Questo è un post congiunto scritto da AWS e Voxel51. Voxel51 è la società dietro FiftyOne, il toolkit open source per la creazione di set di dati e modelli di visione artificiale di alta qualità.
Un'azienda di vendita al dettaglio sta creando un'app mobile per aiutare i clienti ad acquistare vestiti. Per creare questa app, hanno bisogno di un set di dati di alta qualità contenente immagini di abbigliamento, etichettate con diverse categorie. In questo post, mostriamo come riutilizzare un set di dati esistente tramite la pulizia dei dati, la preelaborazione e la preetichettatura con un modello di classificazione zero-shot in Cinquantunoe regolando queste etichette con Amazon SageMaker verità fondamentale.
Puoi utilizzare Ground Truth e FiftyOne per accelerare il tuo progetto di etichettatura dei dati. Illustriamo come utilizzare senza problemi le due applicazioni insieme per creare set di dati etichettati di alta qualità. Per il nostro caso d'uso di esempio, lavoriamo con il Set di dati Fashion200K, rilasciato all'ICCV 2017.
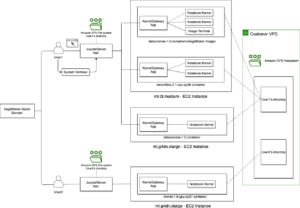
Panoramica della soluzione
Ground Truth è un servizio di etichettatura dei dati completamente self-service e gestito che consente a data scientist, ingegneri di machine learning (ML) e ricercatori di creare set di dati di alta qualità. Cinquantuno by voxel51 è un toolkit open source per la cura, la visualizzazione e la valutazione di set di dati di visione artificiale in modo da poter addestrare e analizzare modelli migliori accelerando i casi d'uso.
Nelle sezioni seguenti, dimostriamo come eseguire le seguenti operazioni:
- Visualizza il set di dati in FiftyOne
- Pulisci il set di dati con il filtraggio e la deduplicazione delle immagini in FiftyOne
- Pre-etichettare i dati puliti con la classificazione zero-shot in FiftyOne
- Etichetta il set di dati curato più piccolo con Ground Truth
- Inserisci i risultati etichettati da Ground Truth in FiftyOne e rivedi i risultati etichettati in FiftyOne
Panoramica dei casi d'uso
Supponi di possedere un'azienda di vendita al dettaglio e di voler creare un'applicazione mobile per fornire consigli personalizzati per aiutare gli utenti a decidere cosa indossare. I tuoi potenziali utenti sono alla ricerca di un'applicazione che dica loro quali capi di abbigliamento nel loro armadio funzionano bene insieme. Qui vedi un'opportunità: se riesci a identificare buoni abiti, puoi usarlo per consigliare nuovi capi di abbigliamento che completano l'abbigliamento che già possiede un cliente.
Vuoi rendere le cose il più semplici possibile per l'utente finale. Idealmente, qualcuno che utilizza la tua applicazione deve solo scattare foto dei vestiti nel proprio guardaroba e i tuoi modelli ML fanno la loro magia dietro le quinte. Potresti addestrare un modello generico o perfezionare un modello in base allo stile unico di ciascun utente con una qualche forma di feedback.
Prima, tuttavia, è necessario identificare il tipo di abbigliamento che l'utente sta catturando. È una camicia? Un paio di pantaloni? O qualcos'altro? Dopotutto, probabilmente non vorrai consigliare un outfit con più vestiti o più cappelli.
Per affrontare questa sfida iniziale, si desidera generare un set di dati di addestramento costituito da immagini di vari articoli di abbigliamento con vari modelli e stili. Per prototipare con un budget limitato, si desidera eseguire il bootstrap utilizzando un set di dati esistente.
Per illustrare e guidarti attraverso il processo in questo post, utilizziamo il set di dati Fashion200K rilasciato all'ICCV 2017. È un set di dati consolidato e ben citato, ma non è direttamente adatto al tuo caso d'uso.
Sebbene gli articoli di abbigliamento siano etichettati con categorie (e sottocategorie) e contengano una varietà di tag utili estratti dalle descrizioni originali del prodotto, i dati non sono sistematicamente etichettati con informazioni su modelli o stili. Il tuo obiettivo è trasformare questo set di dati esistente in un solido set di dati di addestramento per i tuoi modelli di classificazione dell'abbigliamento. È necessario pulire i dati, aumentando lo schema di etichettatura con etichette di stile. E vuoi farlo velocemente e con la minor spesa possibile.
Scarica i dati in locale
Per prima cosa, scarica il file zip women.tar e la cartella labels (con tutte le sue sottocartelle) seguendo le istruzioni fornite nel Repository GitHub del set di dati Fashion200K. Dopo averli decompressi entrambi, crea una directory principale fashion200k e sposta le cartelle delle etichette e delle donne in questa. Fortunatamente, queste immagini sono già state ritagliate nei riquadri di delimitazione del rilevamento degli oggetti, quindi possiamo concentrarci sulla classificazione, piuttosto che preoccuparci del rilevamento degli oggetti.
Nonostante il "200K" nel suo soprannome, la directory delle donne che abbiamo estratto contiene 338,339 immagini. Per generare il set di dati ufficiale di Fashion200K, gli autori del set di dati hanno scansionato più di 300,000 prodotti online e solo i prodotti con descrizioni contenenti più di quattro parole hanno fatto il taglio. Per i nostri scopi, dove la descrizione del prodotto non è essenziale, possiamo utilizzare tutte le immagini scansionate.
Diamo un'occhiata a come sono organizzati questi dati: all'interno della cartella delle donne, le immagini sono organizzate per tipo di articolo di primo livello (gonne, top, pantaloni, giacche e vestiti) e sottocategoria del tipo di articolo (camicette, t-shirt, maniche lunghe superiori).
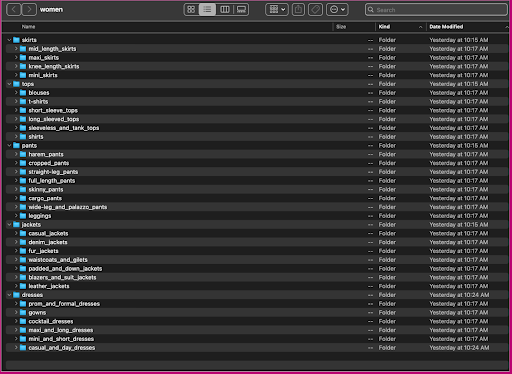
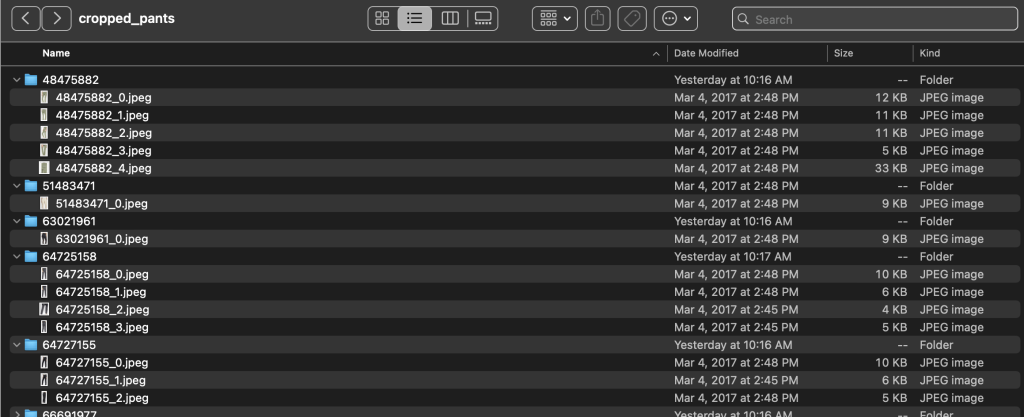
All'interno delle directory delle sottocategorie, c'è una sottodirectory per ogni elenco di prodotti. Ognuno di questi contiene un numero variabile di immagini. La sottocategoria cropped_pants, ad esempio, contiene i seguenti elenchi di prodotti e le immagini associate.
