Data geospasial merupakan data mengenai lokasi tertentu di permukaan bumi. Ini dapat mewakili suatu wilayah geografis secara keseluruhan atau dapat mewakili suatu peristiwa yang terkait dengan suatu wilayah geografis. Analisis data geospasial banyak dicari di beberapa industri. Hal ini melibatkan pemahaman di mana data berada dari perspektif spasial dan mengapa data tersebut ada di sana.
Ada dua jenis data geospasial: data vektor dan data raster. Data raster adalah matriks sel yang direpresentasikan sebagai grid, sebagian besar mewakili foto dan citra satelit. Pada postingan kali ini, kami fokus pada data vektor, yang direpresentasikan sebagai koordinat geografis lintang dan bujur serta garis dan poligon (area) yang menghubungkan atau melingkupinya. Data vektor memiliki banyak kegunaan dalam memperoleh wawasan mobilitas. Data seluler pengguna adalah salah satu komponennya, dan sebagian besar berasal dari posisi geografis perangkat seluler yang menggunakan GPS atau penerbit aplikasi yang menggunakan SDK atau integrasi serupa. Untuk tujuan posting ini, kami menyebut data ini sebagai data mobilitas.
Ini adalah seri dua bagian. Pada postingan pertama ini, kami memperkenalkan data mobilitas, sumbernya, dan skema umum data ini. Kami kemudian membahas berbagai kasus penggunaan dan mengeksplorasi bagaimana Anda dapat menggunakan layanan AWS untuk membersihkan data, bagaimana pembelajaran mesin (ML) dapat membantu upaya ini, dan bagaimana Anda dapat menggunakan data secara etis dalam menghasilkan visual dan wawasan. Postingan kedua akan lebih bersifat teknis dan mencakup langkah-langkah ini secara mendetail bersama kode contoh. Postingan ini tidak memiliki contoh kumpulan data atau kode contoh, melainkan membahas cara menggunakan data setelah dibeli dari agregator data.
Anda dapat menggunakan Kemampuan geospasial Amazon SageMaker untuk melapisi data mobilitas pada peta dasar dan memberikan visualisasi berlapis untuk mempermudah kolaborasi. Visualisator interaktif bertenaga GPU dan notebook Python memberikan cara yang mulus untuk menjelajahi jutaan titik data dalam satu jendela dan berbagi wawasan serta hasil.
Sumber dan skema
Sumber data mobilitas hanya sedikit. Selain ping GPS dan penerbit aplikasi, sumber lain digunakan untuk menambah kumpulan data, seperti titik akses Wi-Fi, data aliran tawaran yang diperoleh melalui penayangan iklan di perangkat seluler, dan pemancar perangkat keras tertentu yang ditempatkan oleh bisnis (misalnya, di toko fisik ). Seringkali sulit bagi bisnis untuk mengumpulkan data ini sendiri, sehingga mereka mungkin membelinya dari agregator data. Agregator data mengumpulkan data mobilitas dari berbagai sumber, membersihkannya, menambah kebisingan, dan menyediakan data setiap hari untuk wilayah geografis tertentu. Karena sifat data itu sendiri dan sulitnya memperolehnya, keakuratan dan kualitas data ini bisa sangat bervariasi, dan terserah pada bisnis untuk menilai dan memverifikasinya dengan menggunakan metrik seperti pengguna aktif harian, total ping harian, dan rata-rata ping harian per perangkat. Tabel berikut menunjukkan skema umum feed data harian yang dikirim oleh agregator data.
| Atribut | Deskripsi Produk |
| Id atau PEMBANTU | ID Periklanan Seluler (MAID) perangkat (di-hash) |
| lat | Lintang perangkat |
| lng | Bujur perangkat |
| geohash | Lokasi geohash perangkat |
| tipe perangkat | Sistem Operasi perangkat = IDFA atau GAID |
| akurasi_horizontal | Akurasi koordinat GPS horizontal (dalam meter) |
| timestamp | Stempel waktu acara |
| ip | Alamat IP |
| berhenti | Ketinggian perangkat (dalam meter) |
| kecepatan | Kecepatan perangkat (dalam meter/detik) |
| negara | Kode ISO dua digit untuk negara asal |
| negara | Kode yang mewakili negara |
| kota | Kode mewakili kota |
| Kode Pos | Kode pos tempat ID Perangkat terlihat |
| pembawa | Pembawa perangkat |
| perangkat_produsen | Produsen perangkat |
Gunakan kasus
Data mobilitas memiliki penerapan luas di berbagai industri. Berikut ini adalah beberapa kasus penggunaan yang paling umum:
- Metrik kepadatan – Analisis lalu lintas pejalan kaki dapat dikombinasikan dengan kepadatan penduduk untuk mengamati aktivitas dan kunjungan ke tempat menarik (POI). Metrik ini menyajikan gambaran berapa banyak perangkat atau pengguna yang secara aktif berhenti dan terlibat dengan suatu bisnis, yang selanjutnya dapat digunakan untuk pemilihan lokasi atau bahkan menganalisis pola pergerakan di sekitar suatu acara (misalnya, orang yang bepergian untuk hari pertandingan). Untuk memperoleh wawasan tersebut, data mentah yang masuk melalui proses ekstrak, transformasi, dan muat (ETL) untuk mengidentifikasi aktivitas atau keterlibatan dari aliran ping lokasi perangkat yang berkelanjutan. Kita dapat menganalisis aktivitas dengan mengidentifikasi pemberhentian yang dilakukan oleh pengguna atau perangkat seluler dengan mengelompokkan ping menggunakan model ML Amazon SageMaker.
- Perjalanan dan lintasan – Umpan lokasi harian perangkat dapat dinyatakan sebagai kumpulan aktivitas (berhenti) dan perjalanan (pergerakan). Sepasang aktivitas dapat mewakili perjalanan di antara keduanya, dan menelusuri perjalanan dengan perangkat bergerak dalam ruang geografis dapat menghasilkan pemetaan lintasan sebenarnya. Pola lintasan pergerakan pengguna dapat memberikan wawasan menarik seperti pola lalu lintas, konsumsi bahan bakar, perencanaan kota, dan banyak lagi. Hal ini juga dapat memberikan data untuk menganalisis rute yang diambil dari titik iklan seperti papan reklame, mengidentifikasi rute pengiriman yang paling efisien untuk mengoptimalkan operasi rantai pasokan, atau menganalisis rute evakuasi jika terjadi bencana alam (misalnya, evakuasi angin topan).
