Benvenuti nell'era dei dati. L’enorme volume di dati acquisiti quotidianamente continua a crescere, richiedendo l’evoluzione di piattaforme e soluzioni. Servizi come Servizio di archiviazione semplice Amazon (Amazon S3) offrono una soluzione scalabile che si adatta ma rimane conveniente per set di dati in crescita. IL Iniziativa sui dati di sostenibilità di Amazon (ASDI) utilizza le funzionalità di Amazon S3 per fornire una soluzione gratuita per archiviare e condividere carichi di lavoro di scienze climatiche in tutto il mondo. Il programma di sponsorizzazione Open Data di Amazon consente alle organizzazioni di ospitare gratuitamente su AWS.
Nell'ultimo decennio, abbiamo assistito a un'impennata dei framework di data science che si sono concretizzati, insieme all'adozione di massa da parte della comunità della data science. Uno di questi è dask, che è potente per la sua capacità di fornire un'orchestrazione di nodi di calcolo di lavoro, accelerando così analisi complesse su set di dati di grandi dimensioni.
In questo post ti mostriamo come distribuire un file custom Kit di sviluppo cloud AWS (AWS CDK) che estende le funzionalità di Dask per funzionare a livello interregionale attraverso la rete globale di Amazon. La soluzione AWS CDK distribuisce una rete di lavoratori Dask su due regioni AWS, connettendosi a una regione client. Per ulteriori informazioni, fare riferimento a Linee guida per l'elaborazione distribuita con Dask interregionale su AWS e la Repository GitHub per il codice open source.
Dopo la distribuzione, l'utente avrà accesso a un notebook Jupyter, dove potrà interagire con due set di dati da ASDI su AWS: Progetto di intercomparazione dei modelli accoppiati 6 (CMIP6) ed Rianalisi ERA5 dell'ECMWF. Il CMIP6 si concentra sulla sesta fase dell’insieme del modello di circolazione generale accoppiato globale oceano-atmosfera; ERA5 è la quinta generazione di rianalisi atmosferiche dell’ECMWF del clima globale e la prima rianalisi prodotta come servizio operativo.
Questa soluzione è stata ispirata dal lavoro con un cliente chiave di AWS, the Ufficio UK Met. Il Met Office è stato fondato nel 1854 ed è il servizio meteorologico nazionale del Regno Unito. Forniscono previsioni meteorologiche e climatiche per aiutarti a prendere decisioni migliori per rimanere al sicuro e prosperare. Una collaborazione tra il Met Office e EUMETSAT, dettagliata in Calcolo approssimativo dei dati su un cluster Dask distribuito tra data center, evidenzia la crescente necessità di sviluppare una soluzione di data science sostenibile, efficiente e scalabile. Questa soluzione raggiunge questo obiettivo avvicinando l'elaborazione ai dati, anziché forzare i dati ad avvicinarsi alle risorse di elaborazione, il che aggiunge costi, latenza ed energia.
Panoramica della soluzione
Ogni giorno, il Met Office del Regno Unito produce fino a 300 TB di dati meteorologici e climatici, una parte dei quali viene pubblicata su ASDI. Questi set di dati sono distribuiti in tutto il mondo e ospitati per uso pubblico. Il Met Office vorrebbe consentire ai consumatori di sfruttare al meglio i propri dati per contribuire a prendere decisioni cruciali su come affrontare questioni come una migliore preparazione agli incendi e alle inondazioni indotti dai cambiamenti climatici e la riduzione dell’insicurezza alimentare attraverso una migliore analisi della resa dei raccolti.
Le soluzioni tradizionali in uso oggi, in particolare con i dati climatici, sono dispendiose in termini di tempo e sono insostenibili, poiché replicano i set di dati tra le regioni. Il trasferimento di dati non necessario su scala di petabyte è costoso, lento e consuma energia.
Abbiamo stimato che se questa pratica fosse adottata dagli utenti del Met Office, si potrebbe risparmiare ogni giorno l’equivalente del consumo energetico giornaliero di 40 case e si potrebbe anche ridurre il trasferimento di dati tra regioni.
Il diagramma seguente illustra l'architettura della soluzione.
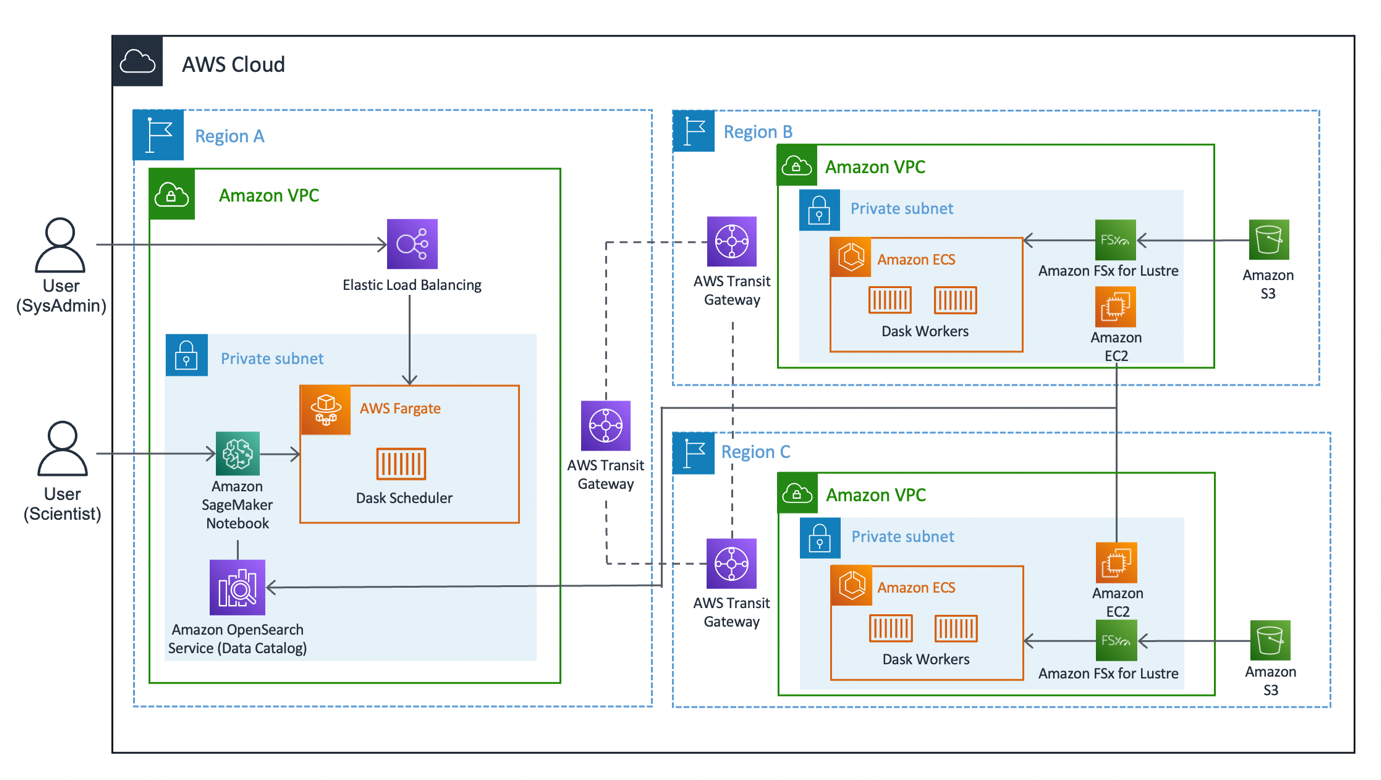
La soluzione può essere suddivisa in tre segmenti principali: cliente, lavoratori e rete. Immergiamoci in ciascuno e vediamo come si uniscono.
.
Il client rappresenta la regione di origine a cui si connettono i data scientist. Questa regione (regione A nel diagramma) contiene un Notebook Amazon SageMaker, una Servizio Amazon OpenSearch dominio e a Programmatore di sera come componenti chiave. Gli amministratori di sistema hanno accesso alla dashboard Dash integrata esposta tramite un file Bilanciamento del carico elastico.
I data scientist hanno accesso al notebook Jupyter ospitato su SageMaker. Il notebook è in grado di connettersi ed eseguire carichi di lavoro sullo scheduler Dask. Il dominio del servizio OpenSearch memorizza i metadati sui set di dati collegati alle regioni. Gli utenti di notebook possono interrogare questo servizio per recuperare dettagli come la corretta regione dei lavoratori Dask senza dover conoscere in anticipo la posizione regionale dei dati.
Lavoratore
Ciascuna delle regioni lavoratrici (regioni B e C nel diagramma) è composta da un Servizio di container elastici Amazon (Amazon ECS) cluster di Lavoratori notturni, una Amazon FSx per Lustre file system e un file system autonomo Cloud di calcolo elastico di Amazon (Amazon EC2). FSx for Lustre consente ai lavoratori Dask di accedere ed elaborare i dati Amazon S3 da un file system ad alte prestazioni collegando i tuoi file system ai bucket S3. Fornisce latenze inferiori al millisecondo, fino a centinaia di GB/s di throughput e milioni di IOPS. Una caratteristica fondamentale di Lustre è che vengono sincronizzati solo i metadati del file system. Lustre gestisce il saldo dei file da caricare e mantenere caldi, in base alla richiesta.
I cluster di lavoratori si ridimensionano in base all'utilizzo della CPU, forniscono lavoratori aggiuntivi in periodi prolungati di domanda e si ridimensionano quando le risorse diventano inattive.
Ogni notte alle 0:00 UTC, un processo di sincronizzazione dei dati richiede al file system Lustre di risincronizzarsi con il bucket S3 collegato ed estrae un catalogo di metadati aggiornato del bucket. Successivamente, l'istanza EC2 autonoma inserisce questi aggiornamenti nel servizio OpenSearch rispettivo all'indice di quella regione. Il servizio OpenSearch fornisce le informazioni necessarie al cliente su quale pool di lavoratori dovrebbe essere chiamato per un particolare set di dati.
Network NetPoulSafe
La rete costituisce il punto cruciale di questa soluzione, utilizzando la rete dorsale interna di Amazon. Usando Gateway di transito AWS, siamo in grado di connettere ciascuna delle Regioni tra loro senza la necessità di attraversare la rete Internet pubblica. Ciascuno dei lavoratori è in grado di connettersi dinamicamente allo scheduler di Dask, consentendo ai data scientist di eseguire query interregionali tramite Dask.
Prerequisiti
Il pacchetto AWS CDK utilizza il linguaggio di programmazione TypeScript. Segui i passaggi indicati in Nozioni di base su AWS CDK per configurare il tuo ambiente locale ed eseguire il bootstrap del tuo account di sviluppo (dovrai eseguire il bootstrap di tutte le regioni specificate nel file Repository GitHub).
Per una distribuzione di successo, avrai bisogno di Docker installato e in esecuzione sul tuo computer locale.
Distribuisci il pacchetto AWS CDK
La distribuzione di un pacchetto AWS CDK è semplice. Dopo aver installato i prerequisiti e aver avviato il tuo account, puoi procedere con il download della codebase.
- Scarica la Repository GitHub:
- Installa i moduli del nodo:
- Distribuisci il CDK AWS:
La distribuzione dello stack può richiedere più di un'ora e mezza.
Procedura dettagliata del codice
In questa sezione esaminiamo alcune delle caratteristiche principali del codice base. Se desideri esaminare la base di codice completa, fai riferimento a Repository GitHub.
Configura e personalizza il tuo stack
Nel file bin/variabili.ts, troverai due dichiarazioni di variabile: una per il cliente e una per i lavoratori. La dichiarazione client è un dizionario con un riferimento a una regione e a un intervallo CIDR. La personalizzazione di queste variabili modificherà sia la regione che l'intervallo CIDR in cui verranno distribuite le risorse client.
La variabile lavoratore copia questa stessa funzionalità; tuttavia, è un elenco di dizionari per consentire l'aggiunta o la sottrazione di set di dati che l'utente desidera includere. Inoltre, ogni dizionario contiene i campi aggiunti di dataset ed lustreFileSystemPath. Il set di dati viene utilizzato per specificare l'URI S3 di connessione a cui Lustre può connettersi. IL lustreFileSystemPath La variabile viene utilizzata come mappatura per il modo in cui l'utente desidera che il set di dati venga mappato localmente sul file system di lavoro. Vedere il seguente codice:
Pubblica dinamicamente l'IP dello scheduler
Una sfida inerente alla natura interregionale di questo progetto è stata il mantenimento di una connessione dinamica tra i lavoratori di Dask e lo scheduler. Come potremmo pubblicare un indirizzo IP, che può cambiare, nelle regioni AWS? Siamo stati in grado di raggiungere questo obiettivo attraverso l'uso di Mappa del cloud AWS ed associare-vpc-con-zona-ospitata. Il servizio consente ad AWS di gestire questo spazio dei nomi DNS in privato. Vedere il seguente codice:
Interfaccia utente del taccuino Jupyter
Il notebook Jupyter ospitato su SageMaker fornisce agli scienziati un ambiente già pronto per la distribuzione per connettersi e sperimentare facilmente sui set di dati caricati. Abbiamo usato a script di configurazione del ciclo di vita per fornire al notebook un ambiente di sviluppo preconfigurato e una codebase di esempio. Vedere il seguente codice:
Nodi di lavoro Dask
Per quanto riguarda i Dask Worker, viene fornita una maggiore personalizzazione, più specificamente sul tipo di istanza, sui thread per contenitore e sugli allarmi di ridimensionamento. Per impostazione predefinita, i nodi di lavoro effettuano il provisioning sull'istanza di tipo m5d.4xlarge, vengono montati sul file system Lustre all'avvio e suddividono dinamicamente i relativi nodi di lavoro e thread in porte. Tutto questo è facoltativamente personalizzabile. Vedere il seguente codice:
Prestazione
Per valutare le prestazioni, utilizziamo un calcolo campione e un grafico della temperatura dell'aria a 2 metri in base alla differenza tra la previsione CMIP6 per un mese e la temperatura media dell'aria ERA5 per 10 anni. Abbiamo fissato un punto di riferimento di due lavoratori in ciascuna regione e valutiamo la differenza nella riduzione del tempo man mano che venivano aggiunti ulteriori lavoratori. In teoria, man mano che la soluzione si espande, dovrebbe esserci una differenza materiale produttiva nella riduzione del tempo complessivo.
La tabella seguente riassume i dettagli del nostro set di dati.
| dataset | Variabili | Dimensione del disco | Dimensioni del set di dati Xarray | Regione |
| ERA5 | 2011-2020 (120 file netcdf) | 53.5GB | 364.1 GB | us-est-1 |
| CMIP6 | 1.13GB | 0.11 GB | noi-ovest-2 |
La tabella seguente mostra i risultati raccolti, mostrando il tempo (in secondi) per ciascun calcolo e previsione in tre fasi nel calcolo della previsione CMIP6, ERA5 e della differenza.
| . | . | Numero di lavoratori | |||
| Calcolare | Regione | 2(CMIP) + 2(ERA) | 2(CMIP) + 4(ERA) | 2(CMIP) + 8(ERA) |
2(CMIP) + 12(ERA) |
CMIP6 (predicted_tas_regridded) |
noi-ovest-2 | 11.8 | 11.5 | 11.2 | 11.6 |
ERA5 (historic_temp_regridded) |
us-est-1 | 1512 | 711 | 427 | 202 |
Differenza (propogated pool) |
us-west-2 e us-east-1 | 1527 | 906 | 469 | 251 |
Il grafico seguente visualizza le prestazioni e la scala.
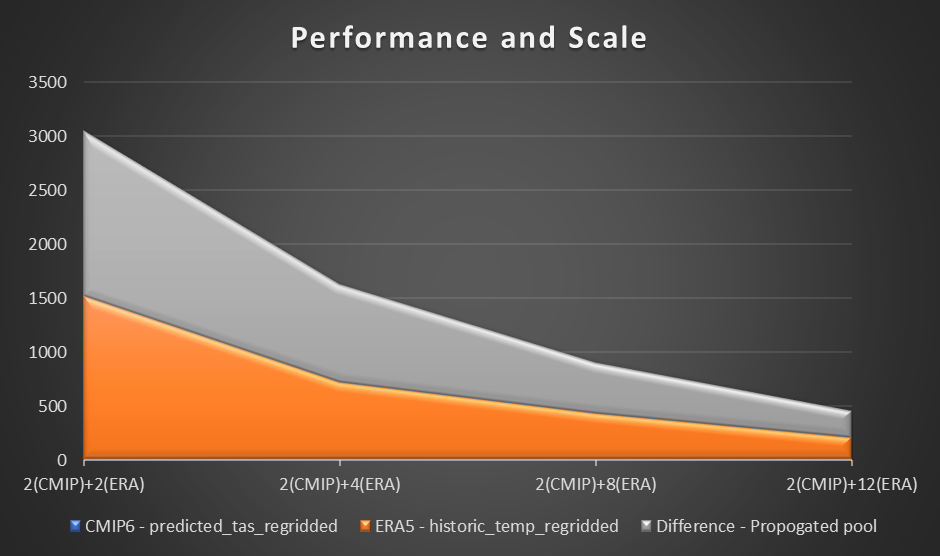
Dal nostro esperimento, abbiamo osservato un miglioramento lineare nel calcolo per il set di dati ERA5 all'aumentare del numero di lavoratori. Con l’aumento del numero dei lavoratori, i tempi di calcolo a volte venivano dimezzati.
Notebook Jupyter
Nell'ambito del lancio della soluzione, distribuiamo un notebook Jupyter preconfigurato per aiutare a testare la soluzione Dask interregionale. Il notebook dimostra la rimozione della preoccupazione di dover conoscere la posizione regionale dei set di dati, interrogando invece un catalogo tramite una serie di notebook Jupyter in esecuzione in background.
Per iniziare, seguire le istruzioni in questa sezione.
Il codice per i taccuini può essere trovato in lib/SagemakerCode con il taccuino principale essendo ux_notebook.ipynb. Questo notebook richiama altri notebook, attivando script di supporto. ux_notebook è progettato per essere il punto di ingresso per gli scienziati, senza la necessità di andare altrove.
Per iniziare, apri questo notebook in SageMaker dopo aver distribuito AWS CDK. AWS CDK crea un'istanza notebook con tutti i file nel repository caricati e sottoposti a backup su un file AWS CodeCommit repository.
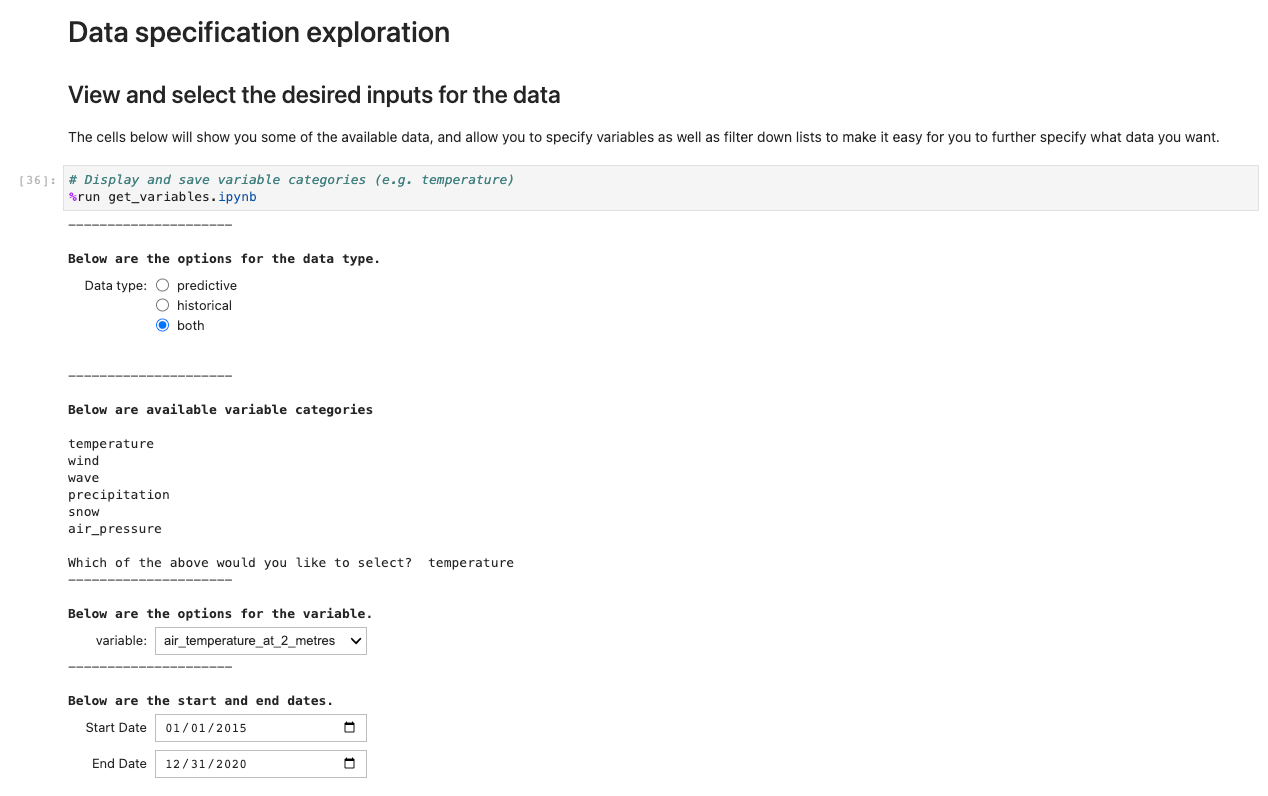
Per eseguire l'applicazione, aprire ed eseguire la prima cella di ux_notebook. Questa cella esegue il get_variables notebook in background, che richiede l'immissione dei dati che desideri selezionare. Includiamo un esempio; tuttavia, tieni presente che le domande verranno visualizzate solo dopo aver selezionato l'opzione precedente. Ciò è intenzionale per limitare le scelte del menu a discesa ed è facoltativamente configurabile modificando il file get_variables taccuino.
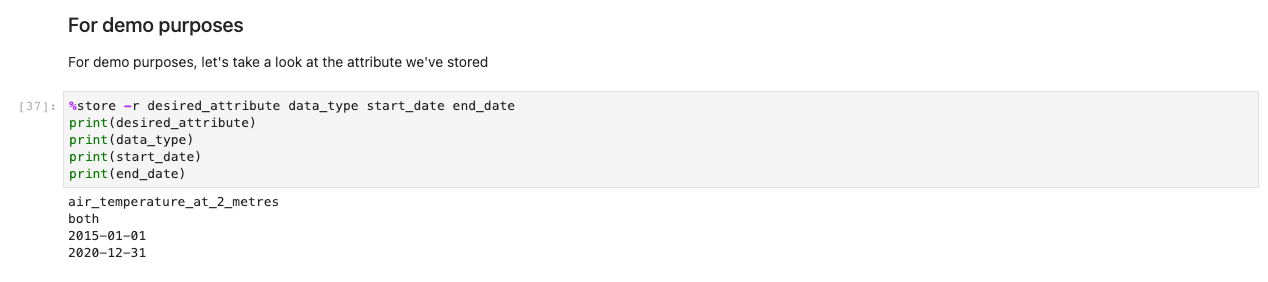
Il codice precedente memorizza le variabili a livello globale in modo che altri notebook possano recuperare e caricare la selezione di scelte. A scopo dimostrativo, la cella successiva dovrebbe restituire le variabili di salvataggio di prima.
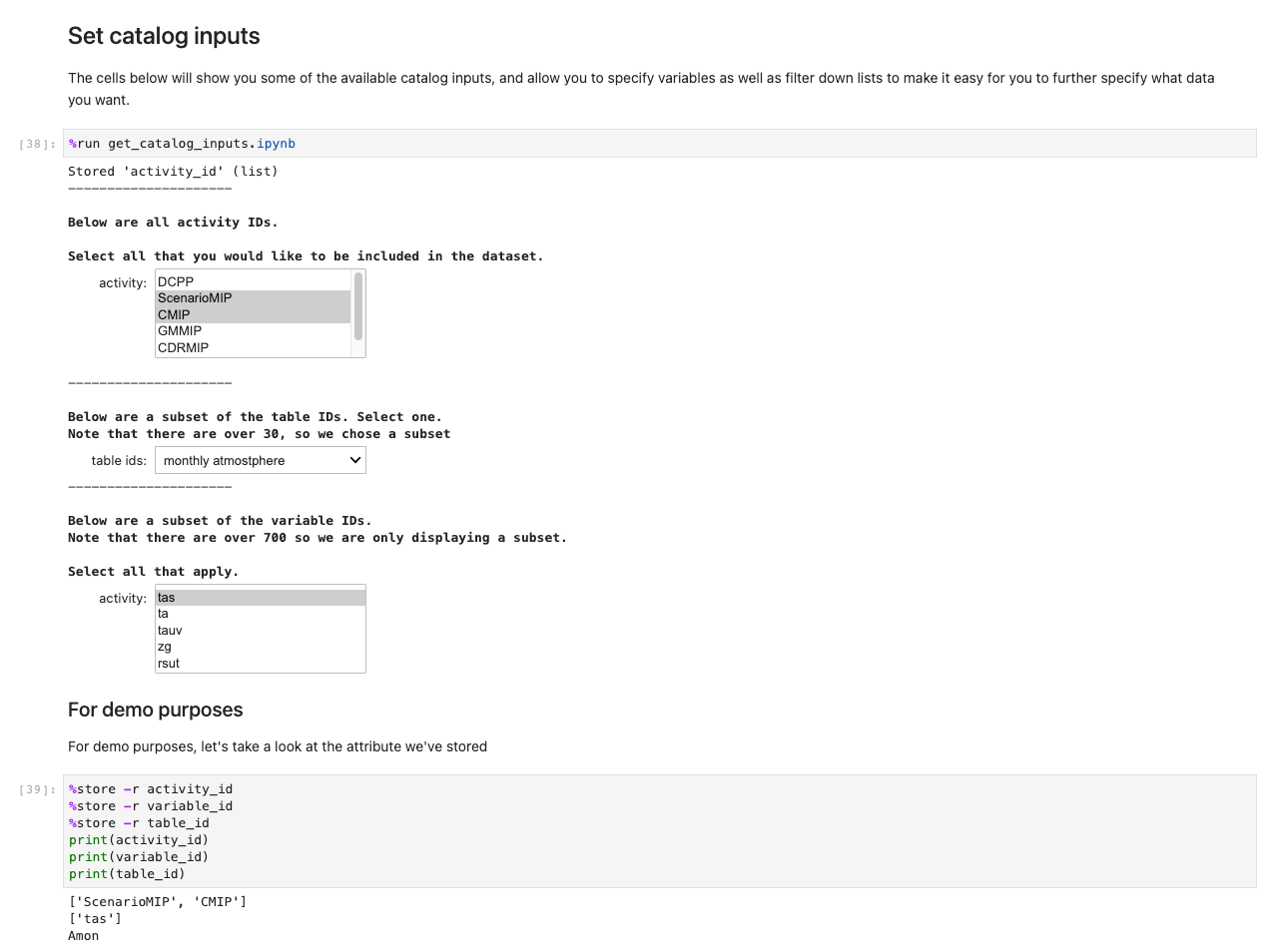
Successivamente, viene visualizzata una richiesta per ulteriori specifiche dei dati. Questa cella perfeziona i dati che stai cercando presentando gli ID delle tabelle in formato leggibile dall'uomo. Gli utenti selezionano come se fosse un modulo, ma i titoli si associano alle tabelle in background che aiutano il sistema a recuperare i set di dati appropriati.
Dopo aver memorizzato tutte le scelte e le celle di selezione, carica i dati nelle regioni eseguendo la cella nel file Recupero dei dati set sezione. Il comando %%capture sopprimerà gli output non necessari dal file get_data taccuino. Tieni presente che puoi rimuoverlo per controllare gli output degli altri notebook. I dati vengono quindi recuperati nel backend.
Mentre altri notebook vengono eseguiti in background, l'unico punto di contatto per l'utente è il ux_notebook. Questo per astrarre il noioso processo di importazione dei dati in un formato che qualsiasi utente può seguire con facilità.
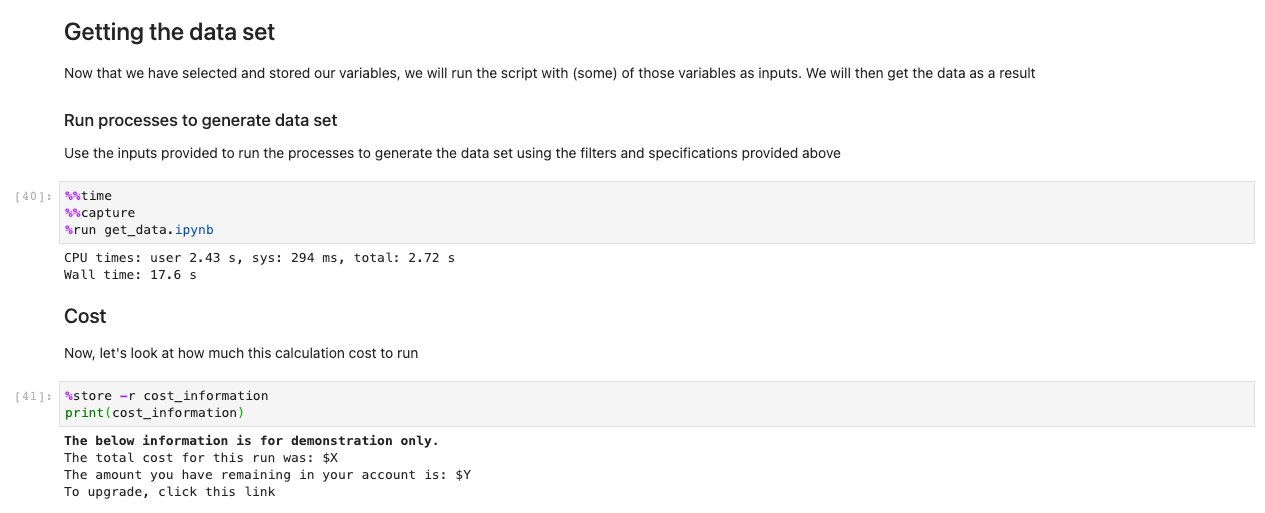
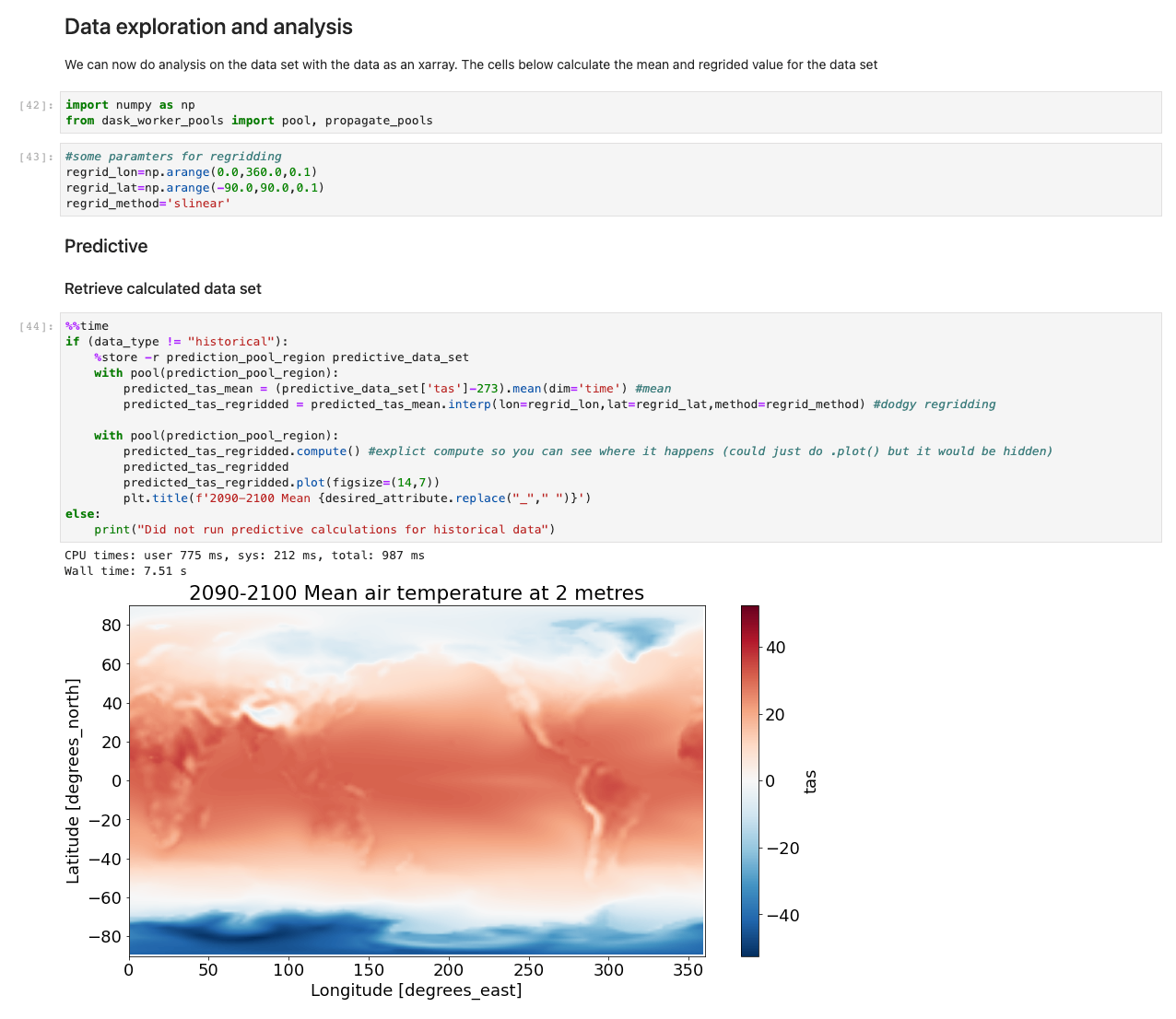
Una volta caricati i dati, possiamo iniziare a interagire con essi. Le celle seguenti sono esempi di calcoli che è possibile eseguire sui dati meteorologici. Utilizzando xarrays, importiamo, calcoliamo e quindi tracciamo tali set di dati.
Il nostro esempio illustra un grafico di dati predittivi che recuperano dati, eseguono il calcolo e tracciano i risultati in meno di 7.5 secondi: ordini di grandezza più veloci di un approccio tipico.
Sotto il cappuccio
I notebook get_catalog_input ed get_variables utilizzare la biblioteca ipywidgets per visualizzare widget come menu a discesa e selezioni multi-casella. Queste opzioni vengono salvate globalmente utilizzando il comando %%store in modo che sia possibile accedervi dal file ux_notebook. Una delle opzioni ti chiede se desideri dati storici, dati predittivi o entrambi. Questa variabile viene passata a get_data notebook per determinare quali notebook successivi eseguire.
Il get_data notebook recupera innanzitutto il dominio condiviso del servizio OpenSearch salvato in Archivio parametri di AWS Systems Manager. Questo dominio consente al nostro notebook di eseguire una query sulla raccolta di informazioni che indicherà dove sono archiviati i set di dati selezionati a livello regionale. Con i set di dati posizionati a livello regionale, il notebook effettuerà un tentativo di connessione allo scheduler Dask, trasmettendo le informazioni raccolte dal servizio OpenSearch. Lo scheduler Dask a sua volta sarà in grado di chiamare i lavoratori nelle regioni corrette.
Come personalizzare e continuare lo sviluppo
Questi notebook vogliono essere un esempio di come è possibile creare un modo per consentire agli utenti di interfacciarsi e interagire con i dati. Il taccuino in questo post serve come illustrazione di ciò che è possibile fare e ti invitiamo a continuare a sviluppare la soluzione per migliorare ulteriormente il coinvolgimento degli utenti. La parte centrale di questa soluzione è la tecnologia di backend, ma senza un meccanismo per interagire con quel backend, gli utenti non realizzeranno il pieno potenziale della soluzione.
