Menemukan kolom serupa di a danau data memiliki aplikasi penting dalam pembersihan dan anotasi data, pencocokan skema, penemuan data, dan analitik di berbagai sumber data. Ketidakmampuan untuk secara akurat menemukan dan menganalisis data dari sumber yang berbeda merupakan potensi pembunuh efisiensi bagi semua orang mulai dari ilmuwan data, peneliti medis, akademisi, hingga analis keuangan dan pemerintah.
Solusi konvensional melibatkan pencarian kata kunci leksikal atau pencocokan ekspresi reguler, yang rentan terhadap masalah kualitas data seperti nama kolom yang tidak ada atau konvensi penamaan kolom yang berbeda di berbagai kumpulan data (misalnya, zip_code, zcode, postalcode).
Dalam posting ini, kami mendemonstrasikan solusi untuk mencari kolom serupa berdasarkan nama kolom, konten kolom, atau keduanya. Solusinya menggunakan perkiraan algoritma tetangga terdekat tersedia di Layanan Pencarian Terbuka Amazon untuk mencari kolom yang mirip secara semantik. Untuk memfasilitasi pencarian, kami membuat representasi fitur (embeddings) untuk masing-masing kolom di data lake menggunakan model Transformer terlatih dari pustaka pengubah kalimat in Amazon SageMaker. Terakhir, untuk berinteraksi dengan dan memvisualisasikan hasil dari solusi kami, kami membuat sebuah interaktif merampingkan aplikasi web berjalan Fargate AWS.
Kami menyertakan a tutorial kode bagi Anda untuk menyebarkan sumber daya untuk menjalankan solusi pada data sampel atau data Anda sendiri.
Ikhtisar solusi
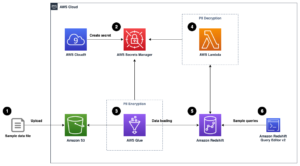
Diagram arsitektur berikut mengilustrasikan alur kerja dua tahap untuk menemukan kolom yang mirip secara semantik. Tahap pertama berjalan an Fungsi Langkah AWS alur kerja yang membuat penyematan dari kolom tabular dan membangun indeks pencarian Layanan OpenSearch. Tahap kedua, atau tahap inferensi online, menjalankan aplikasi Streamlit melalui Fargate. Aplikasi web mengumpulkan kueri penelusuran masukan dan mengambil dari indeks Layanan OpenSearch perkiraan kolom k-paling mirip dengan kueri.

Gambar 1. Arsitektur solusi
Alur kerja otomatis berlangsung dalam langkah-langkah berikut:
- Pengguna mengunggah kumpulan data tabular ke dalam file Layanan Penyimpanan Sederhana Amazon (Amazon S3) bucket, yang memanggil an AWS Lambda fungsi yang memulai alur kerja Step Functions.
- Alur kerja dimulai dengan Lem AWS pekerjaan yang mengubah file CSV menjadi Parket Apache format data.
- Tugas Pemrosesan SageMaker membuat penyematan untuk setiap kolom menggunakan model yang telah dilatih sebelumnya atau model penyematan kolom kustom. Pekerjaan Pemrosesan SageMaker menyimpan penyematan kolom untuk setiap tabel di Amazon S3.
- Fungsi Lambda membuat domain dan klaster Layanan OpenSearch untuk mengindeks penyematan kolom yang dihasilkan pada langkah sebelumnya.
- Terakhir, aplikasi web Streamlit interaktif diterapkan dengan Fargate. Aplikasi web menyediakan antarmuka bagi pengguna untuk memasukkan kueri guna mencari domain Layanan OpenSearch untuk kolom serupa.
Anda dapat mengunduh tutorial kode dari GitHub untuk mencoba solusi ini pada data sampel atau data Anda sendiri. Petunjuk tentang cara menerapkan sumber daya yang diperlukan untuk tutorial ini tersedia di Github.
Prasyarat
Untuk mengimplementasikan solusi ini, Anda memerlukan yang berikut ini:
- An Akun AWS.
- Keakraban dasar dengan layanan AWS seperti Kit Pengembangan AWS Cloud (AWS CDK), Lambda, Layanan OpenSearch, dan Pemrosesan SageMaker.
- Kumpulan data tabular untuk membuat indeks penelusuran. Anda dapat membawa data tabel Anda sendiri atau mengunduh kumpulan data sampel di GitHub.
Membangun indeks pencarian
Tahap pertama membangun kolom indeks mesin pencari. Gambar berikut mengilustrasikan alur kerja Step Functions yang menjalankan tahapan ini.

Gambar 2 – Alur kerja fungsi langkah – beberapa model penyematan
Dataset
Dalam posting ini, kami membuat indeks pencarian untuk menyertakan lebih dari 400 kolom dari lebih dari 25 kumpulan data tabular. Kumpulan data berasal dari sumber publik berikut:
Untuk daftar lengkap tabel yang disertakan dalam indeks, lihat tutorial kode di GitHub.
Anda dapat membawa kumpulan data tabular Anda sendiri untuk menambah data sampel atau membuat indeks pencarian Anda sendiri. Kami menyertakan dua fungsi Lambda yang memulai alur kerja Step Functions untuk membangun indeks pencarian masing-masing file CSV atau sekumpulan file CSV.
Ubah CSV menjadi Parket
File CSV mentah dikonversi ke format data Parket dengan AWS Glue. Parquet adalah format file format berorientasi kolom yang lebih disukai dalam analitik data besar yang memberikan kompresi dan pengodean yang efisien. Dalam percobaan kami, format data Parquet menawarkan pengurangan ukuran penyimpanan yang signifikan dibandingkan dengan file CSV mentah. Kami juga menggunakan Parquet sebagai format data umum untuk mengonversi format data lain (misalnya JSON dan NDJSON) karena mendukung struktur data bersarang tingkat lanjut.
Buat penyematan kolom tabular
Untuk mengekstrak embeddings untuk masing-masing kolom tabel dalam sampel dataset tabel di posting ini, kami menggunakan model pra-terlatih berikut dari sentence-transformers perpustakaan. Untuk model tambahan, lihat Model yang telah dilatih sebelumnya.
Tugas Pemrosesan SageMaker berjalan create_embeddings.py(kode) untuk satu model. Untuk mengekstrak penyematan dari beberapa model, alur kerja menjalankan tugas Pemrosesan SageMaker paralel seperti yang ditunjukkan dalam alur kerja Step Functions. Kami menggunakan model untuk membuat dua set penyematan:
- nama_kolom_embeddings – Penyematan nama kolom (header)
- kolom_konten_embeddings – Penyematan rata-rata semua baris dalam kolom
Untuk informasi lebih lanjut tentang proses penyematan kolom, lihat tutorial kode di GitHub.
Alternatif untuk langkah Pemrosesan SageMaker adalah membuat transformasi batch SageMaker untuk mendapatkan penyematan kolom pada kumpulan data besar. Ini akan membutuhkan penerapan model ke titik akhir SageMaker. Untuk informasi lebih lanjut, lihat Gunakan Transformasi Batch.
Penyematan indeks dengan Layanan OpenSearch
Pada langkah terakhir dari tahap ini, fungsi Lambda menambahkan penyematan kolom ke Perkiraan Layanan OpenSearch k-Nearest-Neighbor (kNN) indeks pencarian. Setiap model diberi indeks pencariannya sendiri. Untuk informasi selengkapnya tentang perkiraan parameter indeks pencarian kNN, lihat k-NN.
Inferensi online dan pencarian semantik dengan aplikasi web
Tahap kedua alur kerja berjalan a merampingkan aplikasi web tempat Anda dapat memberikan input dan mencari kolom yang serupa secara semantik yang diindeks di Layanan OpenSearch. Lapisan aplikasi menggunakan Penyeimbang Beban Aplikasi, Fargate, dan Lambda. Infrastruktur aplikasi secara otomatis digunakan sebagai bagian dari solusi.
Aplikasi ini memungkinkan Anda untuk memberikan input dan mencari nama kolom yang mirip secara semantik, konten kolom, atau keduanya. Selain itu, Anda dapat memilih model penyematan dan jumlah tetangga terdekat untuk dikembalikan dari pencarian. Aplikasi menerima input, menyematkan input dengan model yang ditentukan, dan menggunakan pencarian kNN di Layanan OpenSearch untuk mencari penyematan kolom yang diindeks dan menemukan kolom yang paling mirip dengan input yang diberikan. Hasil pencarian yang ditampilkan mencakup nama tabel, nama kolom, dan skor kesamaan untuk kolom yang diidentifikasi, serta lokasi data di Amazon S3 untuk eksplorasi lebih lanjut.
Gambar berikut menunjukkan contoh aplikasi web. Dalam contoh ini, kami mencari kolom di data lake kami yang serupa Column Names (jenis muatan) ke district (payload). Aplikasi yang digunakan all-MiniLM-L6-v2 sebagai model penyematan dan kembali 10 (k) tetangga terdekat dari indeks Layanan OpenSearch kami.
Aplikasi kembali transit_district, city, borough, dan location sebagai empat kolom paling mirip berdasarkan data yang diindeks di Layanan OpenSearch. Contoh ini menunjukkan kemampuan pendekatan pencarian untuk mengidentifikasi kolom yang serupa secara semantik di seluruh kumpulan data.

Gambar 3: Antarmuka pengguna aplikasi web
Membersihkan
Untuk menghapus sumber daya yang dibuat oleh AWS CDK dalam tutorial ini, jalankan perintah berikut:
cdk destroy --allKesimpulan
Dalam posting ini, kami menyajikan alur kerja end-to-end untuk membangun mesin pencari semantik untuk kolom tabular.
Mulailah hari ini dengan data Anda sendiri dengan tutorial kode kami yang tersedia di GitHub. Jika Anda ingin membantu mempercepat penggunaan ML dalam produk dan proses Anda, silakan hubungi Lab Solusi Pembelajaran Mesin Amazon.
Tentang Penulis
![]() Kachi Odoemene adalah Ilmuwan Terapan di AWS AI. Dia membangun solusi AI/ML untuk memecahkan masalah bisnis bagi pelanggan AWS.
Kachi Odoemene adalah Ilmuwan Terapan di AWS AI. Dia membangun solusi AI/ML untuk memecahkan masalah bisnis bagi pelanggan AWS.
![]() Taylor McNally adalah Arsitek Pembelajaran Jauh di Lab Solusi Pembelajaran Mesin Amazon. Dia membantu pelanggan dari berbagai industri membangun solusi yang memanfaatkan AI/ML di AWS. Dia menikmati secangkir kopi yang enak, alam bebas, dan waktu bersama keluarga dan anjingnya yang energik.
Taylor McNally adalah Arsitek Pembelajaran Jauh di Lab Solusi Pembelajaran Mesin Amazon. Dia membantu pelanggan dari berbagai industri membangun solusi yang memanfaatkan AI/ML di AWS. Dia menikmati secangkir kopi yang enak, alam bebas, dan waktu bersama keluarga dan anjingnya yang energik.
![]() Austin Welch adalah Ilmuwan Data di Amazon ML Solutions Lab. Dia mengembangkan model pembelajaran mendalam khusus untuk membantu pelanggan sektor publik AWS mempercepat penerapan AI dan cloud mereka. Di waktu luangnya, dia suka membaca, jalan-jalan, dan jiu-jitsu.
Austin Welch adalah Ilmuwan Data di Amazon ML Solutions Lab. Dia mengembangkan model pembelajaran mendalam khusus untuk membantu pelanggan sektor publik AWS mempercepat penerapan AI dan cloud mereka. Di waktu luangnya, dia suka membaca, jalan-jalan, dan jiu-jitsu.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://aws.amazon.com/blogs/big-data/build-a-semantic-search-engine-for-tabular-columns-with-transformers-and-amazon-opensearch-service/
- 1
- 100
- a
- kemampuan
- Tentang Kami
- absen
- mempercepat
- mempercepat
- akurat
- di seluruh
- Tambahan
- Selain itu
- Menambahkan
- Adopsi
- maju
- AI
- AI / ML
- Semua
- memungkinkan
- alternatif
- Amazon
- Pembelajaran Mesin Amazon
- Lab Solusi Amazon ML
- Analis
- analisis
- menganalisa
- dan
- Apache
- Aplikasi
- aplikasi
- terapan
- pendekatan
- arsitektur
- ditugaskan
- Otomatis
- secara otomatis
- tersedia
- rata-rata
- AWS
- Lem AWS
- berdasarkan
- karena
- Besar
- Big data
- membawa
- membangun
- Bangunan
- membangun
- bisnis
- Pembersihan
- awan
- adopsi cloud
- Kelompok
- kode
- Tanaman
- mengumpulkan
- Kolom
- Kolom
- Umum
- dibandingkan
- kontak
- Konten
- Konvensi
- mengubah
- dikonversi
- membuat
- dibuat
- menciptakan
- Cangkir
- adat
- pelanggan
- data
- Data Analytics
- Danau Data
- kualitas data
- ilmuwan data
- kumpulan data
- mendalam
- belajar mendalam
- mendemonstrasikan
- menunjukkan
- menyebarkan
- dikerahkan
- penggelaran
- menghancurkan
- Pengembangan
- mengembangkan
- berbeda
- penemuan
- berbeda
- beberapa
- Anjing
- domain
- Download
- setiap
- efisiensi
- efisien
- ujung ke ujung
- Titik akhir
- Mesin
- Eter (ETH)
- semua orang
- contoh
- eksplorasi
- ekstrak
- memudahkan
- Keakraban
- keluarga
- Fitur
- Angka
- File
- File
- terakhir
- Akhirnya
- keuangan
- Menemukan
- temuan
- Pertama
- berikut
- format
- dari
- penuh
- fungsi
- fungsi
- lebih lanjut
- mendapatkan
- diberikan
- baik
- Pemerintah
- header
- membantu
- membantu
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- HTML
- HTTPS
- diidentifikasi
- mengenali
- melaksanakan
- penting
- in
- ketidakmampuan
- memasukkan
- termasuk
- indeks
- sendiri-sendiri
- industri
- informasi
- Infrastruktur
- memulai
- Inisiat
- memasukkan
- instruksi
- berinteraksi
- interaktif
- Antarmuka
- memanggil
- melibatkan
- masalah
- IT
- Pekerjaan
- Jobs
- json
- laboratorium
- danau
- besar
- lapisan
- pengetahuan
- leveraging
- Perpustakaan
- Daftar
- memuat
- lokasi
- mesin
- Mesin belajar
- sesuai
- medis
- ML
- model
- model
- lebih
- paling
- beberapa
- nama
- nama
- penamaan
- Perlu
- tetangga
- jumlah
- ditawarkan
- secara online
- Lainnya
- di luar rumah
- sendiri
- Paralel
- parameter
- bagian
- plato
- Kecerdasan Data Plato
- Data Plato
- silahkan
- Pos
- potensi
- disukai
- disajikan
- sebelumnya
- masalah
- hasil
- proses
- proses
- pengolahan
- Diproduksi
- Produk
- memberikan
- menyediakan
- publik
- kualitas
- Mentah
- Bacaan
- menerima
- reguler
- merupakan
- membutuhkan
- wajib
- peneliti
- Sumber
- masing-masing
- Hasil
- kembali
- Run
- berjalan
- pembuat bijak
- ilmuwan
- ilmuwan
- Pencarian
- mesin pencari
- mencari
- Kedua
- sektor
- layanan
- Layanan
- set
- ditunjukkan
- Pertunjukkan
- penting
- mirip
- Sederhana
- tunggal
- Ukuran
- larutan
- Solusi
- MEMECAHKAN
- sumber
- ditentukan
- Tahap
- mulai
- Langkah
- Tangga
- penyimpanan
- seperti itu
- Mendukung
- rentan
- tabel
- Grafik
- mereka
- Melalui
- waktu
- untuk
- hari ini
- Mengubah
- transformer
- Perjalanan
- tutorial
- menggunakan
- Pengguna
- User Interface
- berbagai
- jaringan
- aplikasi web
- yang
- alur kerja
- akan
- Anda
- zephyrnet.dll