Dua teknologi algoritmik berbasis perangkat lunak terbaru –– pengemudian otonom (ADAS/AD) dan AI generatif (GenAI) –– membuat komunitas teknik semikonduktor tetap terjaga.
Sementara ADAS di Level 2 dan Level 3 berada di jalur yang tepat, AD di Level 4 dan 5 jauh dari kenyataan sehingga menyebabkan penurunan antusiasme modal ventura dan uang. Saat ini, GenAI mendapat perhatian, dan para VC dengan penuh semangat menginvestasikan miliaran dolar.
Kedua teknologi tersebut didasarkan pada algoritma yang modern dan kompleks. Pemrosesan pelatihan dan inferensi mereka memiliki beberapa atribut yang sama, beberapa bersifat penting, yang lainnya penting namun tidak esensial: Lihat tabel I.

Kemajuan perangkat lunak yang luar biasa dalam teknologi ini hingga saat ini belum ditiru oleh kemajuan perangkat keras algoritmik untuk mempercepat pelaksanaannya. Misalnya, prosesor algoritmik canggih tidak memiliki kinerja untuk menjawab kueri ChatGPT-4 dalam satu atau dua detik dengan biaya ¢2 per kueri, tolok ukur yang ditetapkan oleh penelusuran Google, atau untuk memproses data dalam jumlah besar. dikumpulkan oleh sensor AD dalam waktu kurang dari 20 milidetik.
Hingga startup Perancis VSORA menginvestasikan kekuatan otaknya untuk mengatasi hambatan memori yang dikenal sebagai dinding memori.
Dinding Memori
Dinding memori CPU pertama kali dijelaskan oleh Wulf dan McKee pada tahun 1994. Sejak saat itu, akses memori telah menjadi penghambat kinerja komputasi. Kemajuan dalam kinerja prosesor belum tercermin dalam kemajuan akses memori, sehingga menyebabkan prosesor menunggu lebih lama lagi untuk data dikirimkan oleh memori. Pada akhirnya, efisiensi prosesor turun jauh di bawah pemanfaatan 100%.
Untuk mengatasi masalah ini, industri semikonduktor menciptakan struktur memori hierarki multi-level dengan beberapa tingkat cache di dekat prosesor yang mengurangi jumlah lalu lintas dengan memori utama dan eksternal yang lebih lambat.
Kinerja prosesor AD dan GenAI lebih bergantung pada bandwidth memori yang lebar dibandingkan jenis perangkat komputasi lainnya.
VSORA, yang didirikan pada tahun 2015 untuk menargetkan aplikasi 5G, menemukan arsitektur yang dipatenkan yang meruntuhkan struktur memori hierarkis menjadi bandwidth tinggi yang besar, memori berpasangan erat (TCM) yang diakses dalam satu siklus clock.
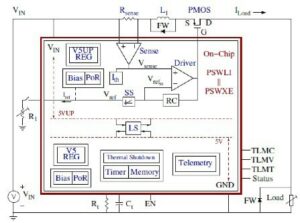
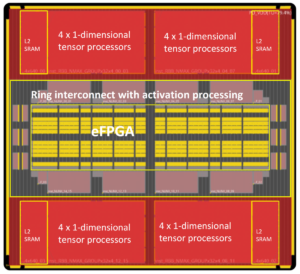
Dari perspektif inti prosesor, TCM terlihat dan bertindak seperti lautan register dalam jumlah MByte versus kByte register fisik sebenarnya. Kemampuan untuk mengakses sel memori apa pun di TMC dalam satu siklus menghasilkan kecepatan eksekusi tinggi, latensi rendah, dan konsumsi daya rendah. Ini juga membutuhkan lebih sedikit area silikon. Memuat data baru dari memori eksternal ke TCM saat data saat ini diproses tidak mempengaruhi throughput sistem. Pada dasarnya, arsitektur memungkinkan pemanfaatan 80+% unit pemrosesan melalui desainnya. Namun, ada kemungkinan untuk menambahkan cache dan memori scratchpad jika perancang sistem menginginkannya. Lihat gambar 1.
")
Melalui struktur memori seperti register yang diterapkan di hampir semua memori di semua aplikasi, keuntungan dari pendekatan memori VSORA tidak dapat dilebih-lebihkan. Biasanya, prosesor GenAI mutakhir memberikan efisiensi persentase satu digit. Misalnya, prosesor GenAI dengan throughput nominal satu Petaflops dengan kinerja nominal tetapi efisiensi kurang dari 5% memberikan kinerja yang dapat digunakan kurang dari 50 Teraflops. Sebaliknya, arsitektur VSORA mencapai efisiensi lebih dari 10 kali lipat.
Akselerator Algoritma VSORA
VSORA memperkenalkan dua kelas akselerator algoritmik –– keluarga Tyr untuk aplikasi AD dan keluarga Jotunn untuk akselerasi GenAI. Keduanya memberikan throughput luar biasa, latensi minimal, konsumsi daya rendah dalam jejak silikon kecil.
Dengan performa nominal hingga tiga Petaflop, mereka memiliki efisiensi implementasi tipikal sebesar 50-80% apa pun jenis algoritmenya, dan konsumsi daya puncak sebesar 30 Watt/Petaflops. Ini adalah atribut luar biasa yang belum dilaporkan oleh akselerator AI kompetitif mana pun.
Tyr dan Jotunn sepenuhnya dapat diprogram dan mengintegrasikan kemampuan AI dan DSP, meskipun dalam jumlah yang berbeda, dan mendukung pemilihan aritmatika langsung dari 8-bit hingga 64-bit baik berbasis integer atau floating-point. Kemampuan programnya mengakomodasi berbagai algoritma, menjadikannya agnostik algoritma. Beberapa jenis ketersebaran yang berbeda juga didukung.
Atribut prosesor VSORA mendorong mereka menjadi yang terdepan dalam lanskap pemrosesan algoritmik yang kompetitif.
Perangkat Lunak Pendukung VSORA
VSORA merancang platform kompilasi/validasi unik yang disesuaikan dengan arsitektur perangkat kerasnya untuk memastikan perangkat SoC yang kompleks dan berkinerja tinggi memiliki banyak dukungan perangkat lunak.
Dimaksudkan untuk menempatkan perancang algoritmik di kokpit, serangkaian tingkat verifikasi/validasi hierarki –– ESL, hybrid, RTL, dan gerbang –– memberikan umpan balik tombol kepada insinyur algoritmik sebagai respons terhadap eksplorasi ruang angkasa desain. Hal ini membantunya memilih kompromi terbaik antara kinerja, latensi, kekuatan, dan area. Kode pemrograman yang ditulis pada abstraksi tingkat tinggi dapat dipetakan dengan menargetkan inti pemrosesan yang berbeda secara transparan kepada pengguna.
Antarmuka antar inti dapat diimplementasikan dalam silikon yang sama, antar chip pada PCB yang sama, atau melalui koneksi IP. Sinkronisasi antar inti dikelola secara otomatis pada waktu kompilasi dan tidak memerlukan pengoperasian perangkat lunak waktu nyata.
Penghalang Jalan menuju Mengemudi Otonom L4/L5 dan Inferensi AI Generatif di Edge
Solusi yang berhasil juga harus mencakup kemampuan program di lapangan. Algoritma berkembang dengan cepat, didorong oleh ide-ide baru yang ketinggalan jaman dalam semalam. Kemampuan untuk meningkatkan algoritma di lapangan merupakan keuntungan yang patut dicatat.
Meskipun perusahaan-perusahaan berskala besar telah membangun kumpulan komputasi besar dengan banyak prosesor berperforma tertinggi untuk menangani algoritme perangkat lunak tingkat lanjut, pendekatan ini hanya praktis untuk pelatihan, bukan untuk inferensi di edge.
Pelatihan biasanya didasarkan pada aritmatika floating-point 32-bit atau 64-bit yang menghasilkan volume data yang besar. Ini tidak menerapkan latensi yang ketat dan mentoleransi konsumsi daya yang tinggi serta biaya yang besar.
Inferensi di edge biasanya dilakukan pada aritmatika floating-point 8-bit yang menghasilkan jumlah data yang lebih sedikit, namun memerlukan latensi tanpa kompromi, konsumsi energi rendah, dan biaya rendah.
Dampak Konsumsi Energi terhadap Latensi dan Efisiensi
Konsumsi daya pada IC CMOS didominasi oleh pergerakan data, bukan pemrosesan data.
Sebuah studi di Universitas Stanford yang dipimpin oleh Profesor Mark Horowitz menunjukkan bahwa konsumsi daya akses memori menghabiskan energi lebih besar daripada perhitungan logika digital dasar. Lihat tabel II.

Akselerator AD dan GenAI adalah contoh utama perangkat yang didominasi oleh pergerakan data yang memberikan tantangan dalam membatasi konsumsi daya.
Kesimpulan
Inferensi AD dan GenAI menimbulkan tantangan yang tidak sepele untuk mencapai keberhasilan implementasi. VSORA dapat memberikan solusi perangkat keras dan perangkat lunak pendukung yang komprehensif untuk memenuhi semua persyaratan penting untuk menangani akselerasi AD L4/L5 dan GenAI seperti GPT-4 dengan biaya yang layak secara komersial.
Detail lebih lanjut tentang VSORA dan Tyr dan Jotunn-nya dapat ditemukan di www.vsora.com.
Tentang Lauro Rizzatti
Lauro Rizzzatti adalah penasihat bisnis VSORA, perusahaan rintisan inovatif yang menawarkan solusi IP silikon dan chip silikon, serta konsultan verifikasi terkenal dan pakar industri dalam emulasi perangkat keras. Sebelumnya, beliau menjabat berbagai posisi di bidang manajemen, pemasaran produk, pemasaran teknis, dan teknik.
Baca Juga:
Soitec Merekayasa Masa Depan Industri Semikonduktor
ISO 21434 untuk Pengembangan SoC yang Sadar Keamanan Siber
Pemeliharaan Prediktif dalam Konteks Keselamatan Fungsional Otomotif
Bagikan postingan ini melalui:
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://semiwiki.com/automotive/336201-long-standing-roadblock-to-viable-l4-l5-autonomous-driving-and-generative-ai-inference-at-the-edge/
- :memiliki
- :adalah
- :bukan
- $NAIK
- 000
- 1
- 10
- 1800
- 1994
- 20
- 30
- 50
- 5G
- a
- kemampuan
- Tentang Kami
- abstraksi
- mempercepat
- percepatan
- akselerator
- akselerator
- mengakses
- diakses
- mengakses
- Mencapai
- Mencapai
- di seluruh
- tindakan
- sebenarnya
- Ad
- ADA
- menambahkan
- alamat
- maju
- kemajuan
- Keuntungan
- penasihat
- mempengaruhi
- AI
- algoritma
- algoritmik
- algoritma
- Semua
- memungkinkan
- juga
- jumlah
- jumlah
- an
- dan
- menjawab
- Apa pun
- aplikasi
- pendekatan
- arsitektur
- ADALAH
- DAERAH
- Seni
- AS
- At
- perhatian
- atribut
- secara otomatis
- otomotif
- otonom
- Bandwidth
- berdasarkan
- dasar
- Pada dasarnya
- BE
- menjadi
- menjadi
- di bawah
- patokan
- TERBAIK
- antara
- miliaran
- kedua
- bisnis
- tapi
- by
- Cache
- CAN
- tidak bisa
- kemampuan
- modal
- menyebabkan
- sel
- menantang
- tantangan
- Keripik
- kelas-kelas
- Clock
- Kokpit
- kode
- runtuh
- secara komersial
- masyarakat
- Perusahaan
- kompetitif
- kompleks
- rumit
- luas
- kompromi
- perhitungan
- menghitung
- komputasi
- koneksi
- konsultan
- konsumsi
- mengandung
- konteks
- Biaya
- Biaya
- ditambah
- CPU
- dibuat
- kritis
- terbaru
- canggih
- siklus
- data
- pengolahan data
- menyampaikan
- disampaikan
- memberikan
- padat
- tergantung
- dijelaskan
- Mendesain
- dirancang
- perancang
- rincian
- Devices
- berbeda
- digital
- digit
- do
- tidak
- dolar
- didorong
- penggerak
- Menjatuhkan
- Tetes
- dengan penuh semangat
- Tepi
- efisiensi
- antara
- akhir
- energi
- Konsumsi Energi
- insinyur
- Teknik
- memastikan
- antusiasme
- ESL
- penting
- mapan
- pERNAH
- berkembang
- contoh
- contoh
- eksekusi
- ahli
- luar
- keluarga
- jauh
- Pertanian
- umpan balik
- beberapa
- bidang
- Angka
- Pertama
- mengambang
- Tapak
- Untuk
- garis terdepan
- ditemukan
- Didirikan di
- Perancis
- dari
- sepenuhnya
- fungsionil
- masa depan
- menghasilkan
- generatif
- AI generatif
- Cari Google
- lebih besar
- menangani
- Perangkat keras
- Memiliki
- he
- Dimiliki
- membantu
- dia
- High
- kinerja tinggi
- paling tinggi
- dia
- Horowitz
- http
- HTTPS
- besar
- Hibrida
- i
- ICS
- ide-ide
- if
- ii
- implementasi
- implementasi
- diimplementasikan
- penting
- memaksakan
- in
- memasukkan
- industri
- Pakar Industri
- inovatif
- contoh
- sebagai gantinya
- mengintegrasikan
- ke
- diperkenalkan
- Jadian
- Menginvestasikan
- diinvestasikan
- IP
- IT
- NYA
- jpg
- melompat
- pemeliharaan
- dikenal
- pemandangan
- besar
- Latensi
- Dipimpin
- kurang
- Tingkat
- adalah ide yang bagus
- 'like'
- pemuatan
- logika
- lama berdiri
- lagi
- TERLIHAT
- Rendah
- Utama
- pemeliharaan
- Membuat
- berhasil
- pengelolaan
- mandat
- tanda
- Marketing
- besar-besaran
- max-width
- Pelajari
- kenangan
- Memori
- milidetik
- minimal
- modern
- uang
- lebih
- gerakan
- beberapa
- banyak orang
- New
- malam
- terkenal
- penting
- sekarang
- usang
- of
- menawarkan
- on
- ONE
- hanya
- Operasi
- or
- urutan
- perintah
- Lainnya
- Lainnya
- lebih
- semalam
- dilebih-lebihkan
- dipatenkan
- Puncak
- untuk
- persentase
- prestasi
- dilakukan
- perspektif
- fisik
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Cukup
- Titik
- posisi
- kemungkinan
- Pos
- kekuasaan
- Praktis
- sebelumnya
- Perdana
- Masalah
- proses
- diproses
- pengolahan
- Prosesor
- prosesor
- Produk
- Profesor
- diprogram
- Pemrograman
- Kemajuan
- Mendorong
- menempatkan
- query
- jarak
- cepat
- Baca
- real-time
- Kenyataan
- baru
- mengurangi
- Bagaimanapun juga
- register
- luar biasa
- direplikasi
- Dilaporkan
- membutuhkan
- Persyaratan
- membutuhkan
- tanggapan
- sama
- SEA
- Pencarian
- detik
- melihat
- seleksi
- semikonduktor
- sensor
- beberapa
- Share
- saham
- harus
- menunjukkan
- Silikon
- sejak
- tunggal
- kecil
- So
- Perangkat lunak
- larutan
- Solusi
- MEMECAHKAN
- beberapa
- agak
- sumber
- Space
- kecepatan
- menghabiskan
- Stanford
- Universitas Stanford
- startup
- Negara
- state-of-the-art
- terkenal
- Masih
- efisien
- ketat
- struktur
- Belajar
- besar
- sukses
- mendukung
- Didukung
- pendukung
- sinkronisasi
- sistem
- tabel
- disesuaikan
- target
- penargetan
- Teknis
- Teknologi
- dari
- bahwa
- Grafik
- Masa depan
- mereka
- Mereka
- Sana.
- Ini
- mereka
- ini
- tiga
- Melalui
- keluaran
- rapat
- waktu
- kali
- untuk
- hari ini
- jalur
- tradisional
- lalu lintas
- Pelatihan
- transparan
- dua
- mengetik
- jenis
- khas
- khas
- unik
- unit
- Alam semesta
- universitas
- sampai
- meningkatkan
- dapat digunakan
- Pengguna
- menggunakan
- VCs
- usaha
- modal ventura
- Verifikasi
- Lawan
- melalui
- giat
- sebenarnya
- volume
- menunggu
- Dinding
- adalah
- Cara..
- BAIK
- ketika
- sementara
- lebar
- keinginan
- dengan
- dalam
- tertulis
- namun
- hasil panen
- zephyrnet.dll