AWS गोंद स्टूडियो एक ग्राफिकल इंटरफ़ेस है जो इसमें एक्सट्रैक्ट, ट्रांसफॉर्म और लोड (ETL) जॉब बनाना, चलाना और मॉनिटर करना आसान बनाता है एडब्ल्यूएस गोंद. यह आपको विभिन्न डेटा हैंडलिंग चरणों का प्रतिनिधित्व करने वाले नोड्स का उपयोग करके डेटा ट्रांसफ़ॉर्मेशन वर्कफ़्लोज़ को नेत्रहीन रूप से बनाने की अनुमति देता है, जो बाद में चलने के लिए स्वचालित रूप से कोड में परिवर्तित हो जाते हैं।
AWS गोंद स्टूडियो हाल ही में जारी कोडिंग कौशल के बिना विज़ुअल तरीके से अधिक उन्नत नौकरियां बनाने की अनुमति देने के लिए 10 और दृश्य परिवर्तन। इस पोस्ट में, हम संभावित उपयोग के मामलों पर चर्चा करते हैं जो सामान्य ईटीएल आवश्यकताओं को दर्शाते हैं।
इस पोस्ट में प्रदर्शित किए जाने वाले नए परिवर्तन हैं: कॉन्टेनेट, स्प्लिट स्ट्रिंग, एरे टू कॉलम, वर्तमान टाइमस्टैम्प जोड़ें, कॉलम में पिवट पंक्तियाँ, पंक्तियों में अनपिवट कॉलम, लुकअप, एक्सप्लोड ऐरे या मैप इनटू कॉलम, व्युत्पन्न कॉलम, और ऑटोबैलेंस प्रोसेसिंग .
समाधान अवलोकन
इस उपयोग के मामले में, हमारे पास स्टॉक ऑप्शन ऑपरेशंस के साथ कुछ JSON फाइलें हैं। हम विश्लेषण करना आसान बनाने के लिए डेटा को संग्रहीत करने से पहले कुछ परिवर्तन करना चाहते हैं, और हम एक अलग डेटासेट सारांश भी तैयार करना चाहते हैं।
इस डेटासेट में, प्रत्येक पंक्ति विकल्प अनुबंधों के व्यापार का प्रतिनिधित्व करती है। विकल्प वित्तीय साधन हैं जो एक निश्चित मूल्य पर स्टॉक शेयर खरीदने या बेचने का अधिकार प्रदान करते हैं - लेकिन दायित्व नहीं (कहा जाता है हड़ताल की कीमत) एक परिभाषित समाप्ति तिथि से पहले।
इनपुट डेटा
डेटा निम्न स्कीमा का अनुसरण करता है:
- आदेश ID - एक यूनिक आईडी
- प्रतीक - आमतौर पर निगम की पहचान करने के लिए कुछ अक्षरों पर आधारित एक कोड जो अंतर्निहित स्टॉक शेयरों का उत्सर्जन करता है
- साधन – वह नाम जो खरीदे या बेचे जा रहे विशिष्ट विकल्प की पहचान करता है
- मुद्रा - आईएसओ मुद्रा कोड जिसमें मूल्य व्यक्त किया गया है
- मूल्य - वह राशि जो प्रत्येक विकल्प अनुबंध की खरीद के लिए भुगतान की गई थी (अधिकांश एक्सचेंजों पर, एक अनुबंध आपको 100 स्टॉक शेयर खरीदने या बेचने की अनुमति देता है)
- एक्सचेंज - विनिमय केंद्र या स्थान का कोड जहां विकल्प का कारोबार किया गया था
- बेचा – जब यह बिक्री व्यापार होता है तो बिक्री आदेश भरने के लिए आवंटित किए गए अनुबंधों की संख्या की एक सूची
- खरीदा - अनुबंधों की संख्या की एक सूची जहां यह खरीद व्यापार होने पर खरीद ऑर्डर भरने के लिए आवंटित किया गया है
निम्नलिखित इस पोस्ट के लिए उत्पन्न सिंथेटिक डेटा का एक नमूना है:
ईटीएल आवश्यकताएँ
इस डेटा में कई अनूठी विशेषताएँ हैं, जो अक्सर पुराने सिस्टम पर पाई जाती हैं, जो डेटा को उपयोग करने में कठिन बनाती हैं।
ईटीएल आवश्यकताएं निम्नलिखित हैं:
- उपकरण के नाम में बहुमूल्य जानकारी है जो मनुष्यों को समझने के लिए अभिप्रेत है; हम आसान विश्लेषण के लिए इसे अलग-अलग कॉलम में सामान्यीकृत करना चाहते हैं।
- गुण
boughtऔरsoldपरस्पर अनन्य हैं; हम उन्हें अनुबंध संख्या के साथ एक कॉलम में समेकित कर सकते हैं और एक अन्य कॉलम इंगित कर सकते हैं कि क्या अनुबंध इस क्रम में खरीदे या बेचे गए हैं। - हम व्यक्तिगत अनुबंध आवंटन के बारे में जानकारी रखना चाहते हैं लेकिन उपयोगकर्ताओं को संख्याओं की एक सरणी से निपटने के लिए मजबूर करने के बजाय अलग-अलग पंक्तियों के रूप में रखना चाहते हैं। हम संख्याओं को जोड़ सकते हैं, लेकिन हम इस बारे में जानकारी खो देंगे कि ऑर्डर कैसे भरा गया था (बाजार की तरलता का संकेत)। इसके बजाय, हम तालिका को असामान्य करना चुनते हैं ताकि प्रत्येक पंक्ति में अनुबंधों की एक ही संख्या हो, अलग-अलग पंक्तियों में कई संख्याओं के साथ विभाजन आदेश। एक संपीड़ित स्तंभ प्रारूप में, संपीड़न लागू होने पर इस पुनरावृत्ति का अतिरिक्त डेटासेट आकार अक्सर छोटा होता है, इसलिए डेटासेट को क्वेरी करना आसान बनाना स्वीकार्य है।
- हम प्रत्येक स्टॉक के लिए प्रत्येक विकल्प प्रकार (कॉल और पुट) के लिए वॉल्यूम की सारांश तालिका बनाना चाहते हैं। यह प्रत्येक शेयर और सामान्य रूप से बाजार (लालच बनाम भय) के लिए बाजार की भावना का संकेत देता है।
- समग्र व्यापार सारांश को सक्षम करने के लिए, हम प्रत्येक ऑपरेशन के लिए कुल योग प्रदान करना चाहते हैं और अनुमानित रूपांतरण संदर्भ का उपयोग करके मुद्रा को यूएस डॉलर में मानकीकृत करना चाहते हैं।
- हम उस तारीख को जोड़ना चाहते हैं जब ये परिवर्तन हुए थे। यह उपयोगी हो सकता है, उदाहरण के लिए, मुद्रा रूपांतरण कब किया गया था, इस पर एक संदर्भ होना।
उन आवश्यकताओं के आधार पर, कार्य दो आउटपुट उत्पन्न करेगा:
- प्रत्येक प्रतीक और प्रकार के अनुबंधों की संख्या के सारांश के साथ एक CSV फ़ाइल
- संकेतित परिवर्तनों को करने के बाद, आदेश का इतिहास रखने के लिए एक कैटलॉग तालिका
.. पूर्वापेक्षाएँ
इस उपयोग मामले के साथ पालन करने के लिए आपको अपनी स्वयं की S3 बाल्टी की आवश्यकता होगी। एक नई बकेट बनाने के लिए, देखें एक बाल्टी बनाना.
सिंथेटिक डेटा उत्पन्न करें
इस पोस्ट के साथ पालन करने के लिए (या इस प्रकार के डेटा के साथ स्वयं प्रयोग करें), आप इस डेटासेट को कृत्रिम रूप से उत्पन्न कर सकते हैं। निम्न Python स्क्रिप्ट को Boto3 स्थापित और एक्सेस करने के साथ Python वातावरण पर चलाया जा सकता है अमेज़न सरल भंडारण सेवा (अमेज़न S3)।
डेटा उत्पन्न करने के लिए, निम्न चरणों को पूरा करें:
- एडब्ल्यूएस ग्लू स्टूडियो पर, विकल्प के साथ एक नया कार्य सृजित करें पायथन शेल स्क्रिप्ट संपादक.
- कार्य को एक नाम दें और पर नौकरी विवरण टैब, एक का चयन करें उपयुक्त भूमिका और पायथन लिपि के लिए एक नाम।
- में नौकरी विवरण खंड, विस्तार उन्नत गुण और नीचे स्क्रॉल करें नौकरी के पैरामीटर.
- नामित पैरामीटर दर्ज करें
--bucketऔर उस बकेट के नाम को मान के रूप में असाइन करें जिसका उपयोग आप नमूना डेटा संग्रहीत करने के लिए करना चाहते हैं। - एडब्ल्यूएस गोंद खोल संपादक में निम्न स्क्रिप्ट दर्ज करें:
- कार्य चलाएँ और तब तक प्रतीक्षा करें जब तक कि यह रन टैब पर सफलतापूर्वक पूरा न हो जाए (इसमें कुछ ही सेकंड लगने चाहिए)।
प्रत्येक रन बकेट निर्दिष्ट और उपसर्ग के तहत 1,000 पंक्तियों के साथ एक JSON फ़ाइल उत्पन्न करेगा transformsblog/inputdata/. यदि आप अधिक इनपुट फ़ाइलों के साथ परीक्षण करना चाहते हैं तो आप कार्य को कई बार चला सकते हैं।
सिंथेटिक डेटा में प्रत्येक पंक्ति एक डेटा पंक्ति है जो JSON ऑब्जेक्ट का प्रतिनिधित्व करती है:
एडब्ल्यूएस गोंद दृश्य कार्य बनाएँ
AWS ग्लू विज़ुअल जॉब बनाने के लिए, निम्नलिखित चरणों को पूरा करें:
- एडब्ल्यूएस ग्लू स्टूडियो में जाएं और विकल्प का उपयोग करके नौकरी बनाएं एक खाली कैनवास के साथ दृश्य.
- संपादित करें
Untitled jobइसे एक नाम देने और असाइन करने के लिए AWS गोंद के लिए उपयुक्त भूमिका पर नौकरी विवरण टैब. - एक S3 डेटा स्रोत जोड़ें (आप इसे नाम दे सकते हैं
JSON files source) और S3 URL दर्ज करें जिसके तहत फ़ाइलें संग्रहीत की जाती हैं (उदाहरण के लिए,s3://<your bucket name>/transformsblog/inputdata/), फिर चुनें JSON डेटा प्रारूप के रूप में। - चुनते हैं स्कीमा का अनुमान लगाएं इसलिए यह डेटा के आधार पर आउटपुट स्कीमा सेट करता है।
इस स्रोत नोड से, आप चेनिंग रूपांतरण जारी रखेंगे। प्रत्येक परिवर्तन को जोड़ते समय, सुनिश्चित करें कि चयनित नोड अंतिम जोड़ा गया है, इसलिए इसे माता-पिता के रूप में निर्दिष्ट किया जाता है, जब तक कि निर्देशों में अन्यथा इंगित न किया गया हो।
यदि आपने सही माता-पिता का चयन नहीं किया है, तो आप हमेशा माता-पिता को चुनकर और कॉन्फ़िगरेशन फलक में अन्य माता-पिता चुनकर संपादित कर सकते हैं।
जोड़े गए प्रत्येक नोड के लिए, आप इसे एक विशिष्ट नाम देंगे (इसलिए ग्राफ़ में नोड उद्देश्य दिखाता है) और कॉन्फ़िगरेशन पर बदालना टैब.
