Immagine dell'autore
Immergendoti nel mondo della scienza dei dati e dell'apprendimento automatico, una delle competenze fondamentali che incontrerai è l'arte di leggere i dati. Se hai già esperienza con esso, probabilmente hai familiarità con JSON (JavaScript Object Notation), un formato popolare sia per l'archiviazione che per lo scambio di dati.
Pensa a come i database NoSQL come MongoDB amano archiviare i dati in JSON o a come le API REST spesso rispondono nello stesso formato.
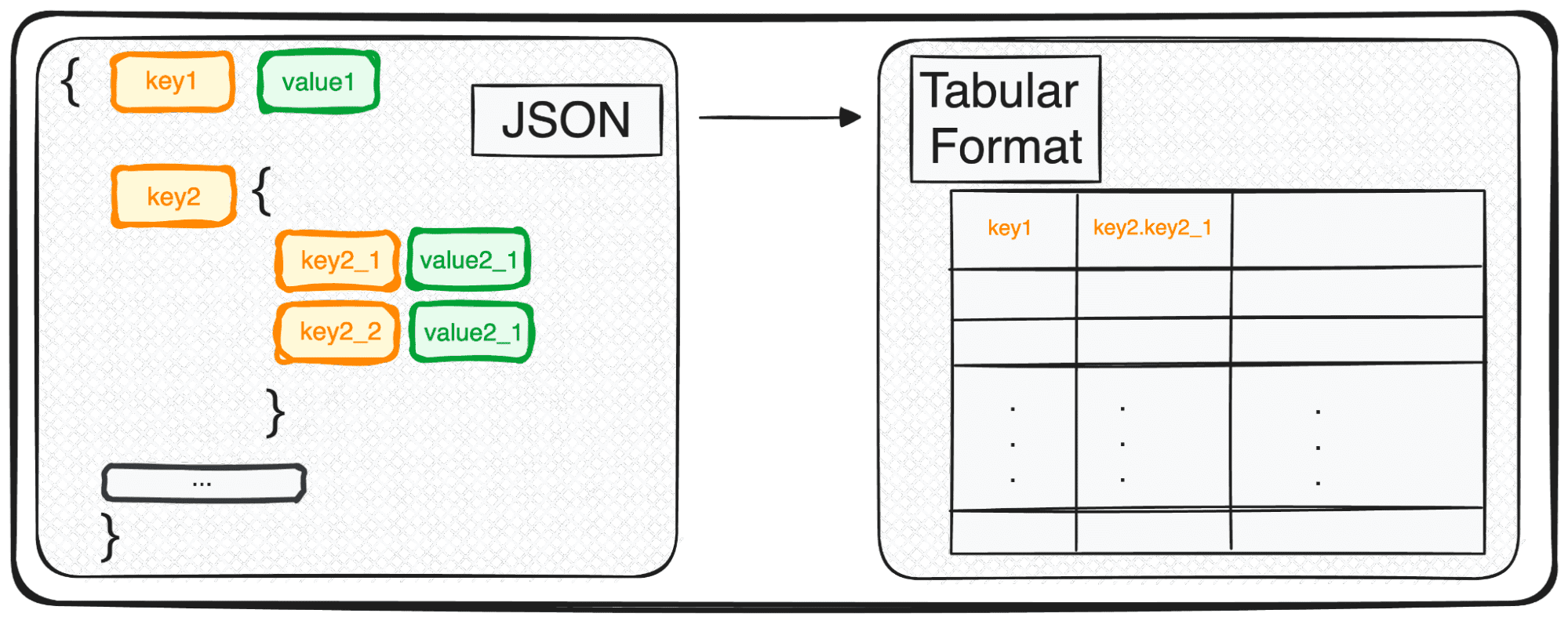
Tuttavia, JSON, sebbene perfetto per l'archiviazione e lo scambio, non è ancora pronto per un'analisi approfondita nella sua forma grezza. È qui che lo trasformiamo in qualcosa di più analiticamente amichevole: un formato tabellare.
