Para peneliti terus mengembangkan arsitektur model baru untuk tugas pembelajaran mesin (ML) umum. Salah satu tugas tersebut adalah klasifikasi gambar, di mana gambar diterima sebagai masukan dan model mencoba untuk mengklasifikasikan gambar secara keseluruhan dengan keluaran label objek. Dengan banyaknya model yang tersedia saat ini yang melakukan tugas klasifikasi gambar ini, seorang praktisi ML mungkin mengajukan pertanyaan seperti: "Model apa yang harus saya sesuaikan dan terapkan untuk mencapai kinerja terbaik pada set data saya?" Dan seorang peneliti ML dapat mengajukan pertanyaan seperti: "Bagaimana saya bisa menghasilkan perbandingan yang adil dari beberapa arsitektur model terhadap kumpulan data tertentu sambil mengontrol hyperparameter pelatihan dan spesifikasi komputer, seperti GPU, CPU, dan RAM?" Pertanyaan sebelumnya membahas pemilihan model di seluruh arsitektur model, sedangkan pertanyaan terakhir menyangkut pembandingan model terlatih terhadap kumpulan data uji.
Dalam postingan ini, Anda akan melihat bagaimana Klasifikasi gambar TensorFlow algoritma dari Mulai Lompatan Amazon SageMaker dapat menyederhanakan implementasi yang diperlukan untuk menjawab pertanyaan-pertanyaan ini. Bersama dengan detail implementasi yang sesuai contoh notebook Jupyter, Anda akan memiliki alat yang tersedia untuk melakukan pemilihan model dengan menjelajahi batas pareto, di mana peningkatan satu metrik kinerja, seperti akurasi, tidak mungkin dilakukan tanpa memperburuk metrik lainnya, seperti throughput.
Ikhtisar solusi
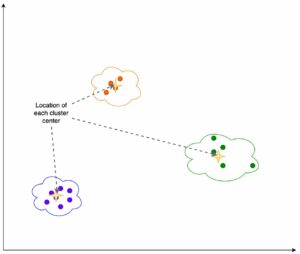
Gambar berikut mengilustrasikan trade-off pemilihan model untuk sejumlah besar model klasifikasi gambar yang disesuaikan pada Caltech-256 kumpulan data, yang merupakan kumpulan menantang dari 30,607 gambar dunia nyata yang mencakup 256 kategori objek. Setiap titik mewakili satu model, ukuran titik diskalakan sehubungan dengan jumlah parameter yang terdiri dari model, dan titik diberi kode warna berdasarkan arsitektur modelnya. Misalnya, titik hijau muda mewakili arsitektur EfficientNet; setiap titik hijau muda adalah konfigurasi yang berbeda dari arsitektur ini dengan pengukuran kinerja model yang disesuaikan dengan baik. Gambar tersebut menunjukkan adanya pareto frontier untuk pemilihan model, di mana akurasi yang lebih tinggi ditukar dengan throughput yang lebih rendah. Pada akhirnya, pemilihan model di sepanjang batas pareto, atau rangkaian solusi efisien pareto, bergantung pada persyaratan kinerja penyebaran model Anda.
