazione
- creazione
- critico
- Clienti
- alle lezioni
- cruscotto
- cruscotti
- dati
- integrazione dei dati
- Lago di dati
- data warehouse
- data-driven
- Strategia basata sui dati
- Banca Dati
- banche dati
- Data
- Date
- datetime
- giorno
- deep
- profonda immersione
- Predefinito
- definizione
- consegnare
- dimostrare
- dipartimenti
- derivato
- descrivere
- Design
- progettazione
- dettaglio
- dispositivo
- diverso
- Dimensioni
- dimensioni
- discutere
- distinto
- distribuzione
- do
- dominio
- fatto
- Dont
- giù
- guidare
- duplicati
- ogni
- In precedenza
- facilmente
- facile
- editore
- efficiente
- o
- incorporato
- enable
- consentendo
- fine
- da un capo all'altro
- impegna
- ingegnere
- garantire
- assicura
- assicurando
- Intero
- entità
- Etere (ETH)
- Evento
- eventi
- Ogni
- ogni giorno
- esempio
- Esempi
- Espandere
- esperienza
- esperto
- Esposizione
- estratto
- fatto
- fattore
- Fattori
- fatti
- fallisce
- Fallimento
- Caratteristiche
- pochi
- campo
- campi
- quinto
- figura
- filtro
- finale
- Nome
- prima volta
- in forma
- concentrato
- i seguenti
- Nel
- modulo
- formato
- quattro
- da
- completamente
- ulteriormente
- futuro
- Guadagno
- generare
- generato
- genera
- ottenere
- ottenere
- Dare
- dato
- buono
- la governance
- Crescere
- a portata di mano
- Avere
- he
- massimo
- il suo
- storico
- Vacanza
- Come
- Tutorial
- HTML
- http
- HTTPS
- IAM
- identificato
- identificare
- identificazione
- Identità
- if
- illustra
- Impact
- realizzare
- implementato
- Implementazione
- importante
- competenze
- miglioramento
- in
- Compreso
- India
- indicare
- indicando
- info
- intuizioni
- integrato
- integrazione
- interezza
- Intelligence
- interattivo
- ai miglioramenti
- IT
- SUO
- join
- congiunto
- accoppiamento
- Entra a far parte
- jpg
- mantenere
- conservazione
- Le
- Tasti
- lago
- Lingua
- dopo
- con i più recenti
- strato
- a sinistra
- lente
- Consente di
- Livello
- linea
- caricare
- Caricamento in corso
- carichi
- collocato
- cerca
- fatto
- FA
- gestito
- Marketing
- abbinato
- significato
- misurare
- menzionato
- Unire
- Metrica
- mente
- errore
- modello
- modellismo
- modellismo
- modelli
- Mese
- Scopri di più
- maggior parte
- multiplo
- nomi
- Naturale
- Navigare
- Bisogno
- che necessitano di
- esigenze
- New
- Note
- notifica
- notifiche
- adesso
- numerose
- Obiettivi d'Esame
- of
- offrire
- di frequente
- on
- esclusivamente
- operativa
- or
- organizzazione
- nostro
- ancora
- complessivo
- parametro
- parte
- appassionato
- per
- eseguire
- performance
- Forse
- periodico
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- popolata
- Post
- energia
- pratica
- prerequisiti
- presenti
- primario
- procedura
- procedure
- processi
- i processi
- Prodotto
- fornire
- purché
- fornisce
- la percezione
- pubblicare
- fini
- Domande
- rapidamente
- aumentare
- Crudo
- dati grezzi
- record
- record
- ridurre
- di cui
- riflette
- regione
- rapporto
- resti
- rimuovere
- sostituire
- rapporto
- Reportistica
- Report
- Requisiti
- Risorse
- responsabilità
- Ruolo
- Rotolo
- RIGA
- Correre
- corre
- vendita
- vendite
- stesso
- Set di dati di esempio
- scalabile
- programma
- programmazione
- sezioni
- settore
- problemi di
- vedere
- separato
- serve
- servizio
- Servizi
- sessioni
- set
- alcuni
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- Un'espansione
- semplicità
- singolo
- Lentamente
- piccole
- inferiore
- Istantanea
- So
- venduto
- soluzione
- alcuni
- Fonte
- fonti
- lo spazio
- specialista
- specifico
- in particolare
- Stage
- messa in scena
- Stella
- iniziato
- Di partenza
- dichiarazione
- step
- Passi
- conservazione
- Tornare al suo account
- memorizzati
- strategie
- Strategia
- La struttura
- di successo
- Con successo
- tale
- sistema
- tavolo
- temporaneo
- decine
- condizioni
- di
- che
- Il
- L’ORIGINE
- il mondo
- loro
- poi
- Là.
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- migliaia
- Attraverso
- biglietto
- vendita biglietti
- biglietti
- tempo
- volte
- timestamp
- suggerimenti
- a
- oggi
- insieme
- ha preso
- Totale
- pista
- delle transazioni
- Trasformare
- trasformato
- viaggiatore
- Digitare
- Tipi di
- tipicamente
- e una comprensione reciproca
- unico
- univocamente
- unicità
- Sconosciuto
- Aggiornanento
- aggiornato
- us
- Impiego
- uso
- caso d'uso
- utilizzato
- utenti
- usa
- utilizzando
- generalmente
- Prezioso
- APPREZZIAMO
- Valori
- vario
- LOCATION
- sedi
- via
- Visualizza
- volume
- walkthrough
- volere
- Magazzino
- Prima
- modi
- we
- sito web
- servizi web
- siti web
- settimana
- quando
- quale
- while
- volere
- con
- entro
- senza
- lavoro
- mondo
- Wrong
- anno
- anni
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro