
जैसे-जैसे एआई क्लाउड से एज की ओर स्थानांतरित होता है, हम देखते हैं कि तकनीक का उपयोग विभिन्न प्रकार के उपयोग के मामलों में किया जा रहा है - विसंगति का पता लगाने से लेकर स्मार्ट शॉपिंग, निगरानी, रोबोटिक्स और फैक्ट्री ऑटोमेशन सहित अनुप्रयोगों तक। इसलिए, कोई एक आकार-फिट-सभी समाधान नहीं है। लेकिन कैमरा-सक्षम उपकरणों के तेजी से विकास के साथ, सुरक्षा बढ़ाने, परिचालन क्षमता में सुधार और बेहतर ग्राहक अनुभव प्रदान करने के लिए वीडियो निगरानी को स्वचालित करने के लिए वास्तविक समय वीडियो डेटा का विश्लेषण करने के लिए एआई को सबसे व्यापक रूप से अपनाया गया है, जिससे अंततः अपने उद्योगों में प्रतिस्पर्धात्मक बढ़त हासिल हो रही है। . वीडियो विश्लेषण को बेहतर समर्थन देने के लिए, आपको एज एआई परिनियोजन में सिस्टम प्रदर्शन को अनुकूलित करने की रणनीतियों को समझना चाहिए।
- आवश्यक प्रदर्शन स्तरों को पूरा करने या उससे अधिक करने के लिए सही आकार के कंप्यूट इंजन का चयन करना। एआई एप्लिकेशन के लिए, इन कंप्यूट इंजनों को संपूर्ण विज़न पाइपलाइन (यानी, वीडियो प्री- और पोस्ट-प्रोसेसिंग, न्यूरल नेटवर्क इंट्रेंसिंग) के कार्य करने होंगे।
एक समर्पित एआई त्वरक, चाहे वह अलग हो या एसओसी में एकीकृत हो (सीपीयू या जीपीयू पर एआई अनुमान चलाने के विपरीत) की आवश्यकता हो सकती है।
- थ्रूपुट और विलंबता के बीच अंतर को समझना; जिससे थ्रूपुट वह दर है जिससे डेटा को एक सिस्टम में संसाधित किया जा सकता है और विलंबता सिस्टम के माध्यम से डेटा प्रोसेसिंग में देरी को मापती है और अक्सर वास्तविक समय प्रतिक्रिया से जुड़ी होती है। उदाहरण के लिए, एक सिस्टम 100 फ्रेम प्रति सेकंड (थ्रूपुट) पर छवि डेटा उत्पन्न कर सकता है लेकिन एक छवि को सिस्टम से गुजरने में 100 एमएस (विलंबता) लगता है।
- भविष्य में बढ़ती जरूरतों, बदलती आवश्यकताओं और विकसित प्रौद्योगिकियों (उदाहरण के लिए, बढ़ी हुई कार्यक्षमता और सटीकता के लिए अधिक उन्नत एआई मॉडल) को समायोजित करने के लिए एआई प्रदर्शन को आसानी से मापने की क्षमता पर विचार करना। आप मॉड्यूल प्रारूप में एआई एक्सेलेरेटर का उपयोग करके या अतिरिक्त एआई एक्सेलेरेटर चिप्स के साथ प्रदर्शन स्केलिंग पूरा कर सकते हैं।