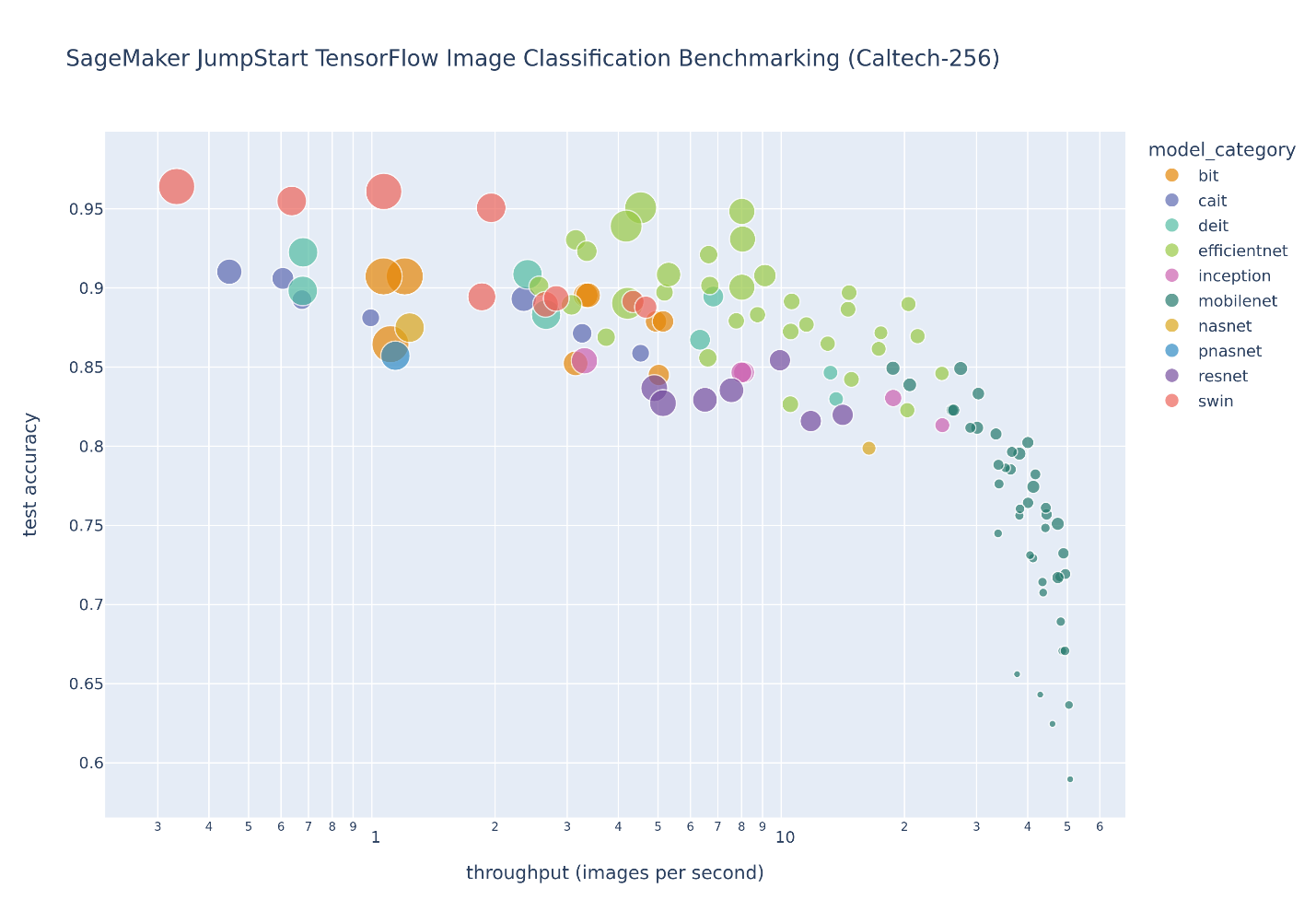
Jika Anda mengamati akurasi pengujian dan menguji batasan throughput yang diinginkan, rangkaian solusi efisien pareto pada gambar sebelumnya diekstrak dalam tabel berikut. Baris diurutkan sedemikian rupa sehingga throughput pengujian meningkat dan akurasi pengujian menurun.
| Model Nama | Jumlah Parameter | Akurasi Tes | Uji 5 Akurasi Teratas | Throughput (gambar/dtk) | Durasi per Zaman |
| swin-large-patch4-window12-384 | 195.6M | 96.4% | 99.5% | 0.3 | 2278.6 |
| swin-large-patch4-window7-224 | 195.4M | 96.1% | 99.5% | 1.1 | 698.0 |
| efesiennet-v2-imagenet21k-ft1k-l | 118.1M | 95.1% | 99.2% | 4.5 | 1434.7 |
| efesiennet-v2-imagenet21k-ft1k-m | 53.5M | 94.8% | 99.1% | 8.0 | 769.1 |
| efesiennet-v2-imagenet21k-m | 53.5M | 93.1% | 98.5% | 8.0 | 765.1 |
| efesiennet-b5 | 29.0M | 90.8% | 98.1% | 9.1 | 668.6 |
| efesiennet-v2-imagenet21k-ft1k-b1 | 7.3M | 89.7% | 97.3% | 14.6 | 54.3 |
| efesiennet-v2-imagenet21k-ft1k-b0 | 6.2M | 89.0% | 97.0% | 20.5 | 38.3 |
| efesiennet-v2-imagenet21k-b0 | 6.2M | 87.0% | 95.6% | 21.5 | 38.2 |
| mobilenet-v3-besar-100-224 | 4.6M | 84.9% | 95.4% | 27.4 | 28.8 |
| mobilenet-v3-besar-075-224 | 3.1M | 83.3% | 95.2% | 30.3 | 26.6 |
| mobilenet-v2-100-192 | 2.6M | 80.8% | 93.5% | 33.5 | 23.9 |
| mobilenet-v2-100-160 | 2.6M | 80.2% | 93.2% | 40.0 | 19.6 |
| mobilenet-v2-075-160 | 1.7M | 78.2% | 92.8% | 41.8 | 19.3 |
| mobilenet-v2-075-128 | 1.7M | 76.1% | 91.1% | 44.3 | 18.3 |
| mobilenet-v1-075-160 | 2.0M | 75.7% | 91.0% | 44.5 | 18.2 |
| mobilenet-v1-100-128 | 3.5M | 75.1% | 90.7% | 47.4 | 17.4 |
| mobilenet-v1-075-128 | 2.0M | 73.2% | 90.0% | 48.9 | 16.8 |
| mobilenet-v2-075-96 | 1.7M | 71.9% | 88.5% | 49.4 | 16.6 |
| mobilenet-v2-035-96 | 0.7M | 63.7% | 83.1% | 50.4 | 16.3 |
| mobilenet-v1-025-128 | 0.3M | 59.0% | 80.7% | 50.8 | 16.2 |
Posting ini memberikan detail tentang cara mengimplementasikan skala besar Amazon SageMaker pembandingan dan tugas pemilihan model. Pertama, kami memperkenalkan JumpStart dan algoritme klasifikasi gambar TensorFlow bawaan. Kami kemudian membahas pertimbangan penerapan tingkat tinggi, seperti konfigurasi hyperparameter JumpStart, ekstraksi metrik dari Log Amazon CloudWatch, dan meluncurkan tugas penyetelan hyperparameter asinkron. Terakhir, kami membahas lingkungan implementasi dan parameterisasi yang mengarah ke solusi efisien pareto pada tabel dan gambar sebelumnya.
Pengantar klasifikasi gambar JumpStart TensorFlow
JumpStart menyediakan penyetelan halus sekali klik dan penerapan berbagai model terlatih di seluruh tugas ML populer, serta pilihan solusi end-to-end yang memecahkan masalah bisnis umum. Fitur-fitur ini menghilangkan beban berat dari setiap langkah proses ML, membuatnya lebih mudah untuk mengembangkan model berkualitas tinggi dan mengurangi waktu penerapan. Itu API JumpStart memungkinkan Anda menerapkan dan menyempurnakan secara terprogram banyak pilihan model yang telah dilatih sebelumnya pada kumpulan data Anda sendiri.
Hub model JumpStart menyediakan akses ke sejumlah besar Model klasifikasi gambar TensorFlow yang memungkinkan pembelajaran transfer dan penyempurnaan pada kumpulan data khusus. Pada tulisan ini, hub model JumpStart berisi 135 model klasifikasi gambar TensorFlow di berbagai arsitektur model populer dari Pusat TensorFlow, untuk menyertakan sisa jaringan (ResNet), Jaringan Seluler, Jaringan yang Efisien, Lahirnya, Jaringan Penelusuran Arsitektur Neural (NASNet), Transfer Besar (Sedikit), menggeser jendela (Berenang) transformer, Class-Attention di Image Transformers (Cait), dan Transformator Gambar Hemat Data (DEIT).
Struktur internal yang sangat berbeda terdiri dari masing-masing arsitektur model. Misalnya, model ResNet menggunakan koneksi lewati untuk memungkinkan jaringan yang jauh lebih dalam, sedangkan model berbasis transformator menggunakan mekanisme perhatian diri yang menghilangkan lokalitas intrinsik dari operasi konvolusi yang mendukung bidang reseptif yang lebih global. Selain beragam set fitur yang disediakan oleh struktur yang berbeda ini, setiap arsitektur model memiliki beberapa konfigurasi yang menyesuaikan ukuran model, bentuk, dan kompleksitas dalam arsitektur tersebut. Ini menghasilkan ratusan model klasifikasi gambar unik yang tersedia di hub model JumpStart. Dikombinasikan dengan pembelajaran transfer bawaan dan skrip inferensi yang mencakup banyak fitur SageMaker, API JumpStart adalah titik peluncuran yang bagus bagi praktisi ML untuk mulai melatih dan menerapkan model dengan cepat.
