
Immagine da Bing Image Creator
L'Exploratory Data Analysis (EDA) è il singolo compito più importante da svolgere all'inizio di ogni progetto di data science.
In sostanza, si tratta di esaminare e caratterizzare a fondo i dati per trovarne il sottostante caratteristiche, possibile anomalie, e nascosto modelli ed relazioni.
Questa comprensione dei tuoi dati è ciò che alla fine guida attraverso i seguenti passaggi di voi pipeline di machine learning, dalla pre-elaborazione dei dati alla creazione di modelli e all'analisi dei risultati.
Il processo dell'EDA comprende fondamentalmente tre compiti principali:
- Passo 1: Panoramica del set di dati e statistiche descrittive
- Passo 2: Valutazione e visualizzazione delle funzionalitàe
- Passo 3: Valutazione della qualità dei dati
Come avrai intuito, ognuna di queste attività può comportare una quantità abbastanza completa di analisi, che ti conquisteranno facilmente affettare, stampare e tracciare i dataframe dei tuoi panda come un pazzo.
A meno che tu non scelga lo strumento giusto per il lavoro.
In questo articolo, ci tufferemo in ogni fase di un efficace processo EDA, e discuti perché dovresti girare ydata-profilazione nel tuo sportello unico per padroneggiarlo.
A dimostrare le migliori pratiche e analizzare gli approfondimenti, useremo il Set di dati sul reddito del censimento degli adulti, liberamente disponibile su Kaggle o UCI Repository (Licenza: CC0: dominio pubblico).
Quando mettiamo le mani per la prima volta su un set di dati sconosciuto, c'è un pensiero automatico che si apre subito: Con cosa sto lavorando?
Dobbiamo avere una profonda comprensione dei nostri dati per gestirli in modo efficiente nelle future attività di machine learning
Come regola generale, tradizionalmente iniziamo caratterizzando i dati relativamente al numero di osservazioni, numero e tipi di funzionalità, complessivamente tasso mancante, e percentuale di duplicare osservazioni.
Con qualche manipolazione dei panda e il giusto cheatsheet, alla fine potremmo stampare le informazioni di cui sopra con alcuni brevi frammenti di codice:
Panoramica del set di dati: set di dati del censimento degli adulti. Numero di osservazioni, feature, tipi di feature, righe duplicate e valori mancanti. Frammento per autore.
Tutto sommato, il formato di output non è l'ideale... Se hai familiarità con i panda, conoscerai anche lo standard modus operandi di avviare un processo EDA - df.describe():
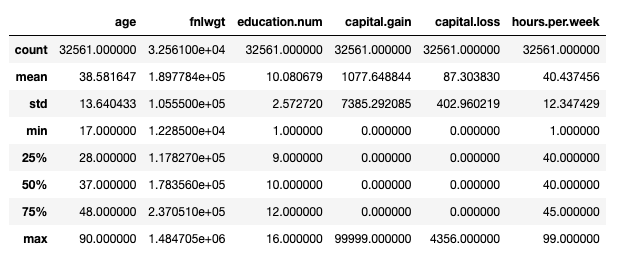
Set di dati per adulti: principali statistiche presentate con df.describe (). Immagine per autore.
Questo, tuttavia, considera solo caratteristiche numeriche. Potremmo usare a df.describe(include='object') per stampare alcune informazioni aggiuntive su caratteristiche categoriali (count, unique, mode, frequency), ma un semplice controllo delle categorie esistenti implicherebbe qualcosa di un po' più prolisso:
Panoramica del set di dati: set di dati del censimento degli adulti. Stampa delle categorie esistenti e delle rispettive frequenze per ciascuna caratteristica categoriale nei dati. Frammento per autore.
Tuttavia, possiamo farlo - e indovina un po', tutte le successive attività EDA! - in una sola riga di codice, utilizzando ydata-profilazione:
Rapporto di profilazione del set di dati del censimento degli adulti, utilizzando ydata-profiling. Frammento per autore.
Il codice precedente genera un report di profilazione completo dei dati, che possiamo utilizzare per spostare ulteriormente il nostro processo EDA, senza la necessità di scrivere altro codice!
Esamineremo le varie sezioni del rapporto nelle sezioni seguenti. Per quanto riguarda il caratteristiche generali dei dati, tutte le informazioni che stavamo cercando sono incluse nel file Panoramica pagina:
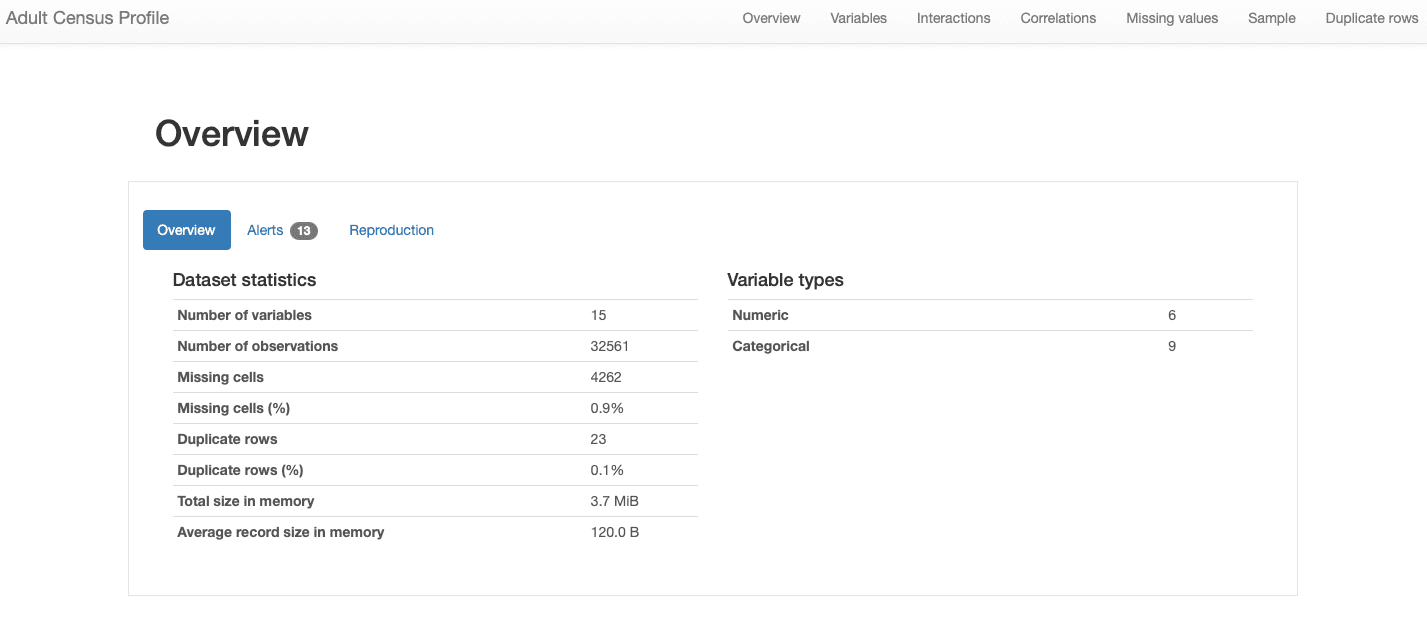
ydata-profiling: report di profilazione dei dati — Panoramica del set di dati. Immagine per autore.
