Model bahasa besar (LLM) menjadi semakin populer, dengan kasus penggunaan baru yang terus dieksplorasi. Secara umum, Anda dapat membangun aplikasi yang didukung oleh LLM dengan memasukkan rekayasa cepat ke dalam kode Anda. Namun, ada beberapa kasus di mana dorongan terhadap LLM yang ada gagal. Di sinilah penyempurnaan model dapat membantu. Rekayasa cepat adalah tentang memandu keluaran model dengan menyusun perintah masukan, sedangkan penyesuaian adalah tentang melatih model pada kumpulan data khusus agar lebih sesuai untuk tugas atau domain tertentu.
Sebelum Anda dapat menyempurnakan model, Anda perlu menemukan himpunan data khusus tugas. Salah satu dataset yang umum digunakan adalah Kumpulan data Perayapan Umum. Korpus Common Crawl berisi data berukuran petabyte, dikumpulkan secara rutin sejak 2008, dan berisi data halaman web mentah, ekstrak metadata, dan ekstrak teks. Selain menentukan kumpulan data mana yang harus digunakan, pembersihan dan pemrosesan data sesuai kebutuhan spesifik penyesuaian juga diperlukan.
Kami baru-baru ini bekerja dengan pelanggan yang ingin melakukan praproses subkumpulan kumpulan data Common Crawl terbaru dan kemudian menyempurnakan LLM mereka dengan data yang telah dibersihkan. Pelanggan mencari cara untuk mencapai hal ini dengan cara yang paling hemat biaya di AWS. Setelah mendiskusikan persyaratannya, kami merekomendasikan penggunaan Amazon EMR Tanpa Server sebagai platform mereka untuk pemrosesan awal data. EMR Serverless sangat cocok untuk pemrosesan data skala besar dan menghilangkan kebutuhan akan pemeliharaan infrastruktur. Dari segi biaya, hanya mengenakan biaya berdasarkan sumber daya dan durasi yang digunakan untuk setiap pekerjaan. Pelanggan dapat melakukan praproses ratusan TB data dalam waktu seminggu menggunakan EMR Tanpa Server. Setelah mereka memproses datanya, mereka menggunakannya Amazon SageMaker untuk menyempurnakan LLM.
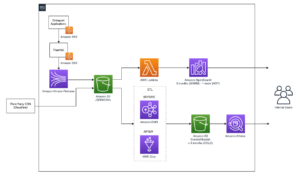
Dalam postingan ini, kami memandu Anda menelusuri kasus penggunaan pelanggan dan arsitektur yang digunakan.
Di bagian berikut, pertama-tama kami memperkenalkan kumpulan data Perayapan Umum dan cara menjelajahi serta memfilter data yang kami perlukan. Amazon Athena hanya mengenakan biaya untuk ukuran data yang dipindai dan digunakan untuk menjelajahi dan memfilter data dengan cepat, sekaligus hemat biaya. EMR Tanpa Server menyediakan opsi hemat biaya dan tanpa pemeliharaan untuk pemrosesan data Spark, dan digunakan untuk memproses data yang difilter. Selanjutnya kita gunakan Mulai Lompatan Amazon SageMaker untuk menyempurnakan Model Lama 2 dengan kumpulan data yang telah diproses sebelumnya. SageMaker JumpStart menyediakan serangkaian solusi untuk kasus penggunaan paling umum yang dapat diterapkan hanya dengan beberapa klik. Anda tidak perlu menulis kode apa pun untuk menyempurnakan LLM seperti Llama 2. Terakhir, kami menerapkan model yang telah disempurnakan menggunakan Amazon SageMaker dan bandingkan perbedaan keluaran teks untuk pertanyaan yang sama antara model Llama 2 asli dan yang telah disempurnakan.
Diagram berikut menggambarkan arsitektur solusi ini.
Sebelum Anda mendalami detail solusinya, selesaikan langkah-langkah prasyarat berikut:
Perayapan Umum adalah kumpulan data korpus terbuka yang diperoleh dengan merayapi lebih dari 50 miliar laman web. Ini mencakup sejumlah besar data tidak terstruktur dalam berbagai bahasa, mulai tahun 2008 dan mencapai tingkat petabyte. Itu terus diperbarui.
Dalam pelatihan GPT-3, kumpulan data Common Crawl menyumbang 60% dari data pelatihannya, seperti yang ditunjukkan dalam diagram berikut (sumber: Model Bahasa adalah Pelajar Sedikit).
Kumpulan data penting lainnya yang perlu disebutkan adalah kumpulan data C4. C4, kependekan dari Colossal Clean Crawled Corpus, adalah kumpulan data yang berasal dari pascapemrosesan kumpulan data Common Crawl. Dalam makalah LLaMA Meta, mereka menguraikan kumpulan data yang digunakan, dengan Common Crawl menyumbang 67% (memanfaatkan 3.3 TB data) dan C4 sebesar 15% (memanfaatkan 783 GB data). Makalah ini menekankan pentingnya menggabungkan data yang telah diproses sebelumnya secara berbeda untuk meningkatkan kinerja model. Meskipun data C4 asli menjadi bagian dari Common Crawl, Meta memilih versi pemrosesan ulang dari data ini.
