Soluzioni di IA generativa hanno il potenziale per trasformare le aziende aumentando la produttività e migliorando l'esperienza dei clienti, e l'utilizzo di modelli linguistici di grandi dimensioni (LLM) con queste soluzioni è diventato sempre più popolare. Costruire prove di concetto è relativamente semplice perché all'avanguardia modelli di fondazione sono disponibili presso fornitori specializzati attraverso una semplice chiamata API. Pertanto, organizzazioni di varie dimensioni e di diversi settori hanno iniziato a reimmaginare i propri prodotti e processi utilizzando l’intelligenza artificiale generativa.
Nonostante la loro ricchezza di conoscenze generali, i LLM all'avanguardia hanno accesso solo alle informazioni su cui sono stati formati. Ciò può portare a inesattezze fattuali (allucinazioni) quando al LLM viene richiesto di generare testo basato su informazioni che non hanno visto durante la formazione. Pertanto, è fondamentale colmare il divario tra la conoscenza generale del LLM e i dati proprietari per aiutare il modello a generare risposte più accurate e contestuali riducendo al contempo il rischio di allucinazioni. Il metodo tradizionale di messa a punto, sebbene efficace, può essere dispendioso in termini di calcolo, costoso e richiede competenze tecniche. Un'altra opzione da considerare è chiamata Recupero della generazione aumentata (RAG), che fornisce ai LLM informazioni aggiuntive da una fonte di conoscenza esterna che può essere aggiornata facilmente.
Inoltre, le aziende devono garantire la sicurezza dei dati durante la gestione di dati proprietari e sensibili, come dati personali o proprietà intellettuale. Ciò è particolarmente importante per le organizzazioni che operano in settori fortemente regolamentati, come i servizi finanziari, la sanità e le scienze della vita. Pertanto, è importante comprendere e controllare il flusso dei dati attraverso l'applicazione di intelligenza artificiale generativa: dove si trova il modello? Dove vengono trattati i dati? Chi ha accesso ai dati? I dati verranno utilizzati per addestrare modelli, rischiando eventualmente la fuga di dati sensibili verso LLM pubblici?
Questo post illustra come le aziende possono creare applicazioni di intelligenza artificiale generativa accurate, trasparenti e sicure mantenendo il pieno controllo sui dati proprietari. La soluzione proposta è una pipeline RAG che utilizza uno stack tecnologico nativo dell’intelligenza artificiale, i cui componenti sono progettati da zero con l’intelligenza artificiale al centro, anziché avere funzionalità di intelligenza artificiale aggiunte in un secondo momento. Dimostreremo come creare un'applicazione RAG end-to-end utilizzando I modelli linguistici di Cohere attraverso Roccia Amazzonica e Database vettoriale Weaviate su AWS Marketplace. Il codice sorgente allegato è disponibile nel file repository GitHub correlato ospitato da Weaviate. Sebbene AWS non sarà responsabile del mantenimento o dell'aggiornamento del codice nel repository del partner, incoraggiamo i clienti a connettersi direttamente con Weaviate per qualsiasi aggiornamento desiderato.
Panoramica della soluzione
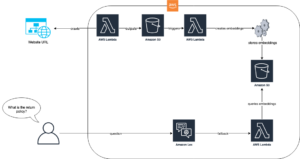
Il seguente diagramma dell'architettura di alto livello illustra la pipeline RAG proposta con uno stack tecnologico nativo di intelligenza artificiale per creare soluzioni di intelligenza artificiale generativa accurate, trasparenti e sicure.
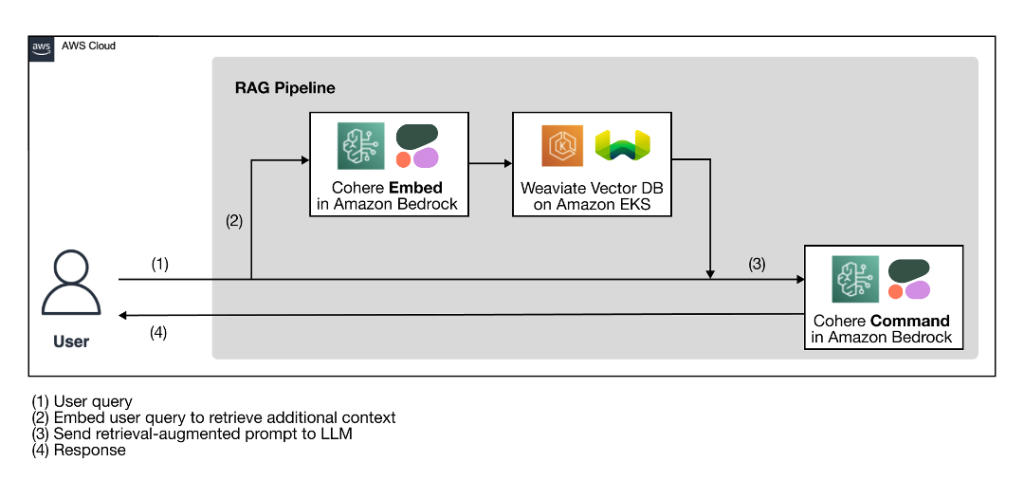
Figura 1: flusso di lavoro RAG che utilizza i modelli linguistici di Cohere tramite Amazon Bedrock e un database vettoriale Weaviate su AWS Marketplace
Come fase di preparazione per il flusso di lavoro RAG, un database vettoriale, che funge da fonte di conoscenza esterna, viene acquisito con il contesto aggiuntivo dai dati proprietari. Il flusso di lavoro RAG effettivo segue i quattro passaggi illustrati nel diagramma:
- L'utente inserisce la propria query.