वास्तविक प्रदर्शन आवश्यकताएँ अनुप्रयोग पर निर्भर हैं। आमतौर पर, कोई उम्मीद कर सकता है कि वीडियो एनालिटिक्स के लिए, सिस्टम को कैमरों से आने वाली डेटा स्ट्रीम को 30-60 फ्रेम प्रति सेकंड और 1080p या 4k के रिज़ॉल्यूशन के साथ संसाधित करना होगा। एक एआई-सक्षम कैमरा एकल स्ट्रीम को संसाधित करेगा; एक किनारे वाला उपकरण समानांतर में कई धाराओं को संसाधित करेगा। किसी भी स्थिति में, एज एआई सिस्टम को कैमरे के सेंसर डेटा को एक प्रारूप में बदलने के लिए प्री-प्रोसेसिंग फ़ंक्शंस का समर्थन करना चाहिए जो एआई अनुमान अनुभाग (चित्रा 1) की इनपुट आवश्यकताओं से मेल खाता है।
एआई एक्सेलेरेटर पर चलने वाले मॉडल में इनपुट फीड करने से पहले, प्री-प्रोसेसिंग फ़ंक्शन कच्चे डेटा को लेते हैं और आकार बदलने, सामान्यीकरण और रंग स्थान रूपांतरण जैसे कार्य करते हैं। प्री-प्रोसेसिंग प्री-प्रोसेसिंग समय को कम करने के लिए ओपनसीवी जैसी कुशल छवि प्रसंस्करण लाइब्रेरी का उपयोग कर सकती है। पोस्टप्रोसेसिंग में अनुमान के आउटपुट का विश्लेषण करना शामिल है। यह कार्रवाई योग्य अंतर्दृष्टि उत्पन्न करने के लिए गैर-अधिकतम दमन (एनएमएस अधिकांश ऑब्जेक्ट डिटेक्शन मॉडल के आउटपुट की व्याख्या करता है) और छवि प्रदर्शन जैसे बाउंडिंग बॉक्स, क्लास लेबल या कॉन्फिडेंस स्कोर जैसे कार्यों का उपयोग करता है।

चित्र 1. एआई मॉडल अनुमान के लिए, प्री- और पोस्ट-प्रोसेसिंग कार्य आमतौर पर एप्लिकेशन प्रोसेसर पर किए जाते हैं।
एआई मॉडल अनुमान में एप्लिकेशन की क्षमताओं के आधार पर, प्रति फ्रेम कई तंत्रिका नेटवर्क मॉडल को संसाधित करने की अतिरिक्त चुनौती हो सकती है। कंप्यूटर विज़न अनुप्रयोगों में आमतौर पर कई AI कार्य शामिल होते हैं जिनके लिए कई मॉडलों की पाइपलाइन की आवश्यकता होती है। इसके अलावा, एक मॉडल का आउटपुट अक्सर अगले मॉडल का इनपुट होता है। दूसरे शब्दों में, किसी एप्लिकेशन में मॉडल अक्सर एक-दूसरे पर निर्भर होते हैं और उन्हें क्रमिक रूप से निष्पादित किया जाना चाहिए। निष्पादित किए जाने वाले मॉडलों का सटीक सेट स्थिर नहीं हो सकता है और फ़्रेम-दर-फ़्रेम आधार पर भी गतिशील रूप से भिन्न हो सकता है।
कई मॉडलों को गतिशील रूप से चलाने की चुनौती के लिए मॉडलों को संग्रहीत करने के लिए समर्पित और पर्याप्त बड़ी मेमोरी के साथ एक बाहरी एआई त्वरक की आवश्यकता होती है। अक्सर SoC के अंदर एकीकृत AI त्वरक SoC में साझा मेमोरी सबसिस्टम और अन्य संसाधनों द्वारा लगाई गई बाधाओं के कारण मल्टी-मॉडल वर्कलोड को प्रबंधित करने में असमर्थ होता है।
