आज के डिजिटल युग में, डेटा हर संगठन की सफलता के केंद्र में है। डेटा के आदान-प्रदान के लिए सबसे अधिक इस्तेमाल किया जाने वाला प्रारूप XML है। XML फ़ाइलों का विश्लेषण करना कई कारणों से महत्वपूर्ण है। सबसे पहले, XML फ़ाइलों का उपयोग वित्त, स्वास्थ्य देखभाल और सरकार सहित कई उद्योगों में किया जाता है। XML फ़ाइलों का विश्लेषण करने से संगठनों को अपने डेटा में अंतर्दृष्टि प्राप्त करने में मदद मिल सकती है, जिससे उन्हें बेहतर निर्णय लेने और अपने संचालन में सुधार करने की अनुमति मिलती है। XML फ़ाइलों का विश्लेषण करने से डेटा एकीकरण में भी मदद मिल सकती है, क्योंकि कई एप्लिकेशन और सिस्टम XML को मानक डेटा प्रारूप के रूप में उपयोग करते हैं। XML फ़ाइलों का विश्लेषण करके, संगठन विभिन्न स्रोतों से डेटा को आसानी से एकीकृत कर सकते हैं और अपने सिस्टम में स्थिरता सुनिश्चित कर सकते हैं, हालाँकि, XML फ़ाइलों में अर्ध-संरचित, अत्यधिक नेस्टेड डेटा होता है, जिससे जानकारी तक पहुँचना और उसका विश्लेषण करना मुश्किल हो जाता है, खासकर यदि फ़ाइल बड़ी हो और जटिल, अत्यधिक नेस्टेड स्कीमा।
XML फ़ाइलें अनुप्रयोगों के लिए उपयुक्त हैं, लेकिन वे एनालिटिक्स इंजन के लिए इष्टतम नहीं हो सकती हैं। क्वेरी प्रदर्शन को बढ़ाने और डाउनस्ट्रीम एनालिटिक्स इंजन जैसे आसान पहुंच को सक्षम करने के लिए अमेज़न एथेना, XML फ़ाइलों को Parquet जैसे स्तंभ प्रारूप में प्रीप्रोसेस करना महत्वपूर्ण है। यह परिवर्तन एनालिटिक्स वर्कफ़्लो में बेहतर दक्षता और उपयोगिता की अनुमति देता है। इस पोस्ट में, हम दिखाते हैं कि XML डेटा का उपयोग कैसे करें एडब्ल्यूएस गोंद और एथेना.
समाधान अवलोकन
हम दो अलग-अलग तकनीकों का पता लगाते हैं जो आपके XML फ़ाइल प्रोसेसिंग वर्कफ़्लो को सुव्यवस्थित कर सकती हैं:
- तकनीक 1: AWS ग्लू क्रॉलर और AWS ग्लू विज़ुअल एडिटर का उपयोग करें - आप अपनी XML फ़ाइलों के लिए तालिका संरचना को परिभाषित करने के लिए क्रॉलर के साथ AWS ग्लू उपयोगकर्ता इंटरफ़ेस का उपयोग कर सकते हैं। यह दृष्टिकोण एक उपयोगकर्ता-अनुकूल इंटरफ़ेस प्रदान करता है और विशेष रूप से उन व्यक्तियों के लिए उपयुक्त है जो अपने डेटा को प्रबंधित करने के लिए ग्राफिकल दृष्टिकोण पसंद करते हैं।
- तकनीक 2: अनुमानित और निश्चित स्कीमा के साथ AWS ग्लू डायनामिकफ़्रेम का उपयोग करें - जब XML फ़ाइलों से बड़ी एकल पंक्ति को संसाधित करने की बात आती है तो क्रॉलर की एक सीमा होती है 1 एमबी. इस प्रतिबंध को दूर करने के लिए, हम AWS ग्लू के निर्माण के लिए AWS ग्लू नोटबुक का उपयोग करते हैं
DynamicFrames, अनुमानित और निश्चित दोनों स्कीमा का उपयोग करना। यह विधि 1 एमबी से अधिक आकार की पंक्तियों वाली XML फ़ाइलों का कुशल प्रबंधन सुनिश्चित करती है।
दोनों दृष्टिकोणों में, हमारा अंतिम लक्ष्य XML फ़ाइलों को Apache Parquet प्रारूप में परिवर्तित करना है, जिससे उन्हें एथेना का उपयोग करके पूछताछ के लिए आसानी से उपलब्ध कराया जा सके। इन तकनीकों के साथ, आप अपने XML डेटा की प्रसंस्करण गति और पहुंच को बढ़ा सकते हैं, जिससे आप आसानी से मूल्यवान अंतर्दृष्टि प्राप्त कर सकेंगे।
.. पूर्वापेक्षाएँ
इस ट्यूटोरियल को शुरू करने से पहले, निम्नलिखित आवश्यक शर्तें पूरी करें (ये दोनों तकनीकों पर लागू होती हैं):
- XML फ़ाइलें डाउनलोड करें तकनीक1.xml और तकनीक2.xml.
- फ़ाइलों को एक पर अपलोड करें अमेज़न सरल भंडारण सेवा (अमेज़ॅन S3) बाल्टी। आप उन्हें अलग-अलग फ़ोल्डरों में एक ही S3 बकेट में या अलग-अलग S3 बकेट में अपलोड कर सकते हैं।
- एक बनाएं AWS पहचान और अभिगम प्रबंधन आपके ईटीएल कार्य या नोटबुक के लिए (आईएएम) भूमिका, जैसा कि निर्देश दिया गया है AWS ग्लू स्टूडियो के लिए IAM अनुमतियाँ सेट करें.
- के साथ अपनी भूमिका में एक इनलाइन नीति जोड़ें पहले से ही: PassRole कार्रवाई:
- अपनी S3 बकेट तक पहुंच के साथ भूमिका में एक अनुमति नीति जोड़ें।
अब जब हमने आवश्यक शर्तें पूरी कर ली हैं, तो आइए पहली तकनीक को लागू करने की ओर आगे बढ़ें।
तकनीक 1: AWS ग्लू क्रॉलर और विज़ुअल एडिटर का उपयोग करें
निम्नलिखित आरेख सरल वास्तुकला को दर्शाता है जिसका उपयोग आप समाधान को लागू करने के लिए कर सकते हैं।
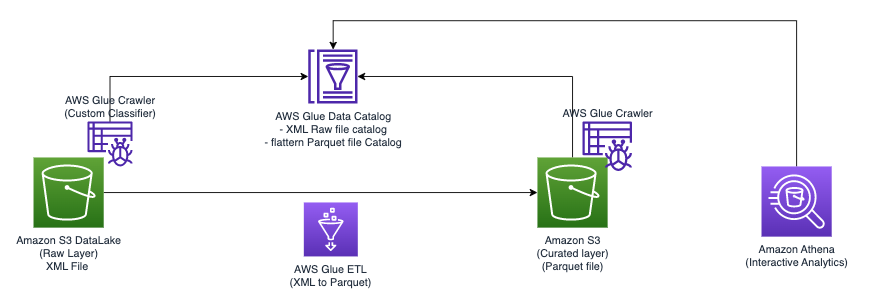
AWS ग्लू और एथेना का उपयोग करके Amazon S3 में संग्रहीत XML फ़ाइलों का विश्लेषण करने के लिए, हम निम्नलिखित उच्च-स्तरीय चरणों को पूरा करते हैं:
- XML मेटाडेटा निकालने और AWS ग्लू डेटा कैटलॉग में एक तालिका बनाने के लिए AWS ग्लू क्रॉलर बनाएं।
- AWS ग्लू एक्सट्रेक्ट, ट्रांसफ़ॉर्म और लोड (ETL) जॉब का उपयोग करके XML डेटा को एथेना के लिए उपयुक्त प्रारूप (जैसे Parquet) में संसाधित और परिवर्तित करें।
- AWS ग्लू कंसोल या के माध्यम से AWS ग्लू जॉब सेट अप करें और चलाएं AWS कमांड लाइन इंटरफ़ेस (AWS CLI)।
- SQL क्वेरी को सक्षम करते हुए, एथेना तालिकाओं के साथ संसाधित डेटा (पैरक्वेट प्रारूप में) का उपयोग करें।
- अमेज़ॅन S3 में संग्रहीत अपने डेटा पर SQL क्वेरी के साथ XML डेटा का विश्लेषण करने के लिए एथेना में उपयोगकर्ता के अनुकूल इंटरफ़ेस का उपयोग करें।
यह आर्किटेक्चर AWS ग्लू और एथेना का उपयोग करके Amazon S3 पर XML डेटा का विश्लेषण करने के लिए एक स्केलेबल, लागत प्रभावी समाधान है। आप जटिल बुनियादी ढांचे प्रबंधन के बिना बड़े डेटासेट का विश्लेषण कर सकते हैं।
हम XML फ़ाइल मेटाडेटा निकालने के लिए AWS ग्लू क्रॉलर का उपयोग करते हैं। आप सामान्य प्रयोजन XML वर्गीकरण के लिए डिफ़ॉल्ट AWS ग्लू क्लासिफायरियर चुन सकते हैं। यह स्वचालित रूप से XML डेटा संरचना और स्कीमा का पता लगाता है, जो सामान्य प्रारूपों के लिए उपयोगी है।
हम इस समाधान में एक कस्टम XML क्लासिफायरियर का भी उपयोग करते हैं। इसे विशिष्ट XML स्कीमा या प्रारूपों के लिए डिज़ाइन किया गया है, जो सटीक मेटाडेटा निष्कर्षण की अनुमति देता है। यह गैर-मानक XML प्रारूपों के लिए आदर्श है या जब आपको वर्गीकरण पर विस्तृत नियंत्रण की आवश्यकता होती है। एक कस्टम क्लासिफायर यह सुनिश्चित करता है कि केवल आवश्यक मेटाडेटा निकाला जाए, जिससे डाउनस्ट्रीम प्रसंस्करण और विश्लेषण कार्य सरल हो जाएं। यह दृष्टिकोण आपकी XML फ़ाइलों के उपयोग को अनुकूलित करता है।
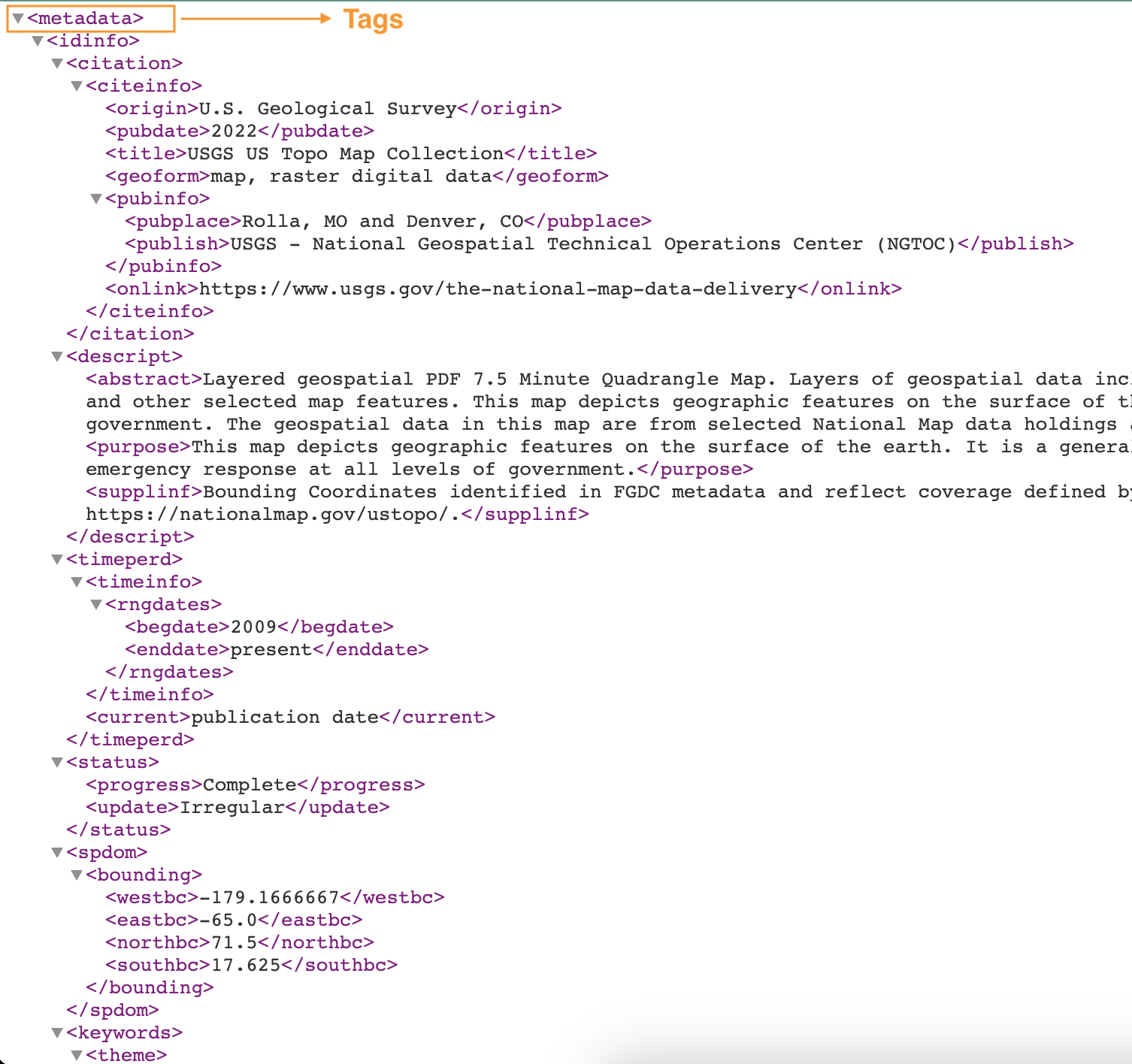
निम्नलिखित स्क्रीनशॉट टैग के साथ XML फ़ाइल का एक उदाहरण दिखाता है।
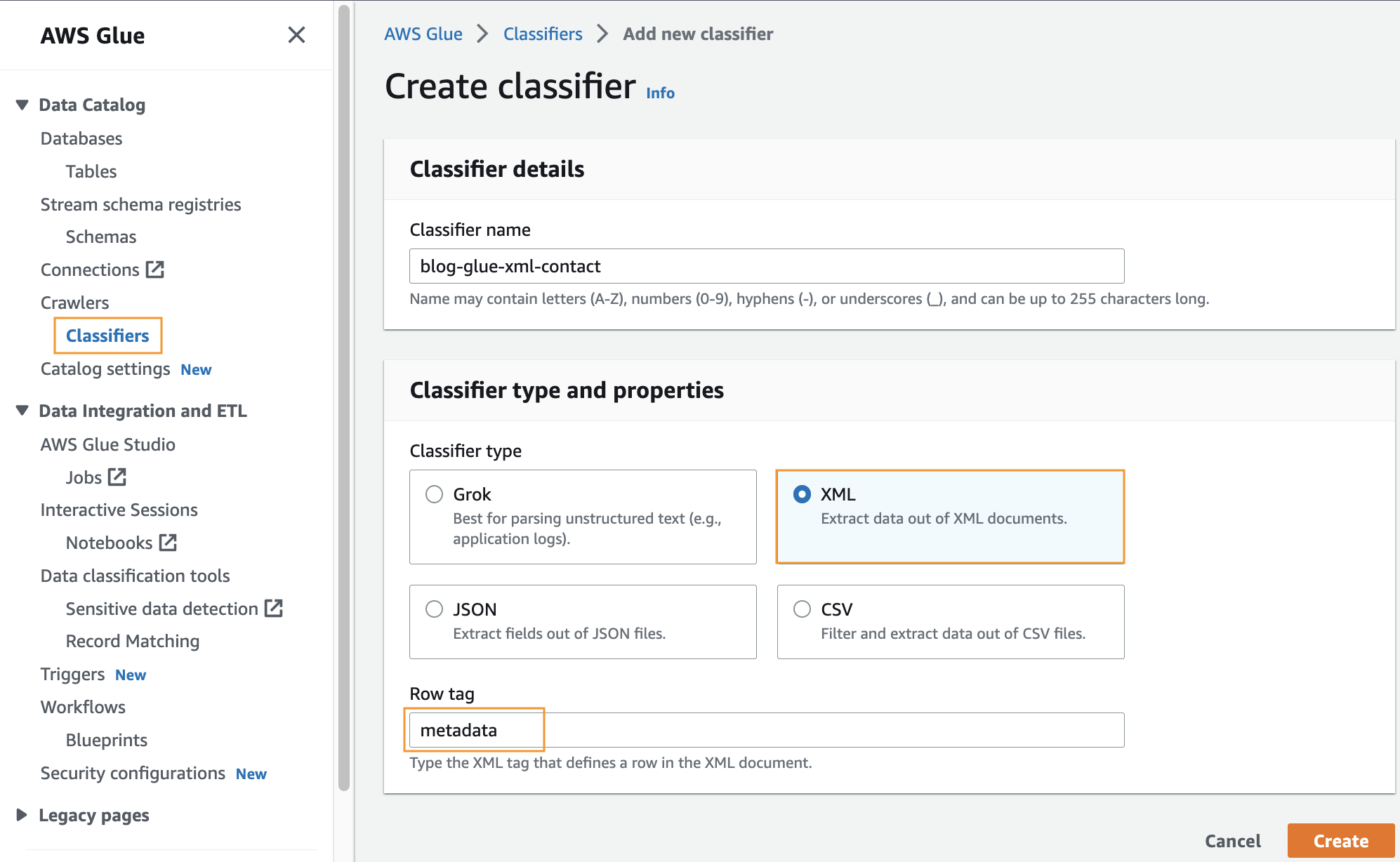
एक कस्टम क्लासिफायरियर बनाएं
इस चरण में, आप XML फ़ाइल से मेटाडेटा निकालने के लिए एक कस्टम AWS ग्लू क्लासिफायरियर बनाते हैं। निम्नलिखित चरणों को पूरा करें:
- AWS गोंद कंसोल पर, के तहत क्रौलर नेविगेशन फलक में, चुनें classifiers.
- चुनें क्लासीफायर जोड़ें.
- चुनते हैं एक्सएमएल क्लासिफायर प्रकार के रूप में।
- क्लासिफायर के लिए एक नाम दर्ज करें, जैसे कि
blog-glue-xml-contact. - के लिए पंक्ति टैग, रूट टैग का नाम दर्ज करें जिसमें मेटाडेटा शामिल है (उदाहरण के लिए,
metadata). - चुनें बनाएं.
xml फ़ाइल को क्रॉल करने के लिए AWS ग्लू क्रॉलर बनाएं
इस अनुभाग में, हम पिछले चरण में बनाए गए ग्राहक क्लासिफायर का उपयोग करके XML फ़ाइल से मेटाडेटा निकालने के लिए एक ग्लू क्रॉलर बना रहे हैं।
एक डेटाबेस बनाएँ
- इस पर जाएँ AWS गोंद कंसोल, चुनें डेटाबेस नेविगेशन फलक में
- पर क्लिक करें डेटाबेस जोड़ें.
- ऐसा कोई नाम प्रदान करें
blog_glue_xml - चुनें बनाएं डाटाबेस
एक क्रॉलर बनाएं
अपना पहला क्रॉलर बनाने के लिए निम्नलिखित चरणों को पूरा करें:
- एडब्ल्यूएस गोंद कंसोल पर, चुनें क्रौलर नेविगेशन फलक में
- चुनें क्रॉलर बनाएं.
- पर क्रॉलर गुण सेट करें पृष्ठ, नए क्रॉलर के लिए एक नाम प्रदान करें (जैसे
blog-glue-parquet), उसके बाद चुनो अगला. - पर डेटा स्रोत और क्लासिफायर चुनें पेज, का चयन करें अभी नहीं के अंतर्गत डेटा स्रोत कॉन्फ़िगरेशन.
- चुनें एक डेटा स्टोर जोड़ें.
- के लिए S3 पथ, ब्राउज़ करें
s3://${BUCKET_NAME}/input/geologicalsurvey/.
सुनिश्चित करें कि आप फ़ोल्डर के अंदर फ़ाइल के बजाय XML फ़ोल्डर चुनें।
- बाकी विकल्पों को डिफ़ॉल्ट के रूप में छोड़ दें और चुनें एक S3 डेटा स्रोत जोड़ें.
- विस्तार कस्टम क्लासिफायर - वैकल्पिक, ब्लॉग-ग्लू-एक्सएमएल-संपर्क चुनें, फिर चुनें अगला और बाकी विकल्पों को डिफ़ॉल्ट रखें।
- अपनी IAM भूमिका चुनें या चुनें नई IAM भूमिका बनाएं, प्रत्यय जोड़ें
glue-xml-contact(उदाहरण के लिए,AWSGlueServiceNotebookRoleBlog), और चुनें अगला. - पर आउटपुट और शेड्यूलिंग सेट करें पृष्ठ, के तहत आउटपुट कॉन्फ़िगरेशन, चुनें
blog_glue_xmlएसटी लक्ष्य डेटाबेस. - दर्ज
console_उपसर्ग के रूप में तालिकाओं में जोड़ा गया (वैकल्पिक) और नीचे क्रॉलर शेड्यूल, आवृत्ति को सेट रखें मांगने पर. - चुनें अगला.
- सभी मापदंडों की समीक्षा करें और चुनें क्रॉलर बनाएं.
क्रॉलर चलाएँ
क्रॉलर बनाने के बाद, इसे चलाने के लिए निम्नलिखित चरणों को पूरा करें:
- एडब्ल्यूएस गोंद कंसोल पर, चुनें क्रौलर नेविगेशन फलक में
- आपके द्वारा बनाया गया क्रॉलर खोलें और चुनें रन.
क्रॉलर को पूरा होने में 1-2 मिनट का समय लगेगा।
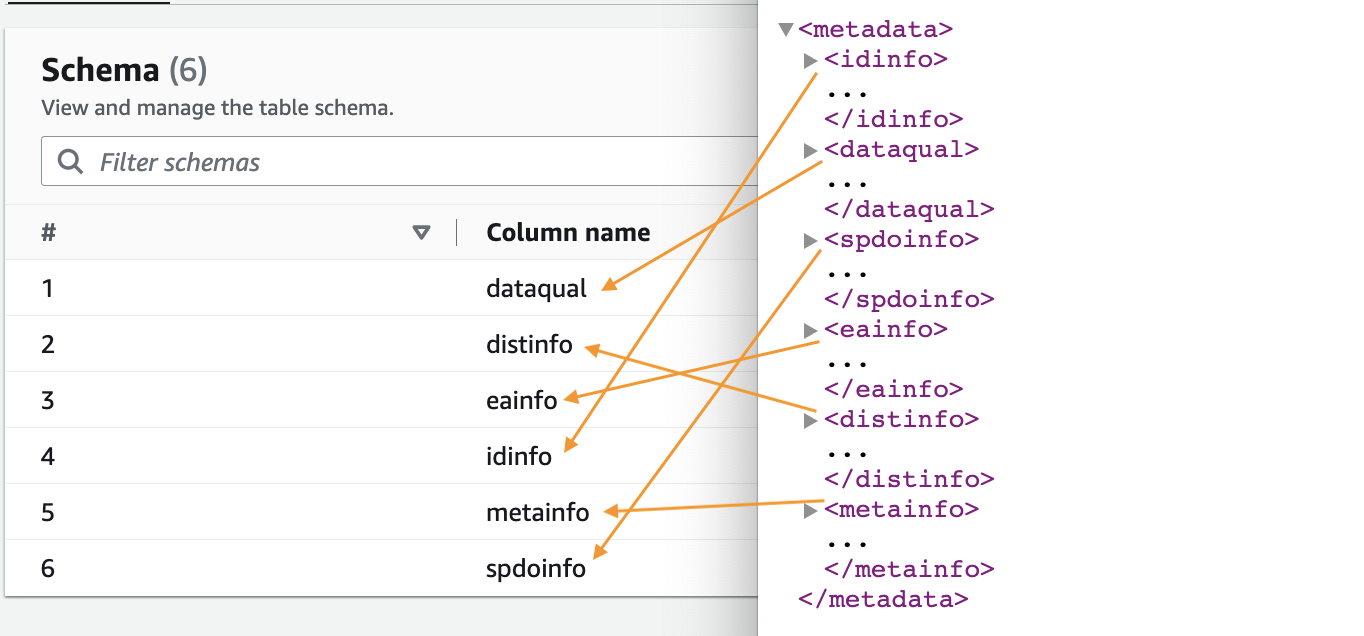
- जब क्रॉलर पूरा हो जाए, तो चुनें डेटाबेस नेविगेशन फलक में
- आपके द्वारा तैयार किया गया डेटाबेस चुनें और क्रॉलर द्वारा निकाली गई स्कीमा देखने के लिए तालिका का नाम चुनें।
XML को Parquet प्रारूप में बदलने के लिए AWS ग्लू जॉब बनाएं
इस चरण में, आप XML फ़ाइल को Parquet फ़ाइल में बदलने के लिए AWS ग्लू स्टूडियो जॉब बनाते हैं। निम्नलिखित चरणों को पूरा करें:
- एडब्ल्यूएस गोंद कंसोल पर, चुनें नौकरियां नेविगेशन फलक में
- के अंतर्गत नौकरी पैदा करो, चुनते हैं एक खाली कैनवास के साथ दृश्य.
- चुनें बनाएं.
- कार्य का नाम बदलें
blog_glue_xml_job.
अब आपके पास एक खाली AWS ग्लू स्टूडियो विज़ुअल जॉब एडिटर है। संपादक के शीर्ष पर विभिन्न दृश्यों के लिए टैब हैं।
- चुनना लिपि AWS ग्लू ETL स्क्रिप्ट का खाली शेल देखने के लिए टैब पर क्लिक करें।
जैसे ही हम विज़ुअल एडिटर में नए चरण जोड़ते हैं, स्क्रिप्ट स्वचालित रूप से अपडेट हो जाएगी।
- चुनना नौकरी विवरण सभी कार्य कॉन्फ़िगरेशन देखने के लिए टैब।
- के लिए IAM भूमिका, चुनें
AWSGlueServiceNotebookRoleBlog. - के लिए गोंद संस्करण, चुनें गोंद 4.0 - स्पार्क 3.3, स्काला 2, पायथन 3 का समर्थन करें.
- सेट श्रमिकों की अनुरोधित संख्या 2 लिए.
- सेट पुनर्प्रयास की संख्या 0 लिए.
- चुनना दृश्य विज़ुअल संपादक पर वापस जाने के लिए टैब।
- पर स्रोत ड्रॉप-डाउन मेनू, चुनें एडब्ल्यूएस गोंद डेटा कैटलॉग.
- पर डेटा स्रोत गुण - डेटा कैटलॉग टैब, निम्नलिखित जानकारी प्रदान करें:
- के लिए डाटाबेस, चुनें
blog_glue_xml. - के लिए तालिका, वह तालिका चुनें जो उस कंसोल_ नाम से शुरू होती है जिसे क्रॉलर ने बनाया है (उदाहरण के लिए,
console_geologicalsurvey).
- के लिए डाटाबेस, चुनें
- पर नोड गुण टैब, निम्नलिखित जानकारी प्रदान करें:
- परिवर्तन नाम सेवा मेरे
geologicalsurveyडाटासेट। - चुनें कार्य और परिवर्तन स्कीमा बदलें (मैपिंग लागू करें).
- चुनें नोड गुण और परिवर्तन का नाम चेंज स्कीमा (मैपिंग लागू करें) से बदलें
ApplyMapping. - पर लक्ष्य मेनू, चुनें S3.
- परिवर्तन नाम सेवा मेरे
- पर डेटा स्रोत गुण - S3 टैब, निम्नलिखित जानकारी प्रदान करें:
- के लिए का गठन, चुनते हैं लकड़ी की छत.
- के लिए संपीड़न प्रकार, चुनते हैं असम्पीडित.
- के लिए S3 स्रोत प्रकार, चुनते हैं S3 स्थान.
- के लिए एस3 यूआरएल, दर्ज
s3://${BUCKET_NAME}/output/parquet/. - चुनें नोड गुण और नाम बदल दें
Output.
- चुनें सहेजें नौकरी बचाने के लिए।
- चुनें रन नौकरी चलाने के लिए।
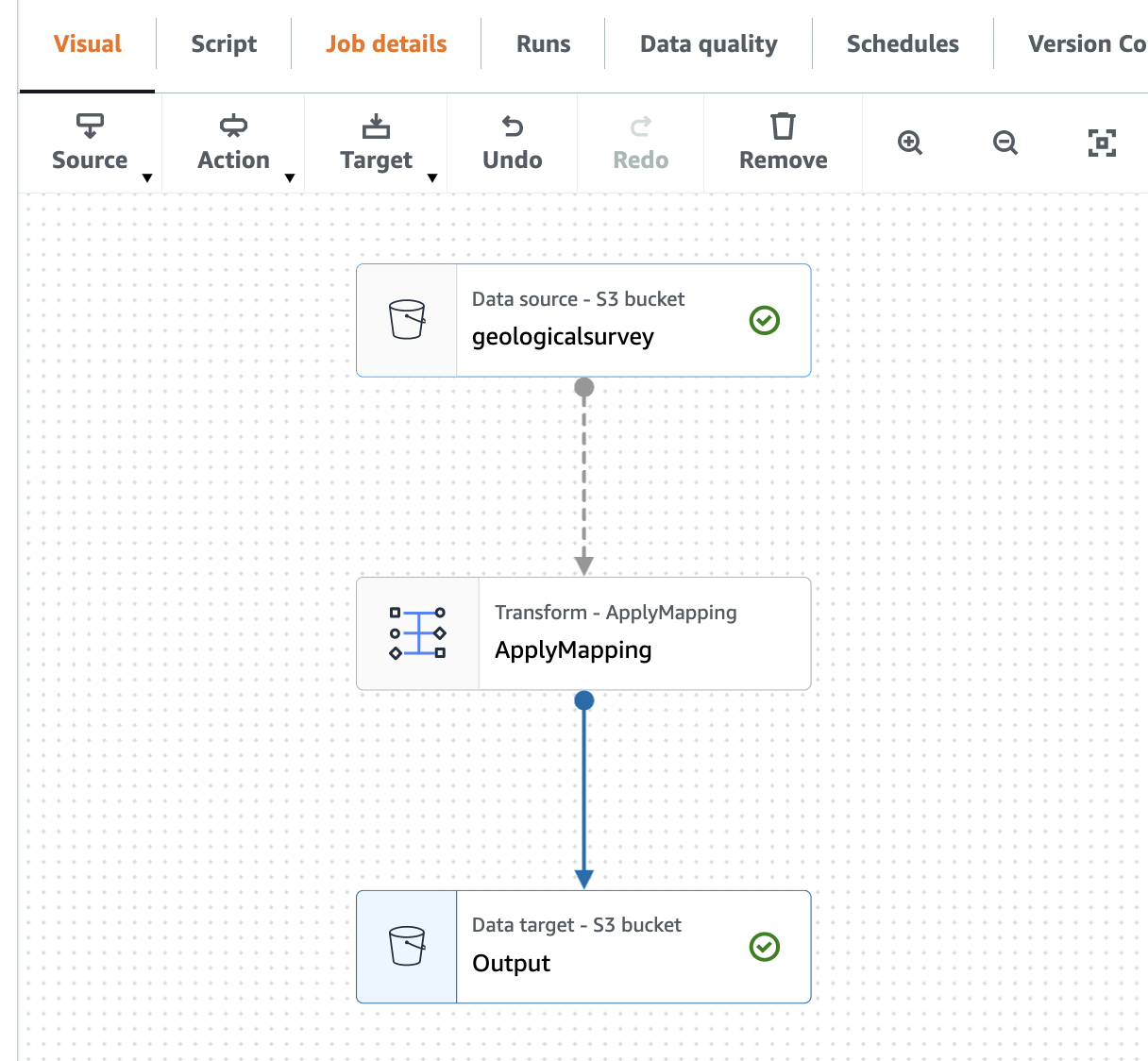
निम्नलिखित स्क्रीनशॉट विज़ुअल एडिटर में कार्य दिखाता है।
Parquet फ़ाइल को क्रॉल करने के लिए AWS ग्यू क्रॉलर बनाएं
इस चरण में, आप AWS ग्लू स्टूडियो जॉब का उपयोग करके बनाई गई Parquet फ़ाइल से मेटाडेटा निकालने के लिए एक AWS ग्लू क्रॉलर बनाते हैं। इस बार, आप डिफ़ॉल्ट क्लासिफायर का उपयोग करें। निम्नलिखित चरणों को पूरा करें:
- एडब्ल्यूएस गोंद कंसोल पर, चुनें क्रौलर नेविगेशन फलक में
- चुनें क्रॉलर बनाएं.
- पर क्रॉलर गुण सेट करें पृष्ठ, नए क्रॉलर के लिए एक नाम प्रदान करें, जैसे ब्लॉग-ग्लू-पैरक्वेट-संपर्क, फिर चुनें अगला.
- पर डेटा स्रोत और क्लासिफायर चुनें पेज, का चयन करें अभी नहीं एसटी डेटा स्रोत कॉन्फ़िगरेशन.
- चुनें एक डेटा स्टोर जोड़ें.
- के लिए S3 पथ, ब्राउज़ करें
s3://${BUCKET_NAME}/output/parquet/.
सुनिश्चित करें कि आप चुनें parquet फ़ोल्डर के अंदर फ़ाइल के बजाय फ़ोल्डर।
- आवश्यक अनुभाग के दौरान बनाई गई अपनी IAM भूमिका चुनें या चुनें नई IAM भूमिका बनाएं (उदाहरण के लिए,
AWSGlueServiceNotebookRoleBlog), और चुनें अगला. - पर आउटपुट और शेड्यूलिंग सेट करें पृष्ठ, के तहत आउटपुट कॉन्फ़िगरेशन, चुनें
blog_glue_xmlएसटी डाटाबेस. - दर्ज
parquet_उपसर्ग के रूप में तालिकाओं में जोड़ा गया (वैकल्पिक) और नीचे क्रॉलर शेड्यूल, आवृत्ति को सेट रखें मांगने पर. - चुनें अगला.
- सभी मापदंडों की समीक्षा करें और चुनें क्रॉलर बनाएं.
अब आप क्रॉलर चला सकते हैं, जिसे पूरा होने में 1-2 मिनट लगते हैं।

आप AWS ग्लू डेटा कैटलॉग में Parquet फ़ाइल के लिए नव निर्मित स्कीमा का पूर्वावलोकन कर सकते हैं, जो XML फ़ाइल की स्कीमा के समान है।
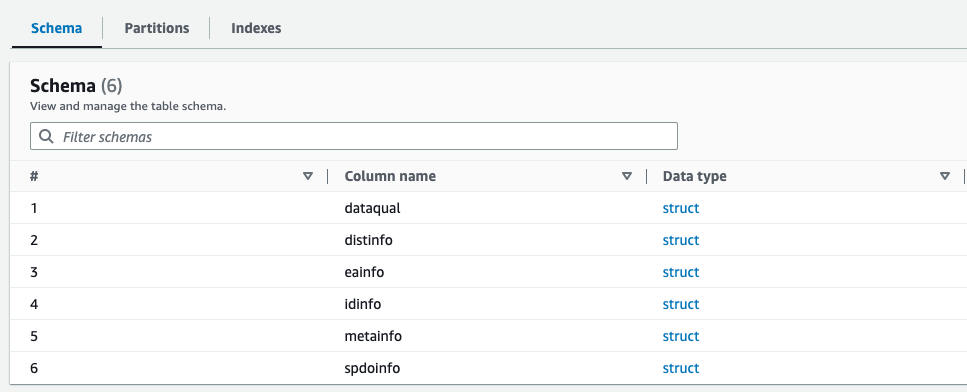
अब हमारे पास वह डेटा है जो एथेना के साथ उपयोग के लिए उपयुक्त है। अगले भाग में, हम एथेना का उपयोग करके डेटा क्वेरी करते हैं।
एथेना का उपयोग करके Parquet फ़ाइल को क्वेरी करें
एथेना पूछताछ का समर्थन नहीं करती एक्सएमएल फ़ाइल स्वरूप, यही कारण है कि आपने अधिक कुशल डेटा क्वेरी और उपयोग के लिए XML फ़ाइल को Parquet में परिवर्तित कर दिया है डॉट नोटेशन जटिल प्रकारों और नेस्टेड संरचनाओं को क्वेरी करने के लिए।
निम्न उदाहरण कोड नेस्टेड डेटा को क्वेरी करने के लिए डॉट नोटेशन का उपयोग करता है:
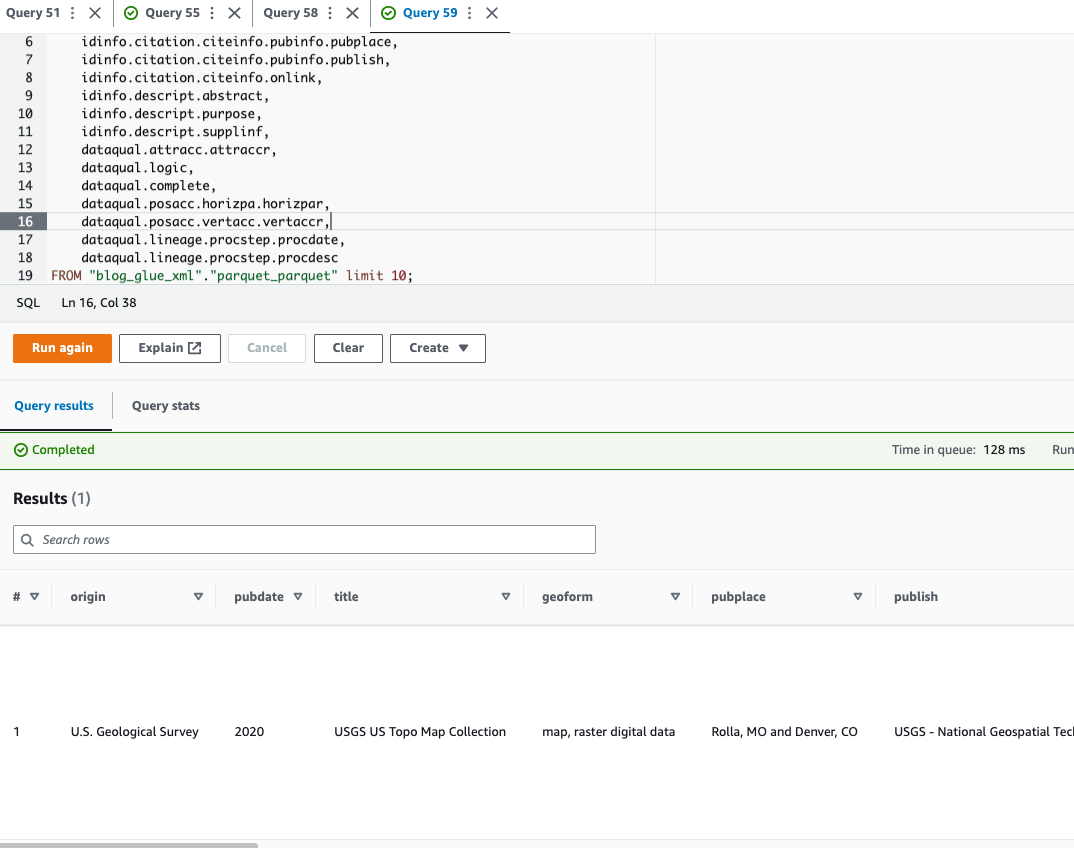
अब जब हमने तकनीक 1 पूरी कर ली है, तो आइए तकनीक 2 के बारे में जानने के लिए आगे बढ़ें।
तकनीक 2: अनुमानित और निश्चित स्कीमा के साथ AWS ग्लू डायनामिकफ़्रेम का उपयोग करें
पिछले अनुभाग में, हमने एक तालिका बनाने के लिए AWS ग्लू क्रॉलर का उपयोग करके एक छोटी XML फ़ाइल को संभालने की प्रक्रिया, फ़ाइल को Parquet प्रारूप में परिवर्तित करने के लिए AWS ग्लू जॉब और Parquet डेटा तक पहुँचने के लिए एथेना को कवर किया था। हालाँकि, जब XML फ़ाइलों को संसाधित करने की बात आती है तो क्रॉलर को सीमाओं का सामना करना पड़ता है 1 एमबी आकार में. इस अनुभाग में, हम बड़ी XML फ़ाइलों के बैच प्रोसेसिंग के विषय पर गहराई से चर्चा करते हैं, जिससे व्यक्तिगत घटनाओं को निकालने और एथेना का उपयोग करके विश्लेषण करने के लिए अतिरिक्त पार्सिंग की आवश्यकता होती है।
हमारे दृष्टिकोण में AWS ग्लू के माध्यम से XML फ़ाइलों को पढ़ना शामिल है डायनामिकफ़्रेम्स, अनुमानित और निश्चित दोनों स्कीमा को नियोजित करना। फिर हम इसका उपयोग करके अलग-अलग घटनाओं को Parquet प्रारूप में निकालते हैं संबंध बनाना परिवर्तन, हमें एथेना का उपयोग करके निर्बाध रूप से उनसे पूछताछ करने और उनका विश्लेषण करने में सक्षम बनाता है।
इस समाधान को लागू करने के लिए, आप निम्न उच्च-स्तरीय चरणों को पूरा करते हैं:
- XML फ़ाइल को पढ़ने और उसका विश्लेषण करने के लिए AWS ग्लू नोटबुक बनाएं।
- उपयोग
DynamicFramesसाथ मेंInferSchemaXML फ़ाइल को पढ़ने के लिए. - किसी भी सरणी को अननेस्ट करने के लिए रिलेशनलाइज़ फ़ंक्शन का उपयोग करें।
- डेटा को Parquet प्रारूप में कनवर्ट करें।
- एथेना का उपयोग करके Parquet डेटा को क्वेरी करें।
- पिछले चरणों को दोहराएँ, लेकिन इस बार एक स्कीमा पास करें
DynamicFramesके बजाय का उपयोग करने काInferSchema.
इलेक्ट्रिक वाहन जनसंख्या डेटा XML फ़ाइल में एक है response इसके मूल स्तर पर टैग करें। इस टैग में एक सारणी शामिल है row टैग, जो इसके भीतर नेस्टेड हैं। पंक्ति टैग एक सरणी है जिसमें अन्य पंक्ति टैग का एक सेट होता है, जो किसी वाहन के बारे में जानकारी प्रदान करता है, जिसमें उसका मेक, मॉडल और अन्य प्रासंगिक विवरण शामिल होते हैं। निम्नलिखित स्क्रीनशॉट एक उदाहरण दिखाता है.

एक AWS ग्लू नोटबुक बनाएं
AWS ग्लू नोटबुक बनाने के लिए, निम्नलिखित चरणों को पूरा करें:
- ओपन AWS गोंद स्टूडियो सांत्वना, चुनें नौकरियां नेविगेशन फलक में
- चुनते हैं जुपीटर नोटबुक और चुनें बनाएं.
- अपने AWS ग्लू कार्य के लिए एक नाम दर्ज करें, जैसे
blog_glue_xml_job_Jupyter. - वह भूमिका चुनें जो आपने पूर्वापेक्षाओं में बनाई है (
AWSGlueServiceNotebookRoleBlog).
AWS ग्लू नोटबुक एक पहले से मौजूद उदाहरण के साथ आता है जो दर्शाता है कि डेटाबेस को कैसे क्वेरी करें और अमेज़ॅन S3 पर आउटपुट कैसे लिखें।
- निम्नलिखित स्क्रीनशॉट में दिखाए अनुसार टाइमआउट (मिनटों में) समायोजित करें और AWS ग्लू इंटरैक्टिव सत्र बनाने के लिए सेल चलाएँ।
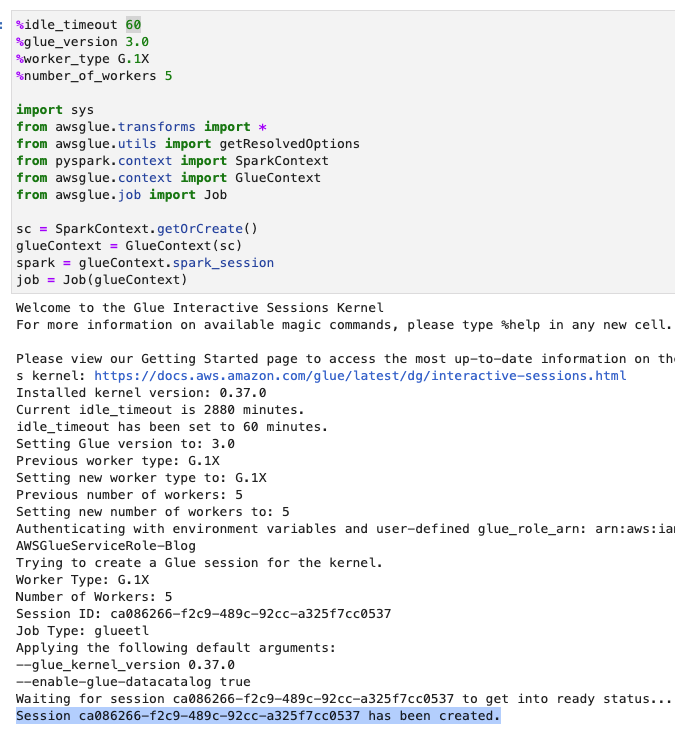
बुनियादी वेरिएबल बनाएं
इंटरैक्टिव सत्र बनाने के बाद, नोटबुक के अंत में, निम्नलिखित चर के साथ एक नया सेल बनाएं (अपना खुद का बकेट नाम प्रदान करें):
स्कीमा का अनुमान लगाते हुए XML फ़ाइल पढ़ें
यदि आप कोई स्कीमा पास नहीं करते हैं DynamicFrame, यह फ़ाइलों की स्कीमा का अनुमान लगाएगा। डायनामिक फ़्रेम का उपयोग करके डेटा पढ़ने के लिए, आप निम्न कमांड का उपयोग कर सकते हैं:
डायनामिकफ़्रेम स्कीमा प्रिंट करें
निम्नलिखित कोड के साथ स्कीमा प्रिंट करें:
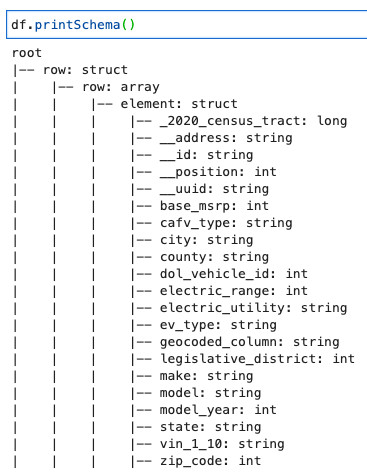
स्कीमा एक नेस्टेड संरचना को दिखाती है row एकाधिक तत्वों वाली सरणी। इस संरचना को लाइनों में विभाजित करने के लिए, आप AWS गोंद का उपयोग कर सकते हैं संबंध बनाना परिवर्तन:
हम केवल पंक्ति सरणी में मौजूद जानकारी में रुचि रखते हैं, और हम निम्नलिखित कमांड का उपयोग करके स्कीमा देख सकते हैं:
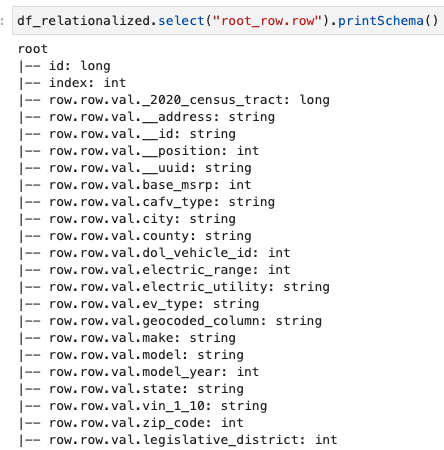
स्तंभ नामों में शामिल हैं row.row, जो डेटासेट में सरणी संरचना और सरणी कॉलम के अनुरूप है। हम इस पोस्ट में कॉलम का नाम नहीं बदलते हैं; ऐसा करने के निर्देशों के लिए, देखें AWS ग्लू का उपयोग करके डेटा फ़ाइलों में डायनामिक मैपिंग और कॉलम नामों का नाम बदलना स्वचालित करें: भाग 1. फिर आप डेटा को Parquet प्रारूप में परिवर्तित कर सकते हैं और निम्नलिखित कमांड का उपयोग करके AWS ग्लू तालिका बना सकते हैं:
एडब्ल्यूएस गोंद DynamicFrame ऐसी सुविधाएँ प्रदान करता है जिनका उपयोग आप डेटा कैटलॉग में स्कीमा बनाने और अपडेट करने के लिए अपनी ईटीएल स्क्रिप्ट में कर सकते हैं। हम उपयोग करते हैं updateBehavior डेटा कैटलॉग में सीधे तालिका बनाने के लिए पैरामीटर। इस दृष्टिकोण के साथ, AWS ग्लू कार्य पूरा होने के बाद हमें AWS ग्लू क्रॉलर चलाने की आवश्यकता नहीं है।

स्कीमा सेट करके XML फ़ाइल पढ़ें
फ़ाइल को पढ़ने का एक वैकल्पिक तरीका एक स्कीमा को पूर्वनिर्धारित करना है। ऐसा करने के लिए, निम्नलिखित चरणों को पूरा करें:
- AWS गोंद डेटा प्रकार आयात करें:
- XML फ़ाइल के लिए एक स्कीमा बनाएं:
- XML फ़ाइल पढ़ते समय स्कीमा पास करें:
- पहले की तरह डेटासेट को अननेस्ट करें:
- डेटासेट को Parquet में बदलें और AWS ग्लू तालिका बनाएं:
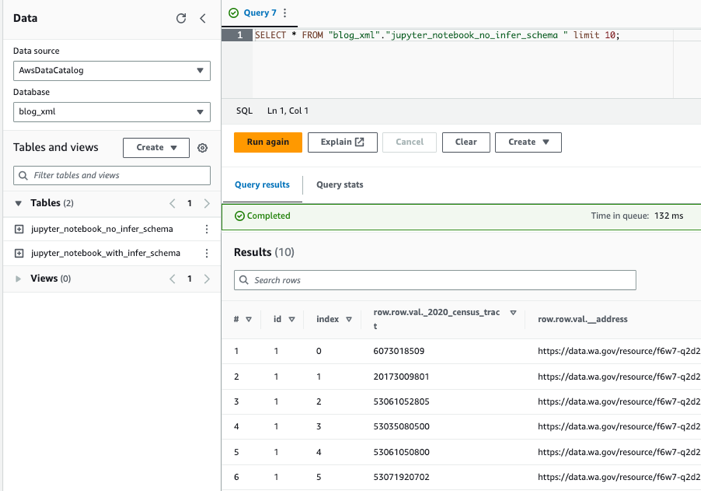
एथेना का उपयोग करके तालिकाओं को क्वेरी करें
अब जब हमने दोनों तालिकाएँ बना ली हैं, तो हम एथेना का उपयोग करके तालिकाओं को क्वेरी कर सकते हैं। उदाहरण के लिए, हम निम्नलिखित क्वेरी का उपयोग कर सकते हैं:
क्लीन अप
इस पोस्ट में, हमने एक IAM भूमिका, एक AWS ग्लू ज्यूपिटर नोटबुक और AWS ग्लू डेटा कैटलॉग में दो तालिकाएँ बनाईं। हमने कुछ फ़ाइलें S3 बकेट में भी अपलोड कीं। इन वस्तुओं को साफ करने के लिए, निम्नलिखित चरणों को पूरा करें:
- IAM कंसोल पर, आपके द्वारा बनाई गई भूमिका हटाएँ।
- AWS ग्लू स्टूडियो कंसोल पर, कस्टम क्लासिफायरियर, क्रॉलर, ETL जॉब्स और ज्यूपिटर नोटबुक हटाएं।
- AWS ग्लू डेटा कैटलॉग पर नेविगेट करें और आपके द्वारा बनाई गई तालिकाओं को हटा दें।
- Amazon S3 कंसोल पर, आपके द्वारा बनाई गई बकेट पर जाएँ और नामित फ़ोल्डर हटाएँ
temp,infer_schema, तथाno_infer_schema.
चाबी छीन लेना
AWS ग्लू में, नामक एक सुविधा है InferSchema AWS गोंद में DynamicFrames. यह स्वचालित रूप से इसमें मौजूद डेटा के आधार पर डेटा फ़्रेम की संरचना का पता लगाता है। इसके विपरीत, स्कीमा को परिभाषित करने का अर्थ स्पष्ट रूप से यह बताना है कि डेटा लोड करने से पहले डेटा फ्रेम की संरचना कैसी होनी चाहिए।
XML, एक टेक्स्ट-आधारित प्रारूप होने के कारण, अपने कॉलम के डेटा प्रकारों को प्रतिबंधित नहीं करता है। यह InferSchema फ़ंक्शन के साथ समस्याएँ पैदा कर सकता है। उदाहरण के लिए, पहले रन में, कॉलम A वाली एक फ़ाइल जिसका मान 2 है, एक पूर्णांक के रूप में कॉलम A वाली Parquet फ़ाइल में परिणत होती है। दूसरे रन में, एक नई फ़ाइल में मान C के साथ कॉलम A होता है, जो एक स्ट्रिंग के रूप में कॉलम A के साथ एक Parquet फ़ाइल की ओर ले जाता है। अब S3 पर दो फ़ाइलें हैं, प्रत्येक में अलग-अलग डेटा प्रकार का कॉलम A है, जो डाउनस्ट्रीम में समस्याएँ पैदा कर सकता है।
नेस्टेड संरचनाओं या सरणियों जैसे जटिल डेटा प्रकारों के साथ भी ऐसा ही होता है। उदाहरण के लिए, यदि किसी फ़ाइल में एक टैग प्रविष्टि है जिसे कहा जाता है transaction, यह एक संरचना के रूप में अनुमानित है। लेकिन यदि किसी अन्य फ़ाइल में समान टैग है, तो इसे एक सरणी के रूप में अनुमानित किया जाता है
इन डेटा प्रकार की समस्याओं के बावजूद, InferSchema यह तब उपयोगी होता है जब आप स्कीमा नहीं जानते हों या किसी स्कीम को मैन्युअल रूप से परिभाषित करना अव्यावहारिक हो। हालाँकि, यह बड़े या लगातार बदलते डेटासेट के लिए आदर्श नहीं है। स्कीमा को परिभाषित करना अधिक सटीक है, विशेष रूप से जटिल डेटा प्रकारों के साथ, लेकिन इसके अपने मुद्दे हैं, जैसे मैन्युअल प्रयास की आवश्यकता और डेटा परिवर्तनों के प्रति अनम्य होना।
InferSchema इसकी सीमाएँ हैं, जैसे गलत डेटा प्रकार का अनुमान और शून्य मानों को संभालने में समस्याएँ। स्कीमा को परिभाषित करने की भी सीमाएँ हैं, जैसे मैन्युअल प्रयास और संभावित त्रुटियाँ।
किसी स्कीमा का अनुमान लगाने और परिभाषित करने के बीच चयन करना परियोजना की आवश्यकताओं पर निर्भर करता है। InferSchema छोटे डेटासेट की त्वरित खोज के लिए बहुत अच्छा है, जबकि स्कीमा को परिभाषित करना सटीकता और स्थिरता की आवश्यकता वाले बड़े, जटिल डेटासेट के लिए बेहतर है। आपके प्रोजेक्ट के लिए सबसे उपयुक्त क्या है, यह चुनने के लिए प्रत्येक विधि के ट्रेड-ऑफ़ और बाधाओं पर विचार करें।
निष्कर्ष
इस पोस्ट में, हमने AWS ग्लू का उपयोग करके XML डेटा को प्रबंधित करने के लिए दो तकनीकों की खोज की, जिनमें से प्रत्येक आपके सामने आने वाली विशिष्ट आवश्यकताओं और चुनौतियों को संबोधित करने के लिए तैयार की गई है।
तकनीक 1 उन लोगों के लिए उपयोगकर्ता-अनुकूल पथ प्रदान करती है जो ग्राफ़िकल इंटरफ़ेस पसंद करते हैं। आप अपनी XML फ़ाइलों के लिए तालिका संरचना को सहजता से परिभाषित करने के लिए AWS ग्लू क्रॉलर और विज़ुअल एडिटर का उपयोग कर सकते हैं। यह दृष्टिकोण डेटा प्रबंधन प्रक्रिया को सरल बनाता है और विशेष रूप से उन लोगों के लिए आकर्षक है जो अपने डेटा को संभालने का सीधा तरीका ढूंढ रहे हैं।
हालाँकि, हम मानते हैं कि क्रॉलर की अपनी सीमाएँ हैं, विशेष रूप से 1 एमबी से बड़ी पंक्तियों वाली XML फ़ाइलों के साथ काम करते समय। यहीं पर तकनीक 2 बचाव के लिए आती है। AWS गोंद का उपयोग करके DynamicFrames अनुमानित और निश्चित दोनों स्कीमा के साथ, और AWS ग्लू नोटबुक का उपयोग करके, आप किसी भी आकार की XML फ़ाइलों को कुशलतापूर्वक संभाल सकते हैं। यह विधि एक मजबूत समाधान प्रदान करती है जो 1 एमबी बाधा से अधिक पंक्तियों वाली XML फ़ाइलों के लिए भी निर्बाध प्रसंस्करण सुनिश्चित करती है।
जैसे ही आप डेटा प्रबंधन की दुनिया में नेविगेट करते हैं, आपके टूलकिट में ये तकनीकें होने से आप अपने प्रोजेक्ट की विशिष्ट आवश्यकताओं के आधार पर सूचित निर्णय लेने में सक्षम हो जाते हैं। चाहे आप तकनीक 1 की सरलता पसंद करें या तकनीक 2 की स्केलेबिलिटी, AWS ग्लू आपको XML डेटा को प्रभावी ढंग से संभालने के लिए आवश्यक लचीलापन प्रदान करता है।
लेखक के बारे में
 नवनीत शुक्लाएनालिटिक्स पर फोकस के साथ AWS स्पेशलिस्ट सॉल्यूशन आर्किटेक्ट के रूप में कार्य करता है। उनके पास ग्राहकों को उनके डेटा से मूल्यवान अंतर्दृष्टि खोजने में सहायता करने के लिए एक मजबूत उत्साह है। अपनी विशेषज्ञता के माध्यम से, वह नवोन्मेषी समाधान तैयार करते हैं जो व्यवसायों को सूचित, डेटा-संचालित विकल्पों पर पहुंचने के लिए सशक्त बनाते हैं। विशेष रूप से, नवनीत शुक्ला “डेटा रैंगलिंग ऑन एडब्ल्यूएस” नामक पुस्तक के निपुण लेखक हैं।
नवनीत शुक्लाएनालिटिक्स पर फोकस के साथ AWS स्पेशलिस्ट सॉल्यूशन आर्किटेक्ट के रूप में कार्य करता है। उनके पास ग्राहकों को उनके डेटा से मूल्यवान अंतर्दृष्टि खोजने में सहायता करने के लिए एक मजबूत उत्साह है। अपनी विशेषज्ञता के माध्यम से, वह नवोन्मेषी समाधान तैयार करते हैं जो व्यवसायों को सूचित, डेटा-संचालित विकल्पों पर पहुंचने के लिए सशक्त बनाते हैं। विशेष रूप से, नवनीत शुक्ला “डेटा रैंगलिंग ऑन एडब्ल्यूएस” नामक पुस्तक के निपुण लेखक हैं।
 पैट्रिक मुलर AWS में वरिष्ठ डेटा लैब आर्किटेक्ट के रूप में काम करता है। उनकी मुख्य ज़िम्मेदारी ग्राहकों को उनके विचारों को उत्पादन-तैयार डेटा उत्पाद में बदलने में सहायता करना है। अपने खाली समय में, पैट्रिक को फुटबॉल खेलना, फिल्में देखना और यात्रा करना पसंद है।
पैट्रिक मुलर AWS में वरिष्ठ डेटा लैब आर्किटेक्ट के रूप में काम करता है। उनकी मुख्य ज़िम्मेदारी ग्राहकों को उनके विचारों को उत्पादन-तैयार डेटा उत्पाद में बदलने में सहायता करना है। अपने खाली समय में, पैट्रिक को फुटबॉल खेलना, फिल्में देखना और यात्रा करना पसंद है।
 अमोघ गायकवाडी अमेज़ॅन वेब सर्विसेज में एक वरिष्ठ समाधान डेवलपर हैं। वह वैश्विक ग्राहकों को AWS पर AI/ML समाधान बनाने और तैनात करने में मदद करता है। उनका काम मुख्य रूप से कंप्यूटर विज़न और प्राकृतिक भाषा प्रसंस्करण पर केंद्रित है और ग्राहकों को स्थिरता के लिए उनके एआई/एमएल वर्कलोड को अनुकूलित करने में मदद करता है। अमोघ ने मशीन लर्निंग में विशेषज्ञता के साथ कंप्यूटर साइंस में मास्टर डिग्री प्राप्त की है।
अमोघ गायकवाडी अमेज़ॅन वेब सर्विसेज में एक वरिष्ठ समाधान डेवलपर हैं। वह वैश्विक ग्राहकों को AWS पर AI/ML समाधान बनाने और तैनात करने में मदद करता है। उनका काम मुख्य रूप से कंप्यूटर विज़न और प्राकृतिक भाषा प्रसंस्करण पर केंद्रित है और ग्राहकों को स्थिरता के लिए उनके एआई/एमएल वर्कलोड को अनुकूलित करने में मदद करता है। अमोघ ने मशीन लर्निंग में विशेषज्ञता के साथ कंप्यूटर साइंस में मास्टर डिग्री प्राप्त की है।
 शीला सोनोने AWS में सीनियर रेजिडेंट आर्किटेक्ट हैं। वह AWS ग्राहकों को उनके डेटा, एनालिटिक्स और AI/ML वर्कलोड और कार्यान्वयन में तेजी लाने के बारे में सूचित विकल्प और ट्रेडऑफ़ बनाने में मदद करती है। अपने खाली समय में, वह अपने परिवार के साथ समय बिताना पसंद करती हैं - आमतौर पर टेनिस कोर्ट पर।
शीला सोनोने AWS में सीनियर रेजिडेंट आर्किटेक्ट हैं। वह AWS ग्राहकों को उनके डेटा, एनालिटिक्स और AI/ML वर्कलोड और कार्यान्वयन में तेजी लाने के बारे में सूचित विकल्प और ट्रेडऑफ़ बनाने में मदद करती है। अपने खाली समय में, वह अपने परिवार के साथ समय बिताना पसंद करती हैं - आमतौर पर टेनिस कोर्ट पर।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/process-and-analyze-highly-nested-and-large-xml-files-using-aws-glue-and-amazon-athena/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 1
- 10
- 100
- 12
- 121
- 13
- 14
- 1994
- 250
- 26
- 53
- 7
- 8
- 9
- a
- About
- अमूर्त
- तेज
- पहुँच
- एक्सेसिबिलिटी
- पूरा
- शुद्धता
- के पार
- कार्य
- जोड़ना
- जोड़ा
- अतिरिक्त
- पता
- बाद
- उम्र
- ऐ / एमएल
- सब
- अनुमति देना
- की अनुमति दे
- की अनुमति देता है
- भी
- वैकल्पिक
- वीरांगना
- अमेज़न एथेना
- अमेज़ॅन वेब सेवा
- an
- विश्लेषण
- विश्लेषिकी
- विश्लेषण करें
- का विश्लेषण
- और
- अन्य
- कोई
- अपाचे
- आकर्षक
- अनुप्रयोगों
- लागू करें
- दृष्टिकोण
- दृष्टिकोण
- स्थापत्य
- हैं
- ऐरे
- AS
- सहायता
- की सहायता
- At
- लेखक
- स्वतः
- उपलब्ध
- एडब्ल्यूएस
- एडब्ल्यूएस गोंद
- वापस
- आधारित
- बुनियादी
- BE
- क्योंकि
- से पहले
- शुरू करना
- जा रहा है
- BEST
- बेहतर
- के बीच
- रिक्त
- किताब
- के छात्रों
- निर्माण
- व्यवसायों
- लेकिन
- by
- बुलाया
- कर सकते हैं
- सूची
- कारण
- सेल
- चुनौतियों
- परिवर्तन
- परिवर्तन
- बदलना
- विकल्प
- चुनें
- City
- वर्गीकरण
- ग्राहकों
- कोड
- स्तंभ
- स्तंभ
- COM
- आता है
- सामान्य
- सामान्यतः
- पूरा
- पूरा
- जटिल
- कंप्यूटर
- कम्प्यूटर साइंस
- Computer Vision
- शर्त
- आचरण
- संयोजन
- विचार करना
- कंसोल
- निरंतर
- की कमी
- निर्माण
- शामिल
- निहित
- शामिल हैं
- इसके विपरीत
- नियंत्रण
- बदलना
- परिवर्तित
- प्रभावी लागत
- लागत प्रभावी समाधान
- काउंटी
- अदालतों
- कवर
- क्रॉलर
- बनाना
- बनाया
- बनाना
- महत्वपूर्ण
- रिवाज
- ग्राहक
- ग्राहक
- तिथि
- डेटा एकीकरण
- आँकड़ा प्रबंधन
- डेटा पर ही आधारित
- डाटाबेस
- डेटासेट
- व्यवहार
- निर्णय
- चूक
- परिभाषित
- परिभाषित करने
- गड्ढा
- दर्शाता
- निर्भर करता है
- तैनात
- बनाया गया
- विस्तृत
- विवरण
- डेवलपर
- विभिन्न
- मुश्किल
- डिजिटल
- डिजिटल युग
- सीधे
- खोज
- अलग
- do
- नहीं करता है
- किया
- dont
- DOT
- दौरान
- गतिशील
- से प्रत्येक
- आराम
- आसानी
- आसान
- संपादक
- प्रभाव
- प्रभावी रूप से
- दक्षता
- कुशल
- कुशलता
- प्रयास
- अनायास
- बिजली
- इलेक्ट्रिक वाहन
- तत्व
- रोजगार
- सशक्त
- अधिकार
- खाली
- सक्षम
- समर्थकारी
- सामना
- समाप्त
- इंजन
- बढ़ाना
- सुनिश्चित
- सुनिश्चित
- दर्ज
- उत्साह
- प्रविष्टि
- त्रुटियाँ
- विशेष रूप से
- ईथर (ईटीएच)
- और भी
- घटनाओं
- प्रत्येक
- उदाहरण
- से अधिक
- का आदान प्रदान
- विशेषज्ञता
- अन्वेषण
- का पता लगाने
- पता लगाया
- उद्धरण
- निष्कर्षण
- परिवार
- Feature
- विशेषताएं
- आंकड़े
- पट्टिका
- फ़ाइलें
- वित्त
- प्रथम
- तय
- लचीलापन
- फोकस
- ध्यान केंद्रित
- निम्नलिखित
- के लिए
- प्रारूप
- फ्रेम
- मुक्त
- आवृत्ति
- से
- समारोह
- लाभ
- सामान्य उद्देश्य
- उत्पन्न
- वैश्विक
- Go
- लक्ष्य
- सरकार
- महान
- संभालना
- हैंडलिंग
- हो जाता
- दोहन
- है
- होने
- he
- स्वास्थ्य सेवा
- दिल
- मदद
- मदद
- मदद करता है
- उसे
- उच्च स्तर
- अत्यधिक
- उसके
- कैसे
- How To
- तथापि
- एचटीएमएल
- http
- HTTPS
- आई ए एम
- आदर्श
- विचारों
- पहचान
- if
- दिखाता है
- लागू करने के
- कार्यान्वयन
- कार्यान्वयन
- आयात
- में सुधार
- उन्नत
- in
- सहित
- व्यक्ति
- व्यक्तियों
- उद्योगों
- करें-
- सूचित
- इंफ्रास्ट्रक्चर
- अभिनव
- अंदर
- अंतर्दृष्टि
- बजाय
- निर्देश
- एकीकृत
- एकीकरण
- इंटरैक्टिव
- रुचि
- इंटरफेस
- में
- शामिल
- मुद्दों
- IT
- आईटी इस
- काम
- नौकरियां
- जेपीजी
- JSON
- जुपीटर नोटबुक
- रखना
- जानना
- प्रयोगशाला
- भाषा
- बड़ा
- बड़ा
- प्रमुख
- जानें
- सीख रहा हूँ
- स्तर
- पसंद
- सीमा
- सीमा
- सीमाओं
- लाइन
- पंक्तियां
- भार
- लोड हो रहा है
- तर्क
- देख
- मशीन
- यंत्र अधिगम
- मुख्य
- मुख्यतः
- बनाना
- निर्माण
- प्रबंध
- प्रबंध
- गाइड
- मैन्युअल
- बहुत
- मानचित्रण
- मास्टर की
- मई..
- साधन
- मेन्यू
- मेटाडाटा
- तरीका
- मिनट
- आदर्श
- अधिक
- अधिक कुशल
- अधिकांश
- चाल
- चलचित्र
- विभिन्न
- नाम
- नामांकित
- नामों
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा संसाधन
- नेविगेट करें
- पथ प्रदर्शन
- आवश्यक
- आवश्यकता
- की जरूरत है
- नया
- नए नए
- अगला
- विशेष रूप से
- नोटबुक
- अभी
- संख्या
- वस्तुओं
- of
- ऑफर
- on
- ONE
- केवल
- संचालन
- इष्टतम
- ऑप्टिमाइज़ करें
- अनुकूलन
- ऑप्शंस
- or
- आदेश
- संगठनों
- मूल
- अन्य
- हमारी
- आउट
- उत्पादन
- के ऊपर
- काबू
- अपना
- पृष्ठ
- फलक
- प्राचल
- पैरामीटर
- भाग
- विशेष रूप से
- पास
- पथ
- पैट्रिक
- निष्पादन
- प्रदर्शन
- अनुमतियाँ
- चुनना
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- खेल
- नीति
- आबादी
- अधिकारी
- पद
- संभावित
- ठीक
- पसंद करते हैं
- आवश्यक शर्तें
- पूर्वावलोकन
- पिछला
- समस्याओं
- प्रक्रिया
- संसाधित
- प्रसंस्करण
- एस्ट्रो मॉल
- परियोजना
- परियोजनाओं
- गुण
- प्रदान करना
- प्रदान करता है
- प्रकाशित करना
- उद्देश्य
- अजगर
- प्रश्नों
- त्वरित
- बल्कि
- पढ़ना
- आसानी से
- पढ़ना
- कारण
- प्राप्त
- पहचान
- उल्लेख
- प्रासंगिक
- आवश्यकताएँ
- बचाव
- संसाधन
- प्रतिक्रिया
- जिम्मेदारी
- बाकी
- रोकना
- बंधन
- परिणाम
- मजबूत
- भूमिका
- जड़
- आरओडब्ल्यू
- रन
- वही
- सहेजें
- स्काला
- अनुमापकता
- स्केलेबल
- विज्ञान
- लिपि
- निर्बाध
- मूल
- दूसरा
- अनुभाग
- देखना
- वरिष्ठ
- सेवाएँ
- सत्र
- सेट
- की स्थापना
- कई
- वह
- खोल
- चाहिए
- दिखाना
- दिखाया
- दिखाता है
- समान
- सरल
- सादगी
- सरल बनाने
- एक
- आकार
- छोटा
- So
- फुटबॉल
- समाधान
- समाधान ढूंढे
- कुछ
- स्रोत
- सूत्रों का कहना है
- स्पार्क
- विशेषज्ञ
- विशेषज्ञता
- विशिष्ट
- विशेष रूप से
- गति
- खर्च
- एसक्यूएल
- मानक
- शुरू होता है
- राज्य
- कथन
- बताते हुए
- कदम
- कदम
- भंडारण
- संग्रहित
- सरल
- सुवीही
- तार
- मजबूत
- संरचना
- संरचनाओं
- स्टूडियो
- सफलता
- ऐसा
- उपयुक्त
- समर्थन
- निश्चित
- स्थिरता
- सिस्टम
- तालिका
- टैग
- अनुरूप
- लेना
- लेता है
- कार्य
- तकनीक
- टेनिस
- से
- कि
- RSI
- जानकारी
- दुनिया
- लेकिन हाल ही
- उन
- फिर
- वहाँ।
- इन
- वे
- इसका
- उन
- यहाँ
- पहर
- शीर्षक
- शीर्षक से
- सेवा मेरे
- आज का दि
- टूलकिट
- ऊपर का
- विषय
- बदालना
- परिवर्तन
- यात्रा का
- मोड़
- ट्यूटोरियल
- दो
- टाइप
- प्रकार
- परम
- के अंतर्गत
- अपडेट
- अद्यतन
- अपलोड की गई
- us
- प्रयोज्य
- उपयोग
- प्रयुक्त
- उपयोगकर्ता
- यूजर इंटरफेस
- उपयोगकर्ता के अनुकूल
- का उपयोग करता है
- का उपयोग
- आमतौर पर
- उपयोग
- मूल्यवान
- मूल्य
- मान
- वाहन
- संस्करण
- के माध्यम से
- देखें
- विचारों
- दृष्टि
- देख
- मार्ग..
- we
- वेब
- वेब सेवाओं
- क्या
- कब
- जहाँ तक
- या
- कौन कौन से
- कौन
- क्यों
- मर्जी
- साथ में
- अंदर
- बिना
- काम
- वर्कफ़्लो
- workflows
- कार्य
- विश्व
- लिखना
- एक्सएमएल
- इसलिए आप
- आपका
- जेफिरनेट