Analisi automatizzata dei dati (ADA) su AWS è una soluzione AWS che ti consente di ricavare informazioni significative dai dati in pochi minuti attraverso un'interfaccia utente semplice e intuitiva. ADA offre una piattaforma di analisi dei dati nativa AWS pronta per essere utilizzata dagli analisti di dati per una varietà di casi d'uso. Con ADA, i team possono acquisire, trasformare, governare ed eseguire query su diversi set di dati da una vasta gamma di origini dati senza richiedere competenze tecniche specialistiche. ADA fornisce una serie di connettori precostituiti per acquisire dati da un'ampia gamma di origini, tra cui Servizio di archiviazione semplice Amazon (Amazon S3), Flussi di dati di Amazon Kinesis, Amazon Cloud Watch, Amazon Cloud Traile Amazon DynamoDB così come molti altri.
ADA fornisce una piattaforma fondamentale che può essere utilizzata dagli analisti di dati in una serie diversificata di casi d'uso tra cui IT, finanza, marketing, vendite e sicurezza. Il connettore dati CloudWatch pronto all'uso di ADA consente l'acquisizione di dati dai log CloudWatch nello stesso account AWS in cui è stato distribuito ADA o da un account AWS diverso.
In questo post dimostriamo come uno sviluppatore o un tester di applicazioni è in grado di utilizzare ADA per ricavare informazioni operative sulle applicazioni in esecuzione in AWS. Dimostriamo inoltre come utilizzare la soluzione ADA per connettersi a diverse origini dati in AWS. Noi per primi implementare la soluzione ADA in un account AWS e impostare la soluzione ADA creando prodotti di dati utilizzando connettori dati. Utilizziamo quindi ADA Query Workbench per unire i set di dati separati ed eseguire query sui dati correlati, utilizzando il familiare Structured Query Language (SQL), per ottenere approfondimenti. Dimostreremo anche come ADA può essere integrato con strumenti di business intelligence (BI) come Tableau per visualizzare i dati e creare report.
Panoramica della soluzione
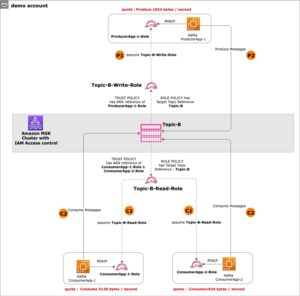
In questa sezione presentiamo l'architettura della soluzione per la demo e spieghiamo il flusso di lavoro. A scopo dimostrativo, l'applicazione personalizzata viene simulata utilizzando un file AWS Lambda funzione che emette i log in Formato registro di Apache ad un intervallo preimpostato utilizzando Amazon EventBridge. Questo formato standard può essere prodotto da molti server Web diversi ed essere letto da molti programmi di analisi dei registri. I log dell'applicazione (funzione Lambda) vengono inviati a un gruppo di log CloudWatch. I log storici dell'applicazione vengono archiviati in un bucket S3 come riferimento e a scopo di query. Una tabella di ricerca con un elenco di Codici di stato HTTP insieme alle descrizioni viene archiviato in una tabella DynamoDB. Questi tre fungono da origini da cui i dati vengono inseriti in ADA per correlazione, query e analisi. Noi implementare la soluzione ADA in un account AWS e istituire l'ADA. Creiamo quindi il prodotti di dati all'interno di ADA per il Gruppo di log di CloudWatch, Benna S3e DynamoDB. Man mano che i prodotti dati vengono configurati, ADA fornisce pipeline di dati per acquisire i dati dalle origini. Con ADA Query Workbench, puoi eseguire query sui dati acquisiti utilizzando SQL semplice per la risoluzione dei problemi dell'applicazione o la diagnosi dei problemi.
Il diagramma seguente fornisce una panoramica dell'architettura e del flusso di lavoro dell'utilizzo di ADA per ottenere informazioni dettagliate sui log dell'applicazione.
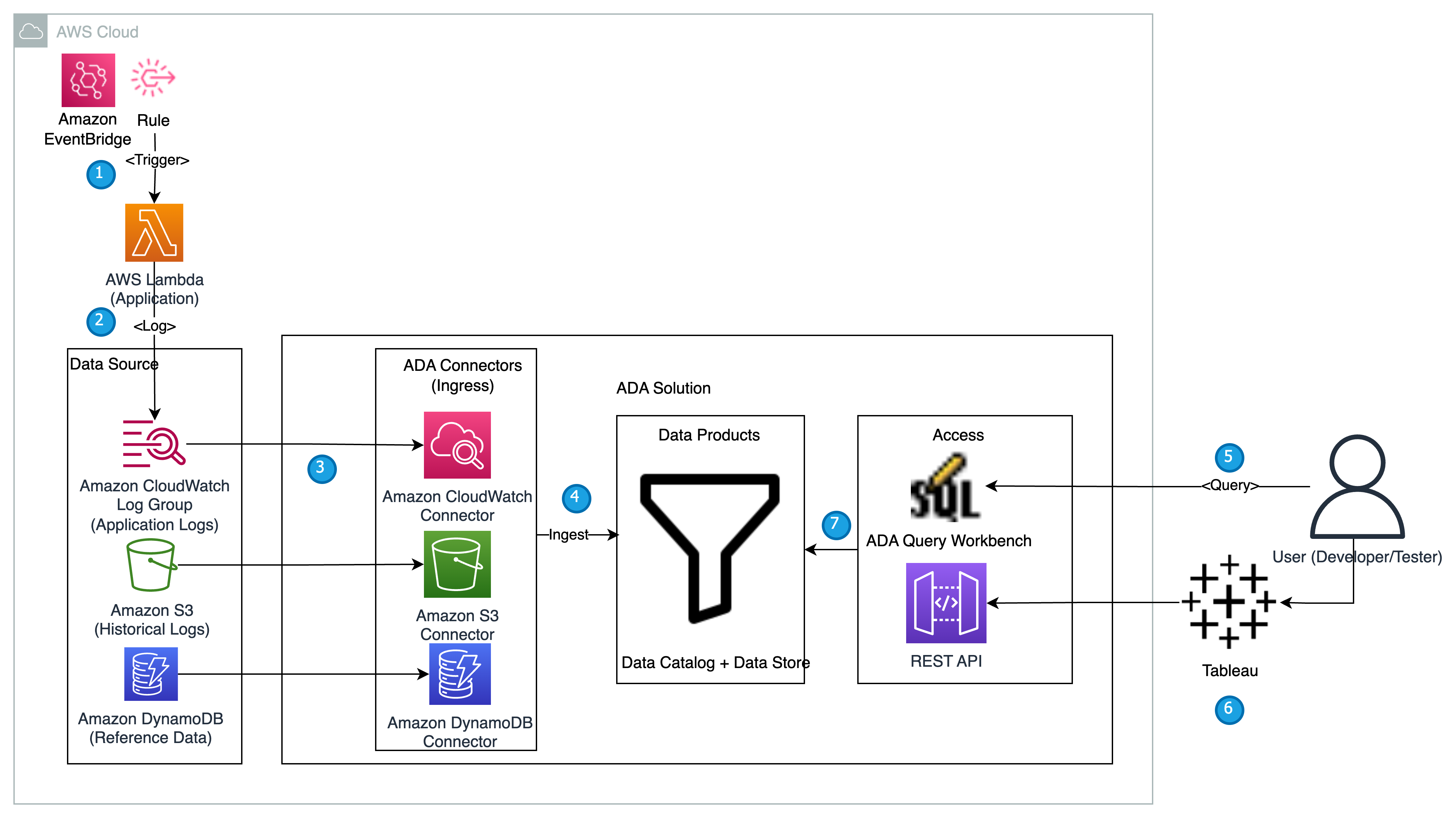
Il flusso di lavoro include i seguenti passaggi:
- È pianificata l'attivazione di una funzione Lambda a intervalli di 2 minuti utilizzando EventBridge.
- La funzione Lambda genera log archiviati in un gruppo di log CloudWatch specificato in
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. I log dell'applicazione vengono generati utilizzando lo schema Apache Log Format ma archiviati nel gruppo di log CloudWatch in formato JSON. - I prodotti dati per CloudWatch, Amazon S3 e DynamoDB vengono creati in ADA. Il prodotto dati CloudWatch si connette al gruppo di log CloudWatch in cui sono archiviati i log dell'applicazione (funzione Lambda). Il connettore Amazon S3 si connette a una cartella del bucket S3 in cui sono archiviati i log cronologici. Il connettore DynamoDB si connette a una tabella DynamoDB in cui sono archiviati i codici di stato a cui fa riferimento l'applicazione e i log cronologici.
- Per ciascuno dei prodotti dati, ADA distribuisce l'infrastruttura della pipeline di dati per acquisire dati dalle origini. Una volta completata l'acquisizione dei dati, è possibile scrivere query utilizzando SQL tramite ADA Query Workbench.
- È possibile accedere al portale ADA e comporre query SQL da Query Workbench per ottenere informazioni dettagliate sui registri dell'applicazione. Facoltativamente puoi salvare la query e condividerla con altri utenti ADA nello stesso dominio. La funzionalità di query ADA è fornita da Amazzone Atena, un servizio di analisi interattivo serverless che fornisce un modo semplificato e flessibile per analizzare petabyte di dati.
- Tableau è configurato per accedere ai prodotti dati ADA tramite endpoint in uscita ADA. Quindi crei una dashboard con due grafici. Il primo grafico è una mappa termica che mostra la prevalenza dei codici di errore HTTP correlati agli endpoint API dell'applicazione. Il secondo grafico è un grafico a barre che mostra le prime 10 API dell'applicazione con un conteggio totale di codici di errore HTTP dai dati cronologici.
Prerequisiti
Per questo post è necessario completare i seguenti prerequisiti:
- installare il Interfaccia della riga di comando di AWS (AWS CLI), Kit di sviluppo cloud AWS (AWSCDK) prerequisiti, specifico di TypeScript prerequisitie git.
- Schierare la soluzione ADA nel tuo account AWS in
us-east-1Regione.- Fornire un'e-mail di amministratore durante l'avvio di ADA AWS CloudFormazione pila. Ciò è necessario affinché ADA invii la password dell'utente root. È necessario un numero di telefono amministratore per ricevere un messaggio con password monouso se è abilitata l'autenticazione a più fattori (MFA). Per questa demo, l'MFA non è abilitato.
- Compila e distribuisci l'applicazione di esempio (disponibile su Repository GitHub) soluzione in modo che sia possibile eseguire il provisioning delle seguenti risorse nel tuo account in
us-east-1Regione:- Una funzione Lambda che simula l'applicazione di registrazione e una regola EventBridge che richiama la funzione dell'applicazione a intervalli di 2 minuti.
- Un bucket S3 con le policy del bucket pertinenti e un file CSV che contiene i log storici dell'applicazione.
- Una tabella DynamoDB con i dati di ricerca.
- Pertinente Gestione dell'identità e dell'accesso di AWS (IAM) ruoli e autorizzazioni richiesti per i servizi.
- Facoltativamente, installa Tableau Desktop, un fornitore di BI di terze parti. Per questo post utilizziamo Tableau Desktop versione 2021.2. L'utilizzo di una versione con licenza dell'applicazione Tableau Desktop comporta un costo. Per ulteriori dettagli, fare riferimento a Licenza Tableau informazioni.
Distribuire e configurare ADA
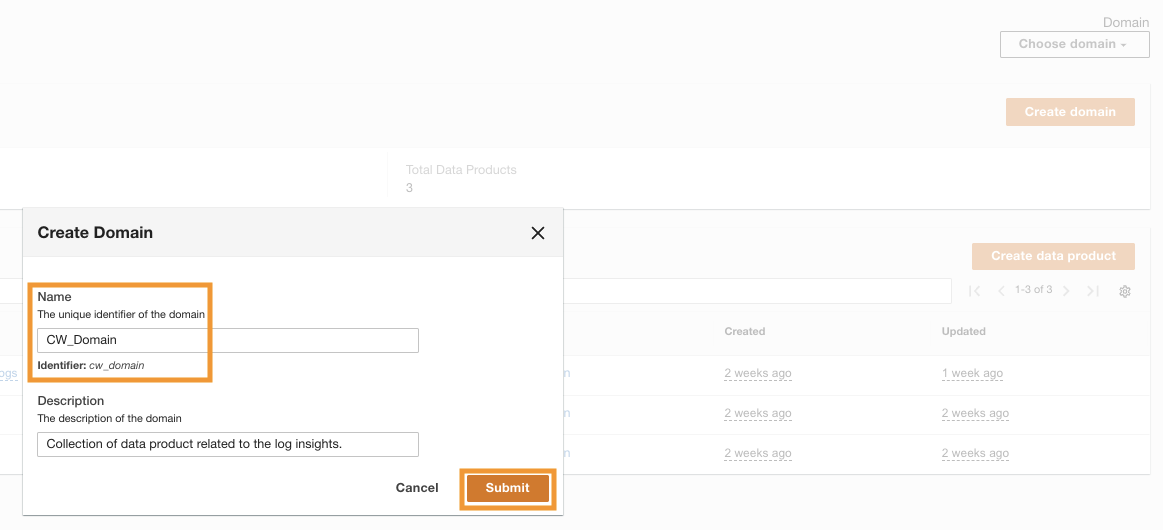
Dopo che ADA è stato distribuito correttamente, puoi farlo log in utilizzando l'e-mail dell'amministratore fornita durante l'installazione. Quindi crei un file dominio detto CW_Domain. Un dominio è una raccolta di prodotti dati definita dall'utente. Ad esempio, un dominio potrebbe essere un team o un progetto. I domini forniscono agli utenti un modo strutturato per organizzare i propri prodotti dati e gestire le autorizzazioni di accesso.
- Sulla console ADA, scegli Domini nel pannello di navigazione.
- Scegli Crea dominio.
- Inserisci un nome (
CW_Domain) e la descrizione, quindi scegliere Invio.
Configura l'infrastruttura dell'applicazione di esempio utilizzando AWS CDK
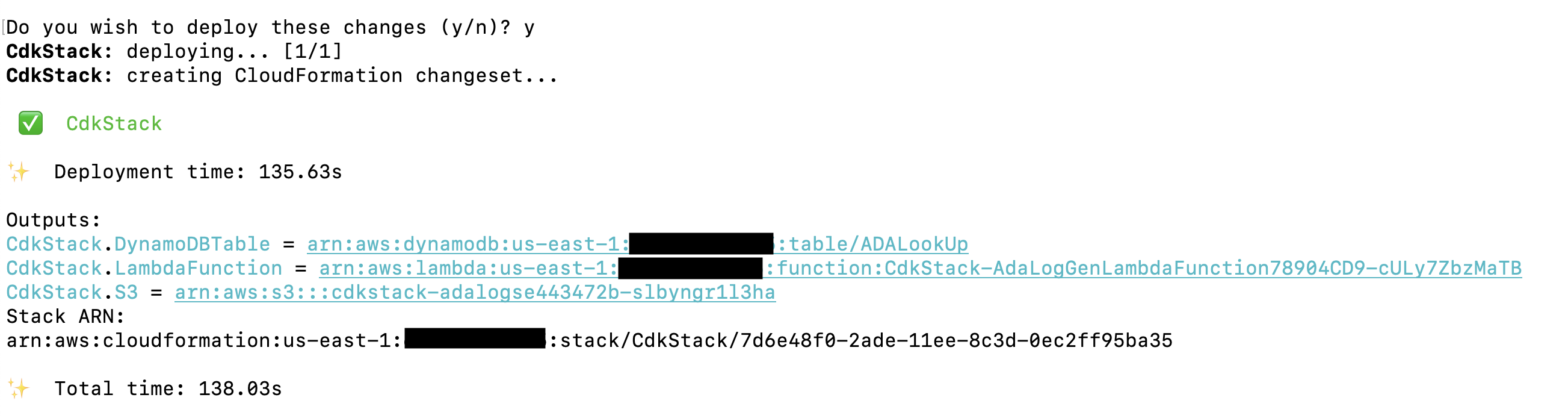
È ospitata la soluzione AWS CDK che distribuisce l'applicazione demo GitHub. I passaggi per clonare il repository e configurare il progetto AWS CDK sono dettagliati in questa sezione. Prima di eseguire questi comandi, assicurati di farlo configure le tue credenziali AWS. Crea una cartella, apri il terminale e accedi alla cartella in cui deve essere installata la soluzione AWS CDK. Esegui il seguente codice:
Questi passaggi eseguono le seguenti azioni:
- Installa le dipendenze della libreria
- Costruisci il progetto
- Genera un modello CloudFormation valido
- Distribuisci lo stack utilizzando AWS CloudFormation nel tuo account AWS
La distribuzione richiede circa 1-2 minuti e crea la tabella di ricerca DynamoDB, la funzione Lambda e il bucket S3 contenente i file di log cronologici come output. Copia questi valori in un'applicazione di modifica del testo, come Blocco note.
