Il valore dei dati è sensibile al tempo. L'elaborazione in tempo reale rende le decisioni basate sui dati accurate e attuabili in pochi secondi o minuti invece che in ore o giorni. Change data capture (CDC) si riferisce al processo di identificazione e acquisizione delle modifiche apportate ai dati in un database e quindi consegna di tali modifiche in tempo reale a un sistema a valle. Catturare ogni modifica dalle transazioni in un database di origine e spostarle nella destinazione in tempo reale mantiene i sistemi sincronizzati e aiuta con casi d'uso di analisi in tempo reale e migrazioni di database senza tempi di inattività. Di seguito sono riportati alcuni vantaggi di CDC:
- Elimina la necessità dell'aggiornamento del caricamento in blocco e delle finestre batch scomode consentendo il caricamento incrementale o lo streaming in tempo reale delle modifiche ai dati nel repository di destinazione.
- Assicura che i dati in più sistemi rimangano sincronizzati. Ciò è particolarmente importante se si prendono decisioni urgenti in un ambiente di dati ad alta velocità.
Kafka Connect è un componente open source di Apache Kafka che funziona come un hub di dati centralizzato per una semplice integrazione dei dati tra database, archivi di valori-chiave, indici di ricerca e file system. IL Registro dello schema di AWS Glue consente di rilevare, controllare ed evolvere centralmente gli schemi del flusso di dati. Kafka Connect e Schema Registry si integrano per acquisire informazioni sullo schema dai connettori. Kafka Connect fornisce un meccanismo per convertire i dati dai tipi di dati interni utilizzati da Kafka Connect ai tipi di dati rappresentati come Avro, Protobuf o JSON Schema. AvroConverter, ProtobufConverter e JsonSchemaConverter registrano automaticamente gli schemi generati dai connettori Kafka (origine) che producono dati in Kafka. I connettori (sink) che consumano dati da Kafka ricevono informazioni sullo schema oltre ai dati per ogni messaggio. Ciò consente ai connettori sink di conoscere la struttura dei dati per fornire funzionalità come la gestione di uno schema di tabella di database in un catalogo dati.
Il post mostra come creare un CDC end-to-end utilizzando Amazon MSK Connect, un servizio gestito da AWS per distribuire ed eseguire le applicazioni Kafka Connect e AWS Glue Schema Registry, che consente di rilevare, controllare ed evolvere centralmente gli schemi del flusso di dati.
Panoramica della soluzione
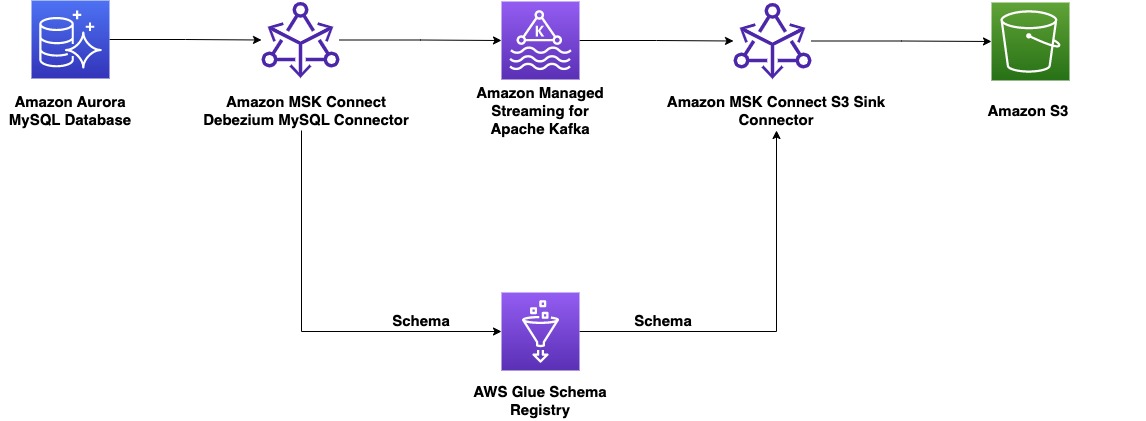
Dal lato del produttore, per questo esempio scegliamo un MySQL compatibile Amazon Aurora database come origine dati e abbiamo a Debezio Connettore MySQL per eseguire CDC. Il connettore Debezium monitora continuamente i database e invia le modifiche a livello di riga a un argomento Kafka. Il connettore recupera lo schema dal database per serializzare i record in un formato binario. Se lo schema non esiste già nel registro, lo schema verrà registrato. Se lo schema esiste ma il serializzatore utilizza una nuova versione, il registro dello schema controlla il file modalità di compatibilità dello schema prima di aggiornare lo schema. In questa soluzione, usiamo modalità di compatibilità con le versioni precedenti. Il registro dello schema restituisce un errore se una nuova versione dello schema non è compatibile con le versioni precedenti e possiamo configurare Kafka Connect per inviare messaggi incompatibili alla coda dei messaggi non recapitabili.
