लेखक द्वारा छवि
यदि आप अप्रशिक्षित शिक्षण प्रतिमान से परिचित हैं, तो आप आयामीता में कमी और आयामीता में कमी के लिए उपयोग किए जाने वाले एल्गोरिदम से परिचित होंगे जैसे कि मुख्य घटक विश्लेषण (पीसीए)। मशीन लर्निंग के लिए डेटासेट में आम तौर पर बड़ी संख्या में सुविधाएं होती हैं, लेकिन ऐसे उच्च-आयामी फीचर स्थान हमेशा सहायक नहीं होते हैं।
सामान्य तौर पर, सभी सुविधाएँ हैं नहीं समान रूप से महत्वपूर्ण है और कुछ ऐसी विशेषताएं हैं जो डेटासेट में भिन्नता के एक बड़े प्रतिशत के लिए जिम्मेदार हैं। आयामीता में कमी एल्गोरिदम का लक्ष्य फीचर स्पेस के आयाम को आयामों की मूल संख्या के एक अंश तक कम करना है। ऐसा करने पर, उच्च विचरण वाली सुविधाएँ अभी भी बरकरार हैं - लेकिन रूपांतरित फीचर स्थान में हैं। और प्रमुख घटक विश्लेषण (पीसीए) सबसे लोकप्रिय आयामी कमी एल्गोरिदम में से एक है।
इस ट्यूटोरियल में, हम सीखेंगे कि प्रिंसिपल कंपोनेंट एनालिसिस (पीसीए) कैसे काम करता है और स्किकिट-लर्न लाइब्रेरी का उपयोग करके इसे कैसे लागू किया जाए।
इससे पहले कि हम आगे बढ़ें और स्किकिट-लर्न में प्रमुख घटक विश्लेषण (पीसीए) लागू करें, यह समझना उपयोगी है कि पीसीए कैसे काम करता है।
जैसा कि उल्लेख किया गया है, प्रमुख घटक विश्लेषण एक आयामी कमी एल्गोरिथ्म है। मतलब यह फीचर स्पेस की आयामीता को कम कर देता है। लेकिन यह यह कमी कैसे हासिल की जाती है?
