
Saat AI bermigrasi dari cloud ke Edge, kami melihat teknologi tersebut digunakan dalam beragam kasus penggunaan – mulai dari deteksi anomali hingga aplikasi termasuk smart shopping, pengawasan, robotika, dan otomatisasi pabrik. Oleh karena itu, tidak ada solusi yang universal. Namun dengan pesatnya pertumbuhan perangkat yang dilengkapi kamera, AI telah banyak diadopsi untuk menganalisis data video real-time guna mengotomatiskan pemantauan video guna meningkatkan keselamatan, meningkatkan efisiensi operasional, dan memberikan pengalaman pelanggan yang lebih baik, yang pada akhirnya mendapatkan keunggulan kompetitif dalam industri mereka. . Untuk mendukung analisis video dengan lebih baik, Anda harus memahami strategi untuk mengoptimalkan kinerja sistem dalam penerapan edge AI.
- Memilih mesin komputasi dengan ukuran yang tepat untuk memenuhi atau melampaui tingkat kinerja yang diperlukan. Untuk aplikasi AI, mesin komputasi ini harus menjalankan fungsi seluruh saluran visi (yaitu, video sebelum dan sesudah pemrosesan, inferensi jaringan saraf).
Akselerator AI khusus, baik terpisah atau terintegrasi ke dalam SoC (sebagai lawan menjalankan inferensi AI pada CPU atau GPU) mungkin diperlukan.
- Memahami perbedaan antara throughput dan latensi; dimana throughput adalah kecepatan pemrosesan data dalam suatu sistem dan latensi mengukur penundaan pemrosesan data melalui sistem dan sering dikaitkan dengan respons waktu nyata. Misalnya, suatu sistem dapat menghasilkan data gambar dengan kecepatan 100 frame per detik (throughput) tetapi dibutuhkan 100ms (latensi) agar gambar dapat melewati sistem.
- Mempertimbangkan kemampuan untuk dengan mudah menskalakan kinerja AI di masa depan untuk mengakomodasi kebutuhan yang terus meningkat, perubahan persyaratan, dan teknologi yang terus berkembang (misalnya, model AI yang lebih canggih untuk meningkatkan fungsionalitas dan akurasi). Anda dapat mencapai penskalaan performa menggunakan akselerator AI dalam format modul atau dengan chip akselerator AI tambahan.
Persyaratan kinerja sebenarnya bergantung pada aplikasi. Biasanya, untuk analisis video, sistem harus memproses aliran data yang masuk dari kamera dengan kecepatan 30-60 frame per detik dan dengan resolusi 1080p atau 4k. Kamera berkemampuan AI akan memproses satu aliran; alat tepi akan memproses banyak aliran secara paralel. Dalam kedua kasus tersebut, sistem edge AI harus mendukung fungsi pra-pemrosesan untuk mengubah data sensor kamera ke dalam format yang sesuai dengan persyaratan input pada bagian inferensi AI (Gambar 1).
Fungsi pra-pemrosesan mengambil data mentah dan melakukan tugas seperti mengubah ukuran, normalisasi, dan konversi ruang warna, sebelum memasukkan masukan ke dalam model yang berjalan pada akselerator AI. Pra-pemrosesan dapat menggunakan pustaka pemrosesan gambar yang efisien seperti OpenCV untuk mengurangi waktu pra-pemrosesan. Postprocessing melibatkan analisis keluaran inferensi. Ia menggunakan tugas-tugas seperti penekanan non-maksimum (NMS menafsirkan keluaran sebagian besar model deteksi objek) dan tampilan gambar untuk menghasilkan wawasan yang dapat ditindaklanjuti, seperti kotak pembatas, label kelas, atau skor kepercayaan.

Gambar 1. Untuk inferensi model AI, fungsi sebelum dan sesudah pemrosesan biasanya dilakukan pada prosesor aplikasi.
Inferensi model AI dapat memiliki tantangan tambahan dalam memproses beberapa model jaringan saraf per frame, bergantung pada kemampuan aplikasi. Aplikasi visi komputer biasanya melibatkan banyak tugas AI yang memerlukan saluran beberapa model. Selain itu, keluaran suatu model sering kali merupakan masukan model berikutnya. Dengan kata lain, model dalam suatu aplikasi sering kali bergantung satu sama lain dan harus dijalankan secara berurutan. Kumpulan model yang akan dieksekusi mungkin tidak statis dan dapat bervariasi secara dinamis, bahkan berdasarkan frame-by-frame.
Tantangan dalam menjalankan beberapa model secara dinamis memerlukan akselerator AI eksternal dengan memori khusus dan cukup besar untuk menyimpan model. Seringkali akselerator AI yang terintegrasi di dalam SoC tidak mampu mengelola beban kerja multi-model karena kendala yang disebabkan oleh subsistem memori bersama dan sumber daya lain di SoC.
Misalnya, pelacakan objek berbasis prediksi gerak mengandalkan deteksi berkelanjutan untuk menentukan vektor yang digunakan untuk mengidentifikasi objek yang dilacak pada posisi masa depan. Efektivitas pendekatan ini terbatas karena tidak mempunyai kemampuan identifikasi ulang yang sebenarnya. Dengan prediksi gerak, jejak suatu objek bisa hilang karena deteksi yang terlewat, oklusi, atau objek meninggalkan bidang pandang, bahkan untuk sesaat. Setelah hilang, tidak ada cara untuk mengaitkan kembali jejak objek tersebut. Menambahkan identifikasi ulang memecahkan keterbatasan ini tetapi memerlukan penyematan tampilan visual (yaitu sidik jari gambar). Penyematan tampilan memerlukan jaringan kedua untuk menghasilkan vektor fitur dengan memproses gambar yang terdapat di dalam kotak pembatas objek yang terdeteksi oleh jaringan pertama. Penyematan ini dapat digunakan untuk mengidentifikasi kembali objek tersebut, terlepas dari waktu atau ruang. Karena penyematan harus dibuat untuk setiap objek yang terdeteksi di bidang pandang, persyaratan pemrosesan meningkat seiring dengan semakin sibuknya pemandangan. Pelacakan objek dengan identifikasi ulang memerlukan pertimbangan yang cermat antara melakukan deteksi akurasi tinggi/resolusi tinggi/kecepatan frame tinggi dan mencadangkan overhead yang cukup untuk skalabilitas penyematan. Salah satu cara untuk mengatasi kebutuhan pemrosesan adalah dengan menggunakan akselerator AI khusus. Seperti disebutkan sebelumnya, mesin AI SoC dapat mengalami kekurangan sumber daya memori bersama. Pengoptimalan model juga dapat digunakan untuk menurunkan persyaratan pemrosesan, namun hal ini dapat memengaruhi performa dan/atau akurasi.
Dalam kamera pintar atau peralatan edge, SoC terintegrasi (yaitu, prosesor host) memperoleh bingkai video dan melakukan langkah-langkah pra-pemrosesan yang kami jelaskan sebelumnya. Fungsi-fungsi ini dapat dilakukan dengan inti CPU atau GPU SoC (jika tersedia), namun fungsi tersebut juga dapat dilakukan oleh akselerator perangkat keras khusus di SoC (misalnya, prosesor sinyal gambar). Setelah langkah-langkah pra-pemrosesan ini selesai, akselerator AI yang terintegrasi ke dalam SoC kemudian dapat langsung mengakses masukan terkuantisasi ini dari memori sistem, atau dalam kasus akselerator AI diskrit, masukan tersebut kemudian dikirimkan untuk inferensi, biasanya melalui Antarmuka USB atau PCIe.
SoC terintegrasi dapat berisi berbagai unit komputasi, termasuk CPU, GPU, akselerator AI, prosesor vision, encoder/decoder video, prosesor sinyal gambar (ISP), dan banyak lagi. Semua unit komputasi ini berbagi bus memori yang sama dan akibatnya mengakses memori yang sama. Selain itu, CPU dan GPU mungkin juga harus berperan dalam inferensi dan unit-unit ini akan sibuk menjalankan tugas lain dalam sistem yang diterapkan. Inilah yang kami maksud dengan overhead tingkat sistem (Gambar 2).
Banyak pengembang yang secara keliru mengevaluasi kinerja akselerator AI bawaan di SoC tanpa mempertimbangkan pengaruh overhead tingkat sistem terhadap kinerja total. Sebagai contoh, pertimbangkan untuk menjalankan benchmark YOLO pada akselerator AI 50 TOPS yang terintegrasi dalam SoC, yang mungkin memperoleh hasil benchmark 100 inferensi/detik (IPS). Namun dalam sistem yang diterapkan dengan semua unit komputasi lainnya aktif, 50 TOPS tersebut dapat dikurangi menjadi sekitar 12 TOPS dan kinerja keseluruhan hanya akan menghasilkan 25 IPS, dengan asumsi faktor pemanfaatan sebesar 25%. Overhead sistem selalu menjadi faktor jika platform terus memproses streaming video. Alternatifnya, dengan akselerator AI terpisah (misalnya, Kinara Ara-1, Hailo-8, Intel Myriad X), pemanfaatan tingkat sistem bisa lebih besar dari 90% karena begitu SoC host memulai fungsi inferensi dan mentransfer masukan model AI data, akselerator berjalan secara mandiri menggunakan memori khusus untuk mengakses bobot dan parameter model.
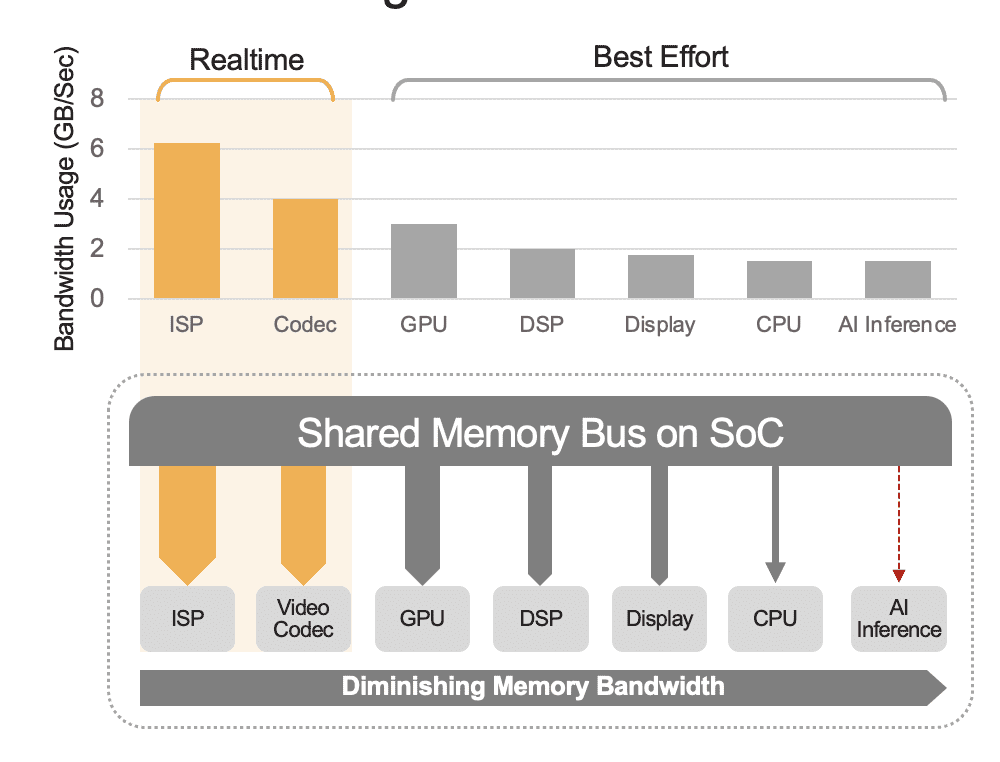
Gambar 2. Bus memori bersama akan mengatur kinerja tingkat sistem, ditunjukkan di sini dengan nilai perkiraan. Nilai sebenarnya akan bervariasi berdasarkan model penggunaan aplikasi Anda dan konfigurasi unit komputasi SoC.
Sampai saat ini, kita telah membahas performa AI dalam hal frame per detik dan TOPS. Namun latensi rendah merupakan persyaratan penting lainnya untuk memberikan respons sistem secara real-time. Misalnya, dalam game, latensi rendah sangat penting untuk pengalaman bermain game yang lancar dan responsif, khususnya dalam game yang dikontrol gerakan dan sistem realitas virtual (VR). Dalam sistem mengemudi otonom, latensi rendah sangat penting untuk deteksi objek, pengenalan pejalan kaki, deteksi jalur, dan pengenalan rambu lalu lintas secara real-time agar tidak membahayakan keselamatan. Sistem mengemudi otonom biasanya memerlukan latensi end-to-end kurang dari 150 ms mulai dari deteksi hingga tindakan sebenarnya. Demikian pula, di bidang manufaktur, latensi rendah sangat penting untuk deteksi cacat secara real-time, pengenalan anomali, dan panduan robotik yang bergantung pada analisis video latensi rendah untuk memastikan pengoperasian yang efisien dan meminimalkan waktu henti produksi.
Secara umum, ada tiga komponen latensi dalam aplikasi analisis video (Gambar 3):
- Latensi pengambilan data adalah waktu mulai dari sensor kamera menangkap bingkai video hingga ketersediaan bingkai ke sistem analitik untuk diproses. Anda dapat mengoptimalkan latensi ini dengan memilih kamera dengan sensor cepat dan prosesor latensi rendah, memilih kecepatan bingkai optimal, dan menggunakan format kompresi video yang efisien.
- Latensi transfer data adalah waktu bagi data video yang diambil dan dikompresi untuk berpindah dari kamera ke perangkat edge atau server lokal. Ini termasuk penundaan pemrosesan jaringan yang terjadi di setiap titik akhir.
- Latensi pemrosesan data mengacu pada waktu bagi perangkat edge untuk melakukan tugas pemrosesan video seperti dekompresi bingkai dan algoritme analitik (misalnya, pelacakan objek berbasis prediksi gerakan, pengenalan wajah). Seperti disebutkan sebelumnya, latensi pemrosesan menjadi lebih penting lagi untuk aplikasi yang harus menjalankan beberapa model AI untuk setiap frame video.
