Gambar oleh Penulis
Saat bekerja dengan data dan variabel yang berbeda, menetapkan satu variabel atau nilai lebih besar dari yang lain itu mudah. Kita mungkin berasumsi bahwa variabel atau titik data tertentu memiliki dampak yang lebih besar pada keluaran, tetapi seberapa yakinkah kita bahwa variabel lain memiliki dampak yang sama?
Dalam statistik, tarif dasar dapat dilihat sebagai probabilitas kelas yang tidak bersyarat pada "bukti fitur". Anda dapat melihat tarif dasar sebagai asumsi probabilitas sebelumnya.
Tarif dasar adalah alat penting dalam penelitian. Misalnya, jika kami adalah perusahaan farmasi dan sedang dalam proses mengembangkan dan mengirimkan vaksinasi baru, kami ingin melihat keberhasilan pengobatan tersebut. Jika kami memiliki 4000 orang yang bersedia menerima vaksinasi ini, dan tarif dasar kami adalah 1/25.
Artinya hanya 160 orang yang berhasil disembuhkan dengan pengobatan dari 4000 orang. Di dunia farmasi, ini adalah tingkat keberhasilan yang sangat rendah. Ini adalah bagaimana tarif dasar dapat digunakan untuk meningkatkan penelitian, dan akurasi serta memastikan bahwa produk akan bekerja dengan baik.
Jika kita membagi kata-kata itu, itu akan memberi kita pemahaman yang lebih baik. Kekeliruan berarti kepercayaan yang salah atau penalaran yang salah. Jika sekarang kita gabungkan dengan definisi kita tentang tarif dasar di atas.
Kekeliruan tarif dasar, juga dikenal sebagai bias tarif dasar dan pengabaian tarif dasar, adalah kemungkinan menilai situasi tertentu, sementara tidak mempertimbangkan semua data yang relevan.
Kekeliruan tarif dasar memiliki informasi tentang tarif dasar serta informasi relevan lainnya. Hal ini dapat disebabkan oleh berbagai alasan seperti tidak memeriksa dan menganalisis data secara menyeluruh, atau ketidaktahuan untuk mendukung bagian tertentu dari data.
Kekeliruan tarif dasar menggambarkan kecenderungan seseorang untuk mengabaikan informasi tarif dasar yang ada, untuk mendorong dan mendukung informasi baru. Ini bertentangan dengan aturan dasar penalaran berbasis bukti.
Anda biasanya akan mendengar tentang hal ini terjadi di industri keuangan. Misalnya, investor akan mendasarkan taktik pembelian atau berbagi mereka pada informasi yang tidak rasional, yang menyebabkan fluktuasi di pasar – meskipun memiliki tarif dasar yang mereka ketahui.
Jadi sekarang kita memiliki pemahaman yang lebih baik tentang tarif dasar dan kekeliruan tarif dasar. Apa relevansi dan dampaknya dalam Ilmu Data?
Kami telah berbicara tentang 'probabilitas kelas' dan 'mempertimbangkan semua data yang relevan'. Jika Anda seorang ilmuwan data, atau insinyur pembelajaran mesin, atau memulai bisnis – Anda akan tahu betapa pentingnya probabilitas dan data yang relevan untuk menghasilkan keluaran yang akurat, proses pembelajaran model pembelajaran mesin Anda, dan menghasilkan model berperforma tinggi.
Untuk menganalisis dan membuat prediksi tentang data atau agar model pembelajaran mesin Anda menghasilkan keluaran yang akurat – Anda perlu mempertimbangkan setiap bit data. Saat Anda memindai data saat pertama kali melihatnya, Anda mungkin menganggap beberapa bagian relevan dan bagian lainnya tidak relevan. Namun, ini adalah penilaian Anda dan belum faktual sampai analisis yang tepat dilakukan.
Seperti disebutkan di atas, tarif dasar awal membantu Anda memastikan akurasi dan menghasilkan model berperforma tinggi. Jadi bagaimana kita bisa melakukan ini dalam Ilmu Data?
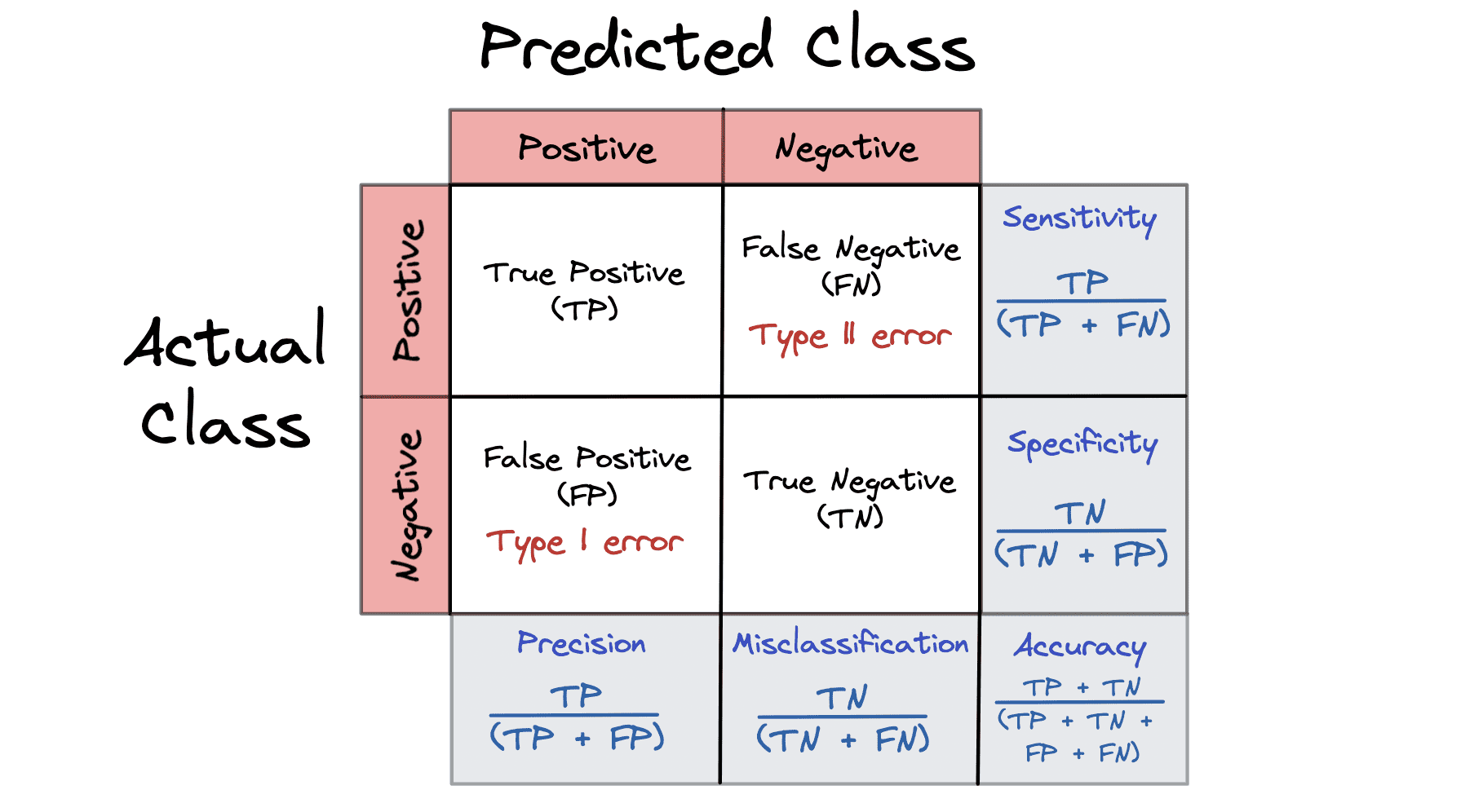
Matriks Kebingungan
Confusion Matrix adalah pengukuran kinerja yang memberikan ringkasan hasil prediksi pada masalah klasifikasi. Semua matriks kebingungan didasarkan pada hasil: Benar, Salah, Positif, dan Negatif.
Matriks kebingungan mewakili prediksi model kami selama fase pengujian. Negatif-palsu dan positif-palsu dalam matriks kebingungan adalah contoh kekeliruan laju dasar.
- True Positive (TP) – model Anda diprediksi positif dan ternyata positif
- True Negative (TN) – model Anda memperkirakan negatif dan hasilnya negatif
- False Positive (FP) – model Anda memperkirakan positif dan negatif
- False Negative (FN) – model Anda memperkirakan negatif dan hasilnya positif
Matriks konfusi dapat menghitung 5 metrik berbeda untuk membantu kami mengukur validitas model kami:
- Kesalahan klasifikasi = FP + FN / TP + TN + FP + FN
- Presisi = TP / TP + FP
- Akurasi = TP + TN / TP + TN + FP + FN
- Kekhususan = TN / TN + FP
- Sensitivitas alias Recall = TP / TP + FN
Untuk lebih memahami matriks kebingungan, lebih baik melihat visualisasi:
Gambar oleh Penulis
Saat Anda membaca artikel ini, Anda mungkin dapat memikirkan berbagai penyebab kekeliruan tarif dasar, seperti tidak mempertimbangkan semua data yang relevan, kesalahan manusia, atau kurangnya presisi.
Meskipun ini semua benar dan menambah penyebab kekeliruan tarif dasar. Mereka semua berhubungan dengan masalah terbesar mengabaikan informasi tarif dasar sejak awal. Informasi tarif dasar sering diabaikan karena dianggap tidak relevan, namun informasi tarif dasar dapat menghemat banyak waktu dan uang. Dengan menggunakan informasi tarif dasar yang tersedia, Anda dapat lebih tepat dalam membuat probabilitas tentang apakah peristiwa tertentu akan terjadi.
Menggunakan informasi tarif dasar akan membantu Anda menghindari kekeliruan tarif dasar.
Menyadari kekeliruan seperti pendapat, proses otomatis, dll – akan memungkinkan Anda untuk mengatasi masalah kekeliruan tarif dasar dan mengurangi potensi kesalahan. Saat Anda mengukur probabilitas terjadinya peristiwa tertentu, metode Bayesian dapat membantu mengurangi kekeliruan tarif dasar.
Tarif dasar penting dalam ilmu data karena membekali Anda dengan pemahaman dasar tentang cara menilai studi atau proyek Anda, dan menyempurnakan model Anda – memberikan peningkatan akurasi dan kinerja secara keseluruhan.
Jika Anda ingin menonton video tentang kekeliruan tarif dasar di bidang medis, lihat video ini: Paradoks Tes Medis
Nisa Arya adalah Ilmuwan Data, Penulis Teknis Lepas, dan Manajer Komunitas di KDnuggets. Dia sangat tertarik untuk memberikan nasihat atau tutorial karir Ilmu Data dan pengetahuan berbasis teori seputar Ilmu Data. Dia juga ingin menjelajahi berbagai cara Kecerdasan Buatan bermanfaat bagi umur panjang kehidupan manusia. Seorang pembelajar yang tajam, berusaha memperluas pengetahuan teknologi dan keterampilan menulisnya, sambil membantu membimbing orang lain.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Mencetak Masa Depan bersama Adryenn Ashley. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/2023/04/base-rate-fallacy-impact-data-science.html?utm_source=rss&utm_medium=rss&utm_campaign=the-base-rate-fallacy-and-its-impact-on-data-science
- :memiliki
- :adalah
