Gambar oleh Editor
Pada 14 Maret 2023, OpenAI meluncurkan GPT-4, versi terbaru dan terkuat dari model bahasa mereka.
Hanya dalam beberapa jam setelah peluncurannya, GPT-4 mengejutkan orang dengan memutar a sketsa yang digambar tangan menjadi situs web fungsional, lulus ujian bar, dan menghasilkan ringkasan yang akurat dari artikel Wikipedia.
Itu juga mengungguli pendahulunya, GPT-3.5, dalam memecahkan masalah matematika dan menjawab pertanyaan berdasarkan logika dan penalaran.
ChatGPT, chatbot yang dibangun di atas GPT-3.5 dan dirilis ke publik, terkenal karena "berhalusinasi". Itu akan menghasilkan tanggapan yang tampaknya benar dan akan mempertahankan jawabannya dengan "fakta", meskipun sarat dengan kesalahan.
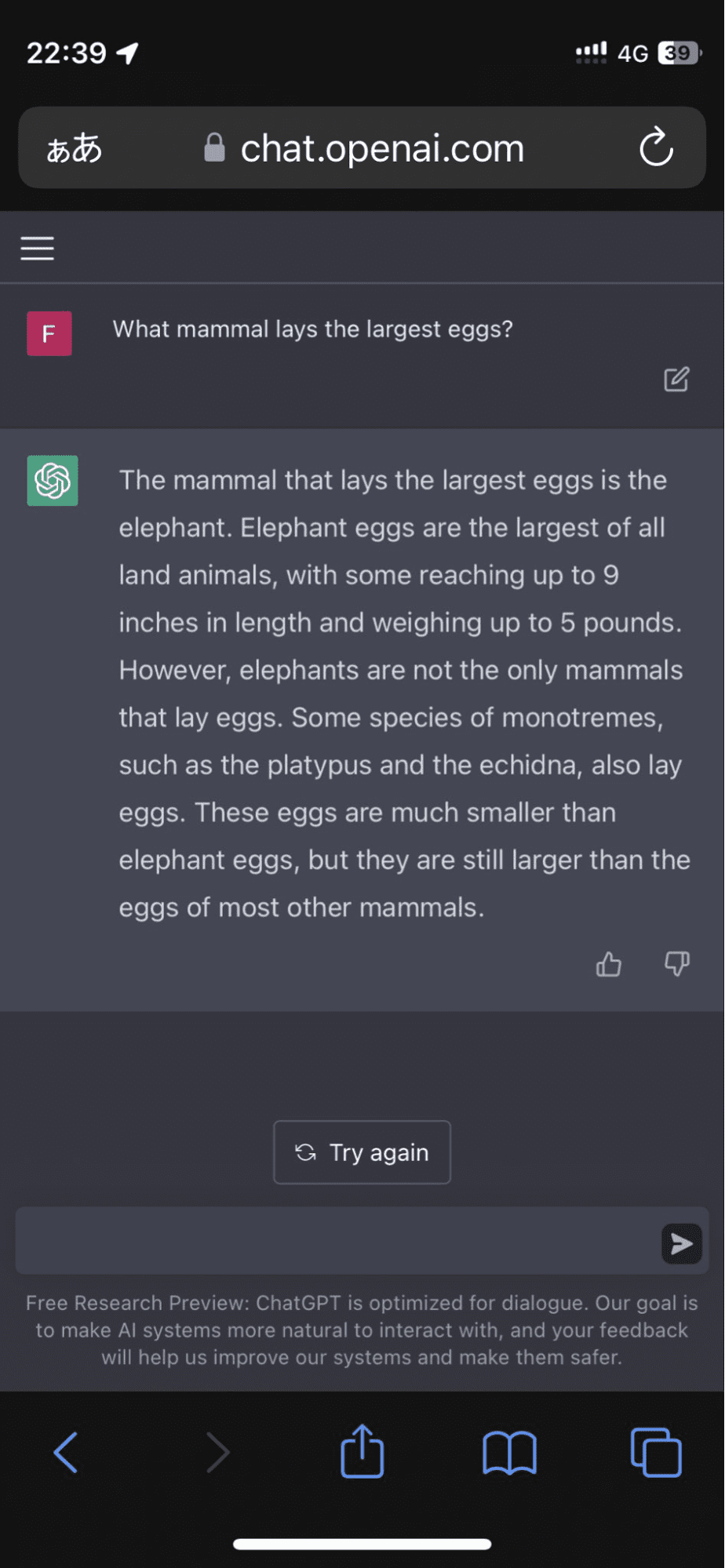
Seorang pengguna menggunakan Twitter setelah model tersebut bersikeras bahwa telur gajah adalah yang terbesar dari semua hewan darat:
Gambar dari FioraAeterna
Dan itu tidak berhenti di situ. Algoritme melanjutkan untuk menguatkan tanggapannya dengan fakta-fakta yang dibuat-buat yang hampir membuat saya yakin sejenak.
GPT-4, di sisi lain, lebih jarang dilatih untuk "berhalusinasi". Model terbaru OpenAI lebih sulit untuk diakali dan tidak terlalu percaya diri menghasilkan kebohongan.
Sebagai ilmuwan data, pekerjaan saya mengharuskan saya menemukan sumber data yang relevan, memproses kumpulan data besar sebelumnya, dan membuat model pembelajaran mesin yang sangat akurat yang mendorong nilai bisnis.
Saya menghabiskan sebagian besar hari saya mengekstraksi data dari berbagai format file dan menggabungkannya di satu tempat.
Setelah ChatGPT pertama kali diluncurkan pada November 2022, saya menggunakan chatbot untuk mendapatkan beberapa panduan dalam alur kerja harian saya. Saya menggunakan alat ini untuk menghemat waktu yang dihabiskan untuk pekerjaan kasar - sehingga saya bisa fokus menghasilkan ide-ide baru dan menciptakan model yang lebih baik.
Setelah GPT-4 dirilis, saya ingin tahu apakah itu akan membuat perbedaan dalam pekerjaan yang saya lakukan. Apakah ada manfaat signifikan menggunakan GPT-4 dibandingkan pendahulunya? Apakah ini akan membantu saya menghemat lebih banyak waktu daripada sebelumnya dengan GPT-3.5?
Pada artikel ini, saya akan menunjukkan kepada Anda bagaimana saya menggunakan ChatGPT untuk mengotomatiskan alur kerja ilmu data.
Saya akan membuat prompt yang sama dan memasukkannya ke GPT-4 dan GPT-3.5, untuk melihat apakah yang pertama benar-benar bekerja lebih baik dan menghasilkan lebih banyak penghematan waktu.
Jika Anda ingin mengikuti semua yang saya lakukan di artikel ini, Anda harus memiliki akses ke GPT-4 dan GPT-3.5.
GPT-3.5
GPT-3.5 tersedia untuk umum di situs web OpenAI. Cukup arahkan ke https://chat.openai.com/auth/login, isi detail yang diperlukan, dan Anda akan memiliki akses ke model bahasa:
Gambar dari ChatGPT
GPT-4
GPT-4, di sisi lain, saat ini tersembunyi di balik paywall. Untuk mengakses model, Anda perlu memutakhirkan ke ChatGPTPlus dengan mengeklik "Tingkatkan ke Plus".
Ada biaya berlangganan bulanan sebesar $20/bulan yang dapat dibatalkan kapan saja:
Gambar dari ChatGPT
Jika Anda tidak ingin membayar biaya berlangganan bulanan, Anda juga dapat bergabung dengan daftar tunggu API untuk GPT-4. Setelah Anda mendapatkan akses ke API, Anda dapat mengikuti ini panduan untuk menggunakannya dengan Python.
Tidak apa-apa jika saat ini Anda tidak memiliki akses ke GPT-4.
Anda masih dapat mengikuti tutorial ini dengan ChatGPT versi gratis yang menggunakan GPT-3.5 di backend.
1. Visualisasi Data
Saat melakukan analisis data eksplorasi, menghasilkan visualisasi cepat dengan Python sering kali membantu saya lebih memahami kumpulan data.
Sayangnya, tugas ini bisa sangat memakan waktu - terutama bila Anda tidak mengetahui sintaks yang tepat untuk digunakan untuk mendapatkan hasil yang diinginkan.
Saya sering menemukan diri saya mencari melalui dokumentasi ekstensif Seaborn dan menggunakan StackOverflow untuk menghasilkan satu plot Python.
Mari kita lihat apakah ChatGPT dapat membantu menyelesaikan masalah ini.
Kami akan menggunakan Pima Indian Diabetes kumpulan data di bagian ini. Anda dapat mengunduh kumpulan data jika Anda ingin mengikuti hasil yang dihasilkan oleh ChatGPT.
Setelah mengunduh dataset, mari muat ke dalam Python menggunakan pustaka Pandas dan cetak kepala kerangka data:
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
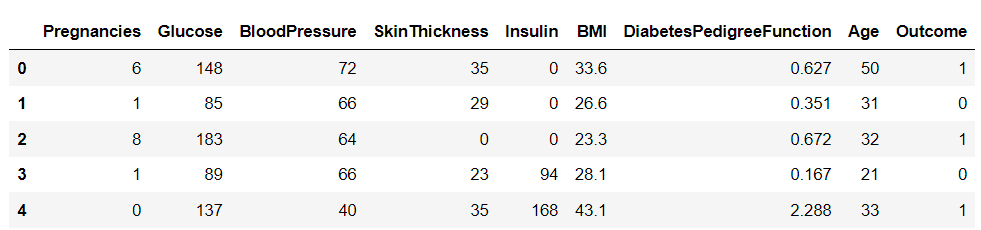
Ada sembilan variabel dalam dataset ini. Salah satunya, "Hasil", adalah variabel target yang memberi tahu kita apakah seseorang akan terkena diabetes. Sisanya adalah variabel independen yang digunakan untuk memprediksi hasil.
Oke! Jadi saya ingin melihat variabel mana yang berdampak pada apakah seseorang akan terkena diabetes.
Untuk mencapai ini, kita dapat membuat bagan batang berkerumun untuk memvisualisasikan variabel “Diabetes” di semua variabel dependen dalam kumpulan data.
Ini sebenarnya cukup mudah untuk dikodekan, tapi mari kita mulai dengan sederhana. Kami akan beralih ke petunjuk yang lebih rumit saat kami melanjutkan artikel.
Visualisasi Data dengan GPT-3.5
Karena saya memiliki langganan berbayar ke ChatGPT, alat ini memungkinkan saya untuk memilih model dasar yang ingin saya gunakan setiap kali saya mengaksesnya.
Saya akan memilih GPT-3.5:
Gambar dari ChatGPT Plus
Jika Anda tidak berlangganan, Anda dapat menggunakan ChatGPT versi gratis karena chatbot menggunakan GPT-3.5 secara default.
Sekarang, mari ketik prompt berikut untuk menghasilkan visualisasi menggunakan dataset diabetes:
Saya memiliki dataset dengan 8 variabel independen dan 1 variabel dependen. Variabel terikat, “Hasil”, memberitahu kita apakah seseorang akan menderita diabetes.
Variabel independen, "Kehamilan", "Glukosa", "Tekanan Darah", "Ketebalan Kulit", "Insulin", "BMI", "Fungsi Pedigree Diabetes", dan "Usia" digunakan untuk memprediksi hasil ini.
Bisakah Anda membuat kode Python untuk memvisualisasikan semua variabel independen ini berdasarkan hasilnya? Outputnya harus berupa satu diagram batang berkerumun yang diwarnai oleh variabel "Hasil". Harus ada total 16 bar, 2 untuk setiap variabel independen.
Inilah respons model terhadap permintaan di atas:
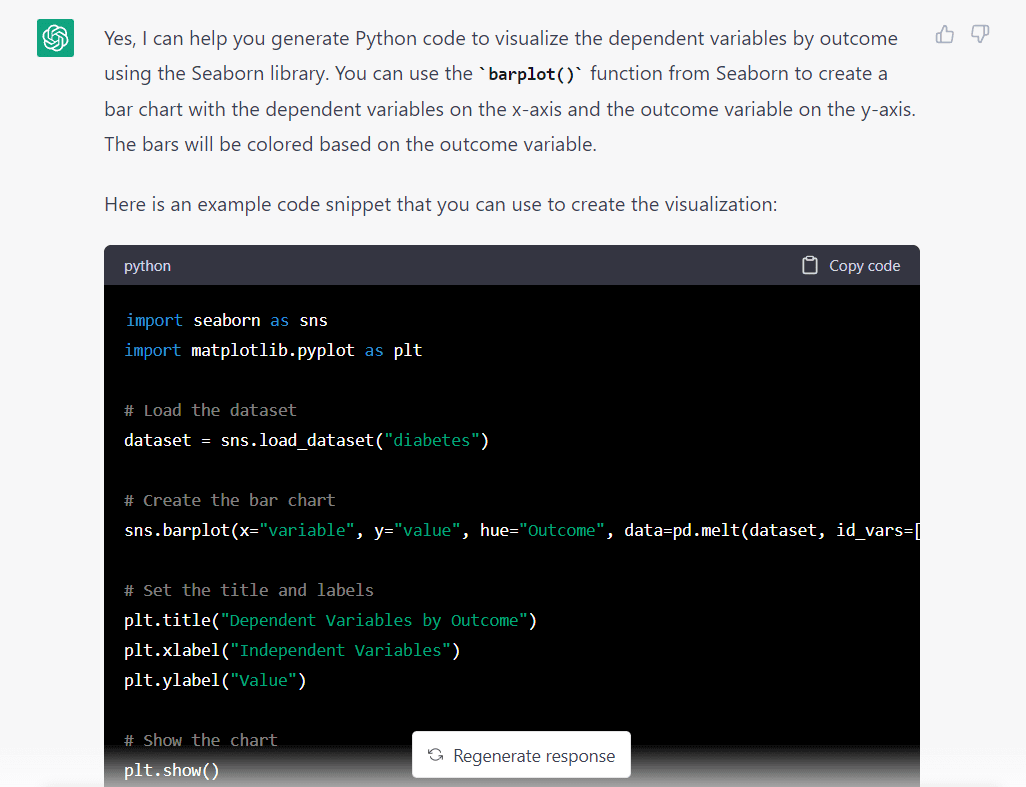
Satu hal yang langsung menonjol adalah model tersebut menganggap kami ingin mengimpor kumpulan data dari Seaborn. Itu mungkin membuat asumsi ini karena kami memintanya untuk menggunakan perpustakaan Seaborn.
Ini bukan masalah besar, kita hanya perlu mengubah satu baris sebelum menjalankan kode.
Berikut cuplikan kode lengkap yang dihasilkan oleh GPT-3.5:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
Anda dapat menyalin dan menempelkan ini ke IDE Python Anda.
Inilah hasil yang dihasilkan setelah menjalankan kode di atas:
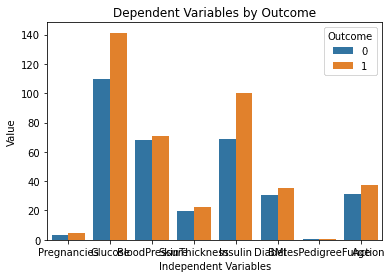
Bagan ini terlihat sempurna! Persis seperti yang saya bayangkan saat mengetik prompt ke ChatGPT.
Namun, satu masalah yang menonjol adalah bahwa teks pada bagan ini tumpang tindih. Saya akan menanyakan model apakah dapat membantu kami memperbaikinya, dengan mengetik perintah berikut:
Algoritme menjelaskan bahwa kami dapat mencegah tumpang tindih ini dengan memutar label bagan atau menyesuaikan ukuran gambar. Itu juga menghasilkan kode baru untuk membantu kami mencapai ini.
Mari kita jalankan kode ini untuk melihat apakah kode tersebut memberi kita hasil yang diinginkan:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
Baris kode di atas akan menghasilkan output berikut:
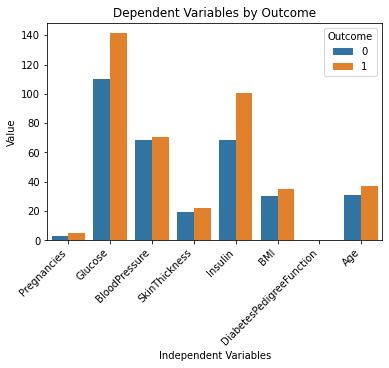
Ini terlihat bagus!
Saya memahami kumpulan data jauh lebih baik sekarang hanya dengan melihat bagan ini. Tampaknya orang dengan kadar glukosa dan insulin yang lebih tinggi lebih mungkin mengembangkan diabetes.
Perhatikan juga bahwa variabel “DiabetesPedigreeFunction” tidak memberi kita informasi apa pun dalam bagan ini. Ini karena fitur tersebut berada pada skala yang lebih kecil (antara 0 dan 2.4). Jika Anda ingin bereksperimen lebih lanjut dengan ChatGPT, Anda dapat memintanya untuk membuat beberapa subplot dalam satu bagan untuk mengatasi masalah ini.
Visualisasi Data dengan GPT-4
Sekarang, mari masukkan permintaan yang sama ke GPT-4 untuk melihat apakah kita mendapatkan respons yang berbeda. Saya akan memilih model GPT-4 di dalam ChatGPT dan mengetik prompt yang sama seperti sebelumnya:
Perhatikan bagaimana GPT-4 tidak berasumsi bahwa kita akan menggunakan kerangka data yang dibangun di Seaborn.
Ini memberi tahu kita bahwa itu akan menggunakan kerangka data yang disebut "df" untuk membangun visualisasi, yang merupakan peningkatan dari respons yang dihasilkan oleh GPT-3.5.
Berikut adalah kode lengkap yang dihasilkan oleh algoritma ini:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
Kode di atas harus menghasilkan plot berikut:
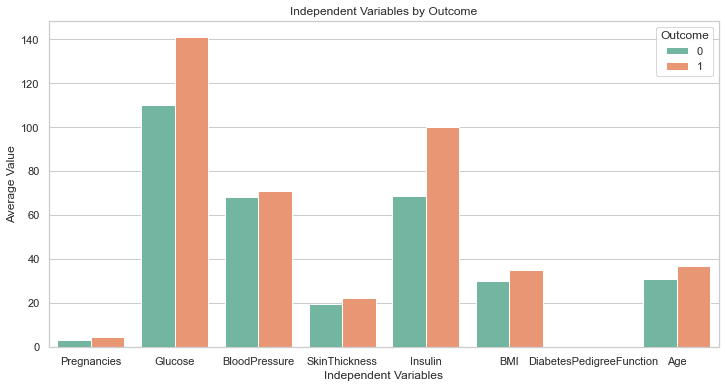
Ini sempurna!
Meskipun kami tidak memintanya, GPT-4 telah menyertakan sebaris kode untuk menambah ukuran plot. Label pada bagan ini semuanya terlihat jelas, jadi kita tidak perlu kembali dan mengubah kode seperti yang kita lakukan sebelumnya.
Ini adalah langkah di atas respons yang dihasilkan oleh GPT-3.5.
Namun secara keseluruhan, tampaknya GPT-3.5 dan GPT-4 sama-sama efektif dalam menghasilkan kode untuk melakukan tugas seperti visualisasi dan analisis data.
Penting untuk diperhatikan bahwa karena Anda tidak dapat mengunggah data ke antarmuka ChatGPT, Anda harus memberikan deskripsi yang akurat tentang set data Anda kepada model untuk hasil yang optimal.
2. Bekerja dengan Dokumen PDF
Meskipun ini bukan kasus penggunaan ilmu data yang umum, saya harus mengekstrak data teks dari ratusan file PDF untuk membuat model analisis sentimen sekali. Datanya tidak terstruktur, dan saya menghabiskan banyak waktu untuk mengekstraksi dan memprosesnya terlebih dahulu.
Saya juga sering bekerja dengan peneliti yang membaca dan membuat konten tentang peristiwa terkini yang terjadi di industri tertentu. Mereka harus tetap mengikuti berita, mengurai laporan perusahaan, dan membaca tentang tren potensial di industri ini.
Daripada membaca 100 halaman laporan perusahaan, bukankah lebih mudah untuk hanya mengekstrak kata-kata yang Anda minati dan hanya membaca kalimat yang mengandung kata kunci tersebut?
Atau jika Anda tertarik dengan tren, Anda dapat membuat alur kerja otomatis yang menampilkan pertumbuhan kata kunci dari waktu ke waktu alih-alih memeriksa setiap laporan secara manual.
Di bagian ini, kami akan menggunakan ChatGPT untuk menganalisis file PDF dengan Python. Kami akan meminta chatbot untuk mengekstrak konten file PDF dan menuliskannya ke dalam file teks.
Sekali lagi, ini akan dilakukan menggunakan GPT-3.5 dan GPT-4 untuk melihat apakah ada perbedaan yang signifikan dalam kode yang dihasilkan.
Membaca File PDF dengan GPT-3.5
Di bagian ini, kami akan menganalisis dokumen PDF yang tersedia untuk umum berjudul Pengantar Singkat Pembelajaran Mesin untuk Insinyur. Pastikan untuk mengunduh file ini jika Anda ingin membuat kode untuk bagian ini.
Pertama, mari kita tanyakan algoritme untuk menghasilkan kode Python untuk mengekstrak data dari dokumen PDF ini dan menyimpannya ke file teks:
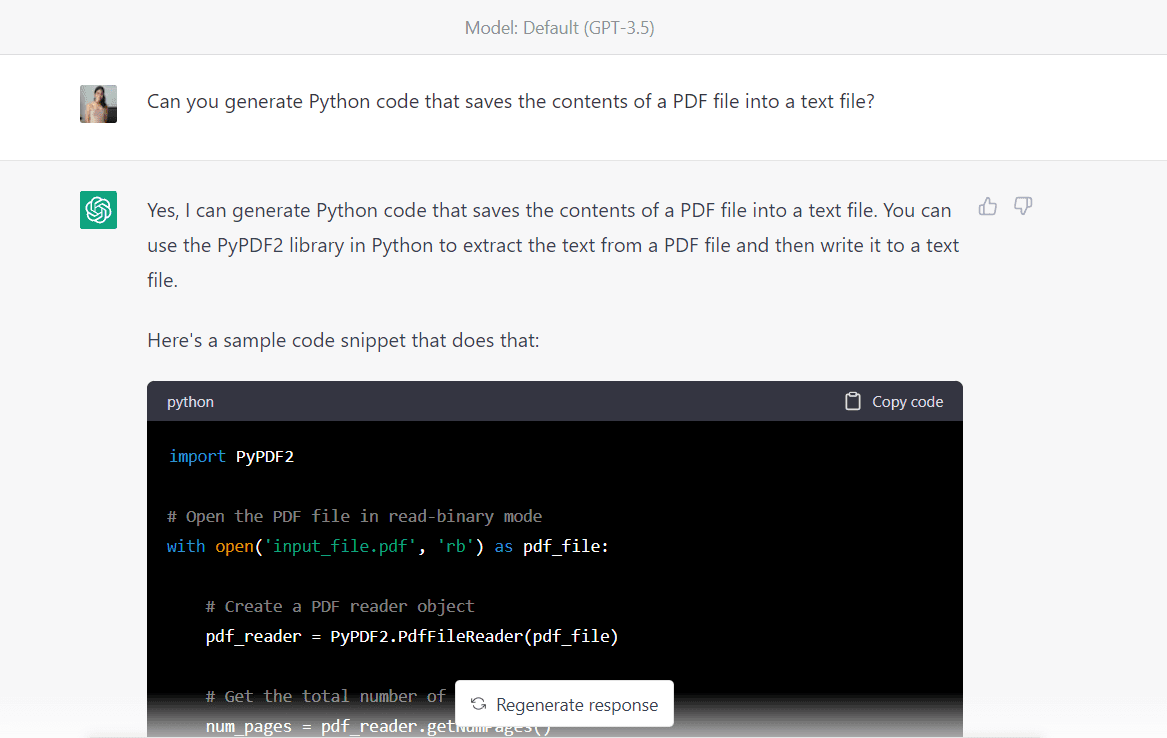
Berikut adalah kode lengkap yang disediakan oleh algoritma:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(Catatan: Pastikan untuk mengubah nama file PDF menjadi yang Anda simpan sebelum menjalankan kode ini.)
Sayangnya, setelah menjalankan kode yang dihasilkan oleh GPT-3.5, saya mengalami kesalahan unicode berikut:

Mari kembali ke GPT-3.5 dan lihat apakah model dapat memperbaikinya:
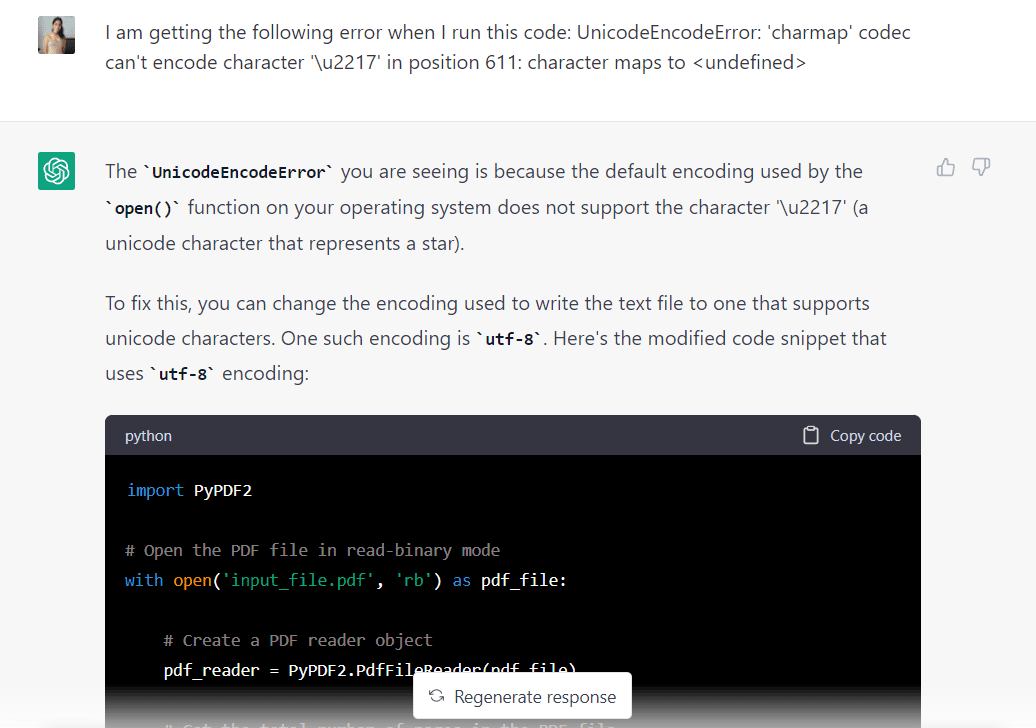
Saya menempelkan kesalahan ke ChatGPT, dan model menjawab bahwa itu dapat diperbaiki dengan mengubah pengkodean yang digunakan menjadi "utf-8". Itu juga memberi saya beberapa kode yang dimodifikasi yang mencerminkan perubahan ini:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
Kode ini berhasil dijalankan dan membuat file teks yang disebut "output_file.txt." Semua konten dalam dokumen PDF telah ditulis ke file:
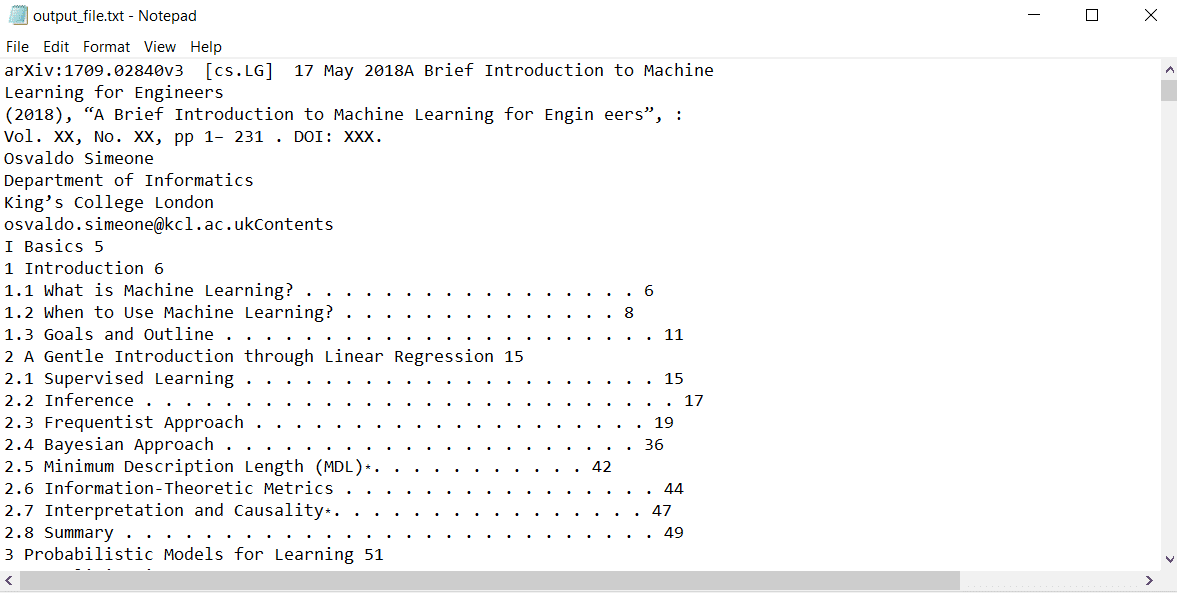
Membaca File PDF dengan GPT-4
Sekarang, saya akan menempelkan prompt yang sama ke GPT-4 untuk melihat seperti apa modelnya:
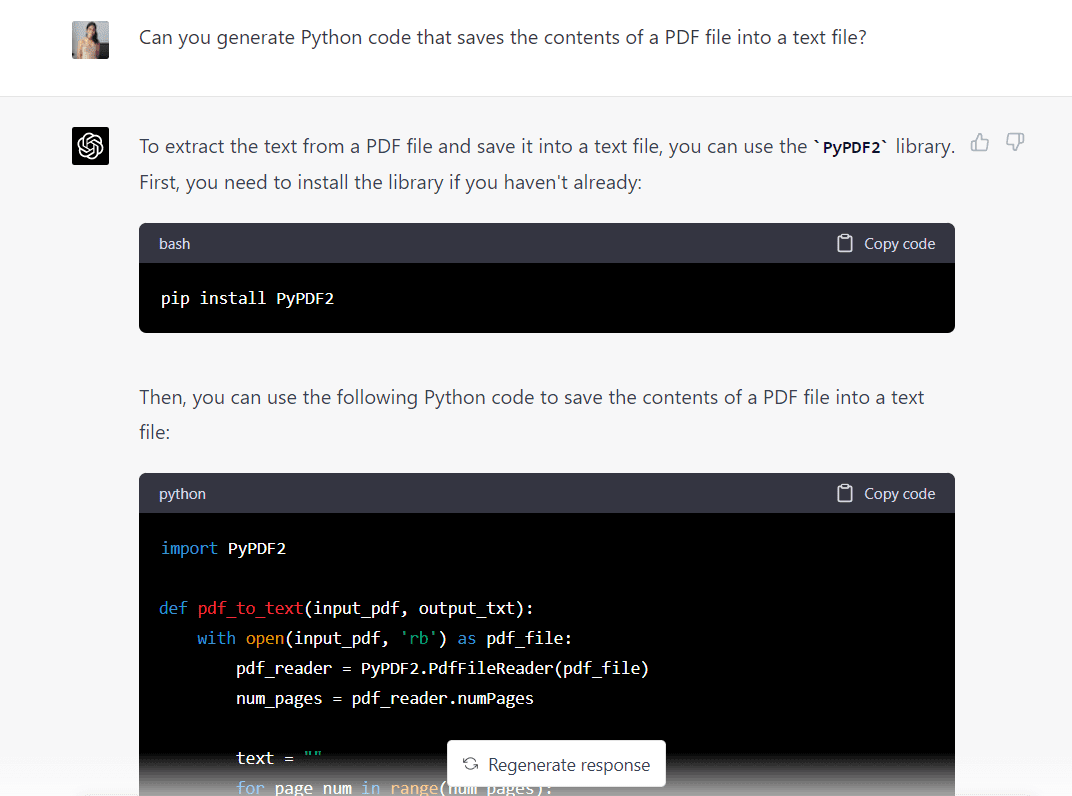
Berikut adalah kode lengkap yang dihasilkan oleh GPT-4:
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
Lihat itu!
Tidak seperti GPT-3.5, GPT-4 telah menetapkan bahwa pengkodean "utf-8" harus digunakan untuk membuka file teks. Kita tidak perlu kembali dan mengubah kode seperti yang kita lakukan sebelumnya.
Kode yang disediakan oleh GPT-4 harus dijalankan dengan sukses, dan Anda akan melihat konten dokumen PDF dalam file teks yang telah dibuat.
Ada banyak teknik lain yang dapat Anda gunakan untuk mengotomatiskan dokumen PDF dengan Python. Jika Anda ingin menjelajahinya lebih jauh, berikut adalah beberapa perintah lain yang dapat Anda ketikkan ke ChatGPT:
- Bisakah Anda menulis kode Python untuk menggabungkan dua file PDF?
- Bagaimana cara menghitung kemunculan kata atau frasa tertentu dalam dokumen PDF dengan Python?
- Bisakah Anda menulis kode Python untuk mengekstrak tabel dari PDF dan menuliskannya di Excel?
Saya sarankan untuk mencoba beberapa di antaranya selama waktu luang Anda - Anda akan terkejut melihat betapa cepatnya GPT-4 dapat membantu Anda menyelesaikan tugas-tugas kasar yang biasanya memerlukan waktu berjam-jam untuk menyelesaikannya.
3. Mengirim Email Otomatis
Saya menghabiskan waktu berjam-jam di minggu kerja saya untuk membaca dan membalas email. Ini tidak hanya memakan waktu, tetapi juga bisa sangat membuat stres untuk tetap mengikuti email saat Anda mengejar tenggat waktu yang ketat.
Dan meskipun Anda tidak bisa membuat ChatGPT menulis semua email untuk Anda (saya harap), Anda masih dapat menggunakannya untuk menulis program yang mengirim email terjadwal pada waktu tertentu atau mengubah satu templat email yang dapat dikirim ke banyak orang .
Di bagian ini, kita akan mendapatkan GPT-3.5 dan GPT-4 untuk membantu kita menulis skrip Python untuk mengirim email otomatis.
Mengirim Email Otomatis dengan GPT-3.5
Pertama, mari ketik prompt berikut untuk menghasilkan kode untuk mengirim email otomatis:
Berikut adalah kode lengkap yang dihasilkan oleh GPT-3.5 (Pastikan untuk mengubah alamat email dan kata sandi sebelum menjalankan kode ini):
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Sayangnya, kode ini tidak berhasil dijalankan untuk saya. Itu menghasilkan kesalahan berikut:
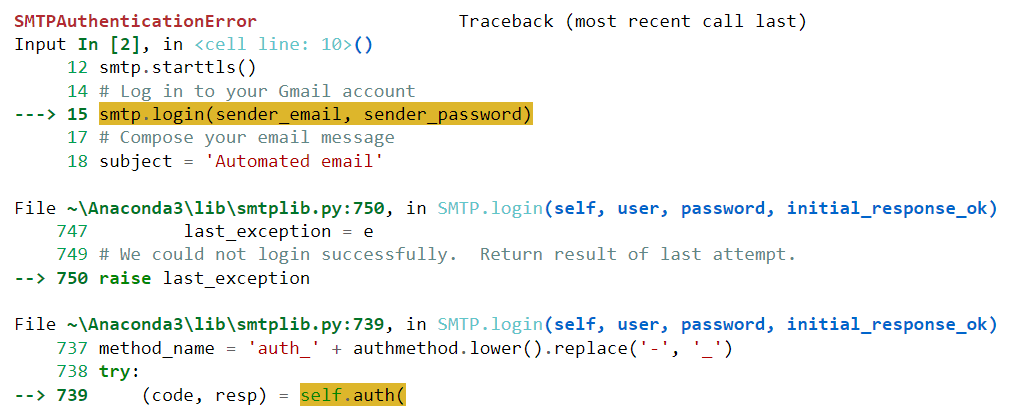
Mari rekatkan kesalahan ini ke ChatGPT dan lihat apakah model tersebut dapat membantu kami menyelesaikannya:

Oke, jadi algoritme menunjukkan beberapa alasan mengapa kita mungkin mengalami kesalahan ini.
Saya tahu pasti bahwa kredensial masuk dan alamat email saya valid, dan tidak ada kesalahan ketik dalam kode. Jadi alasan ini bisa dikesampingkan.
GPT-3.5 juga menyarankan agar mengizinkan aplikasi yang kurang aman dapat mengatasi masalah ini.
Namun, jika Anda mencobanya, Anda tidak akan menemukan opsi di akun Google Anda untuk mengizinkan akses ke aplikasi yang kurang aman.
Ini karena Google tidak lagi memungkinkan pengguna mengizinkan aplikasi yang kurang aman karena masalah keamanan.
Terakhir, GPT-3.5 juga menyebutkan bahwa kata sandi aplikasi harus dibuat jika autentikasi dua faktor diaktifkan.
Saya tidak mengaktifkan autentikasi dua faktor, jadi saya akan (sementara) menyerah pada model ini dan melihat apakah GPT-4 memiliki solusinya.
Mengirim Email Otomatis dengan GPT-4
Oke, jadi jika Anda mengetik prompt yang sama ke GPT-4, Anda akan menemukan bahwa algoritme menghasilkan kode yang sangat mirip dengan yang diberikan GPT-3.5 kepada kami. Ini akan menyebabkan kesalahan yang sama yang kita alami sebelumnya.
Mari kita lihat apakah GPT-4 dapat membantu kami memperbaiki kesalahan ini:

Saran GPT-4 sangat mirip dengan yang kita lihat sebelumnya.
Namun, kali ini, ini memberi kita perincian langkah demi langkah tentang cara menyelesaikan setiap langkah.
GPT-4 juga menyarankan untuk membuat kata sandi aplikasi, jadi mari kita coba.
Pertama, kunjungi Akun Google Anda, arahkan ke "Keamanan", dan aktifkan autentikasi dua faktor. Kemudian, di bagian yang sama, Anda akan melihat opsi bertuliskan "Kata Sandi Aplikasi".
Klik di atasnya dan layar berikut akan muncul:
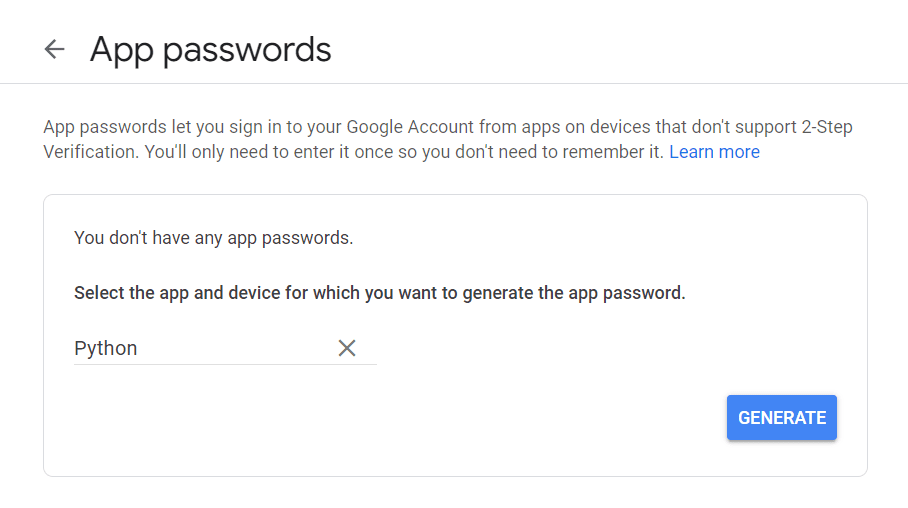
Anda dapat memasukkan nama apa pun yang Anda suka, dan klik "Hasilkan".
Kata sandi aplikasi baru akan muncul.
Ganti kata sandi Anda yang ada di kode Python dengan kata sandi aplikasi ini dan jalankan kode lagi:
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Seharusnya kali ini berjalan dengan sukses, dan penerima Anda akan menerima email yang terlihat seperti ini:
Sempurna!
Berkat ChatGPT, kami telah berhasil mengirimkan email otomatis dengan Python.
Jika Anda ingin melangkah lebih jauh, saya sarankan untuk membuat petunjuk yang memungkinkan Anda untuk:
- Kirim email massal ke beberapa penerima sekaligus
- Kirim email terjadwal ke daftar alamat email yang telah ditentukan sebelumnya
- Kirimi penerima email khusus yang disesuaikan dengan usia, jenis kelamin, dan lokasi mereka.
Natasha Selvaraj adalah seorang ilmuwan data otodidak dengan hasrat untuk menulis. Anda dapat terhubung dengannya di LinkedIn.
- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- Platoblockchain. Intelijen Metaverse Web3. Pengetahuan Diperkuat. Akses Di Sini.
- Sumber: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python
- :adalah
- $NAIK
- 1
- 100
- 2022
- 2023
- 7
- 8
- a
- Tentang Kami
- atas
- mengakses
- menyelesaikan
- Akun
- tepat
- Mencapai
- di seluruh
- sebenarnya
- alamat
- Setelah
- algoritma
- Semua
- Membiarkan
- memungkinkan
- sudah
- Meskipun
- jumlah
- analisis
- menganalisa
- menganalisis
- dan
- hewan
- jawaban
- api
- aplikasi
- muncul
- aplikasi
- ADALAH
- artikel
- AS
- diasumsikan
- anggapan
- At
- Otentikasi
- mengotomatisasikan
- Otomatis
- tersedia
- rata-rata
- kembali
- Backend
- bar
- bar
- berdasarkan
- BE
- karena
- menjadi
- sebelum
- di belakang
- Manfaat
- Lebih baik
- antara
- bmi
- tubuh
- Membosankan
- Kerusakan
- membangun
- dibangun di
- bisnis
- by
- bernama
- CAN
- dibatalkan
- tidak bisa
- Menyebabkan
- perubahan
- mengubah
- Grafik
- ChatBot
- ChatGPT
- Jelas
- Klik
- kode
- COM
- kedatangan
- Umum
- perusahaan
- Perusahaan
- lengkap
- rumit
- Kekhawatiran
- dengan penuh percaya diri
- Terhubung
- koneksi
- konsolidasi
- Konten
- isi
- menguatkan
- bisa
- membuat
- dibuat
- membuat
- Surat kepercayaan
- ingin tahu
- terbaru
- Sekarang
- menyesuaikan
- disesuaikan
- harian
- data
- analisis data
- ilmu data
- ilmuwan data
- visualisasi data
- kumpulan data
- hari
- Default
- tergantung
- deskripsi
- rincian
- mengembangkan
- Diabetes
- MELAKUKAN
- perbedaan
- berbeda
- dokumen
- dokumentasi
- dokumen
- Tidak
- melakukan
- Dont
- Download
- mendorong
- selama
- setiap
- Terdahulu
- mudah
- Efektif
- Telur
- antara
- gajah
- aktif
- diaktifkan
- enkripsi
- Enter
- kesalahan
- kesalahan
- terutama
- Eter (ETH)
- peristiwa
- Setiap
- segala sesuatu
- persis
- Excel
- menjalankan
- ada
- eksperimen
- menjelaskan
- Analisis Data Eksplorasi
- menyelidiki
- luas
- ekstrak
- Fitur
- biaya
- beberapa
- Angka
- File
- File
- mengisi
- Menemukan
- Pertama
- Memperbaiki
- tetap
- Fokus
- mengikuti
- berikut
- Untuk
- Bekas
- Gratis
- sering
- dari
- fungsionil
- lebih lanjut
- Gender
- menghasilkan
- dihasilkan
- menghasilkan
- menghasilkan
- mendapatkan
- Memberikan
- memberikan
- gmail
- Go
- akan
- Pertumbuhan
- bimbingan
- membimbing
- tangan
- Memiliki
- kepala
- membantu
- membantu
- di sini
- Tersembunyi
- lebih tinggi
- sangat
- Horisontal
- JAM
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTTPS
- besar
- Ratusan
- i
- ide-ide
- segera
- Dampak
- mengimpor
- penting
- perbaikan
- in
- termasuk
- Meningkatkan
- luar biasa
- independen
- industri
- industri
- informasi
- sebagai gantinya
- tertarik
- Antarmuka
- Pengantar
- isu
- IT
- NYA
- Pekerjaan
- ikut
- KDnugget
- Tahu
- Label
- Tanah
- bahasa
- besar
- terbesar
- Terbaru
- jalankan
- diluncurkan
- pengetahuan
- Lets
- adalah ide yang bagus
- Perpustakaan
- 'like'
- Mungkin
- baris
- baris
- Daftar
- memuat
- tempat
- tampak
- mencari
- TERLIHAT
- Lot
- mesin
- Mesin belajar
- terbuat
- membuat
- manual
- banyak
- March
- matematika
- matplotlib.dll
- sebutan
- Bergabung
- pesan
- mungkin
- mode
- model
- model
- dimodifikasi
- memodifikasi
- saat
- bulanan
- berlangganan bulanan
- lebih
- paling
- pindah
- beberapa
- nama
- Arahkan
- Perlu
- New
- aplikasi baru
- Terbaru
- berita
- terkenal jahat
- November
- jumlah
- obyek
- of
- Oke
- on
- ONE
- Buka
- OpenAI
- optimal
- pilihan
- Lainnya
- Hasil
- Mengungguli
- keluaran
- halaman
- dibayar
- panda
- gairah
- Kata Sandi
- password
- Membayar
- Konsultan Ahli
- melakukan
- melakukan
- orang
- Tempat
- plato
- Kecerdasan Data Plato
- Data Plato
- plus
- potensi
- kuat
- pendahulu
- meramalkan
- cukup
- mencegah
- sebelumnya
- Mencetak
- mungkin
- Masalah
- masalah
- program
- Kemajuan
- memberikan
- disediakan
- publik
- di depan umum
- Ular sanca
- Pertanyaan
- Cepat
- segera
- Baca
- Pembaca
- Bacaan
- alasan
- menerima
- penerima
- tercermin
- dirilis
- relevan
- yang tersisa
- melaporkan
- laporan
- wajib
- membutuhkan
- peneliti
- menanggapi
- tanggapan
- mengakibatkan
- Hasil
- Run
- berjalan
- sama
- Save
- Tabungan
- mengatakan
- Skala
- dijadwalkan
- Ilmu
- ilmuwan
- Layar
- yg keturunan dr laut
- mencari
- Bagian
- aman
- keamanan
- mengirim
- sentimen
- set
- harus
- Menunjukkan
- penting
- mirip
- Sederhana
- hanya
- sejak
- tunggal
- Ukuran
- lebih kecil
- So
- larutan
- MEMECAHKAN
- Memecahkan
- beberapa
- sumber
- tertentu
- ditentukan
- menghabiskan
- menghabiskan
- berdiri
- awal
- tinggal
- Langkah
- Masih
- berhenti
- subyek
- berlangganan
- berhasil
- Menyarankan
- cocok
- tercengang
- sintaksis
- disesuaikan
- Mengambil
- pengambilan
- target
- tugas
- tugas
- teknik
- mengatakan
- Template
- bahwa
- Grafik
- mereka
- Mereka
- Sana.
- Ini
- hal
- Melalui
- waktu
- membuang-buang waktu
- Judul
- berjudul
- TLS
- untuk
- alat
- puncak
- Total
- terlatih
- Tren
- Putar
- tutorial
- pokok
- memahami
- unicode
- meningkatkan
- us
- menggunakan
- Pengguna
- Pengguna
- biasanya
- nilai
- versi
- terlihat
- Mengunjungi
- visualisasi
- W
- ingin
- Situs Web
- Apa
- apakah
- yang
- SIAPA
- Wikipedia
- akan
- dengan
- dalam
- Word
- kata
- Kerja
- alur kerja
- Alur kerja
- kerja
- akan
- menulis
- penulisan
- tertulis
- Anda
- zephyrnet.dll