उदाहरण के लिए, गति पूर्वानुमान-आधारित ऑब्जेक्ट ट्रैकिंग एक वेक्टर को निर्धारित करने के लिए निरंतर पहचान पर निर्भर करती है जिसका उपयोग भविष्य की स्थिति में ट्रैक किए गए ऑब्जेक्ट की पहचान करने के लिए किया जाता है। इस दृष्टिकोण की प्रभावशीलता सीमित है क्योंकि इसमें वास्तविक पुनर्पहचान क्षमता का अभाव है। गति की भविष्यवाणी के साथ, किसी वस्तु का ट्रैक मिस्ड डिटेक्शन, रोड़ा, या वस्तु के दृश्य क्षेत्र को छोड़ने के कारण खो सकता है, यहां तक कि क्षण भर के लिए भी। एक बार खो जाने पर, वस्तु के ट्रैक को दोबारा जोड़ने का कोई तरीका नहीं है। पुनर्पहचान जोड़ने से यह सीमा हल हो जाती है लेकिन दृश्य उपस्थिति एम्बेडिंग (यानी, एक छवि फ़िंगरप्रिंट) की आवश्यकता होती है। उपस्थिति एम्बेडिंग के लिए पहले नेटवर्क द्वारा पहचाने गए ऑब्जेक्ट के बाउंडिंग बॉक्स के अंदर मौजूद छवि को संसाधित करके फीचर वेक्टर उत्पन्न करने के लिए दूसरे नेटवर्क की आवश्यकता होती है। इस एम्बेडिंग का उपयोग समय या स्थान की परवाह किए बिना, वस्तु को फिर से पहचानने के लिए किया जा सकता है। चूँकि दृश्य क्षेत्र में पाई गई प्रत्येक वस्तु के लिए एम्बेडिंग उत्पन्न की जानी चाहिए, जैसे-जैसे दृश्य व्यस्त होता जाता है, प्रसंस्करण आवश्यकताएँ बढ़ती जाती हैं। पुन: पहचान के साथ ऑब्जेक्ट ट्रैकिंग के लिए उच्च-सटीकता / उच्च रिज़ॉल्यूशन / उच्च-फ़्रेम दर का पता लगाने और एम्बेडिंग स्केलेबिलिटी के लिए पर्याप्त ओवरहेड आरक्षित करने के बीच सावधानीपूर्वक विचार करने की आवश्यकता होती है। प्रसंस्करण आवश्यकता को हल करने का एक तरीका एक समर्पित एआई त्वरक का उपयोग करना है। जैसा कि पहले उल्लेख किया गया है, SoC का AI इंजन साझा मेमोरी संसाधनों की कमी से पीड़ित हो सकता है। मॉडल अनुकूलन का उपयोग प्रसंस्करण आवश्यकता को कम करने के लिए भी किया जा सकता है, लेकिन यह प्रदर्शन और/या सटीकता को प्रभावित कर सकता है।
एक स्मार्ट कैमरा या एज उपकरण में, एकीकृत एसओसी (यानी, होस्ट प्रोसेसर) वीडियो फ्रेम प्राप्त करता है और हमारे द्वारा पहले बताए गए प्री-प्रोसेसिंग चरणों को निष्पादित करता है। इन कार्यों को SoC के सीपीयू कोर या GPU (यदि कोई उपलब्ध है) के साथ किया जा सकता है, लेकिन इन्हें SoC में समर्पित हार्डवेयर एक्सेलेरेटर (उदाहरण के लिए, छवि सिग्नल प्रोसेसर) द्वारा भी किया जा सकता है। इन प्री-प्रोसेसिंग चरणों के पूरा होने के बाद, एसओसी में एकीकृत एआई एक्सेलेरेटर सीधे सिस्टम मेमोरी से इस परिमाणित इनपुट तक पहुंच सकता है, या असतत एआई एक्सेलेरेटर के मामले में, इनपुट को अनुमान के लिए वितरित किया जाता है, आमतौर पर USB या PCIe इंटरफ़ेस.