एल्गोरिदम के पीछे प्रेरणा यह है कि कुछ विशेषताएं हैं जो मूल डेटासेट में भिन्नता के एक बड़े प्रतिशत को पकड़ती हैं। इसलिए इसे ढूंढना महत्वपूर्ण है अधिकतम विचरण की दिशाएँ डेटासेट में. ये दिशाएं कहलाती हैं मूल घटक. और पीसीए अनिवार्य रूप से प्रमुख घटकों पर डेटासेट का एक प्रक्षेपण है।
तो हम प्रमुख घटकों को कैसे खोजें?
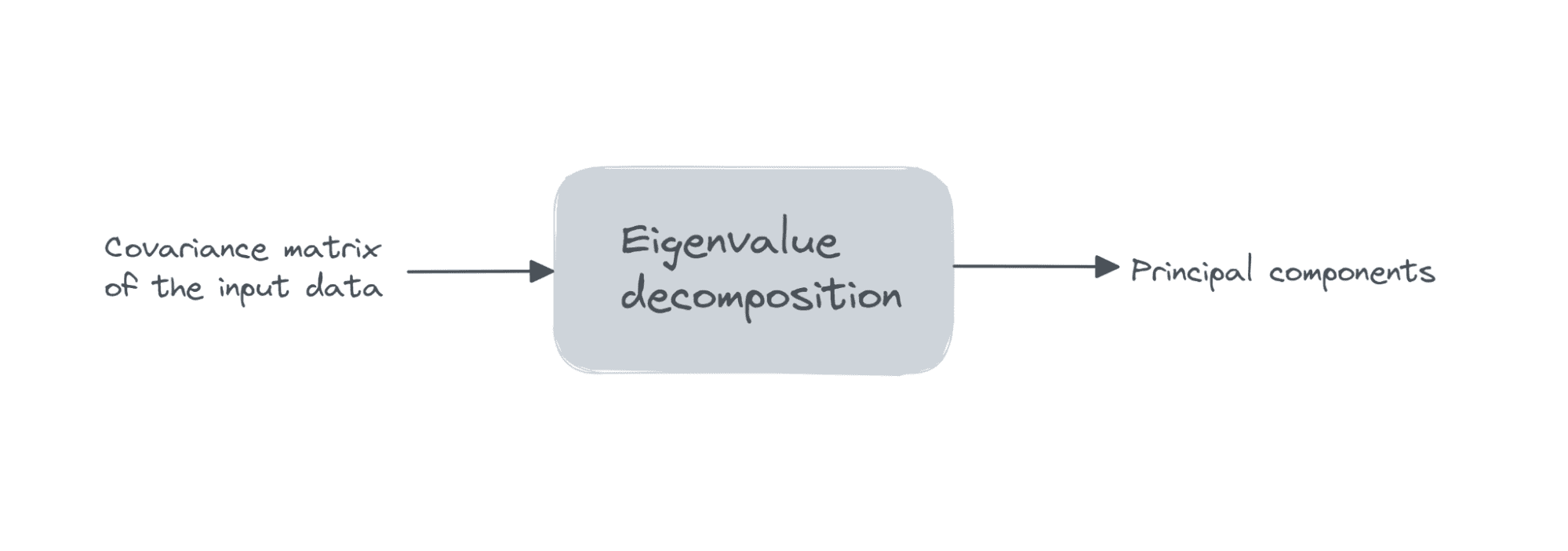
मान लीजिए कि डेटा मैट्रिक्स X आयाम का है num_observations x num_features, हम प्रदर्शन eigenvalue अपघटन पर सहप्रसरण आव्यूह एक्स का.
यदि विशेषताएं सभी शून्य माध्य हैं, तो सहप्रसरण मैट्रिक्स XT X द्वारा दिया गया है। यहां, XT मैट्रिक्स उस कॉलम में और सहप्रसरण मैट्रिक्स की गणना करें। यह देखना सरल है कि सहप्रसरण मैट्रिक्स क्रम का एक वर्ग मैट्रिक्स है num_features.
लेखक द्वारा छवि
पहले k प्रमुख घटक हैं egenvectors के लिए इसी k सबसे बड़ा eigenvalues.
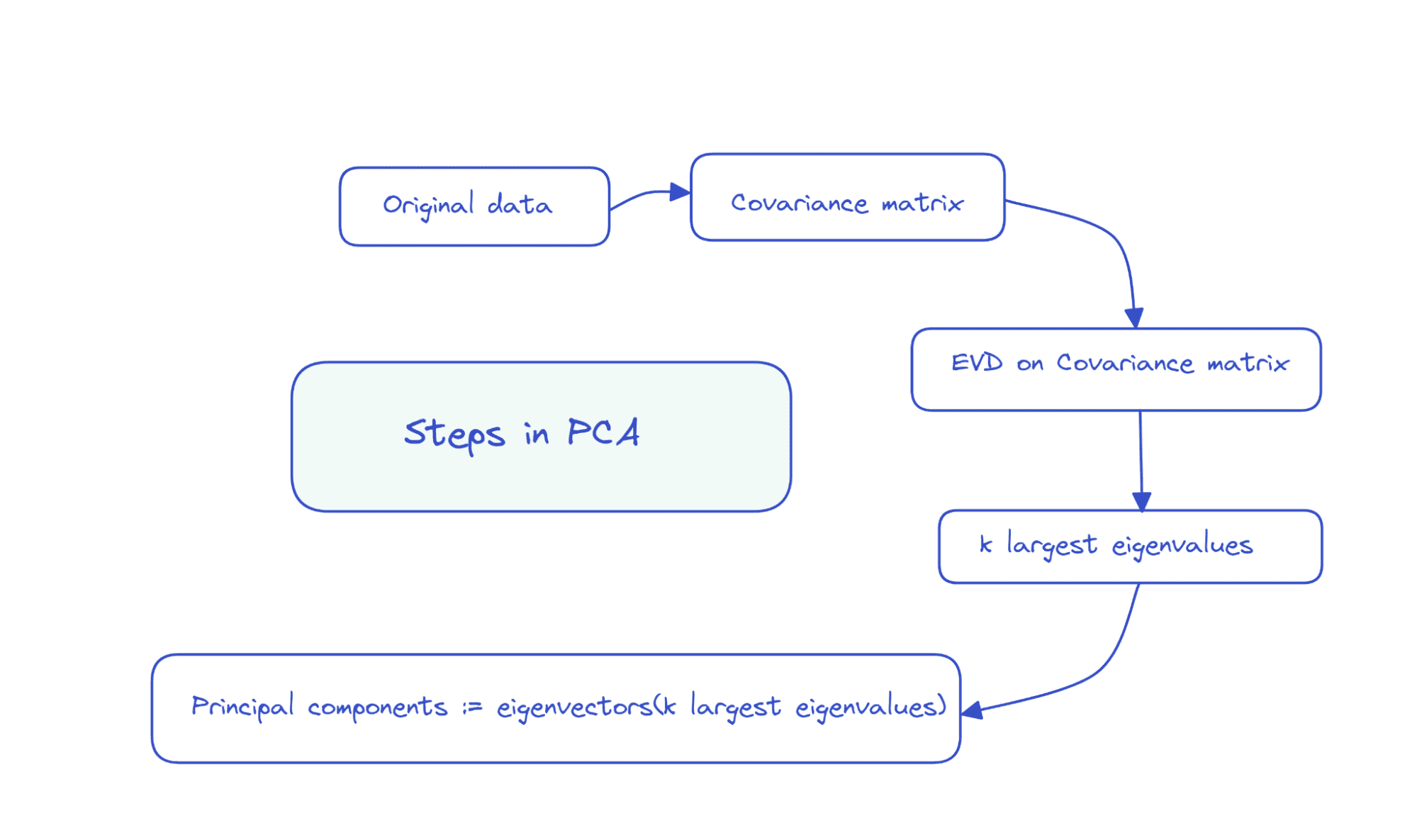
इसलिए पीसीए के चरणों को संक्षेप में इस प्रकार प्रस्तुत किया जा सकता है:
लेखक द्वारा छवि
क्योंकि सहप्रसरण मैट्रिक्स एक सममित और सकारात्मक अर्ध-निश्चित है, eigendecomposition निम्नलिखित रूप लेता है:
एक्सटी एक्स = डी Λ डीटी
जहाँ, D eigenvectors का मैट्रिक्स है और Λ eigenvalues का एक विकर्ण मैट्रिक्स है।
एक अन्य मैट्रिक्स फ़ैक्टराइज़ेशन तकनीक जिसका उपयोग प्रमुख घटकों की गणना करने के लिए किया जा सकता है, वह है एकवचन मूल्य अपघटन या एसवीडी।
सभी मैट्रिक्स के लिए एकवचन मूल्य अपघटन (एसवीडी) परिभाषित किया गया है। मैट्रिक्स X को देखते हुए, X का SVD देता है: वीटी, वी का स्थानान्तरण है।