हर बार जब कोई ट्रांसफ़ॉर्म स्कीमा को बदलता है (उदाहरण के लिए, एक नया कॉलम जोड़ें), तो आउटपुट स्कीमा को अपडेट करने की आवश्यकता होती है ताकि यह डाउनस्ट्रीम ट्रांसफ़ॉर्म को दिखाई दे। आप आउटपुट स्कीमा को मैन्युअल रूप से संपादित कर सकते हैं, लेकिन डेटा पूर्वावलोकन का उपयोग करके इसे करना अधिक व्यावहारिक और सुरक्षित है।
इसके अतिरिक्त, इस तरह से आप सत्यापित कर सकते हैं कि परिवर्तन अब तक अपेक्षा के अनुरूप काम कर रहा है। ऐसा करने के लिए, खोलें डेटा पूर्वावलोकन टैब चयनित परिवर्तन के साथ और एक पूर्वावलोकन सत्र प्रारंभ करें। आपके द्वारा सत्यापित किए जाने के बाद रूपांतरित डेटा अपेक्षा के अनुरूप दिखता है, पर जाएं आउटपुट स्कीमा टैब और चुनें डेटा पूर्वावलोकन स्कीमा का उपयोग करें स्कीमा को स्वचालित रूप से अपडेट करने के लिए।
जैसे ही आप नए प्रकार के परिवर्तन जोड़ते हैं, पूर्वावलोकन अनुपलब्ध निर्भरता के बारे में एक संदेश दिखा सकता है। जब ऐसा होता है, चुनें सत्र समाप्त करें और एक नई शुरुआत करें, ताकि प्रीव्यू नए प्रकार के नोड को चुन सके।
साधन जानकारी निकालें
आइए इंस्ट्रूमेंट के नाम पर जानकारी को कॉलम में सामान्यीकृत करने के लिए शुरू करें जो परिणामी आउटपुट टेबल में एक्सेस करना आसान हो।
- एक जोड़ें स्प्लिट स्ट्रिंग नोड और इसे नाम दें
Split instrument, जो व्हॉट्सएप रेगेक्स का उपयोग करके इंस्ट्रूमेंट कॉलम को टोकनाइज़ करेगा:s+(इस मामले में एक ही स्थान पर्याप्त होगा, लेकिन यह तरीका अधिक लचीला और स्पष्ट रूप से स्पष्ट है)। - हम मूल उपकरण जानकारी को वैसा ही रखना चाहते हैं, इसलिए विभाजित सरणी के लिए एक नया कॉलम नाम दर्ज करें:
instrument_arr.
- एक जोड़ें स्तंभों के लिए सरणी नोड और इसे नाम दें
Instrument columnsको छोड़कर, अभी बनाए गए सरणी कॉलम को नए फ़ील्ड में कनवर्ट करने के लिएsymbol, जिसके लिए हमारे पास पहले से ही एक कॉलम है। - कॉलम का चयन करें
instrument_arr, पहले टोकन को छोड़ दें और इसे आउटपुट कॉलम निकालने के लिए कहेंmonth, day, year, strike_price, typeअनुक्रमणिका का उपयोग करना2, 3, 4, 5, 6(अल्पविराम के बाद रिक्त स्थान पठनीयता के लिए हैं, वे कॉन्फ़िगरेशन को प्रभावित नहीं करते हैं)।
निकाले गए वर्ष को केवल दो अंकों के साथ व्यक्त किया जाता है; आइए एक स्टॉपगैप लगाते हैं यह मानने के लिए कि यह इस सदी में है अगर वे सिर्फ दो अंकों का उपयोग करते हैं।
- एक जोड़ें व्युत्पन्न स्तंभ नोड और इसे नाम दें
Four digits year. - दर्ज
yearव्युत्पन्न स्तंभ के रूप में इसलिए यह इसे ओवरराइड करता है, और निम्न SQL अभिव्यक्ति दर्ज करें:CASE WHEN length(year) = 2 THEN ('20' || year) ELSE year END
सुविधा के लिए, हम एक बनाते हैं expiration_date वह फ़ील्ड जो एक उपयोगकर्ता के पास अंतिम तिथि के संदर्भ के रूप में हो सकता है, विकल्प का प्रयोग किया जा सकता है।