Lihat Transfer pembelajaran untuk model klasifikasi gambar TensorFlow di Amazon SageMaker dan berikut ini contoh notebook untuk mempelajari tentang klasifikasi gambar SageMaker TensorFlow secara lebih mendalam, termasuk cara menjalankan inferensi pada model yang telah dilatih sebelumnya serta menyempurnakan model yang telah dilatih sebelumnya pada set data khusus.
Pertimbangan pemilihan model berskala besar
Pemilihan model adalah proses pemilihan model terbaik dari sekumpulan kandidat model. Proses ini dapat diterapkan di seluruh model dengan tipe yang sama dengan bobot parameter yang berbeda dan di seluruh model dengan tipe yang berbeda. Contoh pemilihan model di seluruh model dengan tipe yang sama mencakup pemasangan model yang sama dengan hyperparameter yang berbeda (misalnya, kecepatan pembelajaran) dan penghentian lebih awal untuk mencegah overfitting bobot model ke kumpulan data kereta. Pemilihan model di seluruh model dari jenis yang berbeda mencakup pemilihan arsitektur model terbaik (misalnya, Swin vs. MobileNet) dan pemilihan konfigurasi model terbaik dalam arsitektur model tunggal (misalnya, mobilenet-v1-025-128 vs mobilenet-v3-large-100-224).
Pertimbangan yang diuraikan dalam bagian ini memungkinkan semua proses pemilihan model ini pada dataset validasi.
Pilih konfigurasi hyperparameter
Klasifikasi gambar TensorFlow di JumpStart memiliki sejumlah besar tersedia hiperparameter yang dapat menyesuaikan perilaku skrip pembelajaran transfer secara seragam untuk semua arsitektur model. Hyperparameter ini terkait dengan augmentasi dan pemrosesan data, spesifikasi pengoptimal, kontrol overfitting, dan indikator lapisan yang dapat dilatih. Anda disarankan untuk menyesuaikan nilai default dari hyperparameter ini seperlunya untuk aplikasi Anda:
Untuk analisis ini dan notebook terkait, semua hyperparameter disetel ke nilai default kecuali untuk kecepatan pembelajaran, jumlah zaman, dan spesifikasi penghentian awal. Tingkat pembelajaran disesuaikan sebagai a parameter kategori oleh Tuning model otomatis SageMaker pekerjaan. Karena setiap model memiliki nilai hyperparameter default yang unik, daftar diskrit kemungkinan laju pembelajaran mencakup laju pembelajaran default serta seperlima dari laju pembelajaran default. Ini meluncurkan dua tugas pelatihan untuk satu tugas penyetelan hyperparameter, dan tugas pelatihan dengan kinerja terbaik yang dilaporkan pada set data validasi dipilih. Karena jumlah epoch diatur ke 10, yang lebih besar dari pengaturan hyperparameter default, tugas pelatihan terbaik yang dipilih tidak selalu sesuai dengan laju pembelajaran default. Akhirnya, kriteria penghentian awal digunakan dengan kesabaran, atau jumlah zaman untuk melanjutkan pelatihan tanpa peningkatan, dari tiga zaman.
Satu pengaturan hyperparameter default yang sangat penting adalah train_only_on_top_layer, di mana, jika diatur ke True, lapisan ekstraksi fitur model tidak disesuaikan pada set data pelatihan yang disediakan. Pengoptimal hanya akan melatih parameter di lapisan klasifikasi teratas yang terhubung sepenuhnya dengan dimensi keluaran yang sama dengan jumlah label kelas dalam kumpulan data. Secara default, hyperparameter ini disetel ke True, yang merupakan setelan yang ditargetkan untuk pembelajaran transfer pada kumpulan data kecil. Anda mungkin memiliki kumpulan data khusus di mana ekstraksi fitur dari pra-pelatihan pada kumpulan data ImageNet tidak memadai. Dalam kasus ini, Anda harus mengatur train_only_on_top_layer untuk False. Meskipun pengaturan ini akan menambah waktu pelatihan, Anda akan mengekstrak fitur yang lebih bermakna untuk masalah yang Anda minati, sehingga meningkatkan akurasi.
Ekstrak metrik dari CloudWatch Logs
Algoritme klasifikasi gambar JumpStart TensorFlow dengan andal mencatat berbagai metrik selama pelatihan yang dapat diakses oleh SageMaker Estimator dan objek HyperparameterTuner. Konstruktor SageMaker Estimator memiliki metric_definitions argumen kata kunci, yang dapat digunakan untuk mengevaluasi tugas pelatihan dengan memberikan daftar kamus dengan dua kunci: Nama untuk nama metrik, dan Regex untuk ekspresi reguler yang digunakan untuk mengekstrak metrik dari log. Yang menyertai buku catatan menunjukkan detail implementasi. Tabel berikut mencantumkan metrik yang tersedia dan ekspresi reguler terkait untuk semua model klasifikasi gambar JumpStart TensorFlow.
| Nama Metrik | Regular Expression |
| jumlah parameter | “- Jumlah parameter: ([0-9\.]+)” |
| jumlah parameter yang dapat dilatih | “- Jumlah parameter yang dapat dilatih: ([0-9\.]+)” |
| jumlah parameter yang tidak dapat dilatih | “- Jumlah parameter yang tidak dapat dilatih: ([0-9\.]+)” |
| melatih metrik kumpulan data | f”- {metrik}: ([0-9\.]+)” |
| metrik set data validasi | f”- val_{metrik}: ([0-9\.]+)” |
| uji metrik kumpulan data | f”- Uji {metrik}: ([0-9\.]+)” |
| durasi kereta api | “- Total durasi latihan: ([0-9\.]+)” |
| durasi kereta api per epoch | “- Durasi pelatihan rata-rata per periode: ([0-9\.]+)” |
| latensi evaluasi tes | “- Latensi evaluasi pengujian: ([0-9\.]+)” |
| uji latensi per sampel | “- Latensi pengujian rata-rata per sampel: ([0-9\.]+)” |
| throughput pengujian | “- Hasil uji rata-rata: ([0-9\.]+)” |
Skrip pembelajaran transfer bawaan menyediakan berbagai metrik dataset pelatihan, validasi, dan pengujian dalam definisi ini, sebagaimana diwakili oleh nilai penggantian f-string. Metrik yang tepat tersedia bervariasi berdasarkan jenis klasifikasi yang dilakukan. Semua model yang dikompilasi memiliki a loss metrik, yang diwakili oleh hilangnya lintas-entropi untuk masalah klasifikasi biner atau kategorikal. Yang pertama digunakan ketika ada satu label kelas; yang terakhir digunakan jika ada dua atau lebih label kelas. Jika hanya ada satu label kelas, maka metrik berikut dihitung, dicatat, dan dapat diekstraksi melalui ekspresi reguler f-string di tabel sebelumnya: jumlah nilai positif yang sebenarnya (true_pos), jumlah positif palsu (false_pos), jumlah negatif sebenarnya (true_neg), jumlah negatif palsu (false_neg), precision, recall, area di bawah kurva karakteristik operasi penerima (ROC) (auc), dan area di bawah kurva presisi-recall (PR) (prc). Demikian pula, jika ada enam label kelas atau lebih, metrik akurasi 5 teratas (top_5_accuracy) juga dihitung, dicatat, dan dapat diekstraksi melalui ekspresi reguler sebelumnya.
Selama pelatihan, metrik ditetapkan ke SageMaker Estimator dipancarkan ke CloudWatch Logs. Saat pelatihan selesai, Anda dapat mengaktifkan SageMaker Mendeskripsikan TrainingJob API dan memeriksa FinalMetricDataList masukkan respons JSON:
API ini hanya memerlukan nama tugas yang akan diberikan ke kueri, jadi, setelah selesai, metrik dapat diperoleh dalam analisis mendatang selama nama tugas pelatihan dicatat dengan tepat dan dapat dipulihkan. Untuk tugas pemilihan model ini, nama tugas penyetelan hyperparameter disimpan dan analisis berikutnya dipasang kembali a HyperparameterTuner objek yang diberi nama tugas penyetelan, ekstrak nama tugas pelatihan terbaik dari penyetel hyperparameter terlampir, lalu aktifkan DescribeTrainingJob API seperti yang dijelaskan sebelumnya untuk mendapatkan metrik yang terkait dengan pekerjaan pelatihan terbaik.