एक एकीकृत एसओसी में सीपीयू, जीपीयू, एआई एक्सेलेरेटर, विज़न प्रोसेसर, वीडियो एनकोडर/डिकोडर, इमेज सिग्नल प्रोसेसर (आईएसपी) और बहुत कुछ सहित गणना इकाइयों की एक श्रृंखला शामिल हो सकती है। ये सभी गणना इकाइयाँ एक ही मेमोरी बस साझा करती हैं और परिणामस्वरूप एक ही मेमोरी तक पहुँच प्राप्त करती हैं। इसके अलावा, सीपीयू और जीपीयू को भी अनुमान में भूमिका निभानी पड़ सकती है और ये इकाइयां तैनात सिस्टम में अन्य कार्यों को चलाने में व्यस्त होंगी। सिस्टम-स्तरीय ओवरहेड (चित्र 2) से हमारा यही तात्पर्य है।
कई डेवलपर्स कुल प्रदर्शन पर सिस्टम-स्तरीय ओवरहेड के प्रभाव पर विचार किए बिना SoC में अंतर्निहित AI त्वरक के प्रदर्शन का गलती से मूल्यांकन करते हैं। उदाहरण के तौर पर, SoC में एकीकृत 50 TOPS AI त्वरक पर YOLO बेंचमार्क चलाने पर विचार करें, जो 100 अनुमान/सेकंड (IPS) का बेंचमार्क परिणाम प्राप्त कर सकता है। लेकिन सक्रिय अन्य सभी कम्प्यूटेशनल इकाइयों के साथ एक तैनात प्रणाली में, वे 50 TOPS 12 TOPS की तरह कम हो सकते हैं और समग्र प्रदर्शन केवल 25 IPS प्राप्त करेगा, एक उदार 25% उपयोग कारक मानते हुए। यदि प्लेटफ़ॉर्म लगातार वीडियो स्ट्रीम संसाधित कर रहा है तो सिस्टम ओवरहेड हमेशा एक कारक होता है। वैकल्पिक रूप से, एक अलग एआई त्वरक (उदाहरण के लिए, किनारा आरा -1, हेलो -8, इंटेल असंख्य एक्स) के साथ, सिस्टम-स्तरीय उपयोग 90% से अधिक हो सकता है क्योंकि एक बार होस्ट SoC अनुमान फ़ंक्शन शुरू करता है और एआई मॉडल के इनपुट को स्थानांतरित करता है डेटा, त्वरक मॉडल भार और मापदंडों तक पहुंचने के लिए अपनी समर्पित मेमोरी का उपयोग करके स्वायत्त रूप से चलता है।
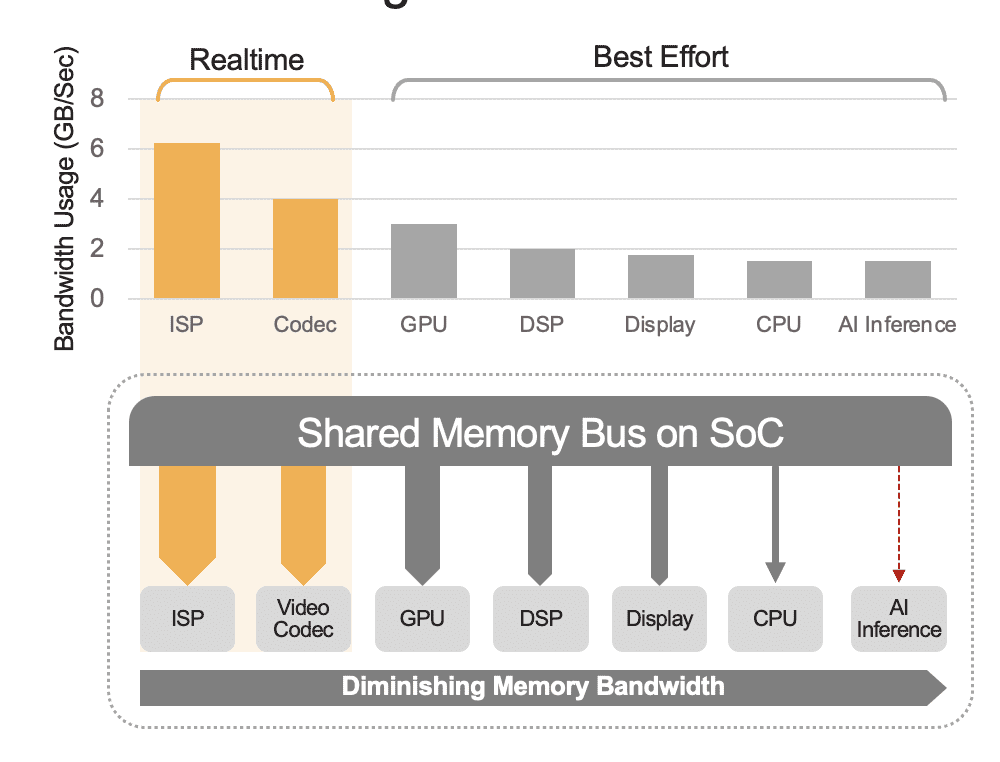
चित्र 2. साझा मेमोरी बस सिस्टम-स्तरीय प्रदर्शन को नियंत्रित करेगी, जिसे अनुमानित मूल्यों के साथ यहां दिखाया गया है। वास्तविक मान आपके एप्लिकेशन उपयोग मॉडल और SoC की गणना इकाई कॉन्फ़िगरेशन के आधार पर अलग-अलग होंगे।
इस बिंदु तक, हमने फ़्रेम प्रति सेकंड और TOPS के संदर्भ में AI प्रदर्शन पर चर्चा की है। लेकिन सिस्टम की वास्तविक समय प्रतिक्रिया देने के लिए कम विलंबता एक और महत्वपूर्ण आवश्यकता है। उदाहरण के लिए, गेमिंग में, सहज और प्रतिक्रियाशील गेमिंग अनुभव के लिए कम विलंबता महत्वपूर्ण है, विशेष रूप से गति-नियंत्रित गेम और वर्चुअल रियलिटी (वीआर) सिस्टम में। स्वायत्त ड्राइविंग सिस्टम में, सुरक्षा से समझौता करने से बचने के लिए वास्तविक समय