Per evitare di incorrere in addebiti futuri, eliminare le risorse. Distruggiamo la nostra soluzione distribuita con il seguente comando:
Conclusione
Questo post mostra l'estensione di Dask a livello interregionale su AWS e una possibile integrazione con set di dati pubblici su AWS. La soluzione è stata creata come modello generico ed è possibile caricare ulteriori set di dati per accelerare analisi I/O elevate su dati complessi.
I dati stanno trasformando ogni campo e ogni azienda. Tuttavia, poiché i dati crescono più velocemente di quanto la maggior parte delle aziende possa tenere traccia, raccogliere dati e ricavarne valore è una sfida. Una moderna strategia dei dati può aiutarti a creare risultati aziendali migliori con i dati. AWS fornisce la serie più completa di servizi per il percorso dei dati end-to-end per aiutarti a ottenere valore dai tuoi dati e trasformarlo in insight.
Per saperne di più sui vari modi di utilizzare i tuoi dati sul cloud, visita il Blog sui Big Data di AWS. Ti invitiamo inoltre a commentare con i tuoi pensieri su questo post e se questa è una soluzione che intendi provare.
Informazioni sugli autori
 Patrick O'Connor è un ingegnere di prototipazione WWSO con sede a Londra. È un risolutore di problemi creativo, adattabile a un'ampia gamma di tecnologie, come IoT, tecnologia serverless, tecnologia spaziale 3D e ML/AI, insieme a un'incessante curiosità su come la tecnologia può continuare a evolvere gli approcci quotidiani.
Patrick O'Connor è un ingegnere di prototipazione WWSO con sede a Londra. È un risolutore di problemi creativo, adattabile a un'ampia gamma di tecnologie, come IoT, tecnologia serverless, tecnologia spaziale 3D e ML/AI, insieme a un'incessante curiosità su come la tecnologia può continuare a evolvere gli approcci quotidiani.