- La query dell'utente viene utilizzata per recuperare il contesto aggiuntivo pertinente dal database vettoriale. Questo viene fatto generando gli incorporamenti vettoriali della query dell'utente con un modello di incorporamento per eseguire una ricerca vettoriale per recuperare il contesto più rilevante dal database.
- Il contesto recuperato e la query dell'utente vengono utilizzati per ampliare un modello di prompt. Il prompt potenziato per il recupero aiuta il LLM a generare un completamento più pertinente e accurato, riducendo al minimo le allucinazioni.
- L'utente riceve una risposta più accurata in base alla sua query.
Lo stack tecnologico nativo dell'intelligenza artificiale illustrato nel diagramma dell'architettura ha due componenti chiave: modelli di linguaggio Cohere e un database vettoriale Weaviate.
Coerenza dei modelli linguistici in Amazon Bedrock
I Piattaforma Cohere porta modelli linguistici con prestazioni all'avanguardia ad aziende e sviluppatori attraverso una semplice chiamata API. Esistono due tipi chiave di funzionalità di elaborazione del linguaggio fornite dalla piattaforma Cohere (generativa e incorporamento) e ciascuna è servita da un diverso tipo di modello:
- Generazione di testo con Comando – Gli sviluppatori possono accedere agli endpoint che potenziano le capacità di intelligenza artificiale generativa, abilitando applicazioni come la conversazione, la risposta alle domande, il copywriting, il riepilogo, l'estrazione di informazioni e altro ancora.
- Rappresentazione del testo con embed – Gli sviluppatori possono accedere a endpoint che catturano il significato semantico del testo, abilitando applicazioni come motori di ricerca vettoriale, classificazione e clustering del testo e altro ancora. Cohere Embed è disponibile in due forme, un modello in lingua inglese e un modello multilingue, entrambi lo sono ora disponibile su Amazon Bedrock.
La piattaforma Cohere consente alle aziende di personalizzare la propria soluzione di intelligenza artificiale generativa in modo privato e sicuro attraverso la distribuzione di Amazon Bedrock. Amazon Bedrock è un servizio cloud completamente gestito che consente ai team di sviluppo di creare e scalare rapidamente applicazioni di intelligenza artificiale generativa aiutandoti a mantenere i tuoi dati e le tue applicazioni sicuri e privati. I tuoi dati non vengono utilizzati per migliorare il servizio, non vengono mai condivisi con fornitori di modelli di terze parti e rimangono nel file Regione dove viene elaborata la chiamata API. I dati sono sempre crittografati in transito e a riposo e puoi crittografarli utilizzando le tue chiavi. Amazon Bedrock supporta i requisiti di sicurezza, tra cui l'idoneità all'HIPAA (Health Insurance Portability and Accountability Act) degli Stati Uniti e la conformità al Regolamento generale sulla protezione dei dati (GDPR). Inoltre, puoi integrare in modo sicuro e distribuire facilmente le tue applicazioni di intelligenza artificiale generativa utilizzando gli strumenti AWS con cui hai già familiarità.
Database vettoriale Weaviate su AWS Marketplace
tessere offre Nativo dell'intelligenza artificiale banca dati vettoriale ciò rende semplice per i team di sviluppo creare applicazioni di intelligenza artificiale generativa sicure e trasparenti. Weaviate viene utilizzato per archiviare e cercare sia dati vettoriali che oggetti sorgente, il che semplifica lo sviluppo eliminando la necessità di ospitare e integrare database separati. Weaviate offre prestazioni di ricerca semantica inferiori al secondo e può scalare per gestire miliardi di vettori e milioni di tenant. Con un'architettura estensibile unica, Weaviate si integra in modo nativo con i modelli di base Cohere distribuiti in Amazon Bedrock per facilitare la comoda vettorizzazione dei dati e utilizzare le sue capacità generative dall'interno del database.
Il database vettoriale Weaviate AI nativo offre ai clienti la flessibilità di implementarlo come soluzione Bring Your Own Cloud (BYOC) o come servizio gestito. Questa vetrina utilizza il file Weaviate Kubernetes Cluster su AWS Marketplace, parte dell'offerta BYOC di Weaviate, che consente la distribuzione scalabile basata su container all'interno del tenant AWS e del VPC con pochi clic utilizzando un AWS CloudFormazione modello. Questo approccio garantisce che il database vettoriale venga distribuito nella tua regione specifica vicino ai modelli di base e ai dati proprietari per ridurre al minimo la latenza, supportare la località dei dati e proteggere i dati sensibili soddisfacendo al contempo potenziali requisiti normativi, come il GDPR.
Panoramica dei casi d'uso
Nelle sezioni seguenti, dimostriamo come creare una soluzione RAG utilizzando lo stack tecnologico nativo dell'intelligenza artificiale con Cohere, AWS e Weaviate, come illustrato nella panoramica della soluzione.
Il caso d'uso di esempio genera annunci pubblicitari mirati per elenchi di soggiorni per vacanze in base a un pubblico di destinazione. L'obiettivo è utilizzare la query dell'utente per il pubblico di destinazione (ad esempio "famiglia con bambini piccoli") per recuperare l'elenco dei soggiorni di vacanza più pertinente (ad esempio un elenco con parchi giochi nelle vicinanze) e quindi generare un annuncio pubblicitario per il elenco recuperato su misura per il pubblico di destinazione.

Figura 2: prime righe di annunci di soggiorni per vacanze disponibili da Inside Airbnb.
Il set di dati è disponibile da All'interno di Airbnb ed è concesso in licenza con a Licenza internazionale Creative Commons Attribution 4.0. Puoi trovare il codice allegato nel file Repository GitHub.
Prerequisiti
Per seguire e utilizzare i servizi AWS nel tutorial seguente, assicurati di disporre di un file Account AWS.
Abilita i componenti dello stack tecnologico nativo dell'intelligenza artificiale
Innanzitutto, devi abilitare i componenti rilevanti discussi nella panoramica della soluzione nel tuo account AWS. Completa i seguenti passaggi:
- Sulla sinistra Console Amazon Bedrockscegli Accesso al modello nel pannello di navigazione.
- Scegli Gestire l'accesso al modello in alto a destra.
- Seleziona i modelli di fondazione che preferisci e richiedi l'accesso.
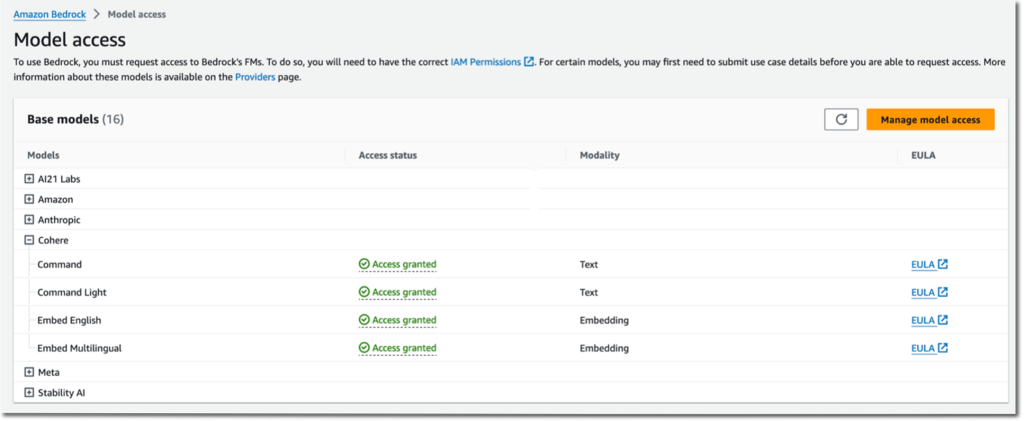
Figura 3: gestione dell'accesso al modello nella console Amazon Bedrock.
Successivamente, configuri un cluster Weaviate.
- Iscriviti alla Weaviate Kubernetes Cluster su AWS Marketplace.
- Avviare il software utilizzando a Modello CloudFormation in base alla zona di disponibilità preferita.
Il modello CloudFormation è precompilato con valori predefiniti.
- Nel Nome dello stack, inserisci un nome di stack.