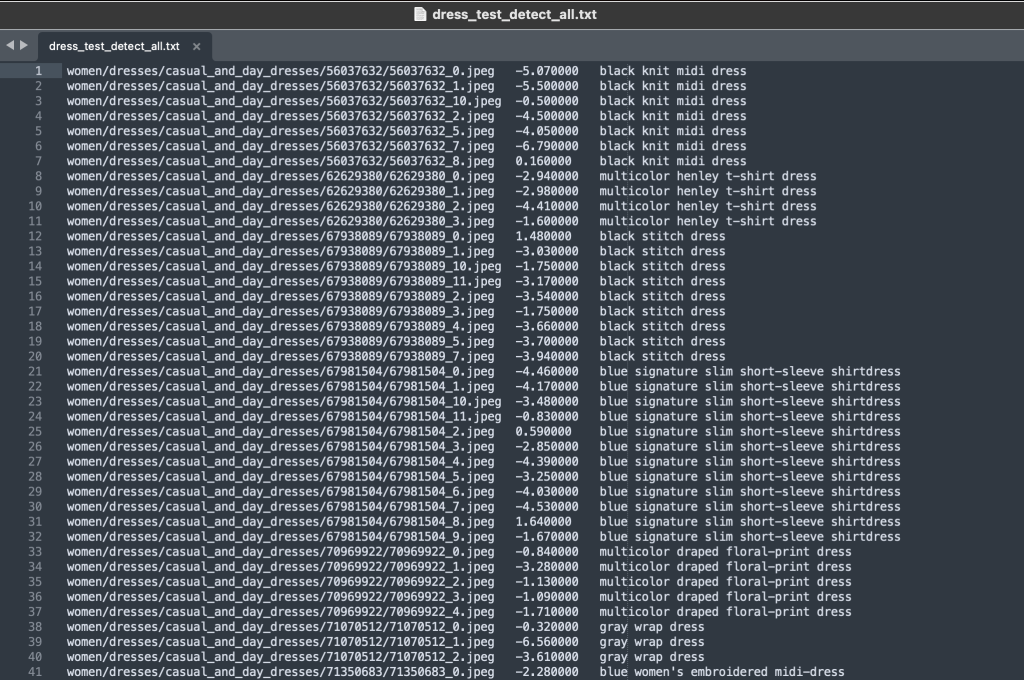
La cartella delle etichette contiene un file di testo per ogni tipo di articolo di primo livello, sia per il treno che per il test. All'interno di ciascuno di questi file di testo è presente una riga separata per ogni immagine, che specifica il percorso del file relativo, un punteggio e i tag dalla descrizione del prodotto.
Poiché stiamo riproponendo il set di dati, combiniamo tutte le immagini del treno e dei test. Li utilizziamo per generare un set di dati specifico per l'applicazione di alta qualità. Dopo aver completato questo processo, possiamo suddividere in modo casuale il set di dati risultante in nuove divisioni di treno e test.
Inserisci, visualizza e cura un set di dati in FiftyOne
Se non lo hai già fatto, installa FiftyOne open source usando pip:
Una best practice consiste nel farlo all'interno di un nuovo ambiente virtuale (venv o conda). Quindi importare i moduli pertinenti. Importa la libreria di base, cinquantuno, FiftyOne Brain, che ha metodi ML incorporati, FiftyOne Zoo, da cui caricheremo un modello che genererà etichette zero-shot per noi, e ViewField, che ci consente di filtrare in modo efficiente il dati nel nostro set di dati:
Vuoi anche importare i moduli Python glob e os, che ci aiuteranno a lavorare con percorsi e pattern match sui contenuti delle directory:
Ora siamo pronti per caricare il set di dati in FiftyOne. Innanzitutto, creiamo un set di dati denominato fashion200k e lo rendiamo persistente, che ci consente di salvare i risultati di operazioni computazionalmente intensive, quindi dobbiamo calcolare tali quantità solo una volta.
Ora possiamo scorrere tutte le directory delle sottocategorie, aggiungendo tutte le immagini all'interno delle directory dei prodotti. Aggiungiamo un'etichetta di classificazione FiftyOne a ciascun campione con il nome del campo article_type, popolato dalla categoria dell'articolo di primo livello dell'immagine. Aggiungiamo anche le informazioni di categoria e sottocategoria come tag:
A questo punto possiamo visualizzare il nostro dataset nell'app FiftyOne avviando una sessione:
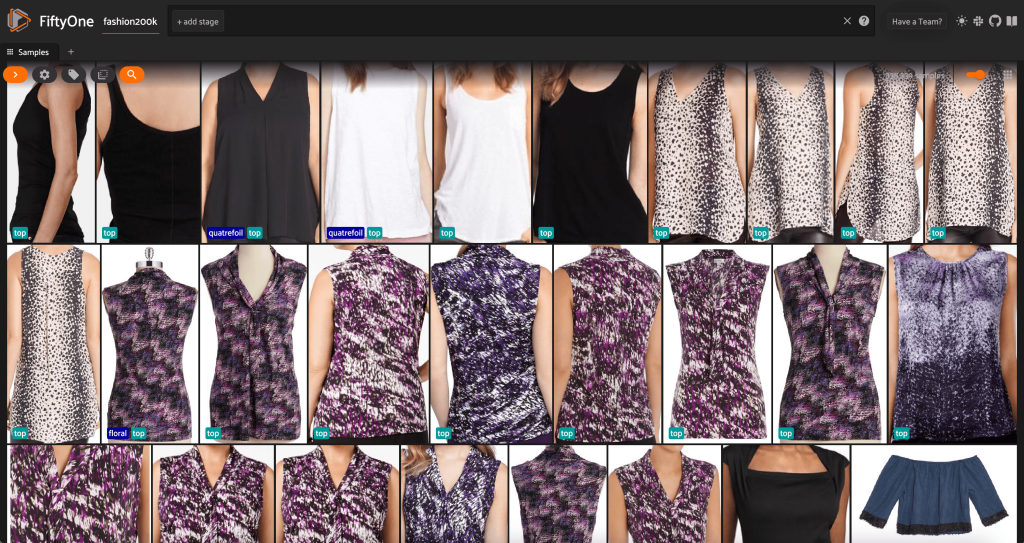
Possiamo anche stampare un riepilogo del set di dati in Python eseguendo print(dataset):
Possiamo anche aggiungere i tag dal file labels directory ai campioni nel nostro set di dati:
Guardando i dati, alcune cose diventano chiare:
- Alcune delle immagini sono piuttosto sgranate, con bassa risoluzione. Ciò è probabile perché queste immagini sono state generate ritagliando le immagini iniziali nei riquadri di delimitazione del rilevamento degli oggetti.
- Alcuni vestiti sono indossati da una persona e alcuni sono fotografati da soli. Questi dettagli sono incapsulati dal file
viewpointproprietà. - Molte immagini dello stesso prodotto sono molto simili, quindi, almeno inizialmente, includere più di un'immagine per prodotto potrebbe non aggiungere molto potere predittivo. Per la maggior parte, la prima immagine di ogni prodotto (che termina con
_0.jpeg) è il più pulito.
Inizialmente, potremmo voler addestrare il nostro modello di classificazione dello stile di abbigliamento su un sottoinsieme controllato di queste immagini. A tal fine, utilizziamo immagini ad alta risoluzione dei nostri prodotti e limitiamo la nostra visione a un campione rappresentativo per prodotto.