Quindi, sia che tu abbia a che fare con un singolo oggetto JSON o con un delizioso insieme di essi, nei termini di Python, stai essenzialmente gestendo un dict o un elenco di dict.
Esploriamo insieme come si svolge questa trasformazione, rendendo i nostri dati maturi per l'analisi ????
Oggi spiegherò un comando magico che ci consente di analizzare facilmente qualsiasi JSON in un formato tabellare in pochi secondi.
Ed è... pd.json_normalize()
Vediamo quindi come funziona con diversi tipi di JSON.
Il primo tipo di JSON con cui possiamo lavorare sono i JSON a livello singolo con poche chiavi e valori. Definiamo i nostri primi JSON semplici come segue:
Codice per autore
Quindi simuliamo la necessità di lavorare con questi JSON. Sappiamo tutti che non c'è molto da fare nel loro formato JSON. Dobbiamo trasformare questi JSON in un formato leggibile e modificabile... il che significa Pandas DataFrames!
1.1 Gestire semplici strutture JSON
Per prima cosa dobbiamo importare la libreria pandas e poi possiamo usare il comando pd.json_normalize(), come segue:
import pandas as pd
pd.json_normalize(json_string)
Applicando questo comando ad un JSON con un singolo record, otteniamo la tabella più elementare. Tuttavia, quando i nostri dati sono un po' più complessi e presentano un elenco di JSON, possiamo comunque utilizzare lo stesso comando senza ulteriori complicazioni e l'output corrisponderà a una tabella con più record.

Immagine dell'autore
Facile... vero?
La prossima domanda naturale è cosa succede quando mancano alcuni valori.
1.2 Gestire i valori nulli
Immagina che alcuni valori non siano informati, come ad esempio che manchi il record del reddito per David. Quando trasformiamo il nostro JSON in un semplice dataframe panda, il valore corrispondente apparirà come NaN.
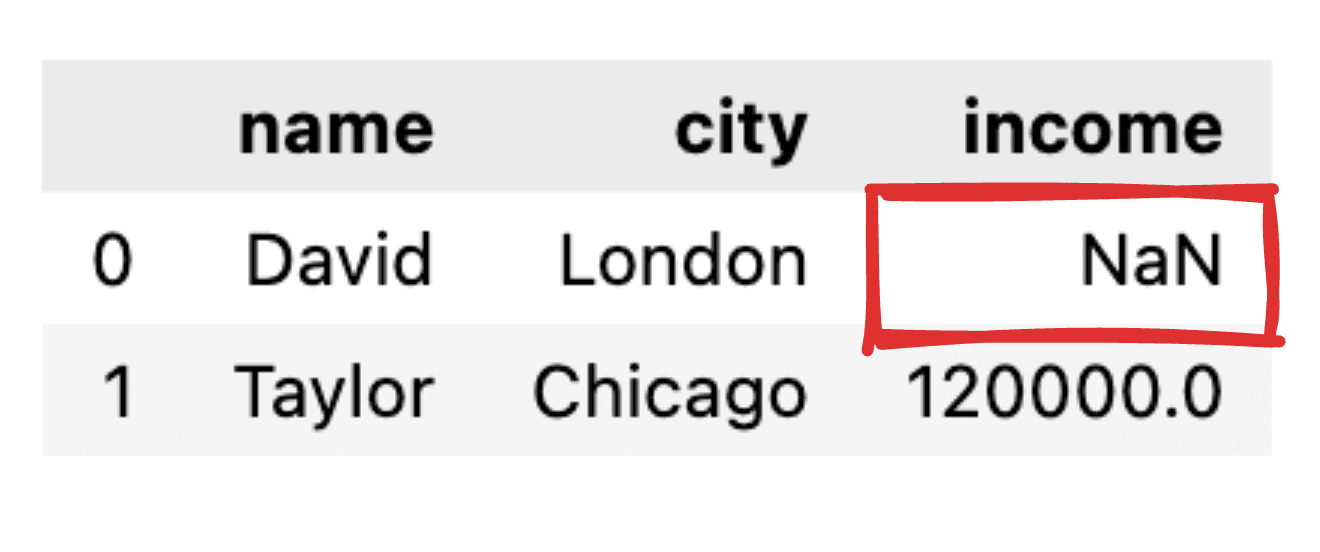
Immagine dell'autore
E se volessi prendere solo alcuni campi?
