Runtime Amazon EMR untuk Apache Spark adalah runtime yang dioptimalkan kinerjanya untuk Apache Spark yang 100% kompatibel dengan API dengan Apache Spark sumber terbuka. Dengan Amazon ESDM rilis 6.9.0, waktu proses EMR untuk Apache Spark mendukung versi Spark yang setara 3.3.0.
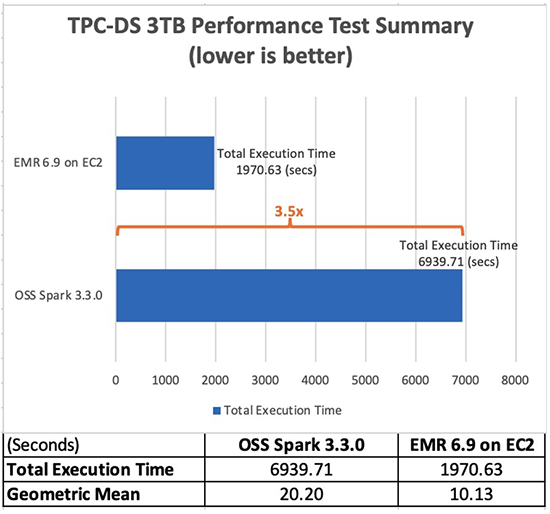
Dengan Amazon EMR 6.9.0, Anda sekarang dapat menjalankan aplikasi Apache Spark 3.x lebih cepat dan dengan biaya lebih rendah tanpa memerlukan perubahan apa pun pada aplikasi Anda. Dalam pengujian tolok ukur kinerja kami, yang berasal dari pengujian kinerja TPC-DS pada skala 3 TB, kami menemukan waktu proses EMR untuk Apache Spark 3.3.0 memberikan peningkatan kinerja rata-rata 3.5 kali (menggunakan total waktu proses) dibandingkan Apache Spark 3.3.0 sumber terbuka. XNUMX.
Dalam posting ini, kami menganalisis hasil dari pengujian benchmark kami yang menjalankan aplikasi TPC-DS Apache Spark sumber terbuka lalu di Amazon EMR 6.9, yang hadir dengan runtime Spark yang dioptimalkan dan kompatibel dengan Spark sumber terbuka. Kami menelusuri analisis biaya mendetail dan akhirnya memberikan petunjuk langkah demi langkah untuk menjalankan tolok ukur.
Hasil diamati
Untuk mengevaluasi peningkatan kinerja, kami menggunakan utilitas uji kinerja Spark sumber terbuka yang berasal dari perangkat uji kinerja TPC-DS. Kami menjalankan pengujian pada klaster EMR c5d.9xlarge tujuh node (enam node inti dan satu node utama) dengan runtime EMR untuk Apache Spark, dan klaster swakelola tujuh node kedua di Cloud komputasi elastis Amazon (Amazon EC2) dengan versi sumber terbuka Spark yang setara. Kami menjalankan kedua tes dengan data masuk Layanan Penyimpanan Sederhana Amazon (Amazon S3).
Alokasi Sumber Daya Dinamis (DRA) adalah fitur hebat yang digunakan untuk berbagai beban kerja. Namun, untuk latihan pembandingan di mana kami membandingkan dua platform murni berdasarkan kinerja, dan volume data pengujian tidak berubah (3 TB dalam kasus kami), kami yakin sebaiknya hindari variabilitas untuk menjalankan perbandingan apel-ke-apel. Dalam pengujian kami di Spark sumber terbuka dan Amazon EMR, kami menonaktifkan DRA saat menjalankan aplikasi pembandingan.
Tabel berikut menampilkan total waktu proses tugas untuk semua kueri (dalam detik) dalam set data kueri 3 TB antara Amazon EMR versi 6.9.0 dan sumber terbuka Spark versi 3.3.0. Kami mengamati bahwa pengujian TPC-DS kami memiliki total waktu proses pekerjaan di Amazon EMR di Amazon EC2 yang 3.5 kali lebih cepat daripada yang menggunakan klaster Spark sumber terbuka dengan konfigurasi yang sama.
Percepatan per kueri di Amazon EMR 6.9 dengan dan tanpa runtime EMR untuk Apache Spark diilustrasikan dalam bagan berikut. Sumbu horizontal menampilkan setiap kueri dalam tolok ukur 3 TB. Sumbu vertikal menunjukkan percepatan setiap kueri karena runtime EMR. Peningkatan performa yang signifikan lebih dari 10 kali lebih cepat untuk kueri TPC-DS 24b, 72, 95, dan 96.

Analisis biaya
Peningkatan kinerja runtime EMR untuk Apache Spark secara langsung menghasilkan biaya yang lebih rendah. Kami dapat mewujudkan penghematan biaya sebesar 67% dalam menjalankan aplikasi benchmark di Amazon EMR dibandingkan dengan biaya yang dikeluarkan untuk menjalankan aplikasi yang sama di Spark sumber terbuka di Amazon EC2 dengan ukuran klaster yang sama berkat pengurangan jam kerja Amazon EMR dan Amazon penggunaan EC2. Harga Amazon EMR adalah untuk aplikasi EMR yang berjalan di klaster EMR dengan instans EC2. Harga Amazon EMR ditambahkan ke harga komputasi dan penyimpanan dasar seperti harga instans EC2 dan Toko Blok Elastis Amazon (Amazon EBS) biaya (jika melampirkan volume EBS). Secara keseluruhan, estimasi biaya tolok ukur di Wilayah AS Timur (Virginia U.) adalah $27.01 per proses untuk Spark sumber terbuka di Amazon EC2 dan $8.82 per proses untuk Amazon EMR.
| Pekerjaan Tolok Ukur | Waktu Proses (Jam) | Estimasi biaya | Total Instans EC2 | Jumlah vCPU | Memori Total (GiB) | Perangkat Root (Amazon EBS) |
|
Spark sumber terbuka di Amazon EC2 (1 node utama dan 6 inti) |
2.23 | $27.01 | 7 | 252 | 504 | 20 GiB gp2 |
|
Amazon EMR di Amazon EC2 (1 node utama dan 6 inti) |
0.63 | $8.82 | 7 | 252 | 504 | 20 GiB gp2 |
Rincian biaya
Berikut adalah perincian biaya untuk pekerjaan Spark sumber terbuka di Amazon EC2 ($27.01):
- Total biaya Amazon EC2 – (7 * $1.728 * 2.23) = (jumlah instans * c5d.9xbesar tarif per jam * runtime pekerjaan dalam jam) = $26.97
- Biaya Amazon EBS – ($0.1/730 * 20 * 7 * 2.23) = (Amazon EBS per GB-tarif per jam * ukuran root EBS * jumlah instans * runtime tugas dalam jam) = $0.042
Berikut adalah perincian biaya untuk Amazon EMR pada pekerjaan Amazon EC2 ($8.82):
- Total biaya Amazon EMR – (7 * $0.27 * 0.63) = ((jumlah node inti + jumlah node utama)* harga Amazon EMR c5d.9xlarge * runtime pekerjaan dalam jam) = $1.19
- Total biaya Amazon EC2 – (7 * $1.728 * 0.63) = ((jumlah node inti + jumlah node utama)* harga instans c5d.9xlarge * runtime tugas dalam jam) = $7.62
- Biaya Amazon EBS – ($0.1/730 * 20 GiB * 7 * 0.63) = (tarif Amazon EBS per GB per jam * ukuran EBS * jumlah instans * runtime tugas dalam jam) = $0.012
Siapkan pembandingan OSS Spark
Pada bagian berikut, kami memberikan garis besar singkat tentang langkah-langkah yang terlibat dalam menyiapkan pembandingan. Untuk instruksi terperinci dengan contoh, lihat GitHub repo.
Untuk pembandingan OSS Spark kami, kami menggunakan alat sumber terbuka Batu api untuk meluncurkan kami yang berbasis Amazon EC2 Apache Spark gugus. Flintrock menyediakan cara cepat untuk meluncurkan klaster Apache Spark di Amazon EC2 menggunakan baris perintah.
Prasyarat
Selesaikan langkah-langkah prasyarat berikut:
- Memiliki Python 3.7.x atau lebih tinggi.
- Memiliki Pip3 22.2.2 atau lebih tinggi.
- Tambahkan direktori bin Python ke jalur lingkungan Anda. Biner Flintrock akan dipasang di jalur ini.
- Run
aws configureuntuk mengkonfigurasi Anda Antarmuka Baris Perintah AWS (AWS CLI) shell untuk menunjuk ke akun pembandingan. Mengacu pada Konfigurasi cepat dengan konfigurasi aws untuk instruksi. - memiliki pasangan kunci dengan izin file terbatas untuk mengakses node utama OSS Spark.
- Buat bucket S3 baru di akun pengujian Anda jika perlu.
- Salin data sumber TPC-DS sebagai input ke bucket S3 Anda.
- Membangun aplikasi benchmark mengikuti langkah-langkah yang disediakan di Langkah-langkah membangun aplikasi spark-benchmark-assembly. Atau, Anda dapat mengunduh file yang sudah dibuat sebelumnya spark-benchmark-assembly-3.3.0.jar jika Anda menginginkan aplikasi berbasis Spark 3.3.0.
Terapkan cluster Spark dan jalankan tugas benchmark
Selesaikan langkah-langkah berikut:
- Instal alat Flintrock melalui pip seperti yang ditunjukkan pada Langkah-langkah untuk menyiapkan Tolok Ukur OSS Spark.
- Jalankan perintah flintrock configure, yang memunculkan file konfigurasi default.
- Ubah default
config.yamlfile berdasarkan kebutuhan Anda. Atau, salin dan tempel file file config.yaml konten ke file konfigurasi default. Kemudian simpan file ke tempatnya. - Terakhir, luncurkan klaster Spark 7-simpul di Amazon EC2 melalui Flintrock.
Ini harus membuat cluster Spark dengan satu node utama dan enam node pekerja. Jika Anda melihat pesan kesalahan, periksa ulang nilai file konfigurasi, terutama versi Spark dan Hadoop serta atribut sumber unduhan dan AMI.
Cluster OSS Spark tidak dilengkapi dengan pengelola sumber daya YARN. Untuk mengaktifkannya, kita perlu mengonfigurasi cluster.
- Download situs-benang.xml dan aktifkan-yarn.sh file dari repo GitHub.
- Mengganti dengan alamat IP node utama di cluster Flintrock Anda.
Anda dapat mengambil alamat IP dari konsol Amazon EC2.
- Unggah file ke semua node cluster Spark.
- Jalankan skrip aktifkan benang.
- Aktifkan dukungan Snappy di Hadoop (pekerjaan benchmark membaca data terkompresi Snappy).
- Unduh file JAR aplikasi utilitas benchmark spark-benchmark-assembly-3.3.0.jar ke mesin lokal Anda.
- Salin file ini ke cluster.
- Masuk ke node utama dan mulai YARN.
- Kirim pekerjaan benchmark pada cluster Spark sumber terbuka seperti yang ditunjukkan pada Mengirimkan tugas benchmark.
Ringkas hasilnya
Unduh file hasil tes dari bucket keluaran S3 s3://$YOUR_S3_BUCKET/EC2_TPCDS-TEST-3T-RESULT/timestamp=xxxx/summary.csv/xxx.csv. (Mengganti $YOUR_S3_BUCKET dengan nama bucket S3 Anda.) Anda dapat menggunakan konsol Amazon S3 dan menavigasi ke lokasi output S3 atau menggunakan AWS CLI.
Aplikasi benchmark Spark membuat folder stempel waktu dan menulis file ringkasan di dalam awalan summary.csv. Stempel waktu dan nama file Anda akan berbeda dari yang ditunjukkan pada contoh sebelumnya.
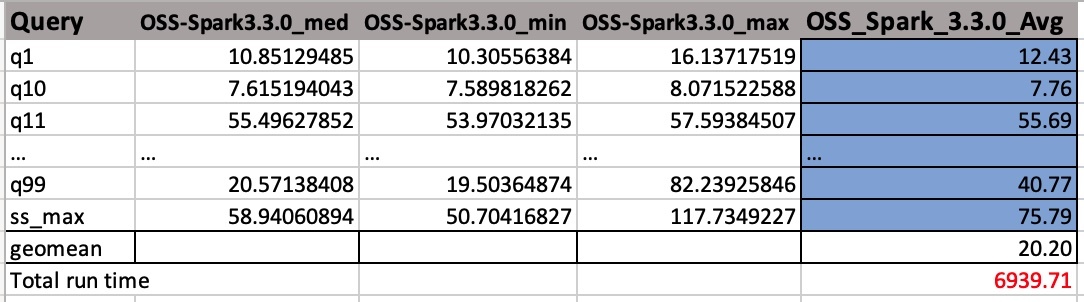
File CSV keluaran memiliki empat kolom tanpa nama header. Mereka:
- Nama kueri
- Waktu tengah
- Waktu minimum
- Waktu maksimal
Tangkapan layar berikut menunjukkan contoh keluaran. Kami telah menambahkan nama kolom secara manual. Cara kami menghitung geomean dan total runtime pekerjaan didasarkan pada cara aritmatika. Pertama-tama kita ambil mean dari nilai med, min, dan max menggunakan rumus AVERAGE(B2:D2). Kemudian kita mengambil rata-rata geometris dari kolom Avg menggunakan rumus GEOMEAN(E2:E105).
Siapkan pembandingan Amazon EMR
Untuk instruksi terperinci, lihat Langkah-langkah untuk menyiapkan Tolok Ukur EMR.
Prasyarat
Selesaikan langkah-langkah prasyarat berikut:
- Run
aws configureuntuk mengonfigurasi shell AWS CLI Anda agar mengarah ke akun pembandingan. Mengacu pada Konfigurasi cepat dengan konfigurasi aws untuk instruksi. - Unggah aplikasi benchmark ke Amazon S3.
Deploy cluster EMR dan jalankan tugas benchmark
Selesaikan langkah-langkah berikut:
- Jalankan Amazon EMR di shell AWS CLI Anda menggunakan baris perintah seperti yang ditunjukkan di Deploy EMR Cluster dan jalankan tugas benchmark.
- Konfigurasikan Amazon EMR dengan satu node utama (c5d.9xlarge) dan enam inti (c5d.9xlarge). Mengacu pada buat-cluster untuk penjelasan mendetail tentang opsi AWS CLI.
- Simpan ID cluster dari respons. Anda membutuhkan ini di langkah selanjutnya.
- Kirimkan pekerjaan tolok ukur di Amazon EMR menggunakan langkah-tambahan di AWS CLI.
Ringkas hasilnya
Ringkas hasil dari keranjang keluaran s3://$YOUR_S3_BUCKET/blog/EMRONEC2_TPCDS-TEST-3T-RESULT dengan cara yang sama seperti yang kami lakukan untuk hasil OSS dan bandingkan.
Membersihkan
Untuk menghindari timbulnya tagihan di masa mendatang, hapus sumber daya yang Anda buat menggunakan petunjuk di Bagian pembersihan dari repo GitHub.
- Hentikan cluster ESDM dan OSS Spark. Anda juga dapat menghapusnya jika tidak ingin mempertahankan kontennya. Anda dapat menghapus sumber daya ini dengan menjalankan skrip pembersihan-benchmark-env.sh dari terminal di lingkungan benchmark Anda.
- Jika Anda dulu AWS Cloud9 sebagai IDE Anda untuk membuat file JAR aplikasi benchmark menggunakan Langkah-langkah membangun aplikasi spark-benchmark-assembly, Anda mungkin ingin menghapus lingkungan juga.
Kesimpulan
Anda dapat menjalankan beban kerja Apache Spark 3.5 kali (berdasarkan waktu proses total) lebih cepat dan dengan biaya lebih rendah tanpa membuat perubahan apa pun pada aplikasi Anda dengan menggunakan Amazon EMR 6.9.0.
Untuk tetap up to date, berlangganan Big Data Blog RSS Feed untuk mempelajari lebih lanjut tentang runtime EMR untuk Apache Spark, praktik terbaik konfigurasi, dan saran penyetelan.
Untuk tes benchmark sebelumnya, lihat Jalankan beban kerja Apache Spark 3.0 1.7 kali lebih cepat dengan runtime Amazon EMR untuk Apache Spark. Perhatikan bahwa hasil tolok ukur sebelumnya sebesar 1.7 kali kinerja didasarkan pada rata-rata geometris. Berdasarkan rata-rata geometris, kinerja di Amazon EMR 6.9 dua kali lebih cepat.
Tentang penulis
 Sekar Srinivasan adalah Sr. Specialist Solutions Architect di AWS yang berfokus pada Big Data dan Analytics. Sekar memiliki lebih dari 20 tahun pengalaman bekerja dengan data. Dia bersemangat membantu pelanggan membangun solusi skalabel yang memodernisasi arsitektur mereka dan menghasilkan wawasan dari data mereka. Di waktu senggangnya, ia suka mengerjakan proyek-proyek nirlaba, terutama yang berfokus pada pendidikan anak-anak kurang mampu.
Sekar Srinivasan adalah Sr. Specialist Solutions Architect di AWS yang berfokus pada Big Data dan Analytics. Sekar memiliki lebih dari 20 tahun pengalaman bekerja dengan data. Dia bersemangat membantu pelanggan membangun solusi skalabel yang memodernisasi arsitektur mereka dan menghasilkan wawasan dari data mereka. Di waktu senggangnya, ia suka mengerjakan proyek-proyek nirlaba, terutama yang berfokus pada pendidikan anak-anak kurang mampu.
 Prabu Ravichandran adalah Arsitek Data Senior dengan Amazon Web Services, berfokus pada Analytics, arsitektur data Lake, dan implementasi. Dia membantu pelanggan merancang dan membangun solusi yang dapat diskalakan dan tangguh menggunakan layanan AWS. Di waktu luangnya, Prabu senang bepergian dan menghabiskan waktu bersama keluarga.
Prabu Ravichandran adalah Arsitek Data Senior dengan Amazon Web Services, berfokus pada Analytics, arsitektur data Lake, dan implementasi. Dia membantu pelanggan merancang dan membangun solusi yang dapat diskalakan dan tangguh menggunakan layanan AWS. Di waktu luangnya, Prabu senang bepergian dan menghabiskan waktu bersama keluarga.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/run-apache-spark-workloads-3-5-times-faster-with-amazon-emr-6-9/
- 1
- 10
- 100
- 1040
- 20 tahun
- 7
- 9
- a
- Sanggup
- Tentang Kami
- atas
- mengakses
- Akun
- menambahkan
- alamat
- nasihat
- Semua
- alokasi
- Amazon
- Amazon EC2
- Amazon ESDM
- Amazon Web Services
- analisis
- analisis
- menganalisa
- dan
- Apache
- Apache Spark
- api
- Aplikasi
- aplikasi
- arsitektur
- atribut
- rata-rata
- AVG
- AWS
- Sumbu
- berdasarkan
- Percaya
- patokan
- TERBAIK
- Praktik Terbaik
- antara
- Besar
- Big data
- Memblokir
- Kerusakan
- membangun
- Bangunan
- kasus
- perubahan
- Perubahan
- beban
- Grafik
- Kelompok
- Kolom
- Kolom
- bagaimana
- membandingkan
- perbandingan
- cocok
- menghitung
- konfigurasi
- konsul
- Konten
- Core
- Biaya
- penghematan biaya
- Biaya
- membuat
- dibuat
- menciptakan
- pelanggan
- data
- Danau Data
- Tanggal
- Default
- Berasal
- deskripsi
- terperinci
- alat
- MELAKUKAN
- berbeda
- langsung
- cacat
- Tidak
- Dont
- Download
- setiap
- Timur
- ebs
- Pendidikan
- aktif
- Lingkungan Hidup
- Setara
- kesalahan
- terutama
- diperkirakan
- Eter (ETH)
- mengevaluasi
- contoh
- contoh
- Latihan
- pengalaman
- keluarga
- lebih cepat
- Fitur
- File
- File
- Akhirnya
- Pertama
- terfokus
- difokuskan
- berikut
- rumus
- ditemukan
- Gratis
- dari
- masa depan
- Keuntungan
- menghasilkan
- GitHub
- besar
- Hadoop
- membantu
- membantu
- Horisontal
- JAM
- Namun
- HTML
- HTTPS
- implementasi
- perbaikan
- perbaikan
- in
- memasukkan
- wawasan
- contoh
- instruksi
- terlibat
- IP
- Alamat IP
- IT
- Pekerjaan
- Menjaga
- danau
- jalankan
- BELAJAR
- baris
- lokal
- tempat
- mesin
- Membuat
- manajer
- cara
- manual
- max
- cara
- Memori
- pesan
- lebih
- nama
- nama
- Arahkan
- Perlu
- dibutuhkan
- kebutuhan
- New
- berikutnya
- simpul
- node
- nirlaba
- penting
- jumlah
- ONE
- open source
- dioptimalkan
- Opsi
- urutan
- Oss
- garis besar
- secara keseluruhan
- bergairah
- lalu
- path
- prestasi
- Izin
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- Pops
- Pos
- praktek
- harga pompa cor beton mini
- harga
- di harga
- primer
- swasta
- memprojeksikan
- memberikan
- disediakan
- menyediakan
- murni
- Ular sanca
- Cepat
- Penilaian
- menyadari
- mengurangi
- wilayah
- melepaskan
- menggantikan
- sumber
- Sumber
- tanggapan
- Bersifat membatasi
- mengakibatkan
- Hasil
- kuat
- akar
- Run
- berjalan
- sama
- Save
- Tabungan
- terukur
- Skala
- Kedua
- detik
- Bagian
- bagian
- senior
- Layanan
- pengaturan
- penyiapan
- Kulit
- harus
- ditunjukkan
- Pertunjukkan
- Sederhana
- ENAM
- Ukuran
- Solusi
- sumber
- percikan
- spesialis
- Pengeluaran
- awal
- Langkah
- Tangga
- penyimpanan
- berlangganan
- seperti itu
- RINGKASAN
- mendukung
- Mendukung
- tabel
- Mengambil
- terminal
- uji
- tes
- Grafik
- mereka
- Melalui
- waktu
- kali
- timestamp
- untuk
- alat
- toolkit
- Total
- menterjemahkan
- Perjalanan
- pokok
- kurang mampu
- us
- penggunaan
- menggunakan
- kegunaan
- Nilai - Nilai
- versi
- melalui
- virginia
- volume
- jaringan
- layanan web
- yang
- sementara
- akan
- tanpa
- Kerja
- pekerja
- kerja
- X
- XML
- yaml
- tahun
- Anda
- zephyrnet.dll