Luncurkan tugas penyetelan hyperparameter asinkron
Lihat yang sesuai buku catatan untuk detail implementasi tentang meluncurkan pekerjaan penyetelan hyperparameter secara asinkron, yang menggunakan pustaka standar Python berjangka bersamaan modul, antarmuka tingkat tinggi untuk callable yang berjalan secara asinkron. Beberapa pertimbangan terkait SageMaker diimplementasikan dalam solusi ini:
- Setiap akun AWS berafiliasi dengan Kuota layanan SageMaker. Anda harus melihat batas Anda saat ini untuk memanfaatkan sepenuhnya sumber daya Anda dan berpotensi meminta peningkatan batas sumber daya sesuai kebutuhan.
- Panggilan API yang sering untuk membuat banyak pekerjaan penyetelan hyperparameter secara bersamaan dapat dilakukan melebihi tingkat Python SDK dan membuang pengecualian pelambatan. Resolusi untuk ini adalah membuat klien SageMaker Boto3 dengan konfigurasi coba ulang kustom.
- Apa yang terjadi jika skrip Anda mengalami kesalahan atau skrip dihentikan sebelum selesai? Untuk pemilihan model atau studi pembandingan yang begitu besar, Anda dapat mencatat nama pekerjaan penyetelan dan menyediakan fungsi kemudahan untuk pasang kembali pekerjaan penyetelan hyperparameter yang sudah ada:
Detail analisis dan pembahasan
Analisis pada postingan ini melakukan transfer learning for ID model dalam algoritme klasifikasi gambar JumpStart TensorFlow pada kumpulan data Caltech-256. Semua tugas pelatihan dilakukan pada instans pelatihan SageMaker ml.g4dn.xlarge, yang berisi satu GPU NVIDIA T4.
Set data pengujian dievaluasi pada instans pelatihan di akhir pelatihan. Pemilihan model dilakukan sebelum evaluasi dataset uji untuk menetapkan bobot model ke zaman dengan kinerja kumpulan validasi terbaik. Throughput pengujian tidak dioptimalkan: ukuran batch set data disetel ke ukuran batch hyperparameter pelatihan default, yang tidak disesuaikan untuk memaksimalkan penggunaan memori GPU; throughput pengujian yang dilaporkan mencakup waktu pemuatan data karena set data tidak di-cache sebelumnya; dan inferensi terdistribusi di beberapa GPU tidak digunakan. Untuk alasan ini, throughput ini adalah pengukuran relatif yang baik, tetapi throughput aktual akan sangat bergantung pada konfigurasi penerapan titik akhir inferensi Anda untuk model yang dilatih.
Meskipun hub model JumpStart berisi banyak jenis arsitektur klasifikasi citra, batas pareto ini didominasi oleh model Swin, EfficientNet, dan MobileNet tertentu. Model Swin lebih besar dan relatif lebih akurat, sedangkan model MobileNet lebih kecil, relatif kurang akurat, dan cocok untuk batasan sumber daya perangkat seluler. Penting untuk dicatat bahwa perbatasan ini dikondisikan pada berbagai faktor, termasuk dataset yang tepat digunakan dan hyperparameter fine-tuning yang dipilih. Anda mungkin menemukan bahwa kumpulan data khusus Anda menghasilkan serangkaian solusi efisien pareto yang berbeda, dan Anda mungkin menginginkan waktu pelatihan yang lebih lama dengan hyperparameter yang berbeda, seperti penambahan data yang lebih banyak atau penyempurnaan lebih dari sekadar lapisan klasifikasi teratas model.
Kesimpulan
Dalam posting ini, kami menunjukkan cara menjalankan pemilihan model skala besar atau tugas pembandingan menggunakan hub model JumpStart. Solusi ini dapat membantu Anda memilih model terbaik untuk kebutuhan Anda. Kami mendorong Anda untuk mencoba dan menjelajahi ini larutan pada kumpulan data Anda sendiri.
Referensi
Informasi lebih lanjut tersedia di sumber berikut:
Tentang penulis
 Dr.Kyle Ulrich adalah Ilmuwan Terapan dengan Algoritme bawaan Amazon SageMaker tim. Minat penelitiannya meliputi algoritme pembelajaran mesin yang dapat diskalakan, visi komputer, deret waktu, non-parametrik Bayesian, dan proses Gaussian. PhD-nya dari Duke University dan dia telah menerbitkan makalah di NeurIPS, Cell, dan Neuron.
Dr.Kyle Ulrich adalah Ilmuwan Terapan dengan Algoritme bawaan Amazon SageMaker tim. Minat penelitiannya meliputi algoritme pembelajaran mesin yang dapat diskalakan, visi komputer, deret waktu, non-parametrik Bayesian, dan proses Gaussian. PhD-nya dari Duke University dan dia telah menerbitkan makalah di NeurIPS, Cell, dan Neuron.
 Dr Ashish Khetan adalah Ilmuwan Terapan Senior dengan Algoritme bawaan Amazon SageMaker dan membantu mengembangkan algoritme pembelajaran mesin. Dia mendapatkan gelar PhD dari University of Illinois Urbana Champaign. Dia adalah peneliti aktif dalam pembelajaran mesin dan inferensi statistik dan telah menerbitkan banyak makalah di konferensi NeurIPS, ICML, ICLR, JMLR, ACL, dan EMNLP.
Dr Ashish Khetan adalah Ilmuwan Terapan Senior dengan Algoritme bawaan Amazon SageMaker dan membantu mengembangkan algoritme pembelajaran mesin. Dia mendapatkan gelar PhD dari University of Illinois Urbana Champaign. Dia adalah peneliti aktif dalam pembelajaran mesin dan inferensi statistik dan telah menerbitkan banyak makalah di konferensi NeurIPS, ICML, ICLR, JMLR, ACL, dan EMNLP.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/image-classification-model-selection-using-amazon-sagemaker-jumpstart/
- 10
- 100
- 9
- a
- Tentang Kami
- mengakses
- dapat diakses
- Akun
- ketepatan
- tepat
- Mencapai
- di seluruh
- aktif
- tambahan
- alamat
- alamat
- Disesuaikan
- Berafiliasi
- terhadap
- algoritma
- algoritma
- Semua
- sudah
- Meskipun
- selalu
- Amazon
- Amazon SageMaker
- Mulai Lompatan Amazon SageMaker
- analisis
- dan
- Lain
- api
- Aplikasi
- terapan
- tepat
- arsitektur
- DAERAH
- argumen
- terkait
- melampirkan
- Mencoba
- secara otomatis
- tersedia
- rata-rata
- AWS
- berdasarkan
- Bayesian
- karena
- sebelum
- makhluk
- TERBAIK
- Besar
- built-in
- bisnis
- Panggilan
- calon
- kasus
- kategori
- menantang
- ciri
- Pilih
- kelas
- klasifikasi
- Klasifikasi
- klien
- bergabung
- Umum
- perbandingan
- lengkap
- Lengkap
- penyelesaian
- kompleksitas
- komputer
- Visi Komputer
- Kekhawatiran
- konferensi
- konfigurasi
- terhubung
- Koneksi
- pertimbangan
- kendala
- mengandung
- terus
- mengendalikan
- kontrol
- kenyamanan
- Sesuai
- menutupi
- membuat
- terbaru
- melengkung
- adat
- data
- kumpulan data
- lebih dalam
- Default
- tergantung
- menyebarkan
- penggelaran
- penyebaran
- kedalaman
- dijelaskan
- deskripsi
- rincian
- mengembangkan
- Devices
- berbeda
- membahas
- didistribusikan
- beberapa
- Tidak
- Duke
- universitas adipati
- selama
- setiap
- Terdahulu
- Awal
- mudah
- efisien
- antara
- menghapuskan
- aktif
- mendorong
- didorong
- ujung ke ujung
- Titik akhir
- Lingkungan Hidup
- masa
- zaman
- kesalahan
- Eter (ETH)
- mengevaluasi
- dievaluasi
- evaluasi
- contoh
- contoh
- Kecuali
- menyelidiki
- Menjelajahi
- ekspresi
- ekstrak
- ekstraksi
- faktor
- adil
- mendukung
- Fitur
- Fitur
- Fields
- Angka
- Akhirnya
- Menemukan
- Pertama
- sesuai
- berikut
- Bekas
- dari
- perbatasan
- Frontiers
- sepenuhnya
- fungsi
- masa depan
- Futures
- menghasilkan
- mendapatkan
- diberikan
- Aksi
- baik
- GPU
- GPU
- besar
- lebih besar
- Hijau
- Terjadi
- berat
- membantu
- membantu
- tingkat tinggi
- berkualitas tinggi
- lebih tinggi
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- Pusat
- Ratusan
- Penyesuaian Hyperparameter
- ICLR
- Illinois
- gambar
- Klasifikasi gambar
- IMAGEnet
- gambar
- melaksanakan
- implementasi
- diimplementasikan
- pentingnya
- penting
- perbaikan
- meningkatkan
- in
- memasukkan
- termasuk
- Termasuk
- Meningkatkan
- Meningkatkan
- meningkatkan
- indikator
- informasi
- memasukkan
- contoh
- bunga
- kepentingan
- Antarmuka
- intern
- hakiki
- memperkenalkan
- IT
- Pekerjaan
- Jobs
- json
- kunci
- kunci-kunci
- label
- Label
- besar
- besar-besaran
- lebih besar
- Latensi
- meluncurkan
- peluncuran
- lapisan
- lapisan
- terkemuka
- BELAJAR
- pengetahuan
- pengangkatan
- cahaya
- MEMBATASI
- batas
- Daftar
- daftar
- pemuatan
- Panjang
- lagi
- lepas
- mesin
- Mesin belajar
- Membuat
- banyak
- Maksimalkan
- berarti
- pengukuran
- Memori
- metrik
- Metrik
- ML
- mobil
- telepon genggam
- model
- model
- modul
- lebih
- beberapa
- nama
- nama
- perlu
- dibutuhkan
- kebutuhan
- jaringan
- saraf
- NeuroIPS
- New
- buku catatan
- jumlah
- Nvidia
- obyek
- objek
- mengamati
- memperoleh
- diperoleh
- ONE
- operasi
- Operasi
- dioptimalkan
- diuraikan
- sendiri
- dokumen
- parameter
- parameter
- tertentu
- Kesabaran
- melakukan
- prestasi
- melakukan
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- poin
- Populer
- mungkin
- Pos
- berpotensi
- pr
- mencegah
- Sebelumnya
- Masalah
- masalah
- proses
- proses
- memberikan
- disediakan
- menyediakan
- menyediakan
- diterbitkan
- Ular sanca
- pertanyaan
- Pertanyaan
- segera
- RAM
- Penilaian
- Tarif
- dunia nyata
- alasan
- mengurangi
- reguler
- relatif
- menghapus
- Dilaporkan
- mewakili
- diwakili
- merupakan
- permintaan
- wajib
- Persyaratan
- membutuhkan
- penelitian
- peneliti
- Resolusi
- sumber
- Sumber
- tanggapan
- Hasil
- Run
- berjalan
- pembuat bijak
- sama
- terukur
- ilmuwan
- script
- SDK
- Pencarian
- Bagian
- terpilih
- memilih
- seleksi
- senior
- Seri
- layanan
- Sidang
- set
- set
- pengaturan
- beberapa
- Bentuknya
- harus
- Pertunjukkan
- Demikian pula
- menyederhanakan
- serentak
- tunggal
- ENAM
- Ukuran
- ukuran
- kecil
- lebih kecil
- So
- larutan
- Solusi
- MEMECAHKAN
- spesifikasi
- spesifikasi
- ditentukan
- standar
- mulai
- statistik
- Langkah
- terhenti
- henti
- tersimpan
- Belajar
- selanjutnya
- substansial
- seperti itu
- cukup
- cocok
- tabel
- ditargetkan
- tugas
- tugas
- tim
- tensorflow
- uji
- Grafik
- mereka
- dengan demikian
- tiga
- keluaran
- waktu
- Seri waktu
- kali
- untuk
- hari ini
- bersama
- alat
- puncak
- top 5
- Total
- Pelatihan VE
- terlatih
- Pelatihan
- transfer
- transformer
- benar
- jenis
- Akhirnya
- bawah
- unik
- universitas
- penggunaan
- menggunakan
- Penggunaan
- dimanfaatkan
- pengesahan
- Nilai - Nilai
- variasi
- Luas
- melalui
- View
- penglihatan
- yang
- sementara
- lebar
- akan
- dalam
- tanpa
- akan
- penulisan
- Anda
- zephyrnet.dll