- Analisis daerah tangkapan air - A daerah tangkapan air mengacu pada tempat-tempat di mana suatu daerah menarik pengunjungnya, yang mungkin merupakan pelanggan atau calon pelanggan. Bisnis ritel dapat menggunakan informasi ini untuk menentukan lokasi optimal untuk membuka toko baru, atau menentukan apakah dua lokasi toko terlalu dekat satu sama lain dengan area tangkapan yang tumpang tindih dan menghambat bisnis satu sama lain. Mereka juga dapat mengetahui asal pelanggan sebenarnya, mengidentifikasi calon pelanggan yang melewati area perjalanan menuju kantor atau rumah, menganalisis metrik kunjungan serupa untuk pesaing, dan banyak lagi. Perusahaan Teknologi Pemasaran (MarTech) dan Teknologi Periklanan (AdTech) juga dapat menggunakan analisis ini untuk mengoptimalkan kampanye pemasaran dengan mengidentifikasi audiens yang dekat dengan toko suatu merek atau untuk menentukan peringkat toko berdasarkan kinerja untuk iklan di luar rumah.
Ada beberapa kasus penggunaan lainnya, termasuk menghasilkan kecerdasan lokasi untuk real estate komersial, menambah data citra satelit dengan jumlah pengunjung, mengidentifikasi pusat pengiriman untuk restoran, menentukan kemungkinan evakuasi di lingkungan sekitar, menemukan pola pergerakan orang selama pandemi, dan banyak lagi.
Tantangan dan penggunaan etis
Penggunaan data mobilitas yang etis dapat menghasilkan banyak wawasan menarik yang dapat membantu organisasi meningkatkan operasi mereka, melakukan pemasaran yang efektif, atau bahkan mencapai keunggulan kompetitif. Untuk memanfaatkan data ini secara etis, beberapa langkah perlu diikuti.
Dimulai dengan pengumpulan data itu sendiri. Meskipun sebagian besar data mobilitas tetap bebas dari informasi identitas pribadi (PII) seperti nama dan alamat, pengumpul dan agregator data harus mendapat izin pengguna untuk mengumpulkan, menggunakan, menyimpan, dan membagikan data mereka. Undang-undang privasi data seperti GDPR dan CCPA harus dipatuhi karena undang-undang tersebut memberdayakan pengguna untuk menentukan bagaimana bisnis dapat menggunakan data mereka. Langkah pertama ini merupakan langkah besar menuju penggunaan data mobilitas yang beretika dan bertanggung jawab, namun masih banyak lagi yang bisa dilakukan.
Setiap perangkat diberi ID Periklanan Seluler (MAID) yang di-hash, yang digunakan untuk mengaitkan ping individual. Hal ini dapat dikaburkan lebih lanjut dengan menggunakan Amazon Macie, Lambda Objek Amazon S3, Amazon Comprehend, atau bahkan Studio Lem AWS Deteksi transformasi PII. Untuk informasi lebih lanjut, lihat Teknik umum untuk mendeteksi data PHI dan PII menggunakan Layanan AWS.
Selain PII, pertimbangan harus dilakukan untuk menutupi lokasi rumah pengguna serta lokasi sensitif lainnya seperti pangkalan militer atau tempat ibadah.
Langkah terakhir untuk penggunaan etis adalah memperoleh dan mengekspor hanya metrik gabungan dari Amazon SageMaker. Ini berarti mendapatkan metrik seperti jumlah rata-rata atau jumlah total pengunjung dibandingkan dengan pola perjalanan individu; mendapatkan tren harian, mingguan, bulanan atau tahunan; atau mengindeks pola mobilitas pada data yang tersedia untuk umum seperti data sensus.
Ikhtisar solusi
Seperti disebutkan sebelumnya, layanan AWS yang dapat Anda gunakan untuk analisis data mobilitas adalah kemampuan geospasial Amazon S3, Amazon Macie, AWS Glue, S3 Object Lambda, Amazon Comprehend, dan Amazon SageMaker. Kemampuan geospasial Amazon SageMaker memudahkan ilmuwan data dan insinyur ML untuk membangun, melatih, dan menerapkan model menggunakan data geospasial. Anda dapat secara efisien mengubah atau memperkaya kumpulan data geospasial skala besar, mempercepat pembuatan model dengan model ML terlatih, dan menjelajahi prediksi model dan data geospasial pada peta interaktif menggunakan grafik akselerasi 3D dan alat visualisasi bawaan.
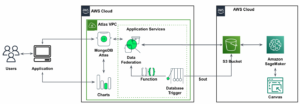
Arsitektur referensi berikut menggambarkan alur kerja menggunakan ML dengan data geospasial.
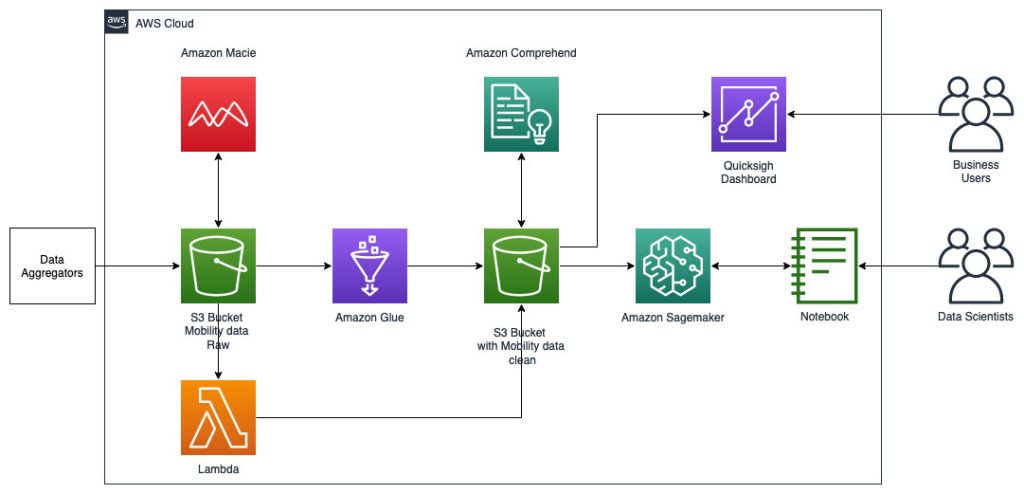
Dalam alur kerja ini, data mentah dikumpulkan dari berbagai sumber data dan disimpan dalam sebuah Layanan Penyimpanan Sederhana Amazon (S3) ember. Amazon Macie digunakan pada bucket S3 ini untuk mengidentifikasi dan menyunting serta PII. AWS Glue kemudian digunakan untuk membersihkan dan mengubah data mentah ke format yang diperlukan, kemudian data yang dimodifikasi dan dibersihkan disimpan dalam bucket S3 terpisah. Untuk transformasi data yang tidak mungkin dilakukan melalui AWS Glue, Anda menggunakan AWS Lambda untuk mengubah dan membersihkan data mentah. Saat data dibersihkan, Anda dapat menggunakan Amazon SageMaker untuk membangun, melatih, dan menerapkan model ML pada data geospasial yang telah disiapkan. Anda juga dapat menggunakan pekerjaan Pemrosesan geospasial fitur kemampuan geospasial Amazon SageMaker untuk melakukan praproses data—misalnya, menggunakan fungsi Python dan pernyataan SQL untuk mengidentifikasi aktivitas dari data mobilitas mentah. Ilmuwan data dapat menyelesaikan proses ini dengan menghubungkan melalui notebook Amazon SageMaker. Anda juga bisa menggunakan Amazon QuickSight untuk memvisualisasikan hasil bisnis dan metrik penting lainnya dari data.
Kemampuan geospasial Amazon SageMaker dan tugas Pemrosesan geospasial
Setelah data diperoleh dan dimasukkan ke Amazon S3 dengan umpan harian dan dibersihkan untuk data sensitif apa pun, data tersebut dapat diimpor ke Amazon SageMaker menggunakan Studio Amazon SageMaker buku catatan dengan gambar geospasial. Tangkapan layar berikut menunjukkan contoh ping perangkat harian yang diunggah ke Amazon S3 sebagai file CSV dan kemudian dimuat dalam bingkai data pandas. Notebook Amazon SageMaker Studio dengan gambar geospasial dilengkapi dengan perpustakaan geospasial seperti GDAL, GeoPandas, Fiona, dan Shapely, dan memudahkan pemrosesan dan analisis data ini.
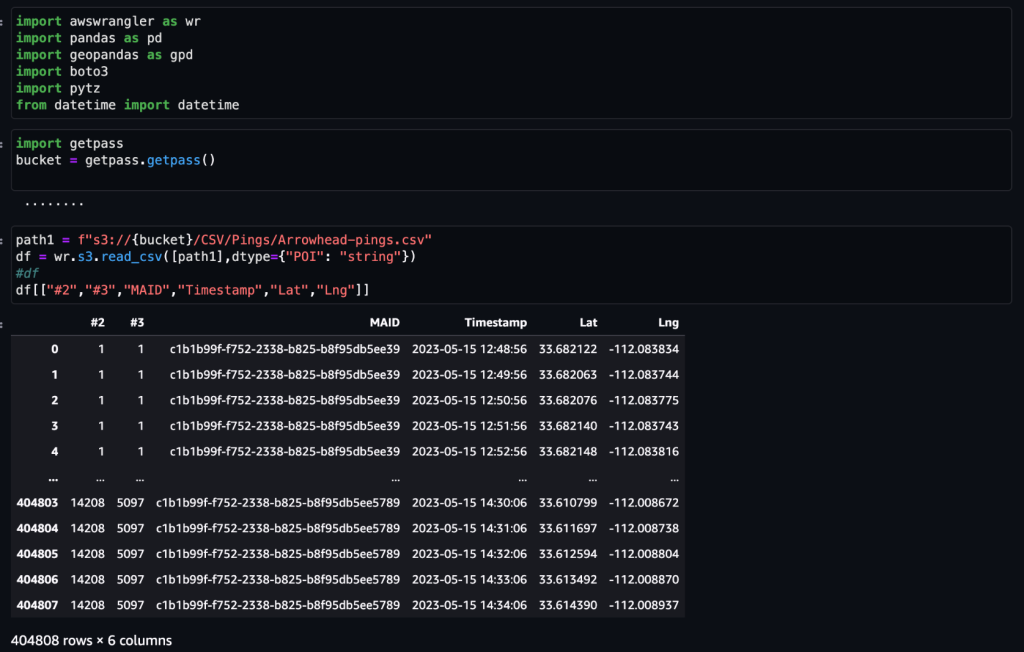
Kumpulan data sampel ini berisi sekitar 400,000 ping perangkat setiap hari dari 5,000 perangkat dari 14,000 tempat unik yang direkam dari pengguna yang mengunjungi Arrowhead Mall, kompleks pusat perbelanjaan populer di Phoenix, Arizona, pada tanggal 15 Mei 2023. Tangkapan layar sebelumnya menunjukkan subkumpulan kolom di skema data. Itu MAID kolom mewakili ID perangkat, dan setiap MAID menghasilkan ping setiap menit yang menyampaikan garis lintang dan bujur perangkat, dicatat dalam file sampel sebagai Lat dan Lng kolom.
Berikut ini adalah tangkapan layar dari alat visualisasi peta kemampuan geospasial Amazon SageMaker yang didukung oleh Foursquare Studio, yang menggambarkan tata letak ping dari perangkat yang mengunjungi mal antara pukul 7 hingga 00.
Tangkapan layar berikut menunjukkan ping dari mal dan sekitarnya.

Berikut tampilan ping dari dalam berbagai toko di mall.
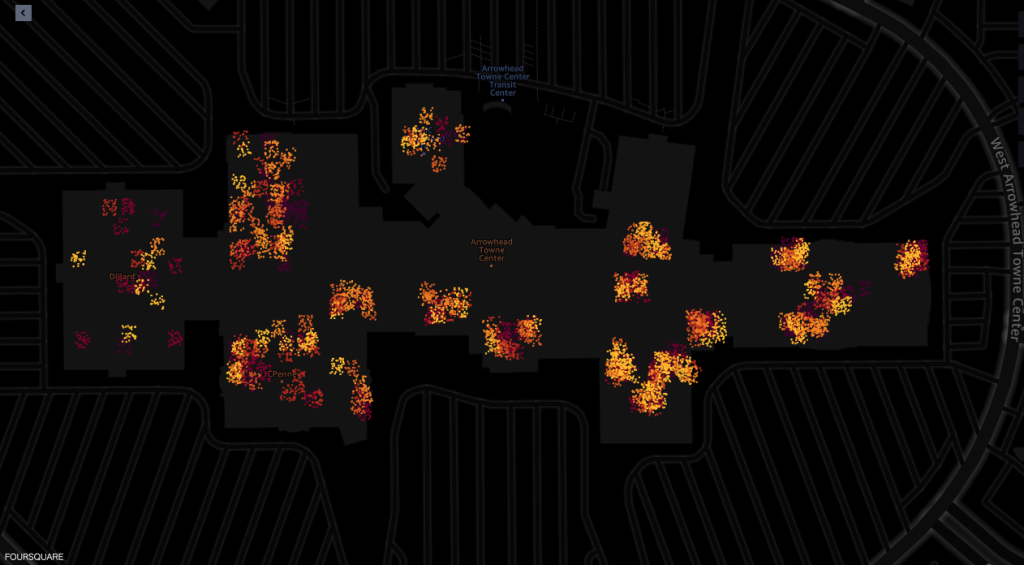
Setiap titik di tangkapan layar menggambarkan ping dari perangkat tertentu pada waktu tertentu. Sekelompok ping mewakili tempat populer tempat perangkat berkumpul atau berhenti, seperti toko atau restoran.
Sebagai bagian dari ETL awal, data mentah ini dapat dimuat ke tabel menggunakan AWS Glue. Anda dapat membuat crawler AWS Glue untuk mengidentifikasi skema data dan tabel formulir dengan menunjuk ke lokasi data mentah di Amazon S3 sebagai sumber data.

Seperti disebutkan di atas, data mentah (ping perangkat harian), bahkan setelah ETL awal, akan mewakili aliran ping GPS yang terus menerus yang menunjukkan lokasi perangkat. Untuk mengekstrak wawasan yang dapat ditindaklanjuti dari data ini, kita perlu mengidentifikasi perhentian dan perjalanan (lintasan). Hal ini dapat dicapai dengan menggunakan pekerjaan Pemrosesan geospasial fitur kemampuan geospasial SageMaker. Pemrosesan SageMaker Amazon menggunakan pengalaman yang disederhanakan dan terkelola di SageMaker untuk menjalankan beban kerja pemrosesan data dengan kontainer geospasial yang dibuat khusus. Infrastruktur dasar untuk pekerjaan Pemrosesan SageMaker dikelola sepenuhnya oleh SageMaker. Fitur ini memungkinkan kode kustom untuk berjalan pada data geospasial yang disimpan di Amazon S3 dengan menjalankan kontainer ML geospasial pada tugas Pemrosesan SageMaker. Anda dapat menjalankan operasi kustom pada data geospasial terbuka atau privat dengan menulis kode kustom dengan pustaka sumber terbuka, dan menjalankan operasi dalam skala besar menggunakan pekerjaan SageMaker Processing. Pendekatan berbasis kontainer memecahkan kebutuhan seputar standarisasi lingkungan pengembangan dengan perpustakaan sumber terbuka yang umum digunakan.
Untuk menjalankan beban kerja berskala besar seperti itu, Anda memerlukan klaster komputasi fleksibel yang dapat menskalakan mulai dari puluhan instans untuk memproses satu blok kota, hingga ribuan instans untuk pemrosesan skala planet. Mengelola cluster komputasi DIY secara manual lambat dan mahal. Fitur ini sangat membantu ketika kumpulan data mobilitas melibatkan lebih dari beberapa kota di beberapa negara bagian atau bahkan beberapa negara dan dapat digunakan untuk menjalankan pendekatan ML dua langkah.
Langkah pertama adalah menggunakan algoritma pengelompokan spasial berbasis kepadatan aplikasi dengan kebisingan (DBSCAN) untuk mengelompokkan penghentian dari ping. Langkah selanjutnya adalah menggunakan metode support vector machine (SVM) untuk lebih meningkatkan keakuratan perhentian yang teridentifikasi dan juga untuk membedakan perhentian dengan keterlibatan dengan POI vs. perhentian tanpa perhentian (seperti rumah atau kantor). Anda juga dapat menggunakan tugas Pemrosesan SageMaker untuk menghasilkan perjalanan dan lintasan dari ping perangkat harian dengan mengidentifikasi perhentian berturut-turut dan memetakan jalur antara perhentian sumber dan tujuan.
Setelah memproses data mentah (ping perangkat harian) dalam skala besar dengan tugas Pemrosesan geospasial, himpunan data baru yang disebut stop harus memiliki skema berikut.
| Atribut | Deskripsi Produk |
| Id atau PEMBANTU | ID Iklan Seluler perangkat (di-hash) |
| lat | Garis lintang pusat massa cluster berhenti |
| lng | Bujur dari pusat massa cluster berhenti |
| geohash | Lokasi geohash dari POI |
| tipe perangkat | Sistem operasi perangkat (IDFA atau GAID) |
| timestamp | Waktu mulai pemberhentian |
| waktu tinggal | Waktu tinggal berhenti (dalam detik) |
| ip | Alamat IP |
| berhenti | Ketinggian perangkat (dalam meter) |
| negara | Kode ISO dua digit untuk negara asal |
| negara | Kode yang mewakili negara |
| kota | Kode mewakili kota |
| Kode Pos | Kode pos tempat ID perangkat terlihat |
| pembawa | Pembawa perangkat |
| perangkat_produsen | Produsen perangkat |
Pemberhentian dikonsolidasikan dengan mengelompokkan ping per perangkat. Pengelompokan berbasis kepadatan dikombinasikan dengan parameter seperti ambang berhenti adalah 300 detik dan jarak minimum antar pemberhentian adalah 50 meter. Parameter ini dapat disesuaikan sesuai kasus penggunaan Anda.
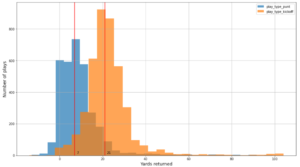
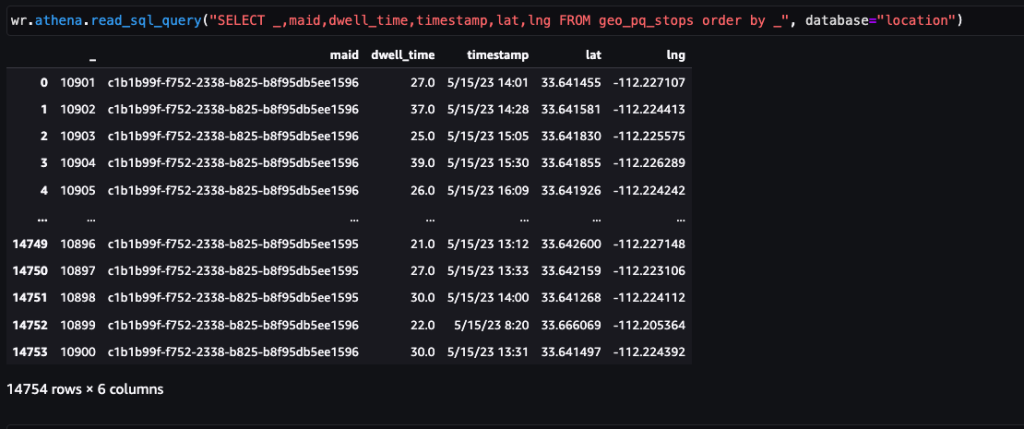
Tangkapan layar berikut menunjukkan sekitar 15,000 pemberhentian yang teridentifikasi dari 400,000 ping. Subset dari skema sebelumnya juga ada, di mana kolomnya Dwell Time mewakili durasi berhenti, dan Lat dan Lng kolom mewakili garis lintang dan bujur dari pusat massa cluster perhentian per perangkat per lokasi.
Pasca ETL, data disimpan dalam format file Parket, yaitu format penyimpanan berbentuk kolom yang memudahkan pemrosesan data dalam jumlah besar.
Tangkapan layar berikut menunjukkan penghentian yang dikonsolidasikan dari ping per perangkat di dalam mal dan area sekitarnya.

Setelah mengidentifikasi perhentian, kumpulan data ini dapat digabungkan dengan data POI yang tersedia untuk umum atau data POI khusus yang spesifik untuk kasus penggunaan guna mengidentifikasi aktivitas, seperti keterlibatan dengan merek.
Tangkapan layar berikut menunjukkan perhentian yang teridentifikasi di POI utama (toko dan merek) di dalam Arrowhead Mall.
Kode pos rumah telah digunakan untuk menutupi lokasi rumah setiap pengunjung untuk menjaga privasi jika itu adalah bagian dari perjalanan mereka dalam kumpulan data. Lintang dan bujur dalam kasus tersebut adalah koordinat masing-masing pusat massa kode pos.
Tangkapan layar berikut adalah representasi visual dari aktivitas tersebut. Gambar kiri memetakan pemberhentian ke toko-toko, dan gambar kanan memberikan gambaran tata letak mal itu sendiri.

Kumpulan data yang dihasilkan ini dapat divisualisasikan dalam beberapa cara, yang akan kita bahas di bagian berikut.
Metrik kepadatan
Kita bisa menghitung dan memvisualisasikan kepadatan aktivitas dan kunjungan.
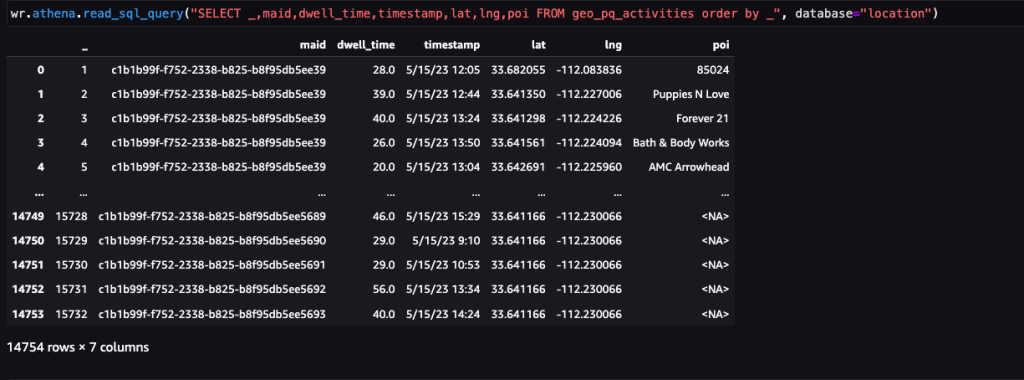
Contoh 1 – Tangkapan layar berikut menunjukkan 15 toko teratas yang dikunjungi di mal.
Contoh 2 – Tangkapan layar berikut menunjukkan jumlah kunjungan ke Apple Store setiap jamnya.

Perjalanan dan lintasan
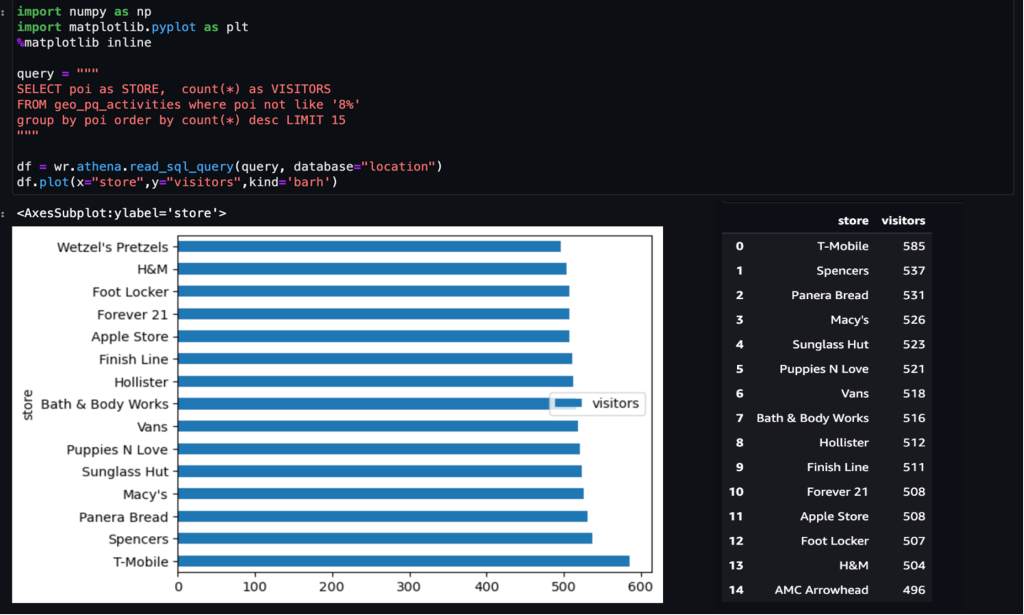
Seperti disebutkan sebelumnya, sepasang aktivitas berturut-turut mewakili sebuah perjalanan. Kita dapat menggunakan pendekatan berikut untuk memperoleh perjalanan dari data aktivitas. Di sini, fungsi jendela digunakan dengan SQL untuk menghasilkan trips tabel, seperti yang ditunjukkan pada tangkapan layar.

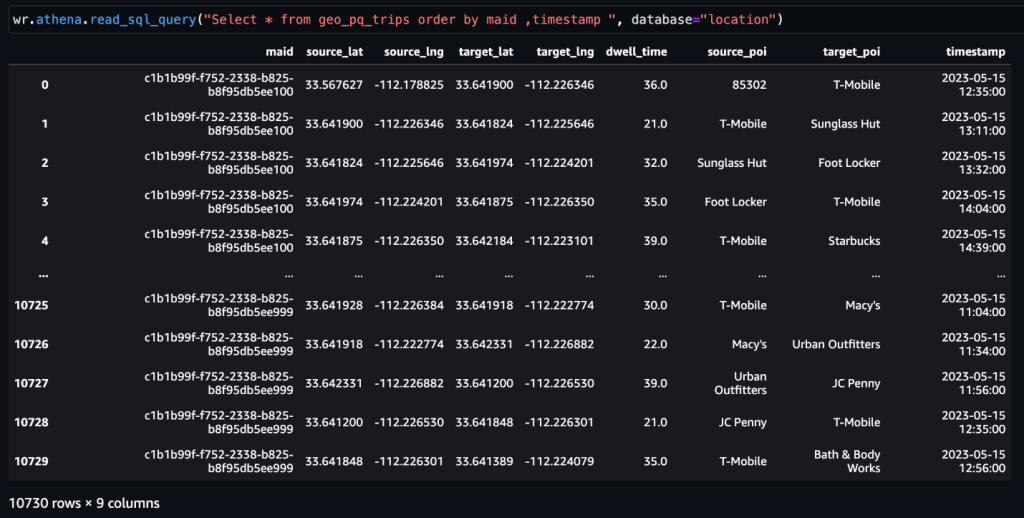
Setelah trips tabel dihasilkan, perjalanan ke POI dapat ditentukan.
Contoh 1 – Tangkapan layar berikut menunjukkan 10 toko teratas yang mengarahkan pengunjung ke Apple Store.

Contoh 2 – Tangkapan layar berikut menunjukkan semua perjalanan ke Arrowhead Mall.

Contoh 3 – Video berikut menunjukkan pola pergerakan di dalam mal.

Contoh 4 – Video berikut menunjukkan pola pergerakan di luar mal.
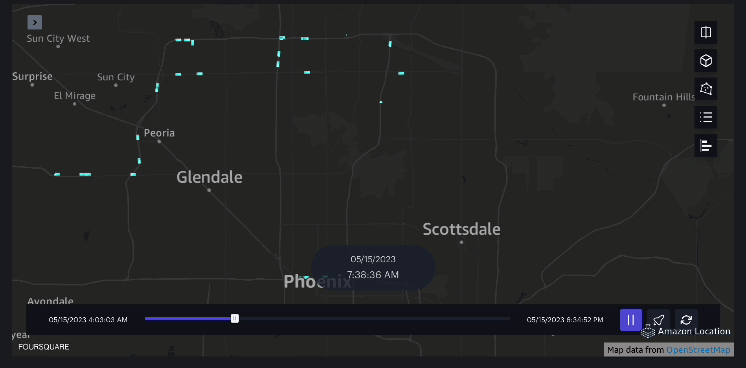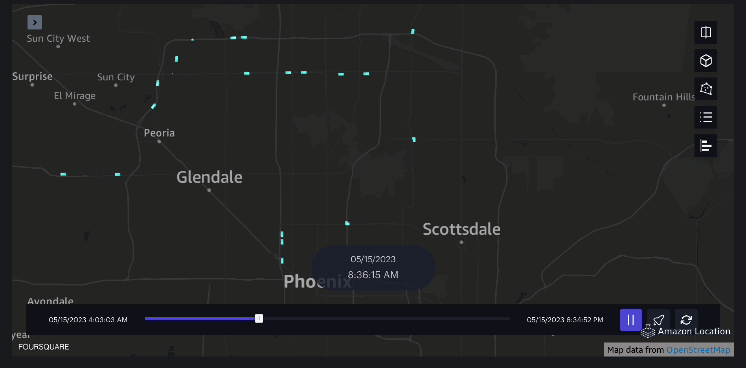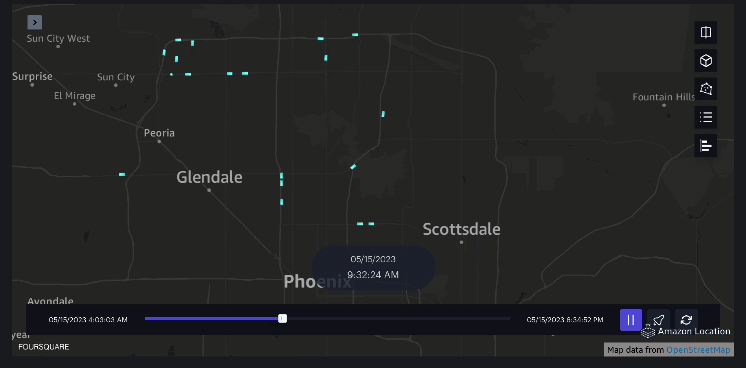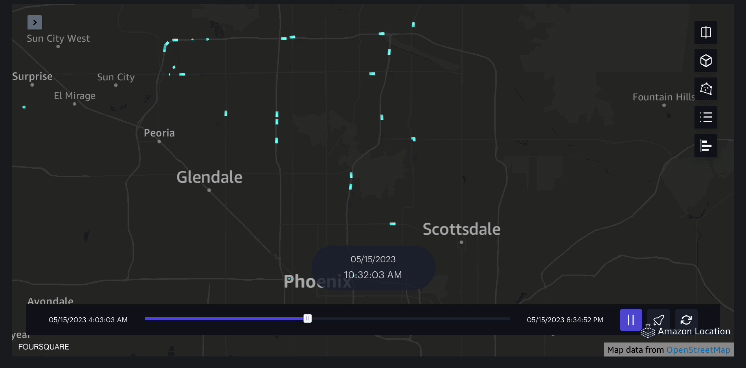
Analisis daerah tangkapan air
Kami dapat menganalisis semua kunjungan ke suatu POI dan menentukan daerah tangkapannya.
Contoh 1 – Tangkapan layar berikut menunjukkan semua kunjungan ke toko Macy.

Contoh 2 – Tangkapan layar berikut menunjukkan 10 kode pos area asal teratas (batas yang disorot) dari tempat kunjungan terjadi.

Pemeriksaan kualitas data
Kami dapat memeriksa kualitas data feed yang masuk setiap hari dan mendeteksi anomali menggunakan dasbor QuickSight dan analisis data. Tangkapan layar berikut menunjukkan contoh dasbor.

Kesimpulan
Data mobilitas dan analisisnya untuk memperoleh wawasan pelanggan dan memperoleh keunggulan kompetitif masih menjadi topik khusus karena sulitnya memperoleh kumpulan data yang konsisten dan akurat. Namun, data ini dapat membantu organisasi menambahkan konteks pada analisis yang ada dan bahkan menghasilkan wawasan baru seputar pola pergerakan pelanggan. Kemampuan geospasial Amazon SageMaker dan tugas Pemrosesan geospasial dapat membantu mengimplementasikan kasus penggunaan ini dan memperoleh wawasan dengan cara yang intuitif dan mudah diakses.
Dalam postingan ini, kami mendemonstrasikan cara menggunakan layanan AWS untuk membersihkan data mobilitas dan kemudian menggunakan kemampuan geospasial Amazon SageMaker untuk menghasilkan kumpulan data turunan seperti pemberhentian, aktivitas, dan perjalanan menggunakan model ML. Kemudian kami menggunakan kumpulan data turunan untuk memvisualisasikan pola pergerakan dan menghasilkan wawasan.
Anda dapat memulai kemampuan geospasial Amazon SageMaker dengan dua cara:
Untuk mempelajari lebih lanjut, kunjungi Kemampuan geospasial Amazon SageMaker dan Memulai geospasial Amazon SageMaker. Juga, kunjungi kami GitHub repo, yang memiliki beberapa contoh notebook tentang kemampuan geospasial Amazon SageMaker.
Tentang Penulis
 Jimy Matthews adalah Arsitek Solusi AWS, dengan keahlian dalam teknologi AI/ML. Jimy berbasis di Boston dan bekerja dengan pelanggan perusahaan saat mereka mengubah bisnis mereka dengan mengadopsi cloud dan membantu mereka membangun solusi yang efisien dan berkelanjutan. Dia sangat menyukai keluarga, mobil, dan seni bela diri campuran.
Jimy Matthews adalah Arsitek Solusi AWS, dengan keahlian dalam teknologi AI/ML. Jimy berbasis di Boston dan bekerja dengan pelanggan perusahaan saat mereka mengubah bisnis mereka dengan mengadopsi cloud dan membantu mereka membangun solusi yang efisien dan berkelanjutan. Dia sangat menyukai keluarga, mobil, dan seni bela diri campuran.
 Girish Keshav adalah Arsitek Solusi di AWS, membantu pelanggan dalam perjalanan migrasi cloud mereka untuk memodernisasi dan menjalankan beban kerja dengan aman dan efisien. Dia bekerja dengan para pemimpin tim teknologi untuk memandu mereka dalam hal keamanan aplikasi, pembelajaran mesin, optimalisasi biaya, dan keberlanjutan. Dia berbasis di San Francisco, dan suka bepergian, hiking, menonton olahraga, dan menjelajahi pabrik kerajinan.
Girish Keshav adalah Arsitek Solusi di AWS, membantu pelanggan dalam perjalanan migrasi cloud mereka untuk memodernisasi dan menjalankan beban kerja dengan aman dan efisien. Dia bekerja dengan para pemimpin tim teknologi untuk memandu mereka dalam hal keamanan aplikasi, pembelajaran mesin, optimalisasi biaya, dan keberlanjutan. Dia berbasis di San Francisco, dan suka bepergian, hiking, menonton olahraga, dan menjelajahi pabrik kerajinan.
 Dermaga Ramesh adalah pemimpin Senior Arsitektur Solusi yang berfokus membantu pelanggan perusahaan AWS memonetisasi aset data mereka. Dia menyarankan para eksekutif dan insinyur untuk merancang dan membangun solusi cloud yang sangat skalabel, andal, dan hemat biaya, terutama yang berfokus pada pembelajaran mesin, data, dan analitik. Di waktu luangnya ia menikmati alam terbuka, bersepeda, dan hiking bersama keluarganya.
Dermaga Ramesh adalah pemimpin Senior Arsitektur Solusi yang berfokus membantu pelanggan perusahaan AWS memonetisasi aset data mereka. Dia menyarankan para eksekutif dan insinyur untuk merancang dan membangun solusi cloud yang sangat skalabel, andal, dan hemat biaya, terutama yang berfokus pada pembelajaran mesin, data, dan analitik. Di waktu luangnya ia menikmati alam terbuka, bersepeda, dan hiking bersama keluarganya.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/use-mobility-data-to-derive-insights-using-amazon-sagemaker-geospatial-capabilities/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 000
- 1
- 10
- 100
- 14
- 15%
- 2023
- 300
- 361
- 3d
- 400
- 50
- 7
- 9
- a
- Tentang Kami
- atas
- mempercepat
- dipercepat
- mengakses
- dapat diakses
- menyelesaikan
- ketepatan
- tepat
- dicapai
- aktif
- aktif
- kegiatan
- sebenarnya
- menambahkan
- alamat
- dipatuhi
- Disesuaikan
- Mengadopsi
- iklan
- Keuntungan
- iklan
- pengiklanan
- Setelah
- Agregator
- Agregator
- AI / ML
- Membantu
- algoritma
- Semua
- di samping
- juga
- Meskipun
- am
- Amazon
- Amazon Comprehend
- Amazon SageMaker
- geospasial Amazon SageMaker
- Studio Amazon SageMaker
- Amazon Web Services
- jumlah
- an
- analisis
- analisis
- analisis
- menganalisa
- menganalisis
- Jangkar
- dan
- Apa pun
- selain
- aplikasi
- Apple
- Aplikasi
- keamanan aplikasi
- aplikasi
- pendekatan
- sekitar
- arsitektur
- ADALAH
- DAERAH
- daerah
- arizona
- sekitar
- Seni
- AS
- Aktiva
- ditugaskan
- terkait
- At
- mencapai
- para penonton
- menambah
- tersedia
- rata-rata
- AWS
- Lem AWS
- mendasarkan
- berdasarkan
- dasar
- BE
- karena
- menjadi
- makhluk
- antara
- tawaran
- Memblokir
- boston
- batas-batas
- merek
- membangun
- Bangunan
- built-in
- bisnis
- bisnis
- tapi
- by
- menghitung
- bernama
- Kampanye
- CAN
- Bisa Dapatkan
- kemampuan
- mobil
- kasus
- kasus
- CCPA
- Sel
- Sensus
- data sensus
- rantai
- memeriksa
- kota
- Kota
- membersihkan
- Penyelesaian
- awan
- Kelompok
- kekelompokan
- kode
- Kode
- kolaborasi
- mengumpulkan
- koleksi
- kolektor
- Kolom
- Kolom
- bergabung
- datang
- kedatangan
- komersial
- perumahan komersial
- Umum
- umum
- Perusahaan
- kompetitif
- pesaing
- kompleks
- komponen
- memahami
- menghitung
- Menghubungkan
- berturut-turut
- persetujuan
- pertimbangan
- konsisten
- konsumsi
- Wadah
- mengandung
- konteks
- kontinu
- Biaya
- negara
- negara
- menutupi
- meliputi
- kerajinan
- crawler
- membuat
- adat
- pelanggan
- pelanggan
- harian
- dasbor
- dasbor
- data
- titik data
- privasi data
- pengolahan data
- kumpulan data
- hari
- pengiriman
- menunjukkan
- kepadatan
- menggambarkan
- menyebarkan
- turunan
- memperoleh
- Berasal
- Mendesain
- tujuan
- rinci
- menemukan
- Menentukan
- ditentukan
- menentukan
- Pengembangan
- alat
- Devices
- sulit
- langsung
- Bencana
- menemukan
- membahas
- jarak
- membedakan
- DIY
- tidak
- dilakukan
- DOT
- menarik
- dua
- lamanya
- selama
- setiap
- Terdahulu
- mudah
- Mudah
- Efektif
- efisien
- efisien
- usaha
- memberdayakan
- memungkinkan
- meliputi
- interaksi
- Pertunangan
- menarik
- Insinyur
- memperkaya
- Enterprise
- pelanggan perusahaan
- Lingkungan Hidup
- terutama
- perkebunan
- Eter (ETH)
- etis
- Bahkan
- Acara
- Setiap
- contoh
- eksekutif
- ada
- ada
- mahal
- pengalaman
- keahlian
- menyelidiki
- Menjelajahi
- ekspor
- menyatakan
- ekstrak
- keluarga
- Fitur
- Fed
- beberapa
- File
- terakhir
- Menemukan
- fiona
- Pertama
- fleksibel
- Fokus
- terfokus
- diikuti
- berikut
- Kaki
- Untuk
- bentuk
- format
- foursquare
- FRAME
- Francisco
- Gratis
- dari
- Bahan bakar
- sepenuhnya
- fungsi
- fungsi
- lebih lanjut
- mendapatkan
- permainan
- dikumpulkan
- GDPR
- menghasilkan
- dihasilkan
- menghasilkan
- menghasilkan
- geografis
- geografis
- ML geospasial
- mendapatkan
- mendapatkan
- gif
- diberikan
- memberikan
- Pergi
- gps
- grafis
- besar
- Pemandangan yang menakjubkan
- kisi
- membimbing
- Perangkat keras
- hash
- Memiliki
- he
- membantu
- bermanfaat
- membantu
- membantu
- di sini
- Disorot
- sangat
- mendaki
- -nya
- Beranda
- Horisontal
- jam
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- http
- HTTPS
- Hub
- badai
- ID
- ide
- diidentifikasi
- mengenali
- mengidentifikasi
- IDFA
- if
- gambar
- melaksanakan
- penting
- memperbaiki
- in
- Termasuk
- masuk
- Menunjukkan
- sendiri-sendiri
- industri
- informasi
- Infrastruktur
- mulanya
- dalam
- wawasan
- contoh
- integrasi
- Intelijen
- interaktif
- bunga
- menarik
- ke
- memperkenalkan
- intuitif
- melibatkan
- IT
- NYA
- Diri
- Pekerjaan
- Jobs
- bergabung
- perjalanan
- jpg
- besar
- besar-besaran
- lintang
- Hukum
- berlapis
- tata ruang
- memimpin
- pemimpin
- pemimpin
- BELAJAR
- pengetahuan
- meninggalkan
- perpustakaan
- 'like'
- kemungkinan
- baris
- memuat
- tempat
- lokasi
- melihat
- terlihat seperti
- mencintai
- mesin
- Mesin belajar
- Mesin
- terbuat
- memelihara
- utama
- membuat
- MEMBUAT
- berhasil
- pelaksana
- manual
- banyak
- peta
- pemetaan
- Peta
- Marketing
- Kampanye pemasaran
- teknologi pemasaran
- MarTech
- bela diri
- masker
- Matriks
- Mungkin..
