Ini adalah postingan bersama yang ditulis bersama oleh AWS dan Voxel51. Voxel51 adalah perusahaan di balik FiftyOne, toolkit sumber terbuka untuk membuat kumpulan data berkualitas tinggi dan model visi komputer.
Sebuah perusahaan ritel sedang membuat aplikasi seluler untuk membantu pelanggan membeli pakaian. Untuk membuat aplikasi ini, mereka memerlukan kumpulan data berkualitas tinggi yang berisi gambar pakaian, diberi label dengan berbagai kategori. Dalam posting ini, kami menunjukkan cara menggunakan kembali kumpulan data yang ada melalui pembersihan data, pemrosesan awal, dan pra-pelabelan dengan model klasifikasi zero-shot di Lima puluh satu, dan menyesuaikan label ini dengan Kebenaran Dasar Amazon SageMaker.
Anda dapat menggunakan Ground Truth dan FiftyOne untuk mempercepat proyek pelabelan data Anda. Kami mengilustrasikan cara menggunakan kedua aplikasi secara bersamaan untuk membuat kumpulan data berlabel berkualitas tinggi. Untuk contoh kasus penggunaan kami, kami bekerja dengan Kumpulan data Fashion200K, dirilis di ICCV 2017.
Ikhtisar solusi
Ground Truth adalah layanan pelabelan data mandiri dan dikelola sepenuhnya yang memberdayakan ilmuwan data, insinyur pembelajaran mesin (ML), dan peneliti untuk membuat kumpulan data berkualitas tinggi. Lima puluh satu by voxel51 adalah perangkat sumber terbuka untuk menyusun, memvisualisasikan, dan mengevaluasi kumpulan data visi komputer sehingga Anda dapat melatih dan menganalisis model yang lebih baik dengan mempercepat kasus penggunaan Anda.
Di bagian berikut, kami mendemonstrasikan cara melakukan hal berikut:
- Visualisasikan kumpulan data di FiftyOne
- Bersihkan dataset dengan pemfilteran dan deduplikasi gambar di FiftyOne
- Memberi label sebelumnya pada data yang dibersihkan dengan klasifikasi zero-shot di FiftyOne
- Beri label pada kumpulan data yang dikurasi lebih kecil dengan Ground Truth
- Masukkan hasil berlabel dari Ground Truth ke FiftyOne dan tinjau hasil berlabel di FiftyOne
Gunakan ikhtisar kasus
Misalkan Anda memiliki perusahaan ritel dan ingin membuat aplikasi seluler untuk memberikan rekomendasi yang dipersonalisasi untuk membantu pengguna memutuskan apa yang akan dikenakan. Calon pengguna Anda sedang mencari aplikasi yang memberi tahu mereka pakaian mana di lemari mereka yang bekerja sama dengan baik. Anda melihat peluang di sini: jika Anda dapat mengidentifikasi pakaian yang bagus, Anda dapat menggunakannya untuk merekomendasikan pakaian baru yang melengkapi pakaian yang sudah dimiliki pelanggan.
Anda ingin membuat segalanya semudah mungkin bagi pengguna akhir. Idealnya, seseorang yang menggunakan aplikasi Anda hanya perlu memotret pakaian di lemari pakaiannya, dan model ML Anda menampilkan keajaibannya di belakang layar. Anda dapat melatih model tujuan umum atau menyempurnakan model untuk gaya unik setiap pengguna dengan beberapa bentuk umpan balik.
Namun, pertama-tama, Anda perlu mengidentifikasi jenis pakaian apa yang diambil pengguna. Apakah itu kemeja? Sepasang celana? Atau sesuatu yang lain? Lagi pula, Anda mungkin tidak ingin merekomendasikan pakaian yang memiliki banyak gaun atau banyak topi.
Untuk mengatasi tantangan awal ini, Anda ingin membuat dataset pelatihan yang terdiri dari gambar berbagai item pakaian dengan berbagai pola dan gaya. Untuk membuat prototipe dengan anggaran terbatas, Anda ingin melakukan bootstrap menggunakan kumpulan data yang ada.
Untuk mengilustrasikan dan memandu Anda melalui proses dalam posting ini, kami menggunakan kumpulan data Fashion200K yang dirilis di ICCV 2017. Ini adalah kumpulan data yang mapan dan dikutip dengan baik, tetapi tidak secara langsung cocok untuk kasus penggunaan Anda.
Meskipun artikel pakaian diberi label dengan kategori (dan subkategori) dan berisi berbagai tag bermanfaat yang diambil dari deskripsi produk asli, data tidak secara sistematis diberi label dengan informasi pola atau gaya. Sasaran Anda adalah mengubah set data yang ada ini menjadi set data pelatihan yang kuat untuk model klasifikasi pakaian Anda. Anda perlu membersihkan data, menambah skema pelabelan dengan label gaya. Dan Anda ingin melakukannya dengan cepat dan dengan pengeluaran sesedikit mungkin.
Unduh data secara lokal
Pertama, unduh file zip women.tar dan folder label (dengan semua subfoldernya) dengan mengikuti petunjuk yang diberikan di Repositori GitHub kumpulan data Fashion200K. Setelah Anda membuka ritsleting keduanya, buat direktori induk fashion200k, dan pindahkan label dan folder wanita ke dalamnya. Untungnya, gambar-gambar ini telah dipotong ke kotak pembatas deteksi objek, sehingga kita dapat fokus pada klasifikasi, daripada mengkhawatirkan deteksi objek.
Terlepas dari "200K" dalam monikernya, direktori wanita yang kami ekstrak berisi 338,339 gambar. Untuk menghasilkan kumpulan data Fashion200K resmi, penulis kumpulan data tersebut merayapi lebih dari 300,000 produk secara online, dan hanya produk dengan deskripsi yang berisi lebih dari empat kata yang berhasil. Untuk tujuan kami, jika deskripsi produk tidak penting, kami dapat menggunakan semua gambar yang dirayapi.
Mari kita lihat bagaimana data ini diatur: di dalam folder wanita, gambar disusun berdasarkan jenis artikel tingkat atas (rok, atasan, celana, jaket, dan gaun), dan subkategori jenis artikel (blus, kaos, lengan panjang puncak).
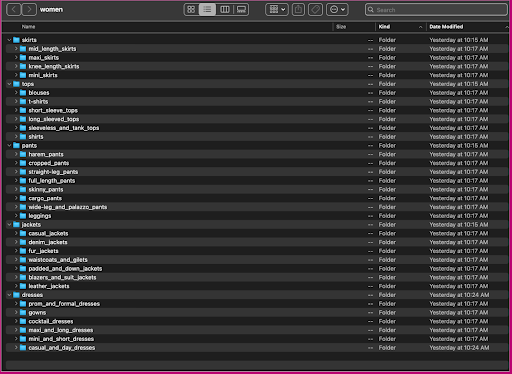
Di dalam direktori subkategori, ada subdirektori untuk setiap daftar produk. Masing-masing berisi sejumlah variabel gambar. Subkategori cropped_pants, misalnya, berisi daftar produk berikut dan gambar terkait.
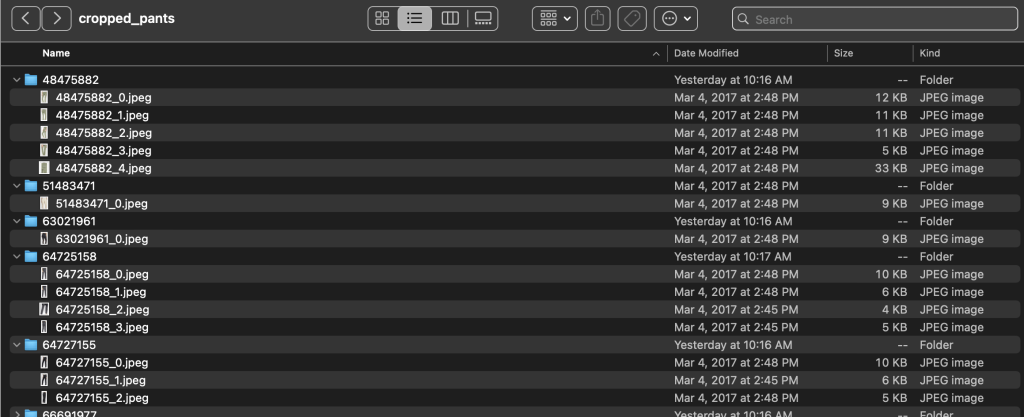
Folder labels berisi file teks untuk setiap jenis artikel tingkat atas, untuk pemisahan pelatihan dan pengujian. Di dalam setiap file teks ini terdapat baris terpisah untuk setiap gambar, yang menentukan jalur file relatif, skor, dan tag dari deskripsi produk.
Karena kami menggunakan ulang kumpulan data, kami menggabungkan semua gambar kereta dan uji. Kami menggunakan ini untuk menghasilkan kumpulan data khusus aplikasi berkualitas tinggi. Setelah kami menyelesaikan proses ini, kami dapat secara acak membagi dataset yang dihasilkan menjadi kereta baru dan pemisahan pengujian.
Menyuntikkan, melihat, dan membuat kumpulan data di FiftyOne
Jika Anda belum melakukannya, instal FiftyOne sumber terbuka menggunakan pip:
Praktik terbaik adalah melakukannya dalam lingkungan virtual (venv atau conda) baru. Kemudian impor modul yang relevan. Impor pustaka dasar, fiftyone, FiftyOne Brain, yang memiliki metode ML bawaan, FiftyOne Zoo, dari mana kita akan memuat model yang akan menghasilkan label zero-shot untuk kita, dan ViewField, yang memungkinkan kita memfilter secara efisien data dalam kumpulan data kami:
Anda juga ingin mengimpor modul glob dan os Python, yang akan membantu kami bekerja dengan pencocokan jalur dan pola pada konten direktori:
Sekarang kita siap memuat dataset ke FiftyOne. Pertama, kami membuat kumpulan data bernama fashion200k dan membuatnya persisten, yang memungkinkan kami menyimpan hasil operasi intensif komputasi, jadi kami hanya perlu menghitung jumlah tersebut satu kali.
Kami sekarang dapat beralih melalui semua direktori subkategori, menambahkan semua gambar di dalam direktori produk. Kami menambahkan label klasifikasi FiftyOne ke setiap sampel dengan nama kolom article_type, yang diisi oleh kategori artikel tingkat atas gambar. Kami juga menambahkan informasi kategori dan subkategori sebagai tag:
Pada titik ini, kita dapat memvisualisasikan kumpulan data kita di aplikasi FiftyOne dengan meluncurkan sebuah sesi:
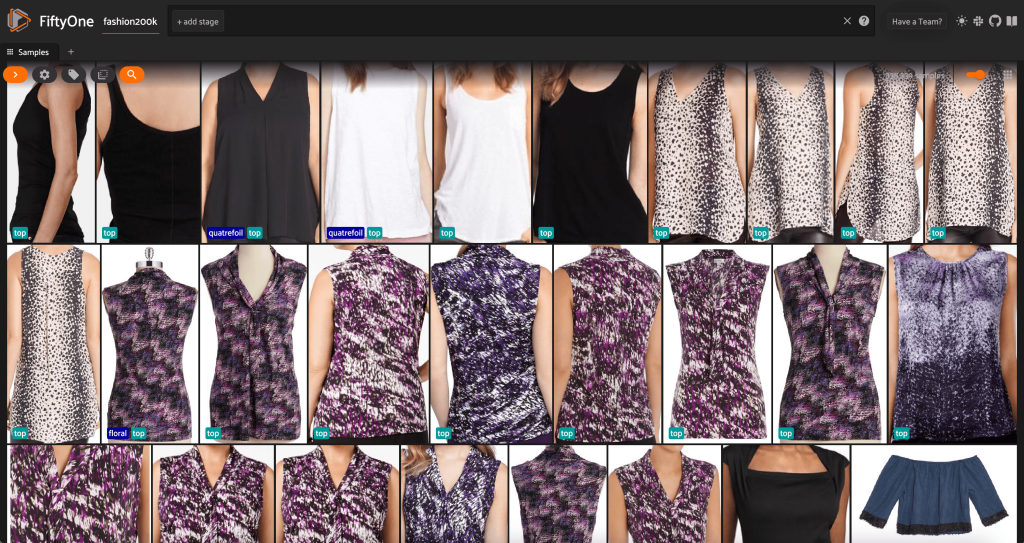
Kami juga dapat mencetak ringkasan dataset dengan Python dengan menjalankan print(dataset):
Kami juga dapat menambahkan tag dari labels direktori ke sampel di dataset kami:
Melihat data, beberapa hal menjadi jelas:
- Beberapa gambar cukup kasar, dengan resolusi rendah. Ini mungkin karena gambar-gambar ini dihasilkan dengan memotong gambar awal dalam kotak pembatas deteksi objek.
- Beberapa pakaian dikenakan oleh seseorang, dan beberapa difoto sendiri. Rincian ini dikemas oleh
viewpointmilik. - Banyak gambar dari produk yang sama sangat mirip, jadi setidaknya pada awalnya, menyertakan lebih dari satu gambar per produk mungkin tidak menambah banyak daya prediksi. Sebagian besar, gambar pertama dari setiap produk (berakhiran dengan
_0.jpeg) adalah yang terbersih.
Awalnya, kita mungkin ingin melatih model klasifikasi gaya pakaian kita pada subset terkontrol dari gambar-gambar ini. Untuk tujuan ini, kami menggunakan gambar beresolusi tinggi dari produk kami, dan membatasi pandangan kami pada satu sampel representatif per produk.
Pertama, kami memfilter gambar beresolusi rendah. Kami menggunakan compute_metadata() metode untuk menghitung dan menyimpan lebar dan tinggi gambar, dalam piksel, untuk setiap gambar dalam kumpulan data. Kami kemudian mempekerjakan FiftyOne ViewField untuk memfilter gambar berdasarkan nilai lebar dan tinggi minimum yang diizinkan. Lihat kode berikut:
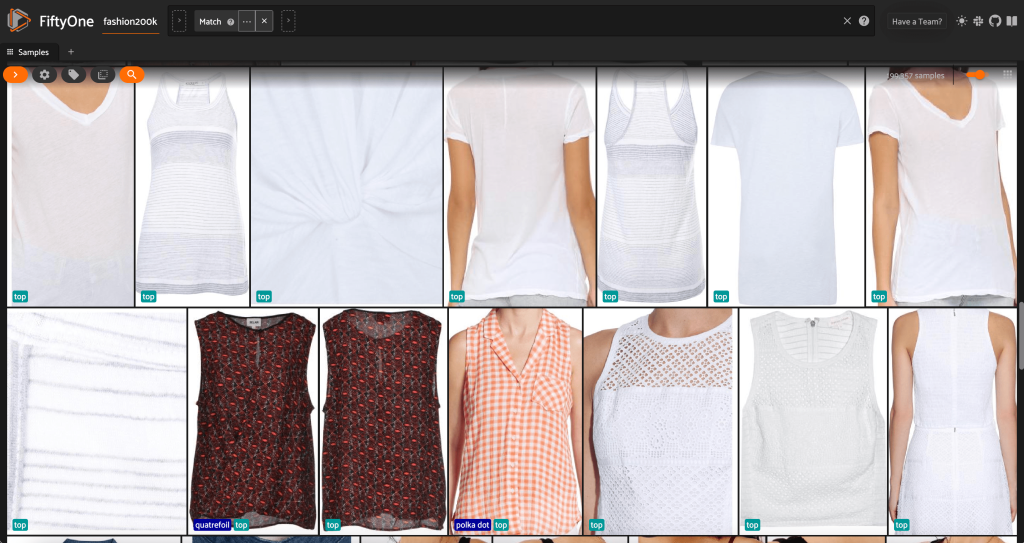
Subset beresolusi tinggi ini hanya memiliki kurang dari 200,000 sampel.