तो X के सहप्रसरण मैट्रिक्स का SVD इस प्रकार दिया गया है:

दो मैट्रिक्स अपघटनों की तुल्यता की तुलना करना:

हमारे पास निम्नलिखित हैं:
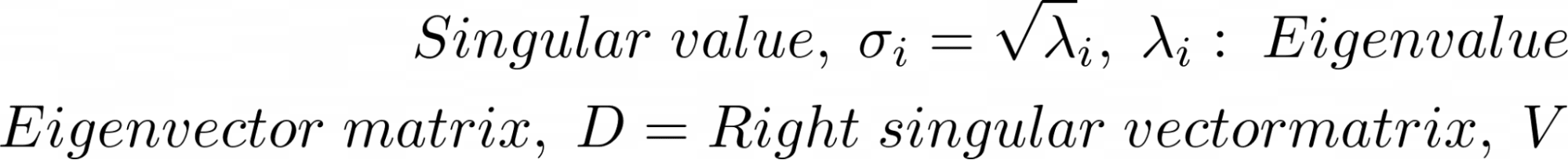
मैट्रिक्स के एसवीडी की गणना के लिए कम्प्यूटेशनल रूप से कुशल एल्गोरिदम हैं। पीसीए का स्किकिट-लर्न कार्यान्वयन प्रमुख घटकों की गणना करने के लिए हुड के तहत एसवीडी का भी उपयोग करता है।
अब जब हमने प्रमुख घटक विश्लेषण की मूल बातें सीख ली हैं, तो आइए इसके स्किकिट-लर्न कार्यान्वयन के साथ आगे बढ़ें।
चरण 1 - डेटासेट लोड करें
यह समझने के लिए कि प्रमुख घटक विश्लेषण को कैसे लागू किया जाए, आइए एक सरल डेटासेट का उपयोग करें। इस ट्यूटोरियल में, हम स्किकिट-लर्न के हिस्से के रूप में उपलब्ध वाइन डेटासेट का उपयोग करेंगे डेटासेट मॉड्यूल।
आइए डेटासेट को लोड और प्रीप्रोसेस करके शुरू करें:
from sklearn import datasets
wine_data = datasets.load_wine(as_frame=True)
df = wine_data.data
इसमें कुल 13 विशेषताएं और 178 रिकॉर्ड हैं।
print(df.shape)
Output >> (178, 13)
print(df.info())
Output >>
RangeIndex: 178 entries, 0 to 177
Data columns (total 13 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 alcohol 178 non-null float64 1 malic_acid 178 non-null float64 2 ash 178 non-null float64 3 alcalinity_of_ash 178 non-null float64 4 magnesium 178 non-null float64 5 total_phenols 178 