1.3 Selezionando solo le colonne di interesse
Nel caso in cui desideriamo solo trasformare alcuni campi specifici in un DataFrame panda tabulare, il comando json_normalize() non ci consente di scegliere quali campi trasformare.
Pertanto, dovrebbe essere eseguita una piccola preelaborazione del JSON in cui filtriamo solo le colonne di interesse.
# Fields to include
fields = ['name', 'city']
# Filter the JSON data
filtered_json_list = [{key: value for key, value in item.items() if key in fields} for item in simple_json_list]
pd.json_normalize(filtered_json_list)
Passiamo quindi a una struttura JSON più avanzata.
Quando si ha a che fare con JSON a più livelli ci troviamo con JSON nidificati all'interno di diversi livelli. La procedura è la stessa di prima, ma in questo caso possiamo scegliere quanti livelli vogliamo trasformare. Per impostazione predefinita, il comando espanderà sempre tutti i livelli e genererà nuove colonne contenenti il nome concatenato di tutti i livelli nidificati.
Quindi, se normalizziamo i seguenti JSON.
Codice per autore
Otterremmo la seguente tabella con 3 colonne sotto le competenze del campo:
- competenze.python
- competenze.SQL
- competenze.GCP
e 4 colonne sotto i ruoli sul campo
- ruoli.responsabile del progetto
- ingegnere di roles.data
- ruoli.scienziato dei dati
- ruoli.analista dei dati

Immagine dell'autore
Tuttavia, immaginiamo di voler semplicemente trasformare il nostro livello più alto. Possiamo farlo definendo specificamente il parametro max_level su 0 (il max_level che vogliamo espandere).
pd.json_normalize(mutliple_level_json_list, max_level = 0)
I valori in sospeso verranno mantenuti all'interno dei JSON all'interno del nostro DataFrame panda.
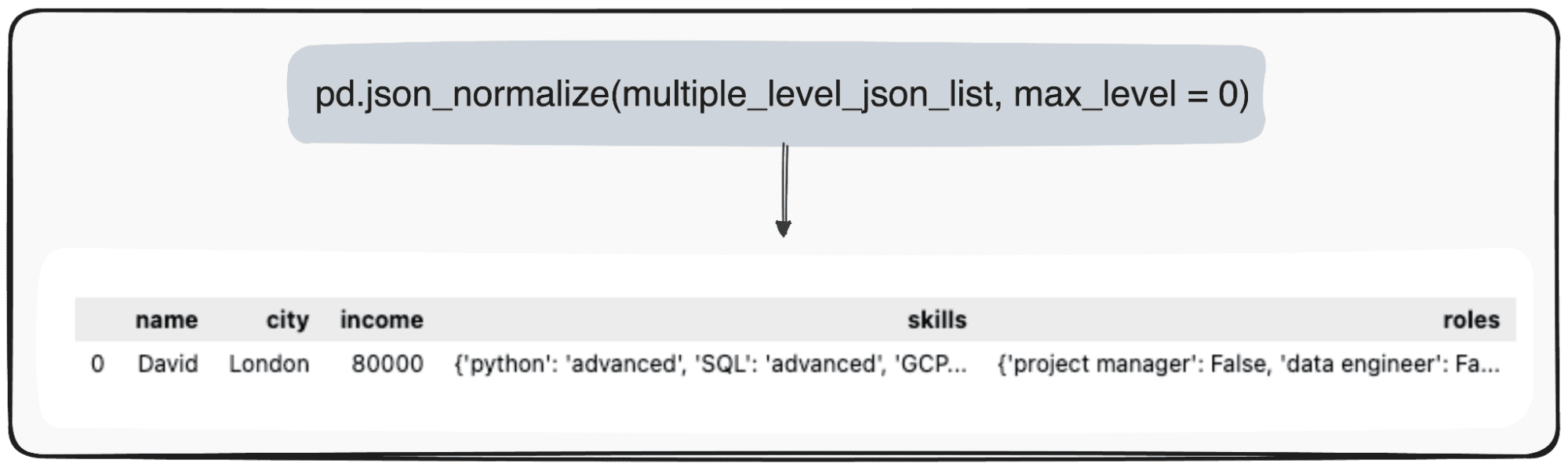
Immagine dell'autore
L'ultimo caso che possiamo trovare è avere un elenco annidato all'interno di un campo JSON. Quindi per prima cosa definiamo i nostri JSON da utilizzare.