Innanzitutto, filtriamo le immagini a bassa risoluzione. Noi usiamo il compute_metadata() metodo per calcolare e memorizzare la larghezza e l'altezza dell'immagine, in pixel, per ogni immagine nel set di dati. Quindi impieghiamo il FiftyOne ViewField per filtrare le immagini in base ai valori minimi di larghezza e altezza consentiti. Vedere il seguente codice:
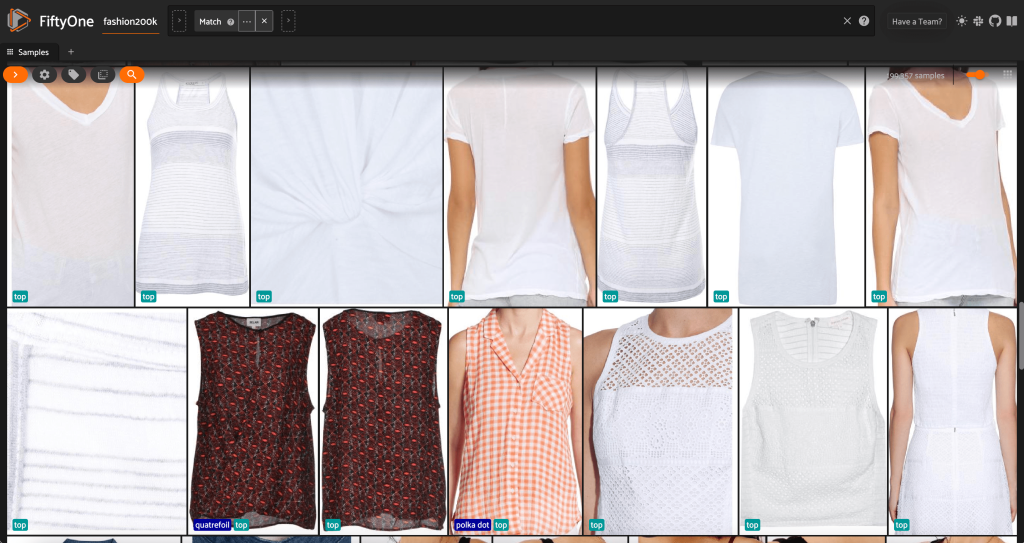
Questo sottoinsieme ad alta risoluzione ha poco meno di 200,000 campioni.
Da questa vista, possiamo creare una nuova vista nel nostro set di dati contenente un solo campione rappresentativo (al massimo) per ogni prodotto. Noi usiamo il ViewField ancora una volta, la corrispondenza dei modelli per i percorsi dei file che terminano con _0.jpeg:
Osserviamo un ordinamento casuale delle immagini in questo sottoinsieme:
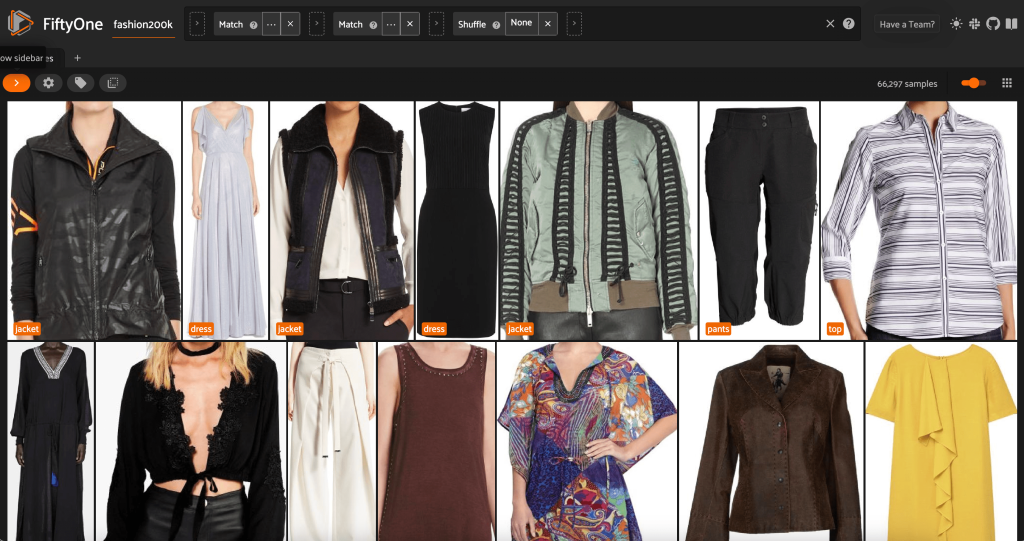
Rimuovere le immagini ridondanti nel set di dati
Questa vista contiene 66,297 immagini, ovvero poco più del 19% del set di dati originale. Quando guardiamo la vista, tuttavia, vediamo che ci sono molti prodotti molto simili. Conservare tutte queste copie probabilmente aggiungerà solo costi alla nostra etichettatura e formazione del modello, senza migliorare sensibilmente le prestazioni. Invece, eliminiamo i duplicati vicini per creare un set di dati più piccolo che offra ancora lo stesso pugno.
Poiché queste immagini non sono duplicati esatti, non possiamo verificare l'uguaglianza in termini di pixel. Fortunatamente, possiamo usare FiftyOne Brain per aiutarci a ripulire il nostro set di dati. In particolare, calcoleremo un incorporamento per ogni immagine (un vettore di dimensione inferiore che rappresenta l'immagine) e quindi cercheremo immagini i cui vettori di incorporamento siano vicini l'uno all'altro. Più vicini sono i vettori, più simili sono le immagini.
Utilizziamo un modello CLIP per generare un vettore di incorporamento a 512 dimensioni per ogni immagine e memorizziamo questi incorporamenti negli incorporamenti di campo sui campioni nel nostro set di dati:
Quindi calcoliamo la vicinanza tra gli incorporamenti, utilizzando somiglianza del coseno, e asserire che due vettori qualsiasi la cui somiglianza è maggiore di una certa soglia sono probabilmente quasi duplicati. I punteggi di somiglianza del coseno si trovano nell'intervallo [0, 1] e, osservando i dati, un punteggio di soglia di thresh=0.5 sembra essere corretto. Ancora una volta, questo non deve essere perfetto. È improbabile che alcune immagini quasi duplicate rovinino il nostro potere predittivo e l'eliminazione di alcune immagini non duplicate non influisce materialmente sulle prestazioni del modello.
Possiamo visualizzare i presunti duplicati per verificare che siano effettivamente ridondanti:
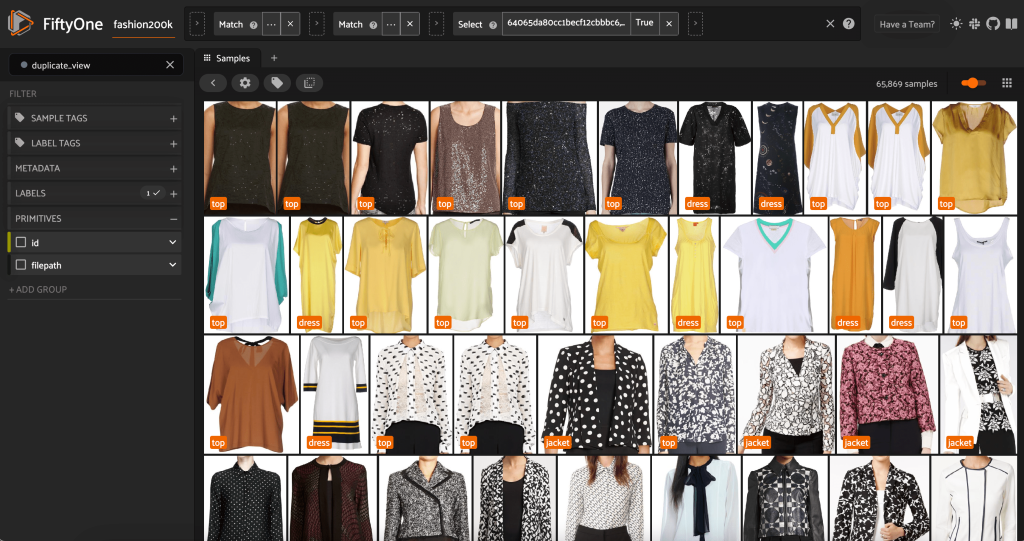
Quando siamo soddisfatti del risultato e crediamo che queste immagini siano effettivamente quasi duplicate, possiamo scegliere un campione da ogni serie di campioni simili da conservare e ignorare gli altri:
Ora questa vista ha 3,729 immagini. Ripulendo i dati e identificando un sottoinsieme di alta qualità del set di dati Fashion200K, FiftyOne ci consente di limitare la nostra attenzione da oltre 300,000 immagini a poco meno di 4,000, con una riduzione del 98%. L'utilizzo degli incorporamenti per rimuovere da solo le immagini quasi duplicate ha ridotto il nostro numero totale di immagini prese in considerazione di oltre il 90%, con un effetto minimo o nullo sui modelli da addestrare su questi dati.