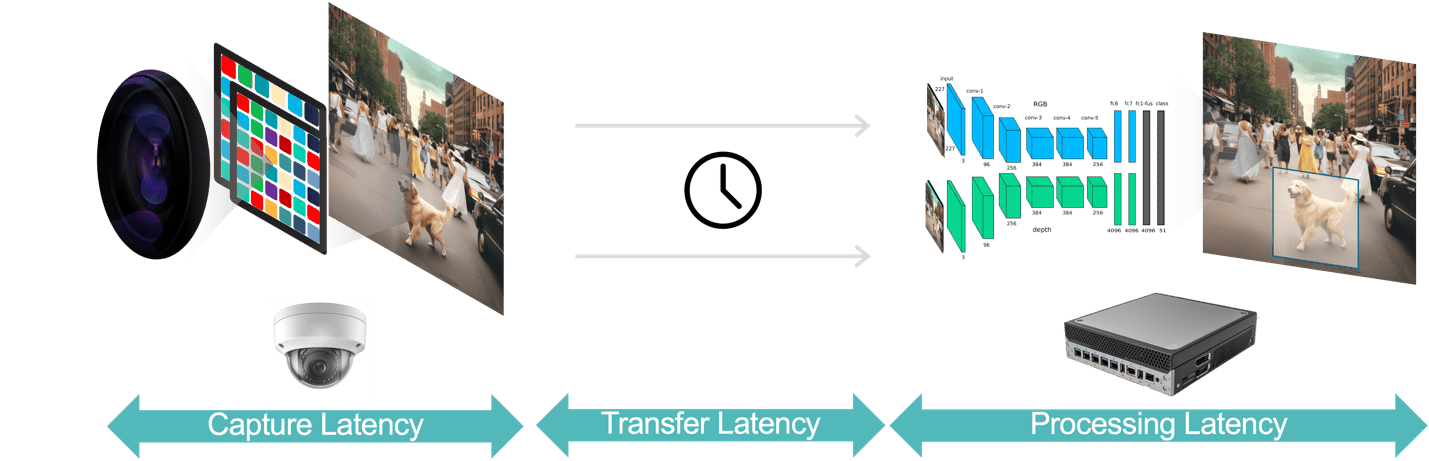
Gambar 3. Saluran analisis video terdiri dari pengambilan data, transfer data, dan pemrosesan data.
Latensi pemrosesan data dapat dioptimalkan menggunakan akselerator AI dengan arsitektur yang dirancang untuk meminimalkan pergerakan data di seluruh chip dan antara komputasi dan berbagai tingkat hierarki memori. Selain itu, untuk meningkatkan latensi dan efisiensi tingkat sistem, arsitektur harus mendukung waktu peralihan antar model nol (atau mendekati nol), agar lebih mendukung aplikasi multi-model yang telah kita bahas sebelumnya. Faktor lain untuk peningkatan kinerja dan latensi berkaitan dengan fleksibilitas algoritmik. Dengan kata lain, beberapa arsitektur dirancang untuk perilaku optimal hanya pada model AI tertentu, namun dengan lingkungan AI yang berubah dengan cepat, model baru untuk performa lebih tinggi dan akurasi lebih baik bermunculan setiap hari. Oleh karena itu, pilih prosesor edge AI tanpa batasan praktis pada topologi model, operator, dan ukuran.
Ada banyak faktor yang harus dipertimbangkan dalam memaksimalkan kinerja pada peralatan AI edge termasuk persyaratan kinerja dan latensi serta overhead sistem. Strategi yang berhasil harus mempertimbangkan akselerator AI eksternal untuk mengatasi keterbatasan memori dan kinerja pada mesin AI SoC.
CH Chee adalah eksekutif pemasaran dan manajemen produk yang ulung, Chee memiliki pengalaman luas dalam mempromosikan produk dan solusi di industri semikonduktor, dengan fokus pada AI berbasis visi, konektivitas, dan antarmuka video untuk berbagai pasar termasuk perusahaan dan konsumen. Sebagai seorang wirausaha, Chee ikut mendirikan dua perusahaan rintisan semikonduktor video yang diakuisisi oleh perusahaan semikonduktor publik. Chee memimpin tim pemasaran produk dan senang bekerja dengan tim kecil yang berfokus pada pencapaian hasil luar biasa.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :memiliki
- :adalah
- :bukan
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- kemampuan
- akselerator
- akselerator
- mengakses
- mengakses
- menampung
- menyelesaikan
- ketepatan
- mencapai
- diperoleh
- Mengakuisisi
- di seluruh
- Tindakan
- aktif
- sebenarnya
- menambahkan
- Tambahan
- diadopsi
- maju
- Setelah
- lagi
- AI
- mesin AI
- Model AI
- algoritmik
- algoritma
- Semua
- juga
- selalu
- an
- analisis
- analisis
- menganalisis
- dan
- deteksi anomali
- Lain
- Aplikasi
- aplikasi
- pendekatan
- arsitektur
- ADALAH
- AS
- terkait
- At
- mengotomatisasikan
- Otomatisasi
- otonom
- secara mandiri
- tersedianya
- tersedia
- menghindari
- berdasarkan
- dasar
- BE
- karena
- menjadi
- menjadi
- sebelum
- makhluk
- patokan
- Lebih baik
- antara
- kedua
- Kotak
- kotak
- built-in
- bis
- sibuk
- tapi
- by
- kamar
- kamera
- CAN
- kemampuan
- kemampuan
- menangkap
- ditangkap
- Menangkap
- hati-hati
- kasus
- kasus
- menantang
- mengubah
- keping
- Keripik
- memilih
- kelas
- awan
- warna
- kedatangan
- perusahaan
- kompetitif
- Lengkap
- komponen
- kompromi
- komputasi
- komputasi
- menghitung
- komputer
- Visi Komputer
- Aplikasi Visi Komputer
- kepercayaan
- konfigurasi
- Konektivitas
- Karena itu
- Mempertimbangkan
- pertimbangan
- dianggap
- mengingat
- terdiri
- kendala
- konsumen
- mengandung
- berisi
- kontinu
- terus menerus
- Konversi
- bisa
- CPU
- kritis
- pelanggan
- data
- pengolahan data
- hari
- dedicated
- menunda
- keterlambatan
- menyampaikan
- disampaikan
- tergantung
- Tergantung
- dikerahkan
- penyebaran
- dijelaskan
- dirancang
- terdeteksi
- Deteksi
- Menentukan
- pengembang
- Devices
- perbedaan
- langsung
- dibahas
- Display
- penghentian
- penggerak
- dua
- dinamis
- e
- setiap
- Terdahulu
- mudah
- Tepi
- efek
- efektivitas
- efisiensi
- efisiensi
- efisien
- antara
- embedding
- akhir
- ujung ke ujung
- Mesin
- Mesin
- mempertinggi
- memastikan
- Enterprise
- Seluruh
- Pengusaha
- Lingkungan Hidup
- penting
- diperkirakan
- mengevaluasi
- Bahkan
- Setiap
- berkembang
- contoh
- melebihi
- menjalankan
- dieksekusi
- eksekutif
- mengharapkan
- pengalaman
- Pengalaman
- luas
- Pengalaman yang luas
- luar
- Menghadapi
- pengenalan wajah
- faktor
- faktor
- pabrik
- FAST
- Fitur
- pemberian makanan
- bidang
- Angka
- sidik jari
- Pertama
- keluwesan
- berfokus
- berfokus
- Untuk
- format
- FRAME
- dari
- fungsi
- fungsi
- fungsi
- Selanjutnya
- masa depan
- mendapatkan
- Games
- game
- pengalaman bermain game
- Umum
- menghasilkan
- dihasilkan
- murah hati
- Go
- GPU
- GPU
- besar
- lebih besar
- Pertumbuhan
- Pertumbuhan
- bimbingan
- Perangkat keras
- Memiliki
- karenanya
- di sini
- hirarki
- High
- lebih tinggi
- tuan rumah
- HTTPS
- i
- mengenali
- if
- gambar
- Dampak
- penting
- Dikenakan
- memperbaiki
- ditingkatkan
- in
- Di lain
- termasuk
- Termasuk
- Meningkatkan
- Pada meningkat
- industri
- industri
- Inisiat
- memasukkan
- dalam
- wawasan
- terpadu
- Intel
- Antarmuka
- interface
- ke
- melibatkan
- melibatkan
- tidak peduli
- ISP
- IT
- NYA
- KDnugget
- Label
- Kekurangan
- Jalur
- besar
- Latensi
- meninggalkan
- Dipimpin
- kurang
- adalah ide yang bagus
- perpustakaan
- 'like'
- pembatasan
- keterbatasan
- Terbatas
- lokal
- kalah
- Rendah
- menurunkan
- mengelola
- pengelolaan
- pabrik
- banyak
- Marketing
- pasar
- Maksimalkan
- memaksimalkan
- Mungkin..
- berarti
- ukuran
- Pelajari
- Memori
- tersebut
- mungkin
- terjawab
- model
- model
- modul
- pemantauan
- lebih
- paling
- gerakan
- gerakan
- beberapa
- harus
- banyak sekali
- Dekat
- kebutuhan
- jaringan
- saraf
- saraf jaringan
- New
- berikutnya
- tidak
- obyek
- Deteksi Objek
- terjadi
- of
- sering
- on
- sekali
- ONE
- hanya
- OpenCV
- operasi
- operasional
- operator
- menentang
- optimal
- optimasi
- Optimize
- dioptimalkan
- mengoptimalkan
- or
- Lainnya
- di luar
- keluaran
- lebih
- secara keseluruhan
- Mengatasi
- Paralel
- parameter
- khususnya
- untuk
- melakukan
- prestasi
- dilakukan
- melakukan
- melakukan
- pipa saluran
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Bermain
- Titik
- posisi
- pengolahan pasca
- Praktis
- ramalan
- proses
- diproses
- pengolahan
- Prosesor
- prosesor
- Produk
- Produksi
- Produk
- mempromosikan
- memberikan
- publik
- jarak
- mulai
- cepat
- cepat
- Penilaian
- Tarif
- Mentah
- data mentah
- nyata
- real-time
- Kenyataan
- pengakuan
- menurunkan
- mengacu
- membutuhkan
- wajib
- kebutuhan
- Persyaratan
- membutuhkan
- Resolusi
- Sumber
- responsif
- pembatasan
- mengakibatkan
- Hasil
- robotika
- Peran
- Run
- berjalan
- berjalan
- Safety/keselamatan
- sama
- Skalabilitas
- Skala
- skala ai
- skala
- adegan
- skor
- mulus
- Kedua
- Bagian
- melihat
- tampaknya
- memilih
- semikonduktor
- set
- Share
- berbagi
- tas
- harus
- ditunjukkan
- menandatangani
- Sinyal
- Demikian pula
- sejak
- tunggal
- Ukuran
- kecil
- pintar
- larutan
- Solusi
- MEMECAHKAN
- Memecahkan
- beberapa
- sesuatu
- Space
- tertentu
- start-up
- Tangga
- menyimpan
- strategi
- Penyelarasan
- aliran
- stream
- sukses
- seperti itu
- cukup
- mendukung
- penekanan
- pengawasan
- sistem
- sistem
- Mengambil
- Dibutuhkan
- tugas
- tim
- tim
- Teknologi
- Teknologi
- istilah
- dari
- bahwa
- Grafik
- Masa depan
- mereka
- kemudian
- Sana.
- karena itu
- Ini
- mereka
- ini
- itu
- tiga
- Melalui
- keluaran
- waktu
- kali
- untuk
- tops
- Total
- jalur
- Pelacakan
- lalu lintas
- transfer
- transfer
- Mengubah
- perjalanan
- benar
- dua
- khas
- Akhirnya
- tidak mampu
- memahami
- satuan
- unit
- penggunaan
- usb
- menggunakan
- bekas
- kegunaan
- menggunakan
- biasanya
- Memanfaatkan
- Nilai - Nilai
- variasi
- berbagai
- Video
- View
- maya
- virtual reality
- penglihatan
- vital
- vr
- Cara..
- we
- adalah
- Apa
- apakah
- yang
- sangat
- akan
- dengan
- tanpa
- kata
- kerja
- akan
- X
- Menghasilkan
- Yolo
- kamu
- Anda
- zephyrnet.dll
- nol