Dal lato del consumatore, usiamo an Servizio di archiviazione semplice Amazon (Amazon S3) connettore sink per deserializzare il record e archiviare le modifiche in Amazon S3. Costruiamo e distribuiamo il connettore Debezium e il sink Amazon S3 utilizzando MSK Connect.
Schema di esempio
Per questo post, utilizziamo il seguente schema come prima versione della tabella:
Prerequisiti
Prima di configurare i connettori produttore e consumatore MSK, è necessario configurare un'origine dati, un cluster MSK e un nuovo registro dello schema. Forniamo un AWS CloudFormazione modello per generare le risorse di supporto necessarie per la soluzione:
- Un database Aurora compatibile con MySQL come origine dati. Per eseguire CDC, attiviamo la registrazione binaria nel file Gruppo di parametri del cluster di database.
- Un cluster MSK. Per semplificare la connessione di rete, utilizziamo lo stesso VPC per il database Aurora e il cluster MSK.
- Due registri di schemi per gestire gli schemi per la chiave del messaggio e il valore del messaggio.
- Un bucket S3 come data sink.
- Plugin MSK Connect e configurazione del lavoratore necessari per questa demo.
- Uno Cloud di calcolo elastico di Amazon (Amazon EC2) per eseguire i comandi del database.
Per configurare le risorse nel tuo account AWS, completa i seguenti passaggi in una regione AWS che supporta Amazon MSK, MSK Connect e AWS Glue Schema Registry:
- Scegli Avvia Stack:
- Scegli Avanti.
- Nel Nome dello stack, inserisci un nome adatto.
- Nel Password del database, immettere la password desiderata per l'utente del database.
- Mantieni gli altri valori come predefiniti.
- Scegli Avanti.
- Nella pagina successiva, scegli Avanti.
- Rivedere i dettagli nella pagina finale e selezionare Riconosco che AWS CloudFormation potrebbe creare risorse IAM.
- Scegli Crea stack.
Plug-in personalizzato per il connettore di origine e destinazione
Un plug-in personalizzato è un insieme di file JAR che contengono l'implementazione di uno o più connettori, trasformazioni o convertitori. Amazon MSK installerà il plug-in sui nodi di lavoro del cluster MSK Connect in cui è in esecuzione il connettore. Come parte di questa demo, per il connettore sorgente utilizziamo l'open source JAR del connettore Debezium MySQL, e per il connettore di destinazione utilizziamo la licenza della comunità Confluent JAR connettore sink Amazon S3. Entrambi i plugin vengono aggiunti anche con librerie per Avro Serializzatori e Deserializzatori del registro degli schemi di AWS Glue. Questi plug-in personalizzati sono già stati creati come parte del modello CloudFormation distribuito nel passaggio precedente.
Utilizza AWS Glue Schema Registry con il connettore Debezium su MSK Connect come produttore MSK
Per prima cosa distribuiamo il connettore di origine utilizzando il plug-in Debezium MySQL per lo streaming di dati da un file Edizione compatibile con Amazon Aurora MySQL database ad Amazon MSK. Completa i seguenti passaggi:
- Nella console Amazon MSK, nel riquadro di navigazione, sotto Connessione MSKscegli Connettori RF.
- Scegli Crea connettore.
- Scegli Utilizza il plug-in personalizzato esistente e quindi scegli il plug-in personalizzato con il nome che inizia
msk-blog-debezium-source-plugin. - Scegli Avanti.
- Inserisci un nome adatto come
debezium-mysql-connectore una descrizione facoltativa. - Nel Cluster Apache Kafkascegli Cluster MSK e scegli il cluster creato dal modello CloudFormation.
- In Configurazione del connettore, eliminare i valori predefiniti e utilizzare le seguenti coppie chiave-valore di configurazione e con i valori appropriati:
- Nome – Il nome utilizzato per il connettore.
- database.nomehost – L'output di CloudFormation per Punto terminale del database.
- database.utente e database.password – I parametri passati nel modello CloudFormation.
- database.history.kafka.bootstrap.servers – L'output di CloudFormation per Kafka Bootstrap.
- key.converter.region e value.converter.region – La tua regione.
Alcune di queste impostazioni sono generiche e devono essere specificate per qualsiasi connettore. Per esempio:
- connector.class è la classe Java del connettore
- task.max è il numero massimo di attività che devono essere create per questo connettore
Alcune impostazioni (database.*, transforms.*) sono specifici del connettore Debezium MySQL. Fare riferimento a Proprietà di configurazione del connettore sorgente MySQL di Debezium per maggiori informazioni.
Alcune impostazioni (key.converter.* ed value.converter.*) sono specifici dello Schema Registry. Noi usiamo il AWSKafkaAvroConverter dal Libreria del registro degli schemi di AWS Glue come convertitore di formato. Da configurare AWSKafkaAvroConverter, usiamo il valore delle proprietà della costante stringa in AWSSchemaRegistryConstants classe:
key.converteredvalue.convertercontrollare il formato dei dati che verranno scritti in Kafka per i connettori sorgente o letti da Kafka per i connettori sink. Noi usiamoAWSKafkaAvroConverterper il formato Avro.key.converter.registry.nameedvalue.converter.registry.namedefinire quale registro dello schema utilizzare.key.converter.compatibilityedvalue.converter.compatibilitydefinire il modello di compatibilità.
Fare riferimento a Utilizzo di Kafka Connect con AWS Glue Schema Registry per maggiori informazioni.
- Successivamente, configuriamo Capacità del connettore. Possiamo scegliere Fornito e lascia le altre proprietà come predefinite
- Nel Configurazione lavoratore, scegli la configurazione di lavoro personalizzata con il nome che inizia
msk-gsr-blogcreato come parte del modello CloudFormation. - Nel Autorizzazioni di accesso, Usa il Gestione dell'identità e dell'accesso di AWS (IAM) generato dal modello CloudFormation
MSKConnectRole. - Scegli Avanti.
- Nel Sicurezza, scegli i valori predefiniti.
- Scegli Avanti.
- Nel Consegna del registro, selezionare Consegna ad Amazon CloudWatch Logs e cercare il gruppo di log creato dal modello CloudFormation (
msk-connector-logs). - Scegli Avanti.
- Rivedi le impostazioni e scegli Crea connettore.
Dopo alcuni minuti, il connettore passa allo stato di esecuzione.
Utilizza AWS Glue Schema Registry con il connettore sink Confluent S3 in esecuzione su MSK Connect come consumer MSK
Distribuiamo il connettore sink utilizzando il plug-in sink Confluent S3 per lo streaming di dati da Amazon MSK ad Amazon S3. Completa i seguenti passaggi:
-
- Nella console Amazon MSK, nel riquadro di navigazione, sotto Connessione MSKscegli Connettori RF.
- Scegli Crea connettore.
- Scegli Utilizza il plug-in personalizzato esistente e scegli il plug-in personalizzato con il nome che inizia
msk-blog-S3sink-plugin. - Scegli Avanti.
- Inserisci un nome adatto come
s3-sink-connectore una descrizione facoltativa. - Nel Cluster Apache Kafkascegli Cluster MSK e seleziona il cluster creato dal modello CloudFormation.
- In Configurazione del connettore, elimina i valori predefiniti forniti e utilizza le seguenti coppie chiave-valore di configurazione con i valori appropriati:
-
- Nome – Lo stesso nome utilizzato per il connettore.
- s3.nome.bucket – L'output di CloudFormation per Nome della benna.
- s3.region, key.converter.region e value.converter.region – La tua regione.
-
- Successivamente, configuriamo Capacità del connettore. Possiamo scegliere Fornito e lascia le altre proprietà come predefinite
- Nel Configurazione lavoratore, scegli la configurazione di lavoro personalizzata con il nome che inizia
msk-gsr-blogcreato come parte del modello CloudFormation. - Nel Autorizzazioni di accesso, utilizza il ruolo IAM generato dal modello CloudFormation
MSKConnectRole. - Scegli Avanti.
- Nel Sicurezza, scegli i valori predefiniti.
- Scegli Avanti.
- Nel Consegna del registro, selezionare Consegna ad Amazon CloudWatch Logs e cercare il gruppo di log creato dal modello CloudFormation
msk-connector-logs. - Scegli Avanti.
- Rivedi le impostazioni e scegli Crea connettore.
Dopo alcuni minuti, il connettore è in esecuzione.
Testare il flusso di log CDC end-to-end
Ora che entrambi i connettori sink Debezium e S3 sono attivi e funzionanti, completa i seguenti passaggi per testare il CDC end-to-end:
- Sulla console Amazon EC2, vai al file Gruppi di sicurezza .
- Seleziona il gruppo di sicurezza
ClientInstanceSecurityGroupe scegli Modifica le regole in entrata. - Aggiungi una regola in entrata che consenta la connessione SSH dalla tua rete locale.
- Sulla Istanze pagina, selezionare l'istanza
ClientInstancee scegli Connettiti. - Sulla Connessione all'istanza EC2 scheda, scegliere Connettiti.
- Assicurati che la tua attuale directory di lavoro sia
/home/ec2-usere ha i filecreate_table.sql,alter_table.sql,initial_insert.sqleinsert_data_with_new_column.sql. - Crea una tabella nel tuo database MySQL eseguendo il seguente comando (fornisci il nome host del database dagli output del modello CloudFormation):
- Quando viene richiesta una password, immettere la password dai parametri del modello CloudFormation.
- Inserisci alcuni dati di esempio nella tabella con il seguente comando:
- Quando viene richiesta una password, immettere la password dai parametri del modello CloudFormation.
- Nella console AWS Glue, scegli Registri di schemi nel riquadro di navigazione, quindi scegli schemi.
- Spostarsi
db1.sampledatabase.moviesversione 1 per controllare il nuovo schema creato per la tabella dei film:
Viene creata una cartella S3 separata per ogni partizione dell'argomento Kafka e i dati per l'argomento vengono scritti in tale cartella.
- Sulla console Amazon S3, controlla i dati scritti in formato Parquet nella cartella per il tuo argomento Kafka.
Evoluzione dello schema
Dopo aver definito lo schema iniziale, le applicazioni potrebbero doverlo evolvere nel tempo. Quando ciò accade, è fondamentale che i consumatori a valle siano in grado di gestire senza problemi i dati codificati sia con il vecchio che con il nuovo schema. Le modalità di compatibilità consentono di controllare in che modo gli schemi possono o non possono evolversi nel tempo. Queste modalità costituiscono il contratto tra le applicazioni che producono e consumano dati. Per informazioni dettagliate sulle diverse modalità di compatibilità disponibili nel registro degli schemi di AWS Glue, fare riferimento a Registro dello schema di AWS Glue. Nel nostro esempio, usiamo la combability all'indietro per garantire che i consumatori possano leggere sia la versione corrente che quella precedente dello schema. Completa i seguenti passaggi:
- Aggiungi una nuova colonna alla tabella eseguendo il seguente comando:
- Inserisci nuovi dati nella tabella eseguendo il seguente comando:
- Nella console AWS Glue, scegli Registri di schemi nel riquadro di navigazione, quindi scegli schemi.
- Passare allo schema
db1.sampledatabase.moviesversione 2 per controllare la nuova versione dello schema creato per la tabella dei film, inclusa la colonna del paese che hai aggiunto:
- Sulla console Amazon S3, controlla i dati scritti in formato Parquet nella cartella dell'argomento Kafka.
ripulire
Per evitare addebiti indesiderati sul tuo account AWS, elimina le risorse AWS utilizzate in questo post:
- Sulla console Amazon S3, vai al bucket S3 creato dal modello CloudFormation.
- Seleziona tutti i file e le cartelle e scegli Elimina.
- Inserisci elimina definitivamente come indicato e scegli Elimina oggetti.
- Sulla console AWS CloudFormation, elimina lo stack che hai creato.
- Attendi che lo stato dello stack cambi in DELETE_COMPLETE.
Conclusione
Questo post ha dimostrato come utilizzare Amazon MSK, MSK Connect e AWS Glue Schema Registry per creare un flusso di log CDC ed evolvere gli schemi per i flussi di dati man mano che le esigenze aziendali cambiano. Puoi applicare questo modello di architettura ad altre origini dati con diversi connettori Kafka. Per ulteriori informazioni, consultare il Esempi di MSK Connect.
L'autore
 Kalyan Janaki è Senior Big Data & Analytics Specialist presso Amazon Web Services. Aiuta i clienti a progettare e creare soluzioni basate su cloud altamente scalabili, performanti e sicure su AWS.
Kalyan Janaki è Senior Big Data & Analytics Specialist presso Amazon Web Services. Aiuta i clienti a progettare e creare soluzioni basate su cloud altamente scalabili, performanti e sicure su AWS.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- Platoblockchain. Web3 Metaverse Intelligence. Conoscenza amplificata. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/build-an-end-to-end-change-data-capture-with-amazon-msk-connect-and-aws-glue-schema-registry/
- :È
- $ SU
- 1
- 10
- 11
- 7
- 8
- a
- capace
- Chi siamo
- accesso
- Il mio account
- preciso
- riconoscere
- aggiunto
- aggiunta
- Tutti
- Consentire
- consente
- già
- Amazon
- Amazon EC2
- Amazon Web Services
- analitica
- ed
- Apache
- Apache Kafka
- applicazioni
- APPLICA
- opportuno
- architettura
- SONO
- AS
- Aurora
- automaticamente
- disponibile
- AWS
- AWS CloudFormazione
- Colla AWS
- BE
- prima
- vantaggi
- fra
- Big
- Big Data
- bootstrap
- costruire
- affari
- by
- Materiale
- funzionalità
- catturare
- Catturare
- casi
- catalogo
- CDC
- centralizzata
- il cambiamento
- Modifiche
- oneri
- dai un'occhiata
- Controlli
- Scegli
- classe
- Cluster
- Colonna
- comunità
- compatibilità
- compatibile
- completamento di una
- componente
- Calcolare
- Configurazione
- ConFluent™
- Connettiti
- veloce
- consolle
- costante
- consumare
- Consumer
- Consumatori
- continuamente
- contratto
- di controllo
- nazione
- creare
- creato
- critico
- Corrente
- costume
- Clienti
- dati
- integrazione dei dati
- data-driven
- Banca Dati
- banche dati
- Giorni
- decisioni
- Predefinito
- defaults
- definito
- consegna
- Dimo
- dimostrato
- dimostra
- schierare
- schierato
- descrizione
- destinazione
- dettagliati
- dettagli
- diverso
- scopri
- non
- Cadere
- ogni
- elimina
- consentendo
- da un capo all'altro
- garantire
- assicura
- entrare
- Ambiente
- errore
- particolarmente
- Etere (ETH)
- Ogni
- evolvere
- esempio
- esistente
- esiste
- pochi
- campi
- Compila il
- File
- finale
- Nome
- i seguenti
- Nel
- modulo
- formato
- da
- generare
- generato
- Gruppo
- Gruppo
- maniglia
- Manovrabilità
- accade
- Avere
- Aiuto
- aiuta
- vivamente
- storia
- host
- ORE
- Come
- Tutorial
- HTML
- http
- HTTPS
- Hub
- IAM
- identificazione
- Identità
- implementazione
- importante
- in
- Compreso
- indici
- informazioni
- inizialmente
- install
- esempio
- invece
- integrare
- integrazione
- interno
- IT
- Java
- jpg
- json
- kafka
- Le
- Sapere
- Lasciare
- biblioteche
- Autorizzato
- piace
- caricare
- Caricamento in corso
- locale
- Lunghi
- fatto
- FA
- Fare
- gestito
- Mastercard
- max
- massimo
- meccanismo
- messaggio
- messaggi
- forza
- verbale
- modello
- modalità di
- monitor
- Scopri di più
- Film
- in movimento
- multiplo
- MySQL
- Nome
- Navigare
- Navigazione
- Bisogno
- di applicazione
- esigenze
- Rete
- New
- GENERAZIONE
- numero
- of
- Vecchio
- on
- ONE
- open source
- Altro
- produzione
- pagina
- coppie
- vetro
- parametro
- parametri
- parte
- Passato
- Password
- Cartamodello
- eseguire
- permanentemente
- scegliere
- Platone
- Platone Data Intelligence
- PlatoneDati
- plug-in
- i plugin
- Post
- prevenire
- precedente
- processi
- lavorazione
- produrre
- produttore
- proprietà
- fornire
- purché
- fornisce
- Leggi
- di rose
- tempo reale
- ricevere
- record
- record
- si riferisce
- regione
- registro
- registrato
- registro
- deposito
- rappresentato
- Risorse
- problemi
- Ruolo
- Regola
- Correre
- running
- stesso
- scalabile
- senza soluzione di continuità
- Cerca
- secondo
- sicuro
- problemi di
- anziano
- delicata
- separato
- servizio
- Servizi
- set
- impostazioni
- dovrebbero
- Un'espansione
- semplificare
- soluzione
- Soluzioni
- alcuni
- Fonte
- fonti
- specialista
- specifico
- specificato
- pila
- Di partenza
- Stato dei servizi
- step
- Passi
- conservazione
- Tornare al suo account
- negozi
- ruscello
- Streaming
- flussi
- La struttura
- adatto
- Supporto
- supporti
- sync.
- sistema
- SISTEMI DI TRATTAMENTO
- tavolo
- Target
- task
- modello
- test
- che
- I
- L’ORIGINE
- Li
- Strumenti Bowman per analizzare le seguenti finiture:
- tempo
- sensibile al tempo
- Titolo
- a
- argomento
- Le transazioni
- TURNO
- Tipi di
- per
- non desiderato
- aggiornamento
- uso
- Utente
- APPREZZIAMO
- Valori
- versione
- sito web
- servizi web
- quale
- volere
- finestre
- con
- lavoratore
- lavoratori
- lavoro
- lavori
- scritto
- Trasferimento da aeroporto a Sharm
- zefiro