 Chakra Nagarajan è una Principal Machine Learning Prototyping SA con 21 anni di esperienza nel machine learning, big data e calcolo ad alte prestazioni. Nel suo ruolo attuale, aiuta i clienti a risolvere problemi aziendali complessi nel mondo reale costruendo prototipi con soluzioni AI/ML end-to-end in dispositivi cloud ed edge. La sua specializzazione in machine learning include visione artificiale, elaborazione del linguaggio naturale, previsione di serie temporali e personalizzazione.
Chakra Nagarajan è una Principal Machine Learning Prototyping SA con 21 anni di esperienza nel machine learning, big data e calcolo ad alte prestazioni. Nel suo ruolo attuale, aiuta i clienti a risolvere problemi aziendali complessi nel mondo reale costruendo prototipi con soluzioni AI/ML end-to-end in dispositivi cloud ed edge. La sua specializzazione in machine learning include visione artificiale, elaborazione del linguaggio naturale, previsione di serie temporali e personalizzazione.
 ValCohen è un ingegnere senior di prototipazione WWSO con sede a Londra. Risolutrice di problemi per natura, Val ama scrivere codice per automatizzare i processi, creare strumenti orientati al cliente e creare infrastrutture per varie applicazioni per la sua base di clienti globale. Val ha esperienza in un'ampia varietà di tecnologie, come sviluppo web front-end, lavoro back-end e AI/ML.
ValCohen è un ingegnere senior di prototipazione WWSO con sede a Londra. Risolutrice di problemi per natura, Val ama scrivere codice per automatizzare i processi, creare strumenti orientati al cliente e creare infrastrutture per varie applicazioni per la sua base di clienti globale. Val ha esperienza in un'ampia varietà di tecnologie, come sviluppo web front-end, lavoro back-end e AI/ML.
 Niall Robinson è responsabile dei futures dei prodotti presso il Met Office del Regno Unito. Lui e il suo team esplorano nuovi modi in cui il Met Office può fornire valore attraverso l'innovazione dei prodotti e le partnership strategiche. Ha avuto una carriera variegata, alla guida di un team multidisciplinare di ricerca e sviluppo informatico, di ricerca accademica nella scienza dei dati e di scienziato sul campo, oltre ad avere esperienza nella modellazione climatica.
Niall Robinson è responsabile dei futures dei prodotti presso il Met Office del Regno Unito. Lui e il suo team esplorano nuovi modi in cui il Met Office può fornire valore attraverso l'innovazione dei prodotti e le partnership strategiche. Ha avuto una carriera variegata, alla guida di un team multidisciplinare di ricerca e sviluppo informatico, di ricerca accademica nella scienza dei dati e di scienziato sul campo, oltre ad avere esperienza nella modellazione climatica.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Coniare il futuro con Adryenn Ashley. Accedi qui.
- Acquista e vendi azioni in società PRE-IPO con PREIPO®. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-efficient-cross-regional-i-o-intensive-workloads-with-dask-on-aws/
- :ha
- :È
- :Dove
- $ SU
- 1
- 10
- 100
- 11
- 12
- 20
- 24
- 3d
- 40
- 50
- 7
- 9
- a
- capacità
- capace
- WRI
- sopra
- ABSTRACT
- abstract
- accademico
- ricerca accademica
- accelerare
- accelerando
- accesso
- accessibile
- ospitare
- realizzare
- Il mio account
- Realizza
- operanti in
- adatta
- aggiunto
- l'aggiunta di
- aggiuntivo
- Inoltre
- indirizzo
- indirizzamento
- Aggiunge
- amministratori
- adottato
- Adozione
- Dopo shavasana, sedersi in silenzio; saluti;
- AI / ML
- ARIA
- Tutti
- Consentire
- consente
- lungo
- anche
- Amazon
- Amazon EC2
- an
- .
- ed
- in qualsiasi
- apparire
- Applicazioni
- applicazioni
- approccio
- approcci
- opportuno
- architettura
- SONO
- AS
- At
- Atmosfera
- atmosferico
- automatizzare
- evitare
- AWS
- Cliente AWS
- Spina dorsale
- Backed
- BACKEND
- sfondo
- Equilibrio
- base
- basato
- BE
- diventare
- stato
- prima
- essendo
- sotto
- Segno di riferimento
- Meglio
- fra
- Big
- Big Data
- bootstrap
- entrambi
- Portare
- Rotto
- costruire
- Costruzione
- costruito
- incassato
- affari
- ma
- by
- calcolare
- chiamata
- detto
- chiamata
- Bandi
- Materiale
- funzionalità
- capace
- Career
- catalogo
- CD
- Celle
- Challenge
- impegnativo
- il cambiamento
- cambiando
- carica
- oneri
- scelte
- Circolazione
- cliente
- Clima
- più vicino
- Cloud
- Cluster
- CO
- codice
- base del codice
- collaborazione
- Raccolta
- Venire
- viene
- arrivo
- commento
- comunità
- Aziende
- completamento di una
- complesso
- componenti
- Compreso
- calcolo
- Calcolare
- computer
- Visione computerizzata
- informatica
- Configurazione
- Connettiti
- collegato
- Collegamento
- veloce
- Consumatori
- consumo
- Contenitore
- contiene
- continua
- continua
- copie
- Nucleo
- correggere
- Costo
- costo effettivo
- potuto
- accoppiato
- CPU
- creare
- crea
- Creative
- critico
- raccolto
- Cross
- curiosità
- Corrente
- costume
- cliente
- Clienti
- personalizzabile
- personalizzare
- alle lezioni
- cruscotto
- dati
- scienza dei dati
- strategia di dati
- dataset
- giorno
- decennio
- decisioni
- Predefinito
- Richiesta
- dimostra
- schierare
- schierato
- deployment
- Distribuisce
- progettato
- distruggere
- dettagliati
- dettagli
- Determinare
- sviluppare
- Costruttori
- Mercato
- dispositivi
- differenza
- disabile
- scoperta
- Dsiplay
- distribuito
- calcolo distribuito
- dns
- docker
- dominio
- giù
- dinamico
- dinamicamente
- ogni
- alleviare
- facilmente
- bordo
- montaggio
- efficiente
- altrove
- enable
- da un capo all'altro
- energia
