Gambar dibuat dengan DALL-E3
Kecerdasan Buatan telah menjadi revolusi total dalam dunia teknologi.
Kemampuannya untuk meniru kecerdasan manusia dan melakukan tugas-tugas yang dulunya hanya dianggap sebagai urusan manusia masih membuat sebagian besar dari kita takjub.
Namun, betapapun bagusnya kemajuan AI ini, selalu ada ruang untuk perbaikan.
Dan di sinilah tepatnya rekayasa cepat dimulai!
Masuki bidang ini yang secara signifikan dapat meningkatkan produktivitas model AI.
Mari kita temukan semuanya bersama-sama!
Rekayasa cepat adalah domain yang berkembang pesat dalam AI yang berfokus pada peningkatan efisiensi dan efektivitas model bahasa. Ini semua tentang menyusun perintah yang sempurna untuk memandu model AI guna menghasilkan keluaran yang kita inginkan.
Anggap saja sebagai pembelajaran bagaimana memberikan instruksi yang lebih baik kepada seseorang untuk memastikan mereka memahami dan melaksanakan tugas dengan benar.
Mengapa Rekayasa Cepat Itu Penting
- Peningkatan Produktivitas: Dengan menggunakan perintah berkualitas tinggi, model AI dapat menghasilkan respons yang lebih akurat dan relevan. Hal ini berarti lebih sedikit waktu yang dihabiskan untuk melakukan koreksi dan lebih banyak waktu untuk memanfaatkan kemampuan AI.
- Penghematan biaya: Melatih model AI membutuhkan banyak sumber daya. Rekayasa yang cepat dapat mengurangi kebutuhan pelatihan ulang dengan mengoptimalkan performa model melalui perintah yang lebih baik.
- fleksibilitas: Perintah yang dibuat dengan baik dapat membuat model AI lebih fleksibel, sehingga memungkinkan model tersebut menangani lebih banyak tugas dan tantangan.
Sebelum mendalami teknik paling canggih, mari kita ingat dua teknik rekayasa cepat yang paling berguna (dan mendasar).
Berpikir Berurutan dengan “Mari berpikir langkah demi langkah”
Saat ini diketahui bahwa keakuratan model LLM meningkat secara signifikan ketika menambahkan urutan kata “Mari berpikir langkah demi langkah”.
Mengapa… Anda mungkin bertanya?
Ini karena kami memaksa model untuk memecah tugas apa pun menjadi beberapa langkah, sehingga memastikan model memiliki cukup waktu untuk memproses setiap tugas.
Misalnya, saya dapat menantang GPT3.5 dengan perintah berikut:
Jika John mempunyai 5 buah pir, lalu makan 2 buah pir, membeli 5 buah pir lagi, lalu memberikan 3 buah pir kepada temannya, berapa banyak buah pir yang dimilikinya?
Model akan segera memberi saya jawaban. Namun, jika saya menambahkan kalimat terakhir “Mari kita berpikir langkah demi langkah”, saya memaksa model untuk menghasilkan proses berpikir dengan beberapa langkah.
Prompt Sedikit Tembakan
Meskipun bisikan Zero-shot mengacu pada meminta model untuk melakukan tugas tanpa memberikan konteks atau pengetahuan sebelumnya, teknik bisikan beberapa tembakan menyiratkan bahwa kita menyajikan LLM dengan beberapa contoh keluaran yang kita inginkan bersama dengan beberapa pertanyaan spesifik.
Misalnya, jika kita ingin menghasilkan model yang mendefinisikan istilah apa pun dengan menggunakan nada puitis, mungkin akan sulit untuk menjelaskannya. Benar?
Namun, kita dapat menggunakan beberapa petunjuk berikut untuk mengarahkan model ke arah yang kita inginkan.
Tugas Anda adalah menjawab dengan gaya yang konsisten selaras dengan gaya berikut.
: Ajari saya tentang ketahanan.
: Ketahanan itu ibarat pohon yang bengkok ditiup angin namun tidak pernah patah.
Ini adalah kemampuan untuk bangkit kembali dari kesulitan dan terus bergerak maju.
: Masukan Anda di sini.
Jika Anda belum mencobanya, Anda dapat menantang GPT.
Namun, karena saya yakin sebagian besar dari Anda sudah mengetahui teknik dasar ini, saya akan mencoba menantang Anda dengan beberapa teknik lanjutan.
1. Anjuran Rantai Pemikiran (CoT).
Diperkenalkan oleh Google pada tahun 2022, metode ini melibatkan menginstruksikan model untuk menjalani beberapa tahap penalaran sebelum memberikan respons akhir.
Kedengarannya familiar bukan? Jika demikian, Anda benar sekali.
Ini seperti menggabungkan Pemikiran Berurutan dan Anjuran Sedikit Pemotretan.
Bagaimana?
Intinya, dorongan CoT mengarahkan LLM untuk memproses informasi secara berurutan. Ini berarti kita memberikan contoh bagaimana memecahkan masalah pertama dengan beberapa langkah penalaran dan kemudian mengirimkan tugas kita yang sebenarnya ke model, berharap model tersebut meniru rantai pemikiran yang sebanding ketika merespons kueri sebenarnya yang ingin kita selesaikan.
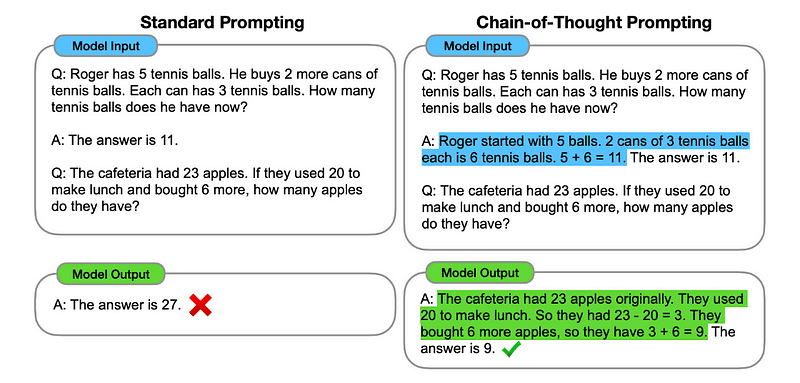
Gambar diambil dari kertas.
Jadi, dengan mengikuti contoh pertama, kita dapat memberikan petunjuk mengenai masalah pertama dan penjelasan berurutan tentang cara menyelesaikannya. Kemudian, kami dapat mengirimkan masukan kami dan melihat bagaimana keajaiban terjadi!
Jika John mempunyai 5 buah pir, lalu makan 2 buah pir, membeli 5 buah pir lagi, lalu memberikan 3 buah pir kepada temannya, berapa banyak buah pir yang dimilikinya? Mari kita berpikir selangkah demi selangkah.
Mari kita lakukan selangkah demi selangkah. John memulai dengan 5 buah pir. Dia makan 2 buah pir, jadi dia mempunyai 5–2 = 3 buah pir tersisa. Kemudian, dia membeli 5 buah pir lagi. Jadi, dia sekarang mempunyai 3 + 5 = 8 buah pir. Akhirnya dia memberikan 3 buah pir kepada temannya. Oleh karena itu, dia mempunyai 8–3 = 5 buah pir tersisa. Jadi, setelah semua langkah ini, John memiliki 5 buah pir.
Masukan Anda di sini.
Namun, sebagian besar dari Anda pasti berpikir… Apakah saya harus memikirkan cara berurutan untuk menyelesaikan masalah setiap kali saya ingin menanyakan sesuatu di ChatGPT?
Ya… kamu bukan yang pertama! Dan ini membawa kita ke…
2. Rantai Pemikiran Otomatis (Auto-CoT)
Dalam 2022, Zhang dan rekannya memperkenalkan metode untuk menghindari proses manual ini. Ada dua alasan utama untuk menghindari tugas manual:
- Ini bisa membosankan.
- It can yield bad results – for instance, when our mental process is wrong.
They suggested using LLMs combined with the “Let’s think step by step” prompt to sequentially produce reasoning chains for each demonstration.
Ini berarti menanyakan ChatGPT cara menyelesaikan masalah apa pun secara berurutan dan kemudian menggunakan contoh yang sama untuk melatihnya cara menyelesaikan masalah lainnya.
3. Konsistensi Diri
Konsistensi diri adalah teknik dorongan menarik lainnya yang bertujuan untuk meningkatkan rantai pemikiran yang mendorong masalah penalaran yang lebih kompleks.
Jadi… apa perbedaan utamanya?
Ide utama dalam Konsistensi Diri adalah kesadaran bahwa kita dapat melatih model dengan contoh yang salah. Bayangkan saja saya menyelesaikan masalah sebelumnya dengan proses mental yang salah:
Jika John mempunyai 5 buah pir, lalu makan 2 buah pir, membeli 5 buah pir lagi, lalu memberikan 3 buah pir kepada temannya, berapa banyak buah pir yang dimilikinya? Mari kita berpikir selangkah demi selangkah.
Start with 5 pears. John eats 2 pears. Then, he gives 3 pears to his friend. These actions can be combined: 2 (eaten) + 3 (given) = 5 pears in total affected. Now, subtract the total pears affected from the initial 5 pears: 5 (initial) – 5 (affected) = 0 pears left.
Maka, tugas lain yang saya kirim ke model akan salah.
Inilah sebabnya mengapa Konsistensi Diri melibatkan pengambilan sampel dari berbagai jalur penalaran, yang masing-masing berisi rantai pemikiran, dan kemudian membiarkan LLM memilih jalur terbaik dan paling konsisten untuk memecahkan masalah.
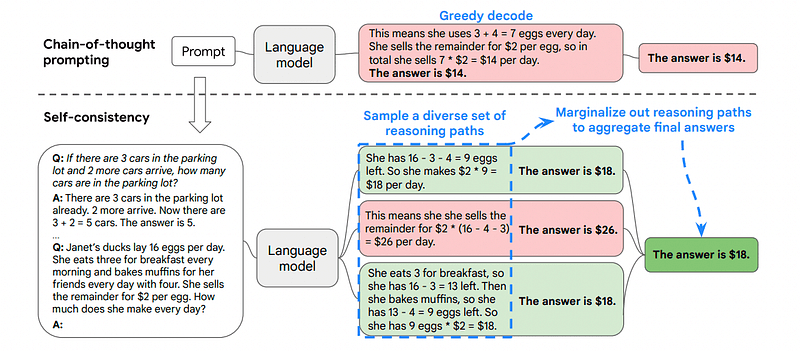
Gambar diambil dari kertas
Dalam kasus ini, dan dengan mengikuti contoh pertama lagi, kita dapat menunjukkan kepada model berbagai cara untuk menyelesaikan masalah.
Jika John mempunyai 5 buah pir, lalu makan 2 buah pir, membeli 5 buah pir lagi, lalu memberikan 3 buah pir kepada temannya, berapa banyak buah pir yang dimilikinya?
Mulailah dengan 5 buah pir. John makan 2 buah pir, menyisakan 5–2 = 3 buah pir. Dia membeli 5 buah pir lagi, sehingga totalnya menjadi 3 + 5 = 8 buah pir. Akhirnya dia memberikan 3 buah pir kepada temannya, sehingga dia mempunyai 8–3 = 5 buah pir yang tersisa.
Jika John mempunyai 5 buah pir, lalu makan 2 buah pir, membeli 5 buah pir lagi, lalu memberikan 3 buah pir kepada temannya, berapa banyak buah pir yang dimilikinya?
Start with 5 pears. He then buys 5 more pears. John eats 2 pears now. These actions can be combined: 2 (eaten) + 5 (bought) = 7 pears in total. Subtract the pear that Jon has eaten from the total amount of pears 7 (total amount) – 2 (eaten) = 5 pears left.
Masukan Anda di sini.
Dan inilah teknik terakhir.
4. Anjuran Pengetahuan Umum
Praktik umum rekayasa cepat adalah menambah kueri dengan pengetahuan tambahan sebelum mengirimkan panggilan API final ke GPT-3 atau GPT-4.
Menurut Jiacheng Liu dan rekannya, kami selalu dapat menambahkan pengetahuan pada permintaan apa pun sehingga LLM lebih mengetahui pertanyaan tersebut.
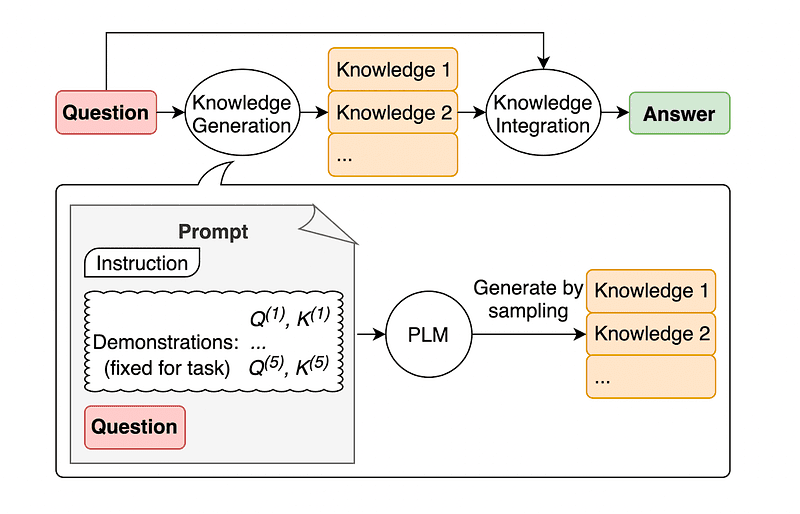
Gambar diambil dari kertas.
Jadi misalnya, ketika menanyakan ChatGPT apakah suatu bagian golf mencoba mendapatkan total poin lebih tinggi daripada yang lain, hal itu akan memvalidasi kami. Namun, tujuan utama golf justru sebaliknya. Inilah sebabnya kita dapat menambahkan beberapa pengetahuan sebelumnya dengan mengatakan “Pemain dengan skor lebih rendah menang”.

Jadi.. apa lucunya jika kita memberi tahu model jawabannya?
Dalam hal ini, teknik ini digunakan untuk meningkatkan cara LLM berinteraksi dengan kami.
So rather than pulling supplementary context from an outside database, the paper’s authors recommend having the LLM produce its own knowledge. This self-generated knowledge is then integrated into the prompt to bolster commonsense reasoning and give better outputs.
Jadi beginilah cara LLM ditingkatkan tanpa menambah kumpulan data pelatihannya!
Rekayasa cepat telah muncul sebagai teknik penting dalam meningkatkan kemampuan LLM. Dengan mengulangi dan meningkatkan perintah, kita dapat berkomunikasi secara lebih langsung dengan model AI sehingga memperoleh keluaran yang lebih akurat dan relevan secara kontekstual, sehingga menghemat waktu dan sumber daya.
Bagi para penggemar teknologi, ilmuwan data, dan pembuat konten, memahami dan menguasai teknik cepat dapat menjadi aset berharga dalam memanfaatkan potensi AI sepenuhnya.
Dengan menggabungkan perintah masukan yang dirancang dengan cermat dengan teknik yang lebih canggih ini, memiliki keahlian teknik cepat pasti akan memberi Anda keunggulan di tahun-tahun mendatang.
Josep Ferrer adalah seorang insinyur analitik dari Barcelona. Dia lulus dalam bidang teknik fisika dan saat ini bekerja di bidang Ilmu Data yang diterapkan pada mobilitas manusia. Dia adalah pembuat konten paruh waktu yang berfokus pada ilmu dan teknologi data. Anda dapat menghubunginya di LinkedIn, Twitter or Medium.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models?utm_source=rss&utm_medium=rss&utm_campaign=some-kick-ass-prompt-engineering-techniques-to-boost-our-llm-models
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 10
- 11
- 2022
- 29
- 7
- 8
- a
- kemampuan
- Tentang Kami
- ketepatan
- tepat
- tindakan
- sebenarnya
- menambahkan
- menambahkan
- Tambahan
- maju
- Setelah
- lagi
- AI
- Model AI
- bertujuan
- selaras
- sama
- Semua
- Membiarkan
- sepanjang
- sudah
- selalu
- am
- jumlah
- an
- analisis
- dan
- Lain
- menjawab
- Apa pun
- api
- terapan
- ADALAH
- AS
- meminta
- meminta
- aset
- penulis
- secara otomatis
- menghindari
- sadar
- jauh
- kembali
- Buruk
- barcelona
- dasar
- BE
- karena
- menjadi
- sebelum
- makhluk
- TERBAIK
- Lebih baik
- mendukung
- mendorong
- Membosankan
- kedua
- membeli
- Melambung
- Istirahat
- istirahat
- Membawa
- lebih luas
- tapi
- Beli
- by
- panggilan
- CAN
- kemampuan
- hati-hati
- kasus
- rantai
- rantai
- menantang
- tantangan
- ChatGPT
- Pilih
- rekan
- bergabung
- menggabungkan
- bagaimana
- datang
- kedatangan
- Umum
- menyampaikan
- sebanding
- lengkap
- kompleks
- dianggap
- konsisten
- kontak
- Konten
- pencipta konten
- konteks
- Koreksi
- benar
- bisa
- dibuat
- pencipta
- pencipta
- Sekarang
- data
- ilmu data
- Basis Data
- Mendefinisikan
- mengantarkan
- dirancang
- diinginkan
- perbedaan
- berbeda
- langsung
- arah
- menemukan
- penyelaman
- do
- tidak
- domain
- domain
- turun
- setiap
- Tepi
- efektivitas
- efisiensi
- muncul
- insinyur
- Teknik
- mempertinggi
- meningkatkan
- cukup
- memastikan
- peminat
- persis
- contoh
- contoh
- menjalankan
- mengharapkan
- Menjelaskan
- penjelasan
- akrab
- beberapa
- bidang
- terakhir
- Akhirnya
- Pertama
- terfokus
- berfokus
- berikut
- Untuk
- paksaan
- Depan
- teman
- dari
- penuh
- lucu
- Umum
- menghasilkan
- mendapatkan
- Memberikan
- diberikan
- memberikan
- Go
- tujuan
- golf
- baik
- membimbing
- Sulit
- Memanfaatkan
- Memiliki
- memiliki
- he
- di sini
- berkualitas tinggi
- lebih tinggi
- dia
- -nya
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTTPS
- manusia
- kecerdasan manusia
- i
- ide
- if
- membayangkan
- memperbaiki
- ditingkatkan
- perbaikan
- meningkatkan
- in
- meningkatkan
- informasi
- mulanya
- memasukkan
- contoh
- instruksi
- terpadu
- Intelijen
- interaktif
- menarik
- ke
- diperkenalkan
- melibatkan
- IT
- NYA
- John
- jon
- hanya
- KDnugget
- Menjaga
- menendang
- Kicks
- Tahu
- pengetahuan
- tahu
- bahasa
- Terakhir
- Terlambat
- Memimpin
- Melompat
- pengetahuan
- meninggalkan
- meninggalkan
- kurang
- membiarkan
- membiarkan
- leveraging
- 'like'
- menurunkan
- sihir
- Utama
- membuat
- Membuat
- cara
- panduan
- banyak
- Menguasai
- hal
- me
- cara
- mental yang
- penggabungan
- metode
- mungkin
- mobilitas
- model
- model
- lebih
- paling
- bergerak
- beberapa
- harus
- Perlu
- tak pernah
- tidak
- sekarang
- memperoleh
- of
- on
- sekali
- seberang
- mengoptimalkan
- or
- Lainnya
- Lainnya
- kami
- di luar
- keluaran
- output
- di luar
- sendiri
- kertas
- bagian
- path
- sempurna
- melakukan
- prestasi
- Fisika
- sangat penting
- plato
- Kecerdasan Data Plato
- Data Plato
- pemain
- Titik
- potensi
- praktek
- tepat
- menyajikan
- cukup
- sebelumnya
- Masalah
- masalah
- proses
- menghasilkan
- produktifitas
- memberikan
- menyediakan
- menarik
- pertanyaan
- agak
- jarak
- agak
- nyata
- alasan
- sarankan
- menurunkan
- mengacu
- relevan
- permintaan
- ketahanan
- intensif sumber daya
- Sumber
- menanggapi
- tanggapan
- tanggapan
- Hasil
- pelatihan ulang
- Revolusi
- benar
- Kamar
- s
- sama
- penghematan
- Ilmu
- Sains dan Teknologi
- ilmuwan
- skor
- melihat
- mengirim
- mengirim
- Urutan
- set
- beberapa
- Menunjukkan
- signifikan
- ketrampilan
- So
- semata-mata
- MEMECAHKAN
- Memecahkan
- beberapa
- Seseorang
- sesuatu
- tertentu
- menghabiskan
- magang
- awal
- dimulai
- mengemudikan
- Langkah
- Tangga
- Masih
- gaya
- yakin
- memecahkan
- diambil
- tugas
- tugas
- tech
- teknik
- teknik
- Teknologi
- jitu
- istilah
- dari
- bahwa
- Grafik
- Mereka
- kemudian
- Sana.
- karena itu
- Ini
- mereka
- berpikir
- Pikir
- ini
- pikir
- Melalui
- Demikian
- waktu
- untuk
- NADA
- Total
- SAMA SEKALI
- Pelatihan VE
- Pelatihan
- pohon
- mencoba
- mencoba
- mencoba
- dua
- terakhir
- bawah
- menjalani
- memahami
- pemahaman
- niscaya
- us
- menggunakan
- bekas
- menggunakan
- MENGESAHKAN
- Berharga
- berbagai
- serba guna
- sangat
- ingin
- Cara..
- cara
- we
- terkenal
- adalah
- ketika
- yang
- mengapa
- akan
- angin
- dengan
- dalam
- tanpa
- Word
- kerja
- dunia
- Salah
- tahun
- namun
- Menghasilkan
- kamu
- Anda
- zephyrnet.dll