Creare prodotti dati ADA
Creiamo tre diversi prodotti dati per questa demo, uno per ciascuna origine dati su cui eseguirai query per ottenere informazioni operative. Un prodotto dati è un set di dati (una raccolta di dati come una tabella o un file CSV) che è stato importato con successo in ADA e su cui è possibile eseguire query.
Crea un prodotto dati CloudWatch
Innanzitutto, creiamo un prodotto dati per i log dell'applicazione configurando ADA per acquisire il gruppo di log CloudWatch per l'applicazione di esempio (funzione Lambda). Usa il CdkStack.LambdaFunction output per ottenere l'ARN della funzione Lambda e individuare l'ARN del gruppo di log CloudWatch corrispondente sulla console CloudWatch.
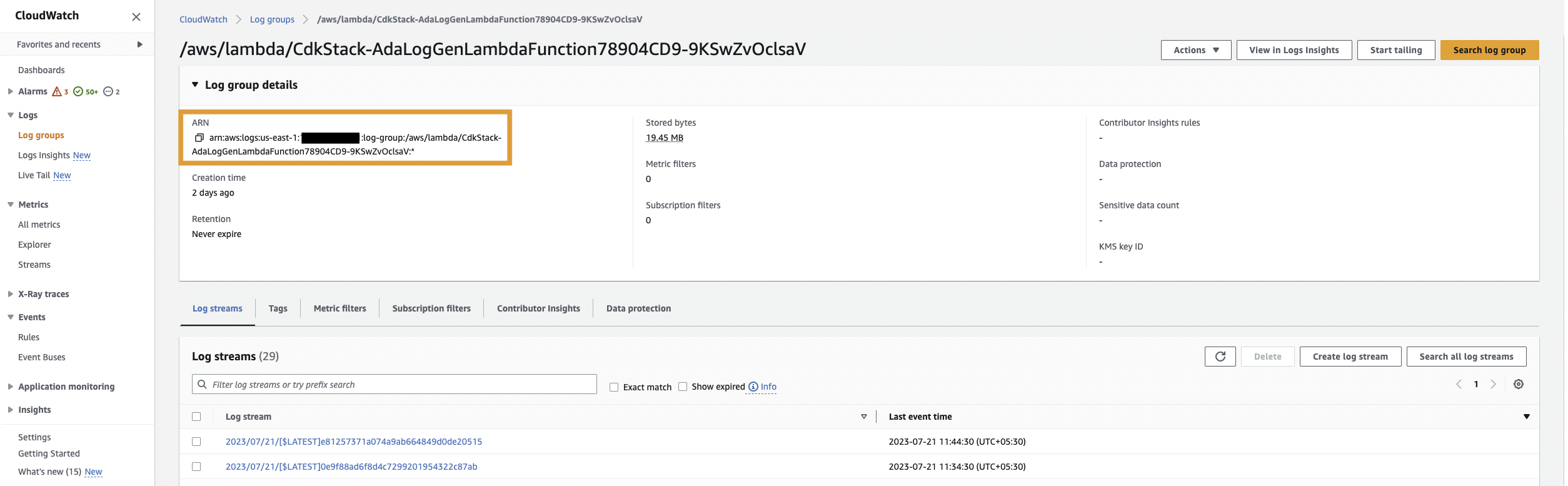
Quindi completare i seguenti passaggi:
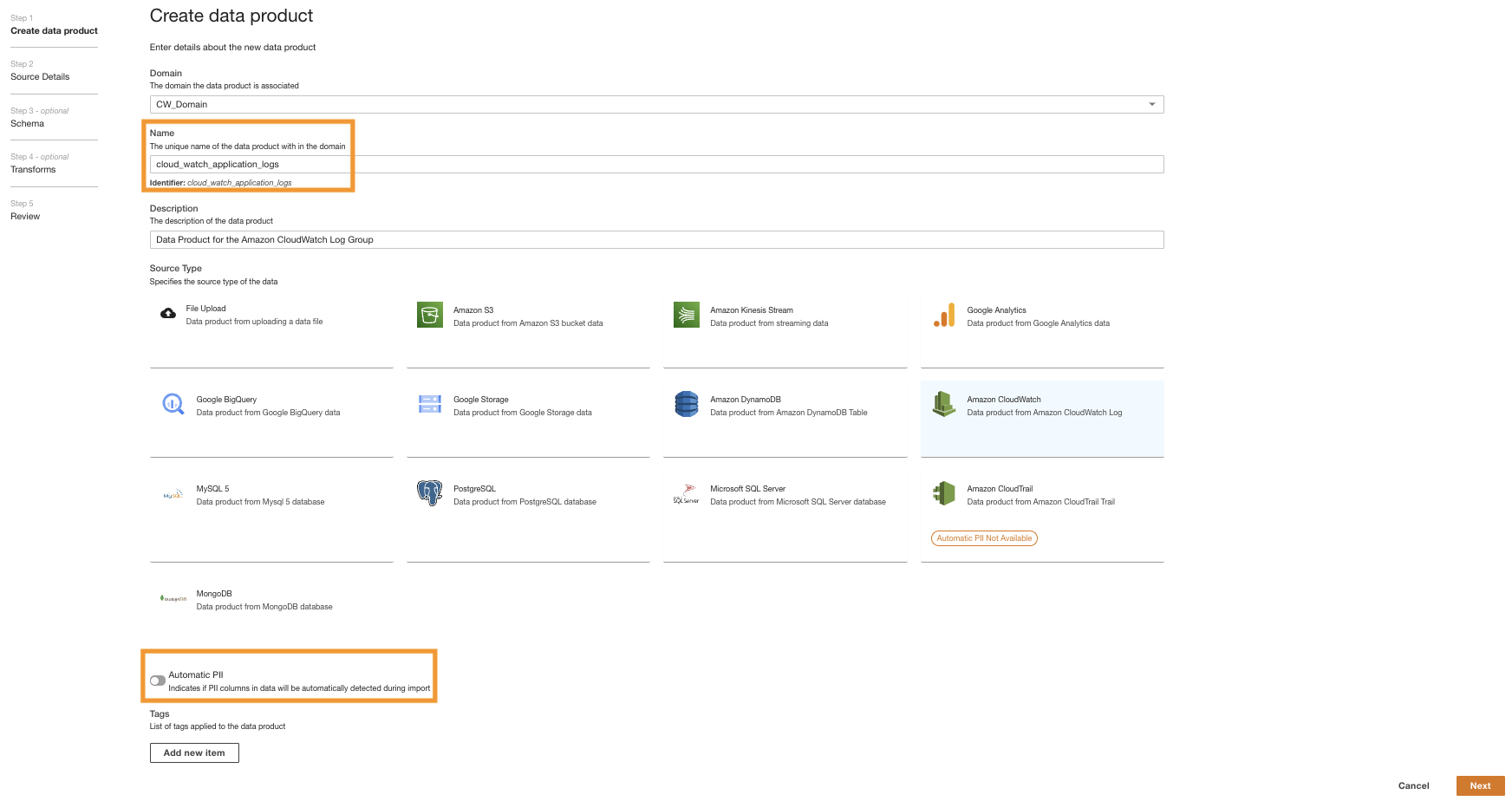
- Nella console ADA, vai al dominio ADA e crea un prodotto dati CloudWatch.
- Nel Nome¸ inserisci un nome.
- Nel Tipo di fonte, scegliere Amazon Cloud Watch.
- Disabilita Informazioni personali automatiche.
ADA dispone di una funzionalità abilitata per impostazione predefinita che rileva automaticamente i dati delle informazioni di identificazione personale (PII) durante l'importazione. Per questa demo, disabilitiamo questa opzione per il prodotto dati perché il rilevamento dei dati PII non rientra nell'ambito di questa demo.
- Scegli Avanti.
- Cerca e scegli l'ARN del gruppo di log CloudWatch copiato dal passaggio precedente.

- Copia l'ARN del gruppo di log.
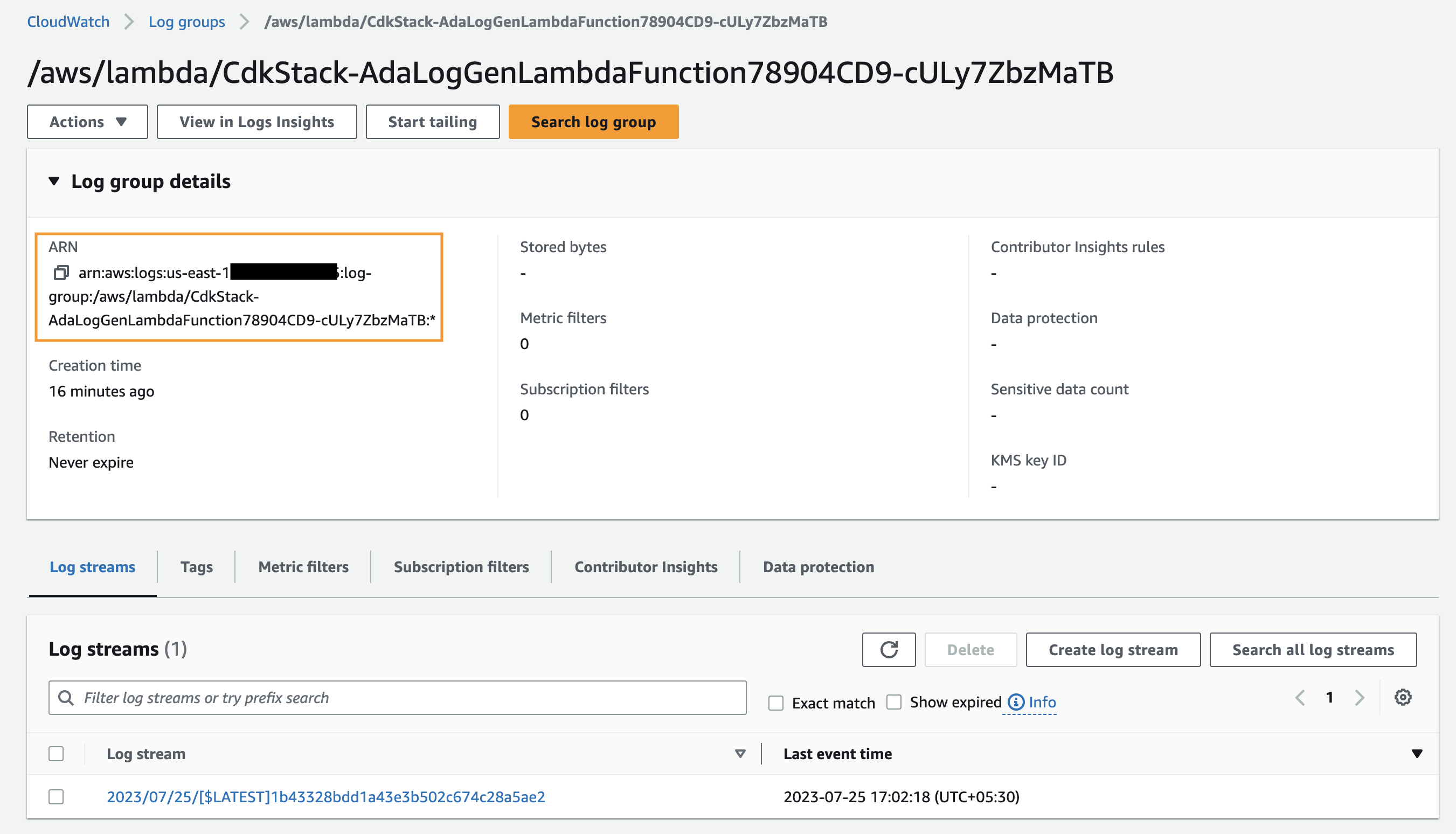
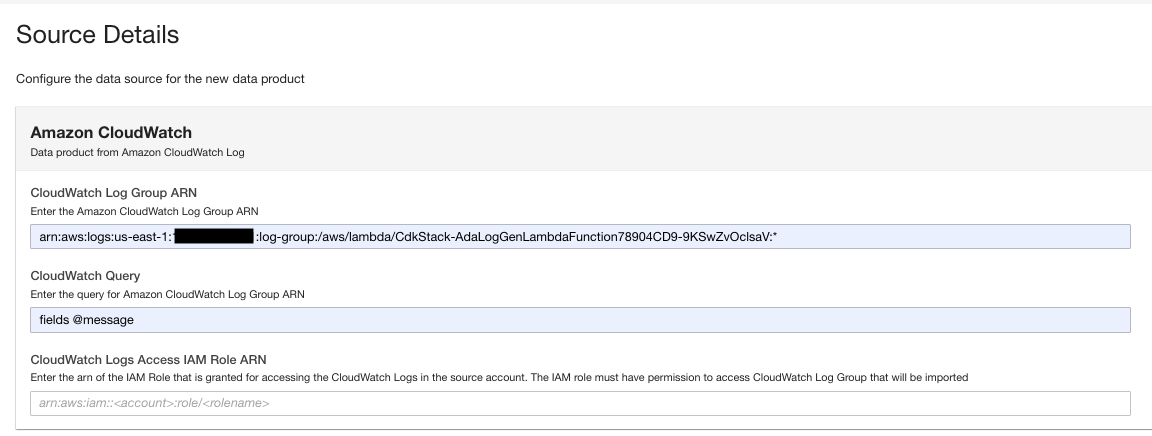
- Nella pagina del prodotto dati, inserisci l'ARN del gruppo di log.
- Nel Query CloudWatch, inserisci una query che desideri che ADA riceva dal gruppo di log.
In questa demo interroghiamo il campo @message perché siamo interessati a ottenere i log dell'applicazione dal gruppo di log.
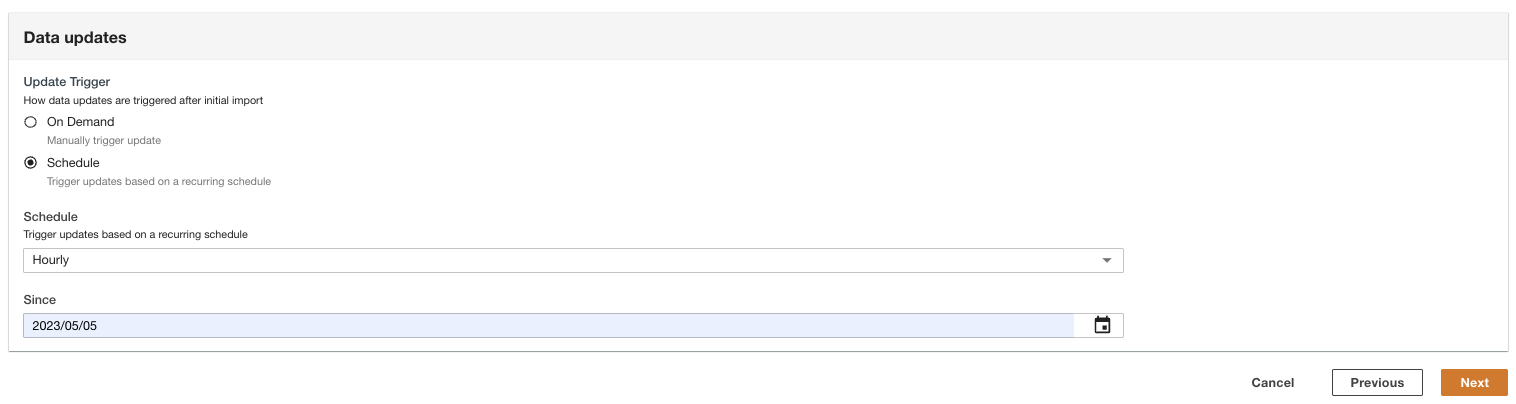
- Seleziona la modalità di attivazione degli aggiornamenti dei dati dopo l'importazione iniziale.