Prima di pre-etichettare questo sottoinsieme, possiamo comprendere meglio i dati visualizzando gli incorporamenti che abbiamo già calcolato. Possiamo usare l'integrato di FiftyOne Brain compute_visualization(), che impiega la tecnica dell'approssimazione uniforme del collettore (UMAP) per proiettare i vettori di incorporamento a 512 dimensioni nello spazio bidimensionale in modo da poterli visualizzare:
Apriamo un nuovo Pannello degli incastri nell'app FiftyOne e colorare per tipo di articolo, e possiamo vedere che questi incorporamenti codificano approssimativamente una nozione di tipo di articolo (tra le altre cose!).
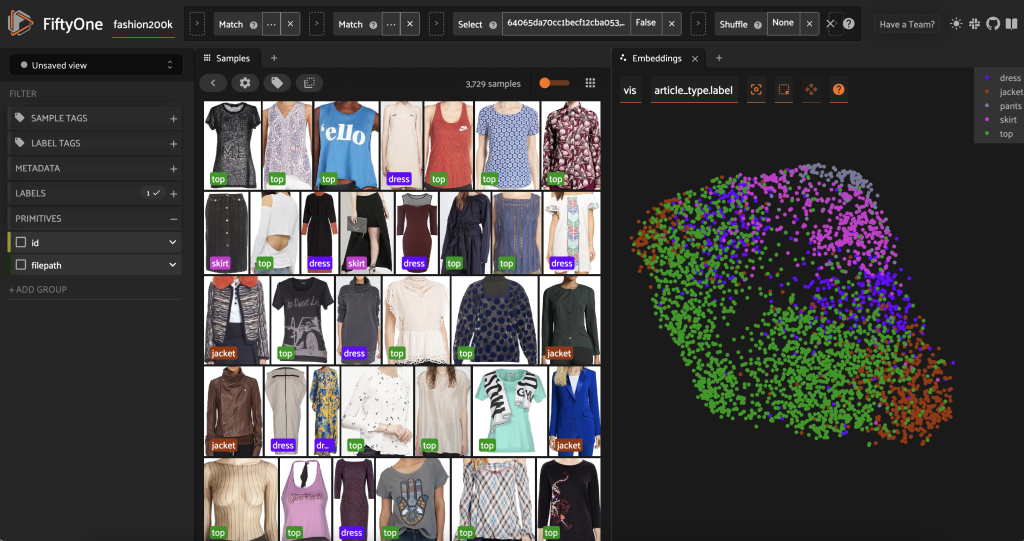
Ora siamo pronti per pre-etichettare questi dati.
Ispezionando queste immagini altamente uniche e ad alta risoluzione, possiamo generare un discreto elenco iniziale di stili da utilizzare come classi nella nostra classificazione zero-shot pre-etichettatura. Il nostro obiettivo nella pre-etichettatura di queste immagini non è necessariamente etichettare correttamente ogni immagine. Piuttosto, il nostro obiettivo è fornire un buon punto di partenza per gli annotatori umani in modo da poter ridurre i tempi e i costi di etichettatura.
Possiamo quindi istanziare un modello di classificazione zero-shot per questa applicazione. Utilizziamo un modello CLIP, che è un modello generico addestrato sia sulle immagini che sul linguaggio naturale. Istanziamo un modello CLIP con il prompt di testo "Abbigliamento nello stile", in modo che, data un'immagine, il modello restituisca la classe per la quale "Abbigliamento nello stile [classe]" è la soluzione migliore. CLIP non è addestrato su dati specifici per la vendita al dettaglio o la moda, quindi non sarà perfetto, ma può farti risparmiare sui costi di etichettatura e annotazione.
Quindi applichiamo questo modello al nostro sottoinsieme ridotto e memorizziamo i risultati in un file article_style campo:
Lanciando ancora una volta l'app FiftyOne, possiamo visualizzare le immagini con queste etichette di stile previste. Ordiniamo in base alla confidenza della previsione, quindi visualizziamo prima le previsioni di stile più sicure:
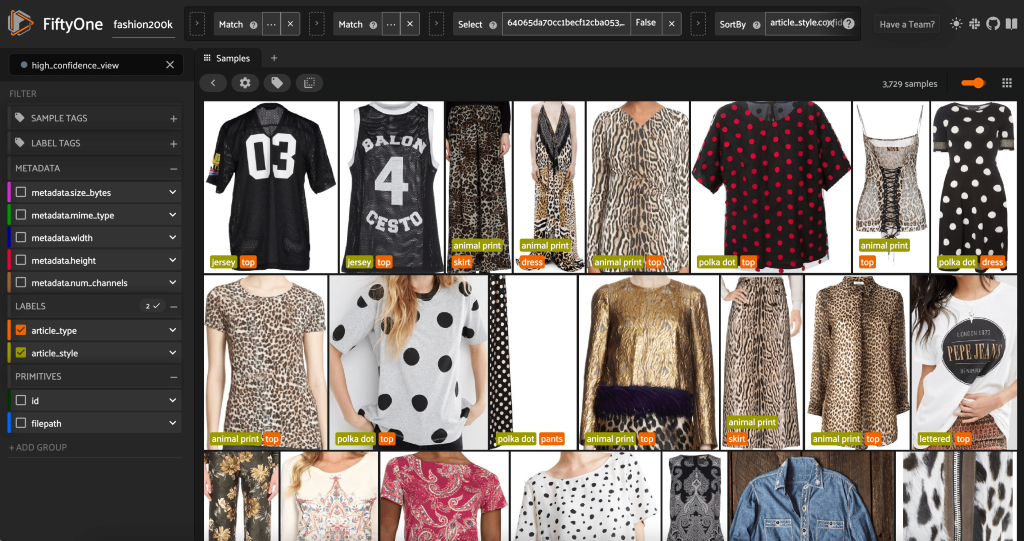
Possiamo vedere che le previsioni di confidenza più elevate sembrano essere per gli stili "jersey", "stampa animalier", "a pois" e "con lettere". Questo ha senso, perché questi stili sono relativamente distinti. Sembra anche che, per la maggior parte, le etichette di stile previste siano accurate.
