Pergeseran Merah Amazon, gudang data cloud yang banyak digunakan, telah berkembang secara signifikan untuk memenuhi persyaratan kinerja beban kerja yang paling menuntut. Posting ini membahas salah satu fitur baru—kunci pengurutan tata letak data multidimensi.
Amazon Redshift kini meningkatkan kinerja kueri Anda dengan mendukung kunci pengurutan tata letak data multidimensi, yang merupakan jenis kunci pengurutan baru yang mengurutkan data tabel berdasarkan predikat filter, bukan kolom fisik tabel. Kunci pengurutan tata letak data multidimensi akan meningkatkan kinerja pemindaian tabel secara signifikan, terutama ketika beban kerja kueri Anda berisi filter pemindaian berulang.
Amazon Redshift sudah menyediakan kemampuan pengoptimalan tabel otomatis (ATO), yang secara otomatis mengoptimalkan desain tabel dengan menerapkan kunci pengurutan dan distribusi tanpa memerlukan intervensi administrator. Dalam postingan ini, kami memperkenalkan kunci pengurutan tata letak data multidimensi sebagai kemampuan tambahan yang ditawarkan oleh ATO dan diperkuat oleh algoritma penasihat kunci pengurutan Amazon Redshift.
Kunci pengurutan tata letak data multidimensi
Saat Anda menentukan tabel dengan kunci pengurutan AUTO, Amazon Redshift ATO akan menganalisis riwayat kueri Anda dan secara otomatis memilih kunci pengurutan kolom tunggal atau kunci pengurutan tata letak data multidimensi untuk tabel Anda, berdasarkan opsi mana yang lebih baik untuk beban kerja Anda. Ketika tata letak data multidimensi dipilih, Amazon Redshift akan membangun fungsi pengurutan multidimensi yang menempatkan baris-baris yang biasanya diakses oleh kueri yang sama, dan fungsi pengurutan selanjutnya digunakan selama menjalankan kueri untuk melewati blok data dan bahkan melewatkan pemindaian predikat individual. kolom.
Pertimbangkan kueri pengguna berikut, yang merupakan pola kueri dominan dalam beban kerja pengguna:
Amazon Redshift menyimpan data untuk setiap kolom dalam blok disk 1 MB dan menyimpan nilai minimum dan maksimum di setiap blok sebagai bagian dari metadata tabel. Jika kueri menggunakan a predikat dengan jangkauan terbatas, Amazon Redshift dapat menggunakan nilai minimum dan maksimum untuk dengan cepat melewati sejumlah besar blok selama pemindaian tabel. Namun, filter kueri pada kolom subkawasan ini tidak dapat digunakan untuk menentukan blok mana yang harus dilewati berdasarkan nilai minimum dan maksimum, dan sebagai hasilnya, Amazon Redshift memindai semua baris dari tabel judul:
Saat kueri pengguna dijalankan dengan titles menggunakan tombol pengurutan satu kolom subregion, hasil query sebelumnya adalah sebagai berikut:
Ini menunjukkan bahwa pemindaian tabel membaca 2,164,081,640 baris.
Untuk meningkatkan pemindaian pada titles tabel, Amazon Redshift mungkin secara otomatis memutuskan untuk menggunakan kunci pengurutan tata letak data multidimensi. Semua baris yang memenuhi lower(subregion) like '%United States%' predikat akan ditempatkan bersama ke wilayah tabel khusus, dan oleh karena itu Amazon Redshift hanya akan memindai blok data yang memenuhi predikat.
Saat kueri pengguna dijalankan dengan titles menggunakan kunci pengurutan tata letak data multidimensi yang mencakup lower(subregion) like '%United States%' sebagai predikat, hasil dari sys_query_detail permintaannya adalah sebagai berikut:
Hal ini menunjukkan bahwa pemindaian tabel membaca 152,324,046 baris, yang hanya 7% dari aslinya, dan menggunakan kunci pengurutan tata letak data multidimensi.
Perhatikan bahwa contoh ini menggunakan satu kueri untuk menampilkan fitur tata letak data multidimensi, namun Amazon Redshift akan mempertimbangkan semua kueri yang berjalan pada tabel dan dapat membuat beberapa wilayah untuk memenuhi predikat yang paling sering dijalankan.
Mari kita ambil contoh lain, kali ini dengan predikat yang lebih kompleks dan beberapa kueri.
Bayangkan memiliki sebuah meja items (cost int, available int, demand int) dengan empat baris seperti yang ditunjukkan pada contoh berikut.
| #Indo | biaya | tersedia | permintaan |
| 1 | 4 | 3 | 3 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 4 | 1 | 1 | 2 |
Beban kerja dominan Anda terdiri dari dua kueri:
- Pola kueri 70%:
- Pola kueri 20%:
Dengan teknik penyortiran tradisional, Anda dapat memilih untuk mengurutkan tabel berdasarkan kolom biaya, sehingga evaluasinya cost > 3 akan mendapat manfaat dari hal semacam itu. Jadi, tabel item setelah diurutkan menggunakan single cost kolomnya akan terlihat seperti berikut.
| #Indo | biaya | tersedia | permintaan |
| Wilayah #1, dengan biaya <= 3 | |||
| Wilayah #2, dengan biaya > 3 | |||
| #Indo | biaya | tersedia | permintaan |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 1 | 4 | 3 | 3 |
| 3 | 5 | 4 | 5 |
Dengan menggunakan pengurutan tradisional ini, kita dapat langsung mengecualikan dua baris teratas (biru) dengan ID 4 dan ID 2, karena tidak memenuhi cost > 3.
Di sisi lain, dengan kunci pengurutan tata letak data multidimensi, tabel akan diurutkan berdasarkan kombinasi dua predikat yang umum muncul dalam beban kerja pengguna, yaitu cost > 3 dan available < demand. Hasilnya, baris tabel diurutkan menjadi empat wilayah.
| #Indo | biaya | tersedia | permintaan |
| Wilayah #1, dengan biaya <= 3 dan tersedia < permintaan | |||
| Wilayah #2, dengan biaya <= 3 dan tersedia >= permintaan | |||
| Wilayah #3, dengan biaya > 3 dan tersedia < permintaan | |||
| Wilayah #4, dengan biaya > 3 dan tersedia >= permintaan | |||
| #Indo | biaya | tersedia | permintaan |
| 4 | 1 | 1 | 2 |
| 2 | 2 | 23 | 6 |
| 3 | 5 | 4 | 5 |
| 1 | 4 | 3 | 3 |
Konsep ini bahkan lebih efektif bila diterapkan pada seluruh blok dibandingkan satu baris, bila diterapkan pada predikat kompleks yang menggunakan operator yang tidak cocok untuk teknik pengurutan tradisional (seperti like), dan bila diterapkan pada lebih dari dua predikat.
Tabel sistem
Tabel sistem Amazon Redshift berikut akan menunjukkan kepada pengguna apakah tata letak data multidimensi digunakan pada tabel dan kueri mereka:
- Untuk menentukan apakah tabel tertentu menggunakan kunci pengurutan tata letak data multidimensi, Anda dapat memeriksa apakah
sortkey1in svv_table_info adalah sama denganAUTO(SORTKEY(padb_internal_mddl_key_col)). - Untuk menentukan apakah kueri tertentu menggunakan tata letak data multidimensi untuk mempercepat pemindaian tabel, Anda bisa memeriksanya
step_attributedalam sys_query_detail melihat. Nilainya akan sama denganmulti-dimensionaljika kunci pengurutan tata letak data multidimensi tabel digunakan selama pemindaian.
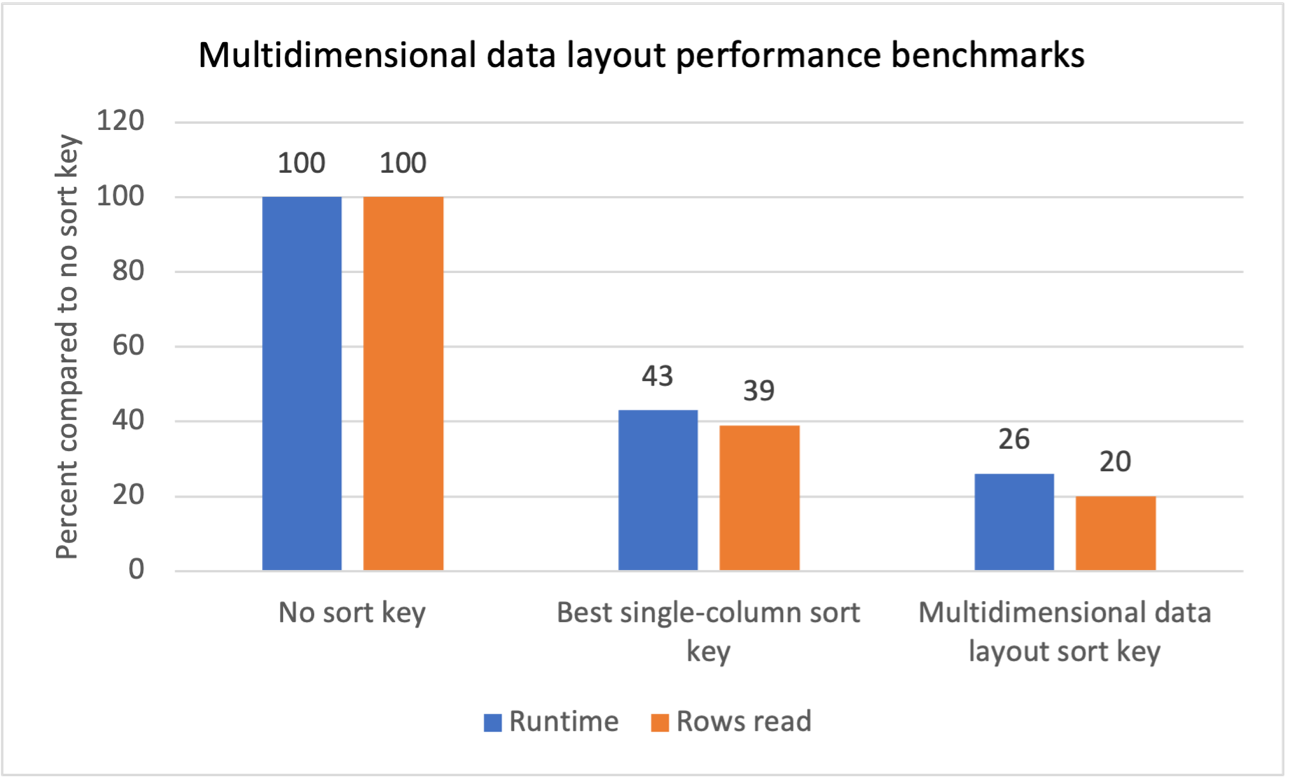
Tolok ukur kinerja
Kami melakukan pengujian benchmark internal untuk beberapa beban kerja dengan filter pemindaian berulang dan melihat bahwa memperkenalkan kunci pengurutan tata letak data multidimensi menghasilkan hasil berikut:
- Pengurangan total waktu proses sebesar 74% dibandingkan dengan tidak adanya kunci pengurutan.
- Pengurangan total waktu proses sebesar 40% dibandingkan dengan memiliki kunci pengurutan satu kolom terbaik di setiap tabel.
- Pengurangan 80% pada total baris yang dibaca dari tabel dibandingkan tanpa kunci pengurutan.
- Pengurangan sebesar 47% pada total baris yang dibaca dari tabel dibandingkan dengan memiliki kunci pengurutan satu kolom terbaik di setiap tabel.
Perbandingan fitur
Dengan diperkenalkannya kunci pengurutan tata letak data multidimensi, tabel Anda kini dapat diurutkan berdasarkan ekspresi berdasarkan predikat filter yang umum muncul dalam beban kerja Anda. Tabel berikut memberikan perbandingan fitur Amazon Redshift terhadap dua pesaing.
| Fitur | Pergeseran Merah Amazon | Pesaing A | Pesaing B |
| Dukungan untuk menyortir berdasarkan kolom | Yes | Yes | Yes |
| Dukungan untuk mengurutkan berdasarkan ekspresi | Yes | Yes | Tidak |
| Pemilihan kolom otomatis untuk penyortiran | Yes | Tidak | Yes |
| Pemilihan ekspresi otomatis untuk penyortiran | Yes | Tidak | Tidak |
| Pemilihan otomatis antara penyortiran kolom atau penyortiran ekspresi | Yes | Tidak | Tidak |
| Penggunaan otomatis properti pengurutan untuk ekspresi selama pemindaian | Yes | Tidak | Tidak |
Pertimbangan
Ingatlah hal berikut saat menggunakan tata letak data multidimensi:
- Tata letak data multidimensi diaktifkan ketika Anda mengatur tabel Anda sebagai SORTKEY AUTO.
- Amazon Redshift Advisor akan secara otomatis memilih kunci pengurutan satu kolom atau tata letak data multidimensi untuk tabel dengan menganalisis beban kerja historis Anda.
- Amazon Redshift ATO menyesuaikan hasil pengurutan tata letak data multidimensi berdasarkan cara kueri yang sedang berlangsung berinteraksi dengan beban kerja.
- Amazon Redshift ATO mempertahankan kunci pengurutan tata letak data multidimensi dengan cara yang sama seperti saat ini untuk kunci pengurutan yang ada. Mengacu pada Bekerja dengan optimasi tabel otomatis untuk rincian lebih lanjut tentang ATO.
- Kunci pengurutan tata letak data multidimensi akan berfungsi dengan klaster yang disediakan dan kelompok kerja tanpa server.
- Kunci pengurutan tata letak data multidimensi akan berfungsi dengan data yang ada selama AUTO SORTKEY diaktifkan di tabel Anda dan beban kerja dengan filter pemindaian berulang terdeteksi. Tabel akan ditata ulang berdasarkan hasil fungsi pengurutan multidimensi.
- Untuk menonaktifkan kunci pengurutan tata letak data multidimensi untuk tabel, gunakan tabel ubah:
ALTER TABLE table_name ALTER SORTKEY NONE. Ini menonaktifkan fitur kunci pengurutan AUTO pada tabel. - Kunci pengurutan tata letak data multidimensi dipertahankan saat memulihkan atau memigrasikan kluster yang disediakan ke kluster tanpa server atau sebaliknya.
Kesimpulan
Dalam postingan ini, kami menunjukkan bahwa kunci pengurutan tata letak data multidimensi dapat secara signifikan meningkatkan kinerja waktu proses kueri untuk beban kerja yang kueri dominannya memiliki filter pemindaian berulang.
Untuk membuat klaster pratinjau dari konsol Amazon Redshift, navigasikan ke Cluster halaman dan pilih Buat kluster pratinjau. Anda dapat membuat klaster di Wilayah AS Timur (Ohio), AS Timur (Virginia Utara), AS Barat (Oregon), Asia Pasifik (Tokyo), Eropa (Irlandia), dan Eropa (Stockholm) dan menguji beban kerja Anda.
Kami akan sangat senang mendengar tanggapan Anda tentang fitur baru ini dan menantikan komentar Anda pada postingan ini.
Tentang penulis
 Milind Oke adalah Arsitek Solusi Spesialis Gudang Data yang berbasis di New York. Dia telah membangun solusi gudang data selama lebih dari 15 tahun dan berspesialisasi dalam Amazon Redshift.
Milind Oke adalah Arsitek Solusi Spesialis Gudang Data yang berbasis di New York. Dia telah membangun solusi gudang data selama lebih dari 15 tahun dan berspesialisasi dalam Amazon Redshift.
 Jialinding adalah Ilmuwan Terapan di Grup Sistem yang Dipelajari, yang mengkhususkan diri dalam penerapan pembelajaran mesin dan teknik pengoptimalan untuk meningkatkan kinerja sistem data seperti Amazon Redshift.
Jialinding adalah Ilmuwan Terapan di Grup Sistem yang Dipelajari, yang mengkhususkan diri dalam penerapan pembelajaran mesin dan teknik pengoptimalan untuk meningkatkan kinerja sistem data seperti Amazon Redshift.
 Yanzhuji adalah Manajer Produk di tim Amazon Redshift. Dia memiliki pengalaman dalam visi dan strategi produk dalam produk dan platform data terkemuka di industri. Dia memiliki keterampilan luar biasa dalam membangun produk perangkat lunak yang substansial menggunakan pengembangan web, desain sistem, basis data, dan teknik pemrograman terdistribusi. Dalam kehidupan pribadinya, Yanzhu suka melukis, fotografi, dan bermain tenis.
Yanzhuji adalah Manajer Produk di tim Amazon Redshift. Dia memiliki pengalaman dalam visi dan strategi produk dalam produk dan platform data terkemuka di industri. Dia memiliki keterampilan luar biasa dalam membangun produk perangkat lunak yang substansial menggunakan pengembangan web, desain sistem, basis data, dan teknik pemrograman terdistribusi. Dalam kehidupan pribadinya, Yanzhu suka melukis, fotografi, dan bermain tenis.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/improve-performance-of-workloads-containing-repetitive-scan-filters-with-multidimensional-data-layout-sort-keys-in-amazon-redshift/
- :memiliki
- :adalah
- :bukan
- :Di mana
- 1
- 100
- 15 tahun
- 15%
- 152
- 7
- 8
- 9
- a
- mempercepat
- diakses
- Tambahan
- penasihat
- Setelah
- terhadap
- algoritma
- Semua
- sudah
- Amazon
- Amazon Web Services
- an
- menganalisa
- menganalisis
- dan
- Lain
- terapan
- Menerapkan
- ADALAH
- AS
- Asia
- Asia Pacific
- mobil
- secara otomatis
- secara otomatis
- tersedia
- AWS
- berdasarkan
- BE
- karena
- menjadi
- patokan
- manfaat
- TERBAIK
- Lebih baik
- antara
- Memblokir
- Blok
- Biru
- kedua
- Bangunan
- tapi
- by
- CAN
- kemampuan
- memeriksa
- Pilih
- awan
- Kelompok
- Kolom
- Kolom
- kombinasi
- komentar
- umum
- dibandingkan
- perbandingan
- pesaing
- kompleks
- konsep
- Mempertimbangkan
- terdiri
- konsul
- membangun
- mengandung
- Biaya
- meliputi
- membuat
- Sekarang
- data
- data warehouse
- Basis Data
- memutuskan
- dedicated
- menetapkan
- Permintaan
- menuntut
- Mendesain
- rincian
- terdeteksi
- Menentukan
- Pengembangan
- didistribusikan
- distribusi
- tidak
- dominan
- Dont
- selama
- setiap
- Timur
- antara
- diaktifkan
- Seluruh
- sama
- terutama
- Eter (ETH)
- Eropa
- evaluasi
- Bahkan
- berkembang
- contoh
- ada
- pengalaman
- ekspresi
- Fitur
- umpan balik
- menyaring
- filter
- berikut
- berikut
- Untuk
- Depan
- empat
- dari
- fungsi
- Kelompok
- tangan
- Memiliki
- memiliki
- he
- mendengar
- dia
- historis
- sejarah
- Namun
- HTML
- HTTPS
- ID
- if
- segera
- memperbaiki
- meningkatkan
- in
- termasuk
- sendiri-sendiri
- industri terkemuka
- sebagai gantinya
- berinteraksi
- intern
- intervensi
- ke
- memperkenalkan
- memperkenalkan
- Pengantar
- Irlandia
- IT
- item
- kunci
- kunci-kunci
- besar
- tata ruang
- belajar
- pengetahuan
- Hidup
- 'like'
- 'like
- Panjang
- melihat
- terlihat seperti
- cinta
- mesin
- Mesin belajar
- mempertahankan
- manajer
- cara
- maksimum
- Pelajari
- Metadata
- mungkin
- bermigrasi
- keberatan
- minimum
- lebih
- paling
- beberapa
- Arahkan
- Perlu
- New
- Fitur baru
- NY
- tidak
- sekarang
- nomor
- terjadi
- of
- lepas
- ditawarkan
- Ohio
- on
- ONE
- terus-menerus
- hanya
- operator
- optimasi
- Mengoptimalkan
- pilihan
- or
- urutan
- Oregon
- asli
- Lainnya
- di luar
- terkemuka
- lebih
- Pasifik
- lukisan
- bagian
- tertentu
- pola
- prestasi
- dilakukan
- pribadi
- fotografi
- fisik
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- bermain
- Pos
- kuat
- diawetkan
- Preview
- Diproduksi
- Produk
- manajer produk
- Produk
- Pemrograman
- properties
- menyediakan
- query
- cepat
- Baca
- pengurangan
- lihat
- wilayah
- daerah
- berulang-ulang
- Persyaratan
- memulihkan
- mengakibatkan
- Hasil
- Run
- berjalan
- berjalan
- sama
- pemindaian
- pemindaian
- scan
- ilmuwan
- Musim
- melihat
- memilih
- terpilih
- seleksi
- Tanpa Server
- Layanan
- set
- dia
- Menunjukkan
- menampilkan
- menunjukkan
- ditunjukkan
- Pertunjukkan
- signifikan
- tunggal
- ketrampilan
- So
- Perangkat lunak
- Solusi
- spesialis
- spesialisasi
- mengkhususkan diri
- toko
- Penyelarasan
- Kemudian
- besar
- seperti itu
- cocok
- pendukung
- sistem
- sistem
- tabel
- Mengambil
- tim
- teknik
- tenis
- uji
- pengujian
- dari
- bahwa
- Grafik
- mereka
- karena itu
- mereka
- ini
- waktu
- judul
- untuk
- Tokyo
- puncak
- Total
- tradisional
- dua
- mengetik
- khas
- us
- menggunakan
- bekas
- Pengguna
- Pengguna
- kegunaan
- menggunakan
- nilai
- Nilai - Nilai
- wakil
- View
- virginia
- penglihatan
- Gudang
- adalah
- Cara..
- we
- jaringan
- pengembangan web
- layanan web
- Barat
- ketika
- apakah
- yang
- sangat
- akan
- dengan
- tanpa
- Kerja
- akan
- tahun
- York
- kamu
- Anda
- zephyrnet.dll