Nell'odierno ambiente aziendale basato sui dati, le organizzazioni affrontano la sfida di preparare e trasformare in modo efficiente grandi quantità di dati per scopi di analisi e data science. Le aziende devono creare data warehouse e data lake basati su dati operativi. Ciò è guidato dalla necessità di centralizzare e integrare i dati provenienti da fonti eterogenee.
Allo stesso tempo, i dati operativi spesso provengono da applicazioni supportate da data store legacy. La modernizzazione delle applicazioni richiede un'architettura di microservizi, che a sua volta richiede il consolidamento dei dati da più origini per creare un archivio dati operativo. Senza la modernizzazione, le applicazioni legacy potrebbero sostenere costi di manutenzione crescenti. La modernizzazione delle applicazioni implica la modifica del motore di database sottostante in un moderno database basato su documenti come MongoDB.
Queste due attività (creazione di data lake o data warehouse e modernizzazione delle applicazioni) implicano lo spostamento dei dati, che utilizza un processo di estrazione, trasformazione e caricamento (ETL). Il lavoro ETL è una funzionalità chiave per avere un processo ben strutturato per avere successo.
Colla AWS è un servizio di integrazione dei dati serverless che semplifica l'individuazione, la preparazione, lo spostamento e l'integrazione dei dati da più fonti per l'analisi, il machine learning (ML) e lo sviluppo di applicazioni. Atlante MongoDB è una suite integrata di database cloud e servizi dati che combina elaborazione transazionale, ricerca basata sulla pertinenza, analisi in tempo reale e sincronizzazione dei dati da mobile a cloud in un'architettura elegante e integrata.
Utilizzando AWS Glue con MongoDB Atlas, le organizzazioni possono semplificare i propri processi ETL. Con la sua soluzione di database completamente gestita, scalabile e sicura, MongoDB Atlas offre un ambiente flessibile e affidabile per l'archiviazione e la gestione dei dati operativi. Insieme, AWS Glue ETL e MongoDB Atlas sono una potente soluzione per le organizzazioni che cercano di ottimizzare il modo in cui creano data lake e data warehouse e di modernizzare le loro applicazioni, al fine di migliorare le prestazioni aziendali, ridurre i costi e guidare la crescita e il successo.
In questo post, dimostriamo come eseguire la migrazione dei dati da Servizio di archiviazione semplice Amazon (Amazon S3) su MongoDB Atlas utilizzando AWS Glue ETL e come estrarre i dati da MongoDB Atlas in un data lake basato su Amazon S3.
Panoramica della soluzione
In questo post, esploriamo i seguenti casi d'uso:
- Estrazione dei dati da MongoDB – MongoDB è un popolare database utilizzato da migliaia di clienti per archiviare i dati delle applicazioni su larga scala. I clienti aziendali possono centralizzare e integrare i dati provenienti da più datastore creando data lake e data warehouse. Questo processo comporta l'estrazione dei dati dagli archivi dati operativi. Quando i dati si trovano in un unico posto, i clienti possono utilizzarli rapidamente per esigenze di business intelligence o per ML.
- Inserimento di dati in MongoDB – MongoDB funge anche da database senza SQL per archiviare i dati delle applicazioni e creare archivi di dati operativi. La modernizzazione delle applicazioni comporta spesso la migrazione dell'archivio operativo a MongoDB. I clienti dovrebbero estrarre i dati esistenti da database relazionali o da file flat. Le app per dispositivi mobili e Web spesso richiedono ai data engineer di creare pipeline di dati per creare un'unica visualizzazione dei dati in Atlas durante l'acquisizione dei dati da più origini in silos. Durante questa migrazione, avrebbero dovuto unire diversi database per creare documenti. Questa complessa operazione di join richiederebbe una notevole potenza di calcolo una tantum. Gli sviluppatori dovrebbero anche crearlo rapidamente per migrare i dati.
AWS Glue è utile in questi casi con il modello pay-as-you-go e la sua capacità di eseguire trasformazioni complesse su enormi set di dati. Gli sviluppatori possono utilizzare AWS Glue Studio per creare in modo efficiente tali pipeline di dati.