- Fidanzamento
- ingegnere
- iscrizione
- Ambiente
- Equivalente
- epoca
- stimato
- Etere (ETH)
- Ogni
- ogni giorno
- quotidiano
- evolvere
- esempio
- Esempi
- esperienza
- esperimento
- competenza
- esplora
- export
- esposto
- estensione
- più veloce
- caratteristica
- Caratteristiche
- campo
- campi
- Compila il
- File
- Trovate
- Nome
- si concentra
- seguire
- i seguenti
- cibo
- Nel
- modulo
- formato
- forme
- essere trovato
- Fondato
- Contesto
- quadri
- Gratis
- da
- fruizione
- pieno
- funzionalità
- ulteriormente
- futuro
- Futures
- Generale
- ELETTRICA
- ottenere
- ottenere
- Idiota
- globali
- rete globale
- Globalmente
- globo
- andando
- grafico
- maggiore
- Griglia
- Crescere
- Crescita
- ha avuto
- Metà
- dimezzato
- Avere
- he
- capo
- Aiuto
- aiuta
- suo
- Alta
- Alte prestazioni
- evidenzia
- il suo
- storico
- host
- ospitato
- ora
- Come
- Tutorial
- Tuttavia
- HTML
- HTTPS
- leggibile dagli umani
- centinaia
- Idle
- ids
- if
- illustra
- importare
- importazione
- competenze
- miglioramento
- in
- includere
- inclusi
- è aumentato
- Index
- indicare
- far sapere
- informazioni
- Infrastruttura
- inerente
- Innovazione
- ingresso
- insicurezza
- intuizione
- fonte di ispirazione
- install
- esempio
- invece
- istruzioni
- integrazione
- Intenzionale
- interagire
- si interagisce
- Interfaccia
- interno
- Internet
- ai miglioramenti
- invitare
- IoT
- IP
- Indirizzo IP
- sicurezza
- IT
- SUO
- Lavoro
- viaggio
- jpg
- Notebook Jupyter
- mantenere
- Le
- Sapere
- Lingua
- grandi
- Cognome
- Latenza
- lanciare
- principale
- IMPARARE
- apprendimento
- Biblioteca
- ciclo di vita
- piace
- collegamento
- Lista
- caricare
- locale
- a livello locale
- collocato
- località
- Londra
- macchina
- machine learning
- maggiore
- make
- gestire
- direttore
- gestisce
- carta geografica
- mappatura
- Massa
- Adozione di massa
- materiale
- Maggio..
- significare
- meccanismo
- Metadati
- milioni
- ML
- modello
- moderno
- moduli
- Mese
- mensile
- dati mensili
- Scopri di più
- maggior parte
- MONTARE
- multidisciplinare
- Nome
- il
- Naturale
- Linguaggio naturale
- Elaborazione del linguaggio naturale
- Natura
- necessaria
- Bisogno
- che necessitano di
- Rete
- New
- GENERAZIONE
- notte
- nodo
- nodi
- taccuino
- computer portatili
- adesso
- numero
- numeri
- of
- offrire
- Office
- on
- ONE
- esclusivamente
- aprire
- dati aperti
- open source
- codice open source
- operativa
- Opzione
- Opzioni
- or
- orchestrazione
- organizzazioni
- Altro
- nostro
- su
- risultati
- produzione
- ancora
- complessivo
- pacchetto
- parametro
- parte
- particolare
- particolarmente
- partnership
- Passato
- Di passaggio
- Cartamodello
- performance
- periodi
- personalizzazione
- petabyte
- fase
- piano
- Piattaforme
- Platone
- Platone Data Intelligence
- PlatoneDati
- punto
- pool
- porte
- possibile
- Post
- potenziale
- energia
- potente
- pratica
- predizione
- Previsioni
- prerequisiti
- precedente
- primario
- Direttore
- un bagno
- Problema
- problemi
- processi
- i processi
- lavorazione
- Prodotto
- Prodotto
- Innovazione di prodotto
- produttivo
- Programma
- Programmazione
- progetto
- prototipi
- prototipazione
- fornire
- purché
- fornisce
- fornitura
- la percezione
- pubblicare
- pubblicato
- Maglioni
- query
- Domande
- R&D
- gamma
- piuttosto
- preconfezionato
- mondo reale
- rendersi conto
- ridurre
- riducendo
- riduzione
- regione
- regionale
- regioni
- implacabile
- resti
- rimuovere
- rimosso
- deposito
- rappresenta
- riparazioni
- Risorse
- quelli
- Risultati
- Ruolo
- Correre
- running
- SA
- sicura
- sagemaker
- stesso
- Risparmi
- scalabile
- Scala
- bilancia
- scala
- Scienze
- Scienziato
- scienziati
- script
- secondo
- Sezione
- vedere
- visto
- segmenti
- selezionato
- prodotti
- anziano
- Serie
- serverless
- serve
- servizio
- Servizi
- set
- Condividi
- condiviso
- dovrebbero
- mostrare attraverso le sue creazioni
- vetrina
- Spettacoli
- Un'espansione
- semplicemente
- sesto
- rallentare
- So
- soluzione
- Soluzioni
- RISOLVERE
- alcuni
- Fonte
- Spaziale
- in particolare
- Specifiche tecniche
- specificato
- sponsorizzazione
- pila
- tappe
- standalone
- inizia a
- iniziato
- soggiorno
- Passi
- conservazione
- Tornare al suo account
- memorizzati
- negozi
- lineare
- Strategico
- Partnership strategiche
- Strategia
- successivo
- Successivamente
- di successo
- tale
- superficie
- ondata
- Sostenibilità
- sostenibile
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- Fai
- team
- Tech
- Tecnologie
- Tecnologia
- test
- di
- che
- Il
- le informazioni
- L’ORIGINE
- Regno Unito
- il mondo
- loro
- poi
- Là.
- in tal modo
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- quelli
- tre
- Prosperare
- Attraverso
- portata
- tempo
- Serie storiche
- volte
- titoli
- a
- oggi
- insieme
- strumenti
- pista
- Tracking
- trasferimento
- trasformazione
- transito
- innescando
- TURNO
- seconda
- Digitare
- Dattiloscritto
- tipico
- Uk
- per
- sbloccare
- insostenibile
- up-to-date
- Aggiornamenti
- su
- URI
- Impiego
- uso
- utilizzato
- Utente
- utenti
- utilizzando
- UTC
- Utilizzando
- VAL
- APPREZZIAMO
- varietà
- vario
- via
- visione
- Visita
- volume
- volere
- vuole
- caldo
- Prima
- Modo..
- modi
- we
- Tempo
- sito web
- Sviluppo Web
- sono stati
- se
- quale
- largo
- Vasta gamma
- volere
- auguri
- con
- senza
- Lavora
- lavoratore
- lavoratori
- mondo
- preoccuparsi
- sarebbe
- scrittura
- anni
- ancora
- dare la precedenza
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro