Pengantar
Dalam lanskap AI generatif yang berkembang pesat, peran penting database vektor menjadi semakin jelas. Artikel ini menyelami sinergi dinamis antara database vektor dan solusi AI generatif, mengeksplorasi bagaimana landasan teknologi ini membentuk masa depan kreativitas kecerdasan buatan. Bergabunglah bersama kami dalam perjalanan menelusuri seluk-beluk aliansi yang kuat ini, membuka wawasan tentang dampak transformatif yang dibawa oleh basis data vektor ke garis depan solusi AI yang inovatif.
Tujuan Pembelajaran
Artikel ini membantu Anda memahami aspek Database Vektor di bawah ini.
- Signifikansi Database Vektor dan komponen utamanya
- Studi mendetail tentang perbandingan database Vektor dengan database Tradisional
- Eksplorasi Penyematan Vektor dari sudut pandang aplikasi
- Pembuatan basis data vektor menggunakan Pincone
- Implementasi database Pinecone Vector menggunakan model langchain LLM
Artikel ini diterbitkan sebagai bagian dari Blogathon Ilmu Data.
Daftar Isi
Apa itu Basis Data Vektor?
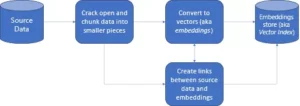
Basis data vektor adalah bentuk pengumpulan data yang disimpan dalam ruang. Namun, di sini, data disimpan dalam representasi matematis karena format yang disimpan dalam database memudahkan model AI terbuka untuk mengingat masukan dan memungkinkan aplikasi AI terbuka kami menggunakan penelusuran kognitif, rekomendasi, dan pembuatan teks untuk berbagai kasus penggunaan di industri yang bertransformasi secara digital. Penyimpanan dan pengambilan data disebut “Vector Embeddings” atau “Embeddings.” Selain itu, ini direpresentasikan dalam format array numerik. Pencarian jauh lebih mudah dibandingkan database tradisional yang digunakan untuk perspektif AI dengan kemampuan terindeks yang sangat besar.
Karakteristik Database Vektor
- Ini memanfaatkan kekuatan penyematan vektor ini, yang mengarah pada pengindeksan dan pencarian di kumpulan data yang sangat besar.
- Dapat dipadatkan dengan semua format data (gambar, teks, atau data).
- Karena mengadaptasi teknik penyematan dan fitur yang sangat terindeks, ia dapat menawarkan solusi lengkap untuk mengelola data dan masukan untuk masalah tertentu.
- Basis data vektor mengatur data melalui vektor berdimensi tinggi yang berisi ratusan dimensi. Kami dapat mengonfigurasinya dengan sangat cepat.
- Setiap dimensi berhubungan dengan fitur atau properti tertentu dari objek data yang diwakilinya.
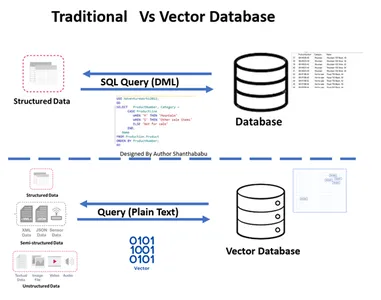
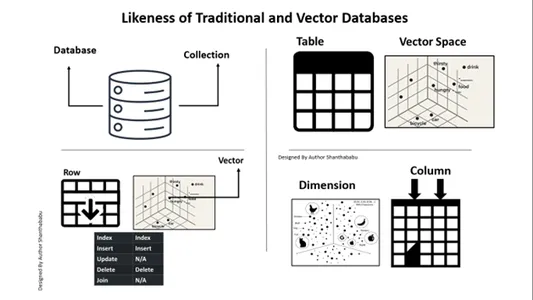
Tradisional Vs. Basis Data Vektor
- Gambar menunjukkan alur kerja tingkat tinggi database tradisional dan vektor
- Interaksi database formal terjadi melalui SQL pernyataan dan data disimpan dalam format basis baris dan tabel.
- Dalam database Vector, interaksi terjadi melalui teks biasa (misalnya bahasa Inggris) dan data disimpan dalam representasi matematika.
Kemiripan Database Tradisional dan Vektor
Kita harus mempertimbangkan perbedaan database Vector dari database tradisional. Mari kita bahas ini di sini. Satu perbedaan cepat yang dapat saya berikan adalah pada database konvensional. Data disimpan apa adanya; kita dapat menambahkan beberapa logika bisnis untuk menyesuaikan data dan menggabungkan atau membagi data berdasarkan kebutuhan atau permintaan bisnis. Namun, database vektor mengalami transformasi besar-besaran, dan datanya menjadi representasi vektor yang kompleks.
Berikut peta untuk pemahaman dan kejelasan perspektif Anda database relasional terhadap database vektor. Gambar di bawah ini cukup jelas untuk memahami database vektor dengan database tradisional. Singkatnya, kita dapat mengeksekusi penyisipan dan penghapusan ke dalam database vektor, bukan memperbarui pernyataan.
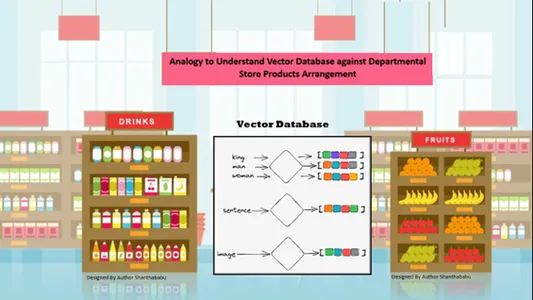
Analogi Sederhana untuk Memahami Database Vektor
Data secara otomatis disusun secara spasial berdasarkan kesamaan konten dalam informasi yang disimpan. Jadi, mari kita pertimbangkan department store untuk analogi database vektor; semua produk disusun di rak berdasarkan sifat, tujuan, pembuatan, penggunaan, dan basis kuantitas. Dalam perilaku serupa, datanya adalah
disusun secara otomatis dalam database vektor dengan jenis yang serupa, meskipun genre tidak terdefinisi dengan baik saat menyimpan atau mengakses data.
Basis data vektor memungkinkan perincian dan dimensi yang menonjol pada kesamaan tertentu, sehingga pelanggan mencari produk, produsen, dan kuantitas yang diinginkan, serta menyimpan barang tersebut di keranjang. Basis data vektor menyimpan semua data dalam struktur penyimpanan yang sempurna; di sini, teknisi Machine Learning dan AI tidak perlu memberi label atau menandai konten yang disimpan secara manual.
Teori penting di balik Database Vektor
- Penyematan Vektor dan Cakupannya
- Persyaratan Pengindeksan
- Memahami Pencarian Semantik dan Kesamaan
Penyematan Vektor dan Cakupannya
Penyematan vektor adalah representasi vektor dalam bentuk nilai numerik. Dalam format terkompresi, penyematan menangkap properti dan asosiasi yang melekat pada data asli, menjadikannya bahan pokok dalam kasus penggunaan Kecerdasan Buatan dan Pembelajaran Mesin. Merancang penyematan untuk menyandikan informasi terkait tentang data asli ke dalam ruang berdimensi lebih rendah memastikan kecepatan pengambilan yang tinggi, efisiensi komputasi, dan penyimpanan yang efisien.
Menangkap esensi data dengan cara terstruktur yang lebih identik adalah proses penyematan vektor, membentuk 'Model Penyematan'. Pada akhirnya, model ini mempertimbangkan semua objek data, mengekstrak pola dan hubungan yang bermakna dalam sumber data, dan mengubahnya menjadi penyematan vektor . Selanjutnya, algoritme memanfaatkan penyematan vektor ini untuk menjalankan berbagai tugas. Banyak model penyematan yang sangat maju, tersedia online secara gratis atau berbayar, memfasilitasi pencapaian penyematan vektor.
Cakupan Penyematan Vektor dari sudut pandang Aplikasi
Penyematan ini kompak, berisi informasi kompleks, mewarisi hubungan antar data yang disimpan dalam database vektor, memungkinkan analisis pemrosesan data yang efisien untuk memfasilitasi pemahaman dan pengambilan keputusan, dan secara dinamis membangun berbagai produk data inovatif di seluruh organisasi.
Teknik penyematan vektor sangat penting dalam menghubungkan kesenjangan antara data yang dapat dibaca dan algoritma yang kompleks. Dengan tipe data berupa vektor numerik, kami dapat membuka potensi beragam aplikasi AI Generatif bersama dengan model Open AI yang tersedia.
Banyak Pekerjaan dengan Penyematan Vektor
Penyematan vektor ini membantu kita melakukan banyak pekerjaan:
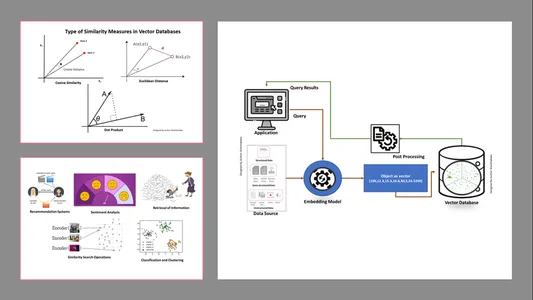
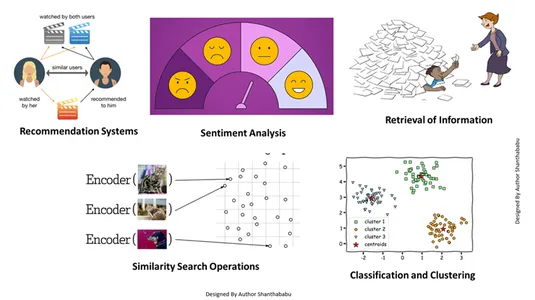
- Pengambilan Informasi: Dengan bantuan teknik canggih ini, kita dapat membangun mesin pencari berpengaruh yang dapat membantu kita menemukan tanggapan berdasarkan pertanyaan pengguna dari file, dokumen, atau media yang disimpan.
- Operasi Pencarian Kesamaan: Ini terorganisir dan terindeks dengan baik; ini membantu kita menemukan kesamaan antara kejadian berbeda dalam data vektor.
- Klasifikasi dan Pengelompokan: Dengan menggunakan teknik penyematan ini, kita dapat menjalankan model ini untuk melatih algoritme pembelajaran mesin yang relevan serta mengelompokkan dan mengklasifikasikannya.
- Sistem Rekomendasi: Karena teknik penyematan diatur dengan benar, hal ini menghasilkan sistem rekomendasi yang menghubungkan produk, media, dan artikel secara akurat berdasarkan data historis.
- Analisis Sentimen: Model penyematan ini membantu kita mengkategorikan dan mendapatkan solusi sentimen.
Persyaratan Pengindeksan
Seperti yang kita ketahui, indeks akan meningkatkan pencarian data dari tabel di database tradisional, mirip dengan database vektor, dan menyediakan fitur pengindeksan.
Basis data vektor menyediakan “Indeks datar”, yang merupakan representasi langsung dari penyematan vektor. Kemampuan pencariannya komprehensif, dan ini tidak menggunakan cluster yang telah dilatih sebelumnya. Ia melakukan vektor kueri yang dilakukan di setiap penyematan vektor tunggal, dan jarak K dihitung untuk setiap pasangan.
- Karena kemudahan indeks ini, diperlukan komputasi minimal untuk membuat indeks baru.
- Memang benar, indeks datar dapat menangani kueri secara efektif dan memberikan waktu pengambilan yang cepat.
Memahami Pencarian Semantik dan Kesamaan
Kami melakukan dua pencarian berbeda dalam database vektor: pencarian semantik dan kesamaan.
- Pencarian semantik: Saat mencari informasi, alih-alih mencari berdasarkan kata kunci, Anda dapat menemukannya berdasarkan metodologi percakapan yang bermakna. Rekayasa yang cepat memainkan peran penting dalam meneruskan masukan ke sistem. Pencarian ini tidak diragukan lagi memungkinkan pencarian dan hasil berkualitas lebih tinggi yang dapat diberikan untuk aplikasi inovatif, SEO, pembuatan teks, dan Peringkasan.
- Pencarian Kesamaan: Selalu dalam analisis data, pencarian kesamaan memungkinkan kumpulan data yang tidak terstruktur dan diberikan dengan lebih baik. Mengenai database vektor, kita harus memastikan kedekatan dua vektor dan kemiripannya satu sama lain: tabel, teks, dokumen, gambar, kata, dan file audio. Dalam proses pemahamannya, kemiripan antar vektor terungkap sebagai kemiripan antara objek data dalam dataset yang diberikan. Latihan ini membantu kita memahami interaksi, mengidentifikasi pola, mengekstrak wawasan, dan membuat keputusan dari perspektif aplikasi. Pencarian Semantik dan Kesamaan akan membantu kami membangun aplikasi di bawah ini untuk keuntungan industri.
- Pengambilan Informasi: Dengan menggunakan Open AI dan Database Vektor, kami akan membangun mesin pencari untuk pengambilan informasi menggunakan kueri pengguna bisnis atau pengguna akhir dan mengindeks dokumen di dalam DB vektor.
- Klasifikasi dan Pengelompokan:Mengklasifikasikan atau mengelompokkan titik data atau kelompok objek yang serupa melibatkan penetapannya ke beberapa kategori berdasarkan karakteristik bersama.
- Deteksi Anomali: Menemukan kelainan dari pola biasa dengan mengukur kesamaan titik data dan menemukan ketidakteraturan.
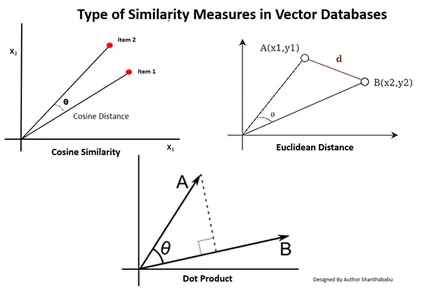
Jenis Ukuran Kesamaan dalam Database Vektor
Metode pengukurannya bergantung pada sifat data dan spesifik aplikasinya. Umumnya, tiga metode digunakan untuk mengukur kesamaan dan keakraban dengan Machine Learning.
Jarak Euclidean
Secara sederhana, jarak kedua vektor adalah jarak garis lurus antara dua titik vektor yang mengukur st.
Produk titik
Hal ini membantu kita memahami keselarasan antara dua vektor, yang menunjukkan apakah keduanya mengarah ke arah yang sama, berlawanan arah, atau tegak lurus satu sama lain.
Kesamaan Cosinus
Ini menilai kesamaan dua vektor dengan menggunakan sudut di antara keduanya, seperti yang ditunjukkan pada gambar. Dalam hal ini, nilai dan besaran vektor tidak signifikan dan tidak mempengaruhi hasil; hanya sudut yang diperhitungkan dalam perhitungan.
Basis data tradisional Mencari kecocokan pernyataan SQL yang tepat dan mengambil data dalam format tabel. Pada saat yang sama, kami menangani database vektor yang mencari vektor yang paling mirip dengan kueri masukan dalam bahasa Inggris menggunakan teknik Prompt Engineering. Basis data menggunakan algoritma pencarian Approximate Nearest Neighbour (ANN) untuk menemukan data serupa. Selalu berikan hasil yang cukup akurat dengan performa, akurasi, dan waktu respons tinggi.
Mekanisme Kerja
- Basis data vektor pertama-tama mengubah data menjadi vektor yang disematkan, menyimpannya dalam basis data vektor, dan membuat pengindeksan untuk pencarian yang lebih cepat.
- Kueri dari aplikasi akan berinteraksi dengan vektor yang disematkan, mencari tetangga terdekat atau data serupa di database vektor menggunakan indeks dan mengambil hasilnya yang diteruskan ke aplikasi.
- Berdasarkan kebutuhan bisnis, data yang diambil akan disesuaikan, diformat, dan ditampilkan ke sisi pengguna akhir atau umpan kueri atau tindakan.
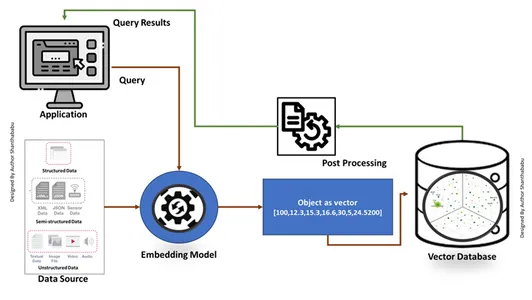
Membuat Basis Data Vektor
Mari terhubung dengan Pinecone.
Anda dapat terhubung ke Pinecone menggunakan Google, GitHub, atau Microsoft ID.
Buat login pengguna baru untuk penggunaan Anda.
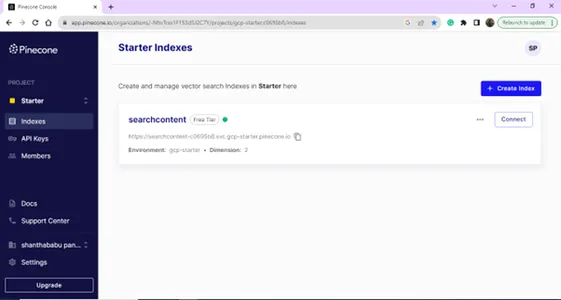
Setelah login berhasil, Anda akan diarahkan ke halaman Indeks; Anda dapat membuat indeks untuk keperluan Database Vektor Anda. Klik pada tombol Buat Indeks.
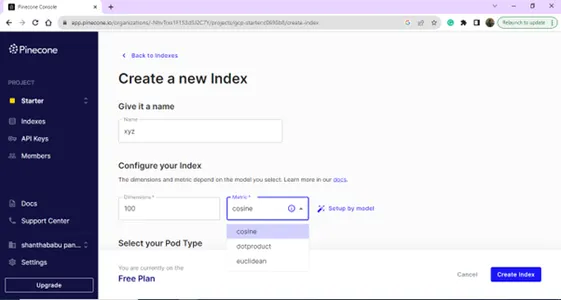
Buat indeks baru Anda dengan memberikan Nama dan Dimensi.
Halaman daftar indeks,
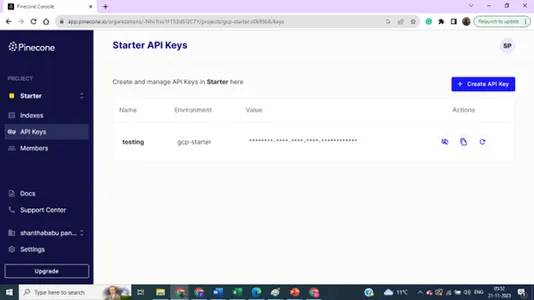
Detail indeks – Nama, Wilayah, dan Lingkungan – Kita memerlukan semua detail ini untuk menghubungkan database vektor kita dari kode pembuatan model.
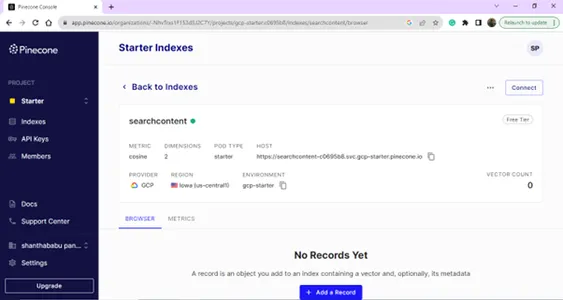
Detail pengaturan proyek,
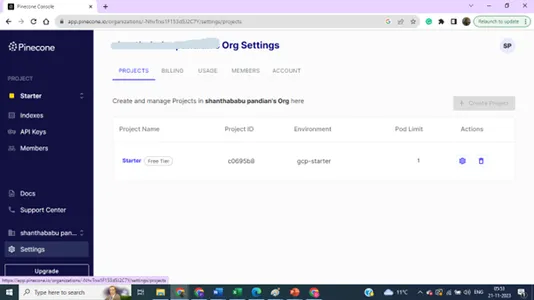
Anda dapat meningkatkan preferensi Anda untuk beberapa indeks dan kunci untuk tujuan proyek.
Sejauh ini, kita telah membahas pembuatan indeks dan pengaturan database vektor di Pinecone.
Implementasi Database Vektor Menggunakan Python
Mari kita lakukan coding sekarang.
Mengimpor perpustakaan
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIMenyediakan kunci API untuk database OpenAI dan Vector
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Memulai LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Memulai Biji Pinus
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Memuat file .csv untuk membangun database vektor
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Pisahkan teks menjadi beberapa bagian
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Menemukan teks di text_chunk
text_chunksKeluaran
[Dokumen(page_content='nama: 100% Brannmfr: Nntipe: Cnkalori: 70nprotein: 4nlemak: 1nsodium: 130nfiber: 10nkarbo: 5ngula: 6nkalium: 280nvitamin: 25nrak: 3nberat: 1ncup: 0.33nrating: 68.402973nrekomendasi : Anak-anak, metadata={ 'sumber': '100% Dedak', 'baris': 0}), , …..
Penyematan bangunan
embeddings = OpenAIEmbeddings()Buat instance Pinecone untuk database vektor dari 'data'
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Buat retriever untuk menanyakan database vektor.
retriever = vectordb.as_retriever(score_threshold = 0.7)Mengambil data dari database vektor
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsMenggunakan Prompt dan mengambil data
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
Mari kita menanyakan datanya.
chain('Can you please provide cereal recommendation for Kids?')Keluaran dari Kueri
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]Kesimpulan
Semoga Anda dapat memahami cara kerja database vektor, komponennya, arsitekturnya, dan karakteristik Database Vektor dalam solusi AI Generatif. Memahami perbedaan database vektor dengan database tradisional dan membandingkannya dengan elemen database konvensional. Memang benar, analogi ini membantu Anda lebih memahami database vektor. Basis data vektor biji pinus dan langkah pengindeksan akan membantu Anda membuat basis data vektor dan memberikan kunci untuk implementasi kode berikut.
Pengambilan Kunci
- Dapat dipadatkan dengan data terstruktur, tidak terstruktur, dan semi terstruktur.
- Ini mengadaptasi teknik penyematan dan fitur yang sangat terindeks.
- Interaksi terjadi melalui teks biasa menggunakan prompt (misalnya, bahasa Inggris). Dan data disimpan dalam representasi matematis.
- Kemiripan dikalibrasi dalam Database Vektor melalui – Jarak Euclidean, Kemiripan Kosinus, dan Perkalian Titik.
Tanya Jawab Umum (FAQ)
A. Basis data vektor menyimpan kumpulan data dalam ruang. Itu menyimpan data dalam representasi matematis. karena format yang disimpan dalam database memudahkan model AI terbuka untuk mengingat masukan sebelumnya dan memungkinkan aplikasi AI terbuka kami menggunakan pencarian kognitif, rekomendasi, dan pembuatan teks yang tepat untuk berbagai kasus penggunaan di industri yang bertransformasi secara digital.
A. Beberapa karakteristiknya adalah: 1. Memanfaatkan kekuatan penyematan vektor ini, yang mengarah pada pengindeksan dan pencarian di kumpulan data yang sangat besar. 2. Dapat dipadatkan dengan data terstruktur, tidak terstruktur, dan semi terstruktur. 3. Basis data vektor mengatur data melalui vektor berdimensi tinggi yang berisi ratusan dimensi
A. Basis Data ==> Koleksi
Tabel==> Ruang Vektor
Baris==>Sektor
Kolom==>Dimensi
Memasukkan dan Menghapus dapat dilakukan di database Vektor, sama seperti di database tradisional.
Pembaruan dan Gabung tidak termasuk dalam cakupan.
– Pengambilan Informasi untuk pengumpulan data besar-besaran dengan cepat.
– Operasi Pencarian Semantik dan Kesamaan dari dokumen berukuran besar.
– Aplikasi Klasifikasi dan Clustering.
– Sistem Rekomendasi dan Analisis Sentimen.
A5: Berikut adalah tiga metode untuk mengukur kesamaan:
- Jarak Euclidean
– Kesamaan Kosinus
- Produk titik
Media yang ditampilkan dalam artikel ini bukan milik Analytics Vidhya dan digunakan atas kebijaksanaan Penulis.
terkait
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :memiliki
- :adalah
- :bukan
- $NAIK
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- Sanggup
- Tentang Kami
- mengakses
- ketepatan
- tepat
- akurat
- di seluruh
- beradaptasi
- menambahkan
- mempengaruhi
- AI
- Model AI
- algoritma
- algoritma
- penjajaran
- Semua
- Persekutuan
- mengizinkan
- memungkinkan
- sepanjang
- selalu
- antara
- an
- analisis
- analisis
- Analisis Vidhya
- dan
- menjawab
- Apa pun
- api
- semu
- Aplikasi
- khusus aplikasi
- aplikasi
- kira-kira
- arsitektur
- ADALAH
- diatur
- susunan
- artikel
- artikel
- buatan
- kecerdasan buatan
- Kecerdasan Buatan dan Pembelajaran Mesin
- AS
- aspek
- menilai
- asosiasi
- At
- audio
- secara otomatis
- tersedia
- berdasarkan
- BE
- menjadi
- menjadi
- laku
- di belakang
- makhluk
- di bawah
- Manfaat
- Lebih baik
- antara
- blogathon
- membawa
- membangun
- Bangunan
- bisnis
- tombol
- by
- dihitung
- perhitungan
- bernama
- CAN
- kemampuan
- kemampuan
- menangkap
- kasus
- kasus
- kategori
- rantai
- rantai
- karakteristik
- kejelasan
- klasifikasi
- Klasifikasi
- Klik
- kekelompokan
- kode
- Pengkodean
- kognitif
- koleksi
- umum
- padat
- membandingkan
- perbandingan
- lengkap
- kompleks
- komponen
- luas
- komputasi
- komputasi
- Terhubung
- Menghubungkan
- Mempertimbangkan
- dianggap
- mengandung
- Konten
- konteks
- konvensional
- Percakapan
- mengubah
- berkorespondensi
- bisa
- membuat
- membuat
- kreativitas
- pelanggan
- data
- analisis data
- titik data
- pengolahan data
- Basis Data
- database
- kumpulan data
- transaksi
- Pengambilan Keputusan
- keputusan
- tuntutan
- memperoleh
- merancang
- diinginkan
- rincian
- Deteksi
- dikembangkan
- berbeda
- perbedaan
- berbeda
- digital
- Dimensi
- ukuran
- langsung
- arah
- arah
- menemukan
- kebijaksanaan
- membahas
- dibahas
- ditampilkan
- jarak
- do
- dokumen
- tidak
- don
- DOT
- dinamis
- dinamis
- e
- setiap
- memudahkan
- mudah
- efektif
- efisiensi
- efisien
- antara
- elemen
- embedding
- aktif
- akhir
- Teknik
- Insinyur
- Mesin
- Inggris
- Memastikan
- Lingkungan Hidup
- esensi
- penting
- Eter (ETH)
- Bahkan
- berkembang
- menjalankan
- Latihan
- Menjelajahi
- ekstrak
- memudahkan
- Keakraban
- jauh
- Fitur
- Fitur
- Fed
- Angka
- File
- File
- Menemukan
- Pertama
- datar
- berikut
- Untuk
- garis terdepan
- bentuk
- format
- Gratis
- dari
- masa depan
- celah
- menghasilkan
- generasi
- generatif
- AI generatif
- aliran
- GitHub
- Memberikan
- diberikan
- Kelompok
- Grup
- menangani
- terjadi
- Memiliki
- membantu
- membantu
- di sini
- High
- tingkat tinggi
- sangat
- historis
- Seterpercayaapakah Olymp Trade? Kesimpulan
- Namun
- HTTPS
- besar
- Ratusan
- i
- ID
- mengenali
- if
- gambar
- Dampak
- implementasi
- mengimpor
- memperbaiki
- in
- makin
- indeks
- diindeks
- indeks
- Menunjukkan
- Indeks
- industri
- industri
- Berpengaruh
- informasi
- inheren
- inovatif
- memasukkan
- input
- Sisipan
- dalam
- wawasan
- contoh
- sebagai gantinya
- Intelijen
- berinteraksi
- interaksi
- interaksi
- ke
- seluk-beluk
- melibatkan
- IT
- NYA
- Jobs
- ikut
- Bergabung dengan kami
- perjalanan
- hanya
- kunci
- kunci-kunci
- kata kunci
- anak
- Tahu
- label
- Tanah
- pemandangan
- besar
- terkemuka
- Memimpin
- pengetahuan
- Leverage
- memanfaatkan
- 'like'
- Daftar
- pemuat
- logika
- masuk
- mesin
- Mesin belajar
- utama
- membuat
- MEMBUAT
- Membuat
- pelaksana
- cara
- manual
- Pabrikan
- peta
- besar-besaran
- korek api
- matematis
- berarti
- mengukur
- ukuran
- ukur
- mekanisme
- Media
- Bergabung
- Metodologi
- metode
- Microsoft
- minimal
- model
- model
- lebih
- Selain itu
- paling
- banyak
- beberapa
- harus
- nama
- Alam
- Perlu
- New
- sekarang
- banyak sekali
- obyek
- objek
- of
- menawarkan
- on
- ONE
- yang
- secara online
- hanya
- Buka
- OpenAI
- Operasi
- seberang
- or
- organisasi
- terorganisir
- mengorganisir
- asli
- OS
- Lainnya
- kami
- dimiliki
- halaman
- pasangan
- bagian
- Lulus
- Lewat
- pola
- sempurna
- melakukan
- prestasi
- dilakukan
- melakukan
- perspektif
- perspektif
- gambar
- sangat penting
- Polos
- plato
- Kecerdasan Data Plato
- Data Plato
- memainkan
- silahkan
- Titik
- poin
- mungkin
- potensi
- kekuasaan
- kuat
- Praktis
- Aplikasi Praktis
- perlu
- tepat
- preferensi
- sebelumnya
- Masalah
- proses
- Produk
- Produk
- proyek
- menonjol
- meminta
- tepat
- properties
- milik
- memberikan
- menyediakan
- ketentuan
- diterbitkan
- Puffs
- tujuan
- tujuan
- kuantitas
- query
- pertanyaan
- Cepat
- lebih cepat
- segera
- cepat
- Rekomendasi
- rekomendasi
- mengenai
- wilayah
- hubungan
- Hubungan
- relevan
- perwakilan
- diwakili
- merupakan
- wajib
- Persyaratan
- tanggapan
- tanggapan
- mengakibatkan
- Hasil
- Terungkap
- Peran
- BARIS
- s
- sama
- Ilmu
- cakupan
- Pencarian
- Mesin pencari
- pencarian
- mencari
- sentimen
- SEO
- pengaturan
- Bentuknya
- membentuk
- berbagi
- Rak
- Pendek
- ditunjukkan
- Pertunjukkan
- sisi
- mirip
- kesamaan
- Sederhana
- sejak
- tunggal
- Ukuran
- So
- larutan
- Solusi
- beberapa
- sumber
- Space
- tertentu
- kecepatan
- membagi
- bercak
- SQL
- Negara
- Pernyataan
- Laporan
- Tangga
- Masih
- penyimpanan
- menyimpan
- tersimpan
- toko
- struktur
- tersusun
- Belajar
- Kemudian
- sukses
- sinergi
- sistem
- sistem
- T
- tabel
- MENANDAI
- tugas
- teknik
- teknologi
- istilah
- teks
- pembuatan teks
- dari
- bahwa
- Grafik
- Masa depan
- mereka
- Mereka
- Ini
- mereka
- ini
- tiga
- Melalui
- waktu
- kali
- untuk
- tradisional
- Pelatihan VE
- Mengubah
- Transformasi
- transformatif
- berubah
- mencoba
- dua
- jenis
- Akhirnya
- memahami
- pemahaman
- niscaya
- membuka kunci
- unlocking
- Memperbarui
- meningkatkan
- us
- penggunaan
- menggunakan
- bekas
- Pengguna
- kegunaan
- menggunakan
- biasa
- Nilai - Nilai
- variasi
- berbagai
- sangat
- vital
- vs
- adalah
- we
- webp
- terdefinisi dengan baik
- adalah
- Apa
- Apa itu
- apakah
- yang
- sementara
- akan
- dengan
- dalam
- kata
- Kerja
- kerja
- akan
- kamu
- Anda
- zephyrnet.dll