ADA può essere configurato per acquisire i dati dall'origine a intervalli flessibili (fino a 15 minuti o successivi) o su richiesta. Per la demo, impostiamo l'esecuzione degli aggiornamenti dei dati ogni ora.
- Scegli Avanti.
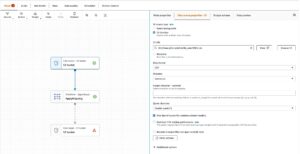
Successivamente, ADA si connetterà al gruppo di log ed interrogherà lo schema. Poiché i log sono in formato log Apache, trasformiamo i log in campi separati in modo da poter eseguire query sui campi di log specifici. ADA ne fornisce quattro difetto trasformazioni e supporta la trasformazione personalizzata tramite uno script Python. In questa demo eseguiamo uno script Python personalizzato per trasformare il campo del messaggio JSON in campi del formato registro Apache.
- Scegli Trasforma lo schema.
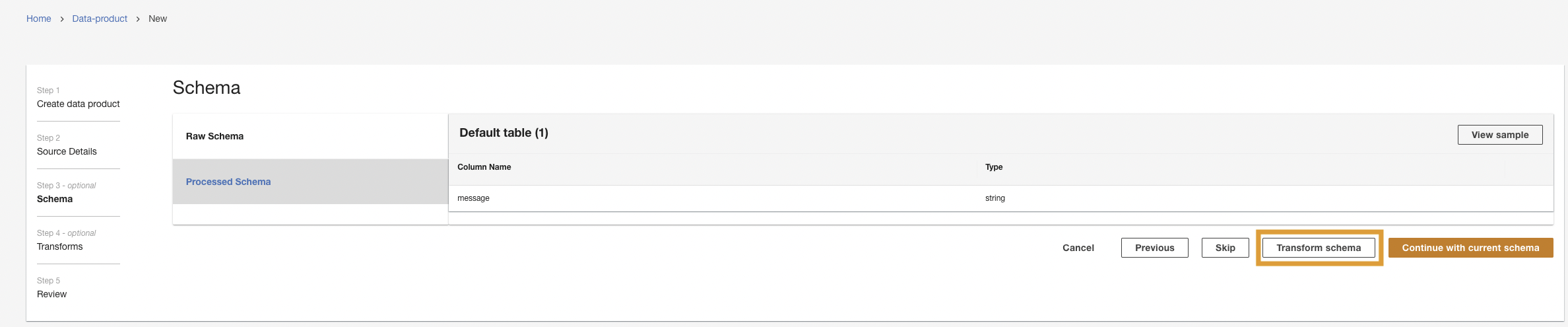
- Scegli Crea una nuova trasformazione.
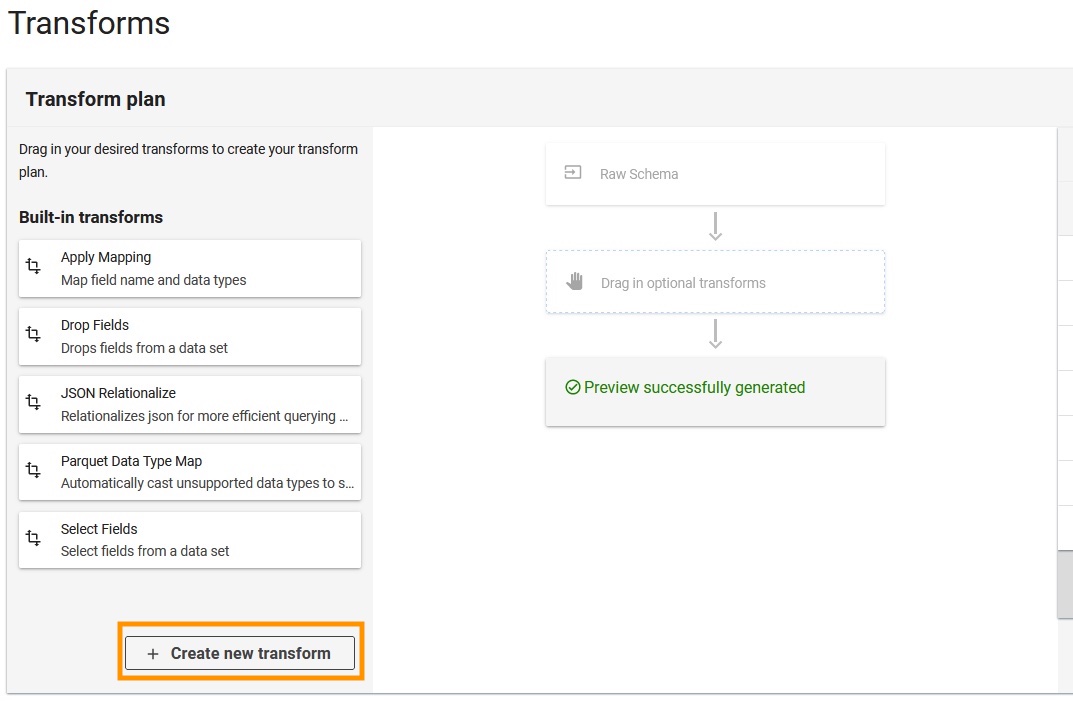
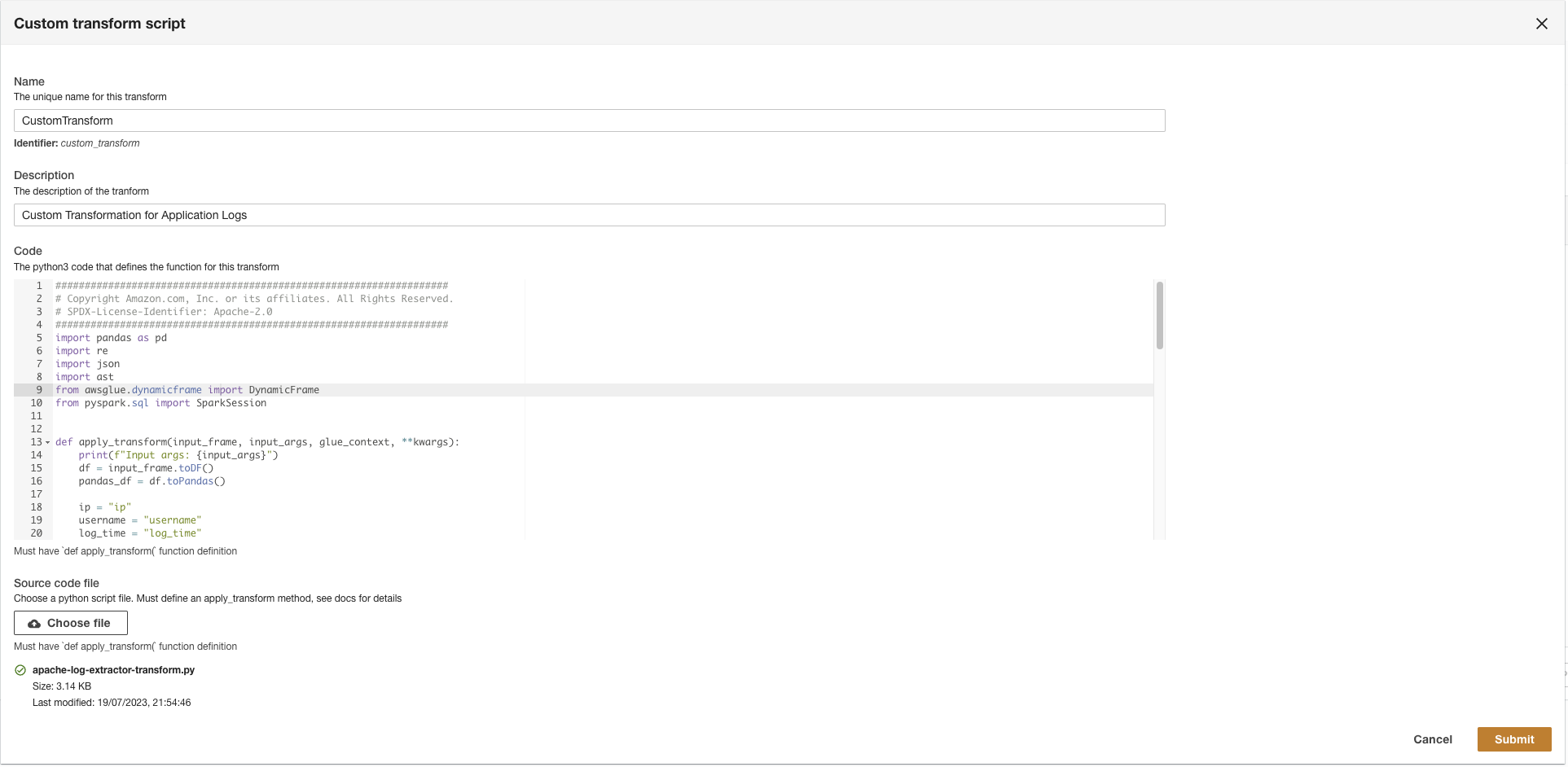
- Carica il
apache-log-extractor-transform.pyscript da/asset/transform_logs/cartella. - Scegli Invio.
ADA trasformerà i log CloudWatch utilizzando lo script e presenterà lo schema elaborato.
- Scegli Avanti.
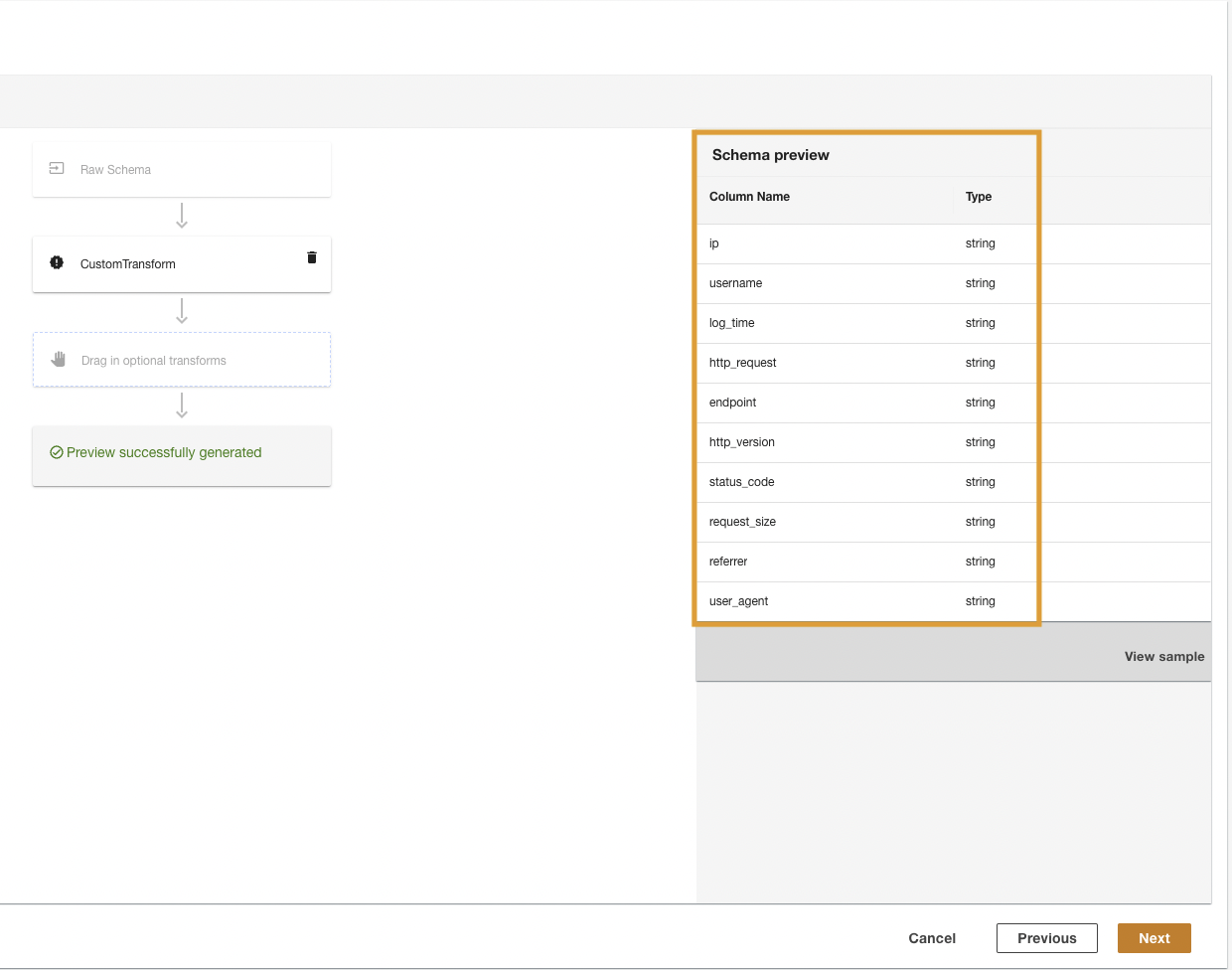
- Nell'ultimo passaggio, rivedi i passaggi e scegli Invio.
ADA avvierà l'elaborazione dei dati, creerà le pipeline di dati e preparerà i gruppi di log CloudWatch da interrogare dal Query Workbench. Il completamento di questo processo richiederà alcuni minuti e verrà visualizzato sulla console ADA di seguito Prodotti dati.