Possiamo anche esaminare le previsioni di stile di confidenza più bassa:
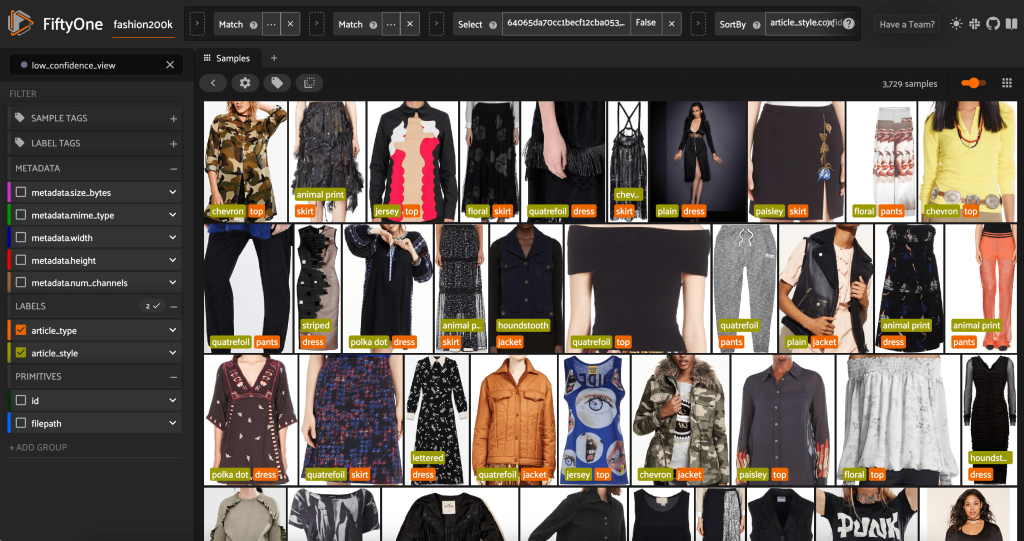
Per alcune di queste immagini, la categoria di stile appropriata è nell'elenco fornito e l'articolo di abbigliamento è etichettato in modo errato. La prima immagine nella griglia, ad esempio, dovrebbe essere chiaramente "camouflage" e non "chevron". In altri casi, invece, i prodotti non rientrano perfettamente nelle categorie di stile. L'abito nella seconda immagine della seconda riga, ad esempio, non è esattamente "a strisce", ma date le stesse opzioni di etichettatura, anche un annotatore umano potrebbe essere in conflitto. Mentre costruiamo il nostro set di dati, dobbiamo decidere se rimuovere i casi limite come questi, aggiungere nuove categorie di stile o aumentare il set di dati.
Esporta il set di dati finale da FiftyOne
Esporta il set di dati finale con il seguente codice:
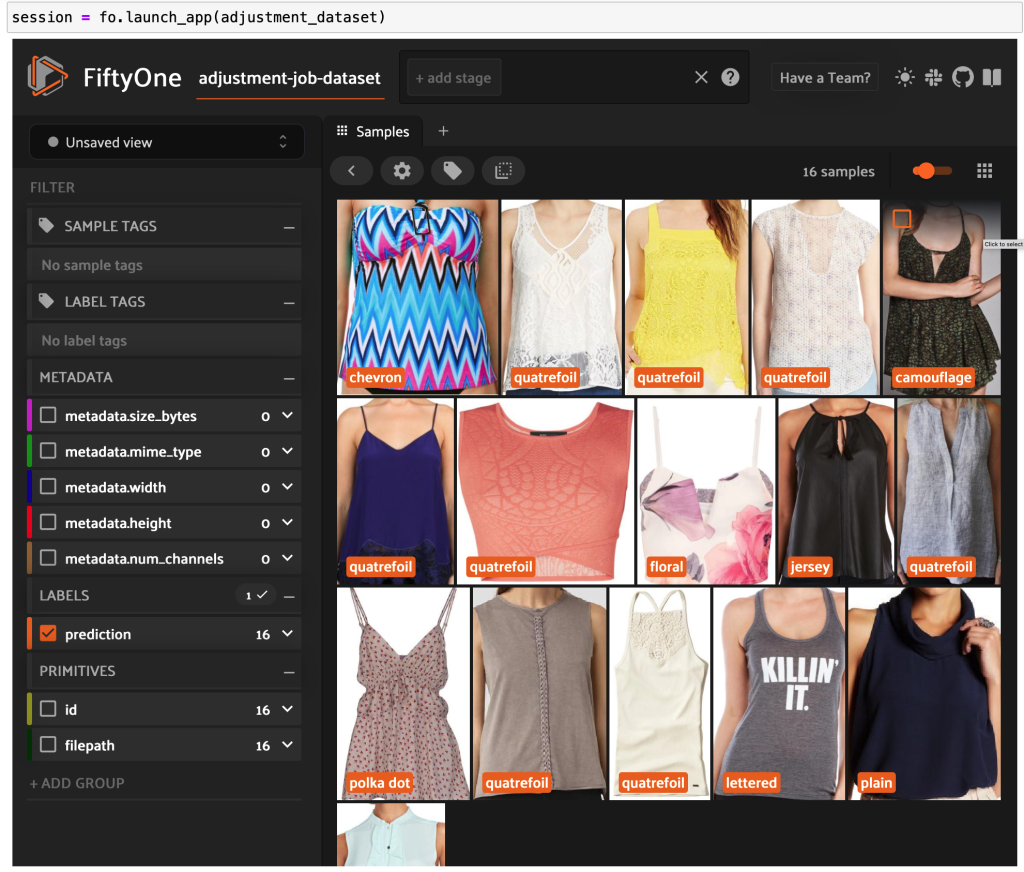
Possiamo esportare un set di dati più piccolo, ad esempio 16 immagini, nella cartella 200kFashionDatasetExportResult-16Images. Creiamo un lavoro di aggiustamento Ground Truth usandolo:
Carica il set di dati rivisto, converti il formato dell'etichetta in Ground Truth, carica su Amazon S3 e crea un file manifest per il lavoro di aggiustamento
Possiamo convertire le etichette nel set di dati in modo che corrispondano al file schema manifest di output di un lavoro di bounding box di Ground Truth e caricare le immagini su un file Servizio di archiviazione semplice Amazon (Amazon S3) secchio per lanciare a Lavoro di aggiustamento di Ground Truth:
Carica il file manifest su Amazon S3 con il seguente codice:
Crea etichette dallo stile corretto con Ground Truth
Per annotare i tuoi dati con etichette di stile utilizzando Ground Truth, completa i passaggi necessari per avviare un lavoro di etichettatura del riquadro di delimitazione seguendo la procedura descritta nel Iniziare con Ground Truth guide con il set di dati nello stesso bucket S3.
- Sulla console SageMaker, crea un lavoro di etichettatura Ground Truth.
- Impostare il Inserire la posizione del set di dati essere il manifest che abbiamo creato nei passaggi precedenti.
- Specificare un percorso S3 per Posizione del set di dati di output.
- Nel Ruolo IAMscegli Inserisci un ruolo IAM personalizzato RNA, quindi inserisci l'ARN del ruolo.
- Nel Categoria di attivitàscegli Immagine e seleziona Rettangolo di selezione.
- Scegli Avanti.
- Nel Lavoratori sezione, scegli il tipo di forza lavoro che desideri utilizzare.
È possibile selezionare una forza lavoro tramite Amazon Mechanical Turk, fornitori di terze parti o la tua forza lavoro privata. Per ulteriori dettagli sulle opzioni della forza lavoro, vedere Crea e gestisci la forza lavoro. - Espandere Opzioni di visualizzazione delle etichette esistenti e seleziona Voglio visualizzare le etichette esistenti dal set di dati per questo lavoro.
- Nel Attributo etichetta name, scegli il nome dal tuo manifest che corrisponde alle etichette che desideri visualizzare per la regolazione.