- :bukan
- $NAIK
- a
- Tentang Kami
- atas
- ketepatan
- tepat
- nasihat
- terhadap
- Semua
- memungkinkan
- juga
- an
- analisa
- analisis
- menganalisis
- dan
- ADALAH
- sekitar
- artikel
- buatan
- kecerdasan buatan
- AS
- anggapan
- At
- secara otomatis
- tersedia
- mendasarkan
- berdasarkan
- Bayesian
- BE
- keyakinan
- manfaat
- Lebih baik
- prasangka
- Terbesar
- Bit
- memperluas
- Pembelian
- by
- menghitung
- CAN
- Lowongan Kerja
- Menyebabkan
- penyebab
- tertentu
- memeriksa
- kelas-kelas
- klasifikasi
- memerangi
- menggabungkan
- masyarakat
- perusahaan
- kebingungan
- Mempertimbangkan
- pertimbangan
- dianggap
- data
- ilmu data
- ilmuwan data
- Meskipun
- berkembang
- berbeda
- Oleh
- selama
- insinyur
- memastikan
- kesalahan
- kesalahan
- dll
- Acara
- Setiap
- bukti
- Memeriksa
- contoh
- contoh
- ada
- menyelidiki
- Nyata
- salah
- bidang
- keuangan
- Pertama
- pertama kali
- fluktuasi
- Kaki
- Untuk
- lepas
- mendasar
- mendapatkan
- Memberikan
- diberikan
- Pergi
- akan
- lebih besar
- membimbing
- Kejadian
- Memiliki
- memiliki
- mendengar
- membantu
- membantu
- membantu
- kinerja tinggi
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTTPS
- manusia
- Ketidaktahuan
- Dampak
- penting
- memperbaiki
- in
- Meningkatkan
- industri
- informasi
- mulanya
- Intelijen
- tertarik
- ke
- Investor
- isu
- IT
- NYA
- KDnugget
- Tajam
- Tahu
- pengetahuan
- dikenal
- Kekurangan
- Memimpin
- pelajar
- pengetahuan
- Hidup
- 'like'
- umur panjang
- melihat
- Lot
- Rendah
- mesin
- Mesin belajar
- membuat
- Membuat
- manajer
- Pasar
- Matriks
- Mungkin..
- cara
- mengukur
- ukur
- medis
- tersebut
- metode
- Metrik
- mungkin
- model
- model
- uang
- lebih
- Perlu
- negatif
- New
- sekarang
- of
- on
- ONE
- hanya
- Pendapat
- or
- Lainnya
- Lainnya
- kami
- Hasil
- keluaran
- secara keseluruhan
- bagian
- khususnya
- bagian
- Konsultan Ahli
- melakukan
- prestasi
- farmasi
- tahap
- Tempat
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- positif
- potensi
- perlu
- Ketelitian
- diprediksi
- ramalan
- Prediksi
- Sebelumnya
- probabilitas
- mungkin
- Masalah
- proses
- proses
- menghasilkan
- Produk
- proyek
- tepat
- tepat
- menyediakan
- menyediakan
- Dorong
- Penilaian
- Tarif
- alasan
- menurunkan
- relevansi
- relevan
- merupakan
- penelitian
- Hasil
- aturan
- s
- Save
- pemindaian
- Ilmu
- ilmuwan
- pencarian
- berbagi
- situasi
- keterampilan
- So
- beberapa
- Seseorang
- tertentu
- membagi
- statistika
- Belajar
- sukses
- berhasil
- seperti itu
- RINGKASAN
- taktik
- Mengambil
- pengambilan
- tech
- Teknis
- uji
- pengujian
- dari
- bahwa
- Grafik
- mereka
- Ini
- ini
- sepenuhnya
- Melalui
- waktu
- untuk
- alat
- pengobatan
- benar
- tutorial
- khas
- tak bersyarat
- memahami
- pemahaman
- us
- bekas
- nilai
- variasi
- berbagai
- Video
- Menonton
- cara
- we
- BAIK
- Apa
- Apa itu
- apakah
- yang
- Sementara
- SIAPA
- akan
- rela
- keinginan
- dengan
- kata
- kerja
- dunia
- akan
- penulis
- penulisan
- kamu
- Anda
- zephyrnet.dll