
Gambar dari Penulis | Pembuat Gambar Bing
boneka 2.0 adalah model bahasa besar (LLM) sumber terbuka, diikuti instruksi, yang disesuaikan dengan baik pada kumpulan data yang dihasilkan manusia. Ini dapat digunakan untuk tujuan penelitian dan komersial.
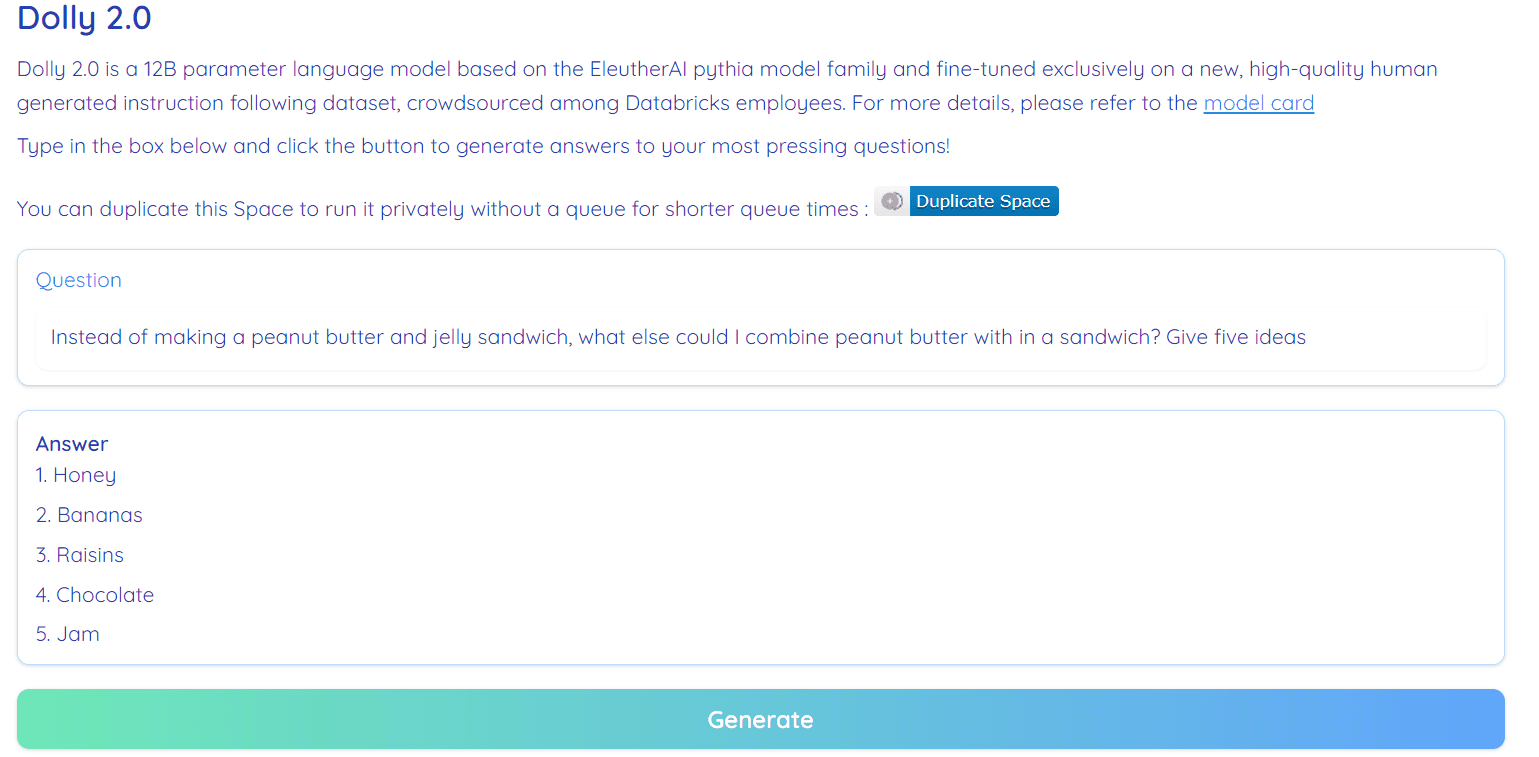
Gambar dari Memeluk Ruang Wajah oleh RamAnanth1
Sebelumnya, tim Databricks merilis boneka 1.0, LLM, yang menunjukkan kemampuan mengikuti instruksi seperti ChatGPT dan biaya pelatihan kurang dari $30. Itu menggunakan kumpulan data tim Stanford Alpaca, yang berada di bawah lisensi terbatas (Hanya penelitian).
Dolly 2.0 telah mengatasi masalah ini dengan menyempurnakan model bahasa parameter 12B (pythia) pada instruksi buatan manusia berkualitas tinggi dalam kumpulan data berikut, yang diberi label oleh karyawan Datbricks. Model dan kumpulan data tersedia untuk penggunaan komersial.
Dolly 1.0 dilatih menggunakan dataset Stanford Alpaca, yang dibuat menggunakan OpenAI API. Kumpulan data berisi keluaran dari ChatGPT dan mencegah siapa pun menggunakannya untuk bersaing dengan OpenAI. Singkatnya, Anda tidak dapat membuat chatbot komersial atau aplikasi bahasa berdasarkan kumpulan data ini.
Sebagian besar model terbaru yang dirilis dalam beberapa minggu terakhir mengalami masalah yang sama, seperti model kambing peru, Koala, GPT4Semua, dan Vicuna. Untuk menyiasatinya, kami perlu membuat kumpulan data baru berkualitas tinggi yang dapat digunakan untuk penggunaan komersial, dan itulah yang telah dilakukan oleh tim Databricks dengan kumpulan data databricks-dolly-15k.
Dataset baru ini berisi 15,000 pasangan prompt/respons berlabel manusia berkualitas tinggi yang dapat digunakan untuk mendesain model penyetelan instruksi bahasa besar. Itu databricks-dolly-15k kumpulan data disertakan Lisensi Creative Commons Attribution-ShareAlike 3.0 Unported, yang memungkinkan siapa saja untuk menggunakannya, memodifikasinya, dan membuat aplikasi komersial di dalamnya.
Bagaimana mereka membuat kumpulan data databricks-dolly-15k?
Penelitian OpenAI kertas menyatakan bahwa model InstructGPT asli dilatih pada 13,000 prompt dan respons. Dengan menggunakan informasi ini, tim Databricks mulai mengerjakannya, dan ternyata menghasilkan 13k pertanyaan dan jawaban adalah tugas yang sulit. Mereka tidak dapat menggunakan data sintetik atau data generatif AI, dan mereka harus menghasilkan jawaban orisinal untuk setiap pertanyaan. Di sinilah mereka memutuskan untuk menggunakan 5,000 karyawan Databricks untuk membuat data buatan manusia.
Databricks telah membuat sebuah kontes, di mana 20 pemberi label teratas akan mendapatkan penghargaan besar. Dalam kontes ini, 5,000 karyawan Databricks berpartisipasi yang sangat tertarik dengan LLM
Dolly-v2-12b bukanlah model yang canggih. Ini berkinerja buruk dolly-v1-6b di beberapa tolok ukur evaluasi. Mungkin karena komposisi dan ukuran set data fine-tuning yang mendasarinya. Keluarga model Dolly sedang dalam pengembangan aktif, jadi Anda mungkin melihat versi terbaru dengan kinerja yang lebih baik di masa mendatang.
Singkatnya, model dolly-v2-12b memiliki kinerja yang lebih baik daripada EleutherAI/gpt-neox-20b dan EleutherAI/pythia-6.9b.

Gambar dari Dolly gratis
Dolly 2.0 adalah 100% sumber terbuka. Muncul dengan kode pelatihan, kumpulan data, bobot model, dan pipa inferensi. Semua komponen cocok untuk penggunaan komersial. Anda bisa mencoba modelnya di Hugging Face Spaces Dolly V2 oleh RamAnanth1.
Gambar dari Wajah Memeluk
Sumber:
Demo Dolly 2.0: Dolly V2 oleh RamAnanth1
Abi Ali Awan (@1abidaliawan) adalah ilmuwan data profesional bersertifikat yang suka membuat model pembelajaran mesin. Saat ini, ia berfokus pada pembuatan konten dan penulisan blog teknis tentang pembelajaran mesin dan teknologi ilmu data. Abid memiliki gelar Magister Manajemen Teknologi dan gelar Sarjana Teknik Telekomunikasi. Visinya adalah untuk membangun produk AI menggunakan jaringan saraf grafik untuk siswa yang berjuang dengan penyakit mental.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Mencetak Masa Depan bersama Adryenn Ashley. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- :memiliki
- :adalah
- :bukan
- $NAIK
- 000
- 1
- 20
- a
- kemampuan
- aktif
- AI
- Semua
- memungkinkan
- alternatif
- an
- dan
- jawaban
- siapapun
- api
- Aplikasi
- ADALAH
- sekitar
- penulis
- tersedia
- hadiah
- berdasarkan
- BE
- Benchmark
- Berkeley
- Lebih baik
- Besar
- bing
- blog
- kedua
- membangun
- Bangunan
- by
- CAN
- tidak bisa
- Tersertifikasi
- ChatBot
- ChatGPT
- kode
- komersial
- Ruang makan besar
- bersaing
- komponen
- mengandung
- Konten
- pembuatan konten
- kontes
- Biaya
- membuat
- dibuat
- penciptaan
- Sekarang
- data
- ilmu data
- ilmuwan data
- batu bata data
- kumpulan data
- memutuskan
- Derajat
- Demo
- Mendesain
- Pengembangan
- MELAKUKAN
- sulit
- Boneka
- Karyawan
- karyawan
- Teknik
- evaluasi
- Setiap
- pameran
- Menghadapi
- keluarga
- beberapa
- berfokus
- berikut
- Untuk
- dari
- masa depan
- menghasilkan
- menghasilkan
- generatif
- mendapatkan
- grafik
- Jaringan Saraf Grafik
- Memiliki
- he
- berkualitas tinggi
- memegang
- HTML
- HTTPS
- penyakit
- gambar
- in
- informasi
- tertarik
- isu
- masalah
- IT
- jpg
- KDnugget
- bahasa
- besar
- Terakhir
- Terbaru
- pengetahuan
- Lisensi
- 'like'
- mesin
- Mesin belajar
- pengelolaan
- menguasai
- mental yang
- Penyakit kejiwaan
- mungkin
- model
- model
- memodifikasi
- Perlu
- jaringan
- saraf
- saraf jaringan
- New
- of
- on
- hanya
- Buka
- open source
- OpenAI
- or
- asli
- keluaran
- pasang
- parameter
- berpartisipasi
- prestasi
- pipa saluran
- plato
- Kecerdasan Data Plato
- Data Plato
- Produk
- profesional
- tujuan
- pertanyaan
- Pertanyaan
- dirilis
- penelitian
- diselesaikan
- terbatas
- s
- sama
- Ilmu
- ilmuwan
- set
- Pendek
- Ukuran
- So
- beberapa
- sumber
- Space
- spasi
- Stanford
- mulai
- state-of-the-art
- Negara
- Berjuang
- Siswa
- cocok
- sintetis
- data sintetis
- tugas
- tim
- Teknis
- Teknologi
- Teknologi
- telekomunikasi
- dari
- bahwa
- Grafik
- Masa depan
- mereka
- ini
- untuk
- puncak
- Pelatihan VE
- terlatih
- Pelatihan
- bawah
- pokok
- diperbarui
- menggunakan
- bekas
- menggunakan
- versi
- penglihatan
- adalah
- we
- minggu
- adalah
- Apa
- yang
- SIAPA
- dengan
- Kerja
- akan
- penulisan
- kamu
- zephyrnet.dll