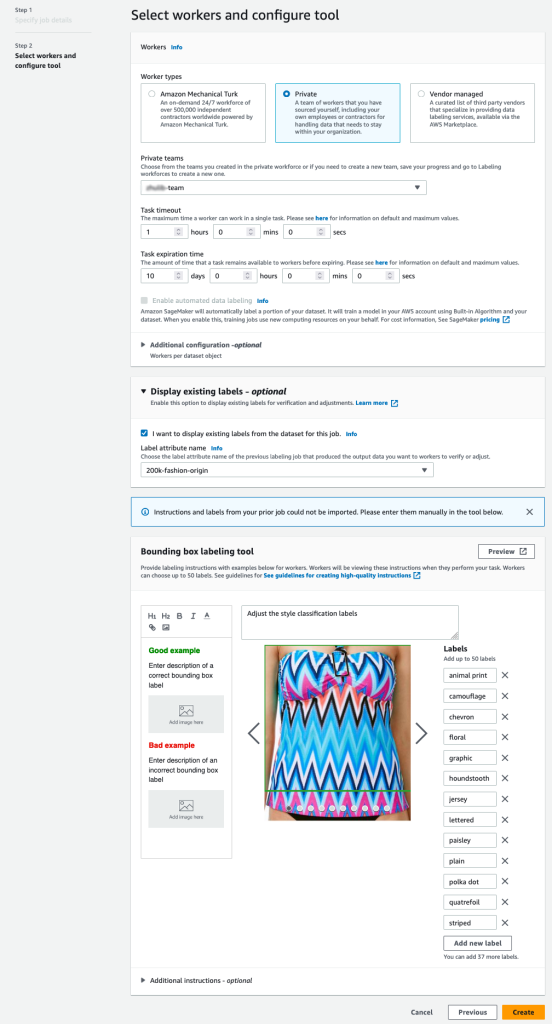
Vedrai solo i nomi degli attributi delle etichette per le etichette che corrispondono al tipo di attività selezionato nei passaggi precedenti. - Inserisci manualmente le etichette per Strumento di etichettatura del riquadro di delimitazione.
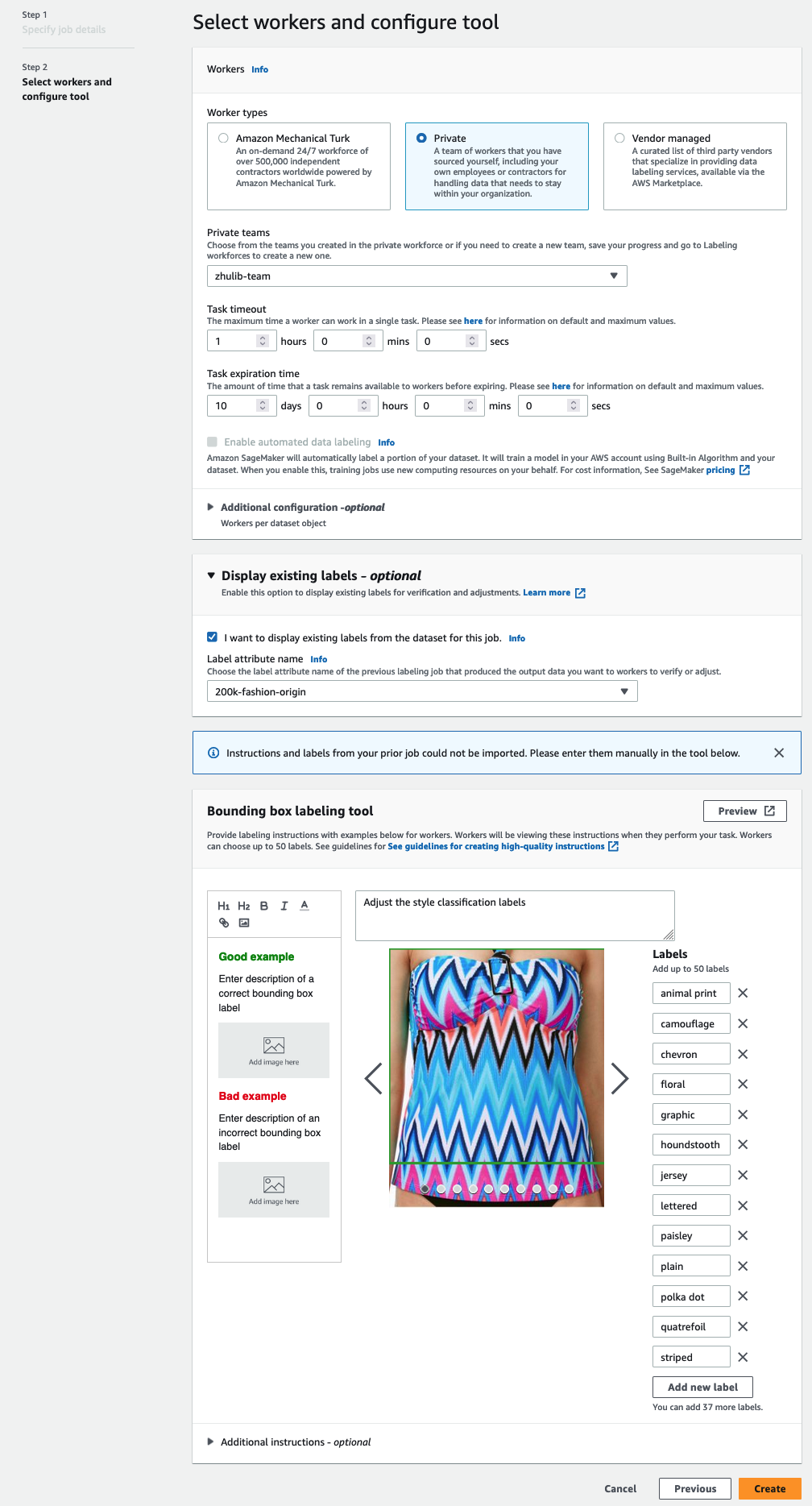 Le etichette devono contenere le stesse etichette utilizzate nel set di dati pubblico. Puoi aggiungere nuove etichette. Lo screenshot seguente mostra come puoi scegliere i lavoratori e configurare lo strumento per il tuo lavoro di etichettatura.
Le etichette devono contenere le stesse etichette utilizzate nel set di dati pubblico. Puoi aggiungere nuove etichette. Lo screenshot seguente mostra come puoi scegliere i lavoratori e configurare lo strumento per il tuo lavoro di etichettatura.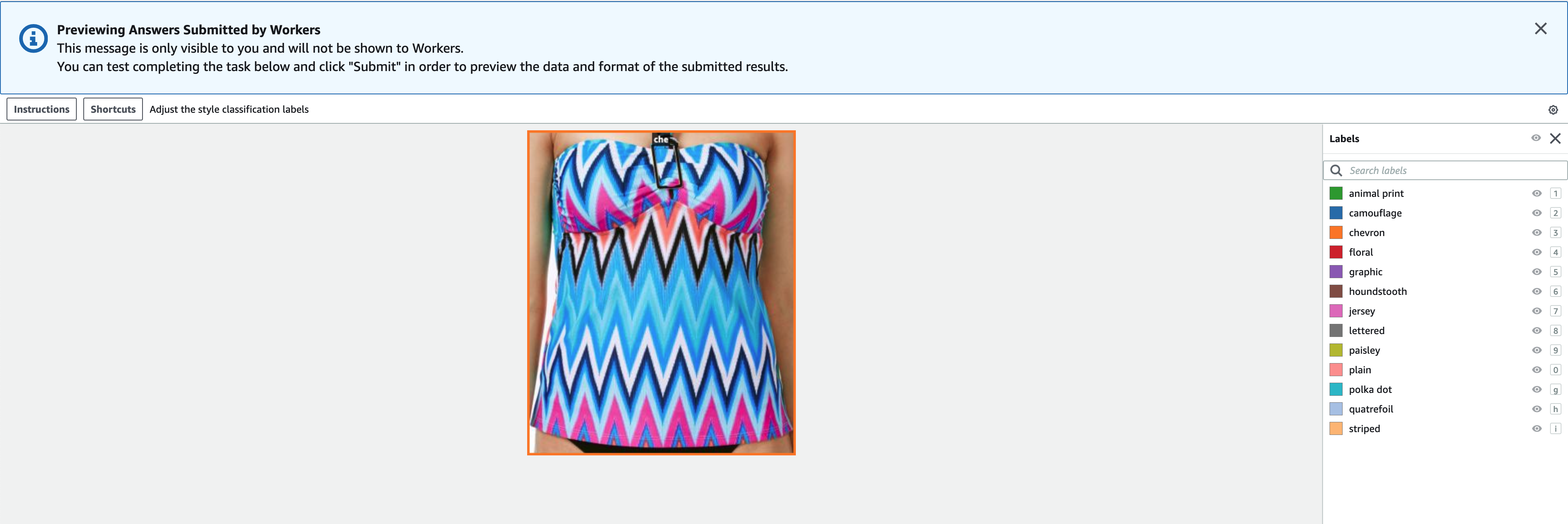
- Scegli Anteprima per visualizzare in anteprima l'immagine e le annotazioni originali.