- Nel tipo di autenticazione del timone, si consiglia di abilitare l'autenticazione impostando
helmauthenticationtypeaapikeye definendo a helmauthenticationapikey. - Nel helmauthenticationapikey, inserisci la tua chiave API Weaviate.
- Nel helmchartversion, inserisci il numero della tua versione. Deve essere almeno v.16.8.0. Fare riferimento al Repository GitHub per l'ultima versione.
- Nel helmenabledmodules, assicurarsi
tex2vec-awsedgenerative-awssono presenti nella lista dei moduli abilitati all'interno di Weaviate.

Figura 4: modello CloudFormation.
Il completamento di questo modello richiede circa 30 minuti.
Connettiti a Weaviate
Completa i seguenti passaggi per connetterti a Weaviate:
- Nel Console di Amazon SageMaker, navigare verso Istanze di notebook nel riquadro di navigazione tramite Taccuino > Istanze di notebook sulla sinistra.
- Crea una nuova istanza del notebook.
- Installa il pacchetto client Weaviate con le dipendenze richieste:
- Connettiti alla tua istanza Weaviate con il seguente codice:
- URL intrecciato – Accedi a Weaviate tramite l'URL del bilanciatore del carico. Nel Cloud di calcolo elastico di Amazon (Amazon EC2), scegli Bilanciatori di carico nel riquadro di navigazione e trova il bilanciatore del carico. Cerca la colonna del nome DNS e aggiungi
http://davanti ad esso. - Chiave API Weaviate – Questa è la chiave impostata in precedenza nel modello CloudFormation (
helmauthenticationapikey). - Chiave di accesso AWS e chiave di accesso segreta – Puoi recuperare la chiave di accesso e la chiave di accesso segreta per il tuo utente nel file Gestione dell'identità e dell'accesso di AWS console (IAM).
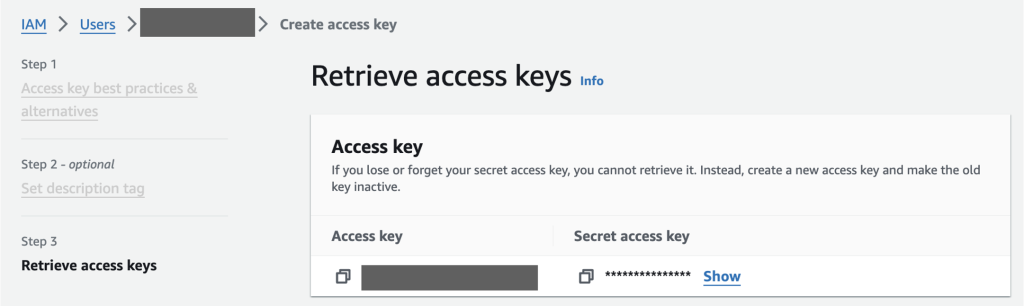
Figura 5: Console AWS Identity and Access Management (IAM) per recuperare la chiave di accesso AWS e la chiave di accesso segreta.
Configura il modulo Amazon Bedrock per abilitare i modelli Cohere
Successivamente, definisci una raccolta dati (class) chiamato Listings per memorizzare gli oggetti dati degli elenchi, il che è analogo alla creazione di una tabella in un database relazionale. In questa fase, configurerai i moduli rilevanti per abilitare l'utilizzo dei modelli linguistici Cohere ospitati su Amazon Bedrock in modo nativo dal database vettoriale Weaviate. Il vettorizzatore (“text2vec-aws“) e modulo generativo (“generative-aws“) sono specificati nella definizione della raccolta dati. Entrambi questi moduli accettano tre parametri:
- "servizio" - Uso "
bedrock" per Amazon Bedrock (in alternativa, utilizzare "sagemaker"Per JumpStart di Amazon SageMaker) - "Regione" – Inserisci la regione in cui viene distribuito il tuo modello
- "modello" – Fornire il nome del modello di fondazione
Vedi il seguente codice:
Inserisci i dati nel database vettoriale Weaviate
In questo passaggio definisci la struttura della raccolta dati configurandone le proprietà. Oltre al nome della proprietà e al tipo di dati, puoi anche configurare se verrà archiviato solo l'oggetto dati o se verrà archiviato insieme ai suoi incorporamenti vettoriali. In questo esempio, host_name ed property_type non sono vettorizzati:
Esegui il codice seguente per creare la raccolta nella tua istanza Weaviate:
Ora puoi aggiungere oggetti a Weaviate. Utilizzi un processo di importazione batch per la massima efficienza. Eseguire il codice seguente per importare i dati. Durante l'importazione, Weaviate utilizzerà il vettorizzatore definito per creare un incorporamento vettoriale per ciascun oggetto. Il codice seguente carica gli oggetti, inizializza un processo batch e aggiunge gli oggetti alla raccolta di destinazione uno per uno:
Recupero generazione aumentata
Puoi creare una pipeline RAG implementando una query di ricerca generativa sulla tua istanza Weaviate. Per questo, definisci prima un modello di prompt sotto forma di una stringa f che può accettare la query dell'utente ({target_audience}) direttamente e il contesto aggiuntivo ({{host_name}}, {{property_type}}, {{description}}e {{neighborhood_overview}}) dal database vettoriale in fase di esecuzione:
