Pergeseran Merah Amazon adalah gudang data cloud berskala petabyte yang dikelola sepenuhnya dan digunakan oleh puluhan ribu pelanggan untuk memproses data berukuran exabyte setiap hari untuk mendukung beban kerja analitik mereka. Anda dapat menyusun data Anda, mengukur proses bisnis, dan mendapatkan wawasan berharga dengan cepat dapat dilakukan dengan menggunakan model dimensi. Amazon Redshift menyediakan fitur bawaan untuk mempercepat proses pemodelan, pengaturan, dan pelaporan dari model dimensional.
Dalam posting ini, kita membahas bagaimana mengimplementasikan model dimensi, khususnya Metodologi Kimball. Kami membahas penerapan dimensi dan fakta dalam Amazon Redshift. Kami menunjukkan cara melakukan ekstrak, transformasi, dan pemuatan (ELT), sebuah proses integrasi yang berfokus untuk mendapatkan data mentah dari data lake ke lapisan pementasan untuk melakukan pemodelan. Secara keseluruhan, postingan tersebut akan memberi Anda pemahaman yang jelas tentang cara menggunakan pemodelan dimensi di Amazon Redshift.
Ikhtisar solusi
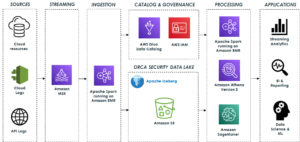
Diagram berikut menggambarkan arsitektur solusi.

Pada bagian berikut, pertama-tama kita akan membahas dan mendemonstrasikan aspek kunci dari model dimensional. Setelah itu, kami membuat data mart menggunakan Amazon Redshift dengan model data dimensi termasuk tabel dimensi dan fakta. Data dimuat dan dipentaskan menggunakan COPY perintah, data dalam dimensi dimuat menggunakan MENGGABUNGKAN pernyataan, dan fakta akan digabungkan ke dimensi dari mana wawasan berasal. Kami menjadwalkan pemuatan dimensi dan fakta menggunakan Editor Kueri Amazon Redshift V2. Terakhir, kami menggunakan Amazon QuickSight untuk mendapatkan wawasan tentang data yang dimodelkan dalam bentuk dasbor QuickSight.
Untuk solusi ini, kami menggunakan kumpulan data sampel (dinormalisasi) yang disediakan oleh Amazon Redshift untuk penjualan tiket acara. Untuk posting ini, kami telah mempersempit kumpulan data untuk tujuan kesederhanaan dan demonstrasi. Tabel berikut menampilkan contoh data penjualan tiket dan venue.


Menurut Metodologi pemodelan dimensi Kimball, ada empat langkah kunci dalam mendesain model dimensi:
- Mengidentifikasi proses bisnis.
- Nyatakan butiran data Anda.
- Mengidentifikasi dan menerapkan dimensi.
- Mengidentifikasi dan menerapkan fakta.
Selain itu, kami menambahkan langkah kelima untuk tujuan demonstrasi, yaitu melaporkan dan menganalisis peristiwa bisnis.
Prasyarat
Untuk penelusuran ini, Anda harus memiliki prasyarat berikut:
Mengidentifikasi proses bisnis
Secara sederhana, mengidentifikasi proses bisnis adalah mengidentifikasi peristiwa terukur yang menghasilkan data dalam suatu organisasi. Biasanya, perusahaan memiliki semacam sistem sumber operasional yang menghasilkan data mereka dalam format mentahnya. Ini adalah titik awal yang baik untuk mengidentifikasi berbagai sumber untuk proses bisnis.
Proses bisnis kemudian bertahan sebagai a data mart dalam bentuk dimensi dan fakta. Melihat kumpulan data sampel kami yang disebutkan sebelumnya, kami dapat dengan jelas melihat proses bisnis adalah penjualan yang dilakukan untuk acara tertentu.
Kesalahan umum yang dilakukan adalah menggunakan departemen perusahaan sebagai proses bisnis. Data (proses bisnis) perlu diintegrasikan di berbagai departemen, dalam hal ini pemasaran dapat mengakses data penjualan. Mengidentifikasi proses bisnis yang benar sangatlah penting—salah langkah ini dapat berdampak pada seluruh data mart (dapat menyebabkan butir diduplikasi dan metrik yang salah pada laporan akhir).
Nyatakan butiran data Anda
Mendeklarasikan grain adalah tindakan mengidentifikasi record secara unik di sumber data Anda. Grain digunakan dalam tabel fakta untuk mengukur data secara akurat dan memungkinkan Anda untuk menggulung lebih jauh. Dalam contoh kami, ini bisa menjadi item baris dalam proses bisnis penjualan.
Dalam kasus penggunaan kami, penjualan dapat diidentifikasi secara unik dengan melihat waktu transaksi saat penjualan terjadi; ini akan menjadi level paling atomik.

Mengidentifikasi dan menerapkan dimensi
Tabel dimensi Anda menjelaskan tabel fakta Anda dan atributnya. Saat mengidentifikasi konteks deskriptif dari proses bisnis Anda, Anda menyimpan teks dalam tabel terpisah, dengan mengingat butir tabel fakta. Saat menggabungkan tabel dimensi ke tabel fakta, seharusnya hanya ada satu baris yang terkait dengan tabel fakta. Dalam contoh kami, kami menggunakan tabel berikut untuk dipisahkan menjadi tabel dimensi; bidang ini menggambarkan fakta yang akan kita ukur.
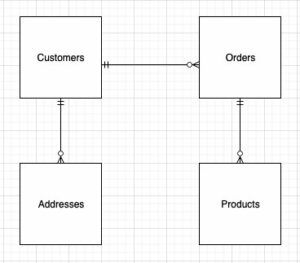
Saat mendesain struktur model dimensi (skema), Anda dapat membuat a star or kepingan salju skema. Struktur harus selaras dengan proses bisnis; oleh karena itu, skema bintang paling cocok untuk contoh kita. Gambar berikut menunjukkan Entity Relationship Diagram (ERD) kami.

Di bagian berikut, kami merinci langkah-langkah untuk mengimplementasikan dimensi.
Panggung data sumber
Sebelum kita dapat membuat dan memuat tabel dimensi, kita memerlukan data sumber. Oleh karena itu, kami menyusun data sumber ke dalam tabel pementasan atau sementara. Ini sering disebut sebagai lapisan pementasan, yang merupakan salinan mentah dari data sumber. Untuk melakukan ini di Amazon Redshift, kami menggunakan perintah SALIN untuk memuat data dari bucket S3 publik dimensional-modeling-in-amazon-redshift yang terletak di us-east-1 Wilayah. Perhatikan bahwa perintah COPY menggunakan Identitas AWS dan Manajemen Akses (IAM) peran dengan akses ke Amazon S3. Peran itu perlu terkait dengan klaster. Selesaikan langkah-langkah berikut untuk menyusun data sumber:
- Buat
venuetabel sumber:
- Muat data tempat:
- Buat
salestabel sumber:
- Muat data sumber penjualan:
- Buat
calendarmeja:
- Muat data kalender:
Buat tabel dimensi
Mendesain tabel dimensi dapat bergantung pada kebutuhan bisnis Anda—misalnya, apakah Anda perlu melacak perubahan data dari waktu ke waktu? Ada tujuh jenis dimensi yang berbeda. Sebagai contoh kami, kami menggunakan Jenis 1 karena kita tidak perlu melacak perubahan historis. Untuk informasi lebih lanjut tentang tipe 2, lihat Sederhanakan pemuatan data ke dalam dimensi Tipe 2 yang perlahan berubah di Amazon Redshift. Tabel dimensi akan didenormalisasi dengan kunci utama, kunci pengganti, dan beberapa bidang tambahan untuk menunjukkan perubahan pada tabel. Lihat kode berikut:
Beberapa catatan tentang membuat pembuatan tabel dimensi:
- Nama bidang diubah menjadi nama ramah bisnis
- Kunci utama kami adalah
VenueID, yang kami gunakan untuk mengidentifikasi secara unik tempat penjualan berlangsung - Dua baris tambahan akan ditambahkan, menunjukkan kapan record dimasukkan dan diperbarui (untuk melacak perubahan)
- Kami menggunakan sebuah Gaya distribusi OTOMATIS untuk memberi Amazon Redshift tanggung jawab untuk memilih dan menyesuaikan gaya distribusi
Faktor penting lain yang perlu dipertimbangkan dalam pemodelan dimensi adalah penggunaan kunci pengganti. Kunci pengganti adalah kunci buatan yang digunakan dalam pemodelan dimensi untuk secara unik mengidentifikasi setiap record dalam tabel dimensi. Mereka biasanya dihasilkan sebagai bilangan bulat berurutan, dan tidak memiliki arti apa pun dalam domain bisnis. Mereka menawarkan beberapa keuntungan, seperti memastikan keunikan dan meningkatkan kinerja dalam gabungan, karena mereka biasanya lebih kecil dari kunci alami dan sebagai kunci pengganti mereka tidak berubah dari waktu ke waktu. Ini memungkinkan kita untuk konsisten dan menggabungkan fakta dan dimensi dengan lebih mudah.
Di Amazon Redshift, kunci pengganti biasanya dibuat menggunakan kata kunci IDENTITY. Misalnya, pernyataan CREATE sebelumnya membuat tabel dimensi dengan a VenueSkey kunci pengganti. Itu VenueSkey kolom diisi secara otomatis dengan nilai unik saat baris baru ditambahkan ke tabel. Kolom ini kemudian dapat digunakan untuk menggabungkan tabel venue ke FactSaleTransactions tabel.
Beberapa tip untuk merancang kunci pengganti:
- Gunakan tipe data kecil dengan lebar tetap untuk kunci pengganti. Ini akan meningkatkan kinerja dan mengurangi ruang penyimpanan.
- Gunakan kata kunci IDENTITAS, atau buat kunci pengganti menggunakan nilai berurutan atau GUID. Ini akan memastikan bahwa kunci pengganti itu unik dan tidak dapat diubah.
Muat tabel redup menggunakan MERGE
Ada banyak cara untuk memuat meja redup Anda. Faktor-faktor tertentu perlu dipertimbangkan—misalnya, performa, volume data, dan mungkin waktu pemuatan SLA. Dengan MENGGABUNGKAN pernyataan, kami melakukan upsert tanpa perlu menentukan beberapa perintah insert dan update. Anda dapat mengatur MENGGABUNGKAN pernyataan dalam a prosedur tersimpan untuk mengisi data. Anda kemudian menjadwalkan stored procedure untuk dijalankan secara terprogram melalui editor kueri, yang akan kami tunjukkan nanti di postingan. Kode berikut membuat prosedur tersimpan yang disebut SalesMart.DimVenueLoad:
Beberapa catatan tentang pemuatan dimensi:
- Saat record dimasukkan untuk pertama kalinya, tanggal yang dimasukkan dan tanggal yang diperbarui akan diisi. Ketika nilai apa pun berubah, data diperbarui dan tanggal yang diperbarui mencerminkan tanggal ketika diubah. Tanggal yang dimasukkan tetap ada.
- Karena data akan digunakan oleh pengguna bisnis, kita perlu mengganti nilai NULL, jika ada, dengan nilai yang lebih sesuai untuk bisnis.
Mengidentifikasi dan menerapkan fakta
Sekarang kita telah menyatakan biji-bijian kita sebagai peristiwa penjualan yang terjadi pada waktu tertentu, tabel fakta kita akan menyimpan fakta numerik untuk proses bisnis kita.
Kami telah mengidentifikasi fakta numerik berikut untuk diukur:
- Jumlah tiket yang terjual per penjualan
- Komisi untuk penjualan
Menerapkan Fakta
Ada tiga jenis tabel fakta (tabel fakta transaksi, tabel fakta snapshot periodik, dan tabel fakta snapshot terakumulasi). Masing-masing melayani pandangan yang berbeda dari proses bisnis. Sebagai contoh, kami menggunakan tabel fakta transaksi. Selesaikan langkah-langkah berikut:
- Buat tabel fakta
Tanggal yang disisipkan dengan nilai default ditambahkan, menunjukkan jika dan kapan record dimuat. Anda dapat menggunakan ini saat memuat ulang tabel fakta untuk menghapus data yang sudah dimuat untuk menghindari duplikat.
Memuat tabel fakta terdiri dari pernyataan sisipan sederhana yang menggabungkan dimensi Anda yang terkait. Kami bergabung dari DimVenue tabel yang dibuat, yang menggambarkan fakta-fakta kami. Ini praktik terbaik tetapi opsional untuk dimiliki tanggal kalender dimensi, yang memungkinkan pengguna akhir untuk menavigasi tabel fakta. Data dapat dimuat saat ada obral baru, atau setiap hari; di sinilah tanggal yang dimasukkan atau tanggal pemuatan berguna.
Kami memuat tabel fakta menggunakan prosedur tersimpan dan menggunakan parameter tanggal.
- Buat stored procedure dengan kode berikut. Untuk menjaga integritas data yang sama dengan yang kami terapkan dalam pemuatan dimensi, kami mengganti nilai NULL, jika ada, dengan nilai bisnis yang lebih sesuai:
- Muat data dengan memanggil prosedur dengan perintah berikut:
Jadwalkan pemuatan data
Kami sekarang dapat mengotomatiskan proses pemodelan dengan menjadwalkan prosedur tersimpan di Amazon Redshift Query Editor V2. Selesaikan langkah-langkah berikut:
- Kami pertama kali memanggil beban dimensi dan setelah beban dimensi berjalan dengan sukses, beban fakta dimulai:
Jika pemuatan dimensi gagal, pemuatan fakta tidak akan berjalan. Hal ini memastikan konsistensi dalam data karena kita tidak ingin memuat tabel fakta dengan dimensi yang kedaluwarsa.
- Untuk menjadwalkan pemuatan, pilih Susunan acara di Editor Kueri V2.

- Kami menjadwalkan kueri untuk dijalankan setiap hari pada pukul 5.
- Secara opsional, Anda dapat menambahkan notifikasi kegagalan dengan mengaktifkan Layanan Pemberitahuan Sederhana Amazon Notifikasi (Amazon SNS).

Laporkan dan analisis data di Amazon Quicksight
QuickSight adalah layanan intelijen bisnis yang memudahkan penyampaian wawasan. Sebagai layanan yang dikelola sepenuhnya, QuickSight memungkinkan Anda dengan mudah membuat dan menerbitkan dasbor interaktif yang kemudian dapat diakses dari perangkat apa pun dan disematkan ke dalam aplikasi, portal, dan situs web Anda.
Kami menggunakan data mart kami untuk menyajikan fakta secara visual dalam bentuk dasbor. Untuk memulai dan menyiapkan QuickSight, lihat Membuat kumpulan data menggunakan database yang tidak ditemukan secara otomatis.
Setelah Anda membuat sumber data di QuickSight, kami menggabungkan data model (data mart) bersama-sama berdasarkan kunci pengganti kami skey. Kami menggunakan kumpulan data ini untuk memvisualisasikan data mart.

Dasbor akhir kami akan berisi wawasan tentang data mart dan menjawab pertanyaan bisnis penting, seperti total komisi per tempat dan tanggal dengan penjualan tertinggi. Tangkapan layar berikut menunjukkan produk akhir dari data mart.

Membersihkan
Untuk menghindari timbulnya biaya di masa mendatang, hapus sumber daya apa pun yang Anda buat sebagai bagian dari pos ini.
Kesimpulan
Kami sekarang telah berhasil mengimplementasikan data mart menggunakan DimVenue, DimCalendar, dan FactSaleTransactions tabel. Gudang kami tidak lengkap; karena kami dapat memperluas data mart dengan lebih banyak fakta dan mengimplementasikan lebih banyak mart, dan seiring dengan pertumbuhan proses dan persyaratan bisnis dari waktu ke waktu, gudang data juga akan berkembang. Dalam postingan ini, kami memberikan pandangan menyeluruh tentang pemahaman dan penerapan pemodelan dimensi di Amazon Redshift.
Mulailah dengan Anda Pergeseran Merah Amazon model dimensi hari ini.
Tentang Penulis
 Bernard Verster adalah insinyur cloud berpengalaman dengan pengalaman bertahun-tahun dalam menciptakan model data yang dapat diskalakan dan efisien, menentukan strategi integrasi data, dan memastikan tata kelola dan keamanan data. Dia bersemangat menggunakan data untuk mendorong wawasan, sambil menyelaraskan dengan persyaratan dan tujuan bisnis.
Bernard Verster adalah insinyur cloud berpengalaman dengan pengalaman bertahun-tahun dalam menciptakan model data yang dapat diskalakan dan efisien, menentukan strategi integrasi data, dan memastikan tata kelola dan keamanan data. Dia bersemangat menggunakan data untuk mendorong wawasan, sambil menyelaraskan dengan persyaratan dan tujuan bisnis.
 Abhisek Pan adalah Spesialis SA-Analytics WWSO yang bekerja dengan pelanggan sektor Publik AWS India. Dia terlibat dengan pelanggan untuk menentukan strategi berbasis data, memberikan sesi mendalam tentang kasus penggunaan analitik, dan merancang aplikasi analitik yang dapat diskalakan dan berperforma baik. Dia memiliki 12 tahun pengalaman dan sangat tertarik dengan database, analitik, dan AI/ML. Dia adalah seorang pengelana yang rajin dan mencoba mengabadikan dunia melalui lensa kameranya.
Abhisek Pan adalah Spesialis SA-Analytics WWSO yang bekerja dengan pelanggan sektor Publik AWS India. Dia terlibat dengan pelanggan untuk menentukan strategi berbasis data, memberikan sesi mendalam tentang kasus penggunaan analitik, dan merancang aplikasi analitik yang dapat diskalakan dan berperforma baik. Dia memiliki 12 tahun pengalaman dan sangat tertarik dengan database, analitik, dan AI/ML. Dia adalah seorang pengelana yang rajin dan mencoba mengabadikan dunia melalui lensa kameranya.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Otomotif / EV, Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- BlockOffset. Modernisasi Kepemilikan Offset Lingkungan. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Tentang Kami
- mempercepat
- mengakses
- diakses
- akurat
- di seluruh
- Bertindak
- menambahkan
- menambahkan
- Tambahan
- Setelah
- AI / ML
- meluruskan
- yang sejalan
- mengizinkan
- memungkinkan
- sudah
- am
- Amazon
- Amazon Web Services
- an
- analisis
- Analytical
- analisis
- menganalisa
- dan
- menjawab
- Apa pun
- aplikasi
- terapan
- sesuai
- arsitektur
- ADALAH
- buatan
- AS
- aspek
- terkait
- At
- atribut
- mobil
- mengotomatisasikan
- secara otomatis
- menghindari
- AWS
- b
- berdasarkan
- BE
- karena
- mulai
- Manfaat
- TERBAIK
- built-in
- bisnis
- intelijen bisnis
- Proses bisnis
- proses bisnis
- tapi
- by
- Kalender
- panggilan
- bernama
- panggilan
- kamar
- CAN
- menangkap
- kasus
- kasus
- Menyebabkan
- tertentu
- perubahan
- berubah
- Perubahan
- mengubah
- karakter
- beban
- Pilih
- jelas
- Jelas
- rapat
- awan
- kode
- Kolom
- datang
- Komisi
- Umum
- Perusahaan
- perusahaan
- lengkap
- Mempertimbangkan
- konsisten
- terdiri
- konteks
- benar
- bisa
- membuat
- dibuat
- menciptakan
- membuat
- penciptaan
- kritis
- pelanggan
- harian
- dasbor
- dasbor
- data
- integrasi data
- Danau Data
- data warehouse
- Data-driven
- Strategi Berbasis Data
- Basis Data
- database
- Tanggal
- Tanggal
- tanggal Waktu
- hari
- mendalam
- menyelam dalam
- Default
- mendefinisikan
- menyampaikan
- mendemonstrasikan
- departemen
- Berasal
- menggambarkan
- Mendesain
- merancang
- rinci
- alat
- berbeda
- Dimensi
- ukuran
- membahas
- berbeda
- distribusi
- do
- domain
- dilakukan
- Dont
- turun
- mendorong
- duplikat
- setiap
- Terdahulu
- mudah
- Mudah
- editor
- efisien
- antara
- tertanam
- aktif
- memungkinkan
- akhir
- ujung ke ujung
- terlibat
- insinyur
- memastikan
- Memastikan
- memastikan
- Seluruh
- entitas
- Eter (ETH)
- Acara
- peristiwa
- Setiap
- setiap hari
- contoh
- contoh
- Lihat lebih lanjut
- pengalaman
- berpengalaman
- Pencahayaan
- ekstrak
- fakta
- faktor
- faktor
- fakta
- gagal
- Kegagalan
- Fitur
- beberapa
- bidang
- Fields
- kelima
- Angka
- menyaring
- terakhir
- Pertama
- pertama kali
- cocok
- terfokus
- berikut
- Untuk
- bentuk
- format
- empat
- dari
- sepenuhnya
- lebih lanjut
- masa depan
- Mendapatkan
- menghasilkan
- dihasilkan
- menghasilkan
- mendapatkan
- mendapatkan
- Memberikan
- diberikan
- baik
- pemerintahan
- Tumbuh
- berguna
- Memiliki
- he
- paling tinggi
- -nya
- historis
- Liburan
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- http
- HTTPS
- IAM
- diidentifikasi
- mengenali
- mengidentifikasi
- identitas
- if
- menggambarkan
- Dampak
- melaksanakan
- diimplementasikan
- mengimplementasikan
- penting
- memperbaiki
- meningkatkan
- in
- Termasuk
- India
- menunjukkan
- Menunjukkan
- Info
- wawasan
- terpadu
- integrasi
- integritas
- Intelijen
- interaktif
- ke
- IT
- NYA
- ikut
- bergabung
- bergabung
- Bergabung
- jpg
- Menjaga
- pemeliharaan
- kunci
- kunci-kunci
- danau
- bahasa
- kemudian
- Terbaru
- lapisan
- meninggalkan
- lensa
- Lets
- Tingkat
- baris
- memuat
- pemuatan
- beban
- terletak
- mencari
- terbuat
- MEMBUAT
- berhasil
- Marketing
- cocok
- makna
- mengukur
- tersebut
- Bergabung
- Metrik
- keberatan
- kesalahan
- model
- pemodelan
- pemodelan
- model
- Bulan
- lebih
- paling
- beberapa
- nama
- Alam
- Arahkan
- Perlu
- membutuhkan
- kebutuhan
- New
- Catatan
- pemberitahuan
- pemberitahuan
- sekarang
- banyak sekali
- target
- of
- menawarkan
- sering
- on
- hanya
- operasional
- or
- organisasi
- kami
- lebih
- secara keseluruhan
- parameter
- bagian
- bergairah
- untuk
- melakukan
- prestasi
- mungkin
- berkala
- Tempat
- plato
- Kecerdasan Data Plato
- Data Plato
- Titik
- diisi
- Pos
- kekuasaan
- praktek
- prasyarat
- menyajikan
- primer
- Prosedur
- Prosedur
- proses
- proses
- Produk
- memberikan
- disediakan
- menyediakan
- publik
- menerbitkan
- tujuan
- Pertanyaan
- segera
- menaikkan
- Mentah
- data mentah
- catatan
- arsip
- menurunkan
- disebut
- mencerminkan
- wilayah
- hubungan
- sisa
- menghapus
- menggantikan
- melaporkan
- Pelaporan
- laporan
- Persyaratan
- Sumber
- tanggung jawab
- Peran
- Menggulung
- BARIS
- Run
- berjalan
- penjualan
- penjualan
- sama
- Contoh kumpulan data
- terukur
- menjadwalkan
- penjadwalan
- bagian
- sektor
- keamanan
- melihat
- terpisah
- melayani
- layanan
- Layanan
- sesi
- set
- beberapa
- harus
- Menunjukkan
- Pertunjukkan
- Sederhana
- kesederhanaan
- tunggal
- Perlahan
- kecil
- lebih kecil
- Potret
- So
- terjual
- larutan
- beberapa
- sumber
- sumber
- Space
- spesialis
- tertentu
- Secara khusus
- Tahap
- pementasan
- Bintang
- mulai
- Mulai
- Pernyataan
- Langkah
- Tangga
- penyimpanan
- menyimpan
- tersimpan
- strategi
- Penyelarasan
- struktur
- sukses
- berhasil
- seperti itu
- sistem
- tabel
- sementara
- memiliki
- istilah
- dari
- bahwa
- Grafik
- Sumber
- Dunia
- mereka
- kemudian
- Sana.
- karena itu
- Ini
- mereka
- ini
- ribuan
- Melalui
- tiket
- penjualan tiket
- tiket
- waktu
- kali
- timestamp
- Tips
- untuk
- hari ini
- bersama
- mengambil
- Total
- jalur
- .
- Mengubah
- berubah
- wisatawan
- mengetik
- jenis
- khas
- pemahaman
- unik
- unik
- keunikan
- tidak dikenal
- Memperbarui
- diperbarui
- us
- penggunaan
- menggunakan
- gunakan case
- bekas
- Pengguna
- kegunaan
- menggunakan
- biasanya
- Berharga
- nilai
- Nilai - Nilai
- berbagai
- Venue
- keadaan-keadaan
- melalui
- View
- volume
- walkthrough
- ingin
- Gudang
- adalah
- cara
- we
- jaringan
- layanan web
- situs web
- minggu
- ketika
- yang
- sementara
- akan
- dengan
- dalam
- tanpa
- kerja
- dunia
- Salah
- tahun
- tahun
- kamu
- Anda
- zephyrnet.dll