वस्तु का पता लगाने, पैदल यात्री की पहचान, लेन का पता लगाने और यातायात संकेत पहचान के लिए कम विलंबता महत्वपूर्ण है। स्वायत्त ड्राइविंग सिस्टम को आमतौर पर पता लगाने से लेकर वास्तविक कार्रवाई तक 150 एमएस से कम की एंड-टू-एंड विलंबता की आवश्यकता होती है। इसी तरह, विनिर्माण में, वास्तविक समय दोष का पता लगाने, विसंगति की पहचान के लिए कम विलंबता आवश्यक है, और कुशल संचालन सुनिश्चित करने और उत्पादन डाउनटाइम को कम करने के लिए रोबोटिक मार्गदर्शन कम विलंबता वीडियो विश्लेषण पर निर्भर करता है।
सामान्य तौर पर, वीडियो एनालिटिक्स एप्लिकेशन में विलंबता के तीन घटक होते हैं (चित्र 3):
- डेटा कैप्चर विलंबता कैमरा सेंसर द्वारा वीडियो फ़्रेम कैप्चर करने से लेकर प्रोसेसिंग के लिए एनालिटिक्स सिस्टम तक फ़्रेम की उपलब्धता तक का समय है। आप तेज़ सेंसर और कम विलंबता प्रोसेसर वाला कैमरा चुनकर, इष्टतम फ्रेम दर का चयन करके और कुशल वीडियो संपीड़न प्रारूपों का उपयोग करके इस विलंबता को अनुकूलित कर सकते हैं।
- डेटा ट्रांसफर विलंबता कैमरे से किनारे के उपकरणों या स्थानीय सर्वर तक यात्रा करने के लिए कैप्चर किए गए और संपीड़ित वीडियो डेटा का समय है। इसमें प्रत्येक अंतिम बिंदु पर होने वाली नेटवर्क प्रोसेसिंग देरी शामिल है।
- डेटा प्रोसेसिंग विलंबता का तात्पर्य किनारे के उपकरणों के लिए फ्रेम डीकंप्रेसन और एनालिटिक्स एल्गोरिदम (उदाहरण के लिए, गति भविष्यवाणी-आधारित ऑब्जेक्ट ट्रैकिंग, चेहरे की पहचान) जैसे वीडियो प्रोसेसिंग कार्यों को करने के लिए समय से है। जैसा कि पहले बताया गया है, प्रसंस्करण विलंबता उन अनुप्रयोगों के लिए और भी महत्वपूर्ण है जिन्हें प्रत्येक वीडियो फ्रेम के लिए एकाधिक एआई मॉडल चलाना होगा।
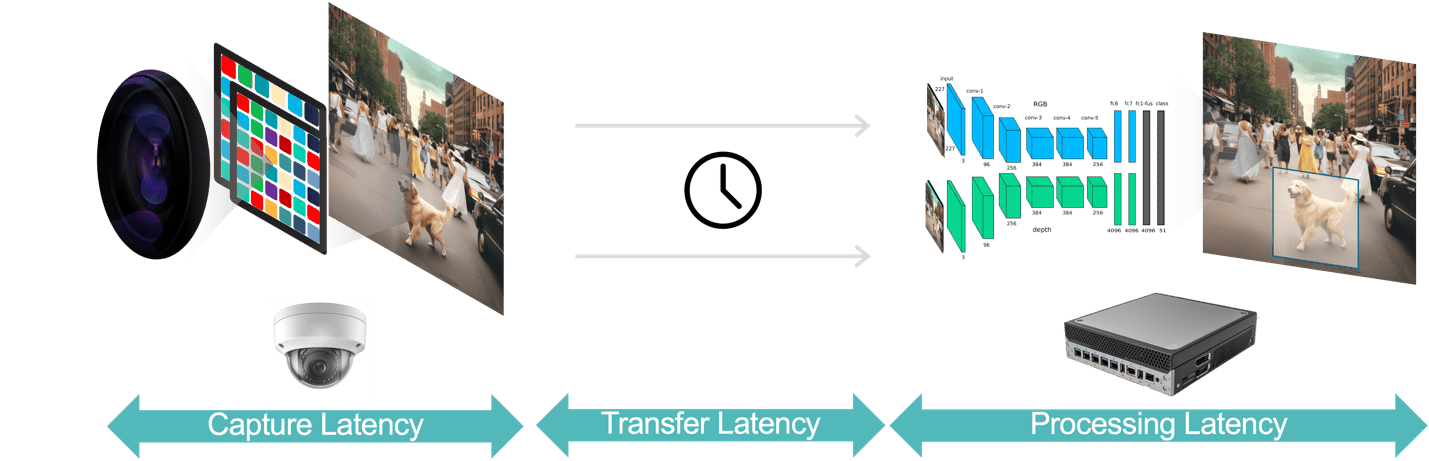
चित्र 3. वीडियो एनालिटिक्स पाइपलाइन में डेटा कैप्चर, डेटा ट्रांसफर और डेटा प्रोसेसिंग शामिल है।
डेटा प्रोसेसिंग विलंबता को एआई एक्सेलेरेटर का उपयोग करके अनुकूलित किया जा सकता है, जिसे चिप के पार और कंप्यूटिंग और मेमोरी पदानुक्रम के विभिन्न स्तरों के बीच डेटा आंदोलन को कम करने के लिए डिज़ाइन किया गया है। इसके अलावा, विलंबता और सिस्टम-स्तरीय दक्षता में सुधार करने के लिए, आर्किटेक्चर को मॉडलों के बीच शून्य (या शून्य के करीब) स्विचिंग समय का समर्थन करना चाहिए, ताकि हमने पहले चर्चा किए गए मल्टी-मॉडल अनुप्रयोगों का बेहतर समर्थन किया जा सके। बेहतर प्रदर्शन और विलंबता दोनों के लिए