Dari tampilan ini, kami dapat membuat tampilan baru ke dalam kumpulan data kami yang berisi hanya satu sampel representatif (paling banyak) untuk setiap produk. Kami menggunakan ViewField sekali lagi, pencocokan pola untuk jalur file yang diakhiri dengan _0.jpeg:
Mari kita lihat urutan gambar yang diacak secara acak dalam subset ini:
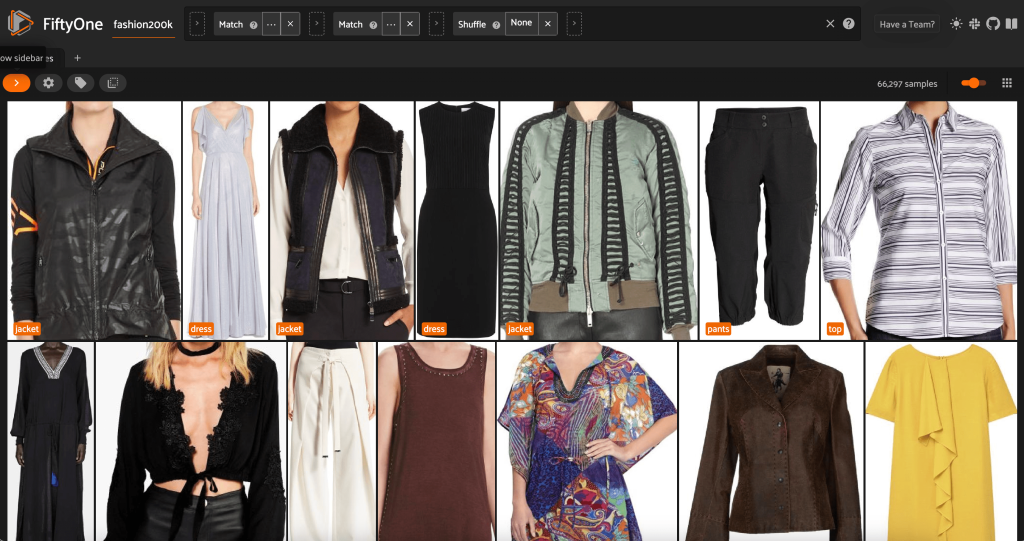
Hapus gambar yang berlebihan dalam kumpulan data
Tampilan ini berisi 66,297 gambar, atau lebih dari 19% dari kumpulan data asli. Namun, ketika kita melihat tampilannya, kita melihat bahwa ada banyak produk yang sangat mirip. Menyimpan semua salinan ini kemungkinan besar hanya akan menambah biaya untuk pelabelan dan pelatihan model kami, tanpa meningkatkan kinerja secara nyata. Sebagai gantinya, mari singkirkan duplikat yang hampir sama untuk membuat kumpulan data yang lebih kecil yang masih mengemas pukulan yang sama.
Karena gambar ini bukan duplikat yang tepat, kami tidak dapat memeriksa kesetaraan piksel. Untungnya, kami dapat menggunakan FiftyOne Brain untuk membantu kami membersihkan dataset kami. Khususnya, kita akan menghitung penyematan untuk setiap gambar—vektor berdimensi lebih rendah yang mewakili gambar—lalu mencari gambar yang vektor penyematannya berdekatan satu sama lain. Semakin dekat vektor, semakin mirip gambarnya.
Kami menggunakan model CLIP untuk menghasilkan vektor penyematan 512 dimensi untuk setiap gambar, dan menyimpan penyematan ini di bidang penyematan pada sampel di kumpulan data kami:
Kemudian kami menghitung kedekatan antara penyematan, menggunakan kesamaan cosinus, dan nyatakan bahwa dua vektor mana pun yang kesamaannya lebih besar dari beberapa ambang kemungkinan akan mendekati duplikat. Skor kesamaan cosinus terletak pada kisaran [0, 1], dan melihat data, skor ambang batas thresh=0.5 tampaknya benar. Sekali lagi, ini tidak perlu sempurna. Beberapa gambar yang hampir duplikat sepertinya tidak akan merusak kekuatan prediktif kami, dan membuang beberapa gambar non-duplikat tidak akan berdampak signifikan pada performa model.
Kami dapat melihat duplikat yang diklaim untuk memverifikasi bahwa mereka benar-benar mubazir:
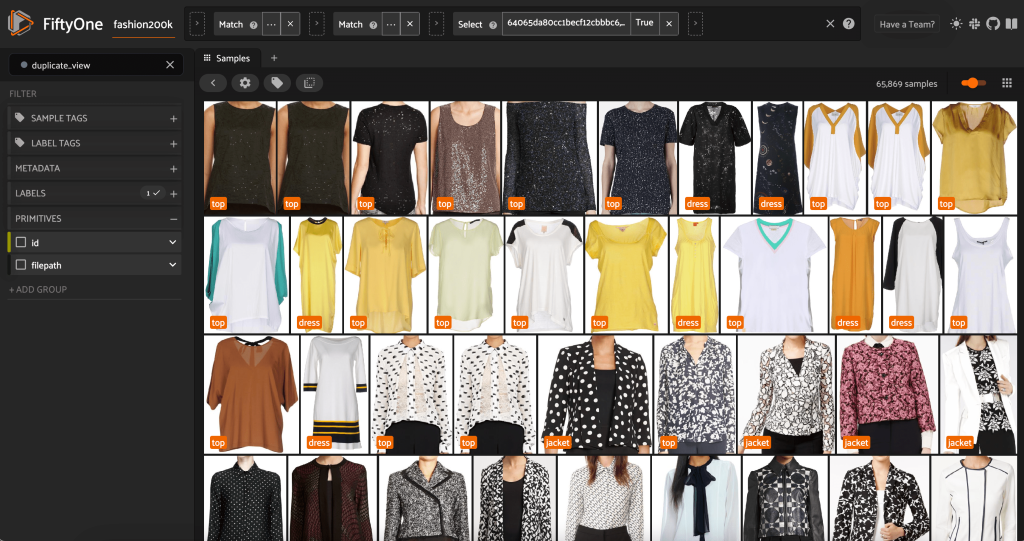
Ketika kita senang dengan hasilnya dan yakin bahwa gambar-gambar ini benar-benar mirip dengan duplikat, kita dapat memilih satu sampel dari setiap kumpulan sampel serupa untuk disimpan, dan mengabaikan yang lainnya:
Sekarang tampilan ini memiliki 3,729 gambar. Dengan membersihkan data dan mengidentifikasi subset berkualitas tinggi dari set data Fashion200K, FiftyOne memungkinkan kami membatasi fokus kami dari lebih dari 300,000 gambar menjadi hanya di bawah 4,000, yang berarti pengurangan sebesar 98%. Menggunakan penyematan untuk menghapus gambar yang hampir duplikat saja membuat jumlah total gambar kami yang dipertimbangkan turun lebih dari 90%, dengan sedikit efek jika ada pada model mana pun yang akan dilatih pada data ini.
Sebelum memberi label pada subset ini, kita dapat lebih memahami data dengan memvisualisasikan penyematan yang telah kita hitung. Kita bisa menggunakan built-in FiftyOne Brain compute_visualization() yang menggunakan teknik uniform manifold approximation (UMAP) untuk memproyeksikan vektor penyisipan 512 dimensi ke dalam ruang dua dimensi sehingga kita dapat memvisualisasikannya:
Kami membuka yang baru Panel penyematan di aplikasi FiftyOne dan mewarnai menurut jenis artikel, dan kita dapat melihat bahwa penyematan ini secara kasar menyandikan gagasan jenis artikel (antara lain!).
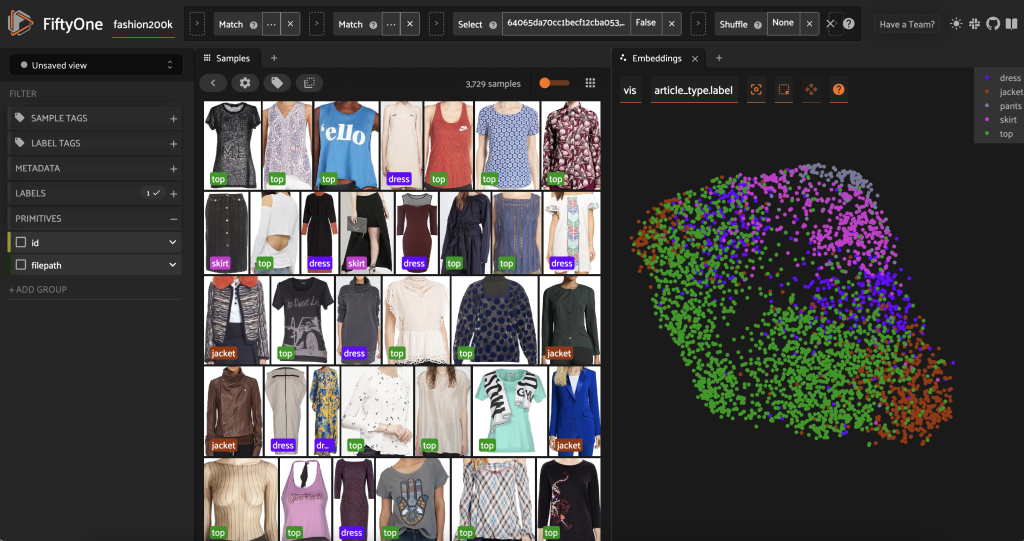
Sekarang kami siap memberi label awal pada data ini.
Dengan memeriksa gambar beresolusi tinggi yang sangat unik ini, kami dapat membuat daftar gaya awal yang layak untuk digunakan sebagai kelas dalam klasifikasi zero-shot pra-pelabelan kami. Tujuan kami dalam memberi label awal pada gambar-gambar ini tidak harus memberi label pada setiap gambar dengan benar. Sebaliknya, tujuan kami adalah memberikan titik awal yang baik bagi anotator manusia sehingga kami dapat mengurangi waktu dan biaya pelabelan.
Kami kemudian dapat membuat model klasifikasi zero-shot untuk aplikasi ini. Kami menggunakan model CLIP, yang merupakan model tujuan umum yang dilatih pada gambar dan bahasa alami. Kita membuat instance model CLIP dengan prompt teks "Clothing in the style", sehingga dengan gambar yang diberikan, model akan menampilkan kelas yang "Clothing in the style [class]" paling sesuai. CLIP tidak dilatih tentang data khusus ritel atau mode, jadi ini tidak akan sempurna, tetapi dapat menghemat biaya pelabelan dan anotasi.
Kami kemudian menerapkan model ini ke subset kami yang dikurangi dan menyimpan hasilnya dalam file article_style bidang:
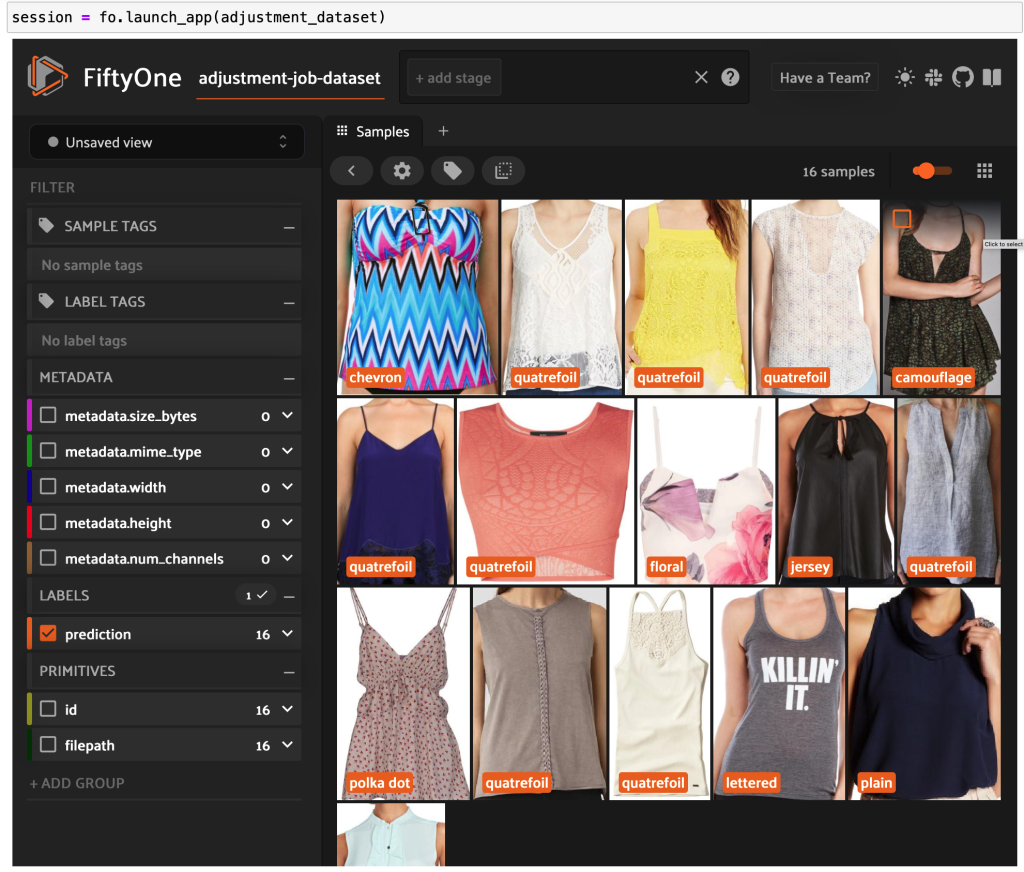
Meluncurkan Aplikasi FiftyOne sekali lagi, kami dapat memvisualisasikan gambar dengan label gaya yang diprediksi ini. Kami mengurutkan berdasarkan keyakinan prediksi sehingga kami melihat prediksi gaya paling percaya diri terlebih dahulu:
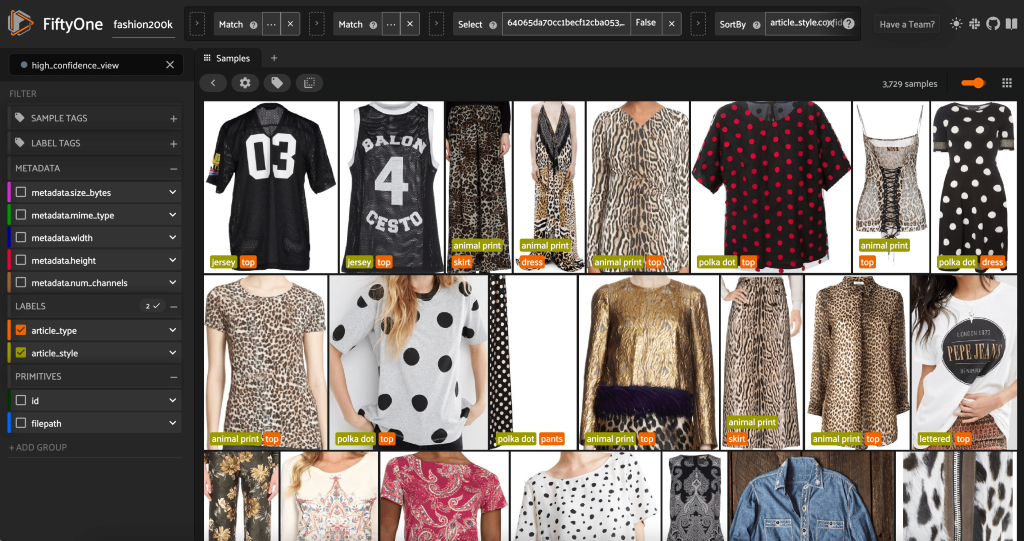
Kita dapat melihat bahwa prediksi kepercayaan tertinggi tampaknya untuk gaya "jersey", "animal print", "polka dot", dan "lettered". Ini masuk akal, karena gaya ini relatif berbeda. Sepertinya, sebagian besar, label gaya yang diprediksi akurat.
Kita juga dapat melihat prediksi gaya paling percaya diri:
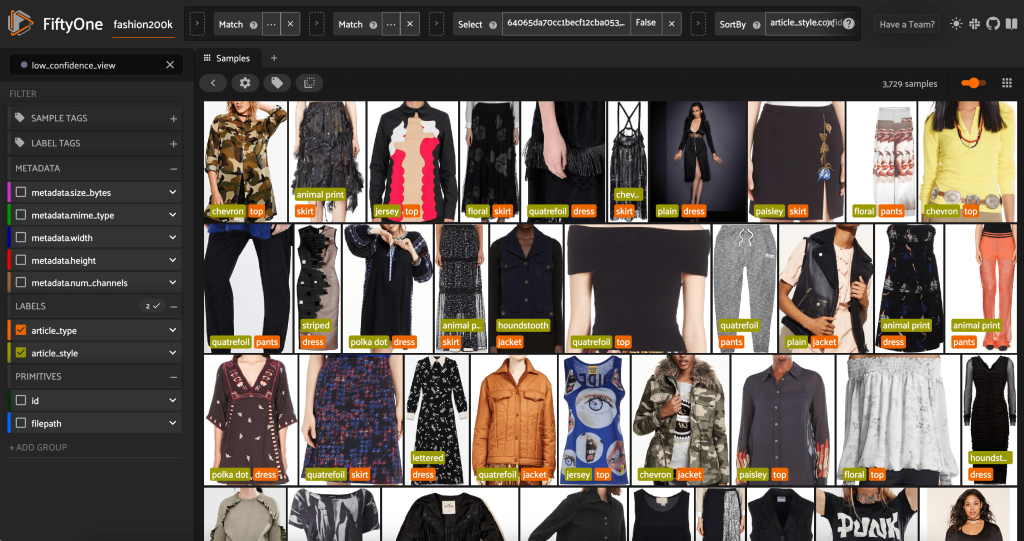
Untuk beberapa gambar ini, kategori gaya yang sesuai ada di daftar yang disediakan, dan artikel pakaian diberi label yang salah. Gambar pertama di grid, misalnya, harus jelas "kamuflase" dan bukan "chevron". Namun, dalam kasus lain, produk tidak cocok dengan kategori gaya. Gaun pada gambar kedua di baris kedua, misalnya, tidak benar-benar "bergaris", tetapi diberi opsi pelabelan yang sama, anotator manusia mungkin juga mengalami konflik. Saat kami membuat kumpulan data, kami perlu memutuskan apakah akan menghapus kasus tepi seperti ini, menambahkan kategori gaya baru, atau menambah kumpulan data.
Ekspor set data terakhir dari FiftyOne
Ekspor set data akhir dengan kode berikut:
Kami dapat mengekspor kumpulan data yang lebih kecil, misalnya 16 gambar, ke folder 200kFashionDatasetExportResult-16Images. Kami membuat pekerjaan penyesuaian Ground Truth dengan menggunakannya:
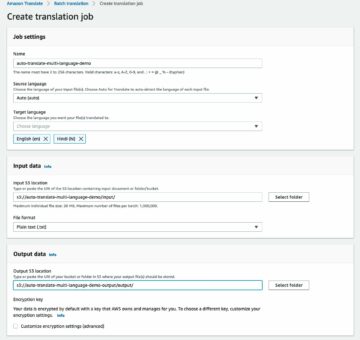
Unggah set data yang telah direvisi, konversikan format label ke Ground Truth, unggah ke Amazon S3, dan buat file manifes untuk tugas penyesuaian
Kita dapat mengonversi label dalam kumpulan data agar sesuai dengan skema manifes keluaran dari pekerjaan kotak pembatas Ground Truth, dan mengunggah gambar ke Layanan Penyimpanan Sederhana Amazon (Amazon S3) ember untuk meluncurkan a Pekerjaan penyesuaian Ground Truth:
Unggah file manifes ke Amazon S3 dengan kode berikut:
Buat label dengan gaya terkoreksi dengan Ground Truth
Untuk menganotasi data Anda dengan label gaya menggunakan Ground Truth, selesaikan langkah-langkah yang diperlukan untuk memulai pekerjaan pelabelan kotak pembatas dengan mengikuti prosedur yang diuraikan dalam Memulai dengan Kebenaran Dasar panduan dengan set data dalam bucket S3 yang sama.
- Di konsol SageMaker, buat tugas pelabelan Ground Truth.
- Mengatur Masukkan lokasi dataset menjadi manifes yang kita buat di langkah sebelumnya.
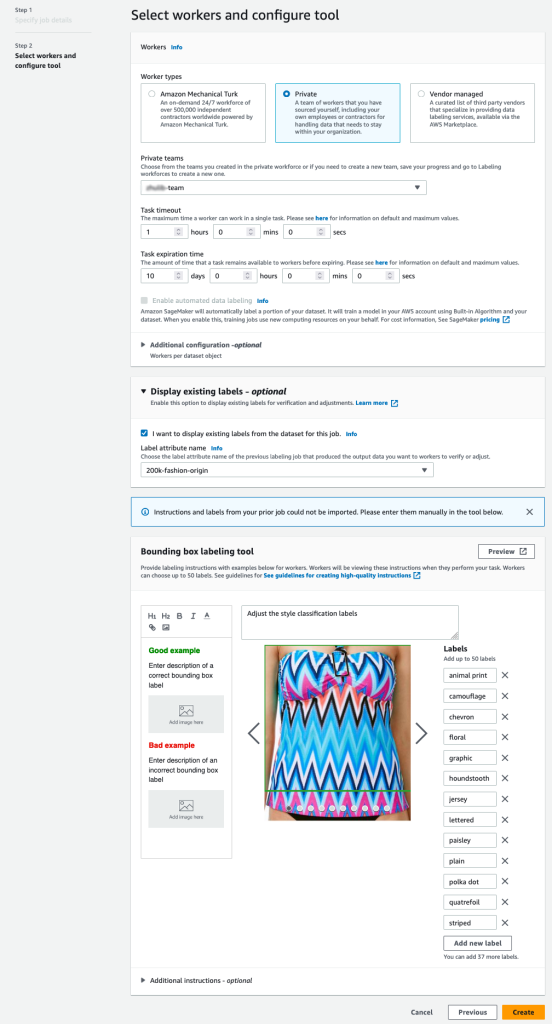
- Tentukan jalur S3 untuk Keluarkan lokasi set data.
- Untuk Peran IAM, pilih Masukkan peran IAM khusus RNA, lalu masukkan peran ARN.
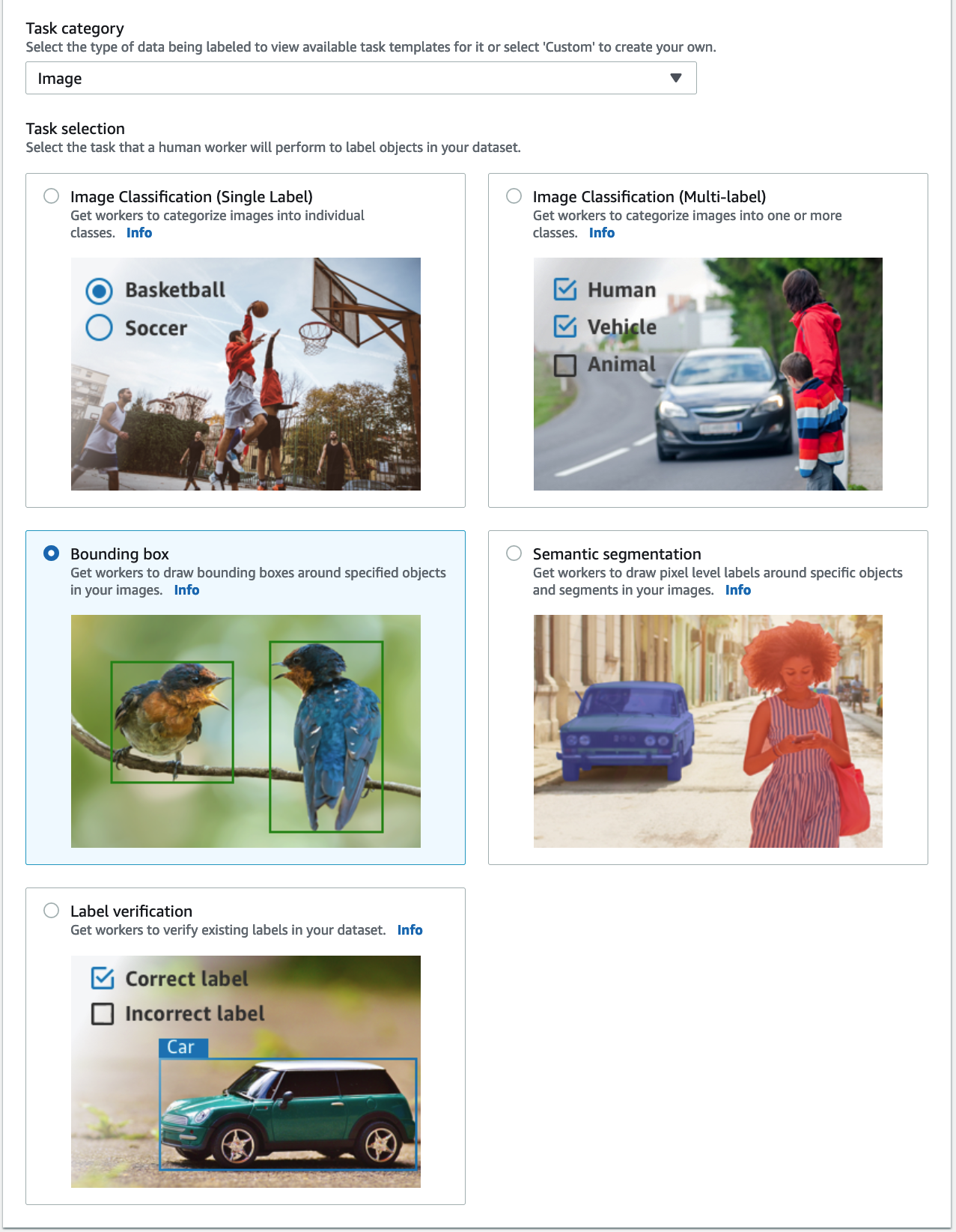
- Untuk Kategori tugas, pilih Gambar dan pilih kotak pembatas.
- Pilih Selanjutnya.
- Dalam majalah Pekerja bagian, pilih jenis tenaga kerja yang ingin Anda gunakan.
Anda dapat memilih tenaga kerja melalui Amazon Mechanical Turk, vendor pihak ketiga, atau tenaga kerja pribadi Anda sendiri. Untuk detail selengkapnya tentang opsi tenaga kerja Anda, lihat Buat dan Kelola Tenaga Kerja. - Lihat lebih lanjut Opsi tampilan label yang ada dan pilih Saya ingin menampilkan label yang ada dari kumpulan data untuk pekerjaan ini.
- Untuk Atribut label name, pilih nama dari manifes Anda yang sesuai dengan label yang ingin Anda tampilkan untuk penyesuaian.
Anda hanya akan melihat nama atribut label untuk label yang cocok dengan jenis tugas yang Anda pilih di langkah sebelumnya. - Masukkan label untuk secara manual Alat pelabelan kotak pembatas.
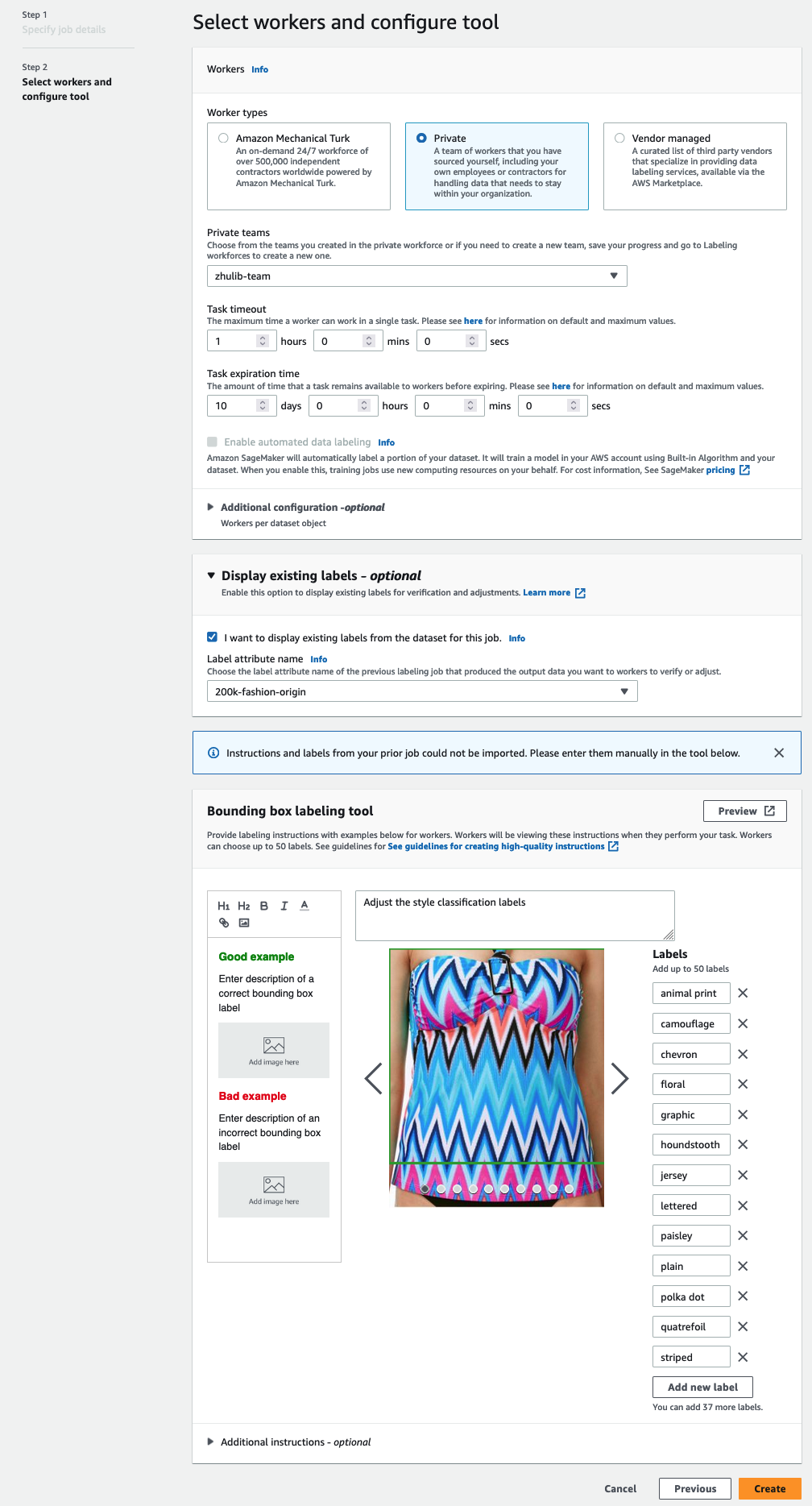 Label harus berisi label yang sama dengan yang digunakan dalam set data publik. Anda dapat menambahkan label baru. Tangkapan layar berikut menunjukkan bagaimana Anda dapat memilih pekerja dan mengonfigurasi alat untuk pekerjaan pelabelan Anda.
Label harus berisi label yang sama dengan yang digunakan dalam set data publik. Anda dapat menambahkan label baru. Tangkapan layar berikut menunjukkan bagaimana Anda dapat memilih pekerja dan mengonfigurasi alat untuk pekerjaan pelabelan Anda.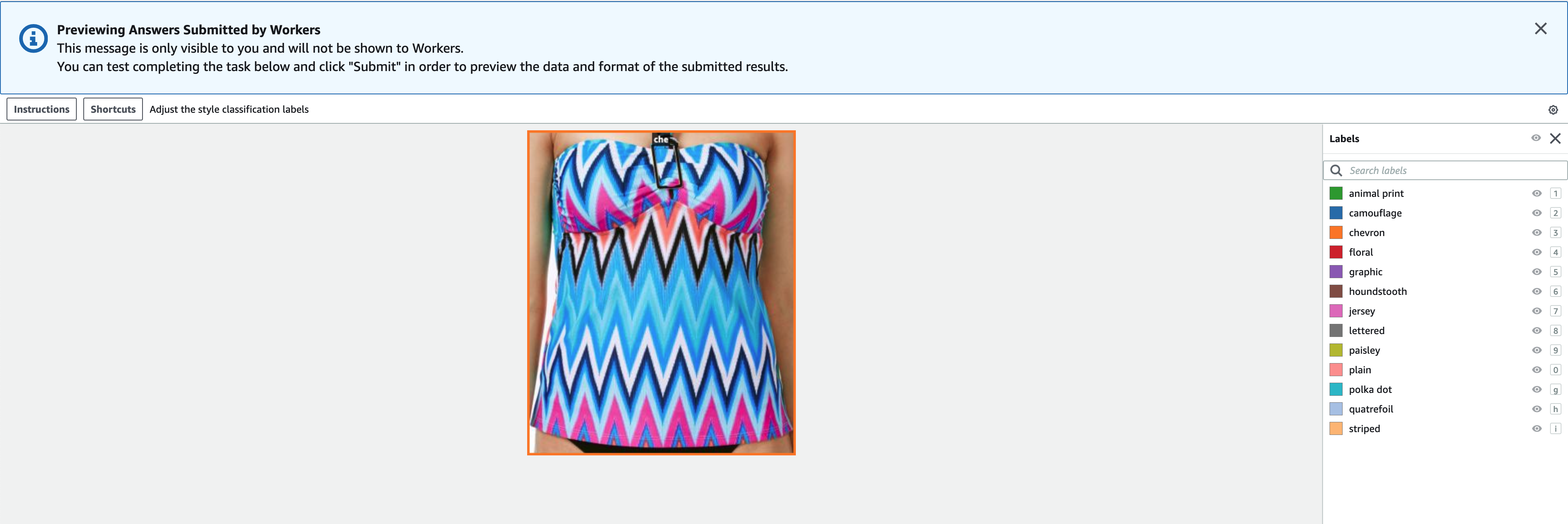
- Pilih Preview untuk mempratinjau gambar dan anotasi asli.
Kami sekarang telah membuat pekerjaan pelabelan di Ground Truth. Setelah pekerjaan kita selesai, kita dapat memuat data berlabel yang baru dibuat ke dalam FiftyOne. Ground Truth menghasilkan data keluaran dalam manifes keluaran Ground Truth. Untuk detail lebih lanjut tentang file manifes keluaran, lihat Keluaran Tugas Kotak Pembatas. Kode berikut menunjukkan contoh format manifes keluaran ini:
Tinjau hasil berlabel dari Ground Truth di FiftyOne
Setelah pekerjaan selesai, unduh manifes keluaran pekerjaan pelabelan dari Amazon S3.
Baca file manifes keluaran:
Buat set data FiftyOne dan ubah garis manifes menjadi sampel di set data:
Sekarang Anda dapat melihat data berlabel berkualitas tinggi dari Ground Truth di FiftyOne.
Kesimpulan
Dalam postingan ini, kami menunjukkan cara membuat kumpulan data berkualitas tinggi dengan menggabungkan kekuatan Lima puluh satu by voxel51, toolkit sumber terbuka yang memungkinkan Anda mengelola, melacak, memvisualisasikan, dan menyeleksi set data Anda, dan Ground Truth, layanan pelabelan data yang memungkinkan Anda memberi label secara efisien dan akurat pada set data yang diperlukan untuk melatih sistem ML dengan menyediakan akses ke beberapa perangkat bawaan -dalam templat tugas dan akses ke tenaga kerja yang beragam melalui Mechanical Turk, vendor pihak ketiga, atau tenaga kerja pribadi Anda sendiri.
Kami mendorong Anda untuk mencoba fungsi baru ini dengan memasang instans FiftyOne dan menggunakan konsol Ground Truth untuk memulai. Untuk mempelajari lebih lanjut tentang Ground Truth, lihat Data Label, FAQ Pelabelan Data Amazon SageMaker, Dan Blog Pembelajaran Mesin AWS.
Terhubung dengan Pembelajaran Mesin & komunitas AI jika Anda memiliki pertanyaan atau umpan balik!
Bergabunglah dengan komunitas FiftyOne!
Bergabunglah dengan ribuan insinyur dan ilmuwan data yang telah menggunakan FiftyOne untuk memecahkan beberapa masalah paling menantang dalam visi komputer saat ini!
Tentang Penulis
Shalendra Chabra saat ini adalah Kepala Manajemen Produk untuk Layanan Human-in-the-Loop (HIL) Amazon SageMaker. Sebelumnya, Shalendra menginkubasi dan memimpin Bahasa dan Kecerdasan Percakapan untuk Rapat Tim Microsoft, adalah EIR di Amazon Alexa Techstars Startup Accelerator, Wakil Presiden Produk dan Pemasaran di Diskusikan.io, Head of Product and Marketing di Clipboard (diakuisisi oleh Salesforce), dan Lead Product Manager di Swype (diakuisisi oleh Nuance). Secara total, Shalendra telah membantu membangun, mengirimkan, dan memasarkan produk yang telah menyentuh lebih dari satu miliar jiwa.
Yakub Marks adalah Insinyur Pembelajaran Mesin dan Penginjil Pengembang di Voxel51, di mana dia membantu menghadirkan transparansi dan kejelasan pada data dunia. Sebelum bergabung dengan Voxel51, Jacob mendirikan sebuah startup untuk membantu musisi baru terhubung dan berbagi konten kreatif dengan penggemar. Sebelumnya, dia bekerja di Google X, Samsung Research, dan Wolfram Research. Di kehidupan sebelumnya, Jacob adalah seorang ahli fisika teoretis, menyelesaikan PhD-nya di Stanford, di mana dia menyelidiki fase materi kuantum. Di waktu luangnya, Jacob suka memanjat, berlari, dan membaca novel fiksi ilmiah.
Jason Corso adalah salah satu pendiri dan CEO Voxel51, di mana dia mengarahkan strategi untuk membantu menghadirkan transparansi dan kejelasan pada data dunia melalui perangkat lunak fleksibel yang canggih. Dia juga seorang Profesor Robotika, Teknik Listrik, dan Ilmu Komputer di University of Michigan, di mana dia berfokus pada masalah mutakhir di persimpangan visi komputer, bahasa alami, dan platform fisik. Di waktu luangnya, Jason menikmati menghabiskan waktu bersama keluarganya, membaca, berada di alam bebas, bermain permainan papan, dan segala macam aktivitas kreatif.
Brian Moore adalah salah satu pendiri dan CTO Voxel51, di mana dia memimpin strategi dan visi teknis. Dia meraih gelar PhD di bidang Teknik Listrik dari University of Michigan, di mana penelitiannya difokuskan pada algoritme yang efisien untuk masalah pembelajaran mesin skala besar, dengan penekanan khusus pada aplikasi visi komputer. Di waktu luangnya, ia menikmati bulu tangkis, golf, hiking, dan bermain dengan kembarannya Yorkshire Terrier.
Zhu Ling Bai adalah Insinyur Pengembangan Perangkat Lunak di Amazon Web Services. Dia bekerja mengembangkan sistem terdistribusi skala besar untuk memecahkan masalah pembelajaran mesin.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoAiStream. Kecerdasan Data Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Mencetak Masa Depan bersama Adryenn Ashley. Akses Di Sini.
- Beli dan Jual Saham di Perusahaan PRE-IPO dengan PREIPO®. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/machine-learning/create-high-quality-datasets-with-amazon-sagemaker-ground-truth-and-fiftyone/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 000
- 1
- 10
- 11
- 110
- 13
- 14
- 20
- 200
- 2017
- 23
- 24
- 250
- 28
- 30
- 500
- 66
- 7
- 8
- 9
- a
- Tentang Kami
- mempercepat
- mempercepat
- akselerator
- mengakses
- tepat
- akurat
- diperoleh
- kegiatan
- menambahkan
- menambahkan
- alamat
- Disesuaikan
- Pengaturan
- Setelah
- lagi
- AI
- Alexa
- algoritma
- Semua
- memungkinkan
- sendirian
- sudah
- juga
- Amazon
- amazon alexa
- Amazon SageMaker
- Kebenaran Dasar Amazon SageMaker
- Amazon Web Services
- antara
- an
- menganalisa
- dan
- hewan
- Apa pun
- aplikasi
- Aplikasi
- aplikasi
- Mendaftar
- sesuai
- ADALAH
- diatur
- artikel
- artikel
- AS
- terkait
- At
- penulis
- jauh
- AWS
- mendasarkan
- berdasarkan
- BE
- karena
- menjadi
- menjadi
- sebelum
- di belakang
- dibalik layar
- makhluk
- Percaya
- TERBAIK
- Lebih baik
- antara
- Milyar
- papan
- Permainan papan
- TULANG
- Bootstrap
- kedua
- Kotak
- kotak
- Otak
- Istirahat
- membawa
- Terbawa
- anggaran belanja
- membangun
- Bangunan
- built-in
- tapi
- membeli
- by
- CAN
- Menangkap
- kasus
- kasus
- kategori
- Kategori
- ceo
- menantang
- menantang
- memeriksa
- Pilih
- kejelasan
- kelas
- kelas-kelas
- klasifikasi
- Pembersihan
- jelas
- Jelas
- klien
- Pendakian
- Penyelesaian
- lebih dekat
- pakaian
- Pakaian
- Co-founder
- kode
- menggabungkan
- menggabungkan
- perusahaan
- Melengkapi
- lengkap
- menyelesaikan
- menghitung
- komputer
- Komputer Ilmu
- Visi Komputer
- Aplikasi Visi Komputer
- kepercayaan
- yakin
- Terhubung
- pertimbangan
- Terdiri dari
- konsul
- mengandung
- Konten
- isi
- dikendalikan
- percakapan
- mengubah
- salinan
- Core
- dikoreksi
- berkorespondensi
- Biaya
- Biaya
- membuat
- dibuat
- Kreatif
- Surat kepercayaan
- CTO
- dikuratori
- kurasi
- Sekarang
- adat
- pelanggan
- pelanggan
- Memotong
- canggih
- data
- kumpulan data
- memutuskan
- mendemonstrasikan
- denim
- kedalaman
- deskripsi
- rincian
- Deteksi
- Pengembang
- berkembang
- Pengembangan
- berbeda
- langsung
- direktori
- Display
- berbeda
- didistribusikan
- sistem terdistribusi
- beberapa
- do
- Tidak
- Anjing
- melakukan
- dilakukan
- Dont
- DOT
- turun
- Download
- duplikat
- e
- setiap
- Mudah
- Tepi
- efek
- efisien
- efisien
- elektro
- embedding
- muncul
- tekanan
- mempekerjakan
- memberdayakan
- dienkapsulasi
- mendorong
- akhir
- insinyur
- Teknik
- Insinyur
- Enter
- Lingkungan Hidup
- persamaan
- penting
- mapan
- Eter (ETH)
- mengevaluasi
- Pengabar Injil
- persis
- contoh
- ada
- ekspor
- hampir
- keluarga
- penggemar
- umpan balik
- beberapa
- Fiksi
- bidang
- Fields
- File
- File
- menyaring
- penyaringan
- terakhir
- Pertama
- cocok
- fleksibel
- Fokus
- terfokus
- berfokus
- berikut
- Untuk
- bentuk
- format
- Untung
- Didirikan di
- empat
- Gratis
- dari
- sepenuhnya
- fungsi
- Games
- tujuan umum
- menghasilkan
- dihasilkan
- mendapatkan
- GitHub
- Memberikan
- diberikan
- tujuan
- golf
- baik
- lebih besar
- kisi
- Tanah
- Kelompok
- membimbing
- senang
- Memiliki
- he
- kepala
- tinggi
- membantu
- membantu
- bermanfaat
- membantu
- di sini
- berkualitas tinggi
- resolusi tinggi
- paling tinggi
- sangat
- mendaki
- -nya
- memegang
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTML
- http
- HTTPS
- manusia
- i
- IAM
- ID
- mengenali
- mengidentifikasi
- id
- if
- gambar
- gambar
- Dampak
- mengimpor
- meningkatkan
- in
- Di lain
- Termasuk
- salah
- diinkubasi
- informasi
- mulanya
- mulanya
- install
- Instalasi
- contoh
- sebagai gantinya
- instruksi
- Intelijen
- persimpangan
- ke
- IT
- NYA
- baju kaos
- Pekerjaan
- bergabung
- bersama
- json
- hanya
- Menjaga
- pemeliharaan
- label
- pelabelan
- Label
- bahasa
- besar-besaran
- jalankan
- peluncuran
- memimpin
- Memimpin
- BELAJAR
- pengetahuan
- paling sedikit
- Dipimpin
- meninggalkan
- Lets
- Perpustakaan
- Hidup
- 'like'
- Mungkin
- MEMBATASI
- Terbatas
- baris
- baris
- Daftar
- daftar
- Daftar
- sedikit
- hidup
- memuat
- melihat
- mencari
- Lot
- Rendah
- mesin
- Mesin belajar
- terbuat
- sihir
- membuat
- MEMBUAT
- mengelola
- berhasil
- pengelolaan
- manajer
- banyak
- peta
- Pasar
- Marketing
- Cocok
- sesuai
- secara material
- hal
- Mungkin..
- mekanis
- Media
- pertemuan
- meta
- Metadata
- metode
- metode
- Michigan
- Microsoft
- tim microsoft
- mungkin
- minimum
- ML
- mobil
- aplikasi ponsel
- model
- model
- Modul
- lebih
- paling
- pindah
- banyak
- beberapa
- musisi
- harus
- nama
- Bernama
- nama
- Alam
- Bahasa Alami
- Alam
- Dekat
- perlu
- perlu
- Perlu
- kebutuhan
- New
- tampak
- Gagasan
- sekarang
- Nuansa
- jumlah
- obyek
- Deteksi Objek
- objek
- of
- resmi
- on
- sekali
- ONE
- secara online
- hanya
- Buka
- open source
- Operasi
- Kesempatan
- Opsi
- or
- terorganisir
- asli
- OS
- Lainnya
- Lainnya
- kami
- di luar
- diuraikan
- keluaran
- lebih
- sendiri
- memiliki
- Paket
- dipasangkan
- bagian
- tertentu
- lalu
- path
- pola
- pola
- sempurna
- prestasi
- orang
- Personalized
- Fase Materi
- fisik
- memilih
- Film
- PLAID
- Polos
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- bermain
- Titik
- diisi
- mungkin
- Pos
- kekuasaan
- praktek
- diprediksi
- ramalan
- Prediksi
- Preview
- sebelumnya
- sebelumnya
- Mencetak
- Sebelumnya
- swasta
- mungkin
- masalah
- proses
- Produk
- manajemen Produk
- manajer produk
- Produk
- Profesor
- proyek
- milik
- bakal
- prototipe
- memberikan
- disediakan
- menyediakan
- publik
- pons
- tujuan
- Ular sanca
- Kuantum
- Pertanyaan
- segera
- jarak
- agak
- Bacaan
- siap
- sarankan
- rekomendasi
- menurunkan
- mengurangi
- pengurangan
- relatif
- dirilis
- relevan
- menghapus
- wakil
- mewakili
- wajib
- penelitian
- peneliti
- Resolusi
- membatasi
- mengakibatkan
- dihasilkan
- Hasil
- eceran
- kembali
- ulasan
- Membersihkan
- robotika
- kuat
- Peran
- kira-kira
- BARIS
- merusak
- berjalan
- pembuat bijak
- Tersebut
- tenaga penjualan
- sama
- Samsung
- Save
- adegan
- Ilmu
- Fiksi Ilmiah
- ilmuwan
- skor
- mulus
- Kedua
- Bagian
- bagian
- melihat
- terlihat
- tampaknya
- terpilih
- rasa
- terpisah
- layanan
- Layanan
- Sidang
- set
- Share
- dia
- harus
- Menunjukkan
- Pertunjukkan
- YA
- mirip
- Sederhana
- lebih kecil
- So
- Perangkat lunak
- pengembangan perangkat lunak
- MEMECAHKAN
- beberapa
- Seseorang
- sesuatu
- Space
- menghabiskan
- Pengeluaran
- membagi
- Berpisah
- Stanford
- awal
- mulai
- Mulai
- startup
- akselerator startup
- state-of-the-art
- Tangga
- Masih
- penyimpanan
- menyimpan
- Penyelarasan
- gaya
- gaya
- RINGKASAN
- Didukung
- sistem
- Mengambil
- tugas
- tim
- Teknis
- Bintang Teknologi
- mengatakan
- template
- uji
- dari
- bahwa
- Grafik
- mereka
- Mereka
- kemudian
- teoretis
- Sana.
- Ini
- mereka
- hal
- berpikir
- pihak ketiga
- ini
- ribuan
- ambang
- Melalui
- Pelemparan
- waktu
- untuk
- bersama
- alat
- toolkit
- puncak
- tingkat atas
- tops
- Total
- tersentuh
- jalur
- Pelatihan VE
- terlatih
- Pelatihan
- Mengubah
- Transparansi
- benar
- kebenaran
- MENGHIDUPKAN
- dua
- mengetik
- jenis
- bawah
- memahami
- unik
- universitas
- University of Michigan
- Memperbarui
- us
- menggunakan
- gunakan case
- bekas
- Pengguna
- Pengguna
- menggunakan
- Nilai - Nilai
- variasi
- berbagai
- vendor
- memeriksa
- sangat
- melalui
- View
- maya
- penglihatan
- ingin
- adalah
- we
- jaringan
- layanan web
- BAIK
- adalah
- Apa
- ketika
- apakah
- yang
- Wikipedia
- akan
- dengan
- dalam
- tanpa
- Wanita
- kata
- Kerja
- bekerja
- pekerja
- Tenaga kerja
- bekerja
- dunia
- kuatir
- akan
- menulis
- X
- kamu
- Anda
- zephyrnet.dll
- Zip
- KEBUN BINATANG