Possiamo vedere che il nostro set di dati comprende 15 feature e 32561 osservazioni, con 23 record duplicati e un tasso complessivo mancante dello 0.9%.
Inoltre, il set di dati è stato correttamente identificato come a set di dati tabulare, e piuttosto eterogeneo, presentando entrambi caratteristiche numeriche e categoriche. For
dati di serie temporali, che ha dipendenza dal tempo e presenta diversi tipi di pattern, ydata-profiling incorporerebbe altre statistiche e analisi nel rapporto.
Possiamo ispezionare ulteriormente il dati grezzi e record duplicati esistenti per avere una comprensione generale delle caratteristiche, prima di addentrarsi in analisi più complesse:
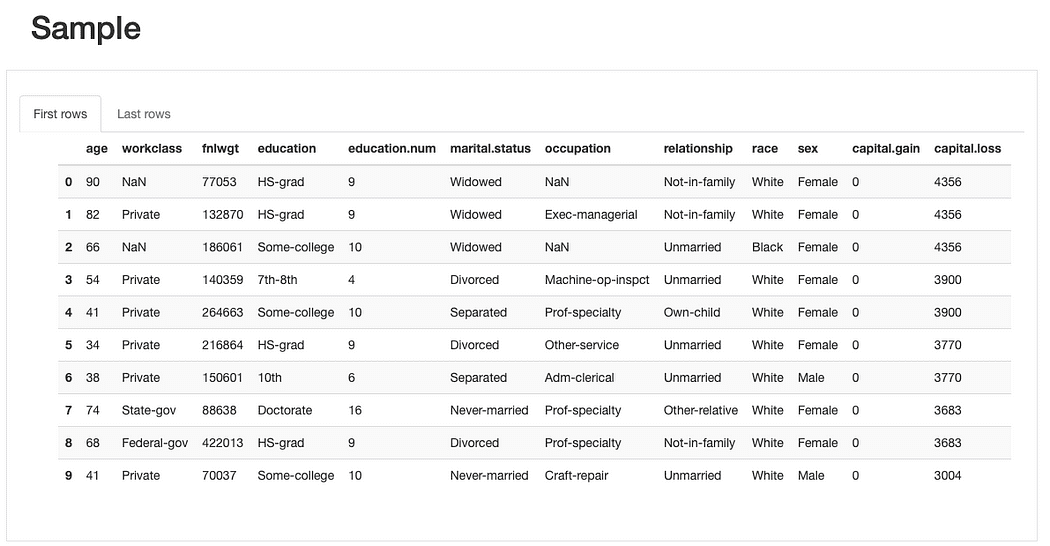
ydata-profiling: rapporto di profilazione dei dati — Anteprima di esempio. Immagine per autore.
Dalla breve anteprima di esempio del campione di dati, possiamo vedere subito che sebbene il set di dati abbia una bassa percentuale di dati mancanti nel complesso, alcune funzionalità potrebbero risentirne più degli altri. Possiamo anche identificare un piuttosto numero considerevole di categorie per alcune funzionalità e funzionalità con valore 0 (o almeno con una quantità significativa di 0).
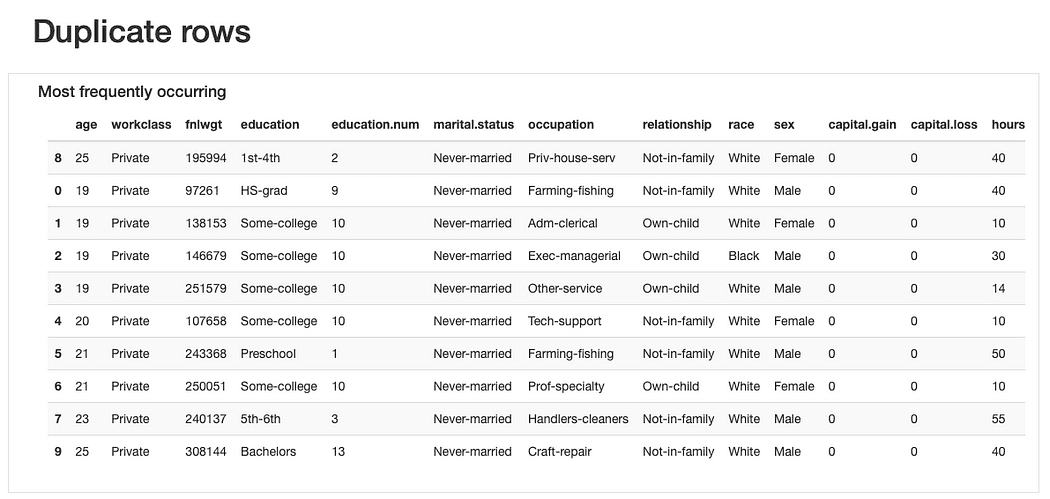
ydata-profiling: rapporto di profilazione dei dati: anteprima delle righe duplicate. Immagine per autore.
Per quanto riguarda le righe duplicate, non sarebbe strano trovare osservazioni "ripetute" dato che la maggior parte delle caratteristiche rappresentano categorie in cui più persone potrebbero "inserirsi" contemporaneamente.
Eppure, forse a "odore di dati" potrebbe essere che queste osservazioni condividano lo stesso age valori (che è plausibile) e lo stesso identico fnlwgt che, visti i valori presentati, sembra più difficile da credere. Quindi sarebbero necessarie ulteriori analisi, ma dovremmo molto probabilmente elimina questi duplicati più tardi.
Nel complesso, la panoramica dei dati potrebbe essere un'analisi semplice, ma una estremamente d'impatto, in quanto ci aiuterà a definire le attività imminenti nella nostra pipeline.
Dopo aver dato un'occhiata ai descrittori generali dei dati, dobbiamo farlo ingrandire le funzionalità del nostro set di dati, al fine di ottenere alcune informazioni sulle loro proprietà individuali - Analisi invariate - così come le loro interazioni e relazioni - Analisi multivariata.
Entrambi i compiti fanno molto affidamento su ricercare statistiche e visualizzazioni adeguate, che devono essere adattato al tipo di funzione a portata di mano (ad esempio, numerico, categorico), e il comportamento stiamo cercando di sezionare (ad esempio, interazioni, correlazioni).
Diamo un'occhiata alle best practice per ogni attività.
Analisi invariate
Analizzare le caratteristiche individuali di ciascuna funzione è fondamentale in quanto ci aiuterà a decidere in merito rilevanza per l'analisi e la tipo di preparazione dei dati possono richiedere per ottenere risultati ottimali.
Ad esempio, potremmo trovare valori che sono estremamente fuori intervallo e potrebbero fare riferimento a incongruenze or valori anomali. Potremmo averne bisogno standardizzare numerico dati o eseguire un file codifica one-hot di categoriale caratteristiche, a seconda del numero di categorie esistenti. Oppure potremmo dover eseguire un'ulteriore preparazione dei dati per gestire le caratteristiche numeriche che sono spostato o inclinato, se l'algoritmo di machine learning che intendiamo utilizzare prevede una particolare distribuzione (normalmente gaussiana).
Le migliori pratiche richiedono quindi l'indagine approfondita delle singole proprietà come le statistiche descrittive e la distribuzione dei dati.
Questi evidenzieranno la necessità di attività successive di rimozione dei valori anomali, standardizzazione, codifica delle etichette, imputazione dei dati, aumento dei dati e altri tipi di pre-elaborazione.
Indaghiamo race ed capital.gain più in dettaglio. Cosa possiamo individuare immediatamente?
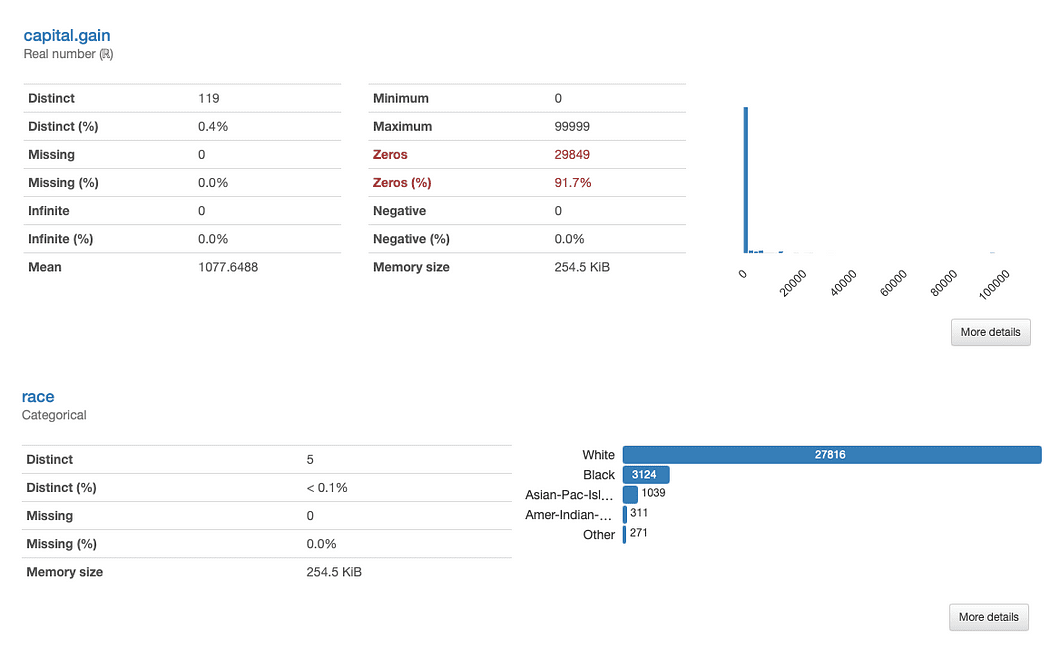
ydata-profiling: Profiling Report (razza e capital.gain). Immagine per autore.
La valutazione di plusvalenza è semplice:
Data la distribuzione dei dati, potremmo chiederci se la funzione aggiunge valore alla nostra analisi, poiché il 91.7% dei valori è "0".
Analisi gara è leggermente più complesso:
C'è una chiara sottorappresentazione di razze diverse da White. Questo porta alla mente due problemi principali:
- Uno è la tendenza generale degli algoritmi di apprendimento automatico a trascurare concetti meno rappresentati, noto come il problema di piccoli disgiunti, che porta a prestazioni di apprendimento ridotte;
- L'altro è in qualche modo derivato da questo problema: poiché abbiamo a che fare con una caratteristica delicata, questa "tendenza a trascurare" può avere conseguenze che si riferiscono direttamente a pregiudizio ed equità sicurezza. Qualcosa che sicuramente non vogliamo insinuarsi nei nostri modelli.
Tenendo conto di questo, forse dovremmo prendere in considerazione l'esecuzione di data augmentation condizionata alle categorie sottorappresentate, oltre che in considerazione metriche basate sull'equità per la valutazione del modello, per verificare eventuali discrepanze nelle prestazioni che si riferiscono a race valori.
Forniremo ulteriori dettagli su altre caratteristiche dei dati che devono essere affrontate quando discuteremo le migliori pratiche sulla qualità dei dati (Passaggio 3). Questo esempio mostra solo quante intuizioni possiamo prendere solo valutando ogni singola caratteristica proprietà.
Infine, si noti come, come accennato in precedenza, diversi tipi di funzionalità richiedano statistiche e strategie di visualizzazione diverse:
- Caratteristiche numeriche il più delle volte comprendono informazioni relative a media, deviazione standard, asimmetria, curtosi e altre statistiche quantiliche e sono rappresentate al meglio utilizzando i grafici dell'istogramma;
- Caratteristiche categoriali sono generalmente descritti utilizzando le tabelle di modalità, mediana e frequenza e rappresentati utilizzando grafici a barre per l'analisi delle categorie.
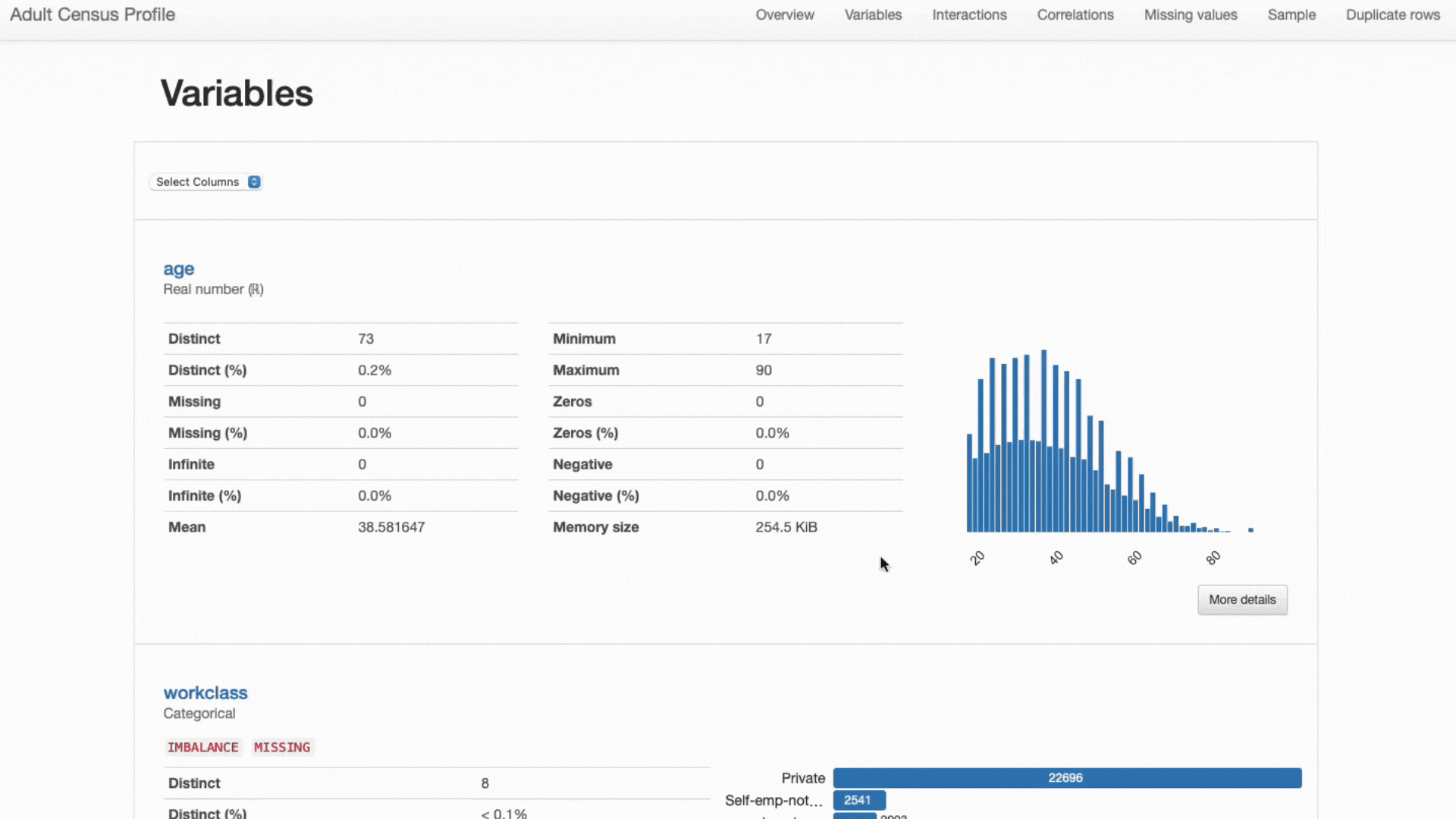
ydata-profiling: rapporto di profilazione. Le statistiche e le visualizzazioni presentate vengono adattate a ciascun tipo di funzionalità. Screencast per autore.
Un'analisi così dettagliata sarebbe ingombrante da eseguire con la manipolazione generale dei panda, ma per fortuna ydata-profiling ha tutte queste funzionalità integrate nel ProfileReport per nostra comodità: allo snippet non sono state aggiunte ulteriori righe di codice!
Analisi multivariata
Per l'analisi multivariata, le migliori pratiche si concentrano principalmente su due strategie: analizzare il interazioni tra le caratteristiche e analizzando le loro correlazioni.
Analizzare le interazioni
Le interazioni ci permettono esplorare visivamente come si comporta ciascuna coppia di funzioni, cioè come i valori di una caratteristica si relazionano con i valori dell'altra.
Ad esempio, possono esibire positivo or negativo. relazioni, a seconda che all'aumento dei propri valori sia associato rispettivamente un aumento o una diminuzione dei valori dell'altro.
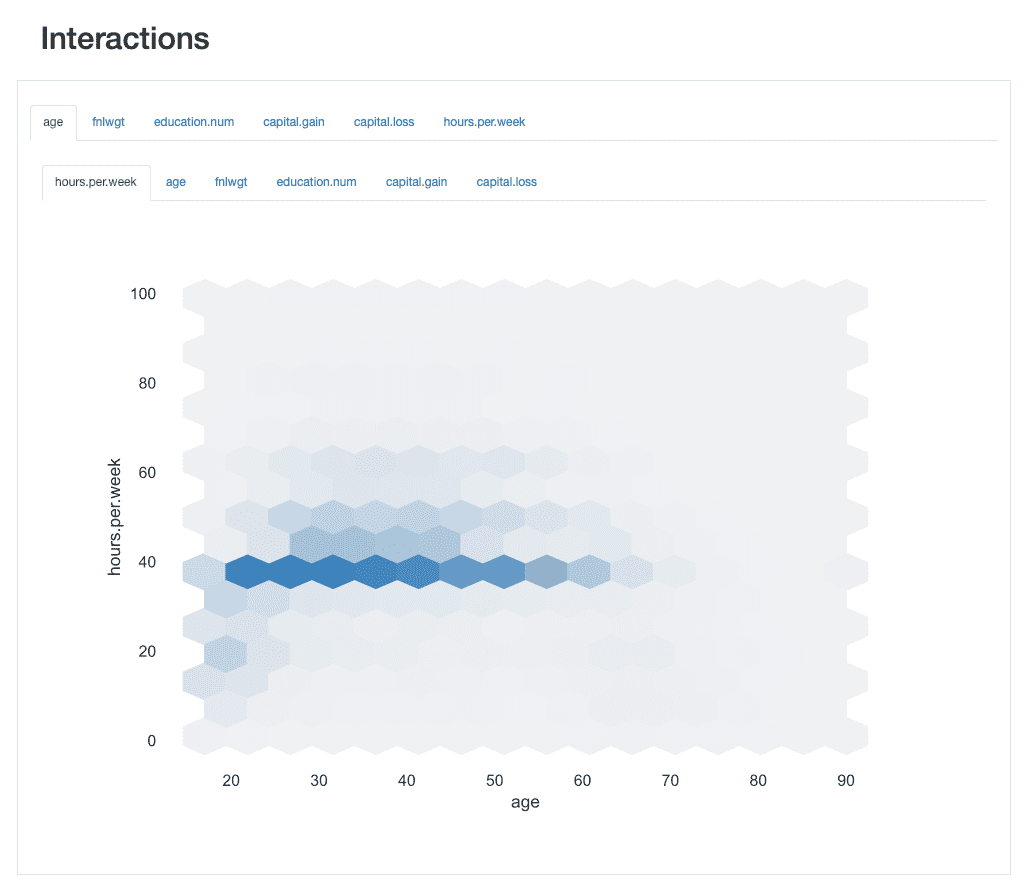
ydata-profiling: Rapporto di profilazione — Interazioni. Immagine per autore.
Prendendo l'interazione tra age ed hours.per.weekad esempio, possiamo vedere che la grande maggioranza della forza lavoro lavora uno standard di 40 ore. Tuttavia, ci sono alcune "api indaffarate" che lavorano oltre (fino a 60 o anche 65 ore) tra i 30 e i 45 anni. Le persone di 20 anni hanno meno probabilità di lavorare troppo e possono avere un programma di lavoro più leggero in alcuni settimane.
Analisi delle correlazioni
Analogamente alle interazioni, le correlazioni ci permettano analizzare la relazione tra le caratteristiche. Le correlazioni, tuttavia, “gli danno un valore”, in modo che sia più facile per noi determinare la “forza” di quella relazione.
Questa "forza" è misurato da coefficienti di correlazione e può essere analizzato sia numericamente (ad esempio, ispezionando a matrice di correlazione) o con a mappa di calore, che utilizza il colore e l'ombreggiatura per evidenziare visivamente modelli interessanti:
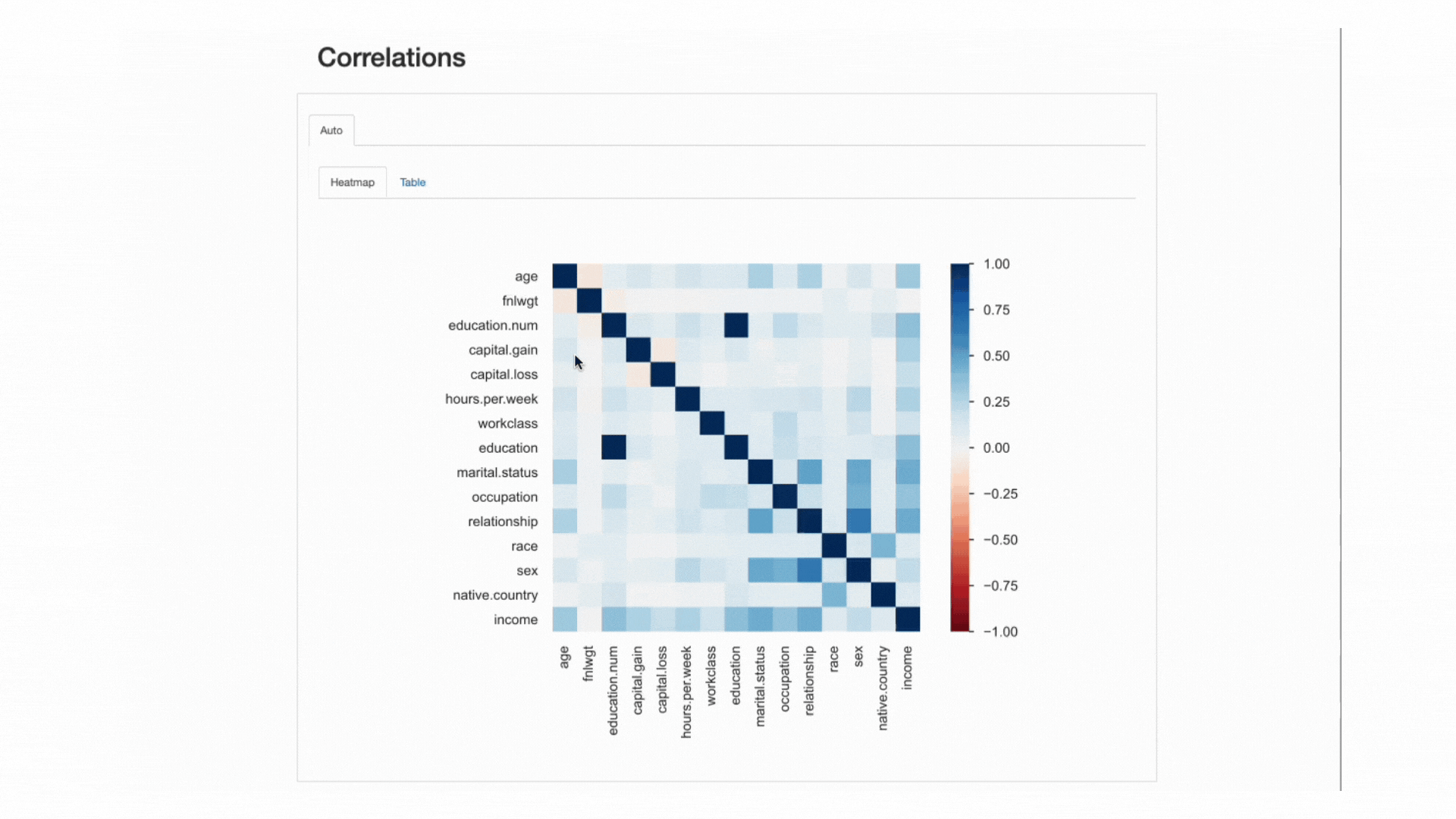
ydata-profiling: Rapporto di profilazione — Heatmap e matrice di correlazione. Screencast per autore.
Per quanto riguarda il nostro set di dati, nota come la correlazione tra education ed education.num spicca. Infatti, contengono le stesse informazionie education.num è solo un binning del education valori.
Un altro modello che cattura l'attenzione è la correlazione tra sex ed relationship anche se ancora una volta non molto istruttivo: osservando i valori di entrambe le caratteristiche, ci renderemmo conto che queste caratteristiche sono molto probabilmente correlate perché male ed female corrisponderà a husband ed wife, Rispettivamente.
Questo tipo di ridondanze può essere controllato per vedere se possiamo rimuovere alcune di queste funzionalità dall'analisi (marital.status è anche correlato a relationship ed sex; native.country ed race ad esempio, tra gli altri).
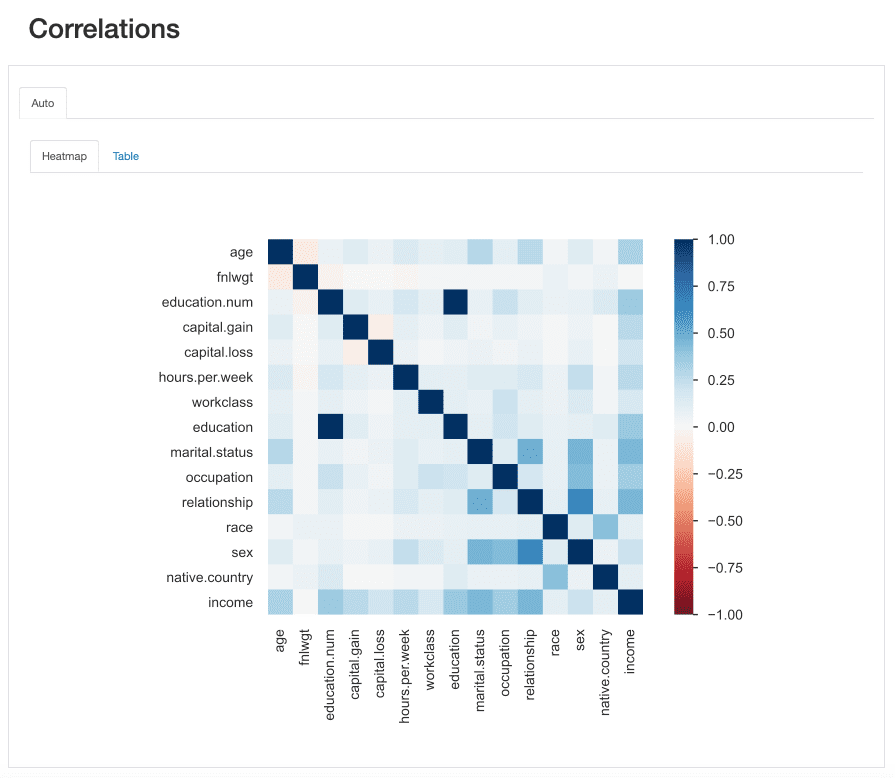
ydata-profiling: Profiling Report — Correlazioni. Immagine per autore.
Tuttavia, ci sono altre correlazioni che spiccano e potrebbero essere interessanti ai fini della nostra analisi.
Ad esempio, la correlazione trasex ed occupation, o sex ed hours.per.week.
Infine, le correlazioni tra income e le restanti funzionalità sono davvero informative, specialmente nel caso in cui stiamo cercando di mappare un problema di classificazione. Sapendo cosa sono i più correlati caratteristiche alla nostra classe di destinazione ci aiuta a identificare il più discriminante caratteristiche e trovare possibili fughe di dati che potrebbero influenzare il nostro modello.
Dalla heatmap, sembra che marital.status or relationship sono tra i predittori più importanti, mentre fnlwgt per esempio, non sembra avere un grande impatto sul risultato.
Analogamente ai descrittori e alle visualizzazioni dei dati, anche le interazioni e le correlazioni devono occuparsi dei tipi di funzionalità a portata di mano.
In altre parole, diverse combinazioni saranno misurate con diversi coefficienti di correlazione. Per impostazione predefinita, ydata-profiling correlazioni su auto, che significa che:
- Numerico contro Numerico le correlazioni sono misurate utilizzando Grado di Spearman coefficiente di correlazione;
- Categorico contro Categorico le correlazioni sono misurate utilizzando Cramer V;
- Numerico contro categorico le correlazioni usano anche V di Cramer, dove la caratteristica numerica viene prima discretizzata;
E se vuoi controllare altri coefficienti di correlazione (ad es. Pearson's, Kendall's, Phi) puoi facilmente configurare i parametri del report.
Mentre navighiamo verso a paradigma datacentrico dello sviluppo dell'IA, essendo in cima al possibili fattori complicanti che sorgono nei nostri dati è essenziale.
Con “fattori complicanti”, ci riferiamo a errori che può verificarsi durante la raccolta dei dati del trattamento, o caratteristiche intrinseche dei dati che sono semplicemente un riflesso del natura dei dati.
Questi includono mancante dati, squilibrata dati, costante valori, duplicati, altamente correlato or ridondante Caratteristiche, rumoroso dati, tra gli altri.
Problemi di qualità dei dati: errori e caratteristiche intrinseche dei dati. Immagine per autore.
Trovare questi problemi di qualità dei dati all'inizio di un progetto (e monitorarli continuamente durante lo sviluppo) è fondamentale.
Se non vengono identificati e affrontati prima della fase di costruzione del modello, possono compromettere l'intera pipeline ML e le successive analisi e conclusioni che potrebbero derivarne.
Senza un processo automatizzato, la capacità di identificare e affrontare questi problemi sarebbe lasciata interamente all'esperienza personale e alla competenza della persona che conduce l'analisi EDA, il che ovviamente non è l'ideale. Inoltre, che peso avere sulle spalle, soprattutto considerando i set di dati ad alta dimensione. Avviso incubo in arrivo!
Questa è una delle caratteristiche più apprezzate di ydata-profiling, le generazione automatica di avvisi sulla qualità dei dati:
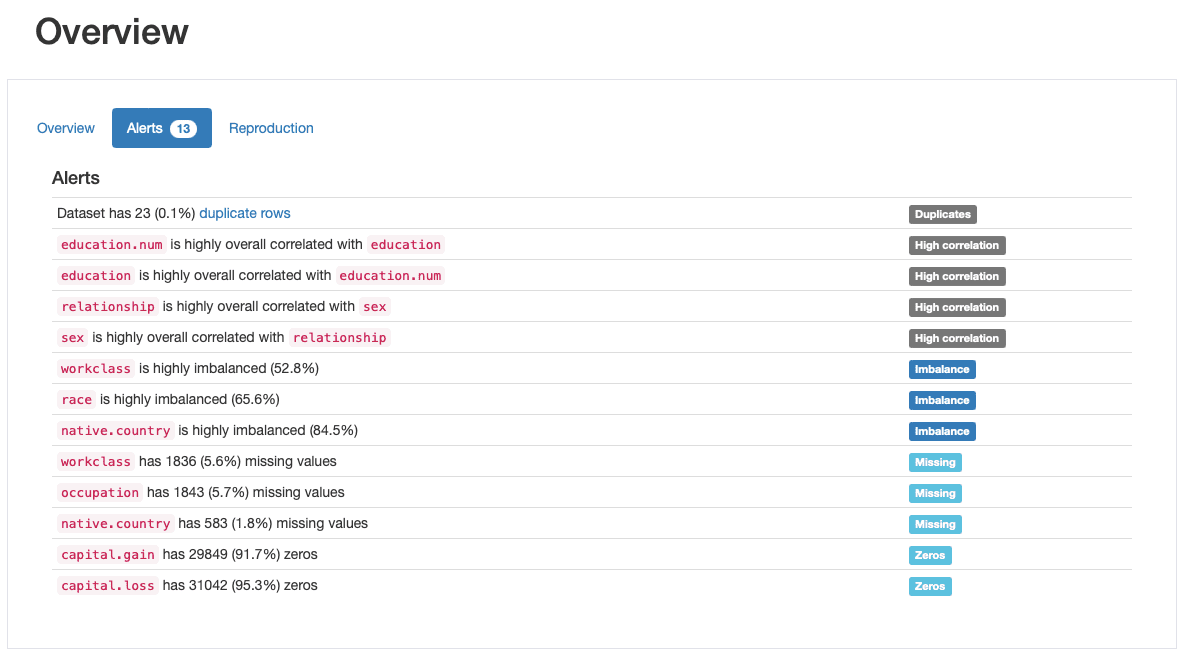
ydata-profiling: Rapporto di profilazione — Avvisi sulla qualità dei dati. Immagine per autore.
Il profilo emette almeno 5 diversi tipi di problemi di qualità dei dati, vale a dire duplicates, high correlation, imbalance, missinge zeros.
In effetti, ne avevamo già identificati alcuni in precedenza, durante il passaggio 2: race è una caratteristica altamente squilibrata e capital.gain è prevalentemente popolato da 0. Abbiamo anche visto la stretta correlazione tra education ed education.nume relationship ed sex.
Analisi dei modelli di dati mancanti
Tra l'ampia gamma di segnalazioni considerate, ydata-profiling è particolarmente utile in analizzare modelli di dati mancanti.