Di bagian ini, kami membahas cara umum untuk berinteraksi, memfilter, dan memproses kumpulan data Perayapan Umum.
Kumpulan data mentah Common Crawl mencakup tiga jenis file data: data halaman web mentah (WARC), metadata (WAT), dan ekstraksi teks (WET).
Data yang dikumpulkan setelah tahun 2013 disimpan dalam format WARC dan mencakup metadata terkait (WAT) dan data ekstraksi teks (WET). Dataset terletak di Amazon S3, diperbarui setiap bulan, dan dapat diakses langsung melalui Pasar AWS.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzKumpulan data Common Crawl juga menyediakan tabel indeks untuk memfilter data, yang disebut cc-index-table.
Cc-index-table adalah indeks data yang ada, menyediakan indeks file WARC berbasis tabel. Hal ini memungkinkan pencarian informasi dengan mudah, seperti file WARC mana yang sesuai dengan URL tertentu.
Misalnya, Anda bisa membuat tabel Athena untuk memetakan data indeks cc dengan kode berikut:
Pernyataan SQL sebelumnya menunjukkan cara membuat tabel Athena, menambahkan partisi, dan menjalankan kueri.
Filter data dari kumpulan data Common Crawl
Seperti yang Anda lihat dari pernyataan SQL buat tabel, ada beberapa bidang yang dapat membantu memfilter data. Misalnya, jika Anda ingin mendapatkan jumlah dokumen berbahasa Mandarin selama periode tertentu, maka pernyataan SQL-nya bisa seperti berikut:
Jika ingin melakukan pemrosesan lebih lanjut, Anda dapat menyimpan hasilnya ke bucket S3 lain.
Analisis data yang difilter
Grafik Repositori GitHub Perayapan Umum memberikan beberapa contoh PySpark untuk memproses data mentah.
Mari kita lihat contoh lari server_count.py (contoh skrip disediakan oleh repo Common Crawl GitHub) pada data yang terletak di s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Pertama, Anda memerlukan lingkungan Spark, seperti EMR Spark. Misalnya, Anda dapat meluncurkan Amazon EMR pada klaster EC2 di us-east-1 (karena dataset sudah masuk us-east-1). Menggunakan EMR pada klaster EC2 dapat membantu Anda melakukan pengujian sebelum mengirimkan pekerjaan ke lingkungan produksi.
Setelah meluncurkan EMR pada klaster EC2, Anda perlu melakukan login SSH ke node utama klaster. Kemudian, kemas lingkungan Python dan kirimkan skripnya (lihat Dokumentasi Conda untuk menginstal Miniconda):
Diperlukan waktu untuk memproses semua referensi di warc.path. Untuk tujuan demo, Anda dapat meningkatkan waktu pemrosesan dengan strategi berikut:
- Download file
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzke mesin lokal Anda, unzip, lalu unggah ke HDFS atau Amazon S3. Ini karena file .gzip tidak dapat dipisah. Anda perlu mengekstraknya untuk memproses file ini secara paralel. - Ubah
warc.pathfile, hapus sebagian besar barisnya, dan simpan hanya dua baris agar pekerjaan berjalan lebih cepat.
Setelah pekerjaan selesai, Anda dapat melihat hasilnya s3://xxxx-common-crawl/output/, dalam format Parket.
Menerapkan logika kepemilikan yang disesuaikan
Repo Common Crawl GitHub menyediakan pendekatan umum untuk memproses file WARC. Umumnya, Anda dapat memperpanjang CCSparkJob untuk mengganti satu metode (process_record), yang cukup untuk banyak kasus.
Mari kita lihat contoh untuk mendapatkan review IMDB dari film terbaru. Pertama, Anda perlu memfilter file di situs IMDB:
Kemudian Anda bisa mendapatkan daftar file WARC yang berisi data ulasan IMDB, dan menyimpan nama file WARC sebagai daftar dalam file teks.
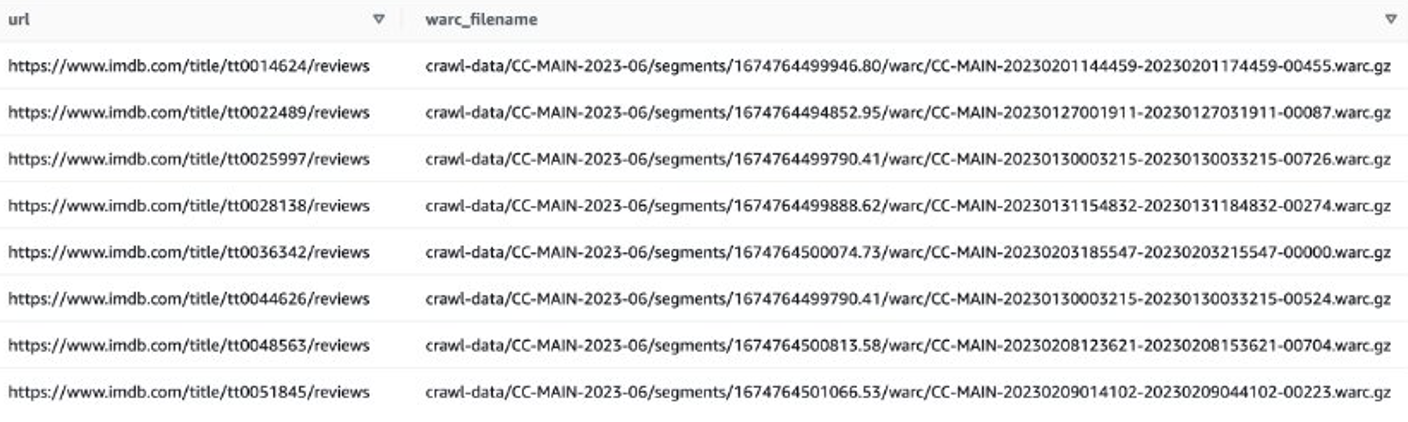
Alternatifnya, Anda dapat menggunakan EMR Spark untuk mendapatkan daftar file WARC dan menyimpannya di Amazon S3. Misalnya:
File keluaran akan terlihat serupa dengan s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Langkah selanjutnya adalah mengekstrak ulasan pengguna dari file WARC ini. Anda dapat memperpanjang CCSparkJob untuk menimpa process_record() Metode:
Anda dapat menyimpan skrip sebelumnya sebagai imdb_extractor.py, yang akan Anda gunakan dalam langkah-langkah berikut. Setelah Anda menyiapkan data dan skrip, Anda dapat menggunakan EMR Serverless untuk memproses data yang disaring.
ESDM Tanpa Server
EMR Tanpa Server adalah opsi penerapan tanpa server untuk menjalankan aplikasi analisis data besar menggunakan kerangka kerja sumber terbuka seperti Apache Spark dan Hive tanpa mengonfigurasi, mengelola, dan menskalakan kluster atau server.
Dengan EMR Tanpa Server, Anda dapat menjalankan beban kerja analitik pada skala apa pun dengan penskalaan otomatis yang mengubah ukuran sumber daya dalam hitungan detik untuk memenuhi perubahan volume data dan persyaratan pemrosesan. EMR Tanpa Server secara otomatis meningkatkan dan menurunkan skala sumber daya untuk menyediakan jumlah kapasitas yang tepat untuk aplikasi Anda, dan Anda hanya membayar sesuai penggunaan.
Memproses himpunan data Perayapan Umum umumnya merupakan tugas pemrosesan satu kali, sehingga cocok untuk beban kerja Tanpa Server EMR.
Buat aplikasi EMR Tanpa Server
Anda dapat membuat aplikasi EMR Serverless di konsol EMR Studio. Selesaikan langkah-langkah berikut:
- Di konsol EMR Studio, pilih Aplikasi bawah Tanpa Server di panel navigasi.
- Pilih Buat aplikasi.

- Berikan nama untuk aplikasi dan pilih versi Amazon EMR.

- Jika akses ke sumber daya VPC diperlukan, tambahkan pengaturan jaringan yang disesuaikan.

- Pilih Buat aplikasi.
Lingkungan tanpa server Spark Anda akan siap.
Sebelum Anda dapat mengirimkan pekerjaan ke EMR Spark Tanpa Server, Anda masih perlu membuat peran eksekusi. Mengacu pada Memulai dengan Amazon EMR Tanpa Server lebih lanjut.
Memproses data Perayapan Umum dengan EMR Tanpa Server
Setelah aplikasi EMR Spark Serverless Anda siap, selesaikan langkah-langkah berikut untuk memproses data:
- Siapkan lingkungan Conda dan unggah ke Amazon S3, yang akan digunakan sebagai lingkungan di EMR Spark Serverless.
- Unggah skrip yang akan dijalankan ke bucket S3. Pada contoh berikut, ada dua skrip:
- imbd_extractor.py – Logika yang disesuaikan untuk mengekstrak konten dari kumpulan data. Isinya bisa dilihat di awal postingan ini.
- cc-pyspark/sparkcc.py – Contoh kerangka kerja PySpark dari Repo GitHub Perayapan Umum, yang perlu disertakan.
- Kirimkan pekerjaan PySpark ke EMR Serverless Spark. Tentukan parameter berikut untuk menjalankan contoh ini di lingkungan Anda:
- id aplikasi – ID aplikasi aplikasi EMR Serverless Anda.
- eksekusi-peran-arn – Peran eksekusi Tanpa Server EMR Anda. Untuk membuatnya, lihat Buat peran runtime pekerjaan.
- Lokasi berkas WARC – Lokasi file WARC Anda.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtberisi daftar file WARC yang difilter, yang Anda peroleh sebelumnya di posting ini. - spark.sql.gudang.dir – Lokasi gudang default (gunakan direktori S3 Anda).
- spark.arsip – Lokasi S3 lingkungan Conda yang disiapkan.
- spark.kirim.pyFiles – Skrip PySpark yang telah disiapkan sparkcc.py.
Lihat kode berikut:
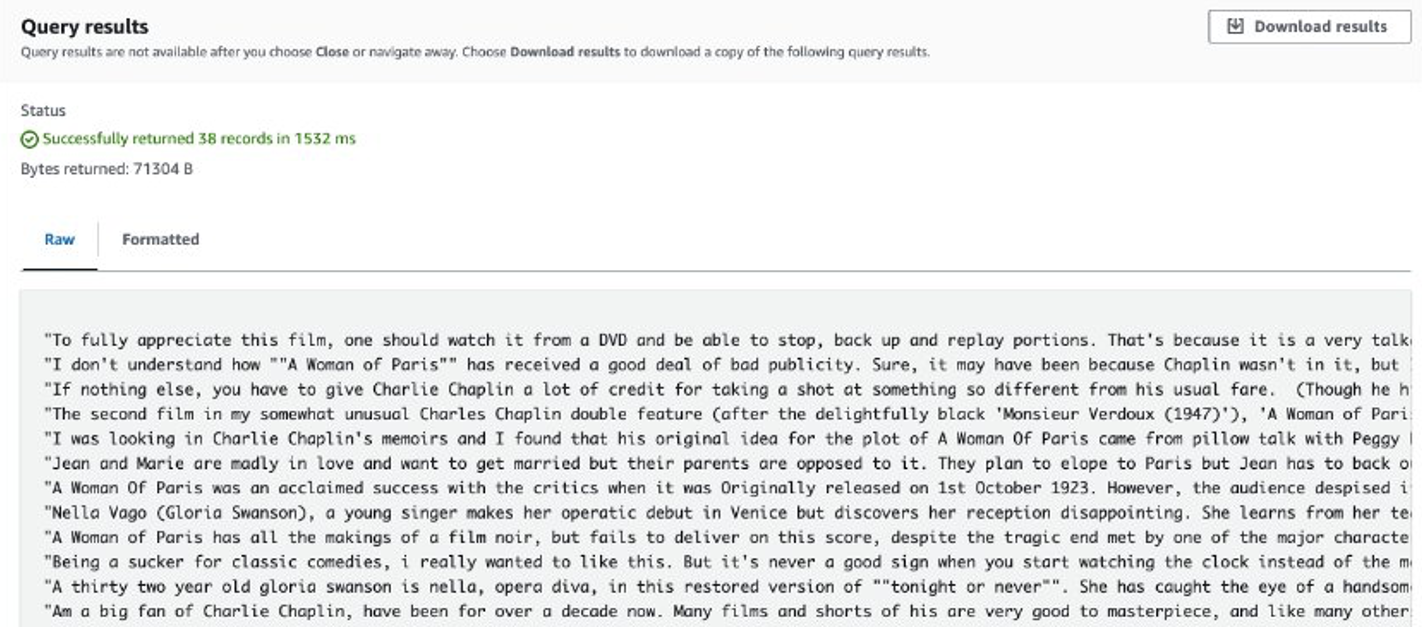
Setelah pekerjaan selesai, ulasan yang diekstrak disimpan di Amazon S3. Untuk memeriksa isinya, Anda dapat menggunakan Amazon S3 Select, seperti yang ditunjukkan pada tangkapan layar berikut.
Pertimbangan
Berikut ini adalah hal-hal yang perlu dipertimbangkan ketika menangani data dalam jumlah besar dengan kode yang disesuaikan:
- Beberapa perpustakaan Python pihak ketiga mungkin tidak tersedia di Conda. Dalam kasus seperti itu, Anda dapat beralih ke lingkungan virtual Python untuk membangun lingkungan runtime PySpark.
- Jika ada sejumlah besar data yang harus diproses, coba buat dan gunakan beberapa aplikasi EMR Serverless Spark untuk memparalelkannya. Setiap aplikasi berhubungan dengan subset daftar file.
- Anda mungkin mengalami masalah pelambatan dengan Amazon S3 saat memfilter atau memproses data Perayapan Umum. Hal ini karena bucket S3 yang menyimpan data dapat diakses secara publik, dan pengguna lain dapat mengakses data tersebut pada saat yang bersamaan. Untuk memitigasi masalah ini, Anda dapat menambahkan mekanisme percobaan ulang atau menyinkronkan data tertentu dari bucket Common Crawl S3 ke bucket Anda sendiri.
Sempurnakan Llama 2 dengan SageMaker
Setelah data disiapkan, Anda dapat menyempurnakan model Llama 2 dengannya. Anda dapat melakukannya menggunakan SageMaker JumpStart, tanpa menulis kode apa pun. Untuk informasi lebih lanjut, lihat Sempurnakan Llama 2 untuk pembuatan teks di Amazon SageMaker JumpStart.
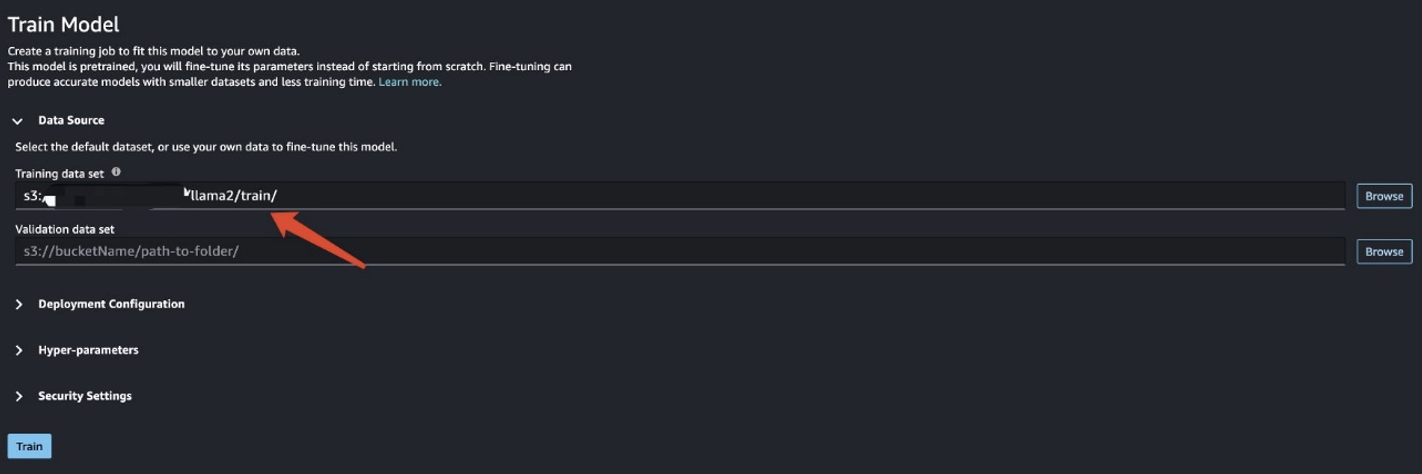
Dalam skenario ini, Anda melakukan penyesuaian adaptasi domain. Dengan dataset ini, input terdiri dari file CSV, JSON, atau TXT. Anda harus memasukkan semua data ulasan ke dalam file TXT. Untuk melakukannya, Anda dapat mengirimkan pekerjaan Spark langsung ke EMR Spark Tanpa Server. Lihat cuplikan kode contoh berikut:
Setelah Anda menyiapkan data pelatihan, masukkan lokasi datanya Kumpulan data pelatihan, Lalu pilih Pelatihan VE.
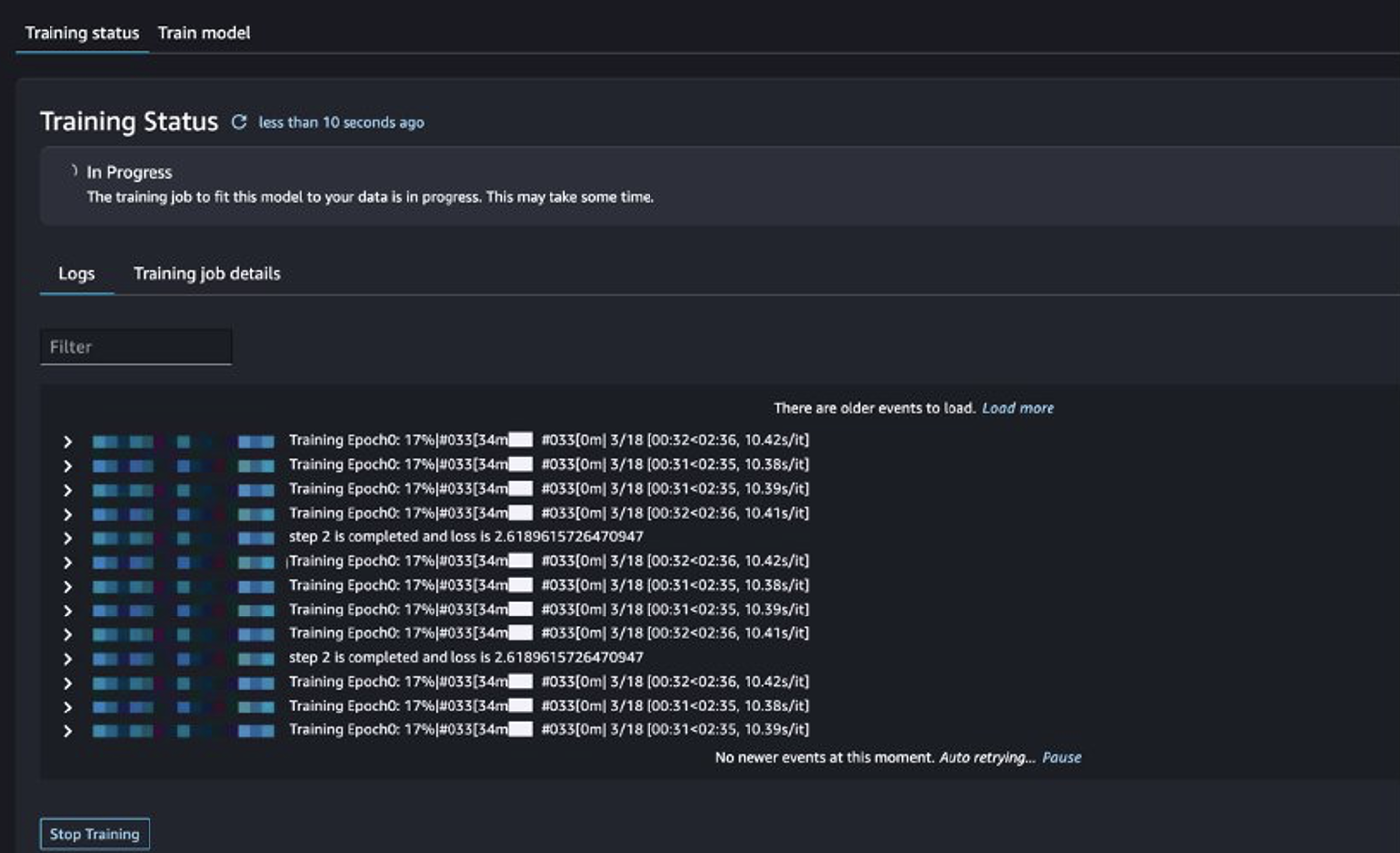
Anda dapat melacak status pekerjaan pelatihan.
Evaluasi model yang telah disesuaikan
Setelah pelatihan selesai, pilih Menyebarkan di SageMaker JumpStart untuk menerapkan model yang telah Anda sesuaikan.

Setelah model berhasil diterapkan, pilih Buka Buku Catatan, yang mengarahkan Anda ke notebook Jupyter yang telah disiapkan tempat Anda dapat menjalankan kode Python Anda.

Anda dapat menggunakan image Data Science 2.0 dan kernel Python 3 untuk notebook.
Kemudian, Anda dapat mengevaluasi model yang telah disempurnakan dan model asli di notebook ini.
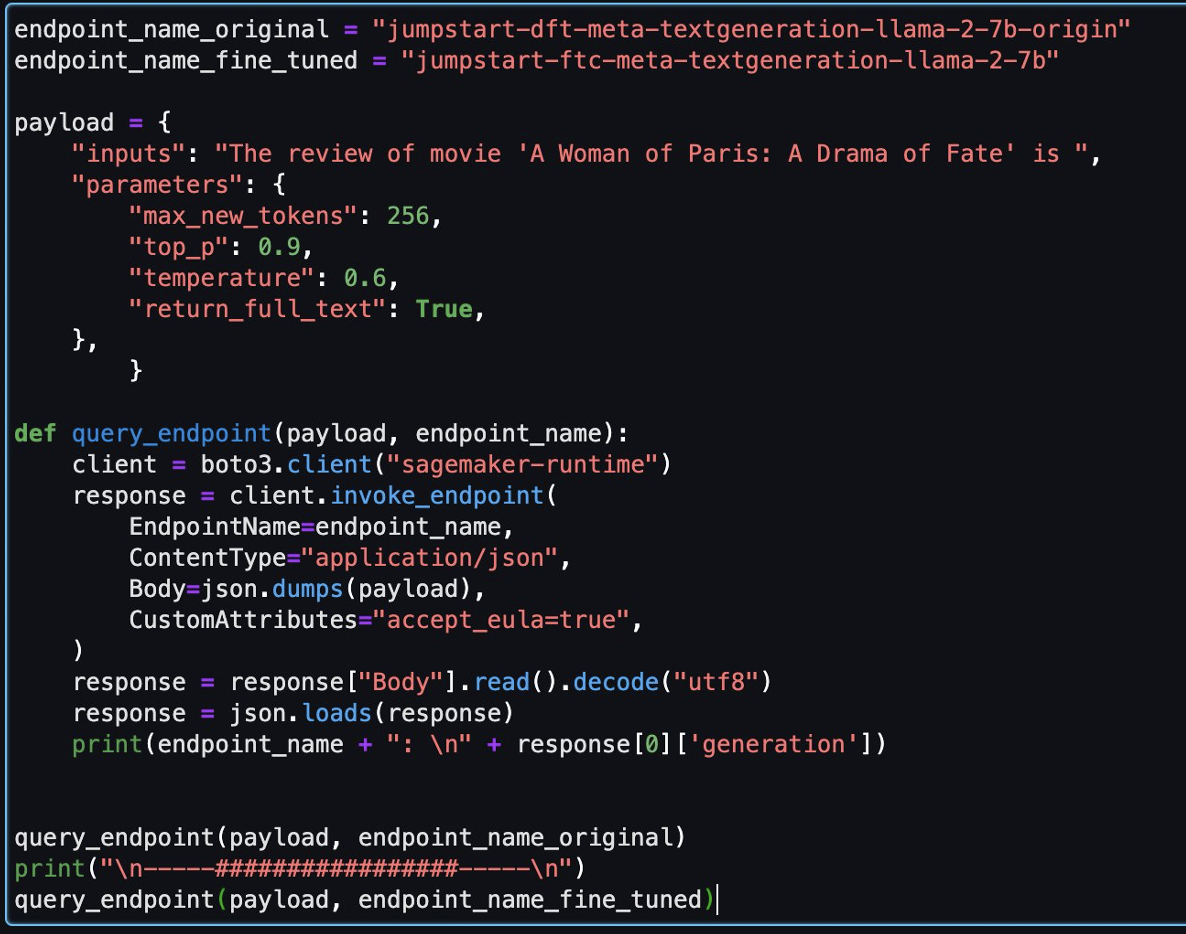
Berikut ini adalah dua tanggapan yang dikembalikan oleh model asli dan model yang telah disesuaikan untuk pertanyaan yang sama.

Kami memberikan kalimat yang sama kepada kedua model: “Ulasan film 'A Woman of Paris: A Drama of Fate' adalah” dan biarkan mereka melengkapi kalimatnya.
Model aslinya menghasilkan kalimat yang tidak berarti:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
Sebaliknya, keluaran model yang disempurnakan lebih mirip ulasan film:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Tentu saja, model yang disempurnakan memiliki kinerja lebih baik dalam skenario khusus ini.
Membersihkan
Setelah Anda menyelesaikan latihan ini, selesaikan langkah-langkah berikut untuk membersihkan sumber daya Anda:
- Hapus keranjang S3 yang menyimpan kumpulan data yang telah dibersihkan.
- Hentikan lingkungan Tanpa Server EMR.
- Hapus titik akhir SageMaker yang menjadi tuan rumah model LLM.
- Hapus domain SageMaker yang menjalankan buku catatan Anda.
Aplikasi yang Anda buat akan berhenti secara otomatis setelah 15 menit tidak aktif secara default.
Secara umum, Anda tidak perlu membersihkan lingkungan Athena karena tidak ada biaya jika Anda tidak menggunakannya.
Kesimpulan
Dalam postingan ini, kami memperkenalkan kumpulan data Perayapan Umum dan cara menggunakan EMR Tanpa Server untuk memproses data untuk penyesuaian LLM. Kemudian kami mendemonstrasikan cara menggunakan SageMaker JumpStart untuk menyempurnakan LLM dan menerapkannya tanpa kode apa pun. Untuk kasus penggunaan EMR Tanpa Server lainnya, lihat Amazon EMR Tanpa Server. Untuk informasi selengkapnya tentang hosting dan penyempurnaan model di Amazon SageMaker JumpStart, lihat Dokumentasi Sagemaker JumpStart.
Tentang Penulis
 Shijian Tang adalah Arsitek Solusi Spesialis Analytics di Amazon Web Services.
Shijian Tang adalah Arsitek Solusi Spesialis Analytics di Amazon Web Services.
 Matius Liem adalah Manajer Arsitektur Solusi Senior di Amazon Web Services.
Matius Liem adalah Manajer Arsitektur Solusi Senior di Amazon Web Services.
 Dalei Xu adalah Arsitek Solusi Spesialis Analytics di Amazon Web Services.
Dalei Xu adalah Arsitek Solusi Spesialis Analytics di Amazon Web Services.
 Yuan Jun Xiao adalah Arsitek Solusi Senior di Amazon Web Services.
Yuan Jun Xiao adalah Arsitek Solusi Senior di Amazon Web Services.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- :adalah
- :bukan
- :Di mana
- $NAIK
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- Sanggup
- Tentang Kami
- mengakses
- diakses
- dapat diakses
- akuntansi
- Akun
- Mencapai
- diaktifkan
- menambahkan
- tambahan
- Afrika
- Setelah
- Semua
- memungkinkan
- juga
- menakjubkan
- Amazon
- Amazon ESDM
- Amazon SageMaker
- Mulai Lompatan Amazon SageMaker
- Amazon Web Services
- jumlah
- jumlah
- an
- analisis
- dan
- Lain
- Apa pun
- Apache
- Apache Spark
- Aplikasi
- aplikasi
- pendekatan
- arsitektur
- ADALAH
- AS
- At
- Australia
- secara otomatis
- secara otomatis
- tersedia
- AWS
- latar belakang
- berdasarkan
- dasar
- BE
- indah
- karena
- menjadi
- sebelum
- mulai
- makhluk
- Lebih baik
- antara
- Besar
- Big data
- Milyar
- tubuh
- kedua
- membangun
- by
- bernama
- CAN
- Bisa Dapatkan
- Kapasitas
- membawa
- kasus
- kasus
- mengubah
- karakter
- beban
- memeriksa
- Cina
- Pilih
- kelas
- membersihkan
- klien
- Kelompok
- kode
- COM
- Umum
- umum
- membandingkan
- lengkap
- mengkonfigurasi
- Mempertimbangkan
- terdiri
- konsul
- terus-menerus
- mengandung
- mengandung
- isi
- terus menerus
- kontras
- Sesuai
- berkorespondensi
- Biaya
- hemat biaya
- bisa
- menghitung
- menutupi
- membuat
- dibuat
- adat
- pelanggan
- disesuaikan
- data
- Data Analytics
- pengolahan data
- ilmu data
- kumpulan data
- Davis
- berurusan
- Penawaran
- mendalam
- Default
- menetapkan
- Demo
- mendemonstrasikan
- menunjukkan
- menyebarkan
- dikerahkan
- penyebaran
- Berasal
- Meskipun
- rincian
- menentukan
- diagram
- perbedaan
- berbeda
- diarahkan
- langsung
- mendiskusikan
- menyelam
- do
- dokumen
- domain
- domain
- donald
- Dont
- turun
- Drama
- pengemudi
- lamanya
- selama
- setiap
- Terdahulu
- Mudah
- menghilangkan
- menekankan
- pertemuan
- Teknik
- meningkatkan
- Enter
- Lingkungan Hidup
- Eter (ETH)
- mengevaluasi
- contoh
- contoh
- eksekusi
- Latihan
- ada
- ada
- menyelidiki
- Dieksplorasi
- memperpanjang
- luar
- ekstrak
- ekstraksi
- Ekstrak
- Air terjun
- palsu
- lebih cepat
- nasib
- fitur
- beberapa
- Fields
- File
- File
- menyaring
- penyaringan
- Akhirnya
- Menemukan
- menyelesaikan
- Pertama
- berikut
- berikut
- Untuk
- format
- ditemukan
- Kerangka
- kerangka
- dari
- lebih lanjut
- Umum
- umumnya
- menghasilkan
- generasi
- mendapatkan
- pergi
- GitHub
- membimbing
- Memiliki
- membantu
- Sarang lebah
- tuan
- host
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- HTTPS
- Ratusan
- i
- IAM
- ID
- if
- menggambarkan
- gambar
- mengimpor
- penting
- memperbaiki
- in
- termasuk
- termasuk
- menggabungkan
- meningkatkan
- indeks
- informasi
- Infrastruktur
- memasukkan
- input
- install
- berinteraksi
- ke
- memperkenalkan
- diperkenalkan
- isu
- IT
- NYA
- dongkrak
- Pekerjaan
- Jobs
- json
- Notebook Jupyter
- hanya
- Menjaga
- kunci
- bahasa
- Bahasa
- besar-besaran
- Terbaru
- jalankan
- peluncuran
- memimpin
- membiarkan
- Tingkat
- perpustakaan
- 'like'
- MEMBATASI
- baris
- Daftar
- daftar
- Llama
- lm
- lokal
- terletak
- tempat
- logika
- masuk
- melihat
- mencari
- lookup
- mesin
- pemeliharaan
- membuat
- Membuat
- manajer
- pelaksana
- banyak
- peta
- besar-besaran
- Mungkin..
- mekanisme
- Pelajari
- Memenuhi
- menyebutkan
- meta
- Metadata
- metode
- menit
- Mengurangi
- model
- model
- bulanan
- lebih
- paling
- film
- bioskop
- banyak
- beberapa
- nama
- nama
- Navigasi
- perlu
- Perlu
- jaringan
- New
- berikutnya
- tidak
- simpul
- buku catatan
- laptop
- diperoleh
- Oktober
- of
- on
- ONE
- hanya
- Buka
- open source
- pilihan
- or
- asli
- Lainnya
- di luar
- diuraikan
- keluaran
- output
- lebih
- mengesampingkan
- sendiri
- pak
- paket
- pane
- kertas
- Paralel
- parameter
- Paris
- bagian
- path
- jalan
- Membayar
- Konsultan Ahli
- prestasi
- pertunjukan
- melakukan
- periode
- petabyte.dll
- Petrus
- juru potret
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- alur
- poin
- Populer
- Pos
- didukung
- pra
- mendahului
- Mempersiapkan
- siap
- primer
- proses
- diproses
- pengolahan
- Produksi
- meminta
- memberikan
- disediakan
- menyediakan
- menyediakan
- di depan umum
- tujuan
- menempatkan
- Ular sanca
- pertanyaan
- pertanyaan
- segera
- Mentah
- data mentah
- mencapai
- Baca
- siap
- baru
- baru-baru ini
- direkomendasikan
- catatan
- lihat
- referensi
- secara teratur
- hubungan
- dirilis
- memperbaiki
- menggantikan
- permintaan
- wajib
- Persyaratan
- Sumber
- tanggapan
- tanggapan
- mengakibatkan
- Hasil
- ulasan
- Review
- benar
- Peran
- rory
- Run
- berjalan
- berjalan
- pembuat bijak
- sama
- Save
- Skala
- sisik
- skala
- scan
- skenario
- Ilmu
- naskah
- script
- detik
- Bagian
- bagian
- melihat
- ruas
- memilih
- DIRI
- senior
- putusan pengadilan
- Tanpa Server
- server
- Layanan
- set
- pengaturan
- beberapa
- dia
- Pendek
- harus
- ditunjukkan
- makna
- mirip
- sejak
- tunggal
- situs web
- Ukuran
- Pelan - pelan
- potongan
- So
- larutan
- Solusi
- sup
- sumber
- percikan
- spesialis
- tertentu
- SQL
- ssh
- mulai
- Mulai
- Pernyataan
- Laporan
- Status
- Langkah
- Tangga
- Masih
- berhenti
- menyimpan
- tersimpan
- toko
- Cerita
- mudah
- strategi
- Tali
- studio
- menyerahkan
- mengirimkan
- berhasil
- seperti itu
- cukup
- cocok
- Beralih
- sinkronisasi.
- tabel
- Mengambil
- target
- tugas
- tugas
- tensorflow
- istilah
- tes
- teks
- pembuatan teks
- bahwa
- Grafik
- mereka
- Mereka
- kemudian
- Sana.
- Ini
- mereka
- pihak ketiga
- ini
- tiga
- Melalui
- waktu
- timestamp
- untuk
- jalur
- Pelatihan
- perjalanan
- benar
- mencoba
- dua
- jenis
- bawah
- tidak terstruktur
- diperbarui
- URL
- menggunakan
- gunakan case
- bekas
- Pengguna
- Ulasan Pengguna
- Pengguna
- menggunakan
- Memanfaatkan
- versi
- maya
- volume
- berjalan
- ingin
- ingin
- Gudang
- adalah
- Cara..
- cara
- we
- jaringan
- layanan web
- minggu
- BAIK
- Apa
- ketika
- sedangkan
- yang
- sementara
- SIAPA
- Margasatwa
- akan
- william
- dengan
- dalam
- tanpa
- wanita
- bekerja
- bernilai
- menulis
- penulisan
- Menghasilkan
- kamu
- Anda
- zephyrnet.dll