Successivamente, esegui una query di ricerca generativa. Ciò richiede il modello generativo definito con un prompt che comprende la query dell'utente e i dati recuperati. La query seguente recupera un oggetto elenco (.with_limit(1)) dal Listings raccolta più simile alla query dell'utente (.with_near_text({"concepts": target_audience})). Quindi la query dell'utente (target_audience) e le proprietà degli elenchi recuperati (["description", "neighborhood", "host_name", "property_type"]) vengono inseriti nel modello di prompt. Vedere il seguente codice:
Nell'esempio seguente, puoi vedere che la parte di codice precedente for target_audience = “Family with small children” recupera un elenco dall'host Marre. Il modello di richiesta viene arricchito con i dettagli dell'inserzione di Marre e il pubblico di destinazione:
Sulla base del prompt potenziato per il recupero, il modello Command di Cohere genera il seguente annuncio pubblicitario mirato:
Personalizzazioni alternative
È possibile effettuare personalizzazioni alternative ai diversi componenti della soluzione proposta, come le seguenti:
- I modelli linguistici di Cohere sono disponibili anche tramite JumpStart di Amazon SageMaker, che fornisce l'accesso a modelli di base all'avanguardia e consente agli sviluppatori di distribuire LLM Amazon Sage Maker, un servizio completamente gestito che riunisce un'ampia gamma di strumenti per consentire il machine learning ad alte prestazioni e a basso costo per qualsiasi caso d'uso. Weaviate è integrato anche con SageMaker.
- Una potente aggiunta a questa soluzione è Endpoint di riclassificazione coerente, disponibile tramite SageMaker JumpStart. La riclassificazione può migliorare la pertinenza dei risultati della ricerca lessicale o semantica. La riclassificazione funziona calcolando i punteggi di rilevanza semantica per i documenti recuperati da un sistema di ricerca e classificando i documenti in base a questi punteggi. L'aggiunta di Rerank a un'applicazione richiede solo una singola riga di modifica del codice.
- Per soddisfare le diverse esigenze di distribuzione dei diversi ambienti di produzione, Weaviate può essere distribuito in vari modi aggiuntivi. Ad esempio, è disponibile come download diretto da Sito Web di Weaviate, che continua Servizio Amazon Elastic Kubernetes (Amazon EKS) o localmente tramite docker or kubernetes. È anche disponibile come file servizio gestito che può essere eseguito in modo sicuro all'interno di un VPC o come servizio cloud pubblico ospitato su AWS con una prova gratuita di 14 giorni.
- Puoi servire la tua soluzione in un VPC utilizzando Cloud privato virtuale di Amazon (Amazon VPC), che consente alle organizzazioni di lanciare servizi AWS in una rete virtuale isolata logicamente, simile a una rete tradizionale ma con i vantaggi dell'infrastruttura scalabile di AWS. A seconda del livello classificato di sensibilità dei dati, le organizzazioni possono anche disabilitare l'accesso a Internet in questi VPC.
ripulire
Per evitare addebiti imprevisti, elimina tutte le risorse distribuite come parte di questo post. Se hai avviato lo stack CloudFormation, puoi eliminarlo tramite la console AWS CloudFormation. Tieni presente che potrebbero esserci alcune risorse AWS, come Negozio di blocchi elastici di Amazon (Amazon EBS) volumi e Servizio di gestione delle chiavi AWS (AWS KMS), che potrebbero non essere eliminate automaticamente quando lo stack CloudFormation viene eliminato.

Figura 6: Elimina tutte le risorse tramite la console AWS CloudFormation.
Conclusione
Questo post ha discusso di come le aziende possono creare applicazioni di intelligenza artificiale generativa accurate, trasparenti e sicure pur mantenendo il pieno controllo sui propri dati. La soluzione proposta è una pipeline RAG che utilizza uno stack tecnologico nativo di intelligenza artificiale come combinazione di modelli di base Cohere in Amazon Bedrock e un database vettoriale Weaviate su AWS Marketplace. L'approccio RAG consente alle aziende di colmare il divario tra la conoscenza generale del LLM e i dati proprietari riducendo al minimo le allucinazioni. Uno stack tecnologico nativo dell'intelligenza artificiale consente uno sviluppo rapido e prestazioni scalabili.
Puoi iniziare a sperimentare le prove di concetto RAG per le tue applicazioni di intelligenza artificiale generativa pronte per l'azienda utilizzando i passaggi descritti in questo post. Il codice sorgente allegato è disponibile nel file repository GitHub correlato. Grazie per aver letto. Sentiti libero di fornire commenti o feedback nella sezione commenti.
Circa gli autori
 Giacomo Yi è un Senior AI/ML Partner Solutions Architect nel team Technology Partners COE Tech presso Amazon Web Services. La sua passione è lavorare con clienti e partner aziendali per progettare, distribuire e scalare applicazioni AI/ML per ricavare valore aziendale. Al di fuori del lavoro, gli piace giocare a calcio, viaggiare e passare il tempo con la sua famiglia.
Giacomo Yi è un Senior AI/ML Partner Solutions Architect nel team Technology Partners COE Tech presso Amazon Web Services. La sua passione è lavorare con clienti e partner aziendali per progettare, distribuire e scalare applicazioni AI/ML per ricavare valore aziendale. Al di fuori del lavoro, gli piace giocare a calcio, viaggiare e passare il tempo con la sua famiglia.
 Leonie Monigatti è un sostenitore degli sviluppatori presso Weaviate. La sua area di interesse è l'intelligenza artificiale/ML e aiuta gli sviluppatori a conoscere l'intelligenza artificiale generativa. Al di fuori del lavoro, condivide anche le sue conoscenze in scienza dei dati e machine learning sul suo blog e su Kaggle.
Leonie Monigatti è un sostenitore degli sviluppatori presso Weaviate. La sua area di interesse è l'intelligenza artificiale/ML e aiuta gli sviluppatori a conoscere l'intelligenza artificiale generativa. Al di fuori del lavoro, condivide anche le sue conoscenze in scienza dei dati e machine learning sul suo blog e su Kaggle.
 Mio Amer è un sostenitore degli sviluppatori presso Cohere, un fornitore di tecnologia all'avanguardia per l'elaborazione del linguaggio naturale (NLP). Aiuta gli sviluppatori a creare applicazioni all'avanguardia con i Large Language Models (LLM) di Cohere.
Mio Amer è un sostenitore degli sviluppatori presso Cohere, un fornitore di tecnologia all'avanguardia per l'elaborazione del linguaggio naturale (NLP). Aiuta gli sviluppatori a creare applicazioni all'avanguardia con i Large Language Models (LLM) di Cohere.
 Shun Mao è un Senior AI/ML Partner Solutions Architect nel team Emerging Technologies di Amazon Web Services. La sua passione è lavorare con clienti e partner aziendali per progettare, distribuire e scalare applicazioni AI/ML per ricavarne i valori aziendali. Fuori dal lavoro gli piace pescare, viaggiare e giocare a ping-pong.
Shun Mao è un Senior AI/ML Partner Solutions Architect nel team Emerging Technologies di Amazon Web Services. La sua passione è lavorare con clienti e partner aziendali per progettare, distribuire e scalare applicazioni AI/ML per ricavarne i valori aziendali. Fuori dal lavoro gli piace pescare, viaggiare e giocare a ping-pong.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-enterprise-ready-generative-ai-solutions-with-cohere-foundation-models-in-amazon-bedrock-and-weaviate-vector-database-on-aws-marketplace/
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 10
- 100
- 11
- 12
- 13
- 16
- 17
- 19
- 23
- 30
- 32
- 33
- 7
- 8
- 9
- a
- Chi siamo
- accesso
- gestione degli accessi
- Secondo
- Il mio account
- responsabilità
- preciso
- operanti in
- Legge
- presenti
- aggiungere
- aggiunto
- l'aggiunta di
- aggiunta
- aggiuntivo
- Informazioni aggiuntive
- Inoltre
- indirizzamento
- Aggiunge
- adulti
- pubblicità
- avvocato
- AI
- AI / ML
- Airbnb
- Tutti
- consente
- lungo
- già
- anche
- alternativa
- Sebbene il
- sempre
- Amazon
- Amazon EC2
- Amazon Sage Maker
- Amazon Web Services
- amsterdam
- an
- ed
- Un altro
- rispondere
- in qualsiasi
- api
- Applicazioni
- applicazioni
- approccio
- architettura
- SONO
- RISERVATA
- aree
- AS
- a parte
- At
- attrazioni
- pubblico
- aumentare
- aumentata
- Autenticazione
- automaticamente
- disponibilità
- disponibile
- lontano
- AWS
- AWS CloudFormazione
- AWS Identity and Access Management (IAM)
- Mercato AWS
- equilibratore
- bar
- basato
- BE
- perché
- diventare
- iniziato
- vantaggi
- MIGLIORE
- fra
- miliardi
- Bloccare
- Blog
- potenziamento
- entrambi
- BRIDGE
- Porta
- ampio
- costruire
- Costruzione
- affari
- aziende
- ma
- by
- caffè
- chiamata
- detto
- Materiale
- funzionalità
- catturare
- Custodie
- approvvigionare
- centrale
- centro
- il cambiamento
- oneri
- Bambini
- scegliere
- Scegli
- Città
- classe
- classificazione
- classificato
- cliente
- Chiudi
- Cloud
- Cluster
- il clustering
- codice
- collezione
- Colonna
- combinazione
- Venire
- viene
- Commenti
- Popolo
- completamento di una
- completamento
- conformità
- componenti
- Compreso
- Calcolare
- informatica
- concetto
- concetti
- configurazione
- Connettiti
- Prendere in considerazione
- consolle
- contesto
- contestuale
- di controllo
- Comodo
- opportunamente
- discorsivo
- copy professionale
- Nucleo
- creare
- Creazione
- cruciale
- cliente
- Clienti
- personalizzare
- bordo tagliente
- dati
- protezione dati
- scienza dei dati
- la sicurezza dei dati
- Banca Dati
- banche dati
- Predefinito
- definire
- definito
- definizione
- definizione
- fornisce un monitoraggio
- dimostrare
- dipendenze
- Dipendente
- schierare
- schierato
- deployment
- derivare
- descrizione
- Design
- progettato
- desiderato
- dettagli
- Costruttori
- sviluppatori
- Mercato
- team di sviluppo
- diverso
- cenare
- dirette
- direttamente
- discusso
- dns
- documenti
- fatto
- scaricare
- durante
- ogni
- In precedenza
- facilmente
- ebs
- Efficace
- efficienza
- elevata
- eleggibilità
- eliminando
- incastrare
- incorporamento
- emergenti del mondo
- tecnologie emergenti
- Potenzia
- enable
- abilitato
- Abilita
- consentendo
- incoraggiare
- crittografato
- da un capo all'altro
- endpoint
- Motori
- Inglese
- garantire
- assicura
- entrare
- Impresa
- clienti aziendali
- aziende
- entra
- Intero
- ambienti
- Etere (ETH)
- alla fine
- esempio
- costoso
- esperienza
- Esperienze
- competenza
- esterno
- estrazione
- facilitare
- Factual
- familiare
- famiglia
- FAST
- Caratteristiche
- Grazie
- Federale
- feedback
- sentire
- pochi
- Compila il
- finanziario
- servizi finanziari
- Trovare
- Nome
- Pesca
- Flessibilità
- Pavimento
- flusso
- Focus
- seguire
- i seguenti
- segue
- Nel
- modulo
- forme
- Fondazione
- quattro
- Gratis
- prova gratuita
- da
- anteriore
- pieno
- completamente
- ulteriormente
- divario
- GDPR
- Generale
- dati generali
- Regolamento generale sulla protezione dei dati
- generare
- genera
- la generazione di
- ELETTRICA
- generativo
- AI generativa
- modello generativo
- GitHub
- dà
- scopo
- Terra
- Gruppo
- Metà
- maniglia
- Manovrabilità
- Avere
- avendo
- he
- Titolo
- Salute e benessere
- assicurazione sanitaria
- assistenza sanitaria
- Cuore
- pesantemente
- Aiuto
- aiutare
- aiuta
- suo
- alto livello
- Alte prestazioni
- il suo
- Casa
- host
- ospitato
- Come
- Tutorial
- http
- HTTPS
- IAM
- Identità
- identità e gestione degli accessi
- Gestione dell'identità e degli accessi (IAM)
- if
- illustra
- Implementazione
- importare
- importante
- competenze
- miglioramenti
- miglioramento
- in
- Compreso
- sempre più
- industrie
- informazioni
- estrazione di informazioni
- Infrastruttura
- interno
- install
- esempio
- assicurazione
- integrare
- integrato
- Integra
- intellettuale
- proprietà intellettuale
- Internazionale
- Internet
- accesso ad Internet
- ai miglioramenti
- isolato
- IT
- SUO
- jpg
- ad appena
- mantenere
- conservazione
- Le
- Tasti
- bambini
- conoscenze
- kubernetes
- Lingua
- grandi
- Latenza
- con i più recenti
- lanciare
- lanciato
- portare
- Leads
- perdita
- IMPARARE
- apprendimento
- meno
- a sinistra
- Livello
- Autorizzato
- Vita
- Life Sciences
- linea
- Lista
- annuncio
- Annunci
- vita
- caricare
- carichi
- locale
- a livello locale
- collocato
- località
- Guarda
- cerca
- a basso costo
- macchina
- machine learning
- mantenimento
- make
- FA
- gestire
- gestito
- gestione
- mercato
- Mastercard
- massimo
- Maggio..