Poiché i dati mancanti sono un problema molto comune nei domini del mondo reale e possono compromettere del tutto l'applicazione di alcuni classificatori o falsare gravemente le loro previsioni, un'altra best practice è analizzare attentamente i dati mancanti percentuale e comportamento che le nostre funzioni potrebbero mostrare:
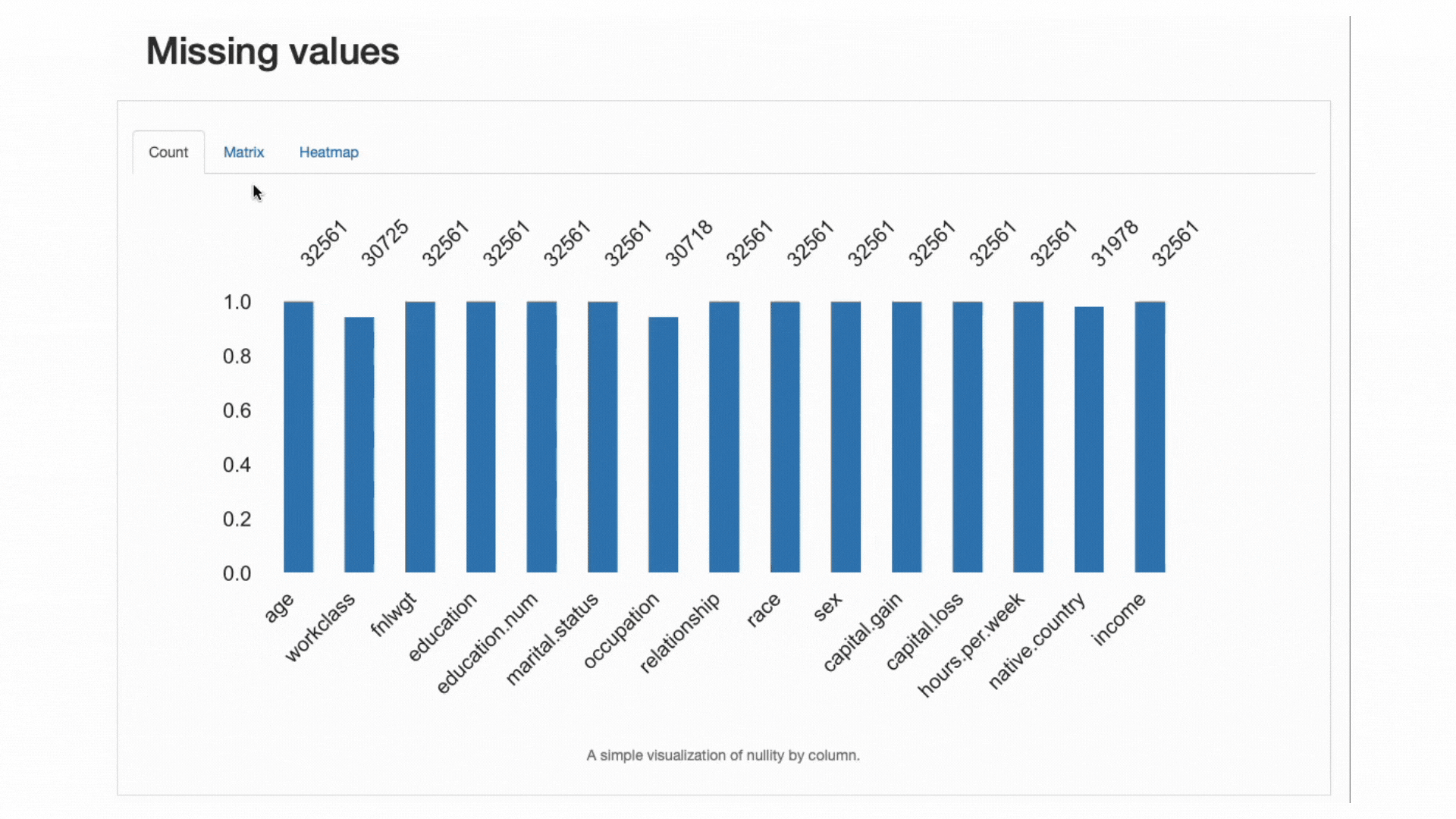
ydata-profiling: rapporto di profilazione — analisi dei valori mancanti. Screencast per autore.
Dalla sezione degli avvisi sui dati, lo sapevamo già workclass, occupatione native.country aveva osservazioni assenti. La heatmap ci dice inoltre che esiste una relazione diretta con il modello mancante in occupation ed workclass: quando c'è un valore mancante in una caratteristica, mancherà anche l'altra.
Intuizione chiave: la profilazione dei dati va oltre l'EDA!
Finora, abbiamo discusso le attività che costituiscono un completo processo EDA e come la valutazione dei problemi e delle caratteristiche della qualità dei dati - un processo che possiamo definire Data Profiling - è sicuramente una buona pratica.
Tuttavia, è importante chiarirlo profilazione dei dati va oltre l'EDA. Considerando che generalmente definiamo EDA come il passaggio esplorativo e interattivo prima di sviluppare qualsiasi tipo di pipeline di dati, la profilazione dei dati è un processo iterativo che dovrebbe avvenire ad ogni passo della preelaborazione dei dati e della costruzione del modello.
Un EDA efficiente pone le basi per una pipeline di machine learning di successo.
È come eseguire una diagnosi sui tuoi dati, imparando tutto ciò che devi sapere su ciò che comporta: è proprietà, relazioni, sicurezza - in modo che tu possa affrontarli in seguito nel miglior modo possibile.
È anche l'inizio della nostra fase di ispirazione: è dall'EDA che iniziano a sorgere domande e ipotesi, e le analisi sono pianificate per convalidarle o rifiutarle lungo il percorso.
In tutto l'articolo, abbiamo coperto i 3 passi fondamentali principali che ti guideranno attraverso un EDA efficace, e discusso l'impatto di avere uno strumento di prim'ordine - ydata-profiling - per indicarci la giusta direzione, e ci fa risparmiare un'enorme quantità di tempo e onere mentale.
Spero che questa guida ti aiuti a padroneggiare l'arte di "giocare al detective dei dati" e come sempre, feedback, domande e suggerimenti sono molto apprezzati. Fammi sapere di quali altri argomenti vorrei che scrivessi, o meglio ancora, vieni a trovarmi al Comunità AI incentrata sui dati e collaboriamo!
Miriam Santo concentrarsi sull'educazione delle comunità di data science e machine learning su come passare da dati grezzi, sporchi, "cattivi" o imperfetti a dati intelligenti, intelligenti e di alta qualità, consentendo ai classificatori di machine learning di trarre conclusioni accurate e affidabili in diversi settori (Fintech , sanità e farmaceutica, telecomunicazioni e vendita al dettaglio).
Originale. Ripubblicato con il permesso.
- Distribuzione di contenuti basati su SEO e PR. Ricevi amplificazione oggi.
- EVM Finance. Interfaccia unificata per la finanza decentralizzata. Accedi qui.
- Quantum Media Group. IR/PR amplificato. Accedi qui.
- PlatoAiStream. Intelligenza dei dati Web3. Conoscenza amplificata. Accedi qui.
- Fonte: https://www.kdnuggets.com/2023/06/data-scientist-essential-guide-exploratory-data-analysis.html?utm_source=rss&utm_medium=rss&utm_campaign=a-data-scientists-essential-guide-to-exploratory-data-analysis
- :ha
- :È
- :non
- :Dove
- $ SU
- 1
- 30
- 40
- 60
- 65
- 91
- a
- capacità
- Chi siamo
- sopra
- assente
- Il mio account
- preciso
- Raggiungere
- operanti in
- aggiunto
- aggiuntivo
- Informazioni aggiuntive
- indirizzo
- Aggiunge
- Rettificato
- Adulto
- influenzare
- ancora
- Ages
- AI
- avvisi
- algoritmo
- Algoritmi
- Tutti
- lungo
- già
- anche
- Sebbene il
- del tutto
- sempre
- am
- tra
- tra
- quantità
- an
- .