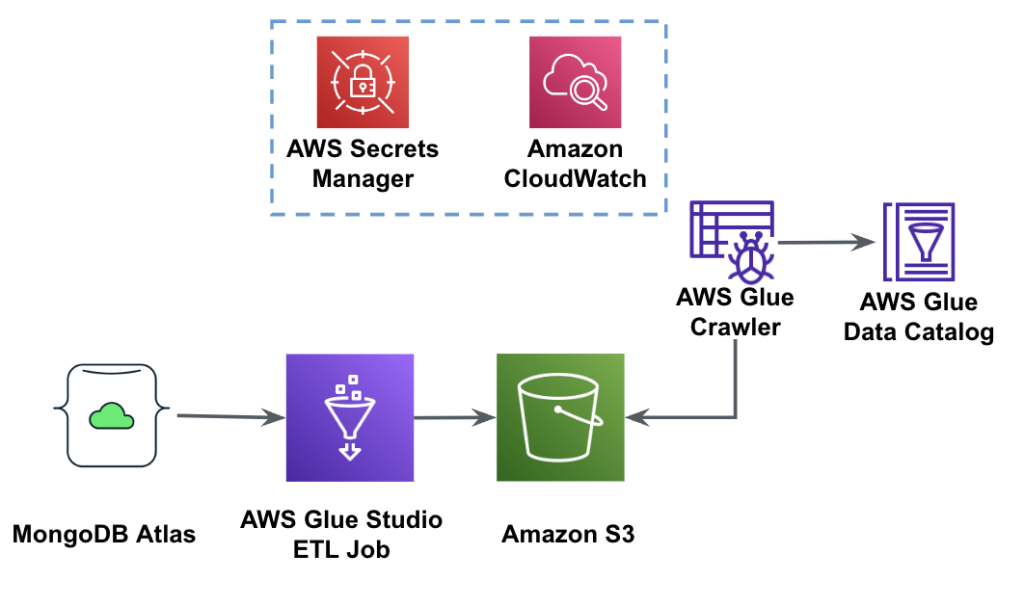
Il diagramma seguente mostra il flusso di lavoro di estrazione dei dati da MongoDB Atlas in un bucket S3 utilizzando AWS Glue Studio.
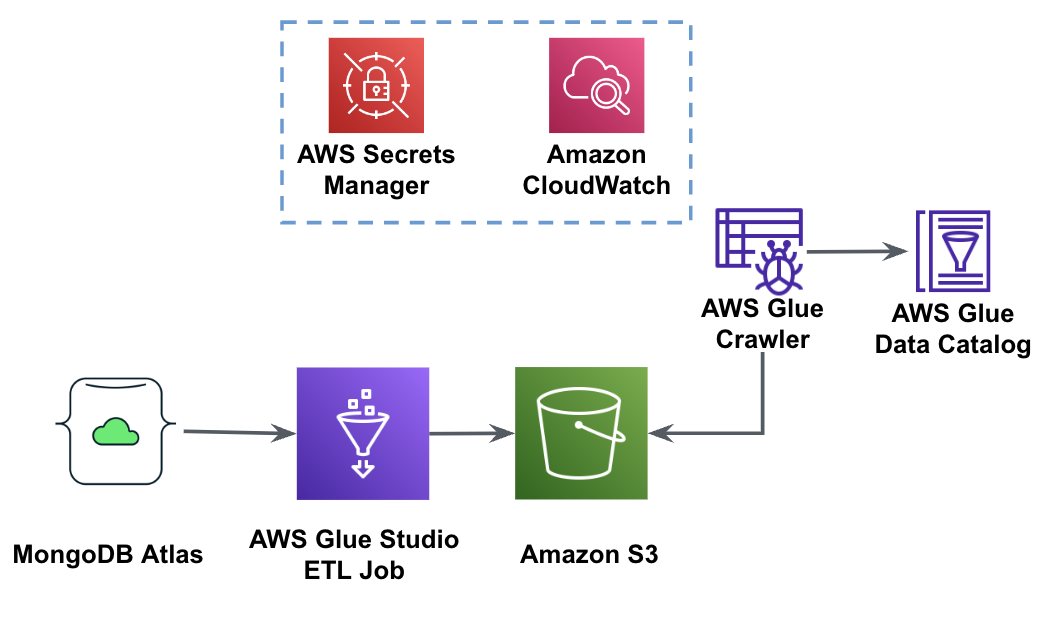
Per implementare questa architettura, avrai bisogno di un cluster MongoDB Atlas, un bucket S3 e un Gestione dell'identità e dell'accesso di AWS (IAM) per AWS Glue. Per configurare queste risorse, fare riferimento ai passaggi preliminari riportati di seguito Repository GitHub.