Codice per autore
Possiamo gestire in modo efficace questi dati utilizzando Panda in Python. La funzione pd.json_normalize() è particolarmente utile in questo contesto. Può appiattire i dati JSON, incluso l'elenco nidificato, in un formato strutturato adatto all'analisi. Quando questa funzione viene applicata ai nostri dati JSON, produce una tabella normalizzata che incorpora l'elenco nidificato come parte dei suoi campi.
Inoltre, Pandas offre la possibilità di perfezionare ulteriormente questo processo. Utilizzando il parametro record_path in pd.json_normalize(), possiamo indirizzare la funzione a normalizzare in modo specifico l'elenco nidificato.
Questa azione dà come risultato una tabella dedicata esclusivamente al contenuto dell'elenco. Per impostazione predefinita, questo processo spiegherà solo gli elementi all'interno dell'elenco. Tuttavia, per arricchire questa tabella con contesto aggiuntivo, ad esempio mantenendo un ID associato per ciascun record, possiamo utilizzare il meta parametro.

Immagine dell'autore
In sintesi, la trasformazione dei dati JSON in file CSV utilizzando la libreria Pandas di Python è semplice ed efficace.
JSON è ancora il formato più comune nell'archiviazione e nello scambio di dati moderni, in particolare nei database NoSQL e nelle API REST. Tuttavia, presenta alcune importanti sfide analitiche quando si tratta di dati nel loro formato grezzo.
Il ruolo fondamentale di pd.json_normalize() di Panda emerge come un ottimo modo per gestire tali formati e convertire i nostri dati in DataFrame di Panda.
Spero che questa guida ti sia stata utile e che la prossima volta che avrai a che fare con JSON, potrai farlo in modo più efficace.
Puoi andare a controllare il corrispondente Jupyter Notebook nel file seguendo il repository GitHub.
Giuseppe Ferrer è un ingegnere analitico di Barcellona. Laureato in ingegneria fisica, attualmente lavora nel campo della Data Science applicata alla mobilità umana. È un creatore di contenuti part-time focalizzato sulla scienza e la tecnologia dei dati. Puoi contattarlo su LinkedIn, Twitter or Medio.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://www.kdnuggets.com/converting-jsons-to-pandas-dataframes-parsing-them-the-right-way?utm_source=rss&utm_medium=rss&utm_campaign=converting-jsons-to-pandas-dataframes-parsing-them-the-right-way
- :È
- :non
- :Dove
- 1
- 1.3
- 11
- 2%
- 4
- 7
- 8
- a
- Chi siamo
- Action
- aggiuntivo
- Avanzate
- Tutti
- consentire
- consente
- già
- sempre
- an
- .
