Suresh adalah seorang eksekutif teknologi dengan keahlian teknis yang mendalam di bidang semikonduktor, kecerdasan buatan, keamanan siber, internet-of-thing, perangkat keras, perangkat lunak, dll. Ia menghabiskan 20 tahun di industri ini, dan terakhir menjabat sebagai Direktur Eksekutif untuk open-source zero- memercayai pengembangan chip di Technology Innovation Institute, Abu Dhabi, dan di perusahaan semikonduktor Fortune 500 lainnya seperti Intel, Qualcomm, dan MediaTek dalam berbagai peran kepemimpinan, tempat ia meneliti dan mengembangkan perangkat berkinerja tinggi, hemat energi, aman pasca-kuantum, aman microchip/ system-on-chip (SoCs)/ akselerator untuk pasar Pusat Data, Klien, Ponsel Cerdas, Jaringan, IoT, dan AI/ML. Dia berkontribusi pada Falcon LLM (peringkat #1 dalam huggingface) dan merupakan arsitek utama untuk platform perangkat keras AI khusus (dibatalkan – prioritas diubah). Dia memegang 15+ Paten AS dan telah menerbitkan/mempresentasikan di lebih dari 20+ konferensi.
Suresh adalah seorang eksekutif teknologi dengan keahlian teknis yang mendalam di bidang semikonduktor, kecerdasan buatan, keamanan siber, internet-of-thing, perangkat keras, perangkat lunak, dll. Ia menghabiskan 20 tahun di industri ini, dan terakhir menjabat sebagai Direktur Eksekutif untuk open-source zero- memercayai pengembangan chip di Technology Innovation Institute, Abu Dhabi, dan di perusahaan semikonduktor Fortune 500 lainnya seperti Intel, Qualcomm, dan MediaTek dalam berbagai peran kepemimpinan, tempat ia meneliti dan mengembangkan perangkat berkinerja tinggi, hemat energi, aman pasca-kuantum, aman microchip/ system-on-chip (SoCs)/ akselerator untuk pasar Pusat Data, Klien, Ponsel Cerdas, Jaringan, IoT, dan AI/ML. Dia berkontribusi pada Falcon LLM (peringkat #1 dalam huggingface) dan merupakan arsitek utama untuk platform perangkat keras AI khusus (dibatalkan – prioritas diubah). Dia memegang 15+ Paten AS dan telah menerbitkan/mempresentasikan di lebih dari 20+ konferensi.
Suresh juga aktif menduduki posisi kepemimpinan di RISC-V International di mana ia mengetuai Trusted Computing Group untuk mengembangkan kemampuan komputasi rahasia RISC-V dan memimpin AI/ML Group untuk mengembangkan akselerasi perangkat keras RISC-V untuk beban kerja AI/ML seperti Model Bahasa Besar Transformer yang digunakan dalam jenis aplikasi ChatGPT. Ia juga memberikan nasihat kepada perusahaan rintisan dan modal ventura mengenai dukungan keputusan investasi, strategi produk, uji tuntas teknologi, dan lain-lain.
Beliau memperoleh gelar MBA dari INSEAD, gelar MS dari Birla Institute of Technology & Science Pilani, sertifikat Systems Engineering dari MIT, sertifikat AI dari Stanford, dan sertifikat keselamatan fungsional otomotif dari TÜV SÜD.
Beritahu kami tentang perusahaan Anda
"Mastiṣka AI” (Mastiṣka berarti Otak dalam bahasa Sansekerta) adalah perusahaan AI yang berfokus pada pembuatan komputer mirip otak untuk menjalankan model dasar secara lebih efisien untuk kasus penggunaan AI Generatif di masa depan.
Masalah apa yang Anda pecahkan?
Mengingat manfaat AI/GenAI, permintaan akan teknologi ini pasti akan meningkat, begitu pula dampak sampingnya terhadap planet kita. Bagaimana kita bisa mengurangi atau menetralisir efek samping AI terhadap planet kita? Penangkapan karbon dan tenaga nuklir berada pada arah yang benar. Namun kita perlu memikirkan kembali secara mendasar cara kita melakukan AI, apakah ini cara yang salah dalam melakukan banyak perkalian matriks?
Otak kita dapat belajar dan melakukan banyak tugas secara paralel, dengan daya di bawah 10W, tetapi mengapa sistem AI ini mengonsumsi 10 megawatt untuk melatih model?
Mungkin di masa depan akan ada arsitektur hemat energi seperti arsitektur neuromorfik dan trafo berbasis jaringan saraf spiking yang paling dekat dengan otak manusia, yang mungkin mengonsumsi energi 100-1000x lebih rendah, sehingga mengurangi biaya penggunaan AI, sehingga mendemokratisasikannya dan menyelamatkan kita. planet.
Tantangan yang kita hadapi saat ini dengan AI yaitu a) ketersediaan, b) aksesibilitas, c) keterjangkauan, dan d) keamanan lingkungan serta beberapa rekomendasi untuk mengatasinya.
Jika kita meramalkan di masa depan, beberapa konsep AGI yang berguna ditunjukkan dalam film “HER”, di mana karakter 'Samantha' – agen percakapan yang alami, memahami emosi, menunjukkan empati, adalah kopilot yang luar biasa di tempat kerja – dan terus berlari perangkat genggam sepanjang hari, maka kita mungkin harus mengatasi tantangan di bawah ini sekarang.
Masalah 1: Pelatihan LLM dapat menghabiskan biaya mulai dari 150K hingga 10+ juta dolar, dan hanya memungkinkan mereka yang berkantong tebal untuk mengembangkan AI. Selain itu, biaya penyimpulan juga sangat besar (biayanya 10x lebih mahal dibandingkan penelusuran web)
—> Kita perlu meningkatkan efisiensi energi model/perangkat keras untuk mendemokratisasi AI demi kepentingan umat manusia.
Masalah 2: Menjalankan model AI yang sangat besar untuk agen percakapan atau sistem rekomendasi, berdampak buruk pada lingkungan dalam hal konsumsi listrik dan pendinginan.
—> Kita perlu meningkatkan efisiensi energi model/perangkat keras untuk menyelamatkan planet kita demi anak-anak kita.
Masalah 3: Otak manusia mampu dan dapat melakukan banyak tugas, namun hanya mengkonsumsi 10 Watt, bukan Megawatt.
—> Mungkin kita harus membuat mesin seperti otak kita dan bukan pengganda matriks biasa dengan lebih cepat.
Kemanusiaan hanya bisa berkembang melalui inovasi yang berkelanjutan, dan bukan dengan menebang habis hutan dan merebus lautan atas nama inovasi. Kita harus melindungi planet kita demi kesejahteraan anak-anak kita dan generasi mendatang…
Area aplikasi apa yang paling kuat?
Pelatihan dan Inferensi model fondasi berbasis Transformer (dan arsitektur saraf masa depan), dengan efisiensi energi 50-100x lebih banyak dibandingkan dengan solusi berbasis GPU saat ini.
Apa yang membuat pelanggan Anda terjaga di malam hari?
Masalah bagi pelanggan yang saat ini menggunakan produk lain:
Konsumsi listrik untuk melatih model bahasa raksasa sangat tinggi, misalnya, melatih LLM parameter 13 miliar pada token teks 390 miliar pada 200 GPU selama 7 hari memerlukan biaya $151,744 (Sumber: halaman layanan cluster pelatihan baru HuggingFace – https://lnkd.in/g6Vc5cz3). Dan model yang lebih besar dengan parameter 100+B berharga $10+M hanya untuk pelatihan. Kemudian bayar untuk menyimpulkan setiap kali permintaan cepat baru tiba.
Konsumsi air untuk pendinginan, para peneliti di University of California, Riverside memperkirakan dampak lingkungan dari layanan mirip ChatGPT, dan mengatakan layanan tersebut menelan 500 mililiter air (mendekati isi botol air 16 ons) setiap kali Anda memintanya. serangkaian antara 5 hingga 50 petunjuk atau pertanyaan. Kisarannya bervariasi tergantung lokasi servernya dan musim. Perkiraan tersebut mencakup penggunaan air tidak langsung yang tidak diukur oleh perusahaan – seperti untuk mendinginkan pembangkit listrik yang memasok listrik ke pusat data. (Sumber: https://lnkd.in/gybcxX8C)
Masalah bagi non-pelanggan produk saat ini:
Tidak mampu membeli CAPEX untuk membeli perangkat keras
Tidak mampu menggunakan layanan cloud
Tidak dapat berinovasi atau memanfaatkan AI — terjebak dengan model layanan yang menghilangkan keunggulan kompetitif apa pun
Seperti apa lanskap kompetitif itu dan bagaimana Anda membedakannya?
- GPU mendominasi ruang pelatihan, meskipun ASIC khusus juga bersaing di segmen ini
- Inferensi Cloud & Edge memiliki terlalu banyak opsi yang tersedia
Digital, Analog, Fotonik — sebut saja, orang-orang mencoba mengatasi masalah yang sama.
Bisakah Anda menyampaikan pendapat Anda tentang kondisi arsitektur chip untuk AI/ML saat ini. Artinya, apa yang Anda lihat sebagai tren dan peluang paling signifikan saat ini?
Tren berikut:
Tren 1: 10 tahun yang lalu, pembelajaran mendalam yang didukung perangkat keras berkembang pesat, dan kini perangkat keras yang sama menghambat kemajuan. Karena tingginya biaya perangkat keras dan biaya listrik untuk menjalankan model, mengakses perangkat keras menjadi tantangan. Hanya perusahaan berkantong tebal yang mampu membelinya dan menjadi monopoli.
Tren 2: Kini setelah model-model ini tersedia, kita perlu menggunakannya untuk tujuan praktis sehingga beban inferensi akan meningkat, sehingga CPU dengan akselerator AI kembali menjadi pusat perhatian.
Tren 3: Startup mencoba menghasilkan representasi angka floating point alternatif yang format IEEE tradisional – seperti berbasis logaritmik dan posit – sudah bagus tetapi tidak cukup. Pengoptimalan ruang desain PPA$ meledak ketika kami mencoba mengoptimalkan satu dan yang lainnya gagal.
Tren 4: Industri ini beralih dari model AI berbasis layanan ke hosting model pribadi di lokasi mereka sendiri — namun akses terhadap perangkat keras merupakan sebuah tantangan karena kekurangan pasokan, sanksi, dan lain-lain.
Keadaan saat ini:
Ketersediaan perangkat keras dan data mendorong pertumbuhan AI 10 tahun yang lalu, namun sekarang perangkat keras yang sama menghambatnya — izinkan saya menjelaskannya
Sejak kinerja CPU buruk dan GPU diubah fungsinya menjadi AI, banyak hal terjadi
Perusahaan telah menangani 4 segmen AI/ML yaitu – 1) pelatihan cloud, 2) inferensi cloud, 3) inferensi tepi, dan 4) pelatihan tepi (pembelajaran gabungan untuk aplikasi yang sensitif terhadap privasi).
Digital & Analog
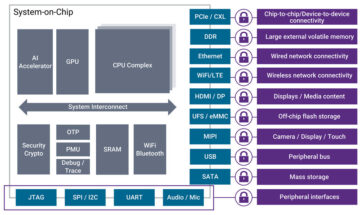
Sisi pelatihan – banyak perusahaan yang memproduksi GPU, akselerator pelanggan berdasarkan RISC-V, chip skala wafer (850 ribu inti), dan sebagainya yang tidak dimiliki CPU tradisional (tujuan umumnya). Sisi inferensi – Akselerator NN tersedia dari setiap produsen, di ponsel cerdas, laptop, dan perangkat edge lainnya.
Arsitektur berbasis memristor analog juga muncul beberapa waktu lalu.
Kami yakin CPU bisa membuat kesimpulan dengan sangat baik jika kami meningkatkannya dengan akselerasi seperti ekstensi matriks
Sisi RISC-V:
Di sisi RISC-V, kami sedang mengembangkan akselerator untuk operasi matriks dan operasi non-linier lainnya guna menghilangkan kemungkinan kemacetan pada beban kerja transformator. Kemacetan Von Neumann juga diatasi dengan merancang memori yang lebih dekat dengan komputasi, yang pada akhirnya menjadikan CPU dengan akselerasi AI sebagai pilihan yang tepat untuk melakukan inferensi.
Peluang:
Ada peluang unik untuk mengisi pasar model pondasi. Contoh – OpenAI telah menyebutkan bahwa mereka tidak dapat mengamankan komputasi AI (GPU) yang cukup untuk terus mendorong layanan ChatGPT mereka… dan berita melaporkan tentang biaya listrik sebesar 10x lipat dari biaya pencarian internet biasa dan 500ml air untuk mendinginkan sistem untuk setiap permintaan. Ada pasar yang harus diisi di sini — ini bukan pasar khusus, namun keseluruhan pasar yang akan mendemokratisasi AI dengan mengatasi semua tantangan yang disebutkan di atas – a) ketersediaan, b) aksesibilitas, c) keterjangkauan, dan d) keamanan lingkungan
Fitur/teknologi baru apa yang sedang Anda kerjakan?
Kami sedang membangun otak seperti komputer yang memanfaatkan teknologi neuromodrphic dan menyesuaikan model untuk memanfaatkan perangkat keras yang hemat energi, menggunakan kembali kerangka kerja terbuka yang tersedia
Bagaimana Anda membayangkan sektor AI/ML tumbuh atau berubah dalam 12-18 bulan ke depan?
Karena permintaan akan GPU yang menurun (harganya sekitar $30K) dan beberapa negara di dunia menghadapi sanksi untuk membeli GPU ini, beberapa negara merasa mereka terhenti dalam penelitian dan pengembangan AI tanpa akses ke GPU. Platform perangkat keras alternatif akan merebut pasar.
Model mungkin akan mulai menyusut — model khusus atau bahkan secara mendasar kepadatan informasi akan bertambah
Pertanyaan yang sama tapi bagaimana dengan pertumbuhan dan perubahan dalam 3-5 tahun ke depan?
a) CPU dengan ekstensi AI akan menangkap pasar inferensi AI
b) Model akan menjadi gesit, dan parameter akan hilang seiring peningkatan kepadatan informasi dari 16% menjadi 90%
c) Efisiensi energi meningkat, jejak CO2 berkurang
d) Arsitektur baru bermunculan
e) biaya perangkat keras dan energi turun sehingga hambatan masuk bagi perusahaan kecil untuk membuat dan melatih model menjadi terjangkau
f) orang-orang berbicara tentang momen sebelum AGI, tetapi tolok ukur saya adalah karakter Samantha (AI percakapan) dalam film “dia”.. yang mungkin tidak mungkin mengingat tingginya biaya untuk meningkatkannya
Apa saja tantangan yang dapat berdampak atau membatasi pertumbuhan sektor AI/ML?
a) Akses ke perangkat keras
b) Biaya energi dan biaya pendinginan serta kerusakan lingkungan
Baca Juga:
Wawancara CEO: David Moore dari Pragmatic
Wawancara CEO: Dr. Meghali Chopra dari Sandbox Semiconductor
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://semiwiki.com/ceo-interviews/338703-ceo-interview-suresh-sugumar-of-mastiska-ai/
- :memiliki
- :adalah
- :bukan
- :Di mana
- $NAIK
- 1
- 10
- 150
- 20
- 20 tahun
- 200
- 50
- 500
- 7
- a
- Sanggup
- Tentang Kami
- atas
- abu dhabi
- percepatan
- akselerator
- mengakses
- aksesibilitas
- aktif
- alamat
- dialamatkan
- menangani
- Keuntungan
- Urusan
- lagi
- Agen
- agen
- AGI
- silam
- AI
- Model AI
- ai penelitian
- Sistem AI
- saya menggunakan kasus
- AI / ML
- selaras
- Semua
- Membiarkan
- memungkinkan
- sepanjang
- juga
- alternatif
- menakjubkan
- an
- dan
- Lain
- Apa pun
- di manapun
- Aplikasi
- aplikasi
- arsitektur
- ADALAH
- daerah
- Tiba
- buatan
- kecerdasan buatan
- AS
- Asics
- meminta
- At
- otomotif
- tersedianya
- tersedia
- jauh
- b
- pembatas
- berdasarkan
- BE
- menjadi
- menjadi
- menjadi
- menjadi
- makhluk
- Percaya
- di bawah
- patokan
- manfaat
- Manfaat
- antara
- Luar
- kemacetan
- terikat
- Otak
- otak
- membangun
- Bangunan
- tapi
- membeli
- by
- california
- CAN
- dibatalkan
- kemampuan
- mampu
- modal
- menangkap
- karbon
- menangkap karbon
- kasus
- Pusat
- ceo
- Wawancara CEO
- sertifikat
- menantang
- tantangan
- perubahan
- berubah
- mengubah
- karakter
- ChatGPT
- anak-anak
- keping
- Keripik
- pilihan
- Chopra
- klien
- Penyelesaian
- lebih dekat
- awan
- Kelompok
- co2
- bagaimana
- Perusahaan
- perusahaan
- dibandingkan
- bersaing
- kompetitif
- menghitung
- komputer
- komputer
- komputasi
- konsep
- konferensi
- memakan
- konsumsi
- terus
- berkontribusi
- percakapan
- AI percakapan
- dingin
- Biaya
- Biaya
- bisa
- membuat
- terbaru
- Kondisi saat ini
- Sekarang
- adat
- pelanggan
- pelanggan
- pemotongan
- Keamanan cyber
- data
- Pusat Data
- Datacenter
- David
- hari
- Hari
- keputusan
- mendalam
- belajar mendalam
- lebih dalam
- Permintaan
- mendemokrasikan
- Demokratisasi
- menunjukkan
- kepadatan
- Tergantung
- Mendesain
- mengembangkan
- dikembangkan
- berkembang
- Pengembangan
- Devices
- Dhabi
- membedakan
- ketekunan
- arah
- Kepala
- do
- tidak
- melakukan
- dolar
- Dont
- turun
- dr
- Menjatuhkan
- dua
- memperoleh
- Tepi
- efek
- efisiensi
- efisien
- efisien
- listrik
- penggunaan listrik
- menghapuskan
- menghilangkan
- emosi
- empati
- energi
- efisiensi energi
- Teknik
- mempertinggi
- cukup
- Seluruh
- masuk
- Lingkungan Hidup
- lingkungan
- membayangkan
- memperkirakan
- diperkirakan
- dll
- Eter (ETH)
- Bahkan
- akhirnya
- Setiap
- contoh
- eksekutif
- Direktur Eksekutif
- ada
- keahlian
- Meledak
- ekstensi
- Menghadapi
- menghadapi
- elang
- lebih cepat
- perasaan
- mengisi
- perusahaan
- mengambang
- terfokus
- Kaki
- Untuk
- meramalkan
- format
- Nasib
- Prinsip Dasar
- kerangka
- dari
- beku
- didorong
- fungsionil
- secara fundamental
- masa depan
- Umum
- Generasi
- generatif
- AI generatif
- diberikan
- Go
- Pergi
- akan
- baik
- GPU
- Kelompok
- Pertumbuhan
- Pertumbuhan
- Perangkat keras
- Memiliki
- he
- karenanya
- di sini
- High
- memegang
- tuan
- Seterpercayaapakah Olymp Trade? Kesimpulan
- HTTPS
- besar
- MemelukWajah
- manusia
- Kemanusiaan
- IEEE
- if
- gambar
- Dampak
- memperbaiki
- meningkatkan
- in
- Di lain
- termasuk
- Meningkatkan
- industri
- informasi
- berinovasi
- Innovation
- inovasi
- sebagai gantinya
- Lembaga
- Intel
- Intelijen
- Internasional
- Internet
- Wawancara
- investasi
- idiot
- IT
- NYA
- hanya
- anak
- Jenis
- Kekurangan
- pemandangan
- bahasa
- laptop
- besar
- lebih besar
- memimpin
- Kepemimpinan
- BELAJAR
- pengetahuan
- membiarkan
- Leverage
- leveraging
- 'like'
- pusat perhatian
- MEMBATASI
- memuat
- terletak
- melihat
- terlihat seperti
- menurunkan
- Mesin
- Membuat
- Pabrikan
- banyak
- Pasar
- pasar
- Matriks
- max-width
- Mungkin..
- mungkin
- MBA
- me
- makna
- cara
- mengukur
- kenangan
- tersebut
- mungkin
- juta
- juta dolar
- MIT
- model
- model
- saat
- monopoli
- bulan
- lebih
- paling
- film
- bergerak
- MS
- harus
- my
- nama
- yaitu
- Alam
- Perlu
- berbasis jaringan
- jaringan
- saraf
- New
- berita
- berikutnya
- ceruk
- malam
- gesit
- sekarang
- nuklir
- Daya nuklir
- jumlah
- lautan
- of
- on
- ONE
- hanya
- Buka
- open source
- OpenAI
- Operasi
- Peluang
- optimasi
- Optimize
- Opsi
- or
- Lainnya
- kami
- di luar
- sendiri
- halaman
- Paralel
- parameter
- parameter
- bagian
- Paten
- Membayar
- Konsultan Ahli
- mungkin
- planet
- tanaman
- Platform
- Platform
- plato
- Kecerdasan Data Plato
- Data Plato
- kebanyakan
- plus
- saku
- Titik
- posisi
- mungkin
- kekuasaan
- pembangkit listrik
- Praktis
- Mencetak
- swasta
- Masalah
- masalah
- Produk
- Produk
- Profil
- Kemajuan
- meminta
- melindungi
- tujuan
- tujuan
- Dorong
- Menempatkan
- Qualcomm
- pertanyaan
- Pertanyaan
- jarak
- peringkat
- Baca
- baru-baru ini
- Rekomendasi
- rekomendasi
- menurunkan
- mengurangi
- reguler
- laporan
- permintaan
- penelitian
- penelitian dan pengembangan
- peneliti
- benar
- Tepi sungai
- peran
- atap
- Run
- berjalan
- berjalan
- aman
- Safety/keselamatan
- sama
- Sanksi
- bak pasir
- Save
- penghematan
- mengatakan
- skala
- Ilmu
- Pencarian
- Musim
- sektor
- aman
- melihat
- segmen
- semikonduktor
- Semikonduktor
- Seri
- server
- layanan
- Layanan
- porsi
- Share
- kekurangan
- harus
- menunjukkan
- Pertunjukkan
- sisi
- penting
- sejak
- lebih kecil
- smartphone
- smartphone
- So
- Perangkat lunak
- Solusi
- Memecahkan
- beberapa
- sumber
- Space
- khusus
- menghabiskan
- Stanford
- awal
- Startups
- Negara
- Penyelarasan
- terkuat
- seperti itu
- menyediakan
- mendukung
- berkelanjutan
- sistem
- memecahkan
- mengatasi
- jahitan
- Mengambil
- Berbicara
- tugas
- Teknis
- Teknologi
- inovasi teknologi
- istilah
- teks
- dari
- bahwa
- Grafik
- Masa depan
- informasi
- Dunia
- mereka
- Mereka
- kemudian
- Sana.
- dengan demikian
- Ini
- mereka
- hal
- ini
- itu
- meskipun?
- Berkembang
- waktu
- untuk
- hari ini
- Token
- besok
- terlalu
- puncak
- lemparan
- tradisional
- Pelatihan VE
- Pelatihan
- transformator
- transformer
- Tren
- Terpercaya
- mencoba
- mencoba
- bawah
- mengerti
- universitas
- University of California
- mungkin
- us
- penggunaan
- menggunakan
- bekas
- menggunakan
- berbagai
- usaha
- modal ventura
- Perusahaan modal ventura
- sangat
- dari
- adalah
- air
- Cara..
- we
- jaringan
- kesejahteraan
- adalah
- Apa
- ketika
- yang
- SIAPA
- mengapa
- akan
- dengan
- tanpa
- Kerja
- kerja
- dunia
- akan
- Salah
- tahun
- kamu
- Anda
- zephyrnet.dll