La figura seguente mostra il flusso di lavoro di caricamento dei dati da un bucket S3 in MongoDB Atlas utilizzando AWS Glue.
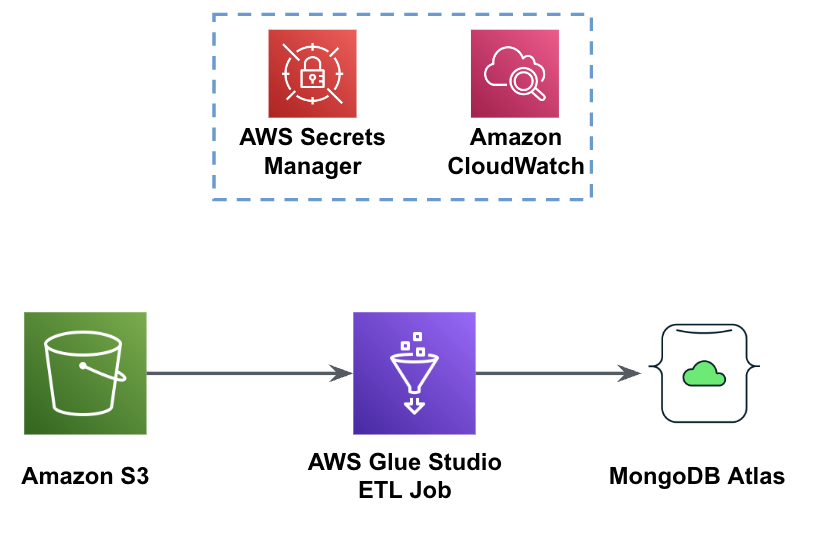
Qui sono necessari gli stessi prerequisiti: un bucket S3, un ruolo IAM e un cluster MongoDB Atlas.
Carica i dati da Amazon S3 a MongoDB Atlas utilizzando AWS Glue
I passaggi seguenti descrivono come caricare i dati dal bucket S3 in MongoDB Atlas utilizzando un processo AWS Glue. Il processo di estrazione da MongoDB Atlas ad Amazon S3 è molto simile, ad eccezione dello script utilizzato. Chiariamo le differenze tra i due processi.
- Crea un cluster gratuito nell'atlante MongoDB.
- Carica il file JSON di esempio al tuo bucket S3.
- Crea un nuovo processo AWS Glue Studio con il file Editor di script Spark opzione.

- A seconda che tu voglia caricare o estrarre i dati dal cluster MongoDB Atlas, inserisci il file carica lo script or estrarre lo script nell'editor di script di AWS Glue Studio.
Lo screenshot seguente mostra uno snippet di codice per il caricamento dei dati nel cluster MongoDB Atlas.

Il codice usa AWS Secrets Manager per recuperare il nome del cluster MongoDB Atlas, il nome utente e la password. Quindi, crea un file DynamicFrame per il bucket S3 e il nome file passati allo script come parametri. Il codice recupera i nomi del database e della raccolta dalla configurazione dei parametri del processo. Infine, il codice scrive il file DynamicFrame al cluster MongoDB Atlas utilizzando i parametri recuperati.
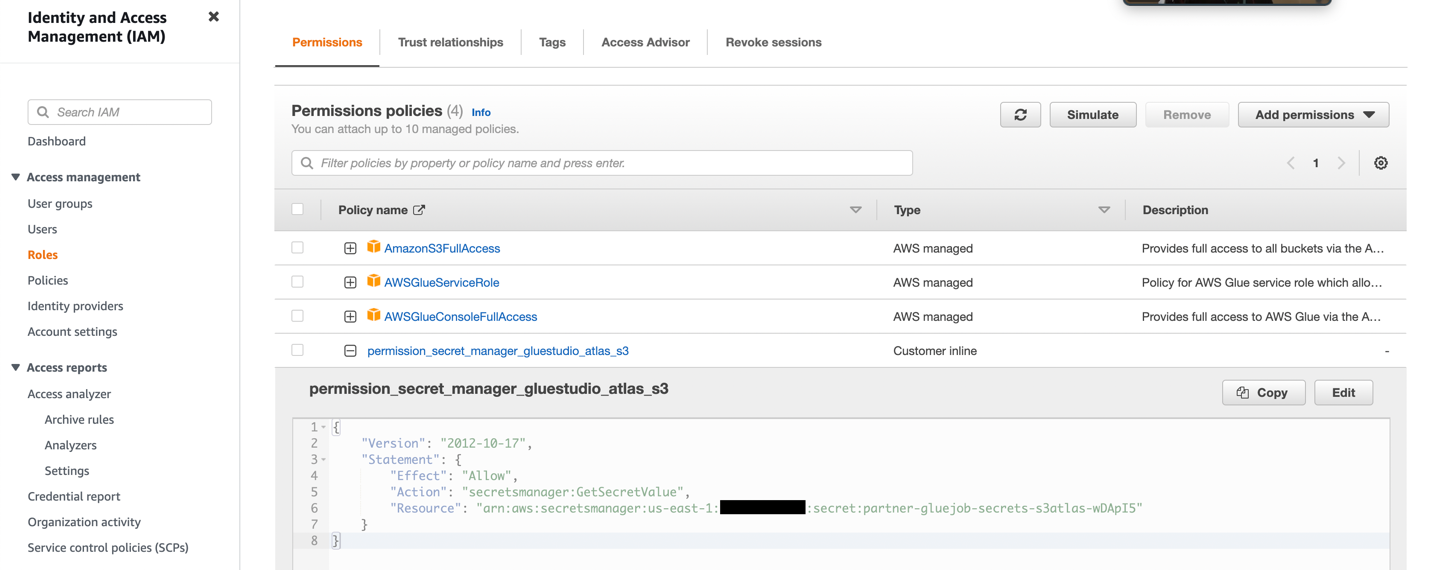
- Crea un ruolo IAM con le autorizzazioni come mostrato nello screenshot seguente.
Per maggiori dettagli, consultare Configura un ruolo IAM per il tuo lavoro ETL.
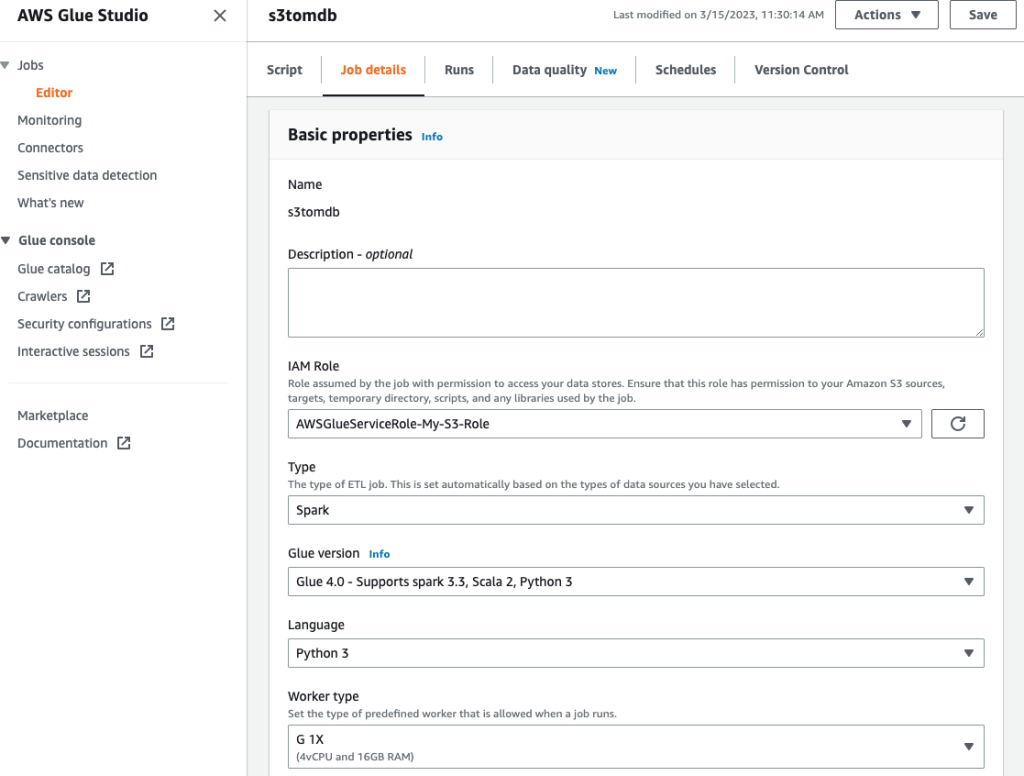
- Assegna un nome al lavoro e fornisci il ruolo IAM creato nel passaggio precedente sul file Dettagli di lavoro scheda.
- Puoi lasciare il resto dei parametri come predefinito, come mostrato negli screenshot seguenti.
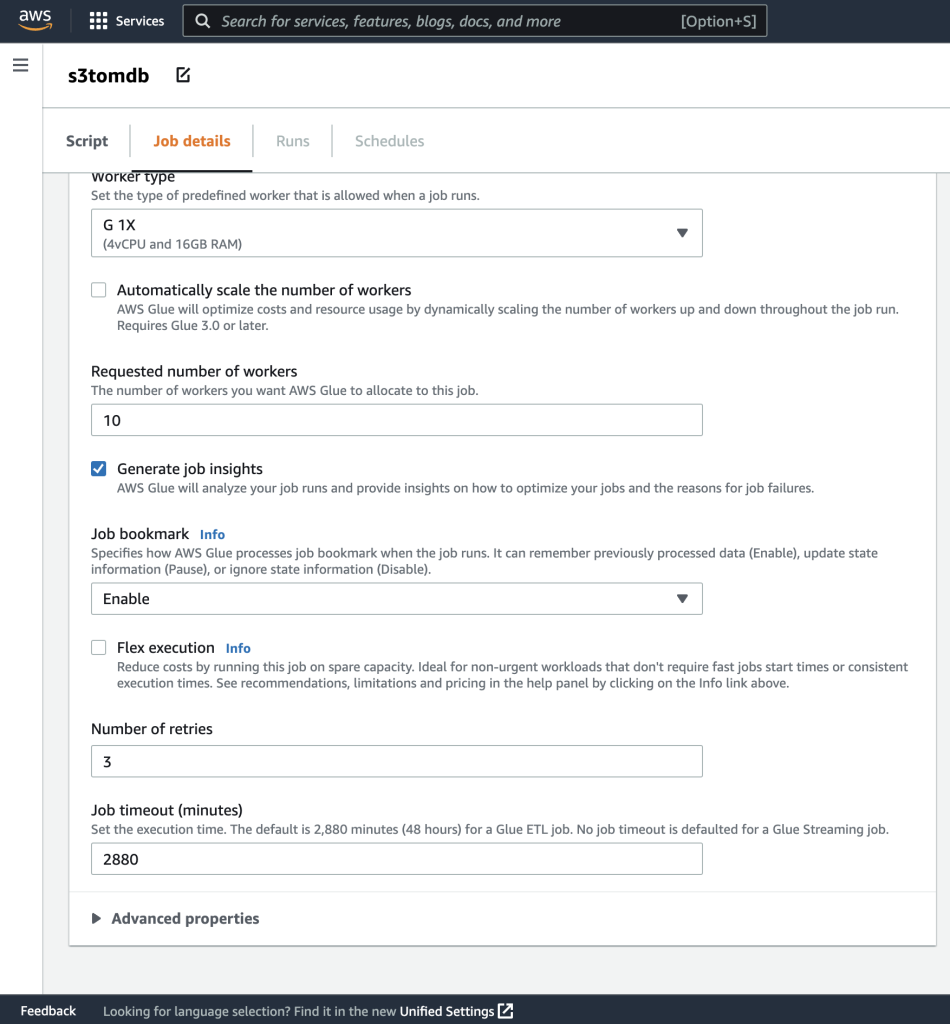
- Successivamente, definisci i parametri del lavoro che lo script utilizza e fornisci i valori predefiniti.