- analista
- Analitico
- analitica
- ed
- in qualsiasi
- API
- apparire
- applicato
- AMMISSIONE
- SONO
- Italia
- Arte
- AS
- associato
- Barcellona
- basic
- BE
- prima
- Po
- entrambi
- ma
- by
- Materiale
- capacità
- Custodie
- sfide
- dai un'occhiata
- Scegli
- Città
- colonne
- Uncommon
- complesso
- complicazioni
- contatti
- contenuto
- testuali
- contesto
- convertire
- conversione
- corrispondere
- Corrispondente
- Creatore
- Attualmente
- dati
- analista dati
- ingegnere dei dati
- scienza dei dati
- scienziato di dati
- memorizzazione dei dati
- banche dati
- David
- trattare
- dedicato
- Predefinito
- definire
- definizione
- delizioso
- DITT
- diverso
- dirette
- do
- effettua
- ogni
- facilmente
- facile
- Efficace
- in maniera efficace
- elementi
- emerge
- incontrare
- ingegnere
- Ingegneria
- arricchire
- essenzialmente
- exchange
- scambio
- esclusivamente
- Espandere
- esperienza
- spiegando
- esplora
- familiare
- pochi
- campo
- campi
- File
- filtro
- Trovare
- Nome
- concentrato
- i seguenti
- segue
- Nel
- modulo
- formato
- amichevole
- da
- function
- fondamentale
- ulteriormente
- GCP
- generare
- ottenere
- GitHub
- Go
- grande
- guida
- maniglia
- Manovrabilità
- accade
- Avere
- avendo
- he
- lui
- speranza
- Come
- Tuttavia
- HTTPS
- umano
- i
- MALATO
- ID
- if
- immagine
- importare
- importante
- in
- Uno sguardo approfondito sui miglioramenti dei pneumatici da corsa di Bridgestone.
- includere
- Compreso
- Reddito
- incorpora
- informati
- esempio
- interesse
- ai miglioramenti
- ISN
- IT
- SUO
- JavaScript
- json
- Notebook Jupyter
- ad appena
- KDnuggets
- Le
- Tasti
- Sapere
- Cognome
- apprendimento
- Livello
- livelli
- Biblioteca
- piace
- Lista
- piccolo
- ll
- amore
- macchina
- machine learning
- magia
- mantenuto
- Fare
- gestire
- direttore
- molti
- si intende
- Meta
- mancante
- mobilità
- moderno
- MongoDB
- Scopri di più
- maggior parte
- cambiano
- molti
- multiplo
- Nome
- Naturale
- Bisogno
- annidato
- New
- GENERAZIONE
- no
- segnatamente
- taccuino
- oggetto
- ottenere
- of
- Offerte
- di frequente
- on
- ONE
- esclusivamente
- or
- nostro
- noi stessi
- produzione
- panda
- parametro
- parte
- particolarmente
- in attesa di
- perfetta
- eseguita
- Fisica
- centrale
- Platone
- Platone Data Intelligence
- PlatoneDati
- Popolare
- regali
- probabilmente
- procedura
- processi
- produce
- progetto
- Python
- domanda
- abbastanza
- Crudo
- RE
- Lettura
- pronto
- record
- record
- raffinare
- Rispondere
- REST
- Risultati
- di ritegno
- destra
- Ruolo
- s
- stesso
- Scienze
- Scienza e Tecnologia
- Scienziato
- secondo
- vedere
- Selezione
- dovrebbero
- Un'espansione
- simulare
- singolo
- abilità
- piccole
- So
- alcuni
- qualcosa
- specifico
- in particolare
- SQL
- Ancora
- conservazione
- Tornare al suo account
- La struttura
- strutturato
- tale
- adatto
- SOMMARIO
- T
- tavolo
- Tecnologia
- condizioni
- che
- I
- il mondo
- loro
- Li
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- quelli
- tempo
- a
- insieme
- top
- Trasformare
- Trasformazione
- trasformazione
- Digitare
- Tipi di
- per
- us
- uso
- utile
- utilizzando
- Utilizzando
- APPREZZIAMO
- Valori
- volere
- Prima
- Modo..
- we
- Che
- quando
- se
- quale
- while
- volere
- con
- entro
- Lavora
- lavoro
- lavori
- mondo
- sarebbe
- Tu
- zefiro