- analizzare
- analizzato
- l'analisi
- ed
- in qualsiasi
- Applicazioni
- SONO
- Arte
- articolo
- AS
- valutare
- valutazione
- associato
- At
- assistere
- autore
- Automatizzata
- Automatico
- disponibile
- lontano
- Vasca
- bar
- BE
- stato
- prima
- Inizio
- essendo
- CREDIAMO
- MIGLIORE
- best practice
- Meglio
- fra
- Al di là di
- pregiudizio
- Bing
- entrambi
- Porta
- Costruzione
- costruito
- onere
- ma
- by
- chiamata
- Materiale
- capitale
- attentamente
- trasportare
- Custodie
- categoria
- Categoria
- Censimento
- caratteristiche
- dai un'occhiata
- controllato
- classe
- classificazione
- pulire campo
- codice
- collezione
- colore
- combinazioni
- Venire
- Uncommon
- Comunità
- completamento di una
- complesso
- globale
- incluso
- compromesso
- preoccupazioni
- Segui il codice di Condotta
- conduzione
- Conseguenze
- considerato
- considerando
- continuamente
- comodità
- Correlazione
- coefficiente di correlazione
- potuto
- critico
- cruciale
- dati
- analisi dei dati
- Preparazione dei dati
- qualità dei dati
- scienza dei dati
- dataset
- trattare
- decide
- diminuire
- deep
- Predefinito
- decisamente
- Dipendenza
- Dipendente
- derivato
- descritta
- dettaglio
- dettagliati
- Determinare
- in via di sviluppo
- Mercato
- deviazione
- diagnosi
- diverso
- dirette
- direzione
- direttamente
- discutere
- discusso
- discutere
- Dsiplay
- distribuzione
- do
- effettua
- domini
- Dont
- disegnare
- Cadere
- durante
- e
- ogni
- più facile
- facilmente
- educare
- Efficace
- efficiente
- in modo efficiente
- o
- consentendo
- interamente
- errori
- particolarmente
- essenza
- essential
- Etere (ETH)
- Anche
- alla fine
- Ogni
- qualunque cosa
- esaminando
- esempio
- esistente
- aspetta
- esperienza
- competenza
- Analisi dei dati esplorativi
- esplora
- extra
- estremamente
- occhio
- fatto
- familiare
- lontano
- caratteristica
- Caratteristiche
- feedback
- Trovare
- Fintech
- Nome
- Focus
- i seguenti
- Nel
- forza
- formato
- Fondazione
- Frequenza
- da
- funzionalità
- fondamentale
- fondamentalmente
- ulteriormente
- futuro
- Guadagno
- Generale
- generalmente
- genera
- ELETTRICA
- ottenere
- gif
- dato
- Go
- va
- andando
- grande
- indovinato
- guida
- ha avuto
- cura
- maniglia
- Mani
- Avere
- avendo
- assistenza sanitaria
- pesantemente
- Aiuto
- utile
- aiuta
- alta qualità
- Highlight
- vivamente
- tenere
- speranza
- ORE
- Come
- Tutorial
- Tuttavia
- HTTPS
- i
- ideale
- identificato
- identificare
- if
- Immagine
- subito
- Impact
- importante
- in
- incluso
- Reddito
- In arrivo
- Aumento
- individuale
- industrie
- informazioni
- informativo
- intuizione
- intuizioni
- Ispirazione
- esempio
- Intelligente
- intendono
- interazione
- interazioni
- interattivo
- interessante
- ai miglioramenti
- intrinseco
- indagare
- indagine
- coinvolgere
- problema
- sicurezza
- IT
- SUO
- Mettere a repentaglio
- Lavoro
- jpg
- ad appena
- KDnuggets
- Kendall's
- Sapere
- Conoscere
- conosciuto
- curtosi
- Discografica
- dopo
- Lays
- Leads
- apprendimento
- meno
- a sinistra
- meno
- Licenza
- leggera
- piace
- probabile
- linea
- Linee
- piccolo
- Guarda
- cerca
- Basso
- macchina
- machine learning
- Principale
- principalmente
- Maggioranza
- make
- Manipolazione
- carta geografica
- Mastercard
- Matrice
- Maggio..
- me
- significare
- si intende
- misurato
- Soddisfare
- mentale
- menzionato
- Metrica
- forza
- mente
- mancante
- ML
- Moda
- modello
- modelli
- monitoraggio
- Scopri di più
- maggior parte
- cambiano
- molti
- Navigare
- Bisogno
- no
- normalmente
- Avviso..
- numero
- oggetto
- ovvio
- verificarsi
- of
- di frequente
- on
- ONE
- esclusivamente
- ottimale
- or
- minimo
- Altro
- Altri
- nostro
- su
- Risultato
- produzione
- complessivo
- panoramica
- coppia
- panda
- particolare
- passato
- Cartamodello
- modelli
- Persone
- percentuale
- eseguire
- performance
- esecuzione
- Forse
- autorizzazione
- persona
- cronologia
- Pharma
- fase
- scegliere
- conduttura
- previsto
- Platone
- Platone Data Intelligence
- PlatoneDati
- plausibile
- punto
- Pops
- popolata
- possibile
- pratica
- pratiche
- Previsioni
- prevalentemente
- preparazione
- presentata
- regali
- Anteprima
- in precedenza
- Stampa
- stampa
- Precedente
- Problema
- processi
- lavorazione
- Profilo
- profiling
- progetto
- proprietà
- la percezione
- scopo
- qualità
- domanda
- Domande
- Gara
- gamma
- tasso
- piuttosto
- Crudo
- mondo reale
- rendersi conto
- record
- Ridotto
- riflessione
- per quanto riguarda
- relazionato
- rapporto
- Relazioni
- relativamente
- affidabile
- fare affidamento
- rimanente
- rimozione
- rimuovere
- rapporto
- deposito
- rappresentare
- rappresentato
- richiedere
- necessario
- quelli
- rispettivamente
- Risultati
- nello specifico retail
- destra
- Regola
- running
- stesso
- programma
- Scienze
- portata
- Sezione
- sezioni
- vedere
- sembrare
- sembra
- visto
- delicata
- alcuni
- gravemente
- Condividi
- Shop
- Corti
- dovrebbero
- mostrare attraverso le sue creazioni
- significativa
- Un'espansione
- semplicemente
- contemporaneamente
- singolo
- smart
- So
- alcuni
- qualcosa
- piuttosto
- Spot
- Stage
- stare in piedi
- Standard
- si
- inizia a
- Di partenza
- statistica
- step
- Passi
- lineare
- strategie
- successivo
- di successo
- tale
- Fai
- Target
- Task
- task
- dice
- di
- che
- I
- le informazioni
- loro
- Li
- Là.
- perciò
- Strumenti Bowman per analizzare le seguenti finiture:
- di
- questo
- a fondo
- pensiero
- tre
- Attraverso
- tempo
- a
- top
- Argomenti
- verso
- tradizionalmente
- enorme
- veramente
- seconda
- Digitare
- Tipi di
- sottorappresentati
- e una comprensione reciproca
- unico
- Sconosciuto
- fino a quando
- imminenti
- us
- uso
- usa
- utilizzando
- generalmente
- CONVALIDARE
- APPREZZIAMO
- Valori
- vario
- contro
- molto
- visualizzazione
- volere
- Modo..
- we
- Settimane
- peso
- WELL
- è andato
- sono stati
- Che
- quando
- se
- quale
- tutto
- perché
- wikipedia
- volere
- con
- senza
- parole
- Lavora
- lavoro
- lavori
- sarebbe
- scrivere
- ancora
- Tu
- Trasferimento da aeroporto a Sharm
- zefiro
- zoom






