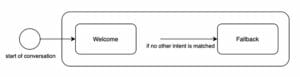
Gambar 1: Representasi aliran Text2SQL
Karena dunia kita semakin global dan dinamis, bisnis semakin bergantung pada data untuk membuat keputusan yang terinformasi, objektif, dan tepat waktu. Namun, untuk saat ini, mengeluarkan potensi penuh dari data organisasi seringkali merupakan hak istimewa segelintir ilmuwan dan analis data. Sebagian besar karyawan tidak menguasai perangkat ilmu data konvensional (SQL, Python, R, dll.). Untuk mengakses data yang diinginkan, mereka melalui lapisan tambahan di mana analis atau tim BI “menerjemahkan” prosa pertanyaan bisnis ke dalam bahasa data. Potensi friksi dan inefisiensi dalam perjalanan ini tinggi — misalnya, data mungkin dikirimkan dengan penundaan atau bahkan ketika pertanyaan sudah usang. Informasi mungkin akan hilang saat persyaratan tidak diterjemahkan secara akurat ke dalam kueri analitik. Selain itu, menghasilkan wawasan berkualitas tinggi memerlukan pendekatan berulang yang tidak disarankan dengan setiap langkah tambahan dalam lingkaran. Di sisi lain, interaksi ad-hoc ini menciptakan gangguan bagi talenta data yang mahal dan mengalihkan perhatian mereka dari pekerjaan data yang lebih strategis, seperti yang dijelaskan dalam “pengakuan” ilmuwan data berikut:
Ketika saya berada di Square dan tim lebih kecil, kami memiliki rotasi "on-call analitik" yang ditakuti. Itu dirotasi secara ketat setiap minggu, dan jika itu adalah giliran Anda, Anda tahu Anda akan menyelesaikan sangat sedikit pekerjaan "nyata" minggu itu dan menghabiskan sebagian besar waktu Anda menjawab pertanyaan ad-hoc dari berbagai tim produk dan operasi di perusahaan (SQL monkeying, kami menyebutnya). Ada persaingan ketat untuk peran manajer di tim analitik dan saya pikir ini sepenuhnya hasil dari pengecualian manajer dari rotasi ini — tidak ada hadiah status yang dapat menandingi wortel karena tidak melakukan pekerjaan sesuai panggilan.[1]
Memang, bukankah keren untuk berbicara langsung dengan data Anda daripada harus melalui beberapa putaran interaksi dengan staf data Anda? Visi ini dianut oleh antarmuka percakapan yang memungkinkan manusia berinteraksi dengan data menggunakan bahasa, saluran komunikasi kita yang paling intuitif dan universal. Setelah menguraikan pertanyaan, algoritme mengkodekannya menjadi bentuk logis terstruktur dalam bahasa kueri pilihan, seperti SQL. Dengan demikian, pengguna non-teknis dapat mengobrol dengan data mereka dan dengan cepat mendapatkan informasi yang spesifik, relevan, dan tepat waktu, tanpa harus memutar melalui tim BI. Pada artikel ini, kami akan mempertimbangkan aspek implementasi Text2SQL yang berbeda dan fokus pada pendekatan modern dengan penggunaan Large Language Models (LLMs), yang mencapai kinerja terbaik saat ini (lih. [2]; untuk survei atas pendekatan alternatif di luar LLM, pembaca dirujuk [3]). Artikel ini disusun berdasarkan "model mental" berikut dari elemen utama yang perlu dipertimbangkan saat merencanakan dan membangun fitur AI:

Mari kita mulai dengan mengingat akhir dan merangkum nilainya — alasan Anda membuat fitur Text2SQL ke dalam produk data atau analitik Anda. Tiga manfaat utama adalah:
- Pengguna bisnis dapat mengakses data organisasi secara langsung dan tepat waktu.
- Ini melegakan ilmuwan data dan analis dari beban permintaan ad-hoc dari pengguna bisnis dan memungkinkan mereka untuk fokus pada tantangan data tingkat lanjut.
- Ini memungkinkan bisnis untuk memanfaatkan datanya dengan cara yang lebih cair dan strategis, akhirnya mengubahnya menjadi dasar yang kokoh untuk pengambilan keputusan.
Sekarang, skenario produk apa yang mungkin Anda pertimbangkan untuk Text2SQL? Tiga pengaturan utama adalah:
- Anda menawarkan a data yang dapat diskalakan/produk BI dan ingin memungkinkan lebih banyak pengguna untuk mengakses data mereka dengan cara non-teknis, sehingga meningkatkan penggunaan dan basis pengguna. Sebagai contoh, ServiceNow punya mengintegrasikan kueri data ke dalam penawaran percakapan yang lebih besar, dan Atlan baru-baru ini mengumumkan eksplorasi data bahasa alami.
- Anda ingin membangun sesuatu di ruang data/AI untuk mendemokratisasi akses data di perusahaan, dalam hal ini Anda berpotensi mempertimbangkan MVP dengan Text2SQL sebagai intinya. Penyedia suka AI2SQL dan Text2sql.ai sudah membuat pintu masuk di ruang ini.
- Anda sedang mengerjakan a sistem BI khusus dan ingin memaksimalkan dan mendemokratisasi penggunaannya di masing-masing perusahaan.
Seperti yang akan kita lihat di bagian berikut, Text2SQL memerlukan penyiapan awal yang tidak sepele. Untuk memperkirakan ROI, pertimbangkan sifat keputusan yang akan didukung serta data yang tersedia. Text2SQL dapat menjadi kemenangan mutlak dalam lingkungan dinamis di mana data berubah dengan cepat dan secara aktif serta sering digunakan dalam pengambilan keputusan, seperti investasi, pemasaran, manufaktur, dan industri energi. Dalam lingkungan ini, alat tradisional untuk manajemen pengetahuan terlalu statis, dan cara yang lebih lancar untuk mengakses data dan informasi membantu perusahaan menghasilkan keunggulan kompetitif. Dari segi data, Text2SQL memberikan nilai terbesar dengan database yaitu:
- Besar dan berkembang, sehingga Text2SQL dapat mengungkapkan nilainya dari waktu ke waktu karena semakin banyak data yang dimanfaatkan.
- Berkualitas tinggi, sehingga algoritme Text2SQL tidak harus berurusan dengan noise yang berlebihan (inkonsistensi, nilai kosong, dll.) dalam data. Secara umum, data yang dibuat secara otomatis oleh aplikasi memiliki kualitas dan konsistensi yang lebih tinggi daripada data yang dibuat dan dikelola oleh manusia.