- cara
- tersebut
- metode
- Metrik
- migrasi
- Militer
- jutaan
- minimum
- menit
- campur aduk
- ML
- mobil
- perangkat mobile
- telepon genggam
- mobilitas
- model
- model
- memodernisasi
- dimodifikasi
- memodifikasi
- uangkan
- bulanan
- lebih
- paling
- kebanyakan
- pindah
- gerakan
- gerak-gerik
- bergerak
- beberapa
- banyaknya
- harus
- nama
- Alam
- Alam
- Perlu
- kebutuhan
- New
- berikutnya
- ceruk
- Kebisingan
- buku catatan
- laptop
- jumlah
- nomor
- obyek
- mengamati
- memperoleh
- diperoleh
- mendapatkan
- terjadi
- of
- sering
- on
- ONE
- hanya
- Buka
- open source
- operasi
- Operasi
- menentang
- optimal
- optimasi
- Optimize
- or
- organisasi
- Lainnya
- kami
- di luar
- hasil
- di luar rumah
- di luar
- lebih
- pasangan
- panda
- pandemi
- parameter
- bagian
- khususnya
- lulus
- bergairah
- path
- pola
- Konsultan Ahli
- untuk
- melakukan
- prestasi
- Sendiri
- perspektif
- phoenix
- foto
- fisik
- gambar
- saleh
- ping
- ditempatkan
- Tempat
- perencanaan
- plato
- Kecerdasan Data Plato
- Data Plato
- pm
- Titik
- poin
- Populer
- populasi
- posisi
- mungkin
- Pos
- potensi
- pelanggan potensial
- didukung
- mendahului
- Prediksi
- menyajikan
- pribadi
- hukum privasi
- swasta
- proses
- pengolahan
- menghasilkan
- memberikan
- di depan umum
- penerbit
- membeli
- dibeli
- tujuan
- Ular sanca
- kualitas
- peringkat
- agak
- Mentah
- data mentah
- nyata
- real estate
- tercatat
- lihat
- referensi
- mengacu
- daerah
- dapat diandalkan
- sisa
- mewakili
- perwakilan
- diwakili
- mewakili
- merupakan
- wajib
- itu
- tanggung jawab
- restoran
- dihasilkan
- Hasil
- eceran
- benar
- Rute
- rute
- Run
- berjalan
- pembuat bijak
- Contoh kumpulan data
- San
- San Fransisco
- satelit
- citra satelit
- terukur
- Skala
- ilmuwan
- screenshot
- SDK
- mulus
- Kedua
- detik
- bagian
- aman
- keamanan
- seleksi
- senior
- peka
- mengirim
- terpisah
- Seri
- Layanan
- porsi
- beberapa
- Share
- tas
- harus
- ditunjukkan
- Pertunjukkan
- mirip
- Sederhana
- disederhanakan
- tunggal
- situs web
- lambat
- So
- Solusi
- Memecahkan
- beberapa
- dicari
- sumber
- sumber
- Space
- spasial
- tertentu
- Olahraga
- spot
- SQL
- standardisasi
- mulai
- dimulai
- Laporan
- Negara
- Langkah
- Tangga
- berhenti
- terhenti
- henti
- Berhenti
- penyimpanan
- menyimpan
- tersimpan
- toko
- mudah
- aliran
- studio
- besar
- seperti itu
- menyediakan
- supply chain
- mendukung
- Permukaan
- Sekitarnya
- Keberlanjutan
- berkelanjutan
- sistem
- tabel
- diambil
- tim
- tech
- Teknis
- teknik
- Teknologi
- memiliki
- dari
- bahwa
- Grafik
- Daerah
- Sumber
- mereka
- Mereka
- diri
- kemudian
- Sana.
- Ini
- mereka
- ini
- itu
- ribuan
- ambang
- Melalui
- waktu
- untuk
- terlalu
- alat
- alat
- puncak
- Top 10
- Total
- terhadap
- jiplakan
- lalu lintas
- Pelatihan VE
- lintasan
- Mengubah
- transformasi
- pemancar
- perjalanan
- Perjalanan
- Tren
- perjalanan
- dua
- jenis
- khas
- pokok
- pemahaman
- unik
- upload
- menggunakan
- gunakan case
- bekas
- Pengguna
- Pengguna
- kegunaan
- menggunakan
- Penggunaan
- berbagai
- memeriksa
- melalui
- Video
- Mengunjungi
- mengunjungi
- pengunjung
- Kunjungan
- visual
- visualisasi
- membayangkan
- visual
- vs
- menonton
- Cara..
- cara
- we
- jaringan
- layanan web
- mingguan
- BAIK
- Apa
- ketika
- yang
- SIAPA
- seluruh
- mengapa
- Wi-fi
- tersebar luas
- akan
- jendela
- dengan
- tanpa
- Kerja
- alur kerja
- bekerja
- penulisan
- tahunan
- kamu
- Anda
- zephyrnet.dll
- Zip