Ora abbiamo creato un lavoro di etichettatura in Ground Truth. Al termine del nostro lavoro, possiamo caricare i dati etichettati appena generati in FiftyOne. Ground Truth produce dati di output in un manifesto di output Ground Truth. Per ulteriori dettagli sul file manifest di output, vedere Output lavoro casella di delimitazione. Il codice seguente mostra un esempio di questo formato manifest di output:
Esamina i risultati etichettati da Ground Truth in FiftyOne
Al termine del lavoro, scarica il manifest di output del lavoro di etichettatura da Amazon S3.
Leggi il file manifest di output:
Crea un set di dati FiftyOne e converti le righe manifest in campioni nel set di dati:
Ora puoi vedere dati etichettati di alta qualità da Ground Truth in FiftyOne.
Conclusione
In questo post, abbiamo mostrato come creare set di dati di alta qualità combinando la potenza di Cinquantuno by voxel51, un toolkit open source che ti consente di gestire, tracciare, visualizzare e curare il tuo set di dati e Ground Truth, un servizio di etichettatura dei dati che ti consente di etichettare in modo efficiente e accurato i set di dati richiesti per l'addestramento dei sistemi ML fornendo l'accesso a più -in modelli di attività e accesso a una forza lavoro diversificata tramite Mechanical Turk, fornitori di terze parti o la tua forza lavoro privata.
Ti invitiamo a provare questa nuova funzionalità installando un'istanza FiftyOne e utilizzando la console Ground Truth per iniziare. Per saperne di più su Ground Truth, fare riferimento a Etichetta dati, Domande frequenti sull'etichettatura dei dati di Amazon SageMaker, e il Blog di apprendimento automatico AWS.
Connettiti con Apprendimento automatico e comunità di intelligenza artificiale se avete domande o feedback!
Unisciti alla community di FiftyOne!
Unisciti alle migliaia di ingegneri e data scientist che già utilizzano FiftyOne per risolvere alcuni dei problemi più impegnativi della visione artificiale oggi!
Informazioni sugli autori
Shalendra Chabra è attualmente Head of Product Management per Amazon SageMaker Human-in-the-Loop (HIL) Services. In precedenza, Shalendra ha incubato e guidato Language and Conversational Intelligence per Microsoft Teams Meetings, è stata EIR presso Amazon Alexa Techstars Startup Accelerator, VP of Product and Marketing presso Discuti.io, Head of Product and Marketing presso Clipboard (acquisita da Salesforce) e Lead Product Manager presso Swype (acquisita da Nuance). In totale, Shalendra ha contribuito a costruire, spedire e commercializzare prodotti che hanno toccato più di un miliardo di vite.
Giacobbe Marchi è un Machine Learning Engineer e Developer Evangelist presso Voxel51, dove aiuta a portare trasparenza e chiarezza ai dati del mondo. Prima di entrare in Voxel51, Jacob ha fondato una startup per aiutare i musicisti emergenti a connettersi e condividere contenuti creativi con i fan. Prima di allora, ha lavorato presso Google X, Samsung Research e Wolfram Research. In una vita passata, Jacob era un fisico teorico, completando il suo dottorato di ricerca a Stanford, dove ha studiato le fasi quantistiche della materia. Nel tempo libero, Jacob ama arrampicarsi, correre e leggere romanzi di fantascienza.
Jason Corso è co-fondatore e CEO di Voxel51, dove dirige la strategia per aiutare a portare trasparenza e chiarezza ai dati del mondo attraverso un software flessibile all'avanguardia. È anche professore di robotica, ingegneria elettrica e informatica presso l'Università del Michigan, dove si concentra su problemi all'avanguardia all'intersezione tra visione artificiale, linguaggio naturale e piattaforme fisiche. Nel tempo libero, a Jason piace passare il tempo con la sua famiglia, leggere, stare nella natura, giocare a giochi da tavolo e ogni sorta di attività creative.
Brian Moore è co-fondatore e CTO di Voxel51, dove guida la strategia tecnica e la visione. Ha conseguito un dottorato di ricerca in ingegneria elettrica presso l'Università del Michigan, dove la sua ricerca si è concentrata su algoritmi efficienti per problemi di apprendimento automatico su larga scala, con particolare attenzione alle applicazioni di visione artificiale. Nel tempo libero ama il badminton, il golf, le escursioni e gioca con i suoi gemelli Yorkshire Terrier.
Zhuling Bai è un Software Development Engineer presso Amazon Web Services. Lavora allo sviluppo di sistemi distribuiti su larga scala per risolvere problemi di machine learning.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Coniare il futuro con Adryenn Ashley. Accedi qui.
- Acquista e vendi azioni in società PRE-IPO con PREIPO®. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :ha
- :È
- :non
- :Dove
- $ SU
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Chi siamo
- accelerare
- accelerando
- acceleratore
- accesso
- preciso
- con precisione
- acquisito
- attività
- aggiungere
- l'aggiunta di
- indirizzo
- Rettificato
- Adattamento
- Dopo shavasana, sedersi in silenzio; saluti;
- ancora
- AI
- Alexa
- Algoritmi
- Tutti
- consente
- da solo
- già
- anche
- Amazon
- amazon alexa
- Amazon Sage Maker
- Amazon SageMaker verità fondamentale
- Amazon Web Services
- tra
- an
- analizzare
- ed
- animali
- in qualsiasi
- App
- Applicazioni
- applicazioni
- APPLICA
- opportuno
- SONO
- disposte
- articolo
- news
- AS
- associato
- At
- gli autori
- lontano
- AWS
- base
- basato
- BE
- perché
- diventare
- stato
- prima
- dietro
- dietro le quinte
- essendo
- CREDIAMO
- MIGLIORE
- Meglio
- fra
- Miliardo
- tavola
- Giochi da tavolo
- OSSO
- bootstrap
- entrambi
- Scatola
- scatole
- Cervello
- Rompere
- portare
- portato
- budget limitato.