- Dewasa secara semantik sebagai kebalikan dari mentah, sehingga manusia dapat menanyakan data berdasarkan konsep sentral, hubungan, dan metrik yang ada dalam model mental mereka. Perhatikan bahwa kematangan semantik dapat dicapai dengan langkah transformasi tambahan yang menyesuaikan data mentah ke dalam struktur konseptual (lih. bagian "Memperkaya prompt dengan informasi basis data").
Berikut ini, kami akan mendalami data, algoritme, pengalaman pengguna, serta persyaratan non-fungsional yang relevan dari fitur Text2SQL. Artikel ini ditulis untuk manajer produk, desainer UX, dan para ilmuwan dan insinyur data yang berada di awal perjalanan Text2SQL mereka. Bagi orang-orang ini, ini tidak hanya memberikan panduan untuk memulai, tetapi juga landasan pengetahuan bersama untuk diskusi seputar antarmuka antara produk, teknologi, dan bisnis, termasuk pertukaran terkait. Jika Anda sudah lebih mahir dalam implementasi, referensi di bagian akhir memberikan berbagai penyelaman mendalam untuk dijelajahi.
Jika konten pendidikan yang mendalam ini bermanfaat bagi Anda, Anda bisa berlangganan milis penelitian AI kami untuk diperingatkan ketika kami merilis materi baru.
1. Data
Setiap upaya pembelajaran mesin dimulai dengan data, jadi kami akan mulai dengan mengklarifikasi struktur input dan data target yang digunakan selama pelatihan dan prediksi. Sepanjang artikel, kami akan menggunakan aliran Text2SQL dari Gambar 1 sebagai representasi kami yang sedang berjalan, dan menyoroti komponen dan hubungan yang saat ini dipertimbangkan dengan warna kuning.

1.1 Format dan struktur data
Biasanya, pasangan input-output Text2SQL mentah terdiri dari pertanyaan bahasa alami dan kueri SQL yang sesuai, misalnya:
Pertanyaan: "Cantumkan nama dan jumlah pengikut untuk setiap pengguna.”
Permintaan SQL:
pilih nama, pengikut dari profil_pengguna
Di ruang data pelatihan, pemetaan antara pertanyaan dan kueri SQL adalah banyak-ke-banyak:
- Permintaan SQL dapat dipetakan ke banyak pertanyaan berbeda dalam bahasa alami; misalnya, semantik kueri di atas dapat diekspresikan dengan: “tunjukkan nama dan jumlah pengikut per pengguna","berapa banyak pengikut yang ada untuk setiap pengguna?"Dll.
- Sintaks SQL sangat serbaguna, dan hampir setiap pertanyaan dapat direpresentasikan dalam SQL dalam berbagai cara. Contoh paling sederhana adalah urutan klausa WHERE yang berbeda. Pada sikap yang lebih maju, setiap orang yang telah melakukan pengoptimalan kueri SQL akan tahu bahwa banyak jalan mengarah ke hasil yang sama, dan kueri yang setara secara semantik mungkin memiliki sintaks yang sama sekali berbeda.
Pengumpulan manual data pelatihan untuk Text2SQL sangat membosankan. Ini tidak hanya membutuhkan penguasaan SQL di pihak annotator, tetapi juga lebih banyak waktu per contoh daripada tugas linguistik yang lebih umum seperti analisis sentimen dan klasifikasi teks. Untuk memastikan jumlah contoh pelatihan yang memadai, augmentasi data dapat digunakan — misalnya, LLM dapat digunakan untuk menghasilkan parafrase untuk pertanyaan yang sama. [3] memberikan survei yang lebih lengkap tentang teknik augmentasi data Text2SQL.
1.2 Memperkaya prompt dengan informasi database
Text2SQL adalah algoritme pada antarmuka antara data tidak terstruktur dan terstruktur. Untuk kinerja optimal, kedua jenis data tersebut harus ada selama pelatihan dan prediksi. Secara khusus, algoritme harus mengetahui tentang basis data yang diminta dan dapat merumuskan kueri sedemikian rupa sehingga dapat dieksekusi terhadap basis data. Pengetahuan ini dapat meliputi:
- Kolom dan tabel database
- Relasi antar tabel (kunci asing)
- Konten basis data
Ada dua opsi untuk menggabungkan pengetahuan basis data: di satu sisi, data pelatihan dapat dibatasi pada contoh yang ditulis untuk basis data tertentu, dalam hal ini skema dipelajari langsung dari kueri SQL dan pemetaannya ke pertanyaan. Pengaturan database tunggal ini memungkinkan untuk mengoptimalkan algoritme untuk database individual dan/atau perusahaan. Namun, ini menghilangkan ambisi untuk skalabilitas, karena model perlu disesuaikan untuk setiap pelanggan atau database. Alternatifnya, dalam pengaturan multi-database, skema database dapat disediakan sebagai bagian dari input, yang memungkinkan algoritme untuk "menggeneralisasi" ke skema database baru yang tidak terlihat. Meskipun Anda benar-benar harus menggunakan pendekatan ini jika Anda ingin menggunakan Text2SQL pada banyak database yang berbeda, perlu diingat bahwa ini memerlukan upaya rekayasa yang cepat. Untuk basis data bisnis apa pun yang masuk akal, memasukkan informasi lengkap dalam prompt akan sangat tidak efisien dan kemungkinan besar tidak mungkin karena keterbatasan panjang prompt. Dengan demikian, fungsi yang bertanggung jawab untuk formulasi prompt harus cukup pintar untuk memilih subset informasi database yang paling "berguna" untuk pertanyaan yang diberikan, dan melakukan ini untuk database yang berpotensi tidak terlihat.
Akhirnya, struktur database memainkan peran penting. Dalam skenario di mana Anda memiliki kontrol yang cukup atas database, Anda dapat membuat hidup model Anda lebih mudah dengan membiarkannya belajar dari struktur intuitif. Sebagai aturan praktis, semakin database Anda mencerminkan bagaimana pengguna bisnis berbicara tentang bisnis, semakin baik dan lebih cepat model Anda dapat belajar darinya. Oleh karena itu, pertimbangkan untuk menerapkan transformasi tambahan pada data, seperti menyusun data yang dinormalisasi atau tersebar ke dalam tabel lebar atau gudang data, menamai tabel dan kolom dengan cara yang eksplisit dan tidak ambigu, dll. Semua pengetahuan bisnis yang dapat Anda enkode di awal akan berkurang beban pembelajaran probabilistik pada model Anda dan membantu Anda mencapai hasil yang lebih baik.
2. algoritma

Text2SQL adalah salah satu jenis penguraian semantik — pemetaan teks ke representasi logis. Dengan demikian, algoritme tidak hanya harus "mempelajari" bahasa alami, tetapi juga representasi target — dalam kasus kita, SQL. Secara khusus, ia harus memperoleh dan beberapa pengetahuan berikut:
- Sintaks dan semantik SQL
- Struktur basis data
- Pemahaman Bahasa Alami (NLU)
- Pemetaan antara bahasa alami dan kueri SQL (sintaksis, leksikal, dan semantik)
2.1 Memecahkan variabilitas linguistik dalam masukan
Pada input, tantangan utama Text2SQL terletak pada fleksibilitas bahasa: seperti yang dijelaskan di bagian Format dan struktur data, pertanyaan yang sama dapat diparafrasekan dengan berbagai cara. Selain itu, dalam konteks percakapan kehidupan nyata, kita harus berurusan dengan sejumlah masalah seperti kesalahan ejaan dan tata bahasa, input yang tidak lengkap dan ambigu, input multibahasa, dll.

LLM seperti model GPT, T5, dan CodeX semakin dekat untuk menyelesaikan tantangan ini. Belajar dari sejumlah besar teks yang beragam, mereka belajar menghadapi sejumlah besar pola dan ketidakteraturan linguistik. Pada akhirnya, mereka mampu menggeneralisasi pertanyaan-pertanyaan yang secara semantik serupa meskipun memiliki bentuk permukaan yang berbeda. LLM dapat diterapkan out-of-the-box (zero-shot) atau setelah fine-tuning. Yang pertama, meski nyaman, mengarah pada akurasi yang lebih rendah. Yang terakhir membutuhkan lebih banyak keterampilan dan kerja, tetapi dapat meningkatkan akurasi secara signifikan.
Dalam hal akurasi, seperti yang diharapkan, model dengan performa terbaik adalah model terbaru dari keluarga GPT termasuk model CodeX. Pada bulan April 2023, GPT-4 menyebabkan peningkatan akurasi dramatis lebih dari 5% dibandingkan dengan state-of-the-art sebelumnya dan mencapai akurasi 85.3% (pada metrik “eksekusi dengan nilai”).[4] Di kamp sumber terbuka, upaya awal untuk memecahkan teka-teki Text2SQL difokuskan pada model penyandian otomatis seperti BERT, yang unggul dalam tugas NLU. [5, 6, 7] Namun, di tengah hype seputar AI generatif, fokus pendekatan terbaru pada model autoregresif seperti model T5. T5 dilatih sebelumnya menggunakan pembelajaran multi-tugas dan dengan demikian mudah beradaptasi dengan tugas linguistik baru, termasuk. varian yang berbeda dari parsing semantik. Namun, model autoregresif memiliki kelemahan intrinsik dalam hal tugas penguraian semantik: mereka memiliki ruang keluaran yang tidak dibatasi dan tidak ada pagar pembatas semantik yang akan membatasi keluarannya, yang berarti mereka dapat menjadi sangat kreatif dalam perilakunya. Meskipun ini adalah hal yang luar biasa untuk menghasilkan konten bentuk bebas, ini merupakan gangguan untuk tugas seperti Text2SQL di mana kami mengharapkan output target yang terstruktur dengan baik.
2.2 Validasi dan peningkatan kueri
Untuk membatasi keluaran LLM, kami dapat memperkenalkan mekanisme tambahan untuk memvalidasi dan meningkatkan kueri. Hal ini dapat diterapkan sebagai langkah validasi ekstra, seperti yang diusulkan dalam sistem PICARD.[8] PICARD menggunakan parser SQL yang dapat memverifikasi apakah sebagian kueri SQL dapat menghasilkan kueri SQL yang valid setelah selesai. Pada setiap langkah pembuatan oleh LLM, token yang akan membatalkan kueri ditolak, dan token valid dengan probabilitas tertinggi disimpan. Menjadi deterministik, pendekatan ini memastikan validitas SQL 100% selama parser mengamati aturan SQL yang benar. Itu juga memisahkan validasi kueri dari generasi, sehingga memungkinkan untuk memelihara kedua komponen secara independen satu sama lain dan untuk memutakhirkan dan memodifikasi LLM.
Pendekatan lain adalah menggabungkan pengetahuan struktural dan SQL langsung ke LLM. Sebagai contoh, Graphix [9] menggunakan lapisan yang sadar grafik untuk menyuntikkan pengetahuan SQL terstruktur ke dalam model T5. Karena sifat probabilistik dari pendekatan ini, ini membuat sistem bias ke kueri yang benar, tetapi tidak memberikan jaminan keberhasilan.
Terakhir, LLM dapat digunakan sebagai agen multi-langkah yang dapat memeriksa dan memperbaiki kueri secara mandiri.[10] Dengan menggunakan beberapa langkah dalam rangkaian pemikiran, agen dapat ditugaskan untuk merefleksikan kebenaran pertanyaannya sendiri dan memperbaiki kekurangan apa pun. Jika kueri yang divalidasi masih tidak dapat dijalankan, traceback pengecualian SQL dapat diteruskan ke agen sebagai umpan balik tambahan untuk perbaikan.
Selain metode otomatis yang terjadi di backend, pengguna juga dapat dilibatkan selama proses pemeriksaan kueri. Kami akan menjelaskan ini secara lebih rinci di bagian Pengalaman pengguna.
2.3 Evaluasi
Untuk mengevaluasi algoritme Text2SQL kami, kami perlu membuat kumpulan data pengujian (validasi), menjalankan algoritme kami di atasnya, dan menerapkan metrik evaluasi yang relevan pada hasilnya. Kumpulan data naif yang dibagi menjadi data pelatihan, pengembangan, dan validasi akan didasarkan pada pasangan pertanyaan-permintaan dan mengarah pada hasil yang kurang optimal. Kueri validasi mungkin terungkap ke model selama pelatihan dan mengarah pada pandangan yang terlalu optimis tentang keterampilan generalisasinya. A pemisahan berbasis kueri, di mana kumpulan data dipecah sedemikian rupa sehingga tidak ada kueri yang muncul selama pelatihan dan selama validasi, memberikan hasil yang lebih jujur.