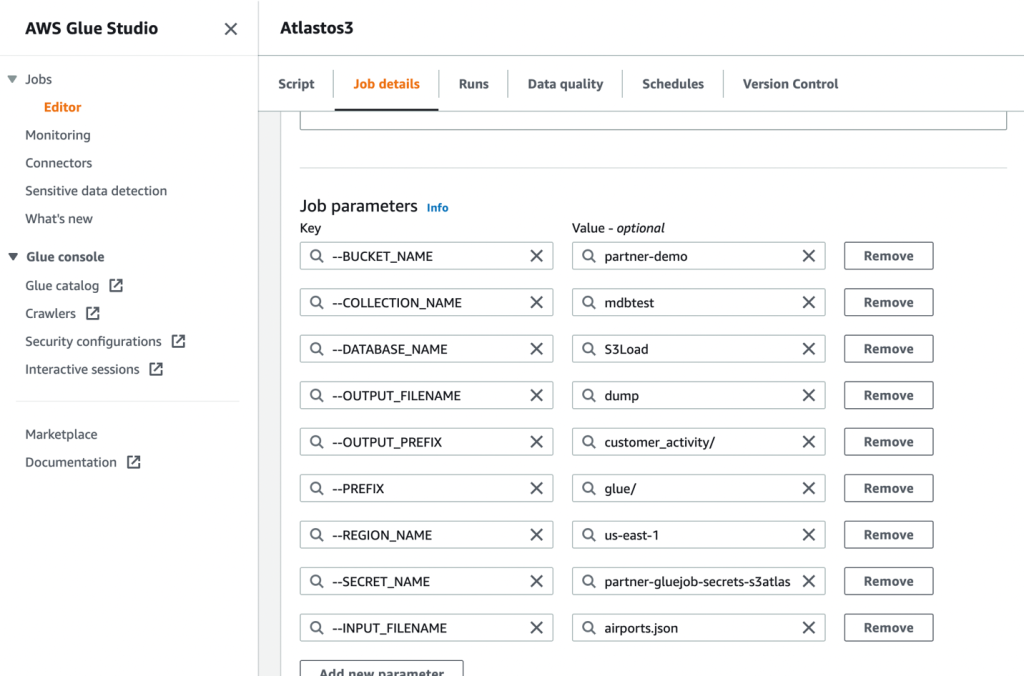
- Salva il lavoro ed eseguilo.
- Per confermare un'esecuzione corretta, osserva il contenuto della raccolta di database MongoDB Atlas se stai caricando i dati o il bucket S3 se stavi eseguendo un'estrazione.



Lo screenshot seguente mostra i risultati di un caricamento dati riuscito da un bucket Amazon S3 nel cluster MongoDB Atlas. I dati sono ora disponibili per le query nell'interfaccia utente di MongoDB Atlas.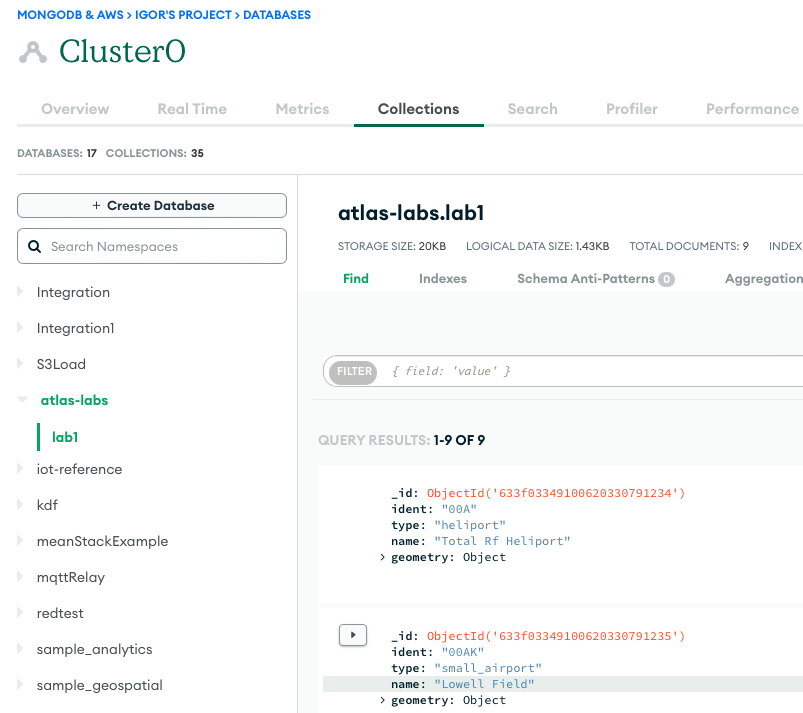
- Per risolvere i problemi relativi alle tue esecuzioni, consulta il file Amazon Cloud Watch logs utilizzando il collegamento su job's Correre scheda.
Lo screenshot seguente mostra che il processo è stato eseguito correttamente, con dettagli aggiuntivi come i collegamenti ai log di CloudWatch.

Conclusione
In questo post, abbiamo descritto come estrarre e inserire i dati in MongoDB Atlas utilizzando AWS Glue.
Con i lavori ETL di AWS Glue, ora possiamo trasferire i dati da MongoDB Atlas a origini compatibili con AWS Glue e viceversa. Puoi anche estendere la soluzione per creare analisi utilizzando i servizi AWS AI e ML.
Per saperne di più, fare riferimento al Repository GitHub per istruzioni dettagliate e codice di esempio. Puoi procurarti Atlante MongoDB su AWS Marketplace.
Informazioni sugli autori

Igor Alekseev è Senior Partner Solution Architect presso AWS nel dominio Dati e analisi. Nel suo ruolo Igor sta lavorando con partner strategici aiutandoli a costruire complesse architetture ottimizzate per AWS. Prima di entrare in AWS, come Data/Solution Architect ha implementato molti progetti nel dominio dei Big Data, inclusi diversi data lake nell'ecosistema Hadoop. In qualità di Data Engineer, è stato coinvolto nell'applicazione di AI/ML al rilevamento delle frodi e all'automazione dell'ufficio.
 Babu Srivasan è Senior Partner Solutions Architect presso MongoDB. Nel suo ruolo attuale, sta lavorando con AWS per creare le integrazioni tecniche e le architetture di riferimento per le soluzioni AWS e MongoDB. Ha più di due decenni di esperienza nelle tecnologie Database e Cloud. È appassionato di fornire soluzioni tecniche ai clienti che lavorano con più Global System Integrator (GSI) in più aree geografiche.
Babu Srivasan è Senior Partner Solutions Architect presso MongoDB. Nel suo ruolo attuale, sta lavorando con AWS per creare le integrazioni tecniche e le architetture di riferimento per le soluzioni AWS e MongoDB. Ha più di due decenni di esperienza nelle tecnologie Database e Cloud. È appassionato di fornire soluzioni tecniche ai clienti che lavorano con più Global System Integrator (GSI) in più aree geografiche.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Coniare il futuro con Adryenn Ashley. Accedi qui.