- एक जोड़ें कॉलम जोड़ना नोड और इसे नाम दें
Build expiration date. - नए कॉलम को नाम दें
expiration_date, कॉलम चुनेंyear,month, तथाday(उस क्रम में), और स्पेसर के रूप में एक हाइफ़न।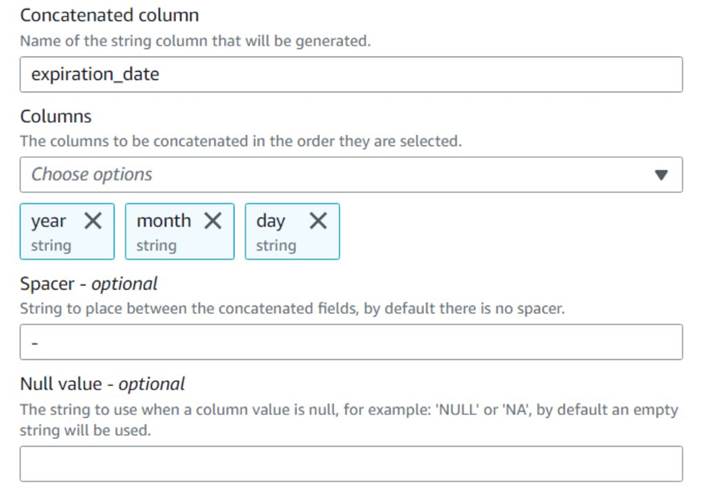
आरेख अब तक निम्न उदाहरण की तरह दिखना चाहिए।
![]()
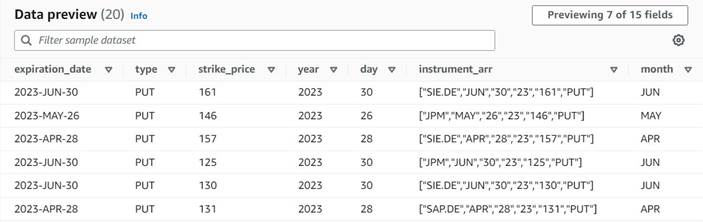
नए कॉलम का अब तक का डेटा पूर्वावलोकन निम्न स्क्रीनशॉट जैसा दिखना चाहिए।
अनुबंधों की संख्या को सामान्य करें
डेटा में प्रत्येक पंक्ति खरीदे या बेचे गए प्रत्येक विकल्प के अनुबंधों की संख्या और उन बैचों को इंगित करती है जिन पर ऑर्डर भरे गए थे। अलग-अलग बैचों के बारे में जानकारी खोए बिना, हम चाहते हैं कि प्रत्येक राशि एक एकल पंक्ति मान के साथ एक व्यक्तिगत पंक्ति पर हो, जबकि शेष जानकारी उत्पादित प्रत्येक पंक्ति में दोहराई जाती है।
सबसे पहले, आइए राशियों को एक कॉलम में मिला दें।
- एक जोड़ें स्तंभों को पंक्तियों में अनपिवट करें नोड और इसे नाम दें
Unpivot actions. - कॉलम चुनें
boughtऔरsoldनामित स्तंभों में नामों और मानों को खोलना और संग्रहीत करनाactionऔरcontracts, क्रमशः।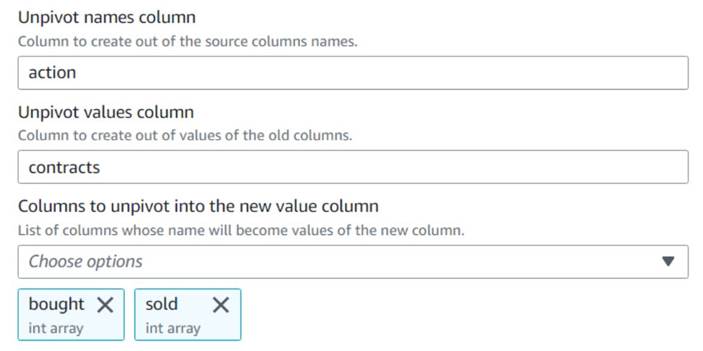
पूर्वावलोकन में ध्यान दें कि नया कॉलमcontractsइस परिवर्तन के बाद भी संख्याओं की एक सरणी है।
- एक जोड़ें पंक्तियों में सरणी या मानचित्र विस्फोट करें पंक्ति नामित
Explode contracts. - चुनना
contractsकॉलम और दर्ज करेंcontractsइसे ओवरराइड करने के लिए नए कॉलम के रूप में (हमें मूल सरणी रखने की आवश्यकता नहीं है)।
पूर्वावलोकन अब दिखाता है कि प्रत्येक पंक्ति में एक एकल है contracts राशि, और शेष क्षेत्र समान हैं।
इसका मतलब यह भी है कि order_id अब कोई अनूठी कुंजी नहीं है। अपने स्वयं के उपयोग के मामलों के लिए, आपको यह तय करने की आवश्यकता है कि आप अपने डेटा को कैसे मॉडल करें और यदि आप असामान्य बनाना चाहते हैं या नहीं।
निम्न स्क्रीनशॉट इसका एक उदाहरण है कि अब तक के परिवर्तनों के बाद नए कॉलम कैसे दिखते हैं।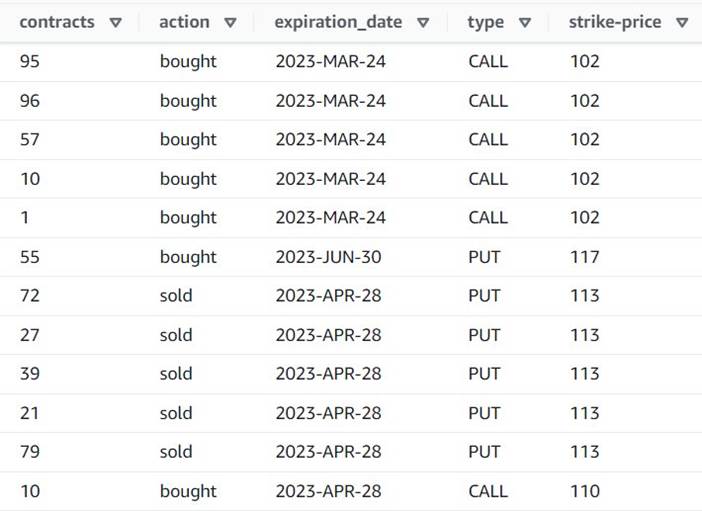
सारांश तालिका बनाएँ
अब आप प्रत्येक प्रकार और प्रत्येक स्टॉक प्रतीक के लिए ट्रेड किए गए अनुबंधों की संख्या के साथ एक सारांश तालिका बनाते हैं।
आइए उदाहरण के उद्देश्यों के लिए मान लें कि संसाधित की गई फाइलें एक ही दिन की हैं, इसलिए यह सारांश व्यापार उपयोगकर्ताओं को इस बारे में जानकारी देता है कि उस दिन बाजार की रुचि और भावना क्या है।
- एक जोड़ें फ़ील्ड्स चुनें नोड और सारांश के लिए रखने के लिए निम्न स्तंभों का चयन करें:
symbol,type, तथाcontracts.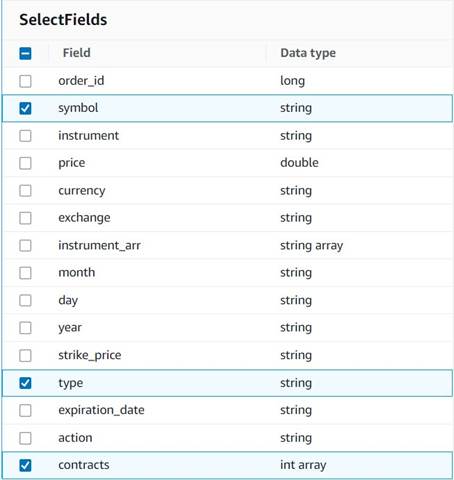
- एक जोड़ें पंक्तियों को स्तंभों में पिवट करें नोड और इसे नाम दें
Pivot summary. - पर एकत्र करें
contractsकॉलम का उपयोग करsumऔर कनवर्ट करना चुनेंtypeस्तंभ.
आम तौर पर, आप इसे संदर्भ के लिए किसी बाहरी डेटाबेस या फ़ाइल पर संग्रहीत करेंगे; इस उदाहरण में, हम इसे Amazon S3 पर CSV फ़ाइल के रूप में सहेजते हैं।
- एक जोड़ें ऑटोबैलेंस प्रोसेसिंग नोड और इसे नाम दें
Single output file. - हालाँकि उस ट्रांसफ़ॉर्म प्रकार का उपयोग सामान्य रूप से समानता को अनुकूलित करने के लिए किया जाता है, यहाँ हम इसका उपयोग आउटपुट को एक फ़ाइल में कम करने के लिए करते हैं। इसलिए प्रवेश करें
1विभाजन विन्यास की संख्या में।
- एक S3 लक्ष्य जोड़ें और इसे नाम दें
CSV Contract summary. - CSV को डेटा प्रारूप के रूप में चुनें और एक S3 पथ दर्ज करें जहाँ फ़ाइलों को संग्रहीत करने के लिए कार्य भूमिका की अनुमति है।
कार्य का अंतिम भाग अब निम्न उदाहरण की तरह दिखना चाहिए।![]()
- कार्य को सहेजें और चलाएं। उपयोग रन टैब यह जांचने के लिए कि यह सफलतापूर्वक कब समाप्त हुआ है।
उस एक्सटेंशन के न होने के बावजूद आपको उस पथ के अंतर्गत एक फ़ाइल मिलेगी जो CSV है। इसे डाउनलोड करने के बाद इसे खोलने के लिए आपको संभवतः एक्सटेंशन जोड़ने की आवश्यकता होगी।
एक उपकरण पर जो सीएसवी पढ़ सकता है, सारांश को निम्न उदाहरण जैसा कुछ दिखना चाहिए।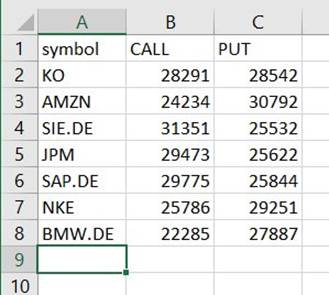
अस्थायी कॉलम साफ करें
भविष्य के विश्लेषण के लिए ऑर्डर को एक ऐतिहासिक तालिका में सहेजने की तैयारी में, आइए रास्ते में बनाए गए कुछ अस्थायी स्तंभों को साफ़ करें।
- एक जोड़ें ड्रॉप फील्ड्स के साथ नोड
Explode contractsनोड को इसके माता-पिता के रूप में चुना गया है (हम एक अलग आउटपुट उत्पन्न करने के लिए डेटा पाइपलाइन को ब्रांच कर रहे हैं)। - छोड़े जाने वाले क्षेत्रों का चयन करें:
instrument_arr,month,day, तथाyear.
बाकी हम रखना चाहते हैं ताकि वे उस ऐतिहासिक तालिका में सहेजे जाएँ जिसे हम बाद में बनाएंगे।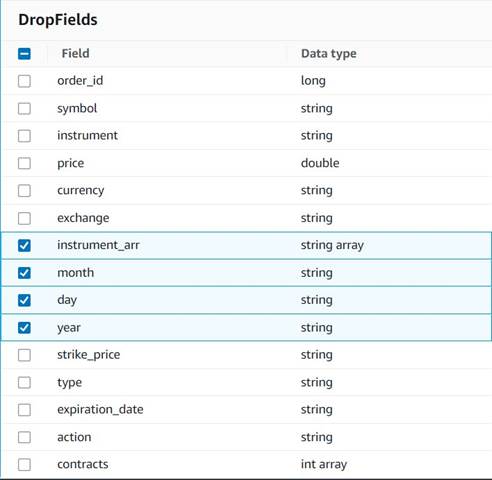
मुद्रा मानकीकरण
इस सिंथेटिक डेटा में दो मुद्राओं पर काल्पनिक संचालन शामिल हैं, लेकिन वास्तविक प्रणाली में आप दुनिया भर के बाजारों से मुद्राएं प्राप्त कर सकते हैं। एकल संदर्भ मुद्रा में संभाली गई मुद्राओं को मानकीकृत करना उपयोगी है ताकि रिपोर्टिंग और विश्लेषण के लिए उनकी आसानी से तुलना की जा सके और उनका योग किया जा सके।
हम का उपयोग करें अमेज़न एथेना अनुमानित मुद्रा रूपांतरणों वाली एक तालिका का अनुकरण करने के लिए जो समय-समय पर अपडेट होती रहती है (यहाँ हम मानते हैं कि हम आदेशों को समय पर पर्याप्त रूप से संसाधित करते हैं कि रूपांतरण तुलनात्मक उद्देश्यों के लिए एक उचित प्रतिनिधि है)।
- एथेना कंसोल को उसी क्षेत्र में खोलें जहां आप एडब्ल्यूएस गोंद का उपयोग कर रहे हैं।
- S3 स्थान सेट करके तालिका बनाने के लिए निम्न क्वेरी चलाएँ जहाँ आपकी Athena और AWS Glue दोनों भूमिकाएँ पढ़ और लिख सकें। साथ ही, हो सकता है कि आप तालिका को किसी भिन्न डेटाबेस में संग्रहीत करना चाहें
default(यदि आप ऐसा करते हैं, तो दिए गए उदाहरणों के अनुसार तालिका योग्य नाम अपडेट करें)। - तालिका में कुछ नमूना रूपांतरण दर्ज करें:
INSERT INTO default.exchange_rates VALUES ('usd', 1.0), ('eur', 1.09), ('gbp', 1.24); - अब आपको निम्न क्वेरी के साथ तालिका देखने में सक्षम होना चाहिए:
SELECT * FROM default.exchange_rates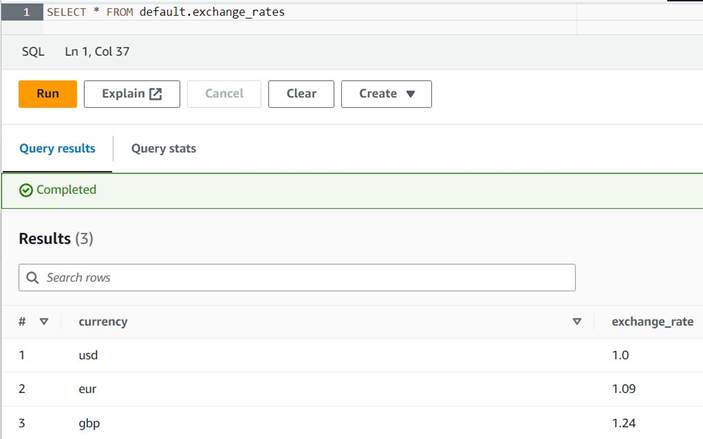
- AWS ग्लू विज़ुअल जॉब पर वापस, एक जोड़ें लुक अप नोड (एक बच्चे के रूप में
Drop Fields) और इसे नाम देंExchange rate. - आपके द्वारा अभी-अभी बनाई गई तालिका का गुणात्मक नाम दर्ज करें
currencyकुंजी के रूप में और चुनेंexchange_rateउपयोग करने के लिए क्षेत्र।
क्योंकि फ़ील्ड का नाम डेटा और लुकअप तालिका दोनों में समान है, हम केवल नाम दर्ज कर सकते हैंcurrencyऔर मैपिंग को परिभाषित करने की आवश्यकता नहीं है।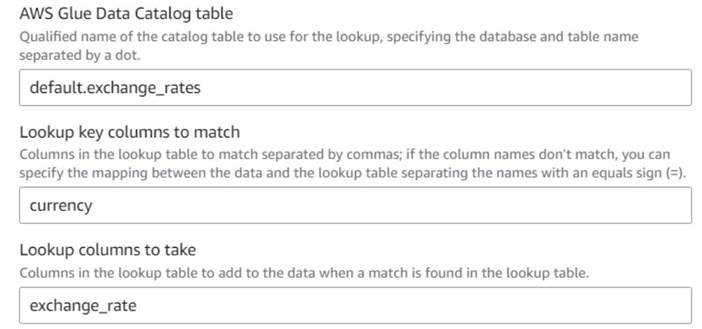
इस लेखन के समय, डेटा पूर्वावलोकन में लुकअप रूपांतरण समर्थित नहीं है और यह एक त्रुटि दिखाएगा कि तालिका मौजूद नहीं है। यह केवल डेटा पूर्वावलोकन के लिए है और कार्य को ठीक से चलने से नहीं रोकता है। पोस्ट के कुछ शेष चरणों में आपको स्कीमा को अपडेट करने की आवश्यकता नहीं है। यदि आपको अन्य नोड्स पर डेटा पूर्वावलोकन चलाने की आवश्यकता है, तो आप लुकअप नोड को अस्थायी रूप से हटा सकते हैं और फिर इसे वापस रख सकते हैं। - एक जोड़ें व्युत्पन्न स्तंभ नोड और इसे नाम दें
Total in usd. - व्युत्पन्न स्तंभ का नाम दें
total_usdऔर निम्न SQL अभिव्यक्ति का उपयोग करें:round(contracts * price * exchange_rate, 2)
- एक जोड़ें वर्तमान टाइमस्टैम्प जोड़ें नोड और कॉलम को नाम दें
ingest_date. - प्रारूप का प्रयोग करें
%Y-%m-%dआपके टाइमस्टैम्प के लिए (प्रदर्शन उद्देश्यों के लिए, हम केवल तारीख का उपयोग कर रहे हैं; यदि आप चाहें तो इसे और अधिक सटीक बना सकते हैं)।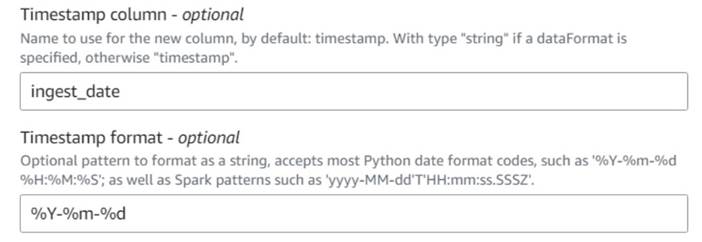
ऐतिहासिक आदेश तालिका सहेजें
ऐतिहासिक आदेश तालिका को सहेजने के लिए, निम्न चरणों को पूरा करें:
- एक S3 लक्ष्य नोड जोड़ें और इसे नाम दें
Orders table. - तड़क-भड़क वाले संपीड़न के साथ Parquet प्रारूप को कॉन्फ़िगर करें, और एक S3 लक्ष्य पथ प्रदान करें जिसके तहत परिणामों को संग्रहीत किया जाए (सारांश से अलग)।
- चुनते हैं डेटा कैटलॉग में एक तालिका बनाएं और बाद के रन पर, स्कीमा को अपडेट करें और नए विभाजन जोड़ें.
- उदाहरण के लिए, लक्ष्य डेटाबेस और नई तालिका के लिए एक नाम दर्ज करें:
option_orders.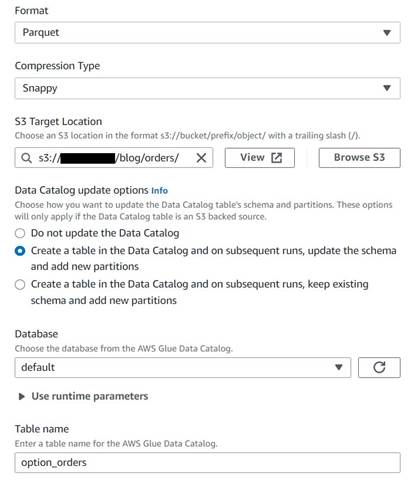
आरेख के अंतिम भाग को अब दो अलग-अलग आउटपुट के लिए दो शाखाओं के साथ निम्न के समान दिखना चाहिए।![]()
कार्य को सफलतापूर्वक चलाने के बाद, आप एथेना जैसे उपकरण का उपयोग उस डेटा की समीक्षा करने के लिए कर सकते हैं, जिसे कार्य ने नई तालिका क्वेरी करके उत्पादित किया है. आप एथेना सूची पर तालिका पा सकते हैं और चुन सकते हैं पूर्वावलोकन तालिका या केवल एक चयन क्वेरी चलाएं (आपके द्वारा उपयोग किए गए नाम और कैटलॉग में तालिका का नाम अपडेट करना):
SELECT * FROM default.option_orders limit 10
आपकी तालिका सामग्री निम्न स्क्रीनशॉट के समान दिखनी चाहिए।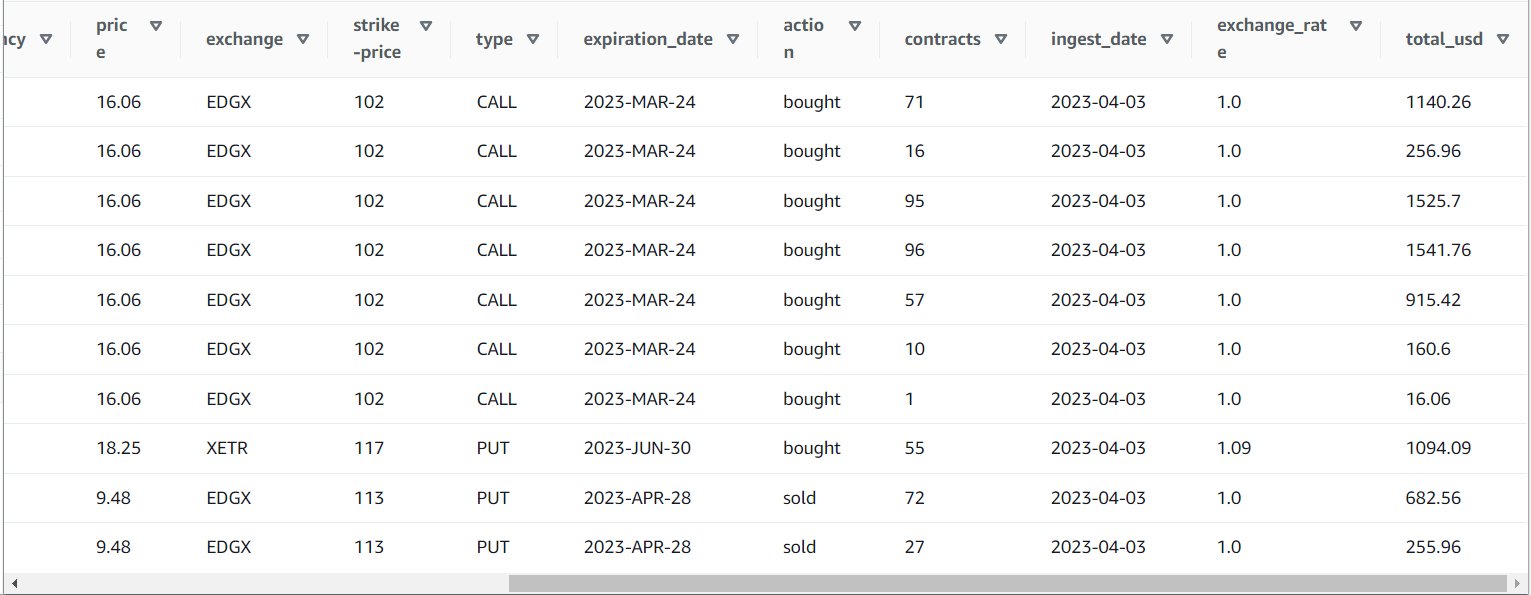
क्लीन अप
यदि आप इस उदाहरण को नहीं रखना चाहते हैं, तो आपके द्वारा बनाए गए दो कार्य, एथेना में दो तालिकाएँ, और S3 पथ जहाँ इनपुट और आउटपुट फ़ाइलें संग्रहीत की गई थीं, हटा दें।
निष्कर्ष
इस पोस्ट में, हमने दिखाया कि कैसे AWS Glue Studio में नया परिवर्तन आपको न्यूनतम कॉन्फ़िगरेशन के साथ अधिक उन्नत परिवर्तन करने में मदद कर सकता है। इसका मतलब है कि आप किसी भी कोड को लिखे और बनाए रखने के बिना अधिक ईटीएल उपयोग मामलों को लागू कर सकते हैं। AWS Glue Studio पर नए परिवर्तन पहले से ही उपलब्ध हैं, इसलिए आप आज ही अपने दृश्य कार्यों में नए परिवर्तनों का उपयोग कर सकते हैं।
लेखक के बारे में
![]() गोंजालो हेरेरोस एडब्ल्यूएस ग्लू टीम में वरिष्ठ बिग डेटा आर्किटेक्ट हैं।
गोंजालो हेरेरोस एडब्ल्यूएस ग्लू टीम में वरिष्ठ बिग डेटा आर्किटेक्ट हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोआईस्ट्रीम। Web3 डेटा इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- मिंटिंग द फ्यूचर डब्ल्यू एड्रिएन एशले। यहां पहुंचें।
- PREIPO® के साथ PRE-IPO कंपनियों में शेयर खरीदें और बेचें। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/ten-new-visual-transforms-in-aws-glue-studio/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 000
- 1
- 10
- 100
- 102
- 11
- 12
- 13
- 14
- 15% तक
- 20
- 23
- 24
- 26
- 28
- 30
- 49
- 67
- 7
- 8
- 9
- 937
- 98
- a
- योग्य
- About
- स्वीकार्य
- पहुँच
- तदनुसार
- जोड़ना
- जोड़ा
- जोड़ने
- उन्नत
- बाद
- सब
- आवंटित
- आवंटन
- अनुमति देना
- की अनुमति देता है
- साथ में
- पहले ही
- भी
- हमेशा
- वीरांगना
- राशि
- राशियाँ
- an
- विश्लेषण
- विश्लेषण करें
- और
- अन्य
- कोई
- लागू
- अनुमानित
- अप्रैल
- हैं
- तर्क
- ऐरे
- AS
- सौंपा
- At
- विशेषताओं
- स्वतः
- उपलब्ध
- एडब्ल्यूएस
- एडब्ल्यूएस गोंद
- वापस
- आधारित
- BE
- से पहले
- जा रहा है
- बड़ा
- बड़ा डेटा
- रिक्त
- बीएमडब्ल्यू
- के छात्रों
- खरीदा
- शाखाएं
- निर्माण
- व्यापार
- लेकिन
- खरीदने के लिए
- by
- कॉल
- कर सकते हैं
- मामला
- मामलों
- सूची
- केंद्र
- सदी
- परिवर्तन
- विशेषताएँ
- चेक
- बच्चा
- चुनें
- चुनने
- साफ
- कोड
- कोडन
- स्तंभ
- स्तंभ
- सामान्य
- तुलना
- तुलना
- पूरा
- पूरा
- विन्यास
- कंसोल
- को मजबूत
- शामिल हैं
- सामग्री
- अनुबंध
- ठेके
- सुविधा
- रूपांतरण
- रूपांतरण
- बदलना
- परिवर्तित
- निगम
- सका
- बनाना
- बनाया
- बनाना
- मुद्रा
- मुद्रा
- वर्तमान
- डेग
- तिथि
- डाटाबेस
- तारीख
- खजूर
- दिनांक और समय
- दिन
- सौदा
- व्यवहार
- तय
- चूक
- परिभाषित
- साबित
- निर्भरता
- निकाली गई
- के बावजूद
- विवरण
- विभिन्न
- अंक
- चर्चा करना
- do
- नहीं करता है
- कर
- डॉलर
- dont
- डबल
- नीचे
- बूंद
- गिरा
- से प्रत्येक
- आसान
- आसानी
- आसान
- संपादक
- सक्षम
- पर्याप्त
- दर्ज
- वातावरण
- त्रुटि
- ईथर (ईटीएच)
- ईयूआर
- उदाहरण
- उदाहरण
- सिवाय
- एक्सचेंज
- एक्सचेंजों
- अनन्य
- मौजूद
- विस्तार
- अपेक्षित
- प्रयोग
- समाप्ति
- व्यक्त
- विस्तार
- बाहरी
- अतिरिक्त
- उद्धरण
- दूर
- डर
- कुछ
- कल्पित
- खेत
- फ़ील्ड
- पट्टिका
- फ़ाइलें
- भरना
- भरा हुआ
- वित्तीय
- वित्तीय प्रपत्र
- खोज
- प्रथम
- तय
- लचीला
- का पालन करें
- निम्नलिखित
- इस प्रकार है
- के लिए
- प्रारूप
- पाया
- से
- भविष्य
- जीबीपी
- सामान्य जानकारी
- आम तौर पर
- उत्पन्न
- उत्पन्न
- मिल
- देना
- देता है
- Go
- ग्राफ
- लालच
- हैंडलिंग
- हो जाता
- है
- होने
- मदद
- यहाँ उत्पन्न करें
- ऐतिहासिक
- इतिहास
- कैसे
- How To
- एचटीएमएल
- http
- HTTPS
- मनुष्य
- i
- पहचानती
- पहचान करना
- if
- प्रभाव
- लागू करने के
- आयात
- in
- अनुक्रमणिका
- संकेत दिया
- इंगित करता है
- यह दर्शाता है
- संकेत
- व्यक्ति
- करें-
- निवेश
- उदाहरण
- बजाय
- निर्देश
- साधन
- यंत्र
- ब्याज
- इंटरफेस
- में
- आईएसओ
- IT
- आईटी इस
- काम
- नौकरियां
- जेपीजी
- JSON
- केवल
- रखना
- कुंजी
- बच्चा
- पिछली बार
- बाद में
- पसंद
- सीमा
- लाइन
- चलनिधि
- सूची
- भार
- स्थान
- लंबे समय तक
- देखिए
- हमशक्ल
- लग रहा है
- लुकअप
- खोना
- हार
- बनाया गया
- बनाए रखना
- बनाना
- बनाता है
- मैन्युअल
- नक्शा
- मानचित्रण
- बाजार
- बाजार की धारणा
- Markets
- मई..
- साधन
- मर्ज
- message
- हो सकता है
- न्यूनतम
- लापता
- आदर्श
- मॉनिटर
- अधिक
- अधिकांश
- विभिन्न
- आपस लगीं
- नाम
- नामांकित
- नामों
- आवश्यकता
- की जरूरत है
- नया
- नहीं
- नोड
- नोड्स
- सामान्य रूप से
- अभी
- संख्या
- संख्या
- वस्तु
- of
- अक्सर
- on
- ONE
- केवल
- खुला
- आपरेशन
- संचालन
- ऑप्टिमाइज़ करें
- विकल्प
- ऑप्शंस
- or
- आदेश
- आदेशों
- मूल
- अन्य
- अन्यथा
- उत्पादन
- के ऊपर
- कुल
- ओवरराइड
- अपना
- प्रदत्त
- फलक
- प्राचल
- भाग
- पथ
- की पसंद
- पाइपलाइन
- प्रधान आधार
- जगह
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- पद
- संभावित
- व्यावहारिक
- ठीक
- को रोकने के
- पूर्वावलोकन
- मूल्य
- शायद
- प्रक्रिया
- प्रसंस्करण
- उत्पादन
- प्रस्तुत
- प्रदान करना
- बशर्ते
- प्रदान करता है
- क्रय
- उद्देश्य
- प्रयोजनों
- रखना
- अजगर
- योग्य
- उठाना
- बिना सोचे समझे
- पढ़ना
- वास्तविक
- उचित
- को कम करने
- प्रतिबिंबित
- क्षेत्र
- शेष
- हटाना
- दोहराया
- रिपोर्टिंग
- प्रतिनिधित्व
- प्रतिनिधि
- का प्रतिनिधित्व
- का प्रतिनिधित्व करता है
- की आवश्यकता होती है
- आवश्यकताएँ
- की आवश्यकता होती है
- क्रमश
- बाकी
- जिसके परिणामस्वरूप
- परिणाम
- की समीक्षा
- भूमिका
- भूमिकाओं
- आरओडब्ल्यू
- रन
- दौड़ना
- सुरक्षित
- वही
- पौधों का रस
- सहेजें
- बचत
- स्क्रॉल
- सेकंड
- चयनित
- का चयन
- बेचना
- वरिष्ठ
- भावुकता
- अलग
- सत्र
- सेट
- की स्थापना
- शेयरों
- खोल
- चाहिए
- दिखाना
- दिखाता है
- समान
- सरल
- एक
- आकार
- कौशल
- छोटा
- So
- अब तक
- बेचा
- कुछ
- कुछ
- स्रोत
- अंतरिक्ष
- रिक्त स्थान
- विशिष्ट
- विनिर्दिष्ट
- विभाजित
- स्प्रेडशीट
- एसक्यूएल
- प्रारंभ
- कदम
- फिर भी
- स्टॉक
- भंडारण
- की दुकान
- संग्रहित
- तार
- स्टूडियो
- आगामी
- सफलतापूर्वक
- उपयुक्त
- सारांश
- समर्थित
- प्रतीक
- कृत्रिम
- सिंथेटिक डेटा
- कृत्रिम
- प्रणाली
- सिस्टम
- तालिका
- लेना
- लक्ष्य
- टीम
- कहना
- अस्थायी
- दस
- परीक्षण
- से
- कि
- RSI
- लेखाचित्र
- जानकारी
- दुनिया
- उन
- फिर
- इसलिये
- इन
- वे
- इसका
- उन
- पहर
- बार
- टाइमस्टैम्प
- सेवा मेरे
- आज
- टोकन
- tokenize
- ले गया
- साधन
- कुल
- व्यापार
- कारोबार
- बदालना
- परिवर्तन
- परिवर्तनों
- तब्दील
- दो
- टाइप
- के अंतर्गत
- आधारभूत
- समझना
- अद्वितीय
- जब तक
- अपडेट
- अद्यतन
- अद्यतन
- यूआरएल
- us
- अमरीकी डॉलर
- यूएसडी
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग
- मूल्यवान
- बहुमूल्य जानकारी
- मूल्य
- मान
- स्थल
- सत्यापित
- सत्यापित
- देखें
- दिखाई
- आयतन
- vs
- प्रतीक्षा
- करना चाहते हैं
- था
- मार्ग..
- we
- थे
- क्या
- कब
- कौन कौन से
- जब
- मर्जी
- साथ में
- बिना
- workflows
- काम कर रहे
- विश्व
- होगा
- लिखना
- लिख रहे हैं
- वर्ष
- इसलिए आप
- आपका
- जेफिरनेट