एक अन्य कारक एल्गोरिथम लचीलेपन से संबंधित है। दूसरे शब्दों में, कुछ आर्किटेक्चर केवल विशिष्ट एआई मॉडल पर इष्टतम व्यवहार के लिए डिज़ाइन किए गए हैं, लेकिन तेजी से बदलते एआई वातावरण के साथ, उच्च प्रदर्शन और बेहतर सटीकता के लिए नए मॉडल हर दूसरे दिन की तरह दिखाई दे रहे हैं। इसलिए, मॉडल टोपोलॉजी, ऑपरेटरों और आकार पर कोई व्यावहारिक प्रतिबंध नहीं होने वाले एज एआई प्रोसेसर का चयन करें।
किसी एज एआई उपकरण में प्रदर्शन को अधिकतम करने के लिए प्रदर्शन और विलंबता आवश्यकताओं और सिस्टम ओवरहेड सहित कई कारकों पर विचार किया जाना चाहिए। एक सफल रणनीति में SoC के AI इंजन में मेमोरी और प्रदर्शन सीमाओं को दूर करने के लिए एक बाहरी AI त्वरक पर विचार करना चाहिए।
सीएच ची एक कुशल उत्पाद विपणन और प्रबंधन कार्यकारी है, ची के पास सेमीकंडक्टर उद्योग में उत्पादों और समाधानों को बढ़ावा देने का व्यापक अनुभव है, जो उद्यम और उपभोक्ता सहित कई बाजारों के लिए दृष्टि-आधारित एआई, कनेक्टिविटी और वीडियो इंटरफेस पर ध्यान केंद्रित करता है। एक उद्यमी के रूप में, ची ने दो वीडियो सेमीकंडक्टर स्टार्ट-अप की सह-स्थापना की, जिन्हें एक सार्वजनिक सेमीकंडक्टर कंपनी द्वारा अधिग्रहित किया गया था। ची ने उत्पाद विपणन टीमों का नेतृत्व किया और एक छोटी टीम के साथ काम करने का आनंद लिया जो अच्छे परिणाम प्राप्त करने पर ध्यान केंद्रित करती है।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :हैस
- :है
- :नहीं
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- क्षमता
- त्वरक
- त्वरक
- पहुँच
- तक पहुँचने
- समायोजित
- पूरा
- शुद्धता
- प्राप्त करने
- प्राप्त
- का अधिग्रहण
- के पार
- कार्य
- सक्रिय
- वास्तविक
- जोड़ने
- अतिरिक्त
- दत्तक
- उन्नत
- बाद
- फिर
- AI
- एआई इंजन
- एआई मॉडल
- एल्गोरिथम
- एल्गोरिदम
- सब
- भी
- हमेशा
- an
- विश्लेषण
- विश्लेषिकी
- का विश्लेषण
- और
- असंगति का पता लगाये
- अन्य
- आवेदन
- अनुप्रयोगों
- दृष्टिकोण
- स्थापत्य
- हैं
- AS
- जुड़े
- At
- को स्वचालित रूप से
- स्वचालन
- स्वायत्त
- स्वायत्त
- उपलब्धता
- उपलब्ध
- से बचने
- आधारित
- आधार
- BE
- क्योंकि
- हो जाता है
- किया गया
- से पहले
- जा रहा है
- बेंचमार्क
- बेहतर
- के बीच
- के छात्रों
- मुक्केबाज़ी
- बक्से
- में निर्मित
- बस
- व्यस्त
- लेकिन
- by
- कैमरा
- कैमरों
- कर सकते हैं
- क्षमताओं
- क्षमता
- कब्जा
- पर कब्जा कर लिया
- कैप्चरिंग
- सावधान
- मामला