- costruire
- Costruzione
- incassato
- ma
- Acquistare
- by
- Materiale
- Catturare
- Custodie
- casi
- categoria
- Categoria
- ceo
- Challenge
- impegnativo
- dai un'occhiata
- Scegli
- chiarezza
- classe
- classi
- classificazione
- Pulizia
- pulire campo
- chiaramente
- cliente
- arrampicata
- Chiudi
- più vicino
- vestiti
- Abbigliamento
- Co-fondatore
- codice
- combinare
- combinando
- azienda
- Complemento
- completamento di una
- completando
- Calcolare
- computer
- Informatica
- Visione computerizzata
- Applicazioni di visione artificiale
- fiducia
- fiducioso
- Connettiti
- considerazione
- Consistente
- consolle
- contiene
- contenuto
- testuali
- controllata
- discorsivo
- convertire
- copie
- Nucleo
- corretto
- corrisponde
- Costo
- Costi
- creare
- creato
- Creative
- Credenziali
- CTO
- a cura
- curatela
- Attualmente
- costume
- cliente
- Clienti
- taglio
- bordo tagliente
- dati
- dataset
- decide
- dimostrare
- Denim
- profondità
- descrizione
- dettagli
- rivelazione
- Costruttori
- in via di sviluppo
- Mercato
- diverso
- direttamente
- directory
- Dsiplay
- distinto
- distribuito
- sistemi distribuiti
- paesaggio differenziato
- do
- non
- Cane
- fare
- fatto
- Dont
- DOT
- giù
- scaricare
- duplicati
- e
- ogni
- facile
- bordo
- effetto
- efficiente
- in modo efficiente
- Ingegneria Elettrica
- incorporamento
- emergenti del mondo
- enfasi
- impiega
- Potenzia
- incapsulato
- incoraggiare
- fine
- ingegnere
- Ingegneria
- Ingegneri
- entrare
- Ambiente
- uguaglianza
- essential
- sviluppate
- Etere (ETH)
- la valutazione
- Evangelista
- di preciso
- esempio
- esistente
- export
- abbastanza
- famiglia
- fan
- feedback
- pochi
- Fantasia
- campo
- campi
- Compila il
- File
- filtro
- filtraggio
- finale
- Nome
- in forma
- flessibile
- Focus
- concentrato
- si concentra
- i seguenti
- Nel
- modulo
- formato
- per fortuna
- Fondato
- quattro
- Gratis
- da
- completamente
- funzionalità
- Giochi
- scopo generale
- generare
- generato
- ottenere
- GitHub
- Dare
- dato
- scopo
- golf
- buono
- maggiore
- Griglia
- Terra
- Gruppo
- guida
- contento
- Avere
- he
- capo
- altezza
- Aiuto
- aiutato
- utile
- aiuta
- qui
- alta qualità
- ad alta risoluzione
- massimo
- vivamente
- escursionismo
- il suo
- detiene
- Come
- Tutorial
- Tuttavia
- HTML
- http
- HTTPS
- umano
- i
- IAM
- ID
- identificare
- identificazione
- ids
- if
- Immagine
- immagini
- Impact
- importare
- miglioramento
- in
- In altre
- Compreso
- in modo non corretto
- incubato
- informazioni
- inizialmente
- inizialmente
- install
- installazione
- esempio
- invece
- istruzioni
- Intelligence
- intersezione
- ai miglioramenti
- IT
- SUO
- Jersey
- Lavoro
- accoppiamento
- giunto
- json
- ad appena
- mantenere
- conservazione
- Discografica
- etichettatura
- per il tuo brand
- Lingua
- larga scala
- lanciare
- lancio
- portare
- Leads
- IMPARARE
- apprendimento
- meno
- Guidato
- a sinistra
- Consente di
- Biblioteca
- Vita
- piace
- probabile
- LIMITE
- Limitato
- linea
- Linee
- Lista
- annuncio
- Annunci
- piccolo
- Lives
- caricare
- Guarda
- cerca
- lotto
- Basso
- macchina
- machine learning
- fatto
- magia
- make
- FA
- gestire
- gestito
- gestione
- direttore
- molti
- carta geografica
- Rappresentanza
- Marketing
- partita
- corrispondenza
- materialmente
- Importanza
- Maggio..
- meccanico
- Media
- incontri
- Meta
- Metadati
- metodo
- metodi
- Michigan
- Microsoft
- squadre di microsoft
- forza
- ordine
- ML
- Mobile
- mobile app
- modello
- modelli
- moduli
- Scopri di più
- maggior parte
- cambiano
- molti
- multiplo
- musicisti
- devono obbligatoriamente:
- Nome
- Detto
- nomi
- Naturale
- Linguaggio naturale
- Natura
- Vicino
- necessariamente
- necessaria
- Bisogno
- esigenze
- New
- notevolmente
- Nozione
- adesso
- Ombra
- numero
- oggetto
- Rilevazione dell'oggetto
- oggetti
- of
- ufficiale
- on
- una volta
- ONE
- online
- esclusivamente
- aprire
- open source
- Operazioni
- Opportunità
- Opzioni
- or
- Organizzato
- i
- OS
- Altro
- Altri
- nostro
- su
- delineato
- produzione
- ancora
- proprio
- possiede
- Pacchetti
- accoppiato
- parte
- particolare
- passato
- sentiero
- Cartamodello
- modelli
- perfetta
- performance
- persona
- Personalizzata
- Fasi della materia
- Fisico
- scegliere
- Immagini
- PLAID
- pianura
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- punto
- popolata
- possibile
- Post
- energia
- pratica
- previsto
- predizione
- Previsioni
- Anteprima
- precedente
- in precedenza
- Stampa
- Precedente
- un bagno
- probabilmente
- problemi
- processi
- Prodotto
- gestione del prodotto
- product manager
- Prodotti
- Insegnante
- progetto
- proprietà
- potenziale
- prototipo
- fornire
- purché
- fornitura
- la percezione
- punch
- fini
- Python
- Quantistico
- Domande
- rapidamente
- gamma
- piuttosto
- Lettura
- pronto
- raccomandare
- raccomandazioni
- ridurre
- Ridotto
- riduzione
- relativamente
- rilasciato
- pertinente
- rimuovere
- rappresentante
- che rappresenta
- necessario
- riparazioni
- ricercatori
- Risoluzione
- limitare
- colpevole
- risultante
- Risultati
- nello specifico retail
- ritorno
- recensioni
- Rid
- robotica
- robusto
- Ruolo
- approssimativamente
- RIGA
- rovina
- running
- sagemaker
- Suddetto
- forza di vendita
- stesso
- Samsung
- Risparmi
- Scene
- Scienze
- Fantascienza
- scienziati
- Punto
- senza soluzione di continuità
- Secondo
- Sezione
- sezioni
- vedere
- sembrare
- sembra
- selezionato
- senso
- separato
- servizio
- Servizi
- Sessione
- set
- Condividi
- lei
- dovrebbero
- mostrare attraverso le sue creazioni
- Spettacoli
- SIM
- simile
- Un'espansione
- inferiore
- So
- Software
- lo sviluppo del software
- RISOLVERE
- alcuni
- Qualcuno
- qualcosa
- lo spazio
- spendere
- Spendere
- dividere
- Si divide
- stanford
- inizia a
- iniziato
- Di partenza
- startup
- acceleratore di avvio
- state-of-the-art
- Passi
- Ancora
- conservazione
- Tornare al suo account
- Strategia
- style
- stili
- SOMMARIO
- supportato
- SISTEMI DI TRATTAMENTO
- Fai
- Task
- le squadre
- Consulenza
- TechStars
- dice
- modelli
- test
- di
- che
- I
- loro
- Li
- poi
- teorico
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- cose
- think
- di parti terze standard
- questo
- migliaia
- soglia
- Attraverso
- Lancio
- tempo
- a
- insieme
- toolkit
- top
- di livello superiore
- Tops, Cardigan & Pullover
- Totale
- toccato
- pista
- Treni
- allenato
- Training
- Trasformare
- Trasparenza
- vero
- Verità
- TURNO
- seconda
- Digitare
- Tipi di
- per
- capire
- unico
- Università
- University of Michigan
- Aggiornanento
- us
- uso
- caso d'uso
- utilizzato
- Utente
- utenti
- utilizzando
- Valori
- varietà
- vario
- fornitori
- verificare
- molto
- via
- Visualizza
- virtuale
- visione
- volere
- Prima
- we
- sito web
- servizi web
- WELL
- sono stati
- Che
- quando
- se
- quale
- wikipedia
- volere
- con
- entro
- senza
- Donna
- parole
- Lavora
- lavorato
- lavoratori
- Forza lavoro
- lavori
- Il mondo di
- preoccuparsi
- sarebbe
- scrivere
- X
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- Codice postale
- ZOO