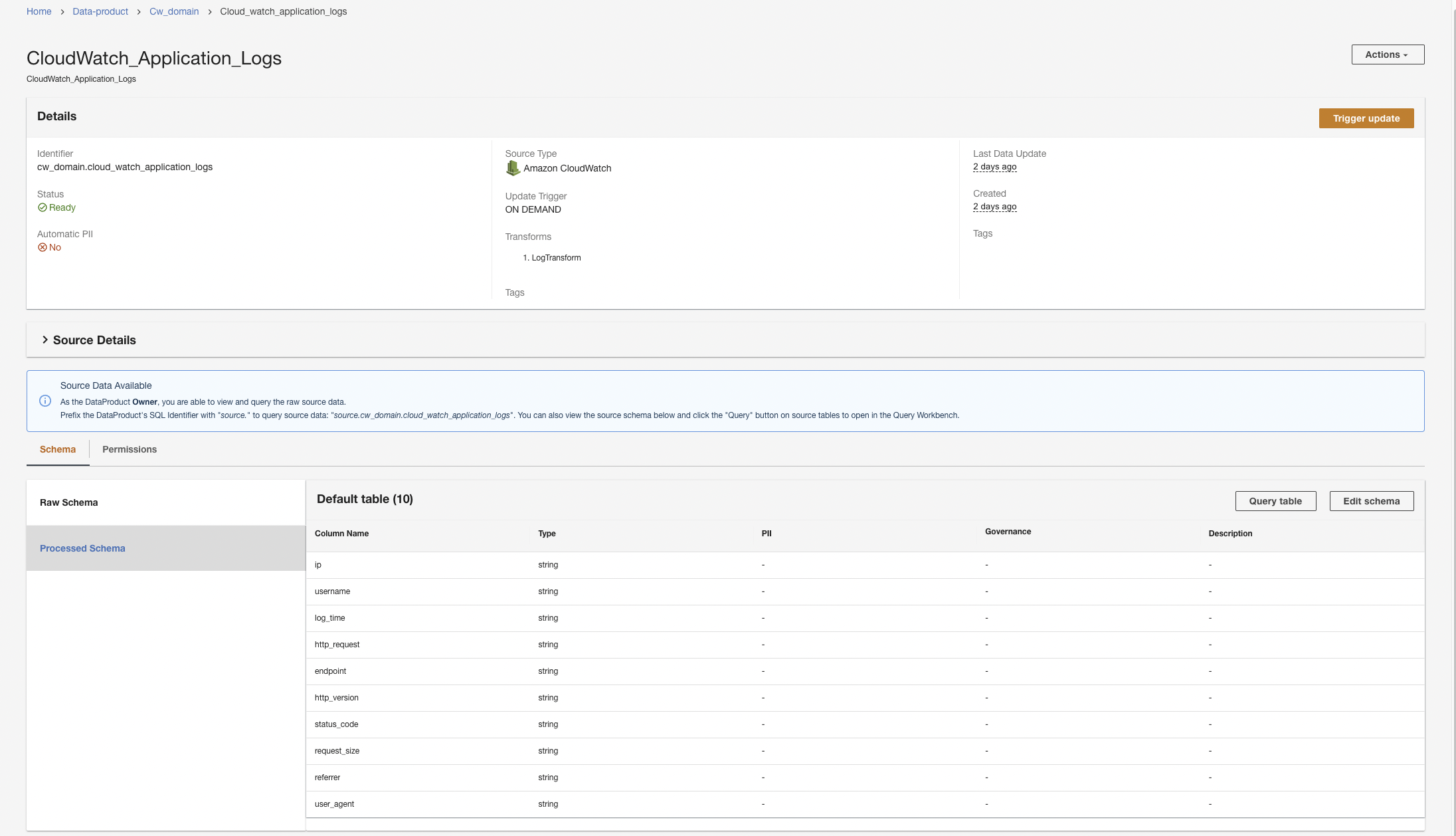
Creare un prodotto dati Amazon S3
Ripetiamo i passaggi per aggiungere i log storici dall'origine dati Amazon S3 e cercare i dati di riferimento dalla tabella DynamoDB. Per queste due origini dati, non creiamo trasformazioni personalizzate perché i formati dei dati sono in formato CSV (per i log storici) e attributi chiave (per i dati di ricerca di riferimento).
- Nella console ADA, crea un nuovo prodotto dati.
- Inserisci un nome (
hist_logs) e scegli Amazon S3.
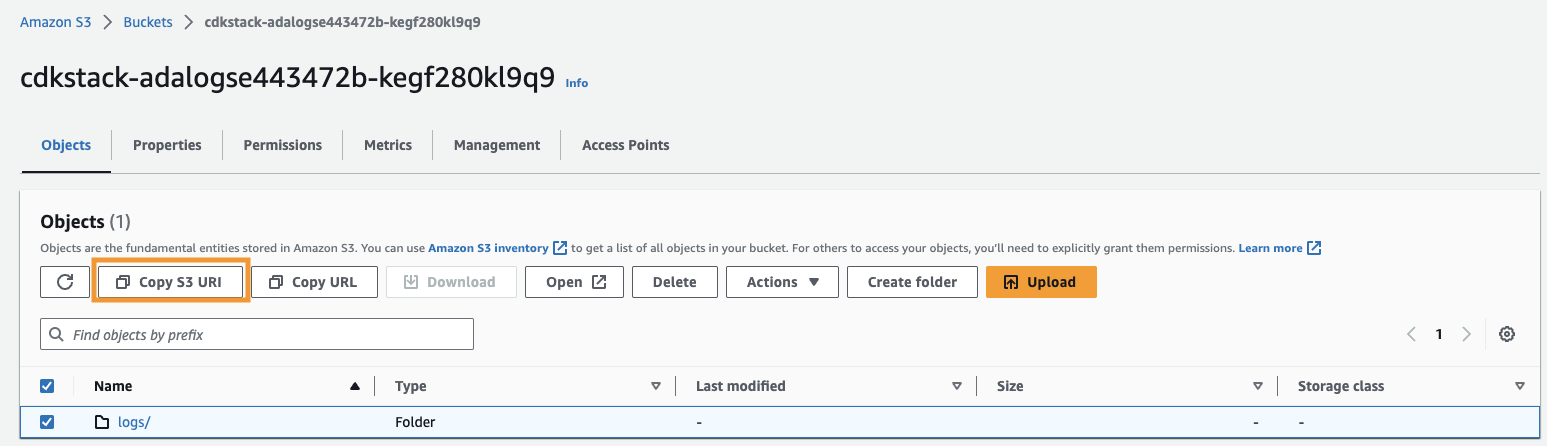
- Copia l'URI di Amazon S3 (il testo dopo
arn:aws:s3:::) dalCdkStack.S3variabile di output e accedere alla console Amazon S3. - Nella casella di ricerca, inserisci il testo copiato, apri il bucket S3, seleziona il file
/logscartella e scegli Copia URI S3.
I log storici vengono archiviati in questo percorso.
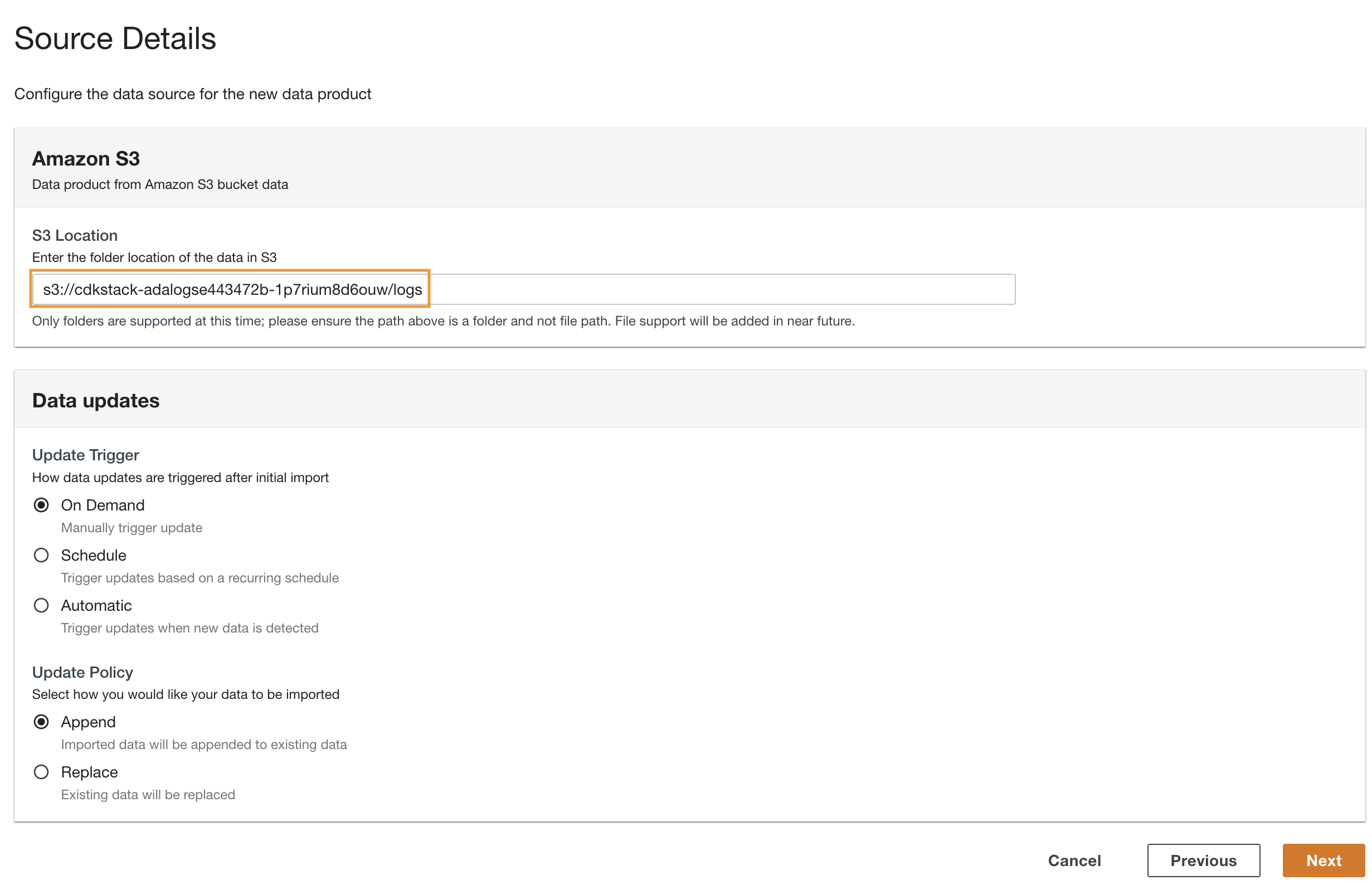
- Torna alla console ADA e inserisci l'URI S3 copiato per Posizione S3.
- Nel Aggiorna trigger, selezionare On Demand perché i log storici vengono aggiornati con una frequenza non specificata.
- Nel Aggiorna politica, selezionare Aggiungere per aggiungere i dati appena importati ai dati esistenti.
- Scegli Avanti.
ADA elabora lo schema per i file nel percorso della cartella selezionata. Poiché i log sono in formato CSV, ADA è in grado di leggere i nomi delle colonne senza richiedere ulteriori trasformazioni. Tuttavia, le colonne status_code ed request_size vengono dedotti come tipo lungo da ADA. Vogliamo mantenere i tipi di dati delle colonne coerenti tra i prodotti di dati in modo da poter unire le tabelle di dati ed eseguire query sui dati. La colonna status_code verrà utilizzato per creare join tra le tabelle di dati.
- Scegli Trasforma lo schema per modificare i tipi di dati delle due colonne nel tipo di dati stringa.
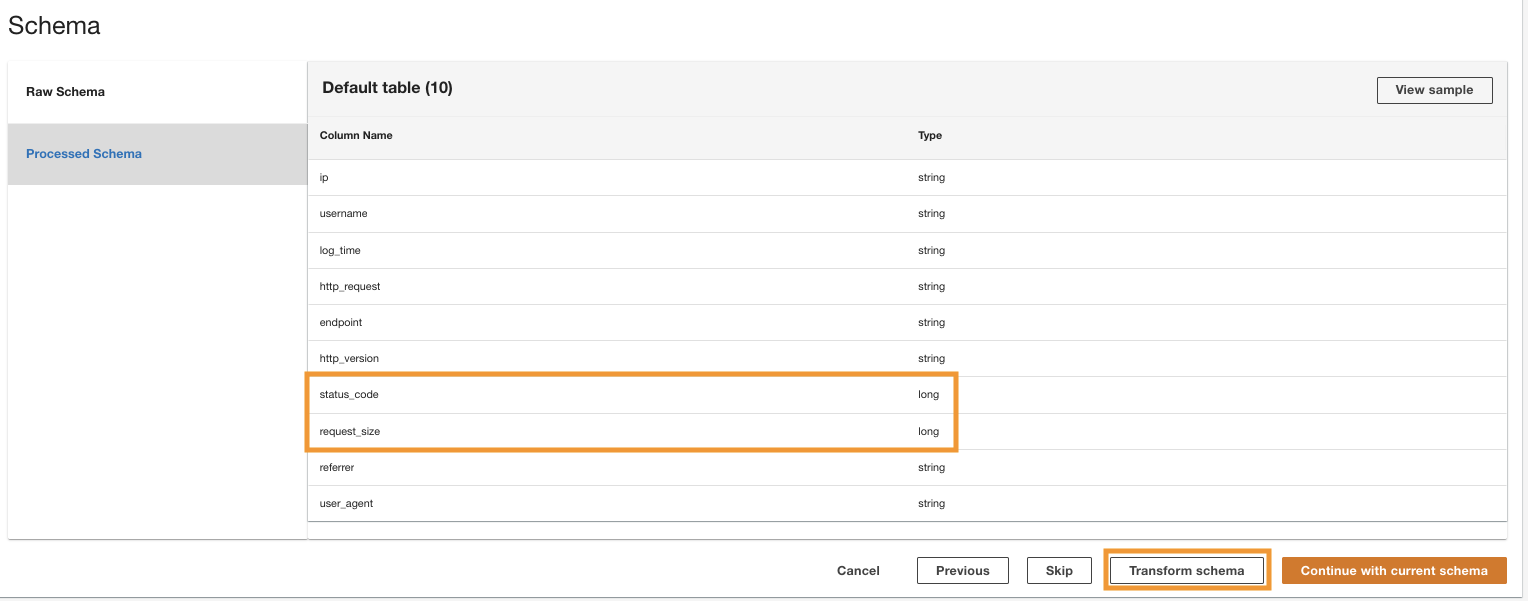
Prendi nota dei nomi delle colonne evidenziate nel file Anteprima dello schema riquadro prima di applicare le trasformazioni del tipo di dati.
- Nel Piano di trasformazione riquadro, sotto Trasformazioni integratescegli Applica la mappatura.
Questa opzione consente di modificare il tipo di dati da un tipo all'altro.
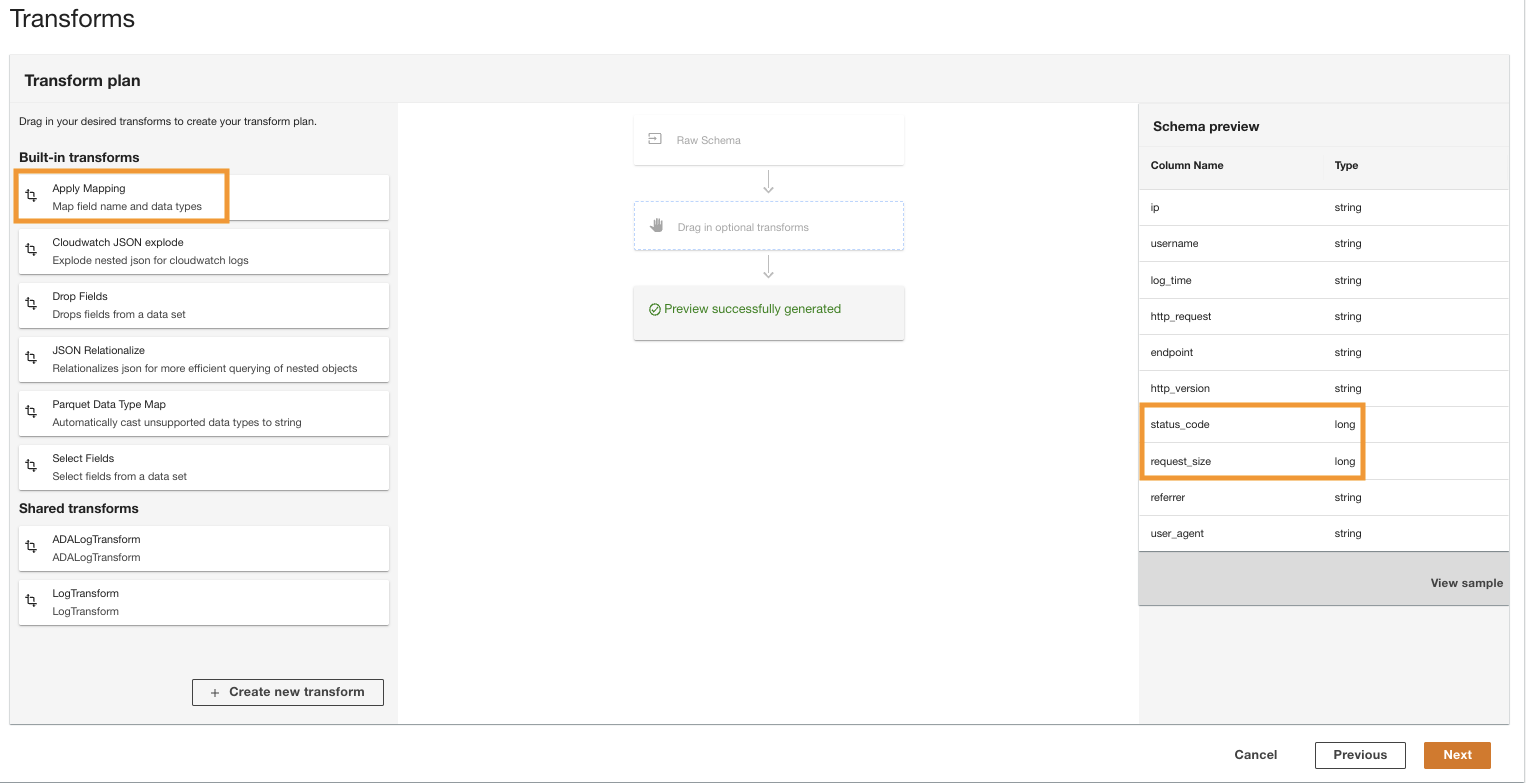
- Nel Applica la mappatura sezione, deseleziona Elimina altri campi.
Se questa opzione non è disabilitata, verranno conservate solo le colonne trasformate e tutte le altre colonne verranno eliminate. Poiché vogliamo conservare tutte le colonne, disabilitiamo questa opzione.
- Sotto Mappature dei campi¸ per Vecchio nome ed Nuovo nome, accedere
status_codee per Nuovo tipo, accederestring.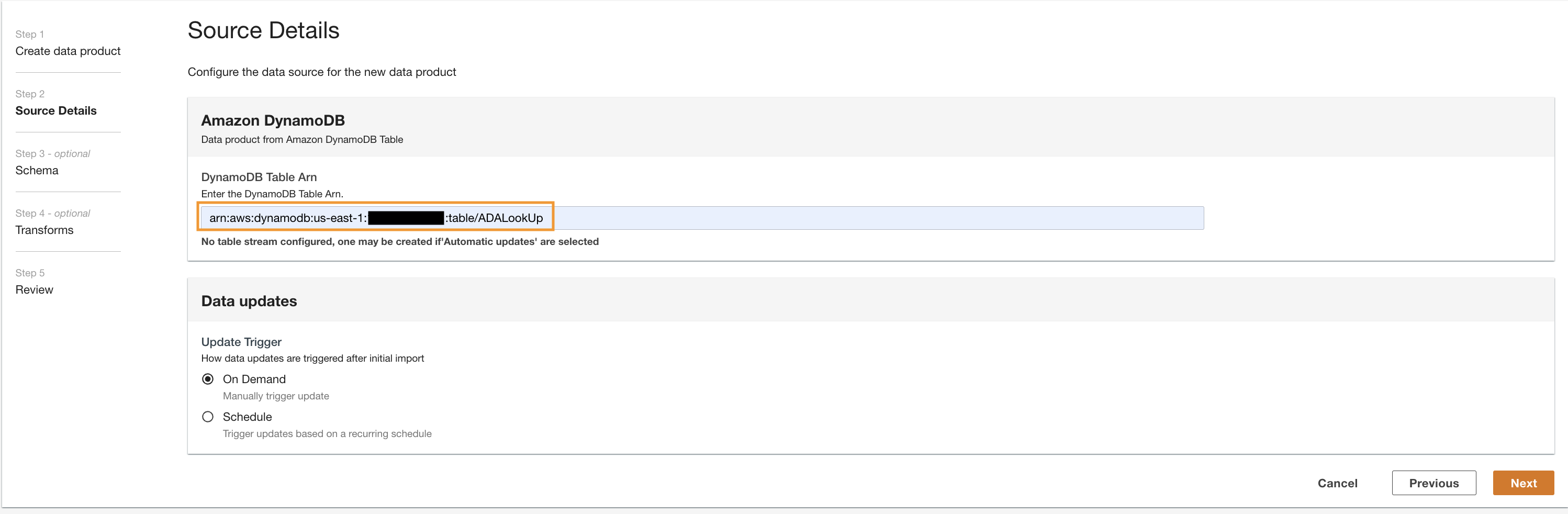
- Scegli Aggiungi articolo.
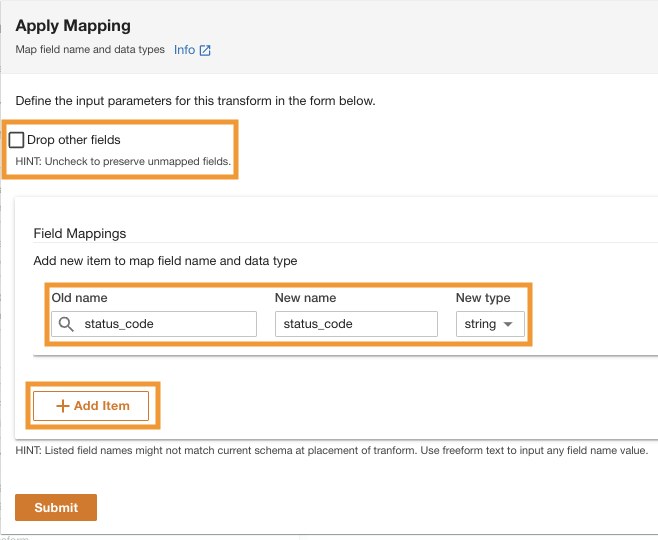
- Nel Vecchio nome ed Nuovo nome¸ inserire request_size e for Nuovo tipo di dati, inserisci la stringa.
- Scegli Invio.
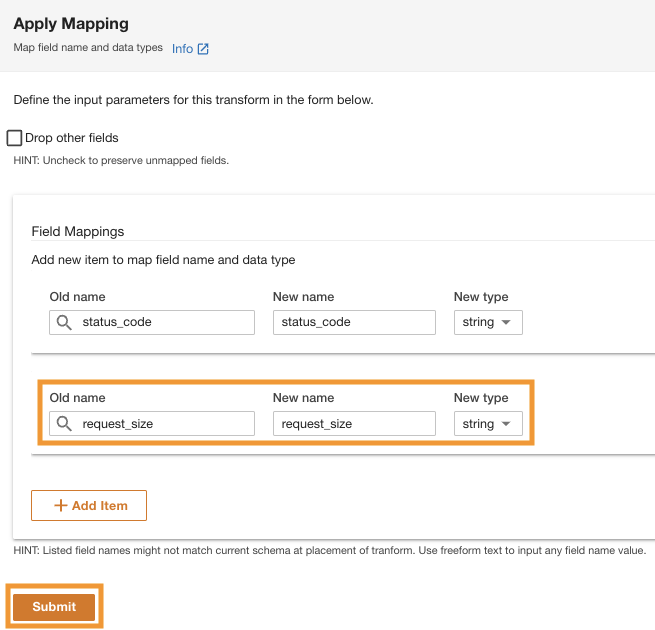
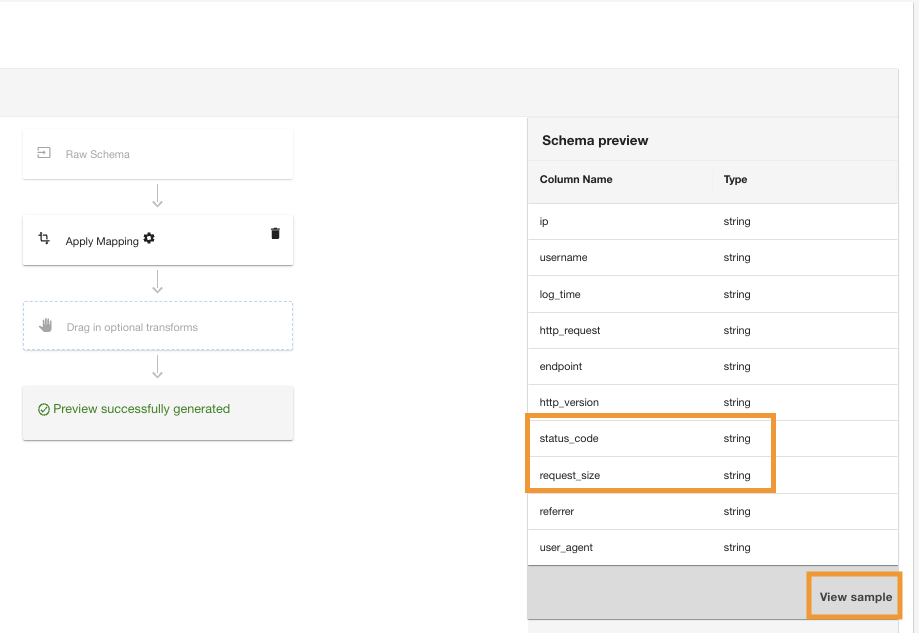
ADA applicherà la trasformazione della mappatura sull'origine dati Amazon S3. Nota i tipi di colonna in Anteprima dello schema riquadro.
- Scegli Visualizza campione per visualizzare in anteprima i dati con la trasformazione applicata.
ADA visualizzerà la conferma dei dati PII per garantire che solo gli utenti autorizzati possano visualizzare i dati o che il set di dati non contenga dati PII.
- Scegli Concordare per continuare a visualizzare i dati di esempio.
Tieni presente che lo schema è identico allo schema del gruppo di log CloudWatch perché sia i log dell'applicazione corrente che quelli storici sono in formato log Apache.
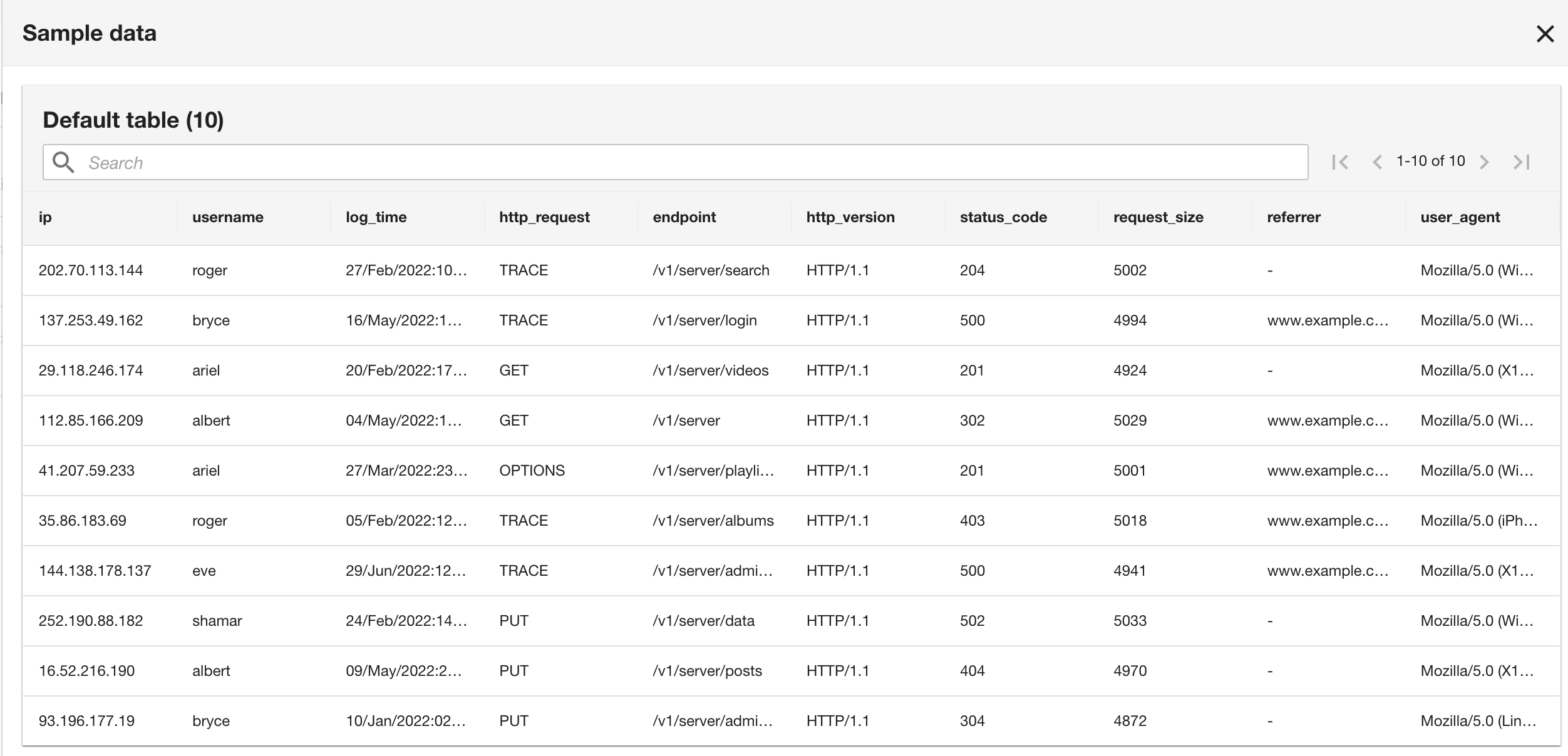
- Nel passaggio finale, rivedi la configurazione e scegli Invio.
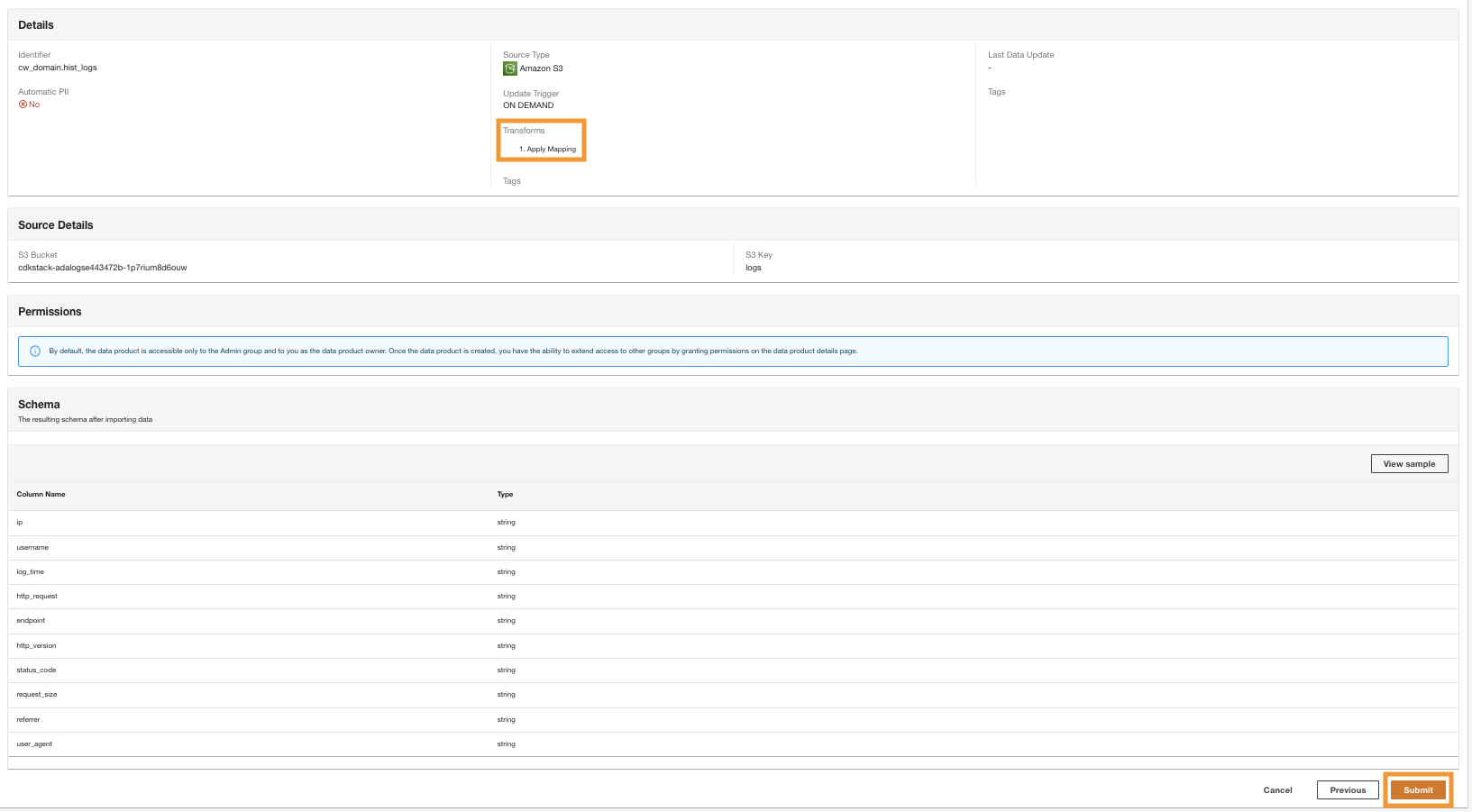
ADA inizia a elaborare i dati dall'origine Amazon S3, crea l'infrastruttura backend e prepara il prodotto dati. Questo processo richiede alcuni minuti a seconda della dimensione dei dati.
Crea un prodotto dati DynamoDB
Infine, creiamo un prodotto dati DynamoDB. Completa i seguenti passaggi:
- Nella console ADA, crea un nuovo prodotto dati.
- Inserisci un nome (
lookup) e scegli Amazon DynamoDB.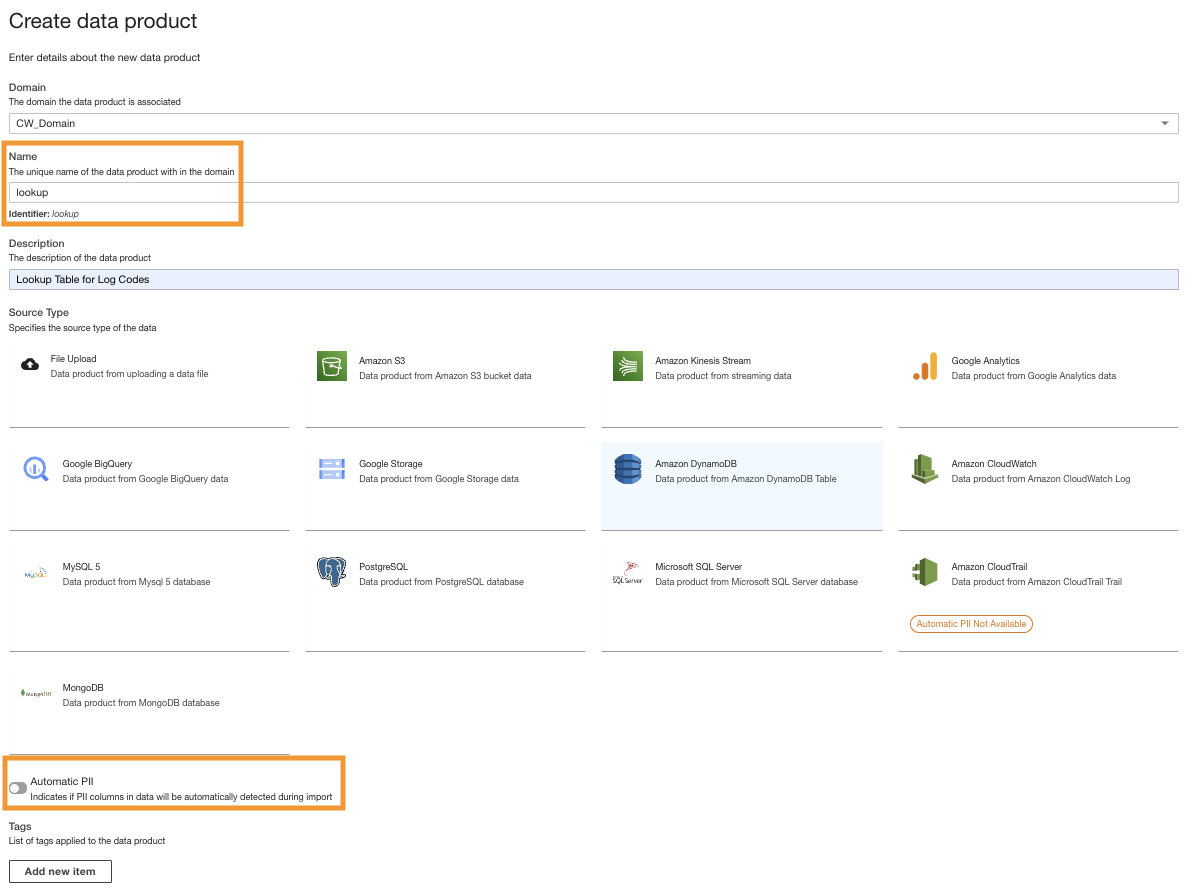
- Inserire il
Cdk.DynamoDBTablevariabile di uscita per ARN della tabella DynamoDB.
Questa tabella contiene attributi chiave che verranno utilizzati come tabella di ricerca in questa demo. Per i dati di ricerca, utilizziamo i codici HTTP e le descrizioni lunghe e brevi dei codici. In alternativa puoi anche utilizzare PostgreSQL, MySQL o un'origine file CSV.
- Nel Aggiorna trigger, selezionare On-Demand.
Gli aggiornamenti saranno su richiesta perché la ricerca è principalmente a scopo di riferimento durante l'esecuzione di query e tutti gli aggiornamenti ai dati di ricerca possono essere aggiornati in ADA utilizzando trigger su richiesta.
- Scegli Avanti.
ADA legge lo schema dallo schema DynamoDB sottostante e presenta il nome e il tipo della colonna per la trasformazione facoltativa. Procederemo con la selezione dello schema predefinito perché i tipi di colonna sono coerenti con i tipi del gruppo di log CloudWatch e dell'origine dati CSV Amazon S3. Avere tipi di dati coerenti tra le origini dati ci consente di scrivere query per recuperare i record unendo le tabelle utilizzando i campi delle colonne. Ad esempio, la colonna key nello schema DynamoDB corrisponde a status_code nei prodotti dati Amazon S3 e CloudWatch. Possiamo scrivere query che possano unire le tre tabelle utilizzando il nome della colonna key. Un esempio è mostrato nella sezione successiva.
- Scegli Continua con lo schema attuale.
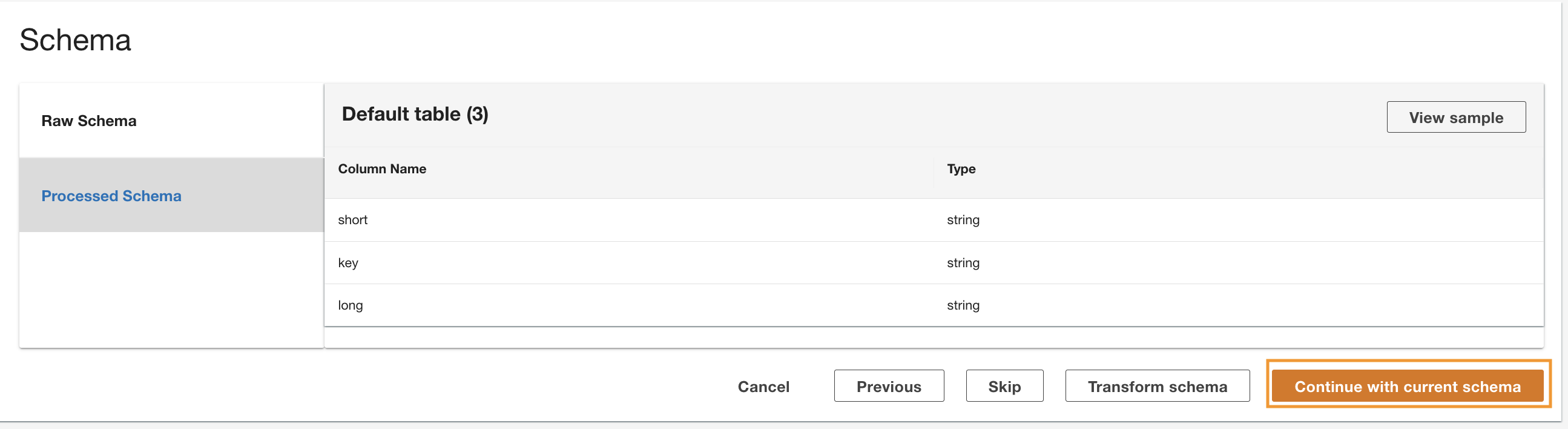
- Rivedi la configurazione e scegli Invio.
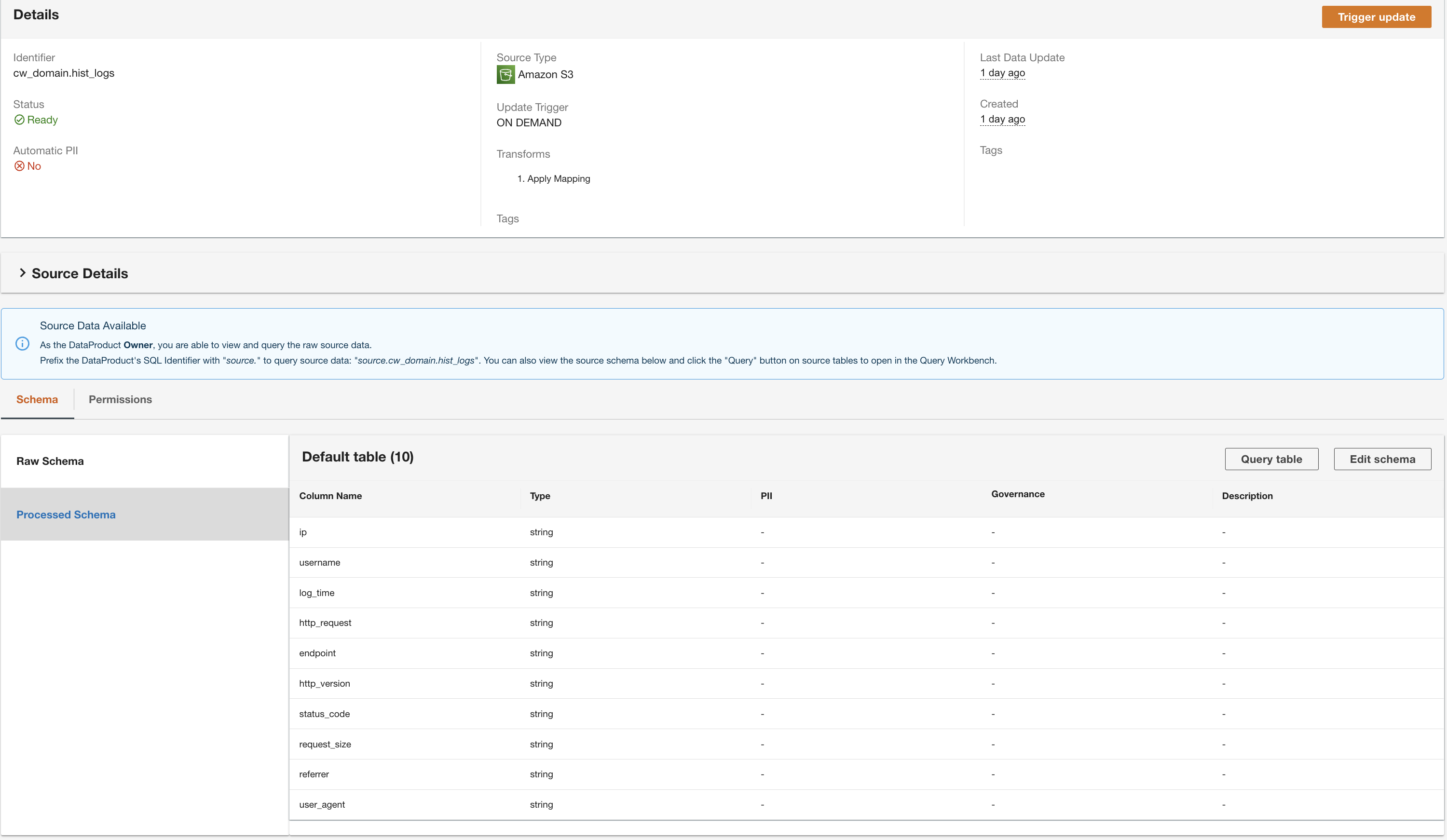
ADA elaborerà i dati dall'origine dati della tabella DynamoDB e preparerà il prodotto dati. A seconda della dimensione dei dati, questo processo richiede alcuni minuti.
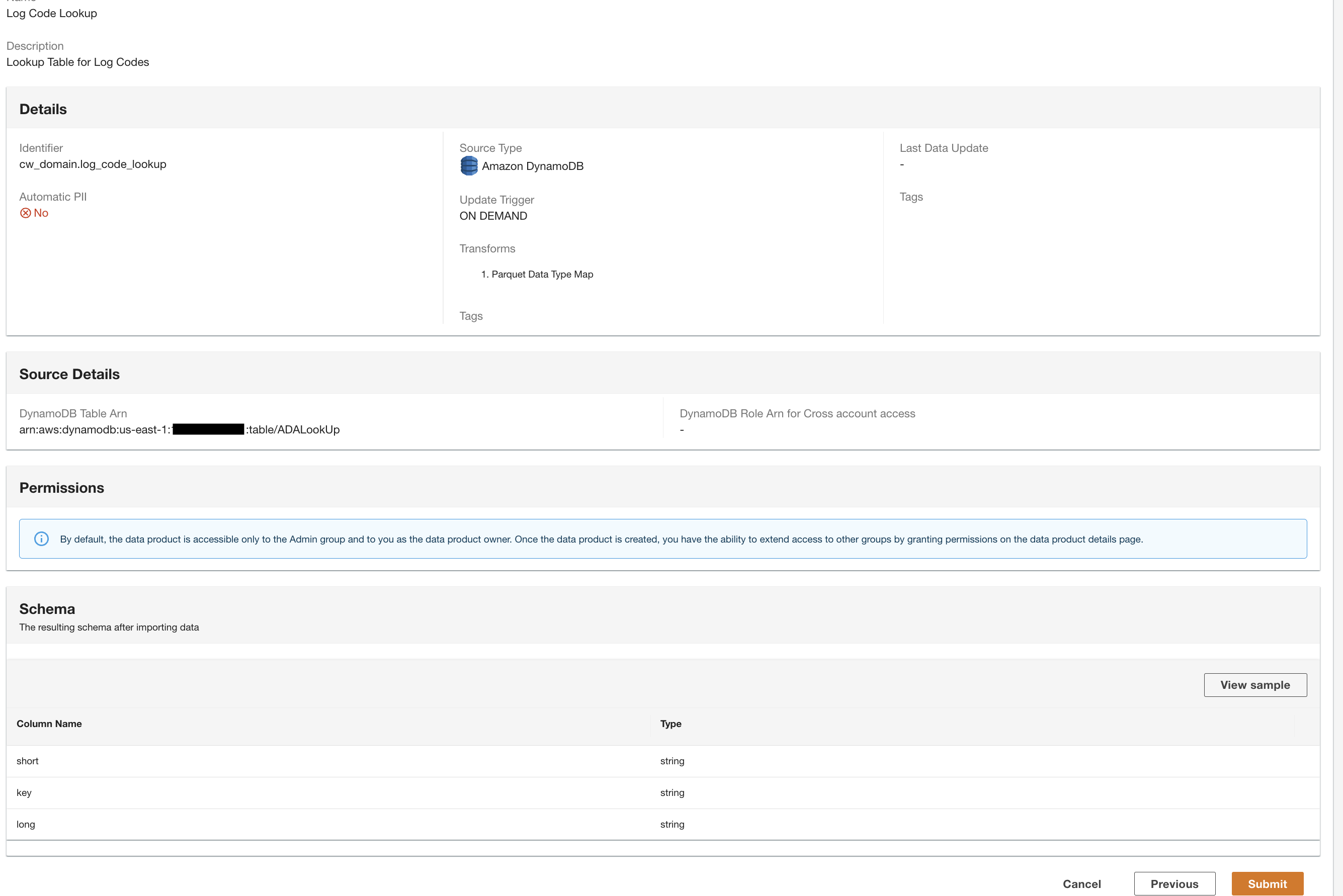
Ora disponiamo di tutti e tre i prodotti dati elaborati da ADA e disponibili per l'esecuzione di query.