- मामलों
- चुनौती
- बदलना
- टुकड़ा
- चिप्स
- चुनने
- कक्षा
- बादल
- रंग
- अ रहे है
- कंपनी
- प्रतियोगी
- पूरा
- घटकों
- समझौता
- गणना
- कम्प्यूटेशनल
- गणना करना
- कंप्यूटर
- Computer Vision
- कंप्यूटर विजन एप्लीकेशन
- आत्मविश्वास
- विन्यास
- कनेक्टिविटी
- इसके फलस्वरूप
- विचार करना
- विचार
- माना
- पर विचार
- होते हैं
- की कमी
- उपभोक्ता
- शामिल
- निहित
- निरंतर
- लगातार
- रूपांतरण
- सका
- सी पी यू
- महत्वपूर्ण
- ग्राहक
- तिथि
- डेटा संसाधन
- दिन
- समर्पित
- देरी
- देरी
- उद्धार
- दिया गया
- निर्भर
- निर्भर करता है
- तैनात
- तैनाती
- वर्णित
- बनाया गया
- पता चला
- खोज
- निर्धारित करना
- डेवलपर्स
- डिवाइस
- अंतर
- सीधे
- चर्चा की
- डिस्प्ले
- स्र्कना
- ड्राइविंग
- दो
- गतिशील
- e
- से प्रत्येक
- पूर्व
- आसानी
- Edge
- प्रभाव
- प्रभावशीलता
- क्षमता
- दक्षता
- कुशल
- भी
- embedding
- समाप्त
- शुरू से अंत तक
- इंजन
- इंजन
- बढ़ाना
- सुनिश्चित
- उद्यम
- संपूर्ण
- उद्यमी
- वातावरण
- आवश्यक
- अनुमानित
- मूल्यांकन करें
- और भी
- प्रत्येक
- उद्विकासी
- उदाहरण
- से अधिक
- निष्पादित
- मार डाला
- कार्यकारी
- उम्मीद
- अनुभव
- अनुभव
- व्यापक
- विस्तृत अनुभव
- बाहरी
- चेहरा
- चेहरा पहचान
- कारक
- कारकों
- कारखाना
- फास्ट
- Feature
- भोजन
- खेत
- आकृति
- अंगुली की छाप
- प्रथम
- लचीलापन
- केंद्रित
- ध्यान केंद्रित
- के लिए
- प्रारूप
- फ्रेम
- से
- समारोह
- कार्यक्षमता
- कार्यों
- और भी
- भविष्य
- पाने
- Games
- जुआ
- जुआ खेलने का अनुभव
- सामान्य जानकारी
- उत्पन्न
- उत्पन्न
- उदार
- Go
- GPU
- GPUs
- महान
- अधिक से अधिक
- बढ़ रहा है
- विकास
- मार्गदर्शन
- हार्डवेयर
- है
- इसलिये
- यहाँ उत्पन्न करें
- पदक्रम
- हाई
- उच्चतर
- मेजबान
- HTTPS
- i
- पहचान करना
- if
- की छवि
- प्रभाव
- महत्वपूर्ण
- लगाया गया
- में सुधार
- उन्नत
- in
- अन्य में
- शामिल
- सहित
- बढ़ना
- वृद्धि हुई
- उद्योगों
- उद्योग
- आरंभ
- निवेश
- अंदर
- अंतर्दृष्टि
- एकीकृत
- इंटेल
- इंटरफेस
- इंटरफेस
- में
- शामिल करना
- शामिल
- निरपेक्ष
- आईएसपी
- IT
- आईटी इस
- केडनगेट्स
- लेबल
- रंग
- लेन
- बड़ा
- विलंब
- छोड़ने
- नेतृत्व
- कम
- स्तर
- पुस्तकालयों
- पसंद
- सीमा
- सीमाओं
- सीमित
- लिंक्डइन
- स्थानीय
- खोया
- निम्न
- कम
- प्रबंधन
- प्रबंध
- विनिर्माण
- बहुत
- विपणन (मार्केटिंग)
- Markets
- अधिकतम करने के लिए
- अधिकतम
- मई..
- मतलब
- उपायों
- मिलना
- याद
- उल्लेख किया
- हो सकता है
- चुक गया
- आदर्श
- मॉडल
- मॉड्यूल
- निगरानी
- अधिक
- अधिकांश
- प्रस्ताव
- आंदोलन
- विभिन्न
- चाहिए
- असंख्य
- निकट
- की जरूरत है
- नेटवर्क
- तंत्रिका
- तंत्रिका नेटवर्क
- नया
- अगला
- नहीं
- वस्तु
- ऑब्जेक्ट डिटेक्शन
- होते हैं
- of
- अक्सर
- on
- एक बार
- ONE
- केवल
- OpenCV
- आपरेशन
- परिचालन
- ऑपरेटरों
- विरोधी
- इष्टतम
- इष्टतमीकरण
- ऑप्टिमाइज़ करें
- अनुकूलित
- के अनुकूलन के
- or
- अन्य
- आउट
- उत्पादन
- के ऊपर
- कुल
- काबू
- समानांतर
- पैरामीटर
- विशेष रूप से
- प्रति
- निष्पादन
- प्रदर्शन
- प्रदर्शन
- प्रदर्शन
- प्रदर्शन
- पाइपलाइन
- मंच
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- प्ले
- बिन्दु
- स्थिति
- प्रोसेसिंग के बाद
- व्यावहारिक
- भविष्यवाणी
- प्रक्रिया
- संसाधित
- प्रसंस्करण
- प्रोसेसर
- प्रोसेसर
- एस्ट्रो मॉल
- उत्पादन
- उत्पाद
- को बढ़ावा देना
- प्रदान करना
- सार्वजनिक
- रेंज
- लेकर
- उपवास
- तेजी
- मूल्यांकन करें
- दरें
- कच्चा
- कच्चा डेटा
- वास्तविक
- वास्तविक समय
- वास्तविकता
- मान्यता
- को कम करने
- संदर्भित करता है
- की आवश्यकता होती है
- अपेक्षित
- आवश्यकता
- आवश्यकताएँ
- की आवश्यकता होती है
- संकल्प
- उपयुक्त संसाधन चुनें
- उत्तरदायी
- प्रतिबंध
- परिणाम
- परिणाम
- रोबोटिक्स
- भूमिका
- रन
- दौड़ना
- चलाता है
- सुरक्षा
- वही
- अनुमापकता
- स्केल
- स्केल एआई
- स्केलिंग
- दृश्य
- स्कोर
- निर्बाध
- दूसरा
- अनुभाग
- देखना
- लगता है
- का चयन
- अर्धचालक
- सेट
- Share
- साझा
- खरीदारी
- चाहिए
- दिखाया
- हस्ताक्षर
- संकेत
- उसी प्रकार
- के बाद से
- एक
- आकार
- छोटा
- स्मार्ट
- समाधान
- समाधान ढूंढे
- हल
- हल करती है
- कुछ
- कुछ
- अंतरिक्ष
- विशिष्ट
- स्टार्ट-अप
- कदम
- की दुकान
- रणनीतियों
- स्ट्रेटेजी
- धारा
- नदियों
- सफल
- ऐसा
- पर्याप्त
- समर्थन
- दमन
- निगरानी
- प्रणाली
- सिस्टम
- लेना
- लेता है
- कार्य
- टीम
- टीमों
- टेक्नोलॉजीज
- टेक्नोलॉजी
- शर्तों
- से
- कि
- RSI
- भविष्य
- लेकिन हाल ही
- फिर
- वहाँ।
- इसलिये
- इन
- वे
- इसका
- उन
- तीन
- यहाँ
- THROUGHPUT
- पहर
- बार
- सेवा मेरे
- सबसे ऊपर है
- कुल
- ट्रैक
- ट्रैकिंग
- यातायात
- स्थानांतरण
- स्थानान्तरण
- बदालना
- यात्रा
- <strong>उद्देश्य</strong>
- दो
- आम तौर पर
- अंत में
- असमर्थ
- समझना
- इकाई
- इकाइयों
- प्रयोग
- USB के
- उपयोग
- प्रयुक्त
- का उपयोग करता है
- का उपयोग
- आमतौर पर
- उपयोग
- मान
- विविधता
- विभिन्न
- वीडियो
- देखें
- वास्तविक
- आभासी वास्तविकता
- दृष्टि
- महत्वपूर्ण
- vr
- मार्ग..
- we
- थे
- क्या
- या
- कौन कौन से
- व्यापक रूप से
- मर्जी
- साथ में
- बिना
- शब्द
- काम कर रहे
- होगा
- X
- प्राप्ति
- Yolo
- इसलिए आप
- आपका
- जेफिरनेट
- शून्य







