
Gambar dari Adobe Firefly
“Jumlah kita terlalu banyak. Kami mempunyai akses terhadap terlalu banyak uang, terlalu banyak peralatan, dan sedikit demi sedikit, kami menjadi gila.”
Francis Ford Coppola tidak sedang membuat metafora untuk perusahaan AI yang menghabiskan terlalu banyak uang dan kehilangan arah, tapi dia bisa saja melakukan hal tersebut. Apocalypse Sekarang merupakan proyek yang epik namun juga merupakan proyek yang panjang, sulit, dan mahal untuk dibuat, seperti halnya GPT-4. Saya berpendapat bahwa pengembangan LLM tertarik pada terlalu banyak uang dan terlalu banyak peralatan. Dan beberapa pernyataan “kami baru saja menemukan kecerdasan umum” agak gila. Namun kini giliran komunitas open source untuk melakukan yang terbaik: menghadirkan perangkat lunak pesaing gratis dengan menggunakan lebih sedikit uang dan peralatan.
OpenAI telah mengambil alih pendanaan sebesar $11 miliar dan diperkirakan biaya GPT-3.5 adalah $5-$6 juta per pelatihan. Kita hanya tahu sedikit tentang GPT-4 karena OpenAI tidak memberi tahu, tapi menurut saya aman untuk berasumsi bahwa GPT-3.5 tidak lebih kecil dari GPT-100. Saat ini terjadi kekurangan GPU di seluruh dunia dan – sebagai gantinya – hal ini bukan disebabkan oleh kriptocoin terbaru. Perusahaan rintisan AI generatif mendapatkan putaran Seri A senilai $XNUMX juta+ dengan penilaian besar ketika mereka tidak memiliki IP apa pun untuk LLM yang mereka gunakan untuk mendukung produk mereka. Kereta musik LLM sedang berkembang pesat dan uang terus mengalir.
Tampaknya segalanya sudah ditentukan: hanya perusahaan kaya seperti Microsoft/OpenAI, Amazon, dan Google yang mampu melatih ratusan miliar model parameter. Model yang lebih besar diasumsikan sebagai model yang lebih baik. GPT-3 ada yang salah? Tunggu saja sampai ada versi yang lebih besar dan semuanya akan baik-baik saja! Perusahaan-perusahaan kecil yang ingin bersaing harus meningkatkan modal lebih banyak atau dibiarkan membangun integrasi komoditas di pasar ChatGPT. Dunia akademis, dengan anggaran penelitian yang lebih terbatas, dikesampingkan.
Untungnya, banyak orang pintar dan proyek open source menganggap hal ini sebagai tantangan, bukan batasan. Para peneliti di Stanford merilis Alpaca, model parameter 7 miliar yang kinerjanya mendekati model parameter 3.5 Miliar GPT-175. Karena tidak memiliki sumber daya untuk membuat set pelatihan sebesar yang digunakan oleh OpenAI, mereka dengan cerdik memilih untuk menggunakan LLM open source terlatih, LLaMA, dan menyempurnakannya pada serangkaian perintah dan keluaran GPT-3.5. Pada dasarnya model tersebut mempelajari apa yang dilakukan GPT-3.5, yang ternyata merupakan strategi yang sangat efektif untuk mereplikasi perilakunya.
Alpaca dilisensikan untuk penggunaan non-komersial hanya dalam kode dan data karena menggunakan model LLaMA non-komersial sumber terbuka, dan OpenAI secara eksplisit melarang penggunaan API-nya untuk membuat produk pesaing. Hal ini menciptakan prospek yang menggiurkan untuk menyempurnakan LLM open source yang berbeda pada perintah dan keluaran Alpaca… menciptakan model ketiga mirip GPT-3.5 dengan kemungkinan lisensi berbeda.
Ada lapisan ironi lain di sini, di mana semua LLM besar dilatih tentang teks dan gambar berhak cipta yang tersedia di Internet dan mereka tidak membayar sepeser pun kepada pemegang haknya. Perusahaan-perusahaan tersebut mengklaim pengecualian “penggunaan wajar” berdasarkan undang-undang hak cipta AS dengan argumen bahwa penggunaan tersebut bersifat “transformatif”. Namun, jika menyangkut keluaran model yang mereka buat dengan data gratis, mereka sebenarnya tidak ingin ada orang yang melakukan hal yang sama terhadap mereka. Saya berharap hal ini akan berubah seiring dengan sikap bijaksana para pemegang hak, dan mungkin akan berakhir di pengadilan suatu saat nanti.
Ini adalah poin terpisah dan berbeda dengan yang diajukan oleh penulis sumber terbuka berlisensi terbatas yang, untuk produk AI generatif untuk Kode seperti CoPilot, menolak kode mereka digunakan untuk pelatihan dengan alasan bahwa lisensinya tidak diikuti. Masalah bagi masing-masing penulis sumber terbuka adalah mereka harus menunjukkan reputasi – penyalinan substantif – dan bahwa mereka telah menimbulkan kerugian. Dan karena model tersebut menyulitkan untuk menghubungkan kode keluaran ke masukan (baris kode sumber oleh penulis) dan tidak ada kerugian ekonomi (seharusnya gratis), jauh lebih sulit untuk mengajukan kasus. Hal ini berbeda dengan pencipta yang mencari keuntungan (misalnya fotografer) yang seluruh model bisnisnya adalah melisensikan/menjual karya mereka, dan yang diwakili oleh agregator seperti Getty Images yang dapat menunjukkan penyalinan substantif.
Hal menarik lainnya tentang LLaMA adalah ia keluar dari Meta. Awalnya dirilis hanya untuk peneliti dan kemudian dibocorkan melalui BitTorrent ke seluruh dunia. Meta berada dalam bisnis yang berbeda secara fundamental dengan OpenAI, Microsoft, Google, dan Amazon karena Meta tidak mencoba menjual layanan atau perangkat lunak cloud kepada Anda, sehingga memiliki insentif yang sangat berbeda. Mereka telah menggunakan sumber terbuka untuk desain komputasi mereka di masa lalu (OpenCompute) dan melihat komunitas meningkatkannya – mereka memahami nilai dari sumber terbuka.
Meta bisa menjadi salah satu kontributor AI sumber terbuka yang paling penting. Tidak hanya memiliki sumber daya yang sangat besar, namun juga mendapat manfaat jika terdapat perkembangan teknologi AI generatif yang hebat: akan ada lebih banyak konten yang dapat dimonetisasi di media sosial. Meta telah merilis tiga model AI sumber terbuka lainnya: ImageBind (pengindeksan data multidimensi), DINOv2 (computer vision), dan Segmen Apapun. Yang terakhir mengidentifikasi objek unik dalam gambar dan dirilis di bawah Lisensi Apache yang sangat permisif.
Terakhir, kami juga mendapat dugaan bocornya dokumen internal Google “Kami Tidak Memiliki Parit, dan OpenAI Juga” yang mengabaikan model tertutup vs. inovasi komunitas yang memproduksi model yang jauh lebih kecil, lebih murah, dan berperforma mendekati atau lebih baik daripada rekan-rekan sumber tertutup mereka. Saya katakan diduga karena tidak ada cara untuk memverifikasi sumber artikel tersebut sebagai internal Google. Namun, ini berisi grafik yang menarik berikut:
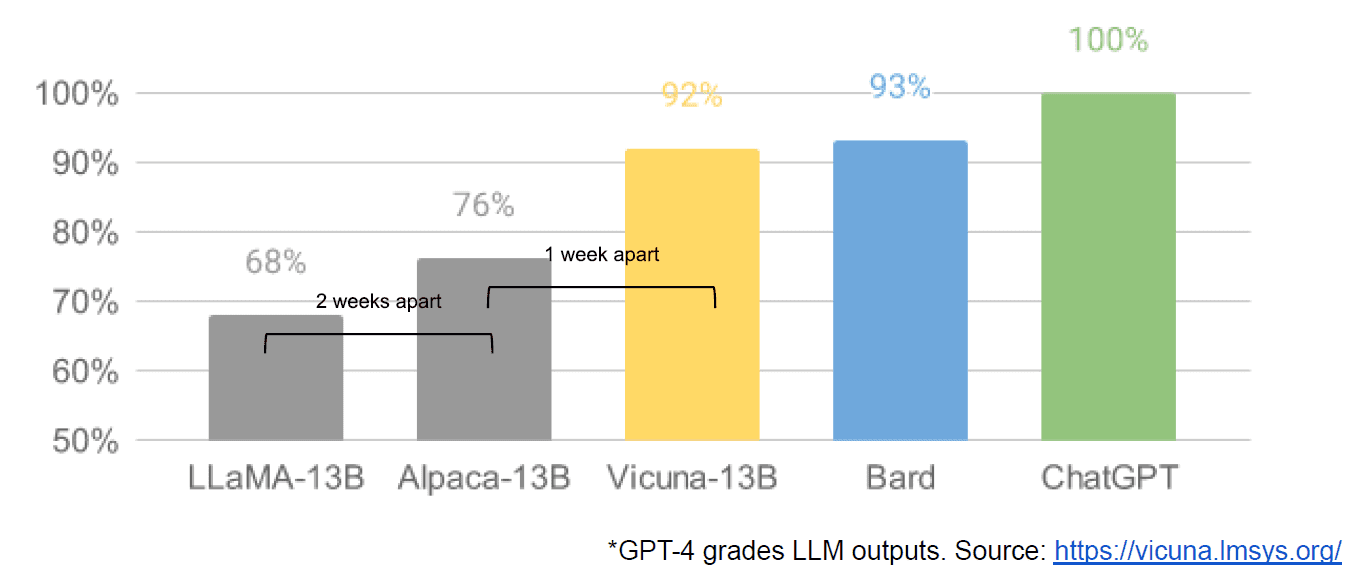
Sumbu vertikal adalah penilaian keluaran LLM menurut GPT-4, agar jelas.
Difusi Stabil, yang mensintesis gambar dari teks, adalah contoh lain di mana AI generatif open source mampu berkembang lebih cepat dibandingkan model berpemilik. Iterasi baru-baru ini dari proyek tersebut (ControlNet) telah memperbaikinya sedemikian rupa sehingga melampaui kemampuan Dall-E2. Hal ini terjadi berkat banyaknya upaya yang dilakukan di seluruh dunia, sehingga menghasilkan kemajuan yang sulit ditandingi oleh institusi mana pun. Beberapa dari mereka yang suka mengotak-atik menemukan cara membuat Difusi Stabil lebih cepat untuk dilatih dan dijalankan pada perangkat keras yang lebih murah, sehingga memungkinkan siklus iterasi yang lebih pendek oleh lebih banyak orang.
Jadi kita telah sampai pada lingkaran penuh. Tidak mempunyai terlalu banyak uang dan terlalu banyak peralatan telah mengilhami tingkat inovasi yang cerdik oleh seluruh komunitas masyarakat awam. Saat yang tepat untuk menjadi pengembang AI.
Mathew Lodge adalah CEO Diffblue, sebuah startup AI For Code. Dia memiliki pengalaman beragam selama lebih dari 25 tahun dalam kepemimpinan produk di perusahaan seperti Anaconda dan VMware. Lodge saat ini menjabat sebagai dewan di Good Law Project dan Wakil Ketua Dewan Pengawas Royal Photographic Society.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoAiStream. Kecerdasan Data Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Mencetak Masa Depan bersama Adryenn Ashley. Akses Di Sini.
- Beli dan Jual Saham di Perusahaan PRE-IPO dengan PREIPO®. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/2023/05/llm-apocalypse-revenge-open-source-clones.html?utm_source=rss&utm_medium=rss&utm_campaign=llm-apocalypse-now-revenge-of-the-open-source-clones
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 9
- a
- Sanggup
- Tentang Kami
- Akademi
- mengakses
- Adobe
- memajukan
- Agregator
- AI
- Semua
- diduga
- diduga
- juga
- Amazon
- an
- dan
- Lain
- Apa pun
- siapapun
- apa saja
- Apache
- Lebah
- ADALAH
- argumen
- artikel
- AS
- diasumsikan
- At
- penulis
- penulis
- tersedia
- Sumbu
- BE
- karena
- menjadi
- makhluk
- Manfaat
- TERBAIK
- Lebih baik
- lebih besar
- BitTorrent
- papan
- kedua
- Anggaran
- membangun
- Bangunan
- ikat
- bisnis
- model bisnis
- tapi
- by
- datang
- CAN
- kemampuan
- modal
- kasus
- ceo
- Kursi
- menantang
- perubahan
- ChatGPT
- murah
- memilih
- Lingkaran
- klaim
- jelas
- Penyelesaian
- tertutup
- awan
- layanan cloud
- kode
- bagaimana
- datang
- komoditi
- Masyarakat
- masyarakat
- Perusahaan
- menarik
- bersaing
- bersaing
- menghitung
- komputer
- Visi Komputer
- Konten
- kontributor
- penyalinan
- hak cipta
- Biaya
- bisa
- Pengadilan
- membuat
- membuat
- pencipta
- koin kripto
- Sekarang
- siklus
- data
- mengantarkan
- wakil
- desain
- Pengembang
- Pengembangan
- Mati
- berbeda
- sulit
- Difusi
- berbeda
- beberapa
- do
- dokumen
- tidak
- Dont
- e
- Ekonomis
- Efektif
- memungkinkan
- akhir
- Seluruh
- EPIC
- peralatan
- dasarnya
- diperkirakan
- Bahkan
- contoh
- mengharapkan
- mahal
- pengalaman
- jauh
- lebih cepat
- pikir
- Mengalir
- diikuti
- Untuk
- Ford
- Gratis
- dari
- penuh
- secara fundamental
- pendanaan
- gigi
- Umum
- generatif
- AI generatif
- baik
- GPU
- grafik
- besar
- memiliki
- Sulit
- Perangkat keras
- Memiliki
- memiliki
- he
- di sini
- High
- sangat
- pemegang
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTTPS
- besar
- Hype
- i
- mengidentifikasi
- if
- gambar
- penting
- memperbaiki
- ditingkatkan
- in
- Insentif
- sendiri-sendiri
- Innovation
- memasukkan
- GILA
- terinspirasi
- sebagai gantinya
- Lembaga
- integrasi
- menarik
- intern
- Internet
- Jadian
- IP
- ironi
- IT
- perulangan
- NYA
- hanya
- KDnugget
- Tahu
- pendaratan
- Terbaru
- Hukum
- lapisan
- Kepemimpinan
- belajar
- meninggalkan
- kurang
- Tingkat
- Lisensi
- Izin
- Perizinan
- 'like'
- baris
- LINK
- sedikit
- Llama
- Panjang
- tampak
- mencari
- kehilangan
- lepas
- Lot
- utama
- membuat
- Membuat
- banyak
- pasar
- besar-besaran
- Cocok
- Mungkin..
- Media
- meta
- Microsoft
- model
- model
- uangkan
- uang
- lebih
- paling
- banyak
- Perlu
- juga tidak
- tidak
- non-komersial
- sekarang
- obyek
- objek
- of
- on
- ONE
- hanya
- Buka
- open source
- proyek sumber terbuka
- OpenAI
- or
- biasa
- semula
- Lainnya
- di luar
- keluaran
- lebih
- sendiri
- Perdamaian
- parameter
- lalu
- Membayar
- Konsultan Ahli
- melakukan
- prestasi
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- kemungkinan
- kekuasaan
- Masalah
- Produk
- Produk
- proyek
- memprojeksikan
- hak milik
- prospek
- menaikkan
- menonjol
- agak
- benar-benar
- baru
- dirilis
- diwakili
- penelitian
- peneliti
- Sumber
- pembatasan
- dihasilkan
- hak
- putaran
- kerajaan
- Run
- s
- aman
- sama
- mengatakan
- terlihat
- ruas
- menjual
- terpisah
- Seri
- Seri A
- melayani
- Layanan
- set
- kekurangan
- Menunjukkan
- sejak
- tunggal
- Ukuran
- lebih kecil
- pintar
- So
- Sosial
- media sosial
- Masyarakat
- Perangkat lunak
- beberapa
- sesuatu
- sumber
- kode sumber
- menghabiskan
- stabil
- Stanford
- start-up
- startup
- Penyelarasan
- seperti itu
- menyarankan
- Seharusnya
- melampaui
- Mengambil
- diambil
- Dibutuhkan
- Teknologi
- dari
- bahwa
- Grafik
- Sumber
- Dunia
- mereka
- Mereka
- kemudian
- Sana.
- mereka
- hal
- berpikir
- Ketiga
- ini
- itu
- tiga
- waktu
- untuk
- terlalu
- mengambil
- Pelatihan VE
- terlatih
- Pelatihan
- MENGHIDUPKAN
- ternyata
- bawah
- mengerti
- unik
- tidak seperti
- sampai
- us
- menggunakan
- bekas
- kegunaan
- menggunakan
- Valuasi
- nilai
- memeriksa
- versi
- vertikal
- sangat
- melalui
- View
- penglihatan
- vmware
- vs
- menunggu
- ingin
- adalah
- Cara..
- we
- pergi
- adalah
- Apa
- ketika
- yang
- SIAPA
- seluruh
- yang
- akan
- BIJAKSANA
- dengan
- Kerja
- dunia
- Salah
- kamu
- zephyrnet.dll