Utilizzare l'ambiente delle query per eseguire query sui dati
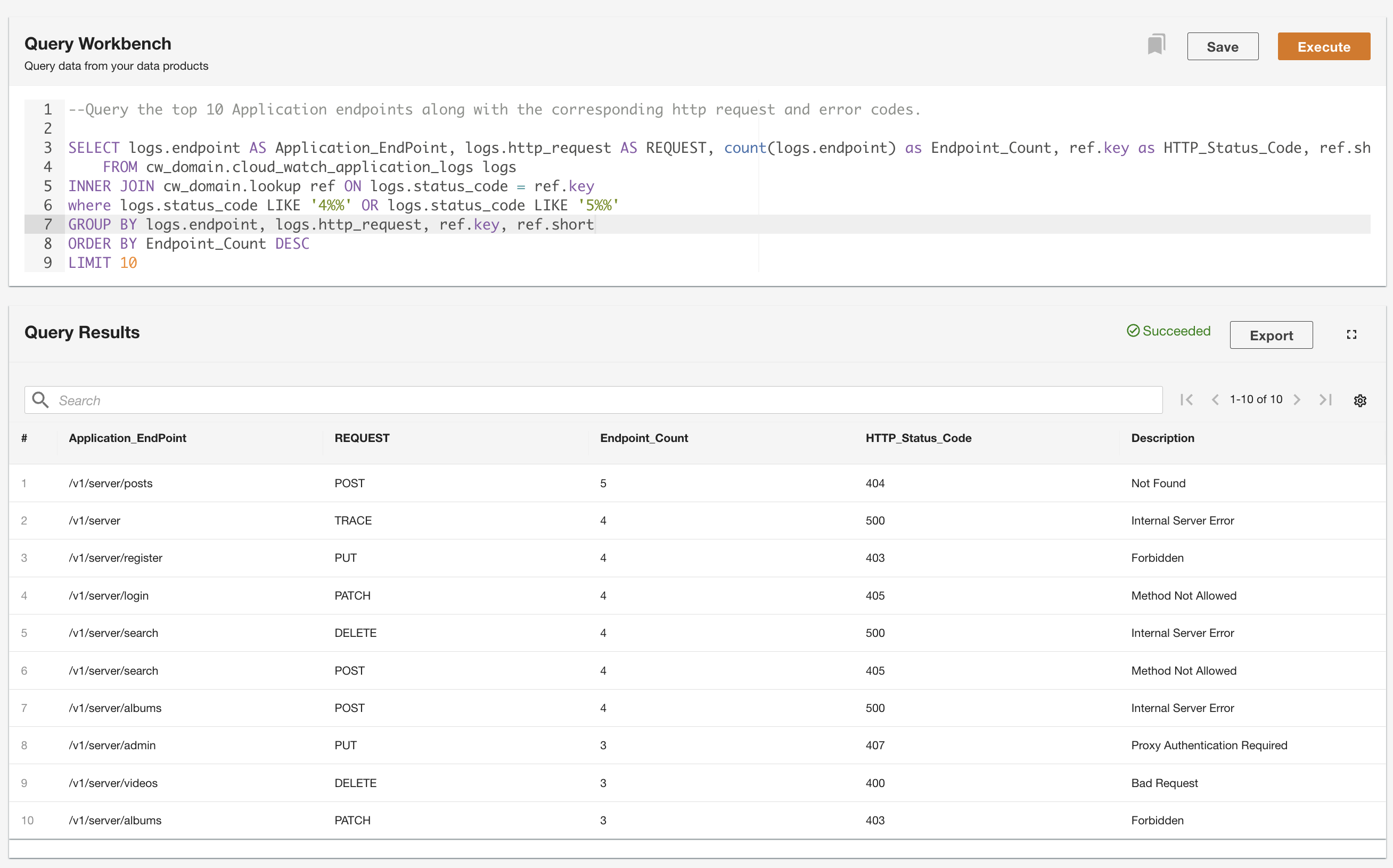
ADA consente di eseguire query sui prodotti dati astraendo l'origine dati e rendendola accessibile utilizzando SQL (Structured Query Language). È possibile scrivere query e unire le tabelle proprio come si farebbe con le tabelle in un database relazionale. Dimostriamo la capacità di interrogazione di ADA tramite due scenari utente. In entrambi gli scenari, uniamo un set di dati del registro dell'applicazione alla tabella di ricerca dei codici di errore. Nel primo caso d'uso, interroghiamo i log dell'applicazione corrente per identificare i primi 10 endpoint dell'applicazione con più accessi insieme ai corrispondenti codici di stato HTTP:
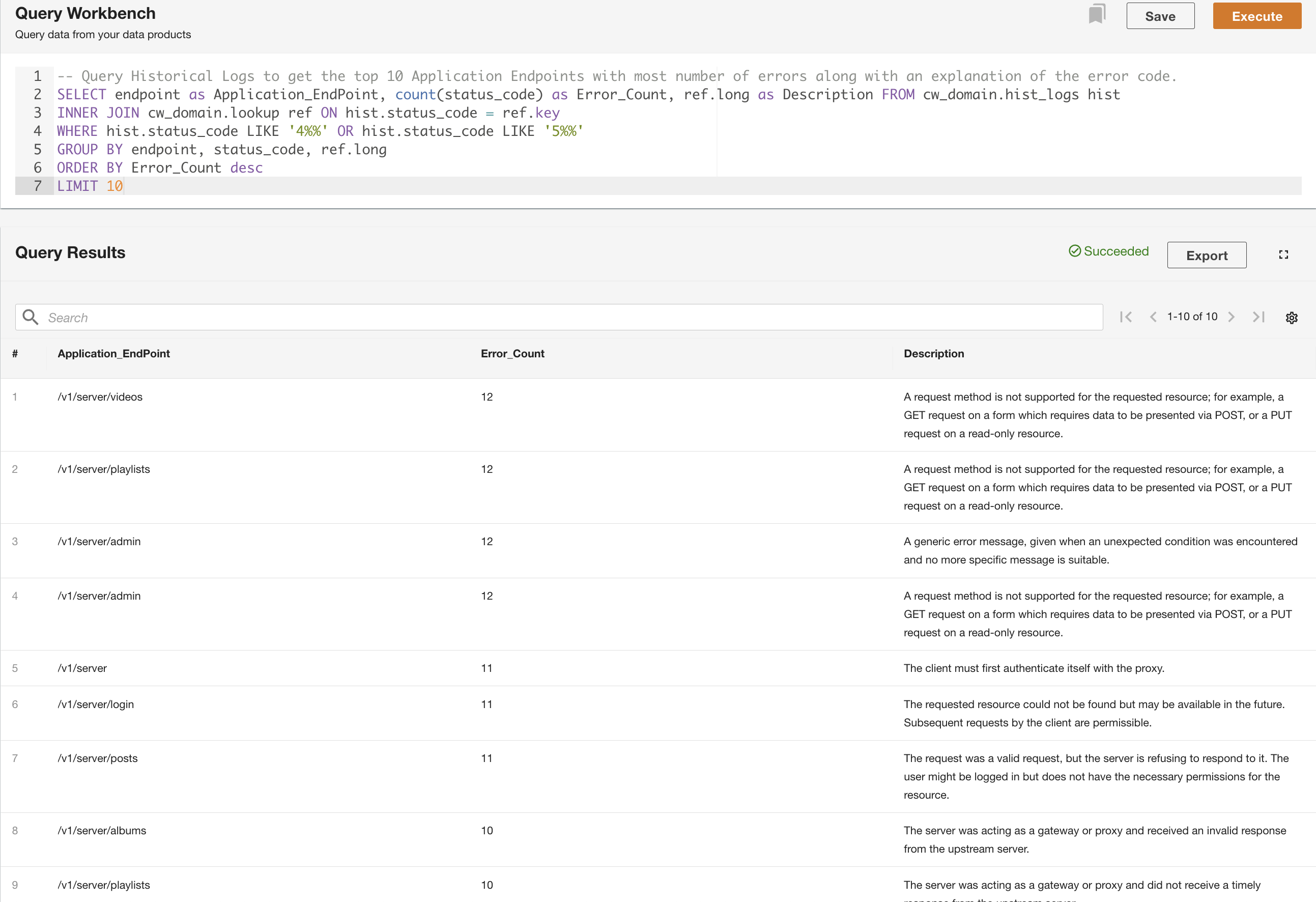
Nel secondo esempio, interroghiamo la tabella dei log storici per ottenere i primi 10 endpoint dell'applicazione con il maggior numero di errori per comprendere il modello di chiamata dell'endpoint:
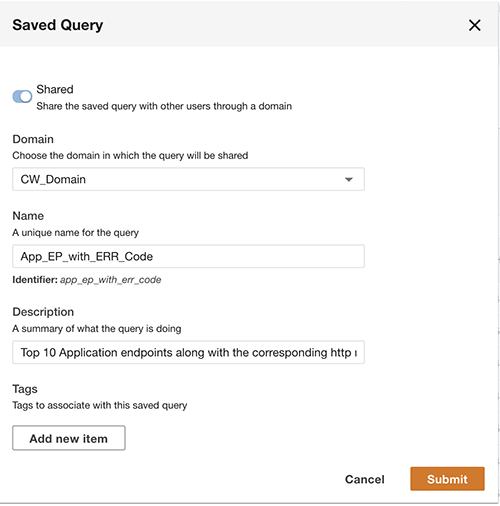
Oltre a eseguire query, puoi facoltativamente salvare la query e condividerla con altri utenti nello stesso dominio. Le query condivise sono accessibili direttamente dal Query Workbench. I risultati della query possono anche essere esportati in formato CSV.
Visualizza i prodotti dati ADA in Tableau
ADA offre la possibilità di farlo connect a strumenti BI di terze parti per visualizzare dati e creare report dai prodotti dati ADA. In questa demo utilizziamo l'integrazione nativa di ADA con Tableau per visualizzare i dati dei tre prodotti dati configurati in precedenza. Utilizzando il connettore Athena di Tableau e seguendo i passaggi in Configurazione del tavolo, puoi configurare ADA come origine dati in Tableau. Una volta stabilita correttamente la connessione tra Tableau e ADA, Tableau popolerà i tre prodotti dati nel catalogo Tableau cw_domain.
Successivamente stabiliamo una relazione tra i tre database utilizzando il codice di stato HTTP come colonna di unione, come mostrato nello screenshot seguente. Tableau ci consente di lavorare in modalità online e offline con le origini dati. In modalità online, Tableau si connetterà ad ADA ed eseguirà query sui prodotti dati in tempo reale. In modalità offline, possiamo usare il file Estratto opzione per estrarre i dati da ADA e importarli in Tableau. In questa demo importiamo i dati in Tableau per rendere le query più reattive. Quindi salviamo la cartella di lavoro di Tableau. Possiamo ispezionare i dati dalle origini dati scegliendo il database e Aggiorna ora.
Con le configurazioni dell'origine dati presenti in Tableau, possiamo creare report, grafici e visualizzazioni personalizzati sui prodotti dati ADA. Consideriamo due casi d'uso per le visualizzazioni.
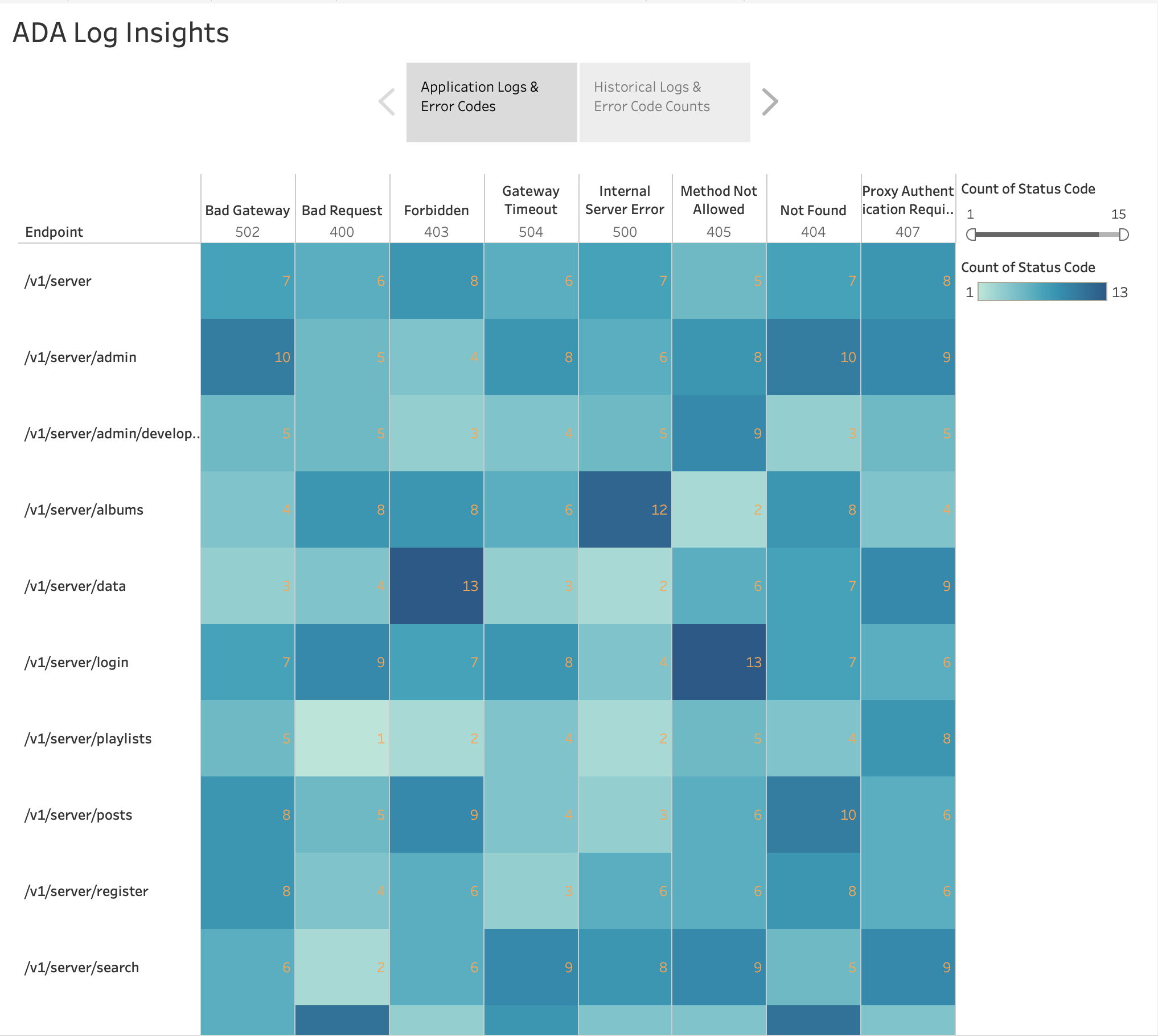
Come mostrato nella figura seguente, abbiamo visualizzato la frequenza degli errori HTTP per endpoint dell'applicazione utilizzando la funzionalità integrata di Tableau mappa di calore grafico. Abbiamo filtrato i codici di stato HTTP per includere solo i codici di errore nell'intervallo 4xx e 5xx.