Dalam hal metrik evaluasi, yang kami pedulikan di Text2SQL bukanlah menghasilkan kueri yang sepenuhnya identik dengan standar emas. Ini “pencocokan string yang tepat” metode ini terlalu ketat dan akan menghasilkan banyak negatif palsu, karena kueri SQL yang berbeda dapat menghasilkan kumpulan data yang dikembalikan sama. Sebaliknya, kami ingin mencapai yang tinggi akurasi semantik dan evaluasi apakah kueri yang diprediksi dan "standar emas" akan selalu mengembalikan kumpulan data yang sama. Ada tiga metrik evaluasi yang mendekati sasaran ini:
- Akurasi pencocokan tepat: kueri SQL yang dihasilkan dan target dibagi menjadi konstituennya, dan set yang dihasilkan dibandingkan untuk identitasnya.[11] Kekurangannya di sini adalah bahwa ini hanya memperhitungkan variasi pesanan dalam kueri SQL, tetapi tidak untuk perbedaan sintaksis yang lebih jelas antara kueri yang setara secara semantik.
- Akurasi eksekusi: dataset yang dihasilkan dari kueri SQL yang dihasilkan dan target dibandingkan identitasnya. Semoga berhasil, kueri dengan semantik berbeda masih dapat lulus pengujian ini pada instance database tertentu. Misalnya, dengan asumsi database di mana semua pengguna berusia di atas 30 tahun, dua kueri berikut akan mengembalikan hasil yang sama meskipun memiliki semantik yang berbeda:
pilih * dari pengguna
pilih * dari pengguna dengan usia > 30 tahun - Akurasi test-suite: akurasi test-suite adalah versi akurasi eksekusi yang lebih maju dan kurang permisif. Untuk setiap kueri, satu set ("test suite") database dihasilkan yang sangat berbeda sehubungan dengan variabel, kondisi, dan nilai dalam kueri. Kemudian, akurasi eksekusi diuji pada masing-masing database tersebut. Meskipun memerlukan upaya tambahan untuk merekayasa generasi rangkaian pengujian, metrik ini juga secara signifikan mengurangi risiko kesalahan positif dalam evaluasi.[12]
3. Pengalaman pengguna

Text2SQL yang canggih saat ini tidak memungkinkan integrasi yang sepenuhnya mulus ke dalam sistem produksi — sebagai gantinya, perlu untuk secara aktif mengelola harapan dan perilaku pengguna, yang harus selalu sadar bahwa dia sedang berinteraksi dengan sistem AI.
3.1 Manajemen kegagalan
Text2SQL bisa gagal dalam dua mode, yang perlu ditangkap dengan cara berbeda:
- kesalahan SQL: kueri yang dihasilkan tidak valid — baik SQL tidak valid, atau tidak dapat dijalankan terhadap database tertentu karena kelemahan leksikal atau semantik. Dalam hal ini, tidak ada hasil yang dapat dikembalikan ke pengguna.
- Kesalahan semantik: kueri yang dihasilkan valid tetapi tidak mencerminkan semantik pertanyaan, sehingga menyebabkan kumpulan data yang dikembalikan salah.
Mode kedua sangat rumit karena risiko "kegagalan diam" — kesalahan yang tidak terdeteksi oleh pengguna — tinggi. Pengguna prototipe tidak akan memiliki waktu maupun keterampilan teknis untuk memverifikasi kebenaran kueri dan/atau data yang dihasilkan. Ketika data digunakan untuk pengambilan keputusan di dunia nyata, kegagalan semacam ini dapat menimbulkan konsekuensi yang menghancurkan. Untuk menghindari hal ini, sangat penting untuk mengedukasi pengguna dan membangun pagar pembatas di tingkat bisnis yang membatasi dampak potensial, seperti pemeriksaan data tambahan untuk keputusan dengan dampak yang lebih tinggi. Di sisi lain, kita juga dapat menggunakan antarmuka pengguna untuk mengelola interaksi manusia-mesin dan membantu pengguna mendeteksi dan memperbaiki permintaan yang bermasalah.
3.2 Interaksi manusia-mesin
Pengguna dapat terlibat dengan sistem AI Anda dengan tingkat intensitas yang berbeda. Lebih banyak interaksi per permintaan dapat memberikan hasil yang lebih baik, tetapi juga memperlambat fluiditas pengalaman pengguna. Selain potensi dampak negatif dari kueri dan hasil yang salah, pertimbangkan juga seberapa termotivasi pengguna Anda untuk memberikan umpan balik bolak-balik untuk mendapatkan hasil yang lebih akurat dan juga membantu meningkatkan produk dalam jangka panjang.
Cara termudah dan paling tidak menarik adalah bekerja dengan skor kepercayaan diri. Sementara perhitungan kepercayaan yang naif sebagai rata-rata probabilitas token yang dihasilkan terlalu sederhana, metode yang lebih maju seperti umpan balik verbal dapat digunakan. [13] Keyakinan dapat ditampilkan di antarmuka dan disorot dengan peringatan eksplisit jika sangat rendah. Dengan cara ini, tanggung jawab untuk tindak lanjut yang sesuai di "dunia nyata" — baik itu penolakan, penerimaan, atau pemeriksaan data tambahan — berada di pundak pengguna Anda. Meskipun ini adalah taruhan yang aman bagi Anda sebagai vendor, mengalihkan pekerjaan ini ke pengguna juga dapat mengurangi nilai produk Anda.
Kemungkinan kedua adalah melibatkan pengguna dalam dialog klarifikasi dalam kasus pertanyaan yang kurang percaya diri, ambigu, atau mencurigakan. Misalnya, sistem Anda mungkin menyarankan koreksi ortografis atau tata bahasa pada masukan dan meminta untuk memperjelas kata atau struktur tata bahasa tertentu. Mungkin juga memungkinkan pengguna untuk secara proaktif meminta koreksi dalam kueri:[14]
PENGGUNA: Tunjukkan tugas John di sprint ini.
ASISTEN: Apakah Anda ingin melihat tugas yang dibuat oleh John, atau yang sedang dia kerjakan?
PENGGUNA: tugas yang dibuat John
ASISTEN: Ok, ini adalah ID tugas:

PENGGUNA: Terima kasih, saya juga ingin melihat informasi lebih lanjut tentang tugas. Harap juga urutkan berdasarkan urgensi.
ASISTEN: Tentu, berikut adalah tugas beserta deskripsi singkat, penerima tugas dan tenggat waktu, diurutkan berdasarkan tenggat waktu.

Terakhir, untuk memudahkan pemahaman kueri oleh pengguna, sistem Anda juga dapat menyediakan perumusan ulang tekstual eksplisit dari kueri dan meminta pengguna untuk mengonfirmasi atau memperbaikinya.[15]
4. Persyaratan non-fungsional
Di bagian ini, kami membahas persyaratan non-fungsional khusus untuk Text2SQL serta trade-off di antara keduanya. Kami akan fokus pada enam persyaratan yang tampaknya paling penting untuk tugas tersebut: akurasi, skalabilitas, kecepatan, penjelasan, privasi, dan kemampuan beradaptasi dari waktu ke waktu.
4.1 Akurasi
Untuk Text2SQL, persyaratan akurasi tinggi. Pertama, Text2SQL biasanya diterapkan dalam pengaturan percakapan di mana prediksi dibuat satu per satu. Jadi, “Hukum bilangan besar” yang biasanya membantu menyeimbangkan kesalahan dalam prediksi berkelompok, tidak membantu. Kedua, validitas sintaksis dan leksikal adalah kondisi "keras": model harus menghasilkan kueri SQL yang terbentuk dengan baik, berpotensi dengan sintaks dan semantik yang kompleks, jika tidak, permintaan tidak dapat dijalankan terhadap database. Dan jika ini berjalan dengan baik dan kueri dapat dijalankan, kueri tersebut masih dapat berisi kesalahan semantik dan menyebabkan kumpulan data yang dikembalikan salah (lihat bagian 3.1 Manajemen kegagalan).
4.2 Skalabilitas
Pertimbangan skalabilitas utama adalah apakah Anda ingin menerapkan Text2SQL pada satu atau beberapa database — dan dalam kasus terakhir, apakah kumpulan database diketahui dan ditutup. Jika ya, Anda akan lebih mudah karena Anda dapat memasukkan informasi tentang database ini selama pelatihan. Namun, dalam skenario produk yang dapat diskalakan — baik itu aplikasi Text2SQL mandiri atau integrasi ke dalam produk data yang sudah ada — algoritme Anda harus mengatasi skema database baru dengan cepat. Skenario ini juga tidak memberi Anda kesempatan untuk mengubah struktur database agar lebih intuitif untuk dipelajari (tautan!). Semua ini mengarah pada trade-off berat dengan akurasi, yang mungkin juga menjelaskan mengapa penyedia Text2SQL saat ini yang menawarkan kueri ad-hoc dari database baru belum mencapai penetrasi pasar yang signifikan.
Kecepatan 4.3
Karena permintaan Text2SQL biasanya akan diproses secara online dalam percakapan, aspek kecepatan penting untuk kepuasan pengguna. Sisi positifnya, pengguna sering menyadari fakta bahwa permintaan data dapat memakan waktu tertentu dan menunjukkan kesabaran yang diperlukan. Namun, niat baik ini dapat dirusak oleh pengaturan obrolan, di mana pengguna secara tidak sadar mengharapkan kecepatan percakapan seperti manusia. Metode pengoptimalan brute-force seperti mengurangi ukuran model mungkin memiliki dampak yang tidak dapat diterima pada akurasi, jadi pertimbangkan pengoptimalan inferensi untuk memenuhi ekspektasi ini.
4.4 Penjelasan dan transparansi
Dalam kasus yang ideal, pengguna dapat mengikuti bagaimana kueri dibuat dari teks, melihat pemetaan antara kata atau ekspresi tertentu dalam pertanyaan dan kueri SQL, dll. Hal ini memungkinkan untuk memverifikasi kueri dan membuat penyesuaian saat berinteraksi dengan sistem . Selain itu, sistem juga dapat menyediakan perumusan ulang tekstual eksplisit dari kueri dan meminta pengguna untuk mengonfirmasi atau memperbaikinya.
Privasi 4.5
Fungsi Text2SQL dapat diisolasi dari eksekusi kueri, sehingga informasi database yang dikembalikan dapat tetap tidak terlihat. Namun, pertanyaan kritisnya adalah berapa banyak informasi tentang database yang disertakan dalam prompt. Tiga opsi (dengan menurunkan tingkat privasi) adalah:
- Tidak ada informasi
- Skema basis data
- Konten basis data
Privasi diimbangi dengan akurasi — semakin sedikit batasan Anda dalam memasukkan informasi berguna di prompt, semakin baik hasilnya.
4.6 Adaptasi dari waktu ke waktu
Untuk menggunakan Text2SQL dengan cara yang tahan lama, Anda perlu beradaptasi dengan pergeseran data, yaitu perubahan distribusi data yang diterapkan model. Sebagai contoh, mari kita asumsikan bahwa data yang digunakan untuk penyesuaian awal mencerminkan perilaku kueri sederhana dari pengguna saat mereka mulai menggunakan sistem BI. Seiring berjalannya waktu, kebutuhan informasi pengguna menjadi lebih canggih dan memerlukan kueri yang lebih kompleks, yang membanjiri model naif Anda. Selain itu, tujuan atau strategi perubahan perusahaan juga dapat melayang dan mengarahkan kebutuhan informasi ke area lain dari database. Terakhir, tantangan khusus Text2SQL adalah penyimpangan basis data. Saat database perusahaan diperluas, kolom dan tabel baru yang tidak terlihat masuk ke prompt. Meskipun algoritme Text2SQL yang dirancang untuk aplikasi multi-database dapat menangani masalah ini dengan baik, hal ini dapat berdampak signifikan pada akurasi model database tunggal. Semua masalah ini paling baik diselesaikan dengan kumpulan data yang disempurnakan yang mencerminkan perilaku pengguna di dunia nyata saat ini. Oleh karena itu, sangat penting untuk mencatat pertanyaan dan hasil pengguna, serta umpan balik terkait yang dapat dikumpulkan dari penggunaan. Selain itu, algoritme pengelompokan semantik, misalnya menggunakan penyematan atau pemodelan topik, dapat diterapkan untuk mendeteksi perubahan jangka panjang yang mendasari perilaku pengguna dan menggunakannya sebagai sumber informasi tambahan untuk menyempurnakan set data fine-tuning Anda
Kesimpulan
Mari kita rangkum poin-poin utama dari artikel ini:
- Text2SQL memungkinkan untuk mengimplementasikan akses data yang intuitif dan demokratis dalam bisnis, sehingga memaksimalkan nilai data yang tersedia.
- Data Text2SQL terdiri dari pertanyaan pada input, dan kueri SQL pada output. Pemetaan antara pertanyaan dan kueri SQL adalah banyak-ke-banyak.
- Penting untuk memberikan informasi tentang database sebagai bagian dari prompt. Selain itu, struktur database dapat dioptimalkan untuk memudahkan algoritme mempelajari dan memahaminya.
- Pada input, tantangan utamanya adalah variabilitas linguistik dari pertanyaan bahasa alami, yang dapat didekati dengan menggunakan LLM yang dilatih sebelumnya pada berbagai macam gaya teks yang berbeda.
- Output dari Text2SQL harus berupa kueri SQL yang valid. Kendala ini dapat digabungkan dengan “menyuntikkan” pengetahuan SQL ke dalam algoritme; sebagai alternatif, dengan menggunakan pendekatan iteratif, kueri dapat diperiksa dan diperbaiki dalam beberapa langkah.
- Karena potensi dampak tinggi dari "kegagalan diam" yang mengembalikan data yang salah untuk pengambilan keputusan, manajemen kegagalan menjadi perhatian utama dalam antarmuka pengguna.
- Dengan cara “augmented”, pengguna dapat secara aktif terlibat dalam validasi iteratif dan peningkatan kueri SQL. Meskipun hal ini membuat aplikasi kurang lancar, hal ini juga mengurangi tingkat kegagalan, memungkinkan pengguna menjelajahi data dengan cara yang lebih fleksibel, dan menciptakan sinyal berharga untuk pembelajaran lebih lanjut.
- Persyaratan non-fungsional utama yang harus dipertimbangkan adalah akurasi, skalabilitas, kecepatan, penjelasan, privasi, dan kemampuan beradaptasi dari waktu ke waktu. Pertukaran utama terdiri antara akurasi di satu sisi, dan skalabilitas, kecepatan, dan privasi di sisi lain.
Referensi
[1] Ken Van Haren. 2023. Mengganti analis SQL dengan 26 petunjuk GPT rekursif
[2] Nitarshan Rajkumar dkk. 2022. Mengevaluasi Kemampuan Text-to-SQL Model Bahasa Besar
[3] Naihao Deng dkk. 2023. Kemajuan Terbaru dalam Text-to-SQL: Survei tentang Apa yang Kami Miliki dan Apa yang Kami Harapkan
[4] Mohammadreza Pourreza dkk. 2023. DIN-SQL: Pembelajaran Dalam Konteks Terdekomposisi dari Text-to-SQL dengan Self-Correction
[5] Victor Zhong dkk. 2021. Adaptasi Beralas untuk Parsing Semantik yang Dapat Dieksekusi Zero-shot
[6] Xi Victoria Lin dkk. 2020. Menjembatani Data Tekstual dan Tabular untuk Parsing Semantik Teks-ke-SQL Lintas Domain
[7] Tong Guo dkk. 2019. Pembuatan Text-to-SQL berbasis BERT yang Ditingkatkan Konten
[8] Torsten Scholak dkk. 2021. PICARD: Parsing Secara Bertahap untuk Dekode Regresi Otomatis Terkendala dari Model Bahasa
[9] Jinyang Li dkk. 2023. Graphix-T5: Menggabungkan Transformer Terlatih dengan Lapisan Sadar Grafik untuk Penguraian Teks ke SQL
[10] Rantai Lang. 2023. LLM dan SQL
[11] Tao Yu dkk. 2018. Spider: Kumpulan Data Berlabel Manusia Berskala Besar untuk Parsing Semantik dan Lintas Domain yang Kompleks dan Tugas Teks-ke-SQL
[12] Ruiqi Zhong dkk. 2020. Evaluasi Semantik untuk Text-to-SQL dengan Distilled Test Suites
[13] Katherine Tian dkk. 2023. Tanyakan Saja untuk Kalibrasi: Strategi untuk Memunculkan Skor Keyakinan Terkalibrasi dari Model Bahasa yang Disempurnakan dengan Umpan Balik Manusia
[14] Braden Hancock dkk. 2019. Belajar dari Dialog setelah Penerapan: Beri Makan Diri Anda, Chatbot!
[15] Ahmed Elgohary dkk. 2020. Bicaralah dengan Parser Anda: Text-to-SQL Interaktif dengan Umpan Balik Bahasa Alami
[16] Janna Lipenkova. 2022. Bicara padaku! Percakapan Text2SQL dengan data perusahaan Anda, berbicara di pertemuan Pemrosesan Bahasa Alami New York.
Semua gambar oleh penulis.
Artikel ini awalnya diterbitkan pada Menuju Ilmu Data dan diterbitkan kembali ke TOPBOTS dengan izin dari penulis.
Selamat menikmati artikel ini? Mendaftar untuk lebih banyak pembaruan penelitian AI.
Kami akan memberi tahu Anda ketika kami merilis lebih banyak artikel ringkasan seperti ini.
terkait
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Otomotif / EV, Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- BlockOffset. Modernisasi Kepemilikan Offset Lingkungan. Akses Di Sini.
- Sumber: https://www.topbots.com/conversational-ai-for-data-analysis/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 11
- 12
- 13
- 14
- 15%
- 16
- 2018
- 2019
- 2020
- 2021
- 2022
- 2023
- 26
- 30
- 7
- 8
- 9
- a
- Sanggup
- Tentang Kami
- atas
- Mutlak
- benar
- penerimaan
- mengakses
- Akses ke data
- Menurut
- Akun
- ketepatan
- tepat
- akurat
- Mencapai
- dicapai
- memperoleh
- aktif
- menyesuaikan
- adaptasi
- beradaptasi
- Tambahan
- Selain itu
- penyesuaian
- maju
- uang muka
- Keuntungan
- Setelah
- terhadap
- usia
- berumur
- Agen
- AI
- ai penelitian
- AL
- Waspada
- algoritma
- algoritma
- Semua
- mengizinkan
- Membiarkan
- memungkinkan
- sepanjang
- sudah
- juga
- alternatif
- selalu
- menakjubkan
- ambisi
- di tengah-tengah
- an
- analisis
- analis
- Analis
- Analytical
- analisis
- dan
- Lain
- Apa pun
- Aplikasi
- aplikasi
- terapan
- Mendaftar
- Menerapkan
- pendekatan
- pendekatan
- sesuai
- kira-kira
- April
- ADALAH
- daerah
- sekitar
- artikel
- artikel
- AS
- penampilan
- aspek
- terkait
- At
- Mencoba
- penulis
- Otomatis
- secara otomatis
- secara mandiri
- tersedia
- rata-rata
- menghindari
- sadar
- Backend
- Saldo
- mendasarkan
- berdasarkan
- dasar
- BE
- menjadi
- Awal
- makhluk
- Manfaat
- selain
- TERBAIK
- Bertaruh
- Lebih baik
- antara
- Luar
- bias
- Terbesar
- kedua
- membangun
- Bangunan
- beban
- bisnis
- bisnis
- tapi
- by
- bernama
- Kamp
- CAN
- Bisa Dapatkan
- tidak bisa
- kemampuan
- yang
- kasus
- tertangkap
- pusat
- tertentu
- menantang
- tantangan
- perubahan
- Perubahan
- mengubah
- Saluran
- memeriksa
- diperiksa
- memeriksa
- Cek
- pilihan
- klasifikasi
- tertutup
- lebih dekat
- kekelompokan
- koleksi
- Kolom
- datang
- kedatangan
- Umum
- Komunikasi
- Perusahaan
- perusahaan
- Perusahaan
- dibandingkan
- kompetisi
- kompetitif
- lengkap
- sama sekali
- penyelesaian
- kompleks
- komponen
- konsep
- konseptual
- Perhatian
- kondisi
- Kondisi
- kepercayaan
- Memastikan
- Konsekuensi
- Mempertimbangkan
- besar
- pertimbangan
- dianggap
- terdiri
- Konten
- konteks
- kontrol
- Mudah
- konvensional
- Percakapan
- percakapan
- AI percakapan
- Antarmuka percakapan
- percakapan
- dingin
- benar
- Koreksi
- Sesuai
- bisa
- membuat
- dibuat
- menciptakan
- membuat
- Kreatif
- kritis
- sangat penting
- terbaru
- Sekarang
- pelanggan
- data
- akses data
- analisis data
- ilmu data
- ilmuwan data
- Basis Data
- database
- kumpulan data
- transaksi
- keputusan
- Pengambilan Keputusan
- keputusan
- decoding
- mendalam
- menyelam dalam
- keterlambatan
- disampaikan
- demokratis
- tergantung
- penyebaran
- menggambarkan
- dijelaskan
- dirancang
- desainer
- diinginkan
- Meskipun
- rinci
- yang menghancurkan
- Pengembangan
- Dialog
- perbedaan
- berbeda
- dibedakan
- langsung
- langsung
- patah hati
- membahas
- diskusi
- tersebar
- ditampilkan
- Gangguan
- distribusi
- beberapa
- do
- tidak
- Tidak
- melakukan
- dilakukan
- Dont
- turun
- dramatis
- dua
- selama
- dinamis
- e
- E&T
- setiap
- memudahkan
- mudah
- termudah
- mudah
- Tepi
- mendidik
- edukasi
- usaha
- antara
- elemen
- memeluk
- karyawan
- aktif
- mencakup
- akhir
- energi
- mengikutsertakan
- menarik
- insinyur
- Teknik
- Insinyur
- ditingkatkan
- cukup
- memperkaya
- memastikan
- Memastikan
- sepenuhnya
- masuk
- lingkungan
- Setara
- kesalahan
- kesalahan
- memperkirakan
- dll
- Eter (ETH)
- mengevaluasi
- evaluasi
- Bahkan
- Setiap
- semua orang
- contoh
- contoh
- Excel
- pengecualian
- dieksekusi
- eksekusi
- dibebaskan
- ada
- ada
- mengharapkan
- harapan
- harapan
- diharapkan
- mahal
- pengalaman
- Menjelaskan
- Dapat dijelaskan
- menyelidiki
- menyatakan
- ekspresi
- tambahan
- sangat
- fakta
- GAGAL
- Kegagalan
- palsu
- keluarga
- Fashion
- lebih cepat
- Fitur
- umpan balik
- Angka
- Akhirnya
- Pertama
- cacat
- kekurangan
- keluwesan
- fleksibel
- aliran
- cairan
- ketidakstabilan
- Fokus
- difokuskan
- mengikuti
- pengikut
- berikut
- Untuk
- asing
- bentuk
- format
- Bekas
- bentuk
- perumusan
- sering
- gesekan
- dari
- penuh
- fungsi
- lebih lanjut
- Umum
- menghasilkan
- dihasilkan
- menghasilkan
- generasi
- generatif
- AI generatif
- mendapatkan
- mendapatkan
- Memberikan
- diberikan
- Aksi
- Go
- tujuan
- Anda
- Pergi
- Gold
- Gold Standard
- baik
- Kemauan baik
- Tatabahasa
- Tanah
- Pertumbuhan
- menjamin
- membimbing
- memiliki
- tangan
- segenggam
- menangani
- tangan
- terjadi
- Memiliki
- memiliki
- he
- berat
- membantu
- membantu
- di sini
- High
- berkualitas tinggi
- lebih tinggi
- Menyoroti
- Disorot
- sangat
- Seterpercayaapakah Olymp Trade? Kesimpulan
- Namun
- HTML
- HTTPS
- besar
- manusia
- Manusia
- Hype
- i
- ideal
- identik
- identitas
- id
- if
- gambar
- Dampak
- melaksanakan
- implementasi
- diimplementasikan
- penting
- mustahil
- memperbaiki
- ditingkatkan
- perbaikan
- meningkatkan
- in
- secara mendalam
- memasukkan
- termasuk
- Termasuk
- menggabungkan
- Tergabung
- menggabungkan
- Meningkatkan
- secara mandiri
- sendiri-sendiri
- industri
- tidak efisien
- informasi
- informasi
- mulanya
- menyuntikkan
- memasukkan
- input
- wawasan
- contoh
- sebagai gantinya
- integrasi
- berinteraksi
- berinteraksi
- interaksi
- interaksi
- interaktif
- Antarmuka
- interface
- ke
- hakiki
- memperkenalkan
- intuitif
- investasi
- melibatkan
- terlibat
- terpencil
- isu
- masalah
- IT
- NYA
- John
- perjalanan
- Menjaga
- terus
- kunci
- kunci-kunci
- Membunuh
- Jenis
- Tahu
- pengetahuan
- Manajemen Pengetahuan
- dikenal
- Tanah
- bahasa
- besar
- besar-besaran
- lebih besar
- Terbaru
- lapisan
- lapisan
- memimpin
- terkemuka
- Memimpin
- BELAJAR
- belajar
- pengetahuan
- paling sedikit
- Dipimpin
- Panjang
- kurang
- membiarkan
- Tingkat
- Leverage
- li
- terletak
- Hidup
- 'like'
- MEMBATASI
- keterbatasan
- lin
- sedikit
- mencatat
- logis
- Panjang
- jangka panjang
- mencari
- kalah
- Rendah
- menurunkan
- keberuntungan
- mesin
- Mesin belajar
- terbuat
- Utama
- memelihara
- utama
- membuat
- MEMBUAT
- Membuat
- mengelola
- pengelolaan
- manajer
- Manajer
- panduan
- pabrik
- banyak
- pemetaan
- ditandai
- Pasar
- Marketing
- menguasai
- penguasaan
- Cocok
- bahan
- kematangan
- max-width
- memaksimalkan
- me
- cara
- mekanisme
- Meetup
- mental yang
- metode
- metode
- metrik
- Metrik
- mungkin
- keberatan
- kesalahan
- Percampuran
- mode
- model
- pemodelan
- model
- modern
- mode
- memodifikasi
- lebih
- paling
- termotivasi
- banyak
- beberapa
- nama
- nama
- penamaan
- Alam
- Bahasa Alami
- Pengolahan Bahasa alami
- Alam
- perlu
- Perlu
- kebutuhan
- negatif
- negatif
- juga tidak
- New
- NY
- tidak
- tidak
- Kebisingan
- non-teknis
- maupun
- sekarang
- jumlah
- nomor
- tujuan
- mengamati
- usang
- of
- lepas
- menawarkan
- menawarkan
- sering
- on
- ONE
- secara online
- hanya
- open source
- Operasi
- Kesempatan
- menentang
- optimal
- mengoptimalkan
- Dioptimalkan
- Optimis
- Opsi
- or
- urutan
- semula
- Lainnya
- jika tidak
- kami
- keluaran
- lebih
- sendiri
- pasangan
- pasang
- bagian
- khususnya
- lulus
- Lulus
- melewati
- Kesabaran
- pola
- penetrasi
- menyempurnakan
- prestasi
- izin
- perencanaan
- plato
- Kecerdasan Data Plato
- Data Plato
- memainkan
- silahkan
- poin
- positif
- kemungkinan
- mungkin
- potensi
- berpotensi
- diprediksi
- ramalan
- Prediksi
- menyajikan
- sebelumnya
- primer
- pribadi
- hak istimewa
- hadiah
- mungkin
- proses
- diproses
- pengolahan
- Produk
- Produksi
- jelas
- diusulkan
- memberikan
- disediakan
- penyedia
- menyediakan
- diterbitkan
- teka-teki
- Ular sanca
- kualitas
- kuantitas
- query
- pertanyaan
- Pertanyaan
- segera
- jarak
- Tarif
- Mentah
- data mentah
- pembaca
- nyata
- dunia nyata
- masuk akal
- rekap
- baru
- Rekursif
- menurunkan
- mengurangi
- mengurangi
- referensi
- disebut
- mencerminkan
- mencerminkan
- terkait
- hubungan
- Hubungan
- melepaskan
- relevan
- perwakilan
- diwakili
- permintaan
- permintaan
- membutuhkan
- wajib
- Persyaratan
- membutuhkan
- penelitian
- menghormati
- tanggung jawab
- tanggung jawab
- terbatas
- mengakibatkan
- dihasilkan
- Hasil
- kembali
- Terungkap
- Risiko
- Saingan
- jalan
- ROI
- Peran
- peran
- putaran
- Aturan
- aturan
- Run
- berjalan
- aman
- sama
- kepuasan
- Skalabilitas
- terukur
- skenario
- skenario
- Ilmu
- ilmuwan
- ilmuwan
- skor
- mulus
- Kedua
- Bagian
- bagian
- melihat
- terlihat
- semantik
- sentimen
- Sekarang Layanan
- set
- set
- pengaturan
- pengaturan
- penyiapan
- dia
- Pendek
- harus
- Menunjukkan
- sisi
- menandatangani
- sinyal
- penting
- signifikan
- mirip
- Sederhana
- sejak
- tunggal
- ENAM
- Ukuran
- ketrampilan
- keterampilan
- melambat
- lebih kecil
- pintar
- So
- padat
- Memecahkan
- sesuatu
- mutakhir
- sumber
- Space
- tertentu
- Secara khusus
- kecepatan
- menghabiskan
- membagi
- Lari cepat
- SQL
- kotak
- Staf
- standalone
- standar
- awal
- mulai
- dimulai
- state-of-the-art
- Status
- Langkah
- Tangga
- Masih
- Strategis
- strategi
- Penyelarasan
- ketat
- Tali
- struktural
- struktur
- tersusun
- sukses
- seperti itu
- cukup
- menyarankan
- RINGKASAN
- Didukung
- Permukaan
- Survei
- mencurigakan
- sintaksis
- sistem
- sistem
- Mengambil
- Bakat
- Berbicara
- target
- tugas
- tugas
- tim
- tim
- Teknis
- teknik
- Teknologi
- istilah
- istilah
- uji
- diuji
- Klasifikasi Teks
- dari
- bahwa
- Grafik
- Kodeks
- informasi
- mereka
- Mereka
- kemudian
- Sana.
- Ini
- mereka
- berpikir
- ini
- itu
- tiga
- Melalui
- di seluruh
- waktu
- untuk
- Token
- terlalu
- toolkit
- alat
- TOPBOT
- tema
- terhadap
- perdagangan
- tradisional
- Pelatihan
- Mentransfer
- Mengubah
- Transformasi
- transformasi
- transformer
- MENGHIDUPKAN
- Putar
- dua
- mengetik
- jenis
- khas
- pokok
- memahami
- pemahaman
- Universal
- Pembaruan
- meningkatkan
- urgensi
- penggunaan
- menggunakan
- bekas
- informasi berguna
- Pengguna
- Pengguna Pengalaman
- User Interface
- Pengguna
- kegunaan
- menggunakan
- ux
- desainer ux
- divalidasi
- memvalidasi
- pengesahan
- Berharga
- nilai
- Nilai - Nilai
- variasi
- berbagai
- Kubah
- penjaja
- memeriksa
- serba guna
- versi
- sangat
- melalui
- Victoria
- View
- penglihatan
- ingin
- adalah
- Cara..
- cara
- we
- minggu
- mingguan
- BAIK
- adalah
- Apa
- ketika
- apakah
- yang
- sementara
- SIAPA
- mengapa
- lebar
- akan
- menang
- dengan
- tanpa
- kata
- Kerja
- kerja
- dunia
- akan
- tertulis
- Salah
- xi
- kuning
- iya nih
- namun
- York
- kamu
- Anda
- diri
- Youtube
- zephyrnet.dll
- Zhong