Servizio Amazon OpenSearch recentemente introdotto Multi-AZ con standby, un'opzione di implementazione progettata per fornire alle aziende una maggiore disponibilità e prestazioni costanti per i carichi di lavoro critici. Con questa funzionalità, i cluster gestiti possono raggiungere una disponibilità del 99.99% pur rimanendo resilienti ai guasti dell'infrastruttura di zona.
In questo post esploriamo il funzionamento della ricerca e dell'indicizzazione con Multi-AZ con Standby e approfondiamo i meccanismi sottostanti che contribuiscono alla sua affidabilità, semplicità e tolleranza agli errori.
sfondo
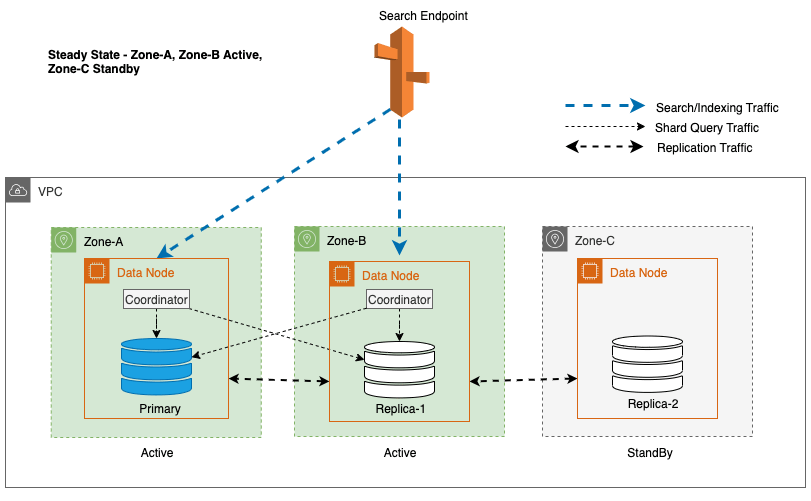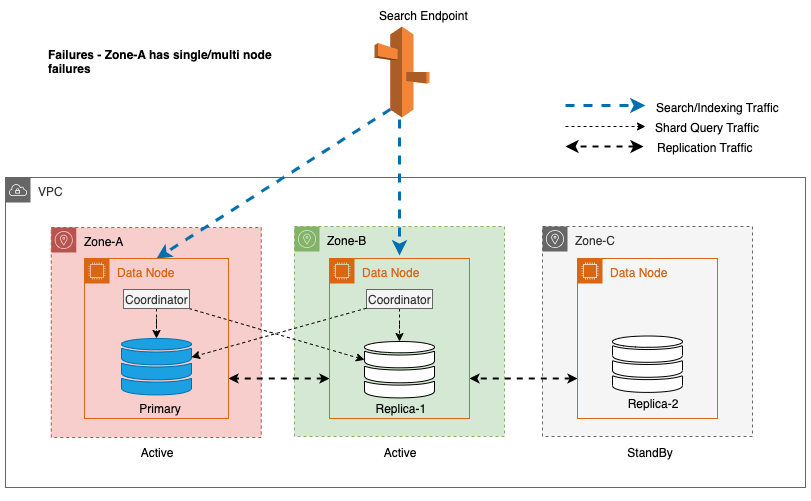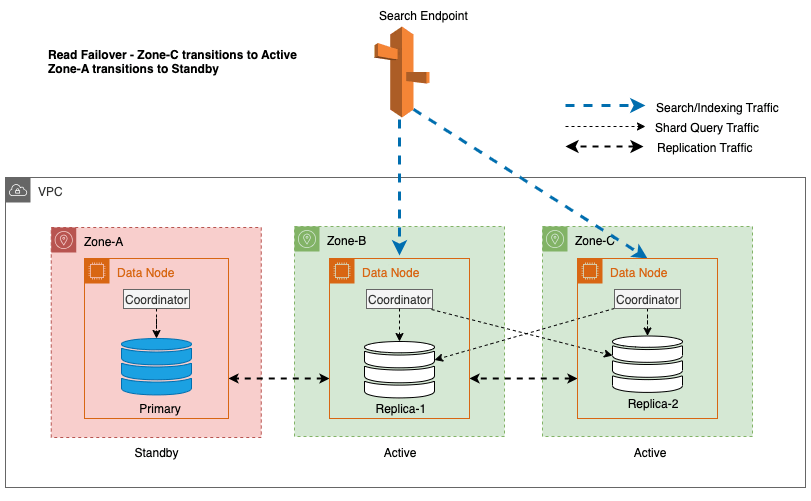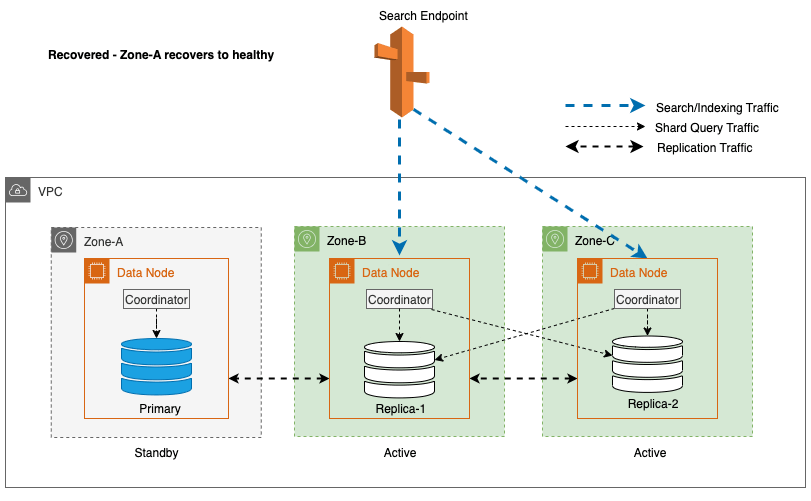
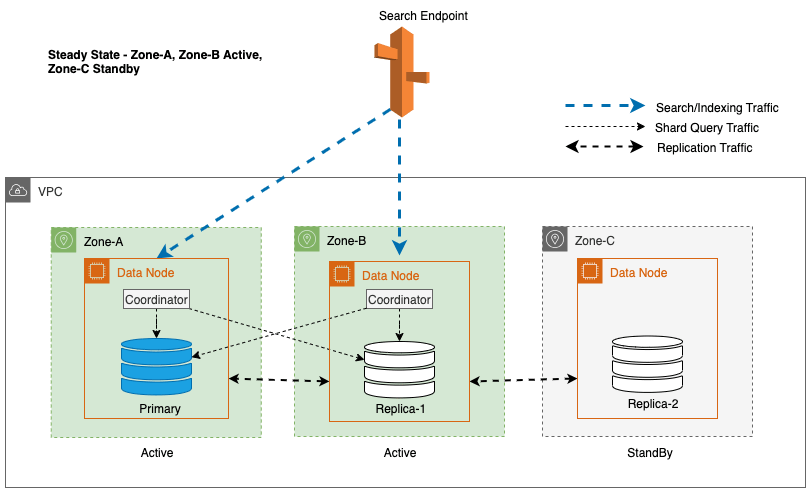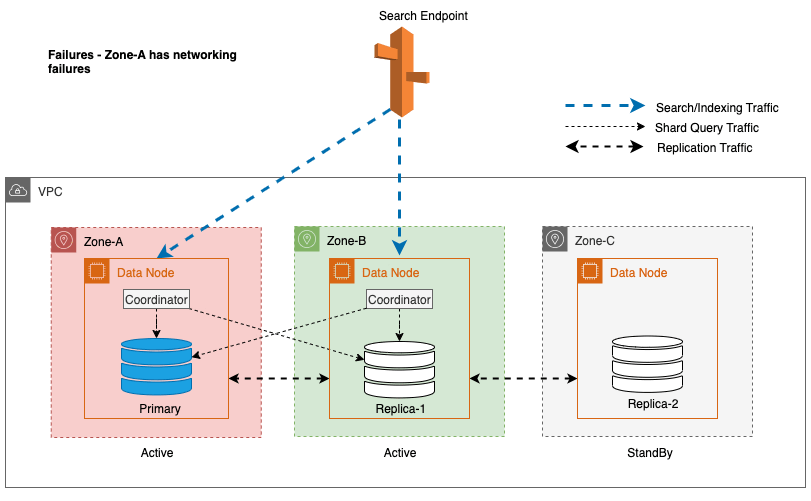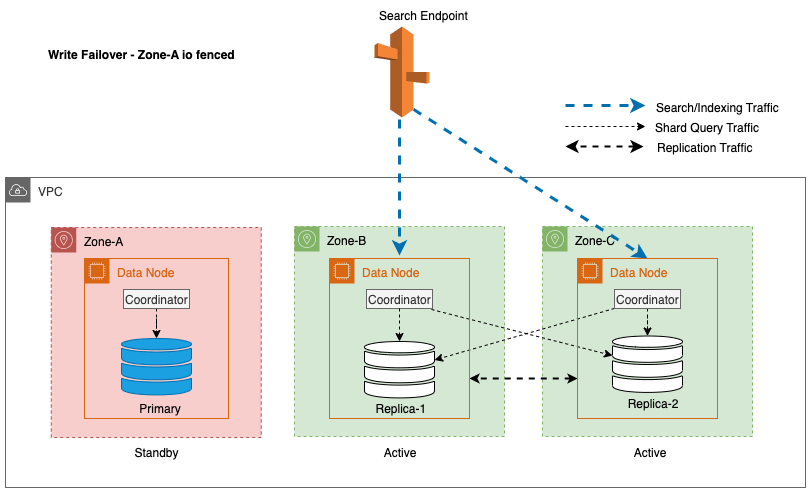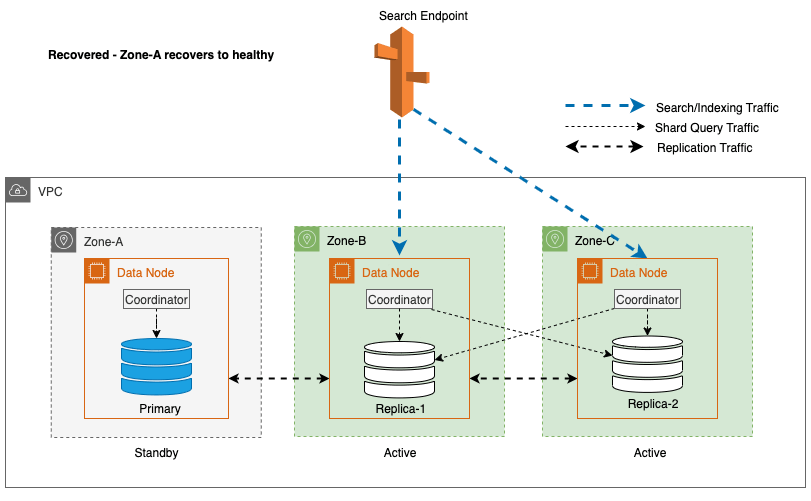
Multi-AZ con Standby distribuisce le istanze del dominio del servizio OpenSearch su tre zone di disponibilità, con due zone designate come attive e una come standby. Questa configurazione garantisce prestazioni costanti, anche in caso di errori di zona, mantenendo la stessa capacità in tutte le zone. È importante sottolineare che questa zona di standby segue a disegno staticamente stabile, eliminando la necessità di provisioning della capacità o di spostamento dei dati in caso di guasti.
Durante le operazioni regolari, la zona attiva gestisce il traffico del coordinatore sia per le richieste di lettura che per quelle di scrittura, nonché per il traffico di query sullo shard. La zona standby, invece, riceve solo traffico di replica. Il servizio OpenSearch utilizza un protocollo di replica sincrona per le richieste di scrittura. Ciò consente al servizio di promuovere tempestivamente una zona di standby allo stato attivo in caso di guasto (tempo medio di failover <= 1 minuto), noto come failover di zona. La zona precedentemente attiva viene quindi retrocessa alla modalità standby e vengono avviate le operazioni di ripristino per ripristinarne lo stato integro.
Cerca l'instradamento del traffico e il failover per garantire un'elevata disponibilità
In un dominio del servizio OpenSearch, a coordinatore è qualsiasi nodo che gestisce le richieste HTTP(S), in particolare le richieste di indicizzazione e di ricerca. In una Multi-AZ con dominio Standby, i nodi dati nella zona attiva fungono da coordinatori per le richieste di ricerca.
Durante la fase di query di una richiesta di ricerca, il coordinatore determina gli shard da interrogare e invia una richiesta al nodo dati che ospita la copia dello shard. La query viene eseguita localmente su ogni frammento e i documenti corrispondenti vengono restituiti al nodo coordinatore. Il nodo coordinatore, responsabile dell'invio della richiesta ai nodi contenenti copie shard, esegue il processo in due passaggi. Innanzitutto, crea un iteratore che definisce l'ordine in cui è necessario interrogare i nodi per una copia shard in modo che il traffico sia distribuito uniformemente tra le copie shard. Successivamente la richiesta viene inviata ai nodi interessati.
Per creare un elenco ordinato di nodi da interrogare per una copia shard, il nodo coordinatore utilizza vari algoritmi. Questi algoritmi includono la selezione round-robin, la selezione della replica adattiva, il routing degli shard basato sulle preferenze e round robin ponderato.
Per Multi-AZ con Standby, l'algoritmo round robin ponderato viene utilizzato per la selezione della copia shard. In questo approccio, alle zone attive viene assegnato un peso pari a 1 e alla zona di standby viene assegnato un peso pari a 0. Ciò garantisce che nessun traffico di lettura venga inviato ai nodi dati nella zona di disponibilità di standby.
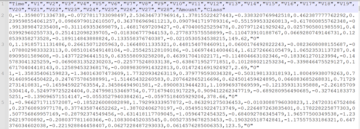
I pesi vengono archiviati nei metadati dello stato del cluster come oggetto JSON:
Come mostrato nella schermata seguente, il us-east-1b La regione ha il suo status di zona come StandBy, indicando che i nodi dati in questa zona di disponibilità sono in stato di standby e non ricevono richieste di ricerca o indicizzazione dal sistema di bilanciamento del carico.

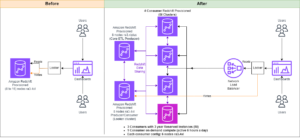
Per mantenere le operazioni stazionarie, la zona di disponibilità in standby viene ruotata ogni 30 minuti, garantendo che tutte le parti della rete siano coperte nelle zone di disponibilità. Questo approccio proattivo verifica la disponibilità dei percorsi di lettura, migliorando ulteriormente la resilienza del sistema durante potenziali guasti. Il diagramma seguente illustra questa architettura.
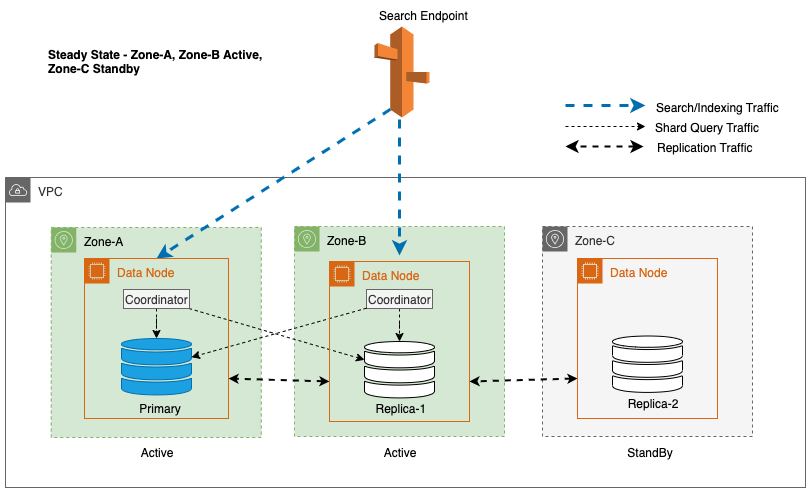
Nel diagramma precedente, la Zona-C ha un peso del round robin ponderato impostato su zero. Ciò garantisce che i nodi dati nella zona di standby non ricevano alcun traffico di indicizzazione o di ricerca. Quando il coordinatore interroga i nodi dati per le copie shard, utilizza un peso round robin ponderato per decidere l'ordine in cui interrogare i nodi. Poiché il peso è zero per la zona di disponibilità in standby, le richieste del coordinatore non vengono inviate.
In un cluster del servizio OpenSearch, le zone attive e in standby possono essere controllate in qualsiasi momento utilizzando i parametri di rotazione delle zone di disponibilità, come mostrato nello screenshot seguente.
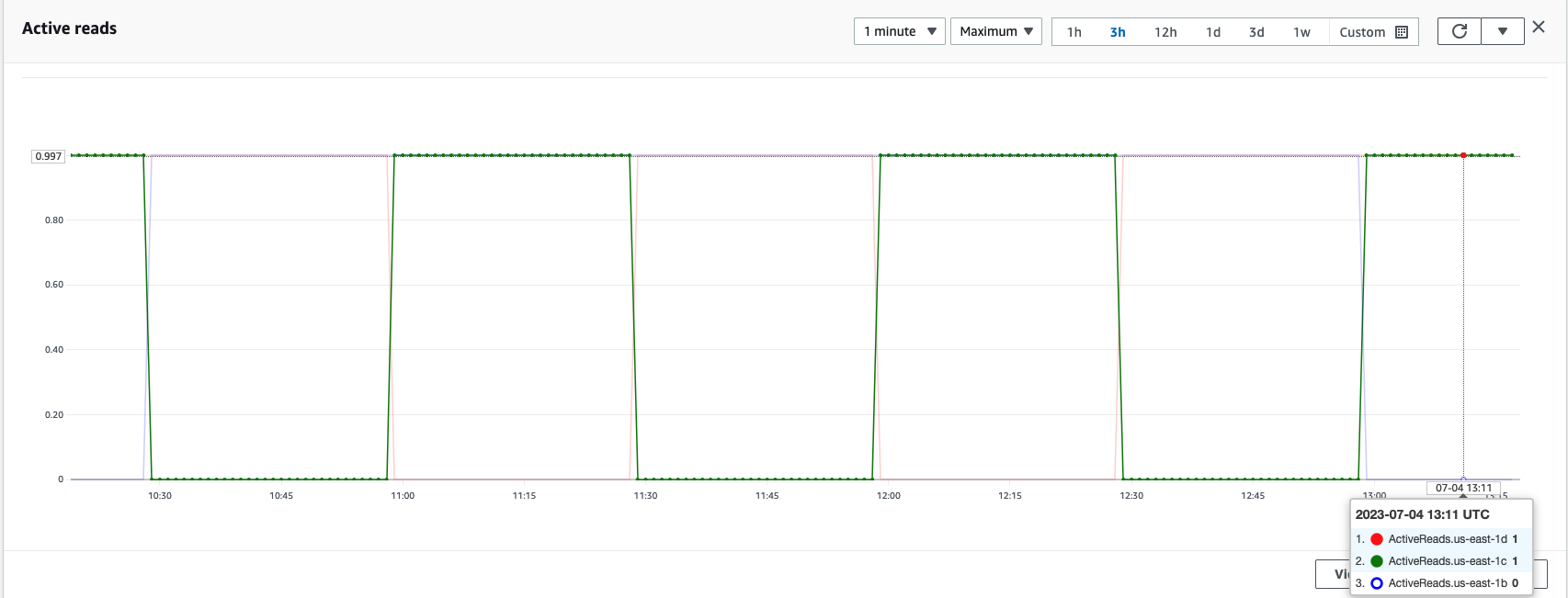
Durante le interruzioni di zona, la zona di disponibilità in standby passa senza problemi alla modalità di apertura non riuscita per le richieste di ricerca. Ciò significa che il traffico delle query sullo shard viene instradato a tutte le zone di disponibilità, anche quelle in standby, quando una copia shard integra non è disponibile nella zona di disponibilità attiva. Questo approccio fail-open salvaguarda le richieste di ricerca dall'interruzione durante i guasti, garantendo un servizio continuo. Il diagramma seguente illustra questa architettura.
Nel diagramma precedente, durante lo stato stazionario, il traffico delle query sullo shard viene inviato al nodo dati nelle zone di disponibilità attive (Zona A e Zona B). A causa di guasti del nodo nella Zona A, la zona di disponibilità in standby (Zona C) non riesce ad aprirsi per accettare il traffico delle query sullo shard in modo che non vi sia alcun impatto sulle richieste di ricerca. Alla fine, la Zona A viene rilevata come non integra e il failover di lettura commuta lo standby nella Zona A.
In che modo il failover garantisce la disponibilità elevata durante il danneggiamento della scrittura
Il modello di replica del servizio OpenSearch segue un modello di backup primario, caratterizzato dalla sua natura sincrona, in cui è necessario il riconoscimento da tutte le copie shard prima che una richiesta di scrittura possa essere riconosciuta dall'utente. Uno svantaggio notevole di questo modello di replica è la sua suscettibilità ai rallentamenti in caso di qualsiasi compromissione nel percorso di scrittura. Questi sistemi si basano su un nodo leader attivo per identificare guasti o ritardi e quindi trasmettere queste informazioni a tutti i nodi. La durata necessaria per rilevare questi problemi (tempo medio di rilevamento) e successivamente risolverli (tempo medio di riparazione) determina in gran parte per quanto tempo il sistema funzionerà in uno stato compromesso. Inoltre, qualsiasi evento di rete che influenzi le comunicazioni tra zone può ostacolare in modo significativo le richieste di scrittura a causa della natura sincrona della replica.
Il servizio OpenSearch utilizza un protocollo di comunicazione interno da nodo a nodo per replicare il traffico di scrittura e coordinare gli aggiornamenti dei metadati tramite un leader eletto. Di conseguenza, mettere in standby la zona sottoposta a stress non risolverebbe efficacemente il problema della compromissione della scrittura.
Failover di scrittura zonale: interruzione del traffico di replica tra zone
Per Multi-AZ con Standby, per mitigare potenziali problemi di prestazioni causati da eventi imprevisti come guasti di zona ed eventi di rete, il failover di scrittura di zona è un approccio efficace. Questo approccio prevede la rimozione graduale dei nodi nella zona interessata dal cluster, interrompendo di fatto il traffico in entrata e in uscita tra le zone. Interrompendo il traffico di replica tra zone, l'impatto degli errori di zona può essere contenuto all'interno della zona interessata. Ciò fornisce un'esperienza più prevedibile per i clienti e garantisce che il sistema continui a funzionare in modo affidabile.
Failover di scrittura grazioso
L'orchestrazione di un failover di scrittura all'interno del servizio OpenSearch viene effettuata dal nodo leader eletto attraverso un meccanismo ben definito. Questo meccanismo prevede un protocollo di consenso per la pubblicazione dello stato del cluster, garantendo un accordo unanime tra tutti i nodi per designare una singola zona (in ogni momento) per lo smantellamento. È importante sottolineare che i metadati relativi alla zona interessata vengono replicati su tutti i nodi per garantirne la persistenza, anche durante un riavvio completo in caso di interruzione.
Inoltre, il nodo leader garantisce una transizione fluida e agevole mettendo inizialmente i nodi nelle zone interessate in standby per una durata di 5 minuti prima di avviare il fencing I/O. Questo approccio deliberato impedisce che qualsiasi nuovo traffico del coordinatore o traffico di query sullo shard venga indirizzato ai nodi all'interno della zona interessata. Ciò, a sua volta, consente a questi nodi di completare le loro attività in corso con garbo e di gestire gradualmente eventuali richieste in volo prima di essere messi fuori servizio. Il diagramma seguente illustra questa architettura.
Nel processo di implementazione di un failover di scrittura per un nodo principale, il servizio OpenSearch segue questi passaggi chiave:
- Abdicazione del leader – Se il nodo leader si trova in una zona pianificata per il failover di scrittura, il sistema garantisce che il nodo leader lasci volontariamente il suo ruolo di leadership. Questa abdicazione viene effettuata in modo controllato e l’intero processo viene affidato a un altro nodo idoneo, che poi si fa carico delle azioni richieste.
- Impedire la rielezione del leader da destituire – Per impedire la rielezione di un leader da una zona contrassegnata per il failover di scrittura, quando il nodo leader idoneo avvia l'azione di failover di scrittura, adotta misure per garantire che eventuali nodi leader da dismettere non partecipino ad ulteriori elezioni. Ciò si ottiene escludendo il nodo leader da dismettere dalla configurazione di voto, impedendogli di fatto di votare durante qualsiasi fase critica del funzionamento del cluster.
I metadati relativi alla zona di failover di scrittura vengono archiviati nello stato del cluster e queste informazioni vengono pubblicate su tutti i nodi nel cluster distribuito del servizio OpenSearch come segue:
Nella schermata seguente viene illustrato che durante un rallentamento della rete in una zona, il failover di scrittura aiuta a ripristinare la disponibilità.
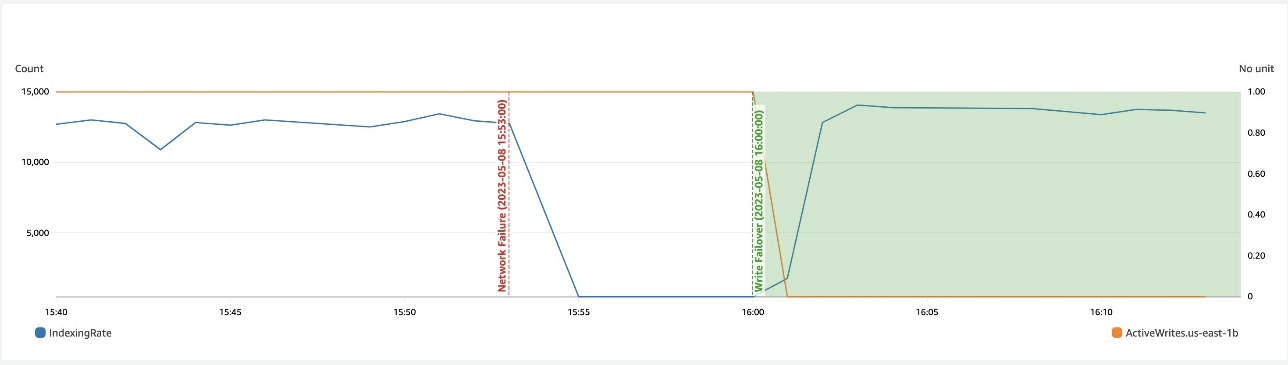
Ripristino zonale dopo il failover di scrittura
Il processo di ricommissioning di zona svolge un ruolo cruciale nella fase di ripristino successiva a un failover di scrittura di zona. Dopo che la zona interessata sarà stata ripristinata e sarà considerata stabile, i nodi precedentemente disattivati si riuniranno al cluster. Questa riattivazione avviene generalmente entro un intervallo di tempo di 2 minuti dopo la riattivazione della zona.
Ciò consente loro di sincronizzarsi con i propri nodi peer e di avviare il processo di ripristino per i frammenti di replica, ripristinando di fatto il cluster allo stato desiderato.
Conclusione
L'introduzione di OpenSearch Service Multi-AZ con Standby fornisce alle aziende una potente soluzione per ottenere elevata disponibilità e prestazioni costanti per i carichi di lavoro critici. Con questa opzione di implementazione, le aziende possono migliorare la resilienza della propria infrastruttura, semplificare la configurazione e la gestione dei cluster e applicare le migliori pratiche. Con funzionalità come la selezione ponderata delle copie shard round robin, meccanismi di failover proattivi e zone di disponibilità standby con apertura in caso di errore, OpenSearch Service Multi-AZ con Standby garantisce un'esperienza di ricerca affidabile ed efficiente per ambienti aziendali esigenti.
Per ulteriori informazioni su Multi-AZ con Standby, fare riferimento a Servizio Amazon OpenSearch Sotto il cofano: Multi-AZ con standby.
L'autore
 Anshu Agarwal è un ingegnere software senior che lavora su AWS OpenSearch presso Amazon Web Services. È appassionata di risolvere problemi legati alla costruzione di sistemi scalabili e altamente affidabili.
Anshu Agarwal è un ingegnere software senior che lavora su AWS OpenSearch presso Amazon Web Services. È appassionata di risolvere problemi legati alla costruzione di sistemi scalabili e altamente affidabili.
 Rishab Nahata è un ingegnere del software che lavora su OpenSearch presso Amazon Web Services. È affascinato dalla risoluzione di problemi nei sistemi distribuiti. Collabora attivamente con OpenSearch.
Rishab Nahata è un ingegnere del software che lavora su OpenSearch presso Amazon Web Services. È affascinato dalla risoluzione di problemi nei sistemi distribuiti. Collabora attivamente con OpenSearch.
 Bukhtawar Khan è un ingegnere principale che lavora su Amazon OpenSearch Service. È interessato ai sistemi distribuiti e autonomi. È un collaboratore attivo di OpenSearch.
Bukhtawar Khan è un ingegnere principale che lavora su Amazon OpenSearch Service. È interessato ai sistemi distribuiti e autonomi. È un collaboratore attivo di OpenSearch.
 Ranjith Ramachandra è un Engineering Manager che lavora su Amazon OpenSearch Service presso Amazon Web Services.
Ranjith Ramachandra è un Engineering Manager che lavora su Amazon OpenSearch Service presso Amazon Web Services.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- PlatoData.Network Generativo verticale Ai. Potenzia te stesso. Accedi qui.
- PlatoAiStream. Intelligenza Web3. Conoscenza amplificata. Accedi qui.
- PlatoneESG. Carbonio, Tecnologia pulita, Energia, Ambiente, Solare, Gestione dei rifiuti. Accedi qui.
- Platone Salute. Intelligence sulle biotecnologie e sulle sperimentazioni cliniche. Accedi qui.
- Fonte: https://aws.amazon.com/blogs/big-data/achieve-high-availability-in-amazon-opensearch-multi-az-with-standby-enabled-domains-a-deep-dive-into-failovers/
- :ha
- :È
- :non
- :Dove
- 1
- 10
- 100
- 12
- 30
- 501
- a
- Chi siamo
- Raggiungere
- raggiunto
- riconosciuto
- operanti in
- Legge
- Action
- azioni
- attivo
- adattabile
- Inoltre
- indirizzo
- influenzato
- Dopo shavasana, sedersi in silenzio; saluti;
- Accordo
- algoritmo
- Algoritmi
- Tutti
- consentire
- Amazon
- Amazon Web Services
- tra
- an
- ed
- Un altro
- in qualsiasi
- approccio
- architettura
- SONO
- AS
- addetto
- At
- autonomo
- sistemi autonomi
- disponibilità
- consapevolezza
- AWS
- di riserva
- equilibratore
- BE
- perché
- stato
- prima
- essendo
- MIGLIORE
- best practice
- fra
- entrambi
- BROADCAST
- Costruzione
- aziende
- by
- Materiale
- Ultra-Grande
- svolta
- ha causato
- caratterizzato
- carica
- controllato
- Cluster
- Comunicazione
- Comunicazioni
- completamento di una
- Configurazione
- Consenso
- conseguentemente
- considerato
- coerente
- consolle
- contenute
- continua
- continuo
- contribuire
- collaboratore
- controllata
- coordinamento
- dell'esame
- coordinatori
- copie
- coperto
- creare
- crea
- critico
- cruciale
- Clienti
- taglio
- dati
- decide
- deep
- profonda immersione
- definisce
- ritardi
- scavare
- esigente
- deployment
- Distribuisce
- designato
- progettato
- desiderato
- individuare
- rilevato
- determina
- indirizzato
- Rottura
- distribuito
- sistemi distribuiti
- immersione
- do
- documenti
- dominio
- domini
- Dont
- giù
- dovuto
- durata
- durante
- ogni
- Efficace
- in maniera efficace
- efficiente
- eletto
- Elezioni
- eleggibile
- eliminando
- abilitato
- Abilita
- imporre
- ingegnere
- Ingegneria
- accrescere
- migliorata
- migliorando
- garantire
- assicura
- assicurando
- Impresa
- Intero
- ambienti
- particolarmente
- Etere (ETH)
- Anche
- Evento
- eventi
- alla fine
- Ogni
- esclusa
- esperienza
- sperimentare
- esplora
- fallisce
- Fallimento
- fallimenti
- caratteristica
- Caratteristiche
- scherma
- Nome
- i seguenti
- segue
- Nel
- TELAIO
- da
- pieno
- ulteriormente
- gif
- Grazioso
- gradualmente
- di garanzia
- cura
- maniglia
- Maniglie
- accade
- he
- sano
- aiuta
- Alta
- vivamente
- cappuccio
- di hosting
- Come
- http
- HTTPS
- identificare
- if
- illustra
- Impact
- impattato
- menomazione
- Implementazione
- importante
- in
- includere
- indicando
- informazioni
- Infrastruttura
- inizialmente
- iniziati
- avviando
- istanze
- interessato
- interno
- ai miglioramenti
- introdotto
- Introduzione
- comporta
- problema
- sicurezza
- IT
- SUO
- jpg
- json
- Le
- conosciuto
- maggiormente
- leader
- Leadership
- piace
- Lista
- caricare
- a livello locale
- collocato
- Lunghi
- mantenere
- mantenimento
- gestito
- gestione
- direttore
- modo
- segnato
- abbinato
- significare
- si intende
- analisi
- meccanismo
- meccanismi di
- Metadati
- Metrica
- minuto
- verbale
- Ridurre la perdita dienergia con una
- Moda
- modello
- Scopri di più
- movimento
- Natura
- necessaria
- Bisogno
- Rete
- internazionale
- New
- no
- nodo
- nodi
- notevole
- oggetto
- of
- MENO
- on
- ONE
- in corso
- esclusivamente
- aprire
- operare
- operazione
- Operazioni
- Opzione
- or
- orchestrazione
- minimo
- Altro
- su
- interruzione
- interruzioni
- ancora
- partecipare
- Ricambi
- appassionato
- sentiero
- percorsi
- pera
- performance
- persistenza
- fase
- sistemazione
- Platone
- Platone Data Intelligence
- PlatoneDati
- gioca
- Post
- potenziale
- potente
- pratiche
- precedente
- Prevedibile
- prevenire
- prevenzione
- impedisce
- in precedenza
- primario
- Direttore
- Proactive
- problemi
- processi
- promuoverlo
- protocollo
- fornire
- fornisce
- Pubblicazione
- pubblicato
- Mettendo
- query
- Leggi
- ricevere
- riceve
- recentemente
- Recuperare
- recupero
- recupero
- riferimento
- regione
- Basic
- relazionato
- pertinente
- problemi di
- affidabile
- fare affidamento
- rimanente
- rimozione
- riparazione
- replica
- replicato
- replicazione
- richiesta
- richieste
- necessario
- elasticità
- elastico
- risolvere
- responsabile
- ripristinare
- restaurato
- il ripristino
- Ruolo
- instradamento
- Correre
- corre
- s
- garanzie
- stesso
- scalabile
- in programma
- senza soluzione di continuità
- Cerca
- prodotti
- invio
- invia
- anziano
- inviato
- servizio
- Servizi
- set
- lei
- mostrato
- significativamente
- semplicità
- semplificare
- singolo
- Rallenta
- rallentamenti
- lisciare
- So
- Software
- Software Engineer
- soluzione
- Soluzione
- stabile
- Regione / Stato
- Stato dei servizi
- costante
- Passi
- memorizzati
- stress
- Successivamente
- di successo
- suscettibilità
- sistema
- SISTEMI DI TRATTAMENTO
- Fai
- preso
- prende
- task
- che
- Il
- loro
- Li
- poi
- Là.
- Strumenti Bowman per analizzare le seguenti finiture:
- questo
- quelli
- tre
- Attraverso
- tempo
- volte
- a
- tolleranza
- traffico
- transizione
- TURNO
- seconda
- tipicamente
- per
- sottostante
- imprevisto
- Aggiornamenti
- utilizzato
- Utente
- usa
- utilizzando
- utilizza
- vario
- volontariamente
- Voto
- we
- sito web
- servizi web
- peso
- WELL
- ben definita
- sono stati
- quando
- quale
- while
- volere
- con
- entro
- lavoro
- lavori
- scrivere
- zefiro
- zero
- zone