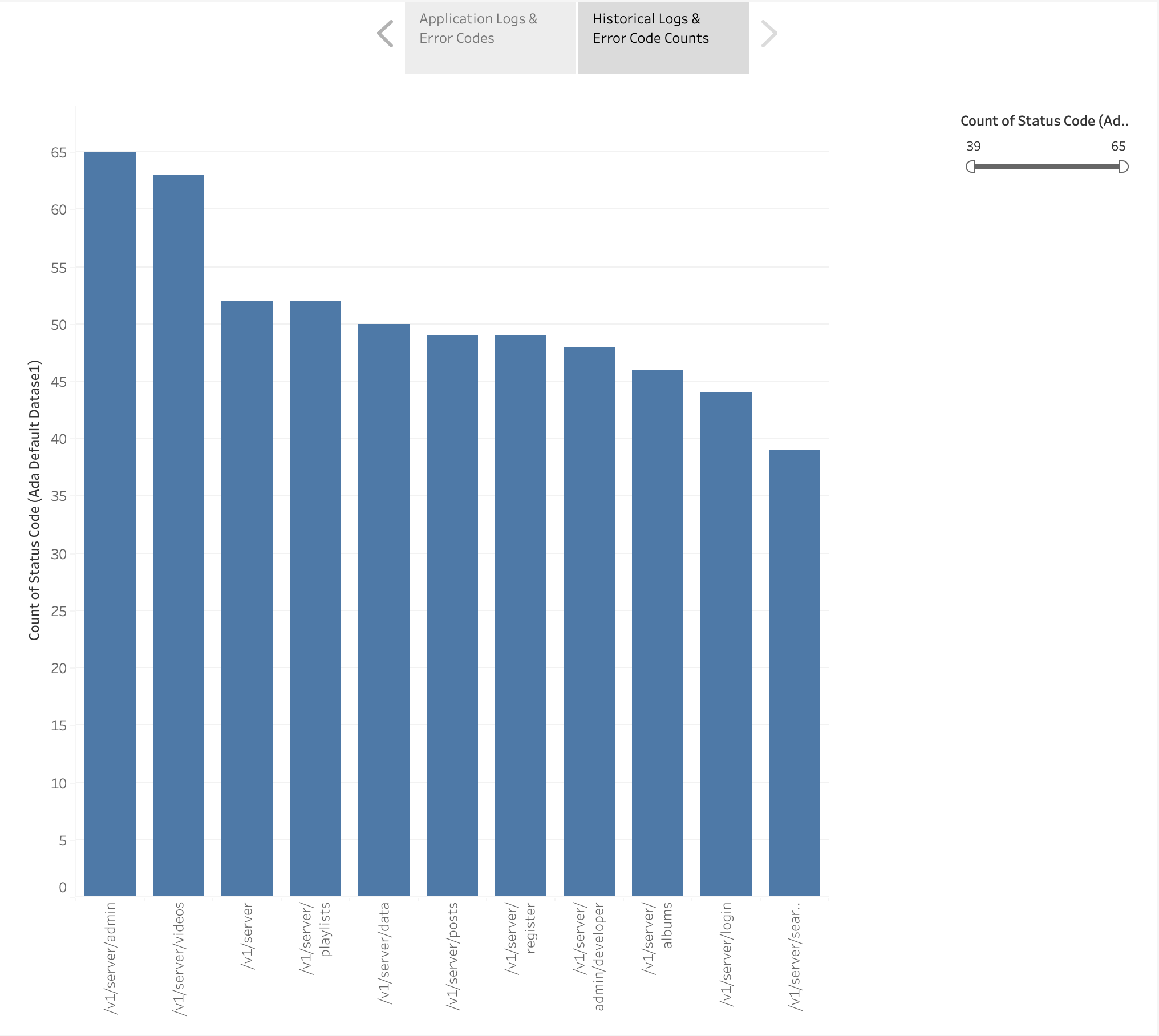
Abbiamo anche creato un grafico a barre per rappresentare gli endpoint dell'applicazione dai log storici ordinati in base al conteggio dei codici di errore HTTP. In questo grafico, possiamo vedere che il /v1/server/admin L'endpoint ha generato il maggior numero di codici di stato di errore HTTP.
ripulire
La pulizia dell'infrastruttura dell'applicazione di esempio è un processo in due fasi. Innanzitutto, per rimuovere l'infrastruttura fornita ai fini di questa demo, esegui il seguente comando nel terminale:
Per la domanda seguente, inserisci y e AWS CDK eliminerà le risorse distribuite per la demo:
In alternativa, puoi rimuovere le risorse tramite la console AWS CloudFormation accedendo allo stack CdkStack e scegliendo Elimina.
Il secondo passo è disinstallare ADA. Per istruzioni, fare riferimento a Disinstallare la soluzione.
Conclusione
In questo post abbiamo dimostrato come utilizzare la soluzione ADA per ricavare informazioni approfondite dai log dell'applicazione archiviati in due diverse origini dati. Abbiamo dimostrato come installare ADA su un account AWS e distribuire i componenti demo utilizzando AWS CDK. Abbiamo creato prodotti dati in ADA e configurato i prodotti dati con le rispettive origini dati utilizzando i connettori dati integrati di ADA. Abbiamo dimostrato come eseguire query sui prodotti dati utilizzando query SQL standard e generare approfondimenti sui dati di registro. Abbiamo anche collegato ad ADA il client Tableau Desktop, un prodotto BI di terze parti, e abbiamo dimostrato come creare visualizzazioni rispetto ai prodotti dati.
ADA automatizza il processo di acquisizione, trasformazione, gestione e interrogazione di diversi set di dati e semplifica la gestione del ciclo di vita dei dati. I connettori predefiniti di ADA ti consentono di acquisire dati da diverse origini dati. I team software con una conoscenza di base dei prodotti e dei servizi AWS saranno in grado di configurare una piattaforma di analisi dei dati operativa in poche ore e fornire un accesso sicuro ai dati. I dati possono quindi essere interrogati in modo semplice e rapido utilizzando un'interfaccia utente web intuitiva e autonoma.
Prova ADA oggi stesso per gestire facilmente i dati e ottenere informazioni approfondite.
Circa gli autori
 Aparajithan Vaidyanathan è Principal Enterprise Solutions Architect presso AWS. Supporta i clienti aziendali nella migrazione e nella modernizzazione dei loro carichi di lavoro sul cloud AWS. È un Cloud Architect con oltre 23 anni di esperienza nella progettazione e nello sviluppo di sistemi software aziendali, su larga scala e distribuiti. È specializzato in Machine Learning e Data Analytics con particolare attenzione al dominio Data and Feature Engineering. È un aspirante maratoneta e i suoi hobby includono l'escursionismo, la bicicletta e passare il tempo con sua moglie e due ragazzi.
Aparajithan Vaidyanathan è Principal Enterprise Solutions Architect presso AWS. Supporta i clienti aziendali nella migrazione e nella modernizzazione dei loro carichi di lavoro sul cloud AWS. È un Cloud Architect con oltre 23 anni di esperienza nella progettazione e nello sviluppo di sistemi software aziendali, su larga scala e distribuiti. È specializzato in Machine Learning e Data Analytics con particolare attenzione al dominio Data and Feature Engineering. È un aspirante maratoneta e i suoi hobby includono l'escursionismo, la bicicletta e passare il tempo con sua moglie e due ragazzi.
 Rashim Rahman è uno sviluppatore di software con sede a Sydney, in Australia, con oltre 10 anni di esperienza nello sviluppo e nell'architettura di software. Lavora principalmente alla creazione di soluzioni AWS open source su larga scala per casi d'uso comuni dei clienti e problemi aziendali. Nel tempo libero ama lo sport e passare il tempo con amici e famiglia.
Rashim Rahman è uno sviluppatore di software con sede a Sydney, in Australia, con oltre 10 anni di esperienza nello sviluppo e nell'architettura di software. Lavora principalmente alla creazione di soluzioni AWS open source su larga scala per casi d'uso comuni dei clienti e problemi aziendali. Nel tempo libero ama lo sport e passare il tempo con amici e famiglia.
 Hafiz Saadullah è Principal Technical Product Manager presso Amazon Web Services. Hafiz si concentra sulle soluzioni AWS, progettate per aiutare i clienti affrontando problemi aziendali e casi d'uso comuni.
Hafiz Saadullah è Principal Technical Product Manager presso Amazon Web Services. Hafiz si concentra sulle soluzioni AWS, progettate per aiutare i clienti affrontando problemi aziendali e casi d'uso comuni.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Automobilistico/VE, Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Grafico Prime. Migliora il tuo gioco di trading con ChartPrime. Accedi qui.
- BlockOffset. Modernizzare la proprietà della compensazione ambientale. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- :ha
- :È
- :non
- :Dove
- $ SU
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- capacità
- capace
- WRI
- accesso
- accessibile
- accessibile
- Il mio account
- operanti in
- azioni
- ADA
- aggiungere
- aggiunta
- aggiuntivo
- indirizzamento
- Admin
- Dopo shavasana, sedersi in silenzio; saluti;
- contro
- Tutti
- consentire
- consente
- lungo
- anche
- alternativa
- Amazon
- Amazon Web Services
- tra
- an
- .
- Gli analisti
- analitica
- analizzare
- ed
- Un altro
- in qualsiasi
- Apache
- api
- API
- Applicazioni
- applicazioni
- applicato
- APPLICA
- AMMISSIONE
- architettura
- SONO
- AS
- aspirante
- At
- gli attributi
- Australia
- Autenticazione
- autorizzato
- Automatizzata
- automatizza
- automaticamente
- disponibile
- AWS
- AWS CloudFormazione
- precedente
- BACKEND
- bar
- basato
- basic
- BE
- perché
- stato
- prima
- su misura
- fra
- entrambi
- Scatola
- costruire
- Costruzione
- incassato
- affari
- business intelligence
- ma
- by
- chiamata
- Materiale
- capacità
- Custodie
- casi
- catalogo
- CD
- il cambiamento
- Grafico
- Grafici
- Scegli
- la scelta
- cliente
- Cloud
- codice
- codici
- collezione
- Colonna
- colonne
- Uncommon
- completamento di una
- componenti
- Configurazione
- configurato
- Connettiti
- collegato
- veloce
- collega
- Prendere in considerazione
- coerente
- consolle
- contiene
- continua
- correlato
- Correlazione
- Corrispondente
- corrisponde
- Costo
- creare
- creato
- crea
- Creazione
- Credenziali
- Corrente
- costume
- cliente
- Clienti
- cruscotto
- dati
- Dati Analytics
- elaborazione dati
- Banca Dati
- banche dati
- dataset
- Predefinito
- Richiesta
- Dimo
- dimostrare
- dimostrato
- Dipendente
- schierare
- schierato
- deployment
- Distribuisce
- descrizione
- progettato
- progettazione
- tavolo
- dettagliati
- dettagli
- Costruttori
- in via di sviluppo
- Mercato
- diagnosi
- diverso
- direttamente
- disabile
- scoperta
- Dsiplay
- distribuito
- paesaggio differenziato
- non
- dominio
- domini
- Dont
- caduto
- durante
- ogni
- In precedenza
- facilmente
- montaggio
- o
- abilitato
- Abilita
- endpoint
- endpoint
- Ingegneria
- garantire
- entrare
- Impresa
- clienti aziendali
- Enterprise Solutions
- errore
- errori
- stabilire
- sviluppate
- Etere (ETH)
- esempio
- esistente
- esperienza
- Spiegare
- spiegazione
- estratto
- estrarre i dati
- familiare
- famiglia
- caratteristica
- pochi
- campo
- campi
- figura
- Compila il
- File
- finale
- finanziare
- Nome
- flessibile
- Focus
- si concentra
- i seguenti
- Nel
- formato
- quattro
- Frequenza
- amici
- da
- function
- Guadagno
- generare
- generato
- ottenere
- ottenere
- governo
- Gruppo
- Gruppo
- Avere
- avendo
- he
- Aiuto
- Evidenziato
- escursionismo
- il suo
- storico
- Hobby
- ospitato
- ORE
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- IAM
- identico
- identificare
- Identità
- if
- importare
- in
- includere
- inclusi
- Compreso
- informazioni
- Infrastruttura
- inizialmente
- intuizioni
- install
- installazione
- istruzioni
- integrato
- integrazione
- Intelligence
- interattivo
- interessato
- Interfaccia
- ai miglioramenti
- intuitivo
- invoca
- coinvolto
- problema
- IT
- join
- accoppiamento
- Entra a far parte
- jpg
- json
- ad appena
- mantenere
- Le
- conoscenze
- Lingua
- grandi
- larga scala
- Cognome
- dopo
- lancio
- apprendimento
- Biblioteca
- Autorizzato
- ciclo di vita
- piace
- LIMITE
- linea
- Lista
- vivere
- ceppo
- registrazione
- Lunghi
- Guarda
- ricerca
- macchina
- machine learning
- make
- Fare
- gestire
- gestione
- direttore
- molti
- carta geografica
- mappatura
- Maratona
- Marketing
- Importanza
- significativo
- messaggio
- AMF
- forza
- migrare
- verbale
- Moda
- modernizzare
- Scopri di più
- maggior parte
- soprattutto
- Mozilla
- autenticazione a più fattori
- MySQL
- Nome
- Detto
- nomi
- nativo
- Navigare
- navigazione
- Navigazione
- Bisogno
- di applicazione
- esigenze
- New
- recentemente
- GENERAZIONE
- numero
- of
- Offerte
- offline
- Vecchio
- on
- On-Demand
- ONE
- online
- esclusivamente
- aprire
- open source
- operativa
- Opzione
- or
- minimo
- Altro
- Altri
- su
- produzione
- panoramica
- pagina
- vetro
- Password
- sentiero
- Cartamodello
- eseguire
- permessi
- Personalmente
- telefono
- pii
- conduttura
- posto
- pianura
- piano
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- Termini e Condizioni
- Portale
- Post
- Postgresql
- alimentato
- Preparare
- prepara
- prerequisiti
- presenti
- presents
- Anteprima
- precedente
- principalmente
- Direttore
- Precedente
- problemi
- procedere
- processi
- elaborati
- i processi
- lavorazione
- Prodotto
- Prodotto
- product manager
- Prodotti
- Prodotti e Servizi
- Programmi
- progetto
- fornire
- purché
- fornitore
- fornisce
- scopo
- fini
- Python
- query
- domanda
- rapidamente
- gamma
- Leggi
- pronto
- ricevere
- record
- di cui
- regione
- rapporto
- pertinente
- rimuovere
- ripetere
- Report
- richiesta
- necessario
- Risorse
- quelli
- di risposta
- Risultati
- conservare
- recensioni
- equitazione
- ruoli
- radice
- Regola
- Correre
- corridore
- running
- vendite
- stesso
- Risparmi
- Scala
- Scenari
- in programma
- portata
- Cerca
- Secondo
- Sezione
- sicuro
- problemi di
- vedere
- selezionato
- prodotti
- inviare
- inviato
- separato
- servire
- serverless
- servizio
- Servizi
- set
- regolazione
- Condividi
- condiviso
- Corti
- mostrato
- Spettacoli
- Un'espansione
- semplificata
- semplificando
- Taglia
- abilità
- So
- Software
- lo sviluppo del software
- soluzione
- Soluzioni
- Fonte
- fonti
- specialista
- specializzata
- specifico
- specificato
- Spendere
- Sports
- SQL
- pila
- standalone
- Standard
- inizia a
- inizio
- Stato dei servizi
- step
- Passi
- conservazione
- memorizzati
- Corda
- strutturato
- di successo
- Con successo
- tale
- supporti
- sicuro
- sydney
- SISTEMI DI TRATTAMENTO
- tavolo
- Quadro
- Fai
- prende
- team
- le squadre
- Consulenza
- abilità tecniche
- terminal
- che
- Il
- L’ORIGINE
- loro
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di parti terze standard
- questo
- tre
- Attraverso
- tempo
- a
- oggi
- strumenti
- top
- Top 10
- Totale
- Trasformare
- Trasformazione
- trasformazioni
- trasformato
- trasformazione
- trasforma
- innescato
- seconda
- Digitare
- Tipi di
- per
- sottostante
- capire
- aggiornato
- Aggiornamenti
- su
- URI
- us
- uso
- caso d'uso
- utilizzato
- Utente
- Interfaccia utente
- utenti
- utilizzando
- Valori
- variabile
- varietà
- versione
- via
- Visualizza
- volere
- Modo..
- we
- sito web
- servizi web
- WELL
- quando
- quale
- while
- largo
- Vasta gamma
- moglie
- volere
- con
- entro
- senza
- Lavora
- flusso di lavoro
- lavori
- sarebbe
- scrivere
- anni
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro