Dalam perjalanan menuju sistem tenaga yang lebih mumpuni, lebih cepat, lebih kecil, dan lebih rendah, Hukum Moore memberikan kebebasan bagi perangkat lunak selama lebih dari 30 tahun atau lebih murni pada evolusi proses semikonduktor. Perangkat keras komputasi menghasilkan metrik kinerja/area/daya yang lebih baik setiap tahunnya, memungkinkan perangkat lunak berkembang dalam kompleksitas dan memberikan lebih banyak kemampuan tanpa kerugian. Kemudian kemenangan mudah menjadi tidak mudah. Proses yang lebih canggih terus menghasilkan jumlah gerbang yang lebih tinggi per satuan luas, namun peningkatan kinerja dan daya mulai menurun. Karena ekspektasi kami terhadap inovasi tidak berhenti, kemajuan arsitektur perangkat keras menjadi lebih penting dalam mengatasi kekurangan tersebut.

Pendorong untuk meningkatkan jumlah inti
Langkah awal dalam arah ini adalah dengan menggunakan CPU multi-core untuk mempercepat total throughput dengan melakukan threading atau memvirtualisasikan campuran tugas-tugas bersamaan di seluruh core, mengurangi daya sesuai kebutuhan dengan menghentikan atau mematikan core yang tidak aktif. Multi-core adalah standar saat ini dan tren banyak-core (bahkan lebih banyak CPU dalam satu chip) sudah terlihat dalam opsi instans server yang tersedia di platform cloud dari AWS, Azure, Alibaba, dan lainnya.
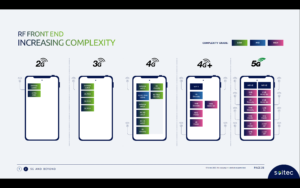
Arsitektur multi-/banyak inti merupakan sebuah langkah maju, namun paralelisme melalui cluster CPU bersifat kasar dan memiliki batas kinerja dan daya tersendiri, berkat hukum Amdahl. Arsitektur menjadi lebih heterogen, menambahkan akselerator untuk gambar, audio, dan kebutuhan khusus lainnya. Akselerator AI juga telah mendorong paralelisme halus, beralih ke susunan sistolik dan teknik khusus domain lainnya. Hal ini berfungsi cukup baik hingga ChatGPT muncul dengan 175 miliar parameter, dan GPT-3 berevolusi menjadi GPT-4 dengan 100 triliun parameter – jauh lebih kompleks daripada sistem AI saat ini – yang memaksa adanya fitur akselerasi yang lebih terspesialisasi dalam akselerator AI.
Di sisi lain, sistem multi-sensor dalam aplikasi otomotif kini terintegrasi ke dalam SoC tunggal untuk meningkatkan kesadaran lingkungan dan meningkatkan PPA. Di sini, tingkat otonomi baru dalam otomotif bergantung pada penggabungan input dari beberapa jenis sensor dalam satu perangkat, dalam subsistem yang direplikasi 2X, 4X, atau 8X.
Menurut Michał Siwinski (CMO di Arteris), pengambilan sampel diskusi selama sebulan dengan beberapa tim desain di berbagai aplikasi menunjukkan bahwa tim tersebut secara aktif beralih ke jumlah inti yang lebih tinggi untuk memenuhi sasaran kemampuan, kinerja, dan kekuatan. Dia memberi tahu saya bahwa mereka juga melihat tren ini semakin cepat. Kemajuan proses masih membantu penghitungan gerbang SoC, namun tanggung jawab untuk memenuhi sasaran kinerja dan daya kini berada di tangan para arsitek.
Lebih banyak inti, lebih banyak interkoneksi
Semakin banyak inti dalam sebuah chip berarti semakin banyak koneksi data antar inti tersebut. Dalam akselerator antara elemen pemrosesan yang berdekatan, ke cache lokal, ke akselerator untuk matriks renggang, dan penanganan khusus lainnya. Tambahkan konektivitas hierarki antara petak akselerator dan bus tingkat sistem. Tambahkan konektivitas untuk penyimpanan berat pada chip, dekompresi, penyiaran, pengumpulan, dan kompresi ulang. Tambahkan konektivitas HBM untuk cache yang berfungsi. Tambahkan mesin fusi jika diperlukan.
Cluster kontrol berbasis CPU harus terhubung ke masing-masing subsistem yang direplikasi dan ke semua fungsi biasa – codec, manajemen memori, pulau keamanan dan root of trust jika sesuai, UCIe jika implementasi multi-chiplet, PCIe untuk I/O bandwidth tinggi , dan Ethernet atau fiber untuk jaringan.
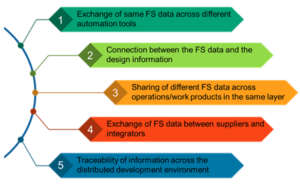
Ada banyak sekali keterhubungan yang mempunyai konsekuensi langsung terhadap daya jual produk. Dalam proses di bawah 16nm, infrastruktur NoC kini berkontribusi 10-12% di area tersebut. Yang lebih penting lagi, sebagai jalan raya komunikasi antar inti, hal ini dapat berdampak signifikan terhadap kinerja dan daya. Ada bahaya nyata bahwa implementasi yang kurang optimal akan menyia-nyiakan kinerja arsitektur dan perolehan daya yang diharapkan, atau lebih buruk lagi, mengakibatkan banyak putaran desain ulang yang menyatu. Namun menemukan implementasi yang baik dalam denah lantai SoC yang kompleks masih bergantung pada optimasi coba-coba yang lambat dalam jadwal desain yang sudah ketat. Kita perlu melakukan lompatan ke desain NoC yang sadar secara fisik, untuk menjamin kinerja penuh dan dukungan daya dari hierarki NoC yang kompleks dan kita perlu membuat pengoptimalan ini lebih cepat.
Desain NoC yang sadar secara fisik menjaga hukum Moore tetap pada jalurnya
Hukum Moore mungkin belum mati, namun kemajuan dalam kinerja dan kekuatan saat ini berasal dari arsitektur dan interkoneksi NoC, bukan dari proses. Arsitektur mendorong lebih banyak inti akselerator, lebih banyak akselerator di dalam akselerator, dan lebih banyak replikasi subsistem dalam chip. Semua meningkatkan kompleksitas interkoneksi on-chip. Ketika desain meningkatkan jumlah inti dan beralih ke geometri proses pada 16nm ke bawah, banyaknya interkoneksi NoC yang mencakup SoC dan sub-sistemnya hanya dapat mendukung potensi penuh dari desain kompleks ini jika diterapkan secara optimal terhadap batasan fisik dan waktu – melalui jaringan yang sadar secara fisik pada desain chip.
Jika Anda juga mengkhawatirkan tren ini, Anda mungkin ingin mempelajari lebih lanjut tentang teknologi IP Arteris FlexNoC 5 SINI.
Bagikan postingan ini melalui:
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :adalah
- $NAIK
- 100
- a
- Tentang Kami
- mempercepat
- mempercepat
- percepatan
- akselerator
- akselerator
- di seluruh
- aktif
- maju
- uang muka
- terhadap
- AI
- Sistem AI
- Alibaba
- Semua
- Membiarkan
- sudah
- dan
- Muncul
- aplikasi
- sesuai
- arsitektur
- ADALAH
- DAERAH
- AS
- At
- audio
- otomotif
- tersedia
- kesadaran
- AWS
- Biru langit
- Bandwidth
- BE
- menjadi
- di bawah
- antara
- Milyar
- menyiarkan
- Bis-bis
- by
- Cache
- CAN
- mampu
- ChatGPT
- keping
- awan
- Kelompok
- CMO
- bagaimana
- Komunikasi
- kompleks
- kompleksitas
- menghitung
- bersamaan
- Terhubung
- Koneksi
- Konektivitas
- Konsekuensi
- kendala
- terus
- kontrol
- bertemu
- Core
- CPU
- BAHAYA
- data
- mati
- menyampaikan
- disampaikan
- tergantung
- Mendesain
- desain
- alat
- berbeda
- langsung
- arah
- diskusi
- turun
- kerugian
- setiap
- Awal
- elemen
- Mesin
- Lingkungan Hidup
- Bahkan
- Setiap
- evolusi
- berkembang
- Lihat lebih lanjut
- harapan
- diharapkan
- lebih cepat
- Fitur
- temuan
- tegas
- Untuk
- Depan
- Gratis
- dari
- depan
- penuh
- fungsi
- fusi
- Keuntungan
- Anda
- baik
- menjamin
- Penanganan
- tangan
- Perangkat keras
- Memiliki
- membantu
- di sini
- High
- lebih tinggi
- Jalan raya
- HTTPS
- gambar
- Dampak
- implementasi
- diimplementasikan
- penting
- ditingkatkan
- in
- non-aktif
- Meningkatkan
- meningkatkan
- Infrastruktur
- Innovation
- contoh
- Mengintegrasikan
- IP
- pulau
- IT
- NYA
- melompat
- Hukum
- BELAJAR
- Tingkat
- adalah ide yang bagus
- batas
- lokal
- Lot
- membuat
- pengelolaan
- March
- Matriks
- max-width
- Pelajari
- pertemuan
- Memori
- Metrik
- mungkin
- Bulan
- lebih
- pindah
- bergerak
- beberapa
- Perlu
- dibutuhkan
- kebutuhan
- jaringan
- jaringan
- New
- banyak sekali
- of
- on
- Opsi
- perintah
- Lainnya
- Lainnya
- sendiri
- parameter
- prestasi
- fisik
- Secara fisik
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- Pos
- potensi
- kekuasaan
- Powering
- cukup
- proses
- proses
- pengolahan
- Produk
- murni
- terdorong
- Mendorong
- jarak
- agak
- nyata
- mengurangi
- direplikasi
- replikasi
- tanggung jawab
- mengakibatkan
- Mengendarai
- akar
- Safety/keselamatan
- semikonduktor
- penting
- sejak
- tunggal
- kendur
- lambat
- lebih kecil
- So
- Perangkat lunak
- matriks jarang
- khusus
- lampu sorot
- standar
- mulai
- Langkah
- Masih
- berhenti
- penyimpanan
- Menyarankan
- mendukung
- sistem
- sistem
- tugas
- tim
- teknik
- Teknologi
- mengatakan
- bahwa
- Grafik
- Ini
- Melalui
- keluaran
- waktu
- untuk
- hari ini
- hari ini
- Total
- kecenderungan
- Tren
- Triliun
- Kepercayaan
- Putar
- jenis
- bawah
- satuan
- melalui
- berat
- BAIK
- yang
- lebar
- Rentang luas
- akan
- Wins
- dengan
- dalam
- kerja
- tahun
- tahun
- zephyrnet.dll