non-null float64 6 flavanoids 178 non-null float64 7 nonflavanoid_phenols 178 non-null float64 8 proanthocyanins 178 non-null float64 9 color_intensity 178 non-null float64 10 hue 178 non-null float64 11 od280/od315_of_diluted_wines 178 non-null float64 12 proline 178 non-null float64
dtypes: float64(13)
memory usage: 18.2 KB
Noneचरण 2 - डेटासेट को प्रीप्रोसेस करें
अगले चरण के रूप में, आइए डेटासेट को प्रीप्रोसेस करें। सभी सुविधाएँ अलग-अलग पैमाने पर हैं। उन सभी को एक समान पैमाने पर लाने के लिए, हम इसका उपयोग करेंगे StandardScaler जो सुविधाओं को शून्य माध्य और इकाई विचरण में बदल देता है:
from sklearn.preprocessing import StandardScaler
std_scaler = StandardScaler()
scaled_df = std_scaler.fit_transform(df)चरण 3 - प्रीप्रोसेस्ड डेटासेट पर पीसीए निष्पादित करें
प्रमुख घटकों को खोजने के लिए, हम स्किकिट-लर्न से पीसीए क्लास का उपयोग कर सकते हैं अपघटन मॉड्यूल।
आइए प्रमुख घटकों की संख्या को शामिल करके एक पीसीए ऑब्जेक्ट को इंस्टेंट करें n_components कंस्ट्रक्टर को.
प्रमुख घटकों की संख्या उन आयामों की संख्या है जिनके लिए आप फीचर स्थान को कम करना चाहते हैं। यहां, हमने घटकों की संख्या 3 निर्धारित की है।
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
pca.fit_transform(scaled_df)
को कॉल करने के बजाय fit_transform() विधि, आप कॉल भी कर सकते हैं fit() द्वारा पीछा किया transform() विधि.