- significato
- si intende
- memorie
- metodo
- milioni
- ridurre al minimo
- minimizzando
- verbale
- ML
- modello
- modelli
- modulo
- moduli
- Scopri di più
- maggior parte
- devono obbligatoriamente:
- Nome
- nativamente
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- Navigare
- Navigazione
- Bisogno
- Rete
- mai
- New
- nlp
- no
- Nota
- taccuino
- adesso
- numero
- oggetto
- oggetti
- of
- offrire
- offerta
- on
- ONE
- esclusivamente
- operativo
- Opzione
- or
- organizzazioni
- Altro
- nostro
- delineato
- al di fuori
- ancora
- panoramica
- proprio
- pacchetto
- pagato
- panda
- vetro
- parametri
- parcheggio
- parte
- particolarmente
- partner
- partner
- appassionato
- perfetta
- eseguire
- performance
- cronologia
- dati personali
- pezzo
- conduttura
- posto
- piattaforma
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioco
- Popolare
- portabilità
- Post
- potenziale
- energia
- potente
- precedente
- preferito
- preparazione
- presenti
- prevenire
- un bagno
- processi
- elaborati
- i processi
- lavorazione
- Produzione
- della produttività
- Prodotti
- istruzioni
- prove
- proprietà
- proprietà
- proposto
- proprio
- protegge
- protezione
- fornire
- fornitore
- fornitori
- fornisce
- la percezione
- cloud pubblico
- domanda
- rapidamente
- straccio
- Posizione
- piuttosto
- RE
- Leggi
- Lettura
- riceve
- raccomandato
- riducendo
- riferimento
- per quanto riguarda
- regione
- regolamentati
- industrie regolamentate
- Regolamento
- normativo
- relativamente
- rilevanza
- pertinente
- resti
- deposito
- richiesta
- necessario
- Requisiti
- richiede
- simile
- Risorse
- risposta
- risposte
- responsabile
- REST
- Ristoranti
- colpevole
- Risultati
- destra
- Rischio
- rischiando
- Prenotazione sale
- RIGA
- Correre
- corre
- s
- sagemaker
- scalabile
- Scala
- Scienze
- SCIENZE
- punteggi
- Cerca
- Motori di ricerca
- Segreto
- Sezione
- sezioni
- sicuro
- in modo sicuro
- problemi di
- vedere
- semantico
- anziano
- delicata
- Sensibilità
- separato
- servire
- servito
- serve
- servizio
- Servizi
- set
- regolazione
- condiviso
- azioni
- lei
- Corti
- vetrina
- simile
- Un'espansione
- semplifica
- singolo
- Dimensioni
- piccole
- Calcio
- Software
- soluzione
- Soluzioni
- alcuni
- Fonte
- codice sorgente
- lo spazio
- specializzata
- specifico
- specificato
- Spendere
- pila
- inizia a
- state-of-the-art
- soggiorno
- step
- Passi
- Ancora
- Tornare al suo account
- memorizzati
- lineare
- La struttura
- tale
- adatto
- supporto
- supporti
- sicuro
- sistema
- tavolo
- su misura
- Fai
- prende
- Target
- mirata
- team
- le squadre
- Tech
- Consulenza
- Tecnologie
- Tecnologia
- modello
- inquilino
- testo
- Classificazione del testo
- di
- ringraziare
- che
- I
- le informazioni
- loro
- poi
- Là.
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- di parti terze standard
- questo
- tre
- Attraverso
- tempo
- a
- insieme
- strumenti
- top
- tradizionale
- Treni
- allenato
- Training
- Trasformare
- transito
- trasparente
- Di viaggio
- prova
- lezione
- seconda
- Digitare
- Tipi di
- noi
- per
- capire
- Inaspettato
- su misura!
- univocamente
- aggiornato
- Aggiornamenti
- aggiornamento
- di sopra
- URL
- Impiego
- uso
- caso d'uso
- utilizzato
- Utente
- usa
- utilizzando
- vacanza
- APPREZZIAMO
- Valori
- vario
- Ve
- versione
- via
- virtuale
- volumi
- camminare
- Modo..
- modi
- we
- Ricchezza
- sito web
- servizi web
- il benvenuto
- WELL
- sono stati
- quando
- quale
- while
- OMS
- di chi
- volere
- con
- entro
- Lavora
- flusso di lavoro
- lavoro
- lavori
- scrivere
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro