ऑप्टिकल कैरेक्टर रिकॉग्निशन (ओसीआर), मशीन-एन्कोडेड टेक्स्ट में हस्तलिखित / मुद्रित ग्रंथों को परिवर्तित करने की विधि, हमेशा विभिन्न क्षेत्रों में अपने कई अनुप्रयोगों के कारण कंप्यूटर दृष्टि में अनुसंधान का एक प्रमुख क्षेत्र रहा है - बैंक बयानों की तुलना करने के लिए ओसीआर का उपयोग करते हैं; सर्वेक्षण के फीडबैक संग्रह के लिए सरकारें ओसीआर का उपयोग करती हैं।

लिखावट और मुद्रित पाठ शैलियों में विविधता के कारण, OCR के हालिया दृष्टिकोणों में उच्च सटीकता हासिल करने के लिए गहरी सीख शामिल है। जैसा कि गहन प्रशिक्षण के लिए मॉडल प्रशिक्षण के लिए बड़ी मात्रा में डेटा की आवश्यकता होती है, Google जैसी कंपनियां अपने OCR सेवाओं के साथ आशाजनक परिणाम देने में बढ़त लेती हैं।
यह लेख Google विज़न OCR के विवरण में गोता लगाता है, जिसमें अजगर में एक सरल ट्यूटोरियल, अनुप्रयोगों की श्रेणी, मूल्य निर्धारण और अन्य विकल्प शामिल हैं।
- Google क्लाउड विजन ओसीआर क्या है?
- एक सरल ट्यूटोरियल
- OCR क्यों?
- उदाहरण उपयोग के मामले
- मूल्य निर्धारण
- Google क्लाउड विजन ओसीआर की मुख्य विशेषताएं
- अल्टरनेटिव्स
- सामान्य मुद्दे
Google क्लाउड विज़न क्या है?

Google क्लाउड विज़न OCR छवियों से पाठ निकालने के लिए Google क्लाउड विज़न API का एक हिस्सा है। विशेष रूप से, चरित्र पहचान में मदद करने के लिए दो एनोटेशन हैं:
- पाठ_नोटबंदी: यह किसी भी छवि से मशीन-एन्कोडेड ग्रंथों को निकालता है और आउटपुट करता है (उदाहरण के लिए, सड़क दृश्य या विज्ञान की तस्वीरें)। चूंकि इसे शुरू में अलग-अलग प्रकाश स्थितियों के तहत प्रयोग करने योग्य बनाया गया था, इसलिए मॉडल कुछ अर्थों में विभिन्न शैलियों के शब्दों को पढ़ने में अधिक मजबूत है, लेकिन केवल अधिक विरल स्तर पर। JSON फ़ाइल में संपूर्ण स्ट्रिंग्स के साथ-साथ व्यक्तिगत शब्द और उनके संबंधित बाउंडिंग बॉक्स शामिल हैं।
- दस्तावेज़_पाठ_एनोटेशन: यह विशेष रूप से घने-प्रस्तुत पाठ दस्तावेजों (जैसे, स्कैन की गई पुस्तकें) के लिए डिज़ाइन किया गया है। इस प्रकार, जबकि यह छोटे और अधिक केंद्रित ग्रंथों को पढ़ने का समर्थन करता है, यह इन-द-वाइल्ड छवियों के अनुकूल कम है। पैराग्राफ, ब्लॉक, और ब्रेक जैसी जानकारी आउटपुट JSON फ़ाइल में शामिल हैं।
एक ओसीआर समाधान की तलाश है जो Google क्लाउड विज़न की कमियों को दूर करे या जोनल ओसीआर? नैनोनेट दें™ उच्च सटीकता, अधिक लचीलापन और व्यापक दस्तावेज़ प्रकारों के लिए एक स्पिन!
एक सरल ट्यूटोरियल
निम्न अनुभाग Google विज़न एपीआई के साथ आरंभ करने में एक सरल ट्यूटोरियल का परिचय देता है, विशेष रूप से Google क्लाउड विज़न ओसीआर सेवा के लिए इसका उपयोग कैसे करें।
सरल अवलोकन
इसके पीछे का विचार बहुत सहज और सरल है।
1) आप अनिवार्य रूप से Google क्लाउड विजन एपीआई में एक छवि (दूरस्थ या अपने स्थानीय भंडारण से) भेजते हैं।
2) छवि को Google क्लाउड पर दूरस्थ रूप से संसाधित किया जाता है और आपके द्वारा कहे गए फ़ंक्शन के संबंध में संबंधित JSON प्रारूप बनाता है।
3) JSON फाइल को फंक्शन के बाद आउटपुट के रूप में लौटाया जाता है।
Google क्लाउड विजन एपीआई की स्थापना
Google विज़न एपीआई द्वारा प्रदान की गई किसी भी सेवा का उपयोग करने के लिए, Google क्लाउड कंसोल को कॉन्फ़िगर करना होगा और प्रमाणीकरण के लिए कई चरणों को पूरा करना होगा। निम्नलिखित संपूर्ण विज़न एपीआई सेवा को सेट करने के चरण-दर-चरण अवलोकन है।
- Google क्लाउड कंसोल में एक प्रोजेक्ट बनाएं - किसी विज़न सेवा का उपयोग शुरू करने के लिए एक प्रोजेक्ट बनाना होगा। परियोजना सहयोगी, एपीआई और मूल्य निर्धारण जानकारी जैसे संसाधनों का आयोजन करती है।
- बिलिंग सक्षम करें - दृष्टि एपीआई को सक्षम करने के लिए, आपको पहले अपने प्रोजेक्ट के लिए बिलिंग सक्षम करना होगा। मूल्य निर्धारण का विवरण बाद के खंडों में संबोधित किया जाएगा।
- विजन एपीआई सक्षम करें
- सेवा खाता बनाएँ - एक सेवा खाता बनाएँ और निर्मित परियोजना से लिंक करें, फिर एक सेवा खाता कुंजी बनाएँ। कुंजी आउटपुट होगी और आपके कंप्यूटर पर JSON फ़ाइल के रूप में डाउनलोड की जाएगी।
- पर्यावरण चर GOOGLE_APPLICATION_CREDENTIALS सेट करें; इस परिवेश चर को सेट करने के लिए, इसे Mac/Linux या Windows पर चलाएँ।
- मैक / लिनक्स के लिए कोड ब्लॉक
- विंडोज के लिए कोड ब्लॉक
उपरोक्त चरणों की अधिक विस्तृत प्रक्रिया Google क्लाउड द्वारा यहां दिए गए आधिकारिक दस्तावेज से पाई जा सकती है:
https://cloud.google.com/vision/docs/quickstart-client-libraries
पायथन में सरल Google विज़न ओसीआर फंक्शन
Google क्लाउड विज़न एपीआई कई लोकप्रिय भाषाओं के साथ काम करता है, जो जावा, नोड्स, पायथन, से लेकर Google की अपनी भाषा गो तक है। सादगी के लिए, हम पायथन में एक साधारण कॉलिंग विधि का परिचय देते हैं।
def detect_text(path): """Detects text in the file.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.text_detection(image=image) texts = response.text_annotations print('Texts:') for text in texts: print('n"{}"'.format(text.description)) vertices = (['({},{})'.format(vertex.x, vertex.y) for vertex in text.bounding_poly.vertices]) print('bounds: {}'.format(','.join(vertices))) दूसरे शब्दों में, विधि फलस्वरूप फ़ंक्शन को कॉल करती है टेक्स्ट_एनोटेशन, फिर आगे प्रतिक्रियाओं को निकालें और जानकारी को प्रिंट करें। दस्तावेज़_पाठ_एनोटेशन घने ग्रंथों को पुनः प्राप्त करने के लिए उसी तरह का उपयोग करके भी बुलाया जा सकता है। एक के माध्यम से छवि को दूर से भी छवियों का पता लगा सकते हैं:
image.source.image_uri = uriजहां यूरी छवि का यूरी है।
कोड के अधिक विवरण यहां प्राप्त किए जा सकते हैं:
https://cloud.google.com/vision
Google क्लाउड विज़न की कमियों को दूर करने वाले OCR समाधान की तलाश है? नैनोनेट्स दें™ उच्च सटीकता, अधिक लचीलापन और व्यापक दस्तावेज़ प्रकारों के लिए एक स्पिन!
उत्पादन के स्तर की पेशकश की
पाठ के आगे के डेटा विश्लेषण में सहायता के लिए, दो Google OCR फ़ंक्शन उपयोगकर्ताओं को उपयोग करने के लिए विभिन्न स्तर के आउटपुट प्रदान करते हैं: के लिए टेक्स्ट_एनोटेशन, दोनों पूरे तार (यदि Google द्वारा एक वाक्य या वाक्यांश के रूप में माना जाता है) और भीतर व्यक्तिगत शब्द; के लिये दस्तावेज़_पाठ_एनोटेशन, क्योंकि मॉडल घने पाठ के लिए अनुकूलित है, पृष्ठ, ब्लॉक, पैराग्राफ, शब्द, और ब्रेक सभी आउटपुट के एक भाग के रूप में पेश किए जाते हैं।
हालांकि यह कितनी अच्छी तरह काम करता है?
मॉडल कितने मजबूत हैं?
जैसा कि पहले उल्लेख किया गया है, Google OCR के लिए दो अलग-अलग स्थितियों में दो फ़ंक्शन प्रदान करता है। निम्नलिखित विभिन्न प्रकार के डेटा को पुनः प्राप्त करने में दो कार्यों की क्षमता का वर्णन करता है।
मुद्रित डेटा
व्याख्या करने के लिए सबसे आसान प्रकार का डेटा मुद्रित पाठ डेटा, यानी, कंप्यूटर लिखित पाठ मुद्रित और स्कैन किया गया है। ओसीआर की आवश्यकता तब होती है जब हमारे पास मूल मशीन-एन्कोडेड पाठों के बजाय केवल इन डेटा की मुद्रित प्रति होती है। जैसा कि इन ग्रंथों में से अधिकांश तंग हैं और पृष्ठों में पैक किए गए हैं, दस्तावेज़_पाठ_एनोटेशन एक बेहतर विकल्प होगा।
हाथ से लिखा हुआ डेटा
सामग्री में हाथ से लिखे गए पाठ हो सकते हैं और हाथ से लिखे गए डेटा की शैलियाँ काफी भिन्न हो सकती हैं। फिर भी, Google विज़न ओसीआर तब तक सही सटीकता प्रदान करता है जब तक कि हस्तलिखित नोट बहुत गन्दा न हों। हाथ से लिखे गए डेटा के माध्यम को कैसे प्रस्तुत किया जाता है, इस पर निर्भर करते हुए, हम केस-टू-केस आधार पर दो कार्यों में से एक का उपयोग करते हैं।
घुमाया / इन-द-वाइल्ड डेटा
जब छवियों या स्कैन की गई तस्वीरों को अपरंपरागत या बिना डिजाइन वाले कोणों में प्रस्तुत किया जाता है, तो हम उन्हें जंगली डेटा के रूप में मानते हैं। ग्रंथों को संभवतः पहले स्थान पर पता लगाया जाना अधिक कठिन हो सकता है, और इसलिए हम आमतौर पर उपयोग करते हैं टेक्स्ट_एनोटेशन फ़ंक्शन जो पहले स्थान पर जंगली डेटा को संसाधित करने के लिए डिज़ाइन किया गया था। विभिन्न कोणों पर कैप्चर किए गए ऊर्ध्वाधर ग्रंथों और सड़क के संकेतों से गुजरने के कुछ प्रयोगों के आधार पर, हम बताते हैं कि Google विज़न ओसीआर वास्तव में विभिन्न वातावरणों के डेटा पर शालीनता से कार्य करता है।
OCR क्यों?
आज हमारे पास मौजूद कई डेटा अनस्ट्रक्चर्ड फॉर्मेट में हैं। उदाहरण के लिए, एक छवि, एक स्कैन किए गए दस्तावेज़, या एक तस्वीर, जबकि मनुष्य जल्दी से ग्रंथों को पहचान सकते हैं और अर्थों की व्याख्या कर सकते हैं, सभी पाठ डेटा केवल रंगों के साथ पिक्सेल हैं, मशीनों को कोई वास्तविक अर्थ प्रदान नहीं करते हैं।

जब कंपनियां या बड़े निगम भारी मात्रा में कागजी कार्रवाई कर रहे हैं, तो बड़े डेटा की मात्रा किसी भी वर्गीकरण या डेटा प्रसंस्करण के लिए पूरी तरह से मानव प्रयास के साथ असंभव हो जाएगी - यह तब है जब मशीन-एन्कोडेड पाठ काम में आता है।
ओसीआर रूपांतरण के बाद, डेटा की प्रकृति के आधार पर कई अलग-अलग तरीकों से जानकारी का विश्लेषण किया जा सकता है:
- संख्यात्मक डेटा के लिए, सांख्यिकीय तरीकों को सीधे किसी भी सहसंबंधों के विश्लेषण के लिए लागू किया जा सकता है। हम पारंपरिक मशीन सीखने के तरीकों (जैसे, KNN, K- मीन्स, रेखीय प्रतिगमन) को भी अपना सकते हैं या प्रतिगमन और / या वर्गीकरण के लिए भविष्य कहनेवाला मॉडल बनाने के लिए गहन शिक्षण दृष्टिकोण।
- पाठ डेटा के लिए, प्रसंस्करण के अधिक चरणों की आवश्यकता हो सकती है। सार्थक आंकड़ों में पाठ डेटा के विश्लेषण और व्याख्या की प्रक्रिया को अक्सर प्राकृतिक भाषा प्रसंस्करण (एनएलपी) कहा जाता है। विशेष रूप से, हम दी गई सामग्री के आधार पर संख्याएँ या शब्दार्थ / वातावरण भी निकाल सकते हैं।
ये सभी विश्लेषण कंपनियों, विशेष रूप से हर दिन नए डेटा की विशाल मात्रा के साथ, मजबूत मॉडल बनाने और यहां तक कि बहुत सारी प्रक्रियाओं को स्वचालित करने और पारंपरिक श्रम-गहन और त्रुटि-भरे दृष्टिकोणों को बदलने की अनुमति दे सकते हैं। निम्नलिखित अनुभाग OCR का उपयोग कैसे किया जा सकता है, इसके कुछ विस्तृत उदाहरणों में बताया गया है।
Google क्लाउड विज़न की कमियों को दूर करने वाले OCR समाधान की तलाश है? नैनोनेट्स दें™ उच्च सटीकता, अधिक लचीलापन और व्यापक दस्तावेज़ प्रकारों के लिए एक स्पिन!
उदाहरण उपयोग के मामले
लाइसेंस प्लेट पढ़ना

शायद आजकल OCR के सबसे सामान्य उपयोगों में से एक लाइसेंस प्लेट रीडिंग में आवेदन है। विकसित देशों में, पार्किंग स्थल के साथ अक्सर पार्किंग प्लेट रीडिंग मॉडल होते हैं, ताकि प्रवेश समय, निकास समय और यहां तक कि कार के सटीक पार्क किए गए स्थान का निर्धारण किया जा सके। कुछ पार्किंग स्थल सरकारी शुल्क से जुड़े होते हैं, ताकि परिवारों से सीधे पार्किंग शुल्क वसूला जा सके - ये सभी निरर्थक मानवीय प्रयासों को कम करते हैं।
लाइसेंस प्लेट OCR मॉडल यातायात उल्लंघन में हिरासत के लिए भी अपनाया जा सकता है, उल्लंघन करने वाले कार के डेटा में पुलिस को मैन्युअल रूप से कुंजी देने के लिए समय कम कर देता है।
रसीद और चालान स्कैन

वित्तीय अनुमान और कंपनियों की संपत्ति और देनदारियों को संतुलित करना किसी भी फर्म के लिए महत्वपूर्ण गतिविधियां हैं। चूंकि बड़ी कंपनियां पूरे वर्ष में कई क्षेत्रों से बड़ी मात्रा में खरीदारी करती हैं, उन्हें वित्तीय विवरण बनाते समय सभी चालान और प्राप्तियों को सावधानीपूर्वक इकट्ठा करने और संसाधित करने की आवश्यकता होती है।
OCR की मदद से हम स्वचालित पाइपलाइन बना सकते हैं जो कई चालान प्रारूपों को पहचानें और उन्हें संख्याओं में परिवर्तित करें। श्रम प्रयासों की केवल जाँच के लिए आवश्यकता होती है, और संरचित डेटा और संख्याएँ कंपनी को अंतर्वाह और बहिर्वाह को जल्दी से संतुलित करने, वित्तीय अनुमान बनाने, साथ ही कंपनी के वित्त के किसी भी दुर्भावनापूर्ण हेरफेर के लिए देखने की अनुमति दे सकती हैं।
इलेक्ट्रिकल मेडिकल रिकॉर्ड

मरीजों का डेटा अक्सर एक क्षेत्र, देश या यहां तक कि देशों में व्यक्तियों की जीवन शैली पर निर्भर करता है। क्लीनिकों और अस्पतालों की विभिन्न शैलियों के कारण (बड़े अस्पतालों ने डेटाबेस का आयोजन किया हो सकता है, जबकि छोटे क्लीनिकों में डॉक्टर सिर्फ हाथ से रिकॉर्ड लिख सकते हैं), रोगियों की उम्र (पुराने रोगियों को नवीकरण और निगमन से पहले एक विशेष डेटाबेस में डाला जा सकता है) कंप्यूटर), और व्यक्तियों के स्थान (लोग एक अलग शहर या विदेश में भी स्थानांतरित कर सकते हैं), एक सार्वभौमिक चिकित्सा रखना वास्तव में बहुत मुश्किल हो सकता है।
एक अच्छी तरह से प्रशिक्षित ओसीआर एक अस्पताल से दूसरे अस्पताल में ईएमआर को स्थानांतरित करने या हाथ से लिखे गए डेटा को मशीन पाठ में बदलने के दौरान काम में आता है - यह दोनों रोगियों के चिकित्सा इतिहास को तेजी से और संक्षिप्त तरीके से समझने की प्रक्रिया को तेज कर सकता है।
प्रपत्र और सर्वेक्षण

संगठनों (चाहे सरकारी या गैर-सरकारी) को अक्सर अपने वर्तमान प्रचार योजनाओं और उत्पादों पर सुधार करने के लिए ग्राहकों या नागरिकों से प्रतिक्रिया की आवश्यकता हो सकती है। चूंकि फॉर्म आमतौर पर हाथ से लिखे जाते हैं, इसलिए किसी भी प्रत्यक्ष सांख्यिकीय विश्लेषण को करना मुश्किल होगा। इसलिए, गणना की सुविधा के लिए असंरचित आंकड़ों और हस्तलिखित सर्वेक्षणों को संख्यात्मक आंकड़ों में बदलने की प्रक्रिया को ओसीआर द्वारा सहायता और त्वरित किया जा सकता है।
Google क्लाउड विज़न की कमियों को दूर करने वाले OCR समाधान की तलाश है? नैनोनेट्स दें™ उच्च सटीकता, अधिक लचीलापन और व्यापक दस्तावेज़ प्रकारों के लिए एक स्पिन!
क्लाउड विजन प्राइसिंग
गूगल के अनुसार वेबसाइट , दोनों टेक्स्ट_एनोटेशन और दस्तावेज़_पाठ_एनोटेशन निम्नलिखित के समान मूल्य स्तर पर पेश किए जाते हैं:
हर महीने के लिए, पहली 1000 इकाइयों को मुफ्त दिया जाता है, 1000-5000000 डॉलर प्रति 1.5 यूनिट्स पर चार्ज किया जाता है। 1000 अंक से टकराने के बाद, कीमत घटकर $ 5000000 प्रति 0.6 यूनिट हो जाती है (Google विज़न एपीआई के माध्यम से भेजी जाने वाली प्रत्येक छवि को प्रति यूनिट माना जाता है)।
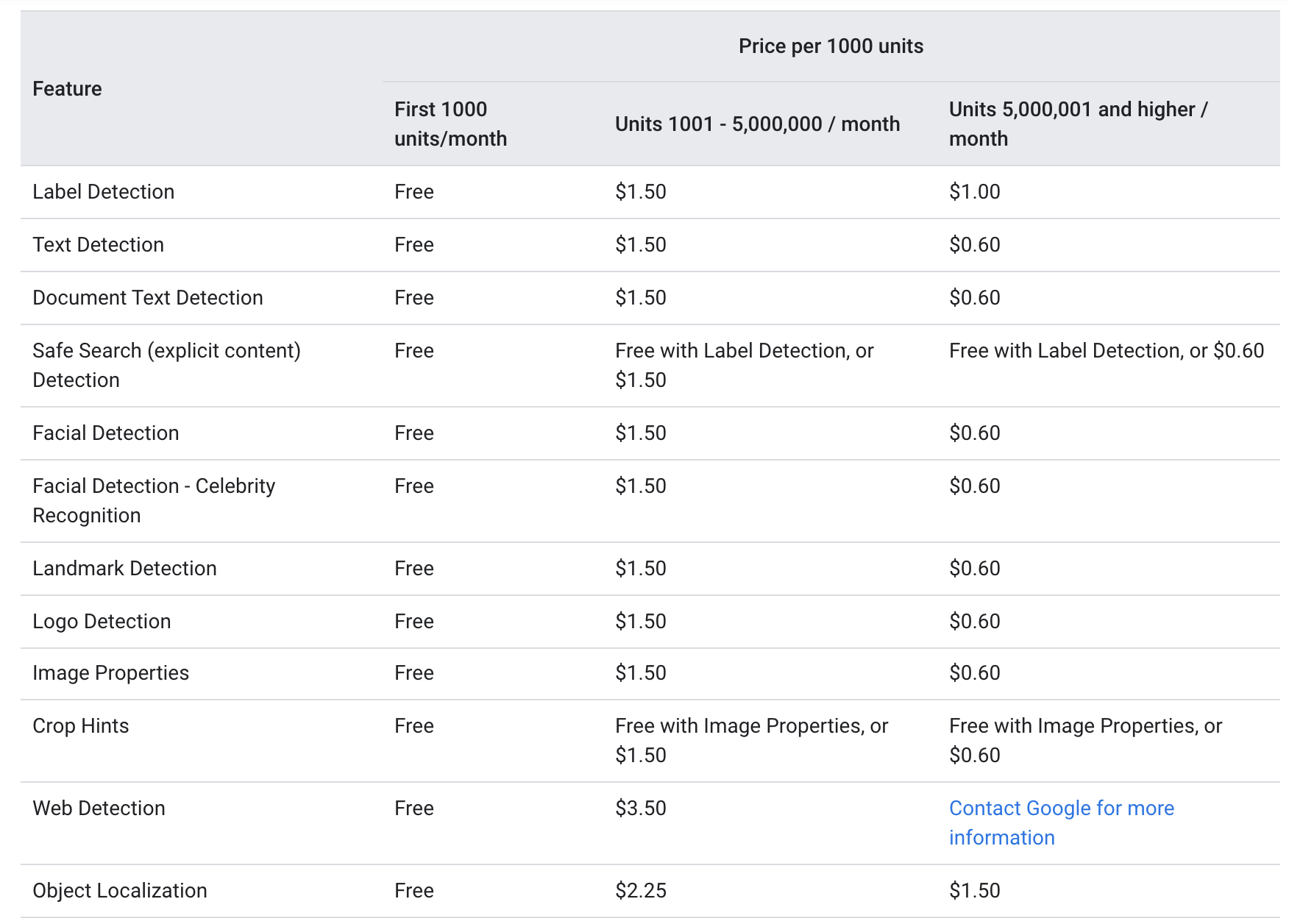
उपरोक्त मूल्य निर्धारण से पता चलता है कि ओसीआर सेवा दोनों छोटी कंपनियों के लिए अपेक्षाकृत कम उपयोग के साथ-साथ बड़े निगमों के लिए अपेक्षाकृत सस्ती है जहां सेवा प्रति माह 5000000 से अधिक बार आवश्यक है।
Google क्लाउड विजन ओसीआर की मुख्य विशेषताएं
Google OCR के विभिन्न लाभ हैं, यहाँ हम कुछ सबसे महत्वपूर्ण लाभों का वर्णन करते हैं:
- पुष्ट - उपयोगकर्ताओं के निर्णय पर निर्भर दो प्रकार के पाठ दस्तावेज़ों की सेवा करने वाले दो कार्य, Google विज़न ओसीआर को एकल-मॉडल ओसीआर इंजनों की तुलना में अधिक मजबूत बनाते हैं।
- भाषा समर्थन - शायद सबसे बड़े भाषा डेटाबेस के साथ, Google ने सलाह दी है कि इसका OCR 60 से अधिक भाषाओं पर लागू है, कुछ दर्जनों पर प्रयोग कर रहा है, और बाकी के कई अन्य भाषा कोड या सामान्य भाषा पहचानकर्ता के लिए मैप करता है।
- उपयोग में आसानी - मॉडल स्वयं इन-बिल्ट Google विज़न लाइब्रेरी का हिस्सा है। एपीआई कुंजी (जो लगभग सभी ओसीआर इंजनों द्वारा आवश्यक है) को कॉन्फ़िगर करने की थोड़ी अधिक घबराहट वाली प्रक्रिया के बाद, फ़ंक्शन-कॉलिंग विधि का उपयोग कई भाषाओं में बहुत सरल तरीके से किया जा सकता है।
- स्केलेबिलिटी - Google की मूल्य निर्धारण रणनीति उपयोगकर्ताओं को एपीआई के उपयोग को बढ़ावा देने के लिए प्रोत्साहित करती है, क्योंकि अधिक उपयोग एक सस्ती औसत कीमत की ओर जाता है।
- गति - Google क्लाउड का स्टोरेज प्लेटफ़ॉर्म शानदार रूप से एपीआई उपयोग के साथ है। छवियों को ड्राइव में अपलोड करके, एपीआई की प्रतिक्रिया का समय बहुत तेज और स्केलेबल हो सकता है।

Google क्लाउड विज़न की कमियों को दूर करने वाले OCR समाधान की तलाश है? नैनोनेट्स दें™ उच्च सटीकता, अधिक लचीलापन और व्यापक दस्तावेज़ प्रकारों के लिए एक स्पिन!
अल्टरनेटिव्स
प्रत्येक सेवा के फायदे और नुकसान के साथ, Google विज़न एपीआई के अलावा अन्य कुछ OCR सेवाएँ निम्नलिखित हैं।
ABBYY
ABBYY FineReader PDF ABBYY द्वारा विकसित एक OCR है, जो विशेष रूप से PDF पढ़ने पर केंद्रित है।
- पेशेवरों: ABBYY व्यक्तिगत उपयोगकर्ताओं के लिए बहुत अधिक लागत के अनुकूल है क्योंकि मूल्य निर्धारण को छोटे क्षेत्रों (1000, 2000 पृष्ठों, आदि) में विभाजित किया गया है। इसे गैर-इंजीनियरिंग ग्राहकों की ओर भी निर्देशित किया जाता है क्योंकि यह एक व्यावसायिक ऐप है।
- विपक्ष: सॉफ्टवेयर केवल पीडीएफ प्रारूप पर केंद्रित है, और बड़े पैमाने पर ओसीआर करते समय कीमत बहुत महंगी हो जाती है।
- कब इस्तेमाल करें: अलग-अलग उपयोगकर्ताओं के लिए जो केवल पीडीएफ को जल्दी से संभालना चाहते हैं, एबीबीवाई Google विज़न एपीआई की तुलना में अधिक व्यवहार्य विकल्प हो सकता है जो अधिक लचीलापन देता है लेकिन अतिरिक्त कोड की आवश्यकता होती है।
माइक्रोसॉफ्ट
Microsoft Azure OCR के लिए Read API भी प्रदान करता है।
- पेशेवरों: Microsoft उपयोग किए जाने वाले डेटा की एक बड़ी संख्या के लिए एक सस्ती कीमत प्रदान करता है। Azure क्लाउड स्टोरेज Google क्लाउड के समान सेवाएं प्रदान करता है।
- विपक्ष: कोई मुफ्त टियर नहीं है, जबकि अन्य विकल्प कम उपयोग के लिए मुफ्त एपीआई कॉल प्रदान करते हैं।
- कब इस्तेमाल करें: बहुत बड़े पैमाने पर ओसीआर उत्पादन पाइपलाइनों को Microsoft के मूल्य निर्धारण से लाभ मिल सकता है।
कोफैक्स
ABBYY की तरह, कोफ़ैक्स भी PDF की OCR रीडिंग प्रदान करता है
- पेशेवरों: मूल्य व्यक्तिगत उपयोग के लिए तय किया गया है, और उद्यमों के लिए छूट की पेशकश की जाती है। 24/7 ग्राहक सहायता भी प्रदान की जाती है।
- विपक्ष: गुणवत्ता के बारे में दावा किया जाता है कि यह एबीबीवाई की तरह नहीं है।
- कब इस्तेमाल करें: कम उपयोग आवश्यकताओं वाले छोटे उद्यम।
AWS बनावट
Google विजन API की तुलना में AWS टेक्सट्रैक बहुत समान भूमिका निभाता है। उनकी सेवाएं और मूल्य निर्धारण बहुत समान हैं, और इसलिए उन्हें अपनाने के लिए पूरी तरह से ग्राहकों की वरीयताओं पर आधारित है।
नैनोनेट्स
पहले से चर्चा की गई सेवाओं के विपरीत, नैनोनेट्स के ओसीआर को विशिष्ट श्रेणियों में वर्गीकृत किया जाता है, जिसमें प्रत्येक डेटा प्रकार (जैसे, रसीदें, चालान, ड्राइविंग लाइसेंस) पर प्रशिक्षित मजबूत मॉडल होते हैं।
- पेशेवरों: श्रेणी-विशिष्ट ओसीआर, इसलिए सटीकता के संदर्भ में बेहतर परिणाम प्रदान करते हैं जब फर्मों को लक्ष्य-विशिष्ट अनुप्रयोगों के लिए ओसीआर की आवश्यकता होती है।
- विपक्ष: अत्यधिक विशिष्ट और अनुरूपित मॉडलों के कारण नैनोनेट्स ओसीआर इन-द-वाइल्ड सेटिंग्स पर कम लागू हो सकता है
- कब इस्तेमाल करें: यदि फर्मों को एक विशेष प्रकार के डेटा जैसे कि इनवॉइस के लिए ओसीआर की आवश्यकता होती है, तो नैनोनेट एक लागत-अनुकूल और अत्यधिक सटीक विकल्प हो सकता है।
आप ऐसा कर सकते हैं यहां नैनोनेट्स ऑनलाइन ओसीआर आज़माएं।
क्लाउड विजन के साथ सामान्य मुद्दे
इस अंतिम खंड में, हम दस्तावेज़ स्कैनिंग और ओसीआर के बारे में स्टैकओवरफ़्लो से कुछ प्रश्नों को संबोधित करना चाहते हैं
तंत्रिका नेटवर्क का उपयोग करते हुए दस्तावेजों को पहचानना
यह Google OCR का सटीक उपयोग है! दस्तावेजों में स्कैन करने और पाठ पुनर्प्राप्ति करने के लिए ऊपर दिए गए चरणों का पालन करें।
ओसीआर के बाद सबसे महत्वपूर्ण विवरण हथियाना
किसी भी दस्तावेज़ के अंदर सबसे सार्थक सामग्री को पार्स करने के विचार को प्राकृतिक भाषा प्रसंस्करण कहा जाता है। चूंकि प्रत्येक दस्तावेज़ में विभिन्न स्वरूपों में ऐसी जानकारी होती है, इसलिए ऐसा करने के लिए कुछ एमएल दृष्टिकोण अपनाने की सिफारिश की जाएगी। बेशक, अगर सभी कार्ड एक ही प्रारूप में हैं, तो कुछ प्रमुख पात्रों के साथ ग्रंथों को पुनः प्राप्त करने के लिए नियम-आधारित तरीके (जैसे, यदि इसमें @ यह एक ईमेल है) भी काम करना चाहिए।
क्या यह ऑफ़लाइन चल सकता है?
लिंक: https://stackoverflow.com/questions/63315520/google-cloud-vision-api-can-it-run-offline
दुर्भाग्यवश नहीं। API Google क्लाउड OCR को दूरस्थ रूप से कॉल करता है, और API ऑफ़लाइन काम नहीं कर सकता क्योंकि पैसा खर्च होता है।
क्या यह पता लगा सकता है कि कोई पाठ बोल्ड या इटैलिक्स में है?
नहीं, Google OCR टेक्स्ट सामग्री को बोल्ड या इटैलिक में होने पर भी सबसे अधिक संभावना का पता लगाएगा, लेकिन OCR मॉडल को फ़ॉन्ट प्रकारों को समझने के लिए डिज़ाइन नहीं किया गया है।
अपडेट: पाठकों के प्रश्नों के आधार पर अधिक जानकारी जोड़ी गई।
- &
- a
- त्वरित
- लेखा
- सही
- के पार
- गतिविधियों
- पता
- फायदे
- सब
- वैकल्पिक
- विकल्प
- हमेशा
- राशियाँ
- विश्लेषण
- विश्लेषण करें
- अन्य
- एपीआई
- एपीआई
- अनुप्रयोग
- उपयुक्त
- आवेदन
- अनुप्रयोगों
- लागू
- दृष्टिकोण
- क्षेत्र
- चारों ओर
- लेख
- संपत्ति
- प्रमाणीकरण
- को स्वचालित रूप से
- स्वचालित
- औसत
- नीला
- Azure क्लाउड
- पृष्ठभूमि
- बैंकों
- आधार
- से पहले
- लाभ
- लाभ
- बिलिंग
- खंड
- पिन
- पुस्तकें
- सीमा
- टूट जाता है
- कार
- पत्ते
- कुछ
- अक्षर
- प्रभार
- आरोप लगाया
- सस्ता
- जाँच
- City
- वर्गीकरण
- बादल
- बादल का भंडारण
- कोड
- सामान्य
- कंपनियों
- कंपनी
- तुलना
- पूरी तरह से
- कंप्यूटर
- कंप्यूटर्स
- जुड़ा हुआ
- विचार करना
- कंसोल
- शामिल हैं
- सामग्री
- अंतर्वस्तु
- रूपांतरण
- निगमों
- इसी
- लागत
- सका
- देशों
- देश
- बनाना
- बनाया
- बनाना
- वर्तमान
- ग्राहक
- ग्राहक सहयोग
- ग्राहक
- तिथि
- डेटा विश्लेषण
- डेटा संसाधन
- डाटाबेस
- डेटाबेस
- दिन
- व्यवहार
- निर्णय
- गहरा
- निर्भर
- निर्भर करता है
- वर्णन
- बनाया गया
- विस्तृत
- विवरण
- पता चला
- निर्धारित करना
- विकसित
- विभिन्न
- मुश्किल
- प्रत्यक्ष
- सीधे
- विविधता
- डॉक्टरों
- दस्तावेजों
- डोमेन
- नीचे
- ड्राइव
- ड्राइविंग
- से प्रत्येक
- सहजता
- Edge
- प्रयास
- प्रयासों
- ईमेल
- उभरा
- सक्षम
- को प्रोत्साहित करती है
- उद्यम
- वातावरण
- विशेष रूप से
- अनिवार्य
- आदि
- उदाहरण
- निकास
- अर्क
- परिवारों
- फास्ट
- विशेषताएं
- प्रतिक्रिया
- फीस
- वित्त
- वित्तीय
- फर्म
- प्रथम
- तय
- लचीलापन
- केंद्रित
- का पालन करें
- निम्नलिखित
- प्रारूप
- रूपों
- पाया
- मुक्त
- से
- समारोह
- कार्यों
- आगे
- सामान्य जानकारी
- मिल रहा
- गूगल
- सरकारी
- सरकारों
- अधिक से अधिक
- संभालना
- मदद
- यहाँ उत्पन्न करें
- हाई
- उच्चतर
- अत्यधिक
- इतिहास
- अस्पतालों
- कैसे
- How To
- HTTPS
- मानव
- मनुष्य
- विचार
- की छवि
- छवियों
- महत्वपूर्ण
- असंभव
- में सुधार
- शामिल
- शामिल
- सहित
- व्यक्ति
- व्यक्तियों
- पता
- करें-
- उदाहरण
- सहज ज्ञान युक्त
- मुद्दों
- IT
- खुद
- जावा
- रखना
- कुंजी
- श्रम
- भाषा
- भाषाऐं
- बड़ा
- बड़ा
- सबसे बड़ा
- बिक्रीसूत्र
- सीख रहा हूँ
- स्तर
- स्तर
- पुस्तकालय
- लाइसेंस
- लाइसेंस
- जीवन शैली
- संभावित
- LINK
- स्थानीय
- स्थान
- स्थानों
- लंबा
- मशीन
- यंत्र अधिगम
- मशीनें
- प्रमुख
- बनाना
- ढंग
- मैन्युअल
- मैप्स
- निशान
- विशाल
- अर्थ
- सार्थक
- मेडिकल
- मध्यम
- उल्लेख किया
- तरीकों
- माइक्रोसॉफ्ट
- ML
- आदर्श
- मॉडल
- धन
- महीना
- अधिक
- अधिकांश
- चाल
- विभिन्न
- प्राकृतिक
- प्रकृति
- की जरूरत है
- नेटवर्क
- फिर भी
- नोट्स
- संख्या
- संख्या
- अनेक
- प्रस्तुत
- ऑफर
- सरकारी
- ऑफ़लाइन
- ऑनलाइन
- अनुकूलित
- विकल्प
- ऑप्शंस
- आदेश
- संगठित
- अन्य
- अपना
- पैक
- पार्किंग
- भाग
- विशेष
- विशेष रूप से
- पासिंग
- पीडीएफ
- स्टाफ़
- शायद
- योजनाओं
- मंच
- पुलिस
- लोकप्रिय
- शक्तिशाली
- मूल्य
- कीमत निर्धारण
- प्रक्रिया
- प्रक्रियाओं
- प्रसंस्करण
- उत्पादन
- उत्पाद
- परियोजना
- अनुमानों
- होनहार
- प्रचार
- प्रदान करना
- बशर्ते
- प्रदान करता है
- प्रदान कर
- खरीद
- गुणवत्ता
- जल्दी से
- रेंज
- लेकर
- RE
- पाठकों
- पढ़ना
- हाल
- पहचान
- अभिलेख
- के बारे में
- क्षेत्र
- दूरस्थ
- की आवश्यकता होती है
- अपेक्षित
- आवश्यकताएँ
- की आवश्यकता होती है
- अनुसंधान
- उपयुक्त संसाधन चुनें
- प्रतिक्रिया
- बाकी
- परिणाम
- सड़क
- भूमिका
- रन
- वही
- स्केलेबल
- स्केल
- स्कैन
- स्कैनिंग
- सेक्टर्स
- भावना
- कई
- सेवा
- सेवाएँ
- सेवारत
- सेट
- की स्थापना
- महत्वपूर्ण
- लक्षण
- समान
- सरल
- के बाद से
- छोटा
- So
- सॉफ्टवेयर
- ठोस
- समाधान
- कुछ
- विशिष्ट
- विशेष रूप से
- स्पिन
- चरणों
- शुरू
- बयान
- सांख्यिकीय
- आँकड़े
- भंडारण
- स्ट्रेटेजी
- सड़क
- संरचित
- समर्थन
- समर्थन करता है
- सर्वेक्षण
- शर्तों
- RSI
- इसलिये
- यहाँ
- भर
- पहर
- बार
- आज
- की ओर
- परंपरागत
- यातायात
- प्रशिक्षण
- स्थानांतरित कर रहा है
- बदलने
- प्रकार
- के अंतर्गत
- समझना
- समझ
- इकाइयों
- सार्वभौम
- उपयोग
- उपयोगकर्ताओं
- आमतौर पर
- विभिन्न
- दृष्टि
- आयतन
- घड़ी
- या
- जब
- कौन
- व्यापक
- खिड़कियां
- अंदर
- शब्द
- काम
- कार्य
- होगा
- X
- वर्ष
- आपका