ध्यान दें कि जब हम पीसीए के स्किकिट-लर्न के कार्यान्वयन का उपयोग करते हैं, तो प्रमुख घटक विश्लेषण के चरण जैसे कि सहप्रसरण मैट्रिक्स की गणना करना, मुख्य घटकों को प्राप्त करने के लिए सहप्रसरण मैट्रिक्स पर ईगेंडेकंपोजिशन या एकवचन मूल्य अपघटन करना, सभी को हटा दिया गया है।
चरण 4 - पीसीए ऑब्जेक्ट की कुछ उपयोगी विशेषताओं की जांच करना
पीसीए उदाहरण pca हमने जो बनाया है उसमें कई उपयोगी विशेषताएं हैं जो हमें यह समझने में मदद करती हैं कि हुड के नीचे क्या चल रहा है।
विशेषता है components_ अधिकतम विचरण (मुख्य घटक) की दिशाओं को संग्रहीत करता है।
print(pca.components_)
Output >>
[[ 0.1443294 -0.24518758 -0.00205106 -0.23932041 0.14199204 0.39466085 0.4229343 -0.2985331 0.31342949 -0.0886167 0.29671456 0.37616741 0.28675223] [-0.48365155 -0.22493093 -0.31606881 0.0105905 -0.299634 -0.06503951 0.00335981 -0.02877949 -0.03930172 -0.52999567 0.27923515 0.16449619 -0.36490283] [-0.20738262 0.08901289 0.6262239 0.61208035 0.13075693 0.14617896 0.1506819 0.17036816 0.14945431 -0.13730621 0.08522192 0.16600459 -0.12674592]]
हमने बताया कि प्रमुख घटक डेटासेट में अधिकतम भिन्नता की दिशाएँ हैं। लेकिन हम कैसे मापते हैं कुल विचरण का कितना हमारे द्वारा चुने गए प्रमुख घटकों की संख्या में शामिल है?
RSI explained_variance_ratio_ विशेषता प्रत्येक प्रमुख घटक द्वारा कैप्चर किए गए कुल विचरण के अनुपात को कैप्चर करती है। सोवे चुने गए घटकों की संख्या में कुल भिन्नता प्राप्त करने के लिए अनुपातों का योग कर सकते हैं।
print(sum(pca.explained_variance_ratio_))
Output >> 0.6652996889318527
यहां, हम देखते हैं कि तीन प्रमुख घटक डेटासेट में कुल भिन्नता के 66.5% से अधिक पर कब्जा कर लेते हैं।
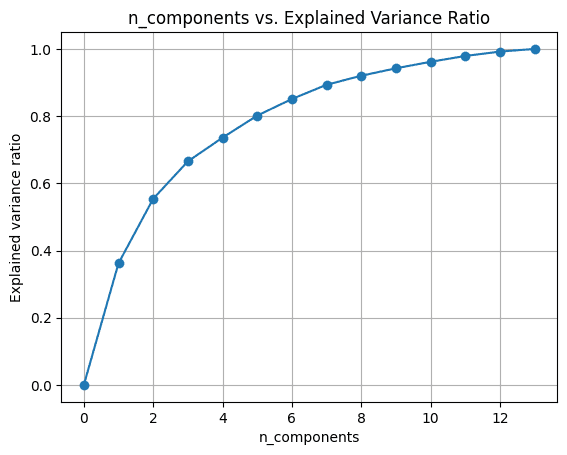
चरण 5 - स्पष्ट विचरण अनुपात में परिवर्तन का विश्लेषण
हम घटकों की संख्या अलग-अलग करके प्रमुख घटक विश्लेषण चलाने का प्रयास कर सकते हैं n_components.
import numpy as np
nums = np.arange(14)
var_ratio = []
for num in nums: pca = PCA(n_components=num) pca.fit(scaled_df) var_ratio.append(np.sum(pca.explained_variance_ratio_))
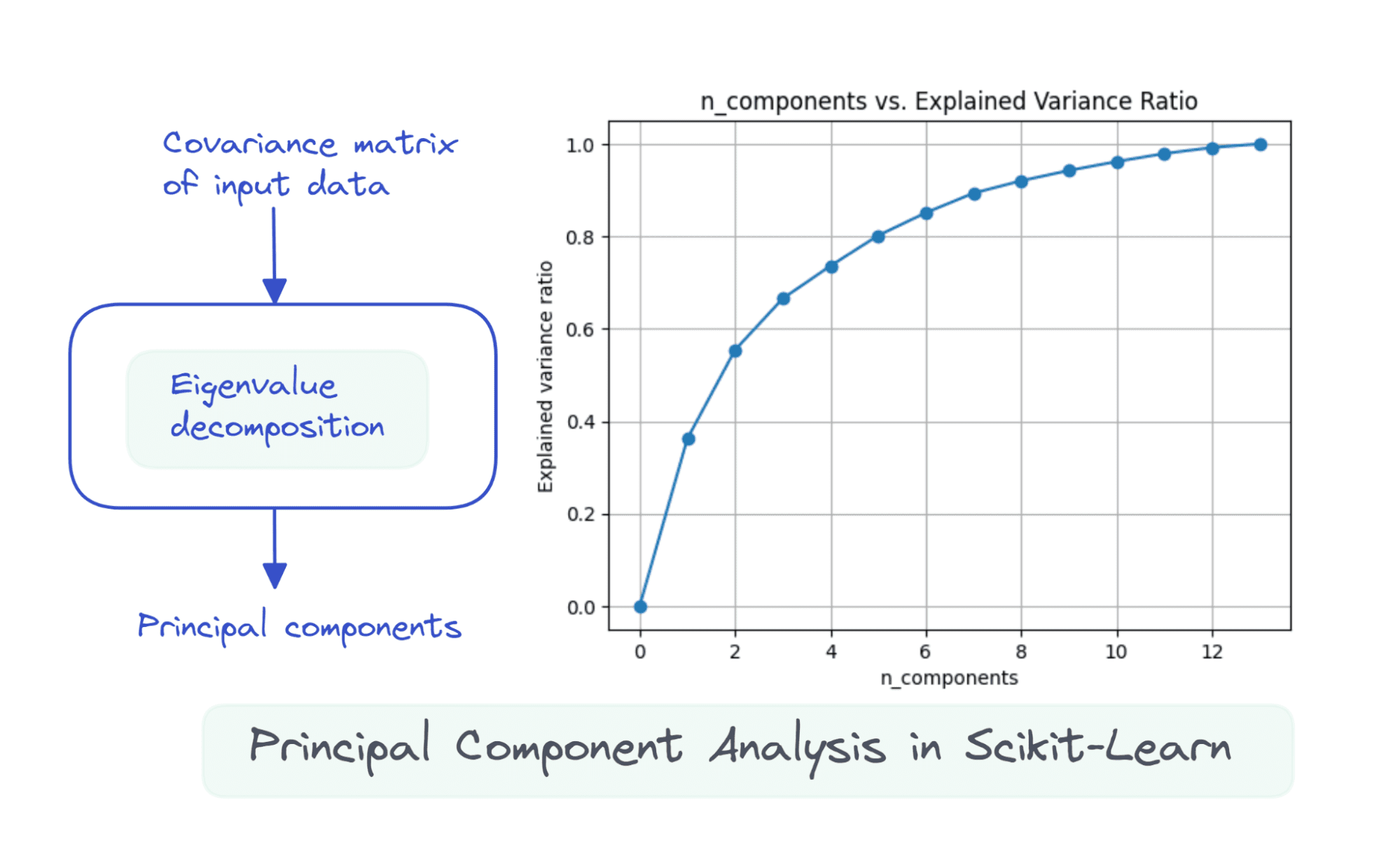
कल्पना करने के लिए explained_variance_ratio_ घटकों की संख्या के लिए, आइए दिखाए गए अनुसार दो मात्राएँ आलेखित करें:
import matplotlib.pyplot as plt plt.figure(figsize=(4,2),dpi=150)
plt.grid()
plt.plot(nums,var_ratio,marker='o')
plt.xlabel('n_components')
plt.ylabel('Explained variance ratio')
plt.title('n_components vs. Explained Variance Ratio')
जब हम सभी 13 घटकों का उपयोग करते हैं, तो explained_variance_ratio_ 1.0 यह दर्शाता है कि हमने डेटासेट में 100% भिन्नता को कैप्चर कर लिया है।
इस उदाहरण में, हम देखते हैं कि 6 प्रमुख घटकों के साथ, हम इनपुट डेटासेट में 80% से अधिक भिन्नता को पकड़ने में सक्षम होंगे।
मुझे आशा है कि आपने स्किकिट-लर्न लाइब्रेरी में अंतर्निहित कार्यक्षमता का उपयोग करके प्रमुख घटक विश्लेषण करना सीख लिया है। इसके बाद, आप अपनी पसंद के डेटासेट पर पीसीए लागू करने का प्रयास कर सकते हैं। यदि आप काम करने के लिए अच्छे डेटासेट की तलाश में हैं, तो इस सूची को देखें आपके डेटा विज्ञान परियोजनाओं के लिए डेटासेट खोजने के लिए वेबसाइटें.
[1] कम्प्यूटेशनल रैखिक बीजगणित, fast.ai
बाला प्रिया सी भारत के एक डेवलपर और तकनीकी लेखक हैं। वह गणित, प्रोग्रामिंग, डेटा विज्ञान और सामग्री निर्माण के क्षेत्र में काम करना पसंद करती है। उनकी रुचि और विशेषज्ञता के क्षेत्रों में DevOps, डेटा विज्ञान और प्राकृतिक भाषा प्रसंस्करण शामिल हैं। उसे पढ़ना, लिखना, कोडिंग और कॉफ़ी पसंद है! वर्तमान में, वह सीखने पर काम कर रही है और ट्यूटोरियल, कैसे-कैसे मार्गदर्शिकाएँ, राय के टुकड़े और बहुत कुछ लिखकर डेवलपर समुदाय के साथ अपना ज्ञान साझा कर रही है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोआईस्ट्रीम। Web3 डेटा इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- मिंटिंग द फ्यूचर डब्ल्यू एड्रिएन एशले। यहां पहुंचें।
- PREIPO® के साथ PRE-IPO कंपनियों में शेयर खरीदें और बेचें। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/2023/05/principal-component-analysis-pca-scikitlearn.html?utm_source=rss&utm_medium=rss&utm_campaign=principal-component-analysis-pca-with-scikit-learn
- :हैस
- :है
- :नहीं
- $यूपी
- 1
- 10
- 11
- 12
- 13
- 14
- 66
- 7
- 8
- 9
- a
- योग्य
- लेखा
- पाना
- के पार
- आगे
- उद्देश्य
- शराब
- कलन विधि
- एल्गोरिदम
- सब
- भी
- हमेशा
- विश्लेषण
- का विश्लेषण
- और
- हैं
- क्षेत्रों के बारे में जानकारी का उपयोग करके ट्रेडिंग कर सकते हैं।
- AS
- At
- विशेषताओं
- संलेखन
- उपलब्ध
- दूर
- मूल बातें
- BE
- किया गया
- पीछे
- लाना
- में निर्मित
- लेकिन
- by
- परिकलन
- कॉल
- बुलाया
- बुला
- कर सकते हैं
- कब्जा
- कब्जा
- कुछ
- परिवर्तन
- चेक
- चुनाव
- चुना
- करने के लिए चुना
- कक्षा
- कोडन
- स्तंभ
- स्तंभ
- कैसे
- सामान्य
- समुदाय
- अंग
- घटकों
- गणना करना
- कंप्यूटिंग
- सामग्री
- सामग्री निर्माण
- इसी
- बनाया
- निर्माण
- वर्तमान में
- तिथि
- डेटा विज्ञान
- डेटासेट
- परिभाषित
- डेवलपर
- DevOps
- विभिन्न
- आयाम
- आयाम
- दिशाओं
- do
- कर देता है
- कर
- से प्रत्येक
- कुशल
- प्रविष्टि
- समान रूप से
- अनिवार्य
- जांच
- उदाहरण
- विशेषज्ञता
- समझाया
- परिचित
- फास्ट
- Feature
- विशेषताएं
- खोज
- प्रथम
- पीछा किया
- निम्नलिखित
- इस प्रकार है
- के लिए
- प्रपत्र
- अंश
- से
- कार्यक्षमता
- सामान्य जानकारी
- मिल
- दी
- देता है
- Go
- जा
- अच्छा
- मार्गदर्शिकाएँ
- है
- मदद
- सहायक
- उसे
- यहाँ उत्पन्न करें
- हाई
- हुड
- आशा
- कैसे
- How To
- एचटीएमएल
- HTTPS
- i
- if
- लागू करने के
- कार्यान्वयन
- आयात
- महत्वपूर्ण
- in
- शामिल
- इंडिया
- यह दर्शाता है
- शुरू में
- निवेश
- उदाहरण
- ब्याज
- प्रतिच्छेदन
- IT
- केवल
- केडनगेट्स
- ज्ञान
- भाषा
- बड़ा
- सबसे बड़ा
- जानें
- सीखा
- सीख रहा हूँ
- बाएं
- पुस्तकालय
- पसंद
- लिंक्डइन
- सूची
- ll
- भार
- लोड हो रहा है
- देख
- मशीन
- यंत्र अधिगम
- गणित
- matplotlib
- मैट्रिक्स
- अधिकतम
- मतलब
- अर्थ
- माप
- याद
- उल्लेख किया
- तरीका
- मॉड्यूल
- अधिक
- अधिकांश
- सबसे लोकप्रिय
- अभिप्रेरण
- बहुत
- प्राकृतिक
- प्राकृतिक भाषा
- प्राकृतिक भाषा संसाधन
- अगला
- संख्या
- numpy
- वस्तु
- of
- on
- ONE
- राय
- or
- आदेश
- मूल
- आउट
- उत्पादन
- के ऊपर
- मिसाल
- भाग
- पासिंग
- प्रतिशतता
- निष्पादन
- प्रदर्शन
- टुकड़े
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- लोकप्रिय
- सकारात्मक
- प्रिंसिपल
- प्रसंस्करण
- प्रोग्रामिंग
- प्रक्षेपण
- अनुपात
- पढ़ना
- अभिलेख
- को कम करने
- कम कर देता है
- कमी
- क्रमश
- सही
- दौड़ना
- s
- वही
- स्केल
- तराजू
- विज्ञान
- scikit सीखने
- देखना
- सेट
- कई
- आकार
- बांटने
- वह
- दिखाया
- सरल
- विलक्षण
- So
- कुछ
- अंतरिक्ष
- रिक्त स्थान
- चौकोर
- प्रारंभ
- कदम
- कदम
- फिर भी
- भंडार
- ऐसा
- लेता है
- तकनीकी
- से
- कि
- RSI
- मूल बातें
- उन
- फिर
- वहाँ।
- इन
- इसका
- तीन
- सेवा मेरे
- कुल
- तब्दील
- कोशिश
- ट्यूटोरियल
- ट्यूटोरियल
- दो
- आम तौर पर
- के अंतर्गत
- समझना
- इकाई
- अप्रकाशित शिक्षा
- us
- प्रयोग
- उपयोग
- प्रयुक्त
- का उपयोग
- मूल्य
- मान
- vs
- we
- क्या
- एचएमबी क्या है?
- कब
- विकिपीडिया
- वाइन
- साथ में
- काम
- काम कर रहे
- कार्य
- लेखक
- लिख रहे हैं
- X
- इसलिए आप
- आपका
- जेफिरनेट
- शून्य