- Acquista e vendi azioni in società PRE-IPO con PREIPO®. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :ha
- :È
- 100
- 11
- a
- capacità
- Chi siamo
- accesso
- operanti in
- aggiuntivo
- AI
- AI / ML
- anche
- Amazon
- importi
- an
- analitica
- ed
- Applicazioni
- Sviluppo di applicazioni
- applicazioni
- AMMISSIONE
- applicazioni
- architettura
- SONO
- AS
- At
- atlante
- Automazione
- disponibile
- AWS
- Colla AWS
- Mercato AWS
- Backed
- basato
- essendo
- fra
- Big
- Big Data
- costruire
- Costruzione
- affari
- business intelligence
- le prestazioni di business
- aziende
- by
- chiamata
- Materiale
- casi
- Challenge
- cambiando
- Cloud
- Cluster
- codice
- collezione
- combina
- viene
- arrivo
- complesso
- Calcolare
- Configurazione
- Confermare
- consolidamento
- costruire
- testuali
- continua
- Costi
- creare
- creato
- crea
- creazione
- Corrente
- Clienti
- dati
- ingegnere dei dati
- integrazione dei dati
- Lago di dati
- scienza dei dati
- data warehouse
- data-driven
- Banca Dati
- banche dati
- dataset
- decenni
- Predefinito
- dimostrare
- descrivere
- descritta
- dettagli
- rivelazione
- sviluppatori
- Mercato
- differenze
- diverso
- scopri
- disparato
- documenti
- dominio
- guidare
- spinto
- durante
- ecosistema
- editore
- in modo efficiente
- motore
- ingegnere
- Ingegneri
- entrare
- Impresa
- clienti aziendali
- Ambiente
- Etere (ETH)
- eccezione
- esistente
- esperienza
- esplora
- estendere
- estratto
- estrazione
- Faccia
- figura
- Compila il
- File
- Infine
- piatto
- flessibile
- i seguenti
- Nel
- frode
- rilevazione di frodi
- Gratis
- da
- completamente
- funzionalità
- geografie
- globali
- Crescita
- Hadoop
- a portata di mano
- avendo
- he
- aiutare
- qui
- il suo
- Come
- Tutorial
- HTML
- http
- HTTPS
- Enorme
- IAM
- Identità
- if
- realizzare
- implementato
- competenze
- in
- Compreso
- crescente
- ingresso
- istruzioni
- integrare
- integrato
- integrazione
- integrazioni
- Intelligence
- ai miglioramenti
- coinvolgere
- coinvolto
- IT
- SUO
- Lavoro
- Offerte di lavoro
- join
- accoppiamento
- json
- Le
- lago
- grandi
- IMPARARE
- apprendimento
- Lasciare
- Eredità
- piace
- LINK
- Collegamento
- caricare
- Caricamento in corso
- cerca
- macchina
- machine learning
- manutenzione
- FA
- gestito
- gestione
- molti
- mercato
- Maggio..
- migrare
- migrazione
- ML
- Mobile
- modello
- moderno
- modernizzazione
- modernizzare
- MongoDB
- Scopri di più
- cambiano
- movimento
- multiplo
- Nome
- nomi
- Bisogno
- di applicazione
- esigenze
- New
- adesso
- osservare
- of
- Office
- di frequente
- on
- ONE
- operazione
- operativa
- OTTIMIZZA
- Opzione
- or
- minimo
- organizzazioni
- su
- parametri
- partner
- partner
- Passato
- appassionato
- Password
- performance
- esecuzione
- permessi
- posto
- Platone
- Platone Data Intelligence
- PlatoneDati
- Popolare
- Post
- energia
- potente
- Preparare
- preparazione
- prerequisiti
- precedente
- Precedente
- processi
- i processi
- lavorazione
- progetti
- fornisce
- fornitura
- fini
- query
- rapidamente
- tempo reale
- ridurre
- affidabile
- richiedere
- richiede
- Risorse
- REST
- Risultati
- recensioni
- Ruolo
- Correre
- stesso
- scalabile
- Scala
- Scienze
- screenshot
- Cerca
- sicuro
- anziano
- serverless
- serve
- servizio
- Servizi
- alcuni
- mostrato
- Spettacoli
- significativa
- simile
- Un'espansione
- singolo
- soluzione
- Soluzioni
- fonti
- step
- Passi
- conservazione
- Tornare al suo account
- negozi
- lineare
- Strategico
- partner strategici
- snellire
- studio
- avere successo
- il successo
- di successo
- Con successo
- tale
- suite
- fornire
- dati
- sistema
- task
- Consulenza
- Tecnologie
- di
- che
- I
- loro
- Li
- poi
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- migliaia
- tempo
- a
- di oggi
- insieme
- transazionale
- trasferimento
- Trasformare
- trasformazioni
- trasformazione
- TURNO
- seconda
- ui
- sottostante
- uso
- utilizzato
- Utente
- utilizzando
- Valori
- molto
- Visualizza
- volere
- Prima
- we
- sito web
- sono stati
- quando
- se
- quale
- while
- volere
- con
- senza
- flusso di lavoro
- lavoro
- sarebbe
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro