- Konten Bertenaga SEO & Distribusi PR. Dapatkan Amplifikasi Hari Ini.
- PlatoData.Jaringan Vertikal Generatif Ai. Berdayakan Diri Anda. Akses Di Sini.
- PlatoAiStream. Intelijen Web3. Pengetahuan Diperkuat. Akses Di Sini.
- PlatoESG. Karbon, teknologi bersih, energi, Lingkungan Hidup, Tenaga surya, Penanganan limbah. Akses Di Sini.
- PlatoHealth. Kecerdasan Uji Coba Biotek dan Klinis. Akses Di Sini.
- Sumber: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :adalah
- 10
- 100
- 15%
- 2023
- 7
- a
- Sanggup
- di seluruh
- Mengadopsi
- AI
- sama
- Semua
- Meskipun
- antara
- an
- dan
- jawaban
- terapan
- ADALAH
- AS
- meminta
- aspek
- asisten
- terkait
- At
- menyerang
- Serangan
- tersedia
- jauh
- BE
- makhluk
- antara
- miliaran
- membangun
- bisnis
- tapi
- by
- CAN
- hati-hati
- ceo
- chatbots
- ChatGPT
- jelas
- tertutup
- Umum
- Perusahaan
- komputer
- Perhatian
- tentang
- Konferensi
- bisa
- membuat
- membuat
- kritis
- Sekarang
- maya
- Tanggal
- mendemonstrasikan
- menunjukkan
- penggelaran
- terperinci
- Deteksi
- mengembangkan
- berbeda
- digital
- ditemukan
- dr
- perusahaan
- Seluruh
- Bahkan
- bukti
- ada
- ada
- Mengeksploitasi
- ekstraksi
- sangat
- sangat menarik
- keuangan
- jasa keuangan
- Pertama
- terfokus
- Untuk
- dari
- lebih lanjut
- diperoleh
- diberikan
- Pemberian
- Tanah
- Memiliki
- Tersembunyi
- highlight
- host
- Seterpercayaapakah Olymp Trade? Kesimpulan
- How To
- Namun
- HTTPS
- MemelukWajah
- penting
- in
- Pada meningkat
- makin
- industri
- memberitahu
- informasi
- keamanan informasi
- berwawasan luas
- Internet
- Menginvestasikan
- investasi
- IT
- jpg
- kunci
- pengetahuan
- dikenal
- bahasa
- besar
- Perusahaan besar
- jalankan
- terkemuka
- BELAJAR
- pengetahuan
- kurang
- sedikit
- mesin
- Mesin belajar
- utama
- Mungkin..
- ukur
- jutaan
- model
- model
- banyak
- New
- of
- on
- Buka
- open source
- or
- di luar
- sendiri
- kertas
- pihak
- Petrus
- Tempat
- perencanaan
- plato
- Kecerdasan Data Plato
- Data Plato
- mungkin
- berpotensi
- kuat
- mempersiapkan
- disajikan
- Utama
- swasta
- memberikan
- di depan umum
- jarak
- Penilaian
- direplikasi
- permintaan
- penelitian
- peneliti
- mengungkapkan
- risiko
- Tersebut
- mengatakan
- ilmuwan
- keamanan
- Layanan
- set
- harus
- Menunjukkan
- lebih kecil
- pintar
- So
- beberapa
- sumber
- Tahap
- Start-up
- badai
- Belajar
- sukses
- berhasil
- seperti itu
- diambil
- pembicaraan
- ditargetkan
- penargetan
- tugas
- tim
- Teknologi
- Teknologi
- pengujian
- dari
- bahwa
- Grafik
- informasi
- Inggris
- Dunia
- mereka
- kemudian
- Sana.
- Ini
- mereka
- berpikir
- Ketiga
- ini
- tahun ini
- kali
- untuk
- alat
- ditransfer
- transformatif
- Uk
- pemahaman
- melakukan
- universitas
- menggunakan
- bekas
- kegunaan
- dihargai
- sangat
- Kerentanan
- adalah
- Cara..
- we
- minggu
- adalah
- yang
- lebar
- Rentang luas
- akan
- dengan
- dalam
- tanpa
- Kerja
- bekerja
- bekerja
- dunia
- mengkhawatirkan
- tahun
- zephyrnet.dll
Lebih dari Nanowerk
Melepaskan era baru perangkat nano yang dapat diatur warna – sumber cahaya terkecil yang pernah ada dengan warna yang dapat diganti
Node Sumber: 2801585
Stempel Waktu: Agustus 3, 2023

Pelarut 'Magic' menciptakan film tipis yang lebih kuat
Node Sumber: 1957849
Stempel Waktu: Februari 14, 2023
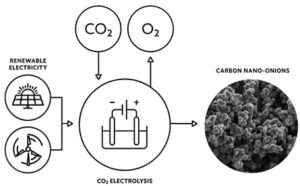
Tabung nano karbon mungkin memainkan peran penting dalam mengikat karbon dioksida di atmosfer
Node Sumber: 2836729
Stempel Waktu: Agustus 21, 2023

Cetakan 3D bergabung dengan sisi gelap dan menghilang
Node Sumber: 2903619
Stempel Waktu: September 27, 2023
Ketika material menjadi kuantum, elektron melambat dan membentuk kristal
Node Sumber: 1975767
Stempel Waktu: Februari 23, 2023

Insinyur mengembangkan proses yang efisien untuk membuat bahan bakar dari karbon dioksida
Node Sumber: 2963812
Stempel Waktu: Oktober 30, 2023