अपाचे हुडी एक खुला तालिका प्रारूप है जो डेटाबेस और डेटा वेयरहाउस क्षमताओं को डेटा लेक में लाता है। अपाचे हुडी डेटा इंजीनियरों को जटिल चुनौतियों का प्रबंधन करने में मदद करता है, जैसे क्वेरी प्रदर्शन को बनाए रखते हुए लेनदेन के साथ लगातार विकसित होने वाले डेटासेट का प्रबंधन करना। डेटा इंजीनियर वर्कलोड स्ट्रीमिंग के साथ-साथ कुशल वृद्धिशील डेटा पाइपलाइन बनाने के लिए अपाचे हुडी का उपयोग करते हैं। हुडी प्रदान करता है टेबल, लेनदेन, कुशल अप्सर्ट और डिलीट, उन्नत सूचकांक, स्ट्रीमिंग अंतर्ग्रहण सेवाएं, डेटा गुच्छन और संघनन अनुकूलन, और समरूपता नियंत्रण, यह सब आपके डेटा को ओपन सोर्स फ़ाइल स्वरूपों में रखते हुए। हुडी के उन्नत प्रदर्शन अनुकूलन अपाचे स्पार्क, प्रेस्टो, ट्रिनो, हाइव इत्यादि सहित किसी भी लोकप्रिय क्वेरी इंजन के साथ विश्लेषणात्मक कार्यभार को तेज़ बनाते हैं।
कई AWS ग्राहकों ने Amazon S3 के शीर्ष पर निर्मित अपने डेटा लेक पर Apache Hudi को अपनाया एडब्ल्यूएस गोंद, एक सर्वर रहित डेटा एकीकरण सेवा जो एनालिटिक्स, मशीन लर्निंग (एमएल) और एप्लिकेशन डेवलपमेंट के लिए कई स्रोतों से डेटा को खोजना, तैयार करना, स्थानांतरित करना और एकीकृत करना आसान बनाती है। एडब्ल्यूएस गोंद क्रॉलर AWS ग्लू का एक घटक है, जो आपको मेटाडेटा की मैन्युअल परिभाषा की आवश्यकता के बिना स्वचालित रूप से डेटा सामग्री से तालिका मेटाडेटा बनाने की अनुमति देता है।
AWS ग्लू क्रॉलर अब Apache Hudi टेबल का समर्थन करते हैं, अपनाने को सरल बनाना एडब्ल्यूएस गोंद डेटा कैटलॉग हुडी तालिकाओं के लिए कैटलॉग के रूप में। एक सामान्य उपयोग मामला हुडी तालिकाओं को पंजीकृत करना है, जिसमें कैटलॉग तालिका परिभाषा नहीं है। एक अन्य विशिष्ट उपयोग का मामला अन्य हुडी कैटलॉग से माइग्रेशन है, जैसे हाइव मेटास्टोर। अन्य Hudi कैटलॉग से माइग्रेट करते समय, आप AWS ग्लू क्रॉलर बना और शेड्यूल कर सकते हैं और एक या अधिक Amazon S3 पथ प्रदान कर सकते हैं जहां Hudi तालिका फ़ाइलें स्थित हैं। आपके पास Amazon S3 पथों की अधिकतम गहराई प्रदान करने का विकल्प है जिसे AWS ग्लू क्रॉलर पार कर सकता है। प्रत्येक रन के साथ, AWS ग्लू क्रॉलर स्कीमा और विभाजन की जानकारी निकालेंगे और स्कीमा और विभाजन परिवर्तनों के साथ AWS ग्लू डेटा कैटलॉग को अपडेट करेंगे। AWS ग्लू क्रॉलर AWS ग्लू डेटा कैटलॉग में नवीनतम मेटाडेटा फ़ाइल स्थान को अपडेट करता है जिसे AWS विश्लेषणात्मक इंजन सीधे उपयोग कर सकते हैं।
इस लॉन्च के साथ, आप AWS ग्लू डेटा कैटलॉग में Hudi तालिकाओं को पंजीकृत करने के लिए AWS ग्लू क्रॉलर बना और शेड्यूल कर सकते हैं। फिर आप एक या एकाधिक अमेज़ॅन एस3 पथ प्रदान कर सकते हैं जहां हुडी टेबल स्थित हैं। आपके पास Amazon S3 पथों की अधिकतम गहराई प्रदान करने का विकल्प है जिसे क्रॉलर पार कर सकते हैं। प्रत्येक क्रॉलर रन के साथ, क्रॉलर प्रत्येक S3 पथ का निरीक्षण करता है और स्कीमा जानकारी को सूचीबद्ध करता है, जैसे कि नई तालिकाएँ, डिलीट और AWS ग्लू डेटा कैटलॉग में स्कीमा के अपडेट। क्रॉलर विभाजन जानकारी का निरीक्षण करते हैं और AWS ग्लू डेटा कैटलॉग में नए जोड़े गए विभाजन जोड़ते हैं। क्रॉलर AWS ग्लू डेटा कैटलॉग में नवीनतम मेटाडेटा फ़ाइल स्थान को भी अपडेट करते हैं जिसे AWS विश्लेषणात्मक इंजन सीधे उपयोग कर सकते हैं।
यह पोस्ट दर्शाती है कि हुडी तालिकाओं को क्रॉल करने की यह नई क्षमता कैसे काम करती है।
AWS ग्लू क्रॉलर हुडी टेबल के साथ कैसे काम करता है
हुडी तालिकाओं की दो श्रेणियां हैं, जिनमें से प्रत्येक के लिए विशिष्ट निहितार्थ हैं:
- लिखने पर प्रतिलिपि (CoW) - डेटा को एक स्तंभ प्रारूप (Parquet) में संग्रहीत किया जाता है, और प्रत्येक अद्यतन लिखने के दौरान फ़ाइलों का एक नया संस्करण बनाता है।
- पढ़ने पर मर्ज (एमओआर) - डेटा को स्तंभ (लकड़ी की छत) और पंक्ति-आधारित (एवरो) प्रारूपों के संयोजन का उपयोग करके संग्रहीत किया जाता है। अद्यतनों को पंक्ति-आधारित पर लॉग किया जाता है
deltaफ़ाइलें और स्तंभ फ़ाइलों के नए संस्करण बनाने के लिए आवश्यकतानुसार संकुचित की जाती हैं।
CoW डेटासेट के साथ, हर बार जब किसी रिकॉर्ड में कोई अपडेट होता है, तो रिकॉर्ड वाली फ़ाइल को अपडेट किए गए मानों के साथ फिर से लिखा जाता है। MoR डेटासेट के साथ, हर बार जब कोई अपडेट होता है, तो हुडी बदले हुए रिकॉर्ड के लिए केवल पंक्ति लिखता है। एमओआर कम पढ़ने वाले लेखन-या परिवर्तन-भारी कार्यभार के लिए बेहतर अनुकूल है। CoW डेटा पर रीड-हेवी वर्कलोड के लिए बेहतर अनुकूल है जो कम बार बदलता है।
हुडी डेटा तक पहुँचने के लिए तीन क्वेरी प्रकार प्रदान करता है:
- स्नैपशॉट प्रश्न - क्वेरीज़ जो किसी दिए गए कमिट या कॉम्पैक्शन एक्शन के रूप में तालिका का नवीनतम स्नैपशॉट देखती हैं। एमओआर तालिकाओं के लिए, स्नैपशॉट क्वेरीज़ क्वेरी के समय नवीनतम फ़ाइल स्लाइस की आधार और डेल्टा फ़ाइलों को मर्ज करके तालिका की नवीनतम स्थिति को उजागर करती हैं।
- वृद्धिशील प्रश्न - क्वेरीज़ केवल किसी दिए गए कमिट या कॉम्पैक्शन के बाद से तालिका में लिखा गया नया डेटा देखती हैं। यह वृद्धिशील डेटा पाइपलाइनों को सक्षम करने के लिए प्रभावी रूप से परिवर्तन स्ट्रीम प्रदान करता है।
- अनुकूलित क्वेरीज़ पढ़ें - एमओआर तालिकाओं के लिए, क्वेरीज़ नवीनतम डेटा को संकलित देखती हैं। CoW तालिकाओं के लिए, क्वेरीज़ प्रतिबद्ध नवीनतम डेटा देखती हैं।
कॉपी-ऑन-राइट टेबल के लिए, क्रॉलर रीडऑप्टिमाइज़्ड सर्ड के साथ AWS ग्लू डेटा कैटलॉग में एक एकल टेबल बनाते हैं org.apache.hudi.hadoop.HoodieParquetInputFormat.
मर्ज-ऑन-रीड टेबल के लिए, क्रॉलर एक ही टेबल स्थान के लिए AWS ग्लू डेटा कैटलॉग में दो टेबल बनाते हैं:
- प्रत्यय के साथ एक तालिका
_ro, जो रीडऑप्टिमाइज्ड सर्ड का उपयोग करता हैorg.apache.hudi.hadoop.HoodieParquetInputFormat - प्रत्यय के साथ एक तालिका
_rt, जो स्नैपशॉट क्वेरी के लिए रीयलटाइम सर्डे का उपयोग करता है:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
प्रत्येक क्रॉल के दौरान, प्रदान किए गए प्रत्येक हुडी पथ के लिए, क्रॉलर अमेज़ॅन एस3 सूची एपीआई कॉल करते हैं, जिसके आधार पर फ़िल्टर किया जाता है .hoodie फ़ोल्डर, और उस Hudi तालिका मेटाडेटा फ़ोल्डर के अंतर्गत नवीनतम मेटाडेटा फ़ाइल ढूंढें।
AWS ग्लू क्रॉलर का उपयोग करके Hudi CoW तालिका को क्रॉल करें
इस अनुभाग में, आइए जानें कि AWS ग्लू क्रॉलर का उपयोग करके हुडी गाय को कैसे क्रॉल किया जाए।
.. पूर्वापेक्षाएँ
यहां इस ट्यूटोरियल के लिए आवश्यक शर्तें दी गई हैं:
- स्थापित करें और कॉन्फ़िगर करें AWS कमांड लाइन इंटरफ़ेस (AWS CLI).
- यदि आपके पास S3 बकेट नहीं है तो उसे बनाएँ।
- AWS ग्लू के लिए अपनी IAM भूमिका बनाएँ यदि आपके पास यह नहीं है. आप की जरूरत है
s3:GetObjectएसटीs3://your_s3_bucket/data/sample_hudi_cow_table/. - नमूना हुडी तालिका को अपने S3 बकेट में कॉपी करने के लिए निम्नलिखित कमांड चलाएँ। (प्रतिस्थापित करें
your_s3_bucketआपके S3 बकेट नाम के साथ।)
यह निर्देश आपको नमूना डेटा कॉपी करने के लिए मार्गदर्शन करता है, लेकिन आप AWS ग्लू का उपयोग करके आसानी से कोई भी हुडी टेबल बना सकते हैं। में और जानें पेश है Apache Hudi, Delta Lake, और Apache Iceberg के लिए Apache Spark के लिए AWS Glue पर मूल समर्थन, भाग 2: AWS Glue Studio Visual Editor.
एक हुडी क्रॉलर बनाएं
इस निर्देश में, कंसोल के माध्यम से क्रॉलर बनाएं। हुडी क्रॉलर बनाने के लिए निम्नलिखित चरणों को पूरा करें:
- एडब्ल्यूएस गोंद कंसोल पर, चुनें क्रौलर.
- चुनें क्रॉलर बनाएं.
- के लिए नाम, दर्ज
hudi_cow_crawler। चुनना अगला. - के अंतर्गत डेटा स्रोत कॉन्फ़िगरेशन, चुनना डेटा स्रोत जोड़ें.
- के लिए डेटा स्रोत, चुनें Hudl.
- के लिए हुडी टेबल पथ शामिल करें, दर्ज
s3://your_s3_bucket/data/sample_hudi_cow_table/. (बदलनाyour_s3_bucketआपके S3 बकेट नाम के साथ।) - चुनें हुडी डेटा स्रोत जोड़ें.
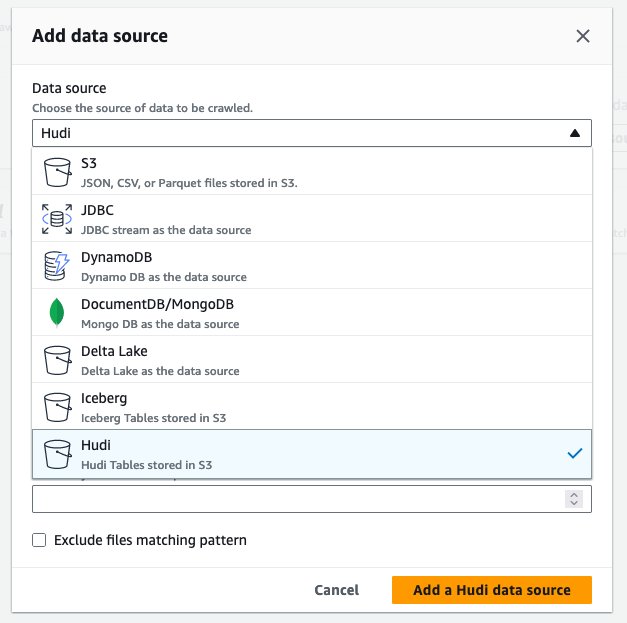
- चुनें अगला.
- के लिए मौजूदा आईएएम भूमिका, अपनी IAM भूमिका चुनें, फिर चुनें अगला.
- के लिए लक्ष्य डेटाबेस, चुनें डेटाबेस जोड़ें, फिर डेटाबेस जोड़ें संवाद प्रकट होता है। के लिए डेटाबेस नाम, दर्ज
hudi_crawler_blog, उसके बाद चुनो बनाएं। चुनना अगला. - चुनें क्रॉलर बनाएं.
अब एक नया हुडी क्रॉलर सफलतापूर्वक बनाया गया है। क्रॉलर को कंसोल के माध्यम से या एसडीके या एडब्ल्यूएस सीएलआई के माध्यम से चलाने के लिए ट्रिगर किया जा सकता है StartCrawl एपीआई। क्रॉलर्स को विशिष्ट समय पर ट्रिगर करने के लिए इसे कंसोल के माध्यम से भी शेड्यूल किया जा सकता है। इस निर्देश में, क्रॉलर को कंसोल के ज़रिए चलाएं.
- चुनें क्रॉलर चलाएं.
- क्रॉलर के पूरा होने की प्रतीक्षा करें।
क्रॉलर चलने के बाद, आप AWS ग्लू कंसोल में हुडी तालिका परिभाषा देख सकते हैं:
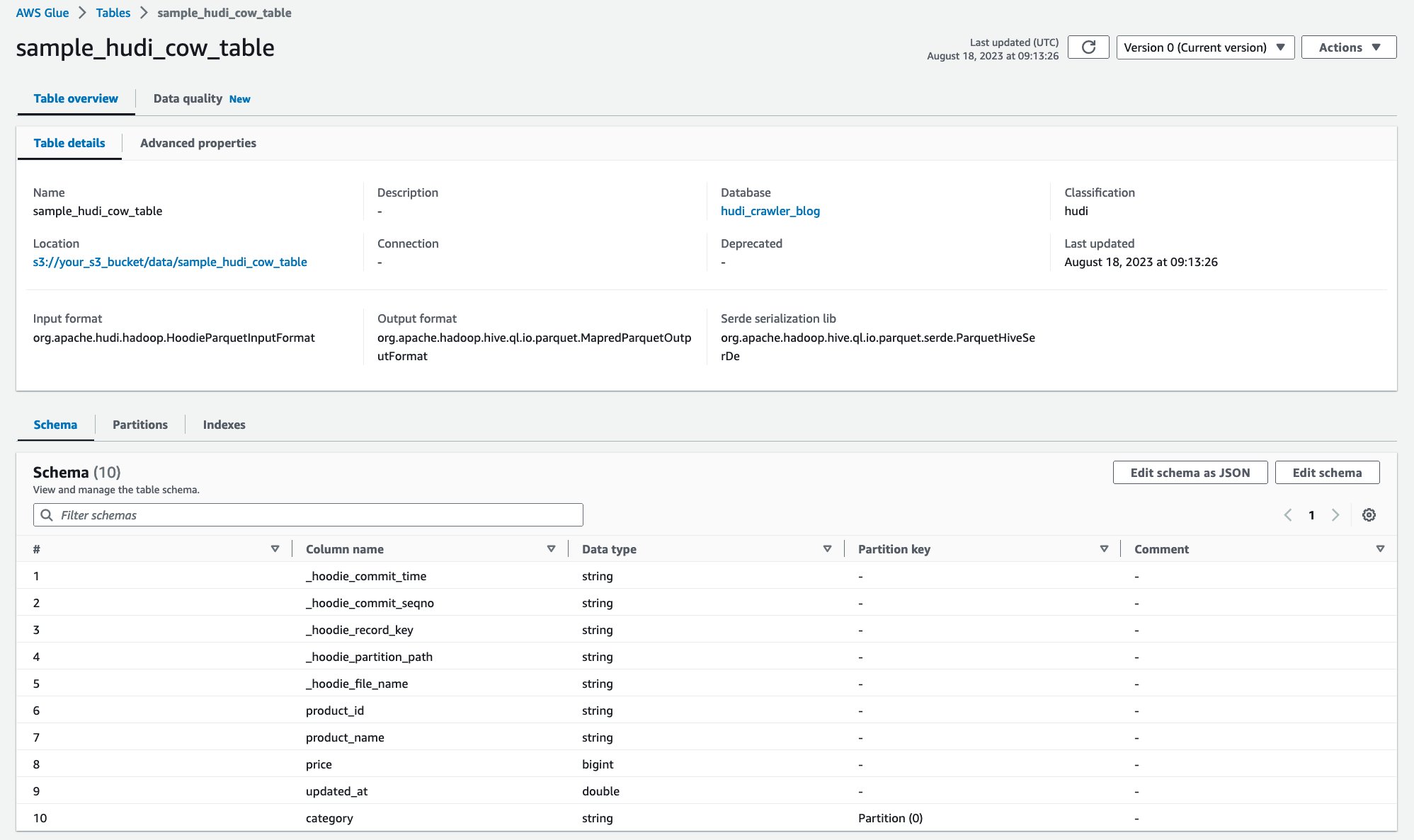
आपने Amazon S3 पर डेटा के साथ Hudi CoR टेबल को सफलतापूर्वक क्रॉल किया है और स्कीमा पॉपुलेटेड के साथ AWS ग्लू डेटा कैटलॉग टेबल बनाई है। आपके द्वारा AWS ग्लू डेटा कैटलॉग पर तालिका परिभाषा बनाने के बाद, Amazon Athena जैसी AWS एनालिटिक्स सेवाएँ Hudi तालिका को क्वेरी करने में सक्षम हैं।
एथेना पर प्रश्न पूछने के लिए निम्नलिखित चरणों को पूरा करें:
- अमेज़न एथेना कंसोल खोलें।
- निम्न क्वेरी चलाएँ।
निम्न स्क्रीनशॉट हमारे आउटपुट को दिखाता है:
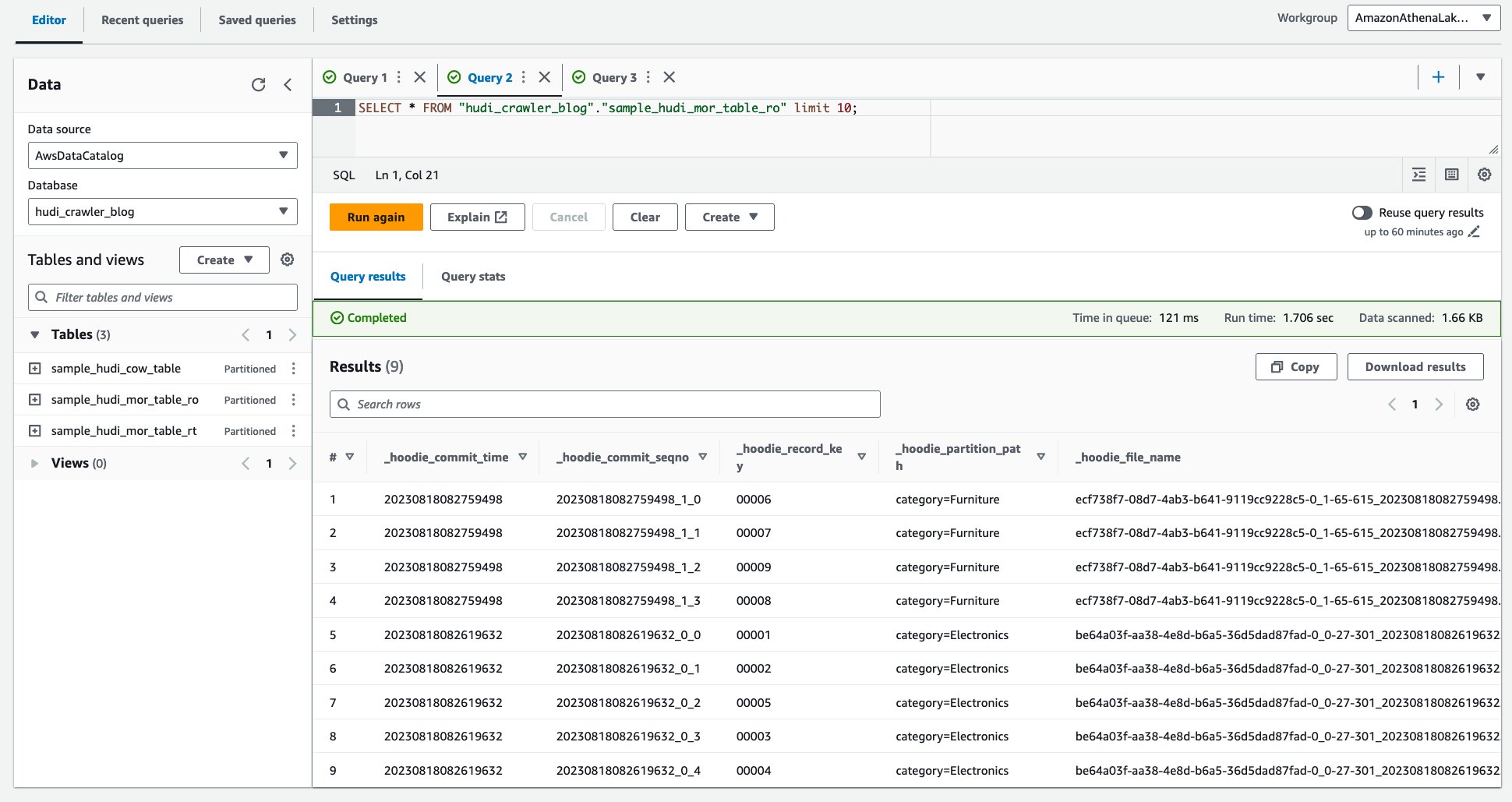
AWS लेक फॉर्मेशन डेटा अनुमतियों के साथ AWS ग्लू क्रॉलर का उपयोग करके हुडी MoR तालिका को क्रॉल करें
इस अनुभाग में, आइए देखें कि AWS ग्लू का उपयोग करके हुडी MoR तालिका को कैसे क्रॉल किया जाए। इस बार, आप IAM और Amazon S3 अनुमति के बजाय Amazon S3 डेटा स्रोतों को क्रॉल करने के लिए AWS लेक फॉर्मेशन डेटा अनुमति का उपयोग करते हैं। यह वैकल्पिक है, लेकिन जब आपका डेटा लेक AWS लेक फॉर्मेशन अनुमतियों द्वारा प्रबंधित किया जाता है तो यह अनुमति कॉन्फ़िगरेशन को सरल बनाता है।
.. पूर्वापेक्षाएँ
यहां इस ट्यूटोरियल के लिए आवश्यक शर्तें दी गई हैं:
- स्थापित करें और कॉन्फ़िगर करें AWS कमांड लाइन इंटरफ़ेस (AWS CLI).
- यदि आपके पास S3 बकेट नहीं है तो उसे बनाएँ।
- AWS ग्लू के लिए अपनी IAM भूमिका बनाएँ यदि आपके पास यह नहीं है. आप की जरूरत है
lakeformation:GetDataAccess. लेकिन आपको जरूरत नहीं हैs3:GetObjectएसटीs3://your_s3_bucket/data/sample_hudi_mor_table/क्योंकि हम फ़ाइलों तक पहुँचने के लिए लेक फॉर्मेशन डेटा अनुमति का उपयोग करते हैं। - नमूना हुडी तालिका को अपने S3 बकेट में कॉपी करने के लिए निम्नलिखित कमांड चलाएँ। (प्रतिस्थापित करें
your_s3_bucketआपके S3 बकेट नाम के साथ।)
प्रसंस्करण चरणों के अलावा, IAM-आधारित पहुंच नियंत्रण के बजाय कैटलॉग संसाधनों को नियंत्रित करने के लिए लेक फॉर्मेशन अनुमतियों का उपयोग करने के लिए AWS ग्लू डेटा कैटलॉग सेटिंग्स को अपडेट करने के लिए निम्नलिखित चरणों को पूरा करें:
- डेटा लेक प्रशासक के रूप में लेक फॉर्मेशन कंसोल में साइन इन करें।
- यदि आप पहली बार लेक फॉर्मेशन कंसोल तक पहुंच रहे हैं, स्वयं को डेटा लेक प्रशासक के रूप में जोड़ें।
- के अंतर्गत प्रशासन, चुनें डेटा कैटलॉग सेटिंग्स.
- के लिए नव निर्मित डेटाबेस और तालिकाओं के लिए डिफ़ॉल्ट अनुमतियाँ, चयन रद्द करें नए डेटाबेस के लिए केवल IAM अभिगम नियंत्रण का उपयोग करें और नए डेटाबेस में नई तालिकाओं के लिए केवल IAM अभिगम नियंत्रण का उपयोग करें.
- के लिए क्रॉस खाता संस्करण सेटिंग, चुनें संस्करण 3.
- चुनें सहेजें.
अगला कदम अपने S3 बकेट को लेक फॉर्मेशन डेटा लेक स्थानों में पंजीकृत करना है:
- लेक फॉर्मेशन कंसोल पर, चुनें डेटा लेक लोकेशन, और चुनें स्थान रजिस्टर करें.
- के लिए अमेज़न S3 पथ, दर्ज
s3://your_s3_bucket/. (प्रतिस्थापित करेंyour_s3_bucketआपके S3 बकेट नाम के साथ।) - चुनें स्थान रजिस्टर करें.
फिर, ग्लू क्रॉलर भूमिका को डेटा स्थान तक पहुंच प्रदान करें ताकि क्रॉलर डेटा तक पहुंचने और स्थान में तालिकाएं बनाने के लिए लेक फॉर्मेशन अनुमति का उपयोग कर सके:
- लेक फॉर्मेशन कंसोल पर, चुनें डेटा स्थान और चुनें अनुदान.
- के लिए IAM उपयोगकर्ता और भूमिकाएँ, उस IAM भूमिका का चयन करें जिसका उपयोग आपने क्रॉलर के लिए किया था।
- के लिए भंडारण स्थान, दर्ज
s3://your_s3_bucket/data/. (प्रतिस्थापित करेंyour_s3_bucketआपके S3 बकेट नाम के साथ।) - चुनें अनुदान.
फिर, डेटाबेस के अंतर्गत तालिकाएँ बनाने के लिए क्रॉलर भूमिका प्रदान करें hudi_crawler_blog:
- लेक फॉर्मेशन कंसोल पर, चुनें डेटा लेक अनुमतियाँ.
- चुनें अनुदान.
- के लिए प्रधानाध्यापकों, चुनें IAM उपयोगकर्ता और भूमिकाएँ, और क्रॉलर भूमिका चुनें।
- के लिए एलएफ टैग या कैटलॉग संसाधन, चुनें नामित डेटा कैटलॉग संसाधन.
- के लिए डाटाबेस, डेटाबेस चुनें
hudi_crawler_blog. - के अंतर्गत डेटाबेस अनुमतियाँ, चुनते हैं तालिका बनाएं.
- चुनें अनुदान.
लेक फॉर्मेशन डेटा अनुमतियों के साथ एक हुडी क्रॉलर बनाएं
हुडी क्रॉलर बनाने के लिए निम्नलिखित चरणों को पूरा करें:
- एडब्ल्यूएस गोंद कंसोल पर, चुनें क्रौलर.
- चुनें क्रॉलर बनाएं.
- के लिए नाम, दर्ज
hudi_mor_crawler। चुनना अगला. - के अंतर्गत डेटा स्रोत कॉन्फ़िगरेशन, चुनना डेटा स्रोत जोड़ें.
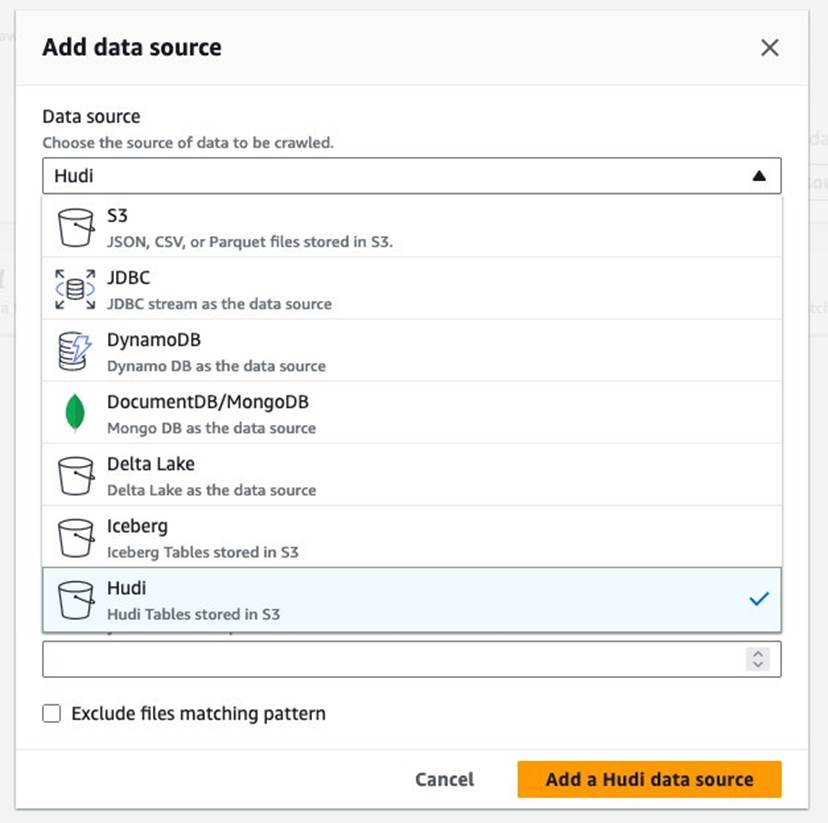
- के लिए डेटा स्रोत, चुनें Hudl.
- के लिए हुडी टेबल पथ शामिल करें, दर्ज
s3://your_s3_bucket/data/sample_hudi_mor_table/. (प्रतिस्थापित करेंyour_s3_bucketआपके S3 बकेट नाम के साथ।) - चुनें हुडी डेटा स्रोत जोड़ें.
- चुनें अगला.
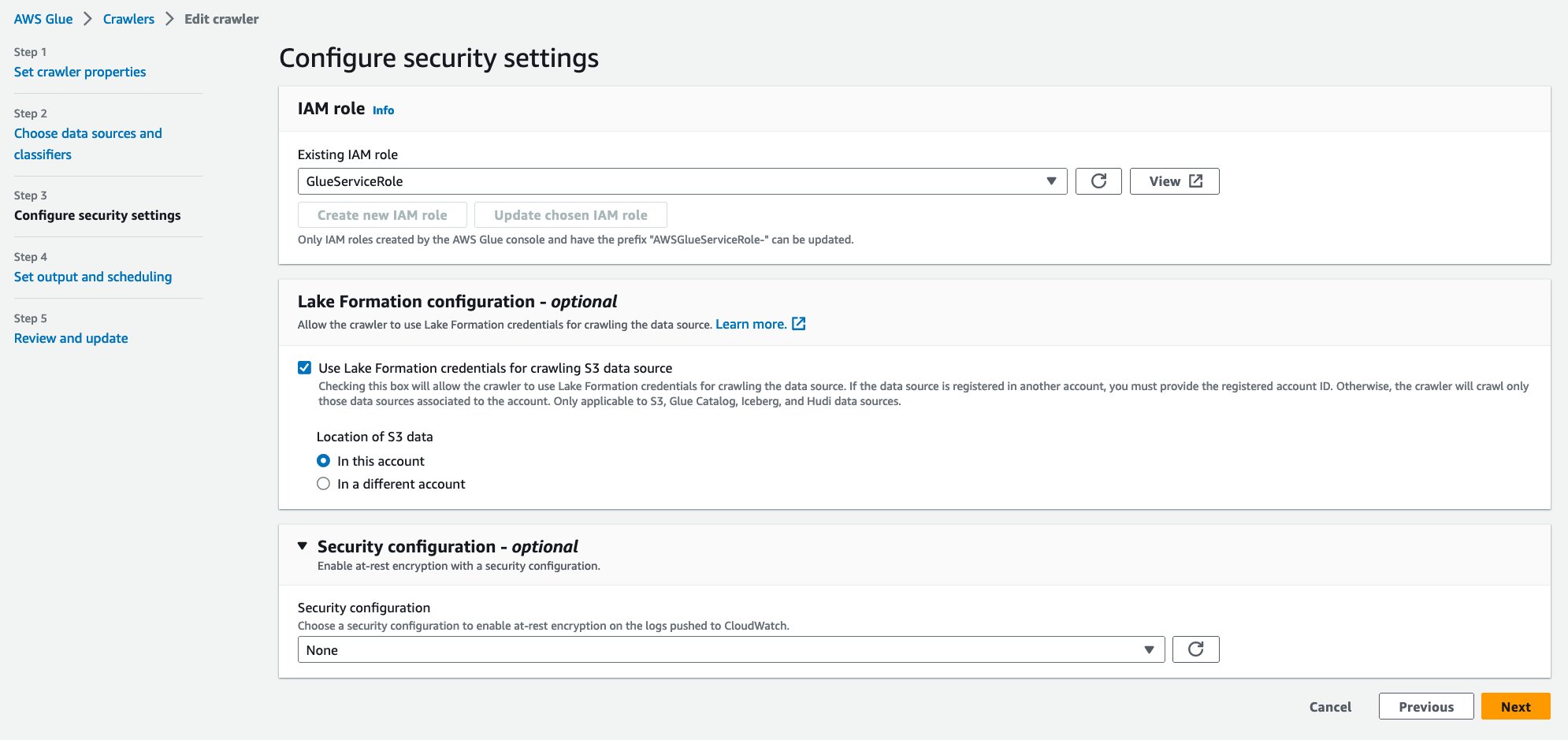
- के लिए मौजूदा आईएएम भूमिका, अपनी IAM भूमिका चुनें।
- के अंतर्गत झील निर्माण विन्यास - वैकल्पिक, चुनते हैं S3 डेटा स्रोत को क्रॉल करने के लिए लेक फॉर्मेशन क्रेडेंशियल्स का उपयोग करें.
- चुनें अगला.
- के लिए लक्ष्य डेटाबेस, चुनें
hudi_crawler_blog। चुनना अगला. - चुनें क्रॉलर बनाएं.
अब एक नया हुडी क्रॉलर सफलतापूर्वक बनाया गया है। क्रॉलर Amazon S3 फ़ाइलों को क्रॉल करने के लिए लेक फॉर्मेशन क्रेडेंशियल्स का उपयोग करता है। आइए नया क्रॉलर चलाएँ:
- चुनें क्रॉलर चलाएं.
- क्रॉलर के पूरा होने की प्रतीक्षा करें।
क्रॉलर चलने के बाद, आप AWS ग्लू कंसोल में हुडी तालिका परिभाषा की दो तालिकाएँ देख सकते हैं:
sample_hudi_mor_table_ro(अनुकूलित तालिका पढ़ें)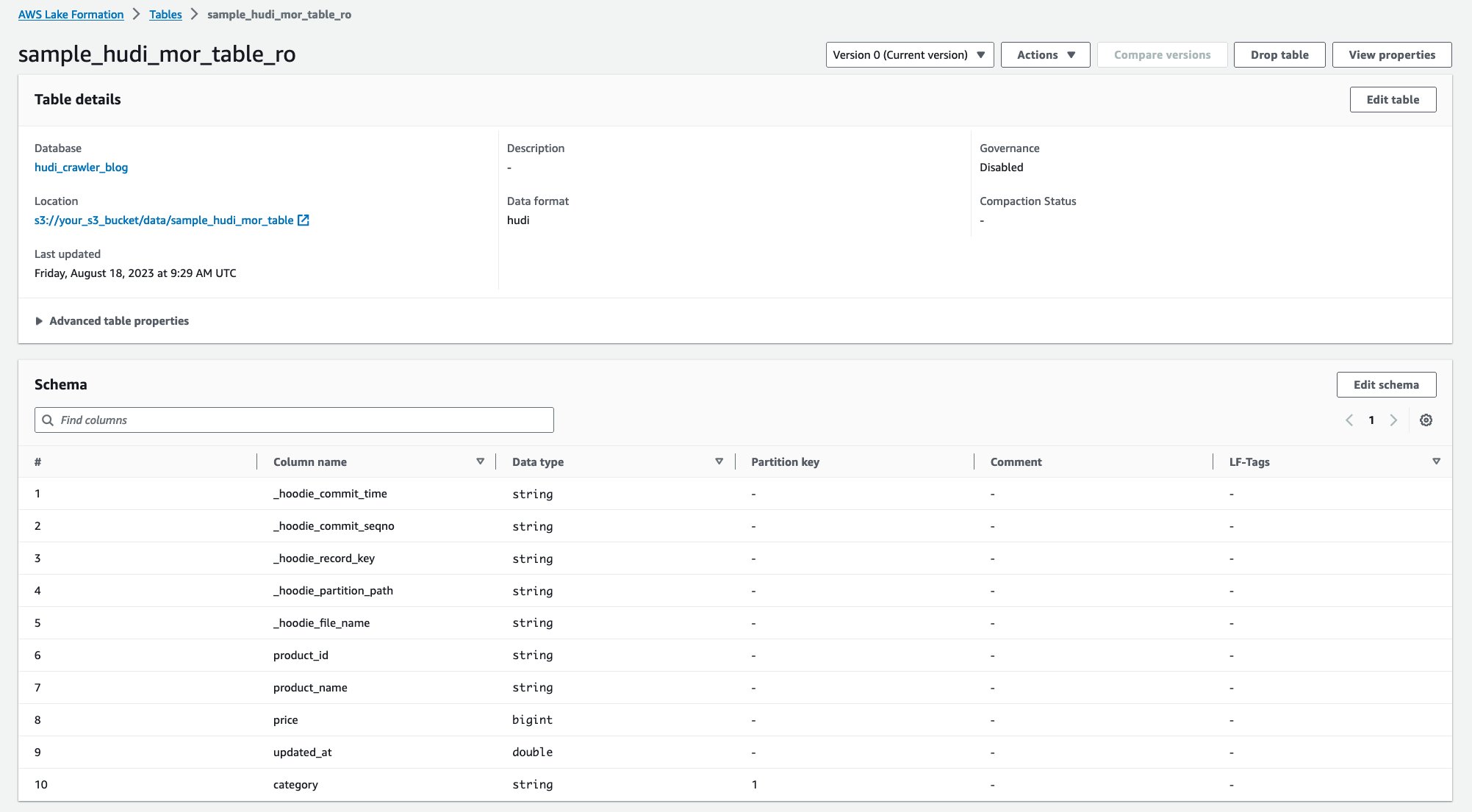
sample_hudi_mor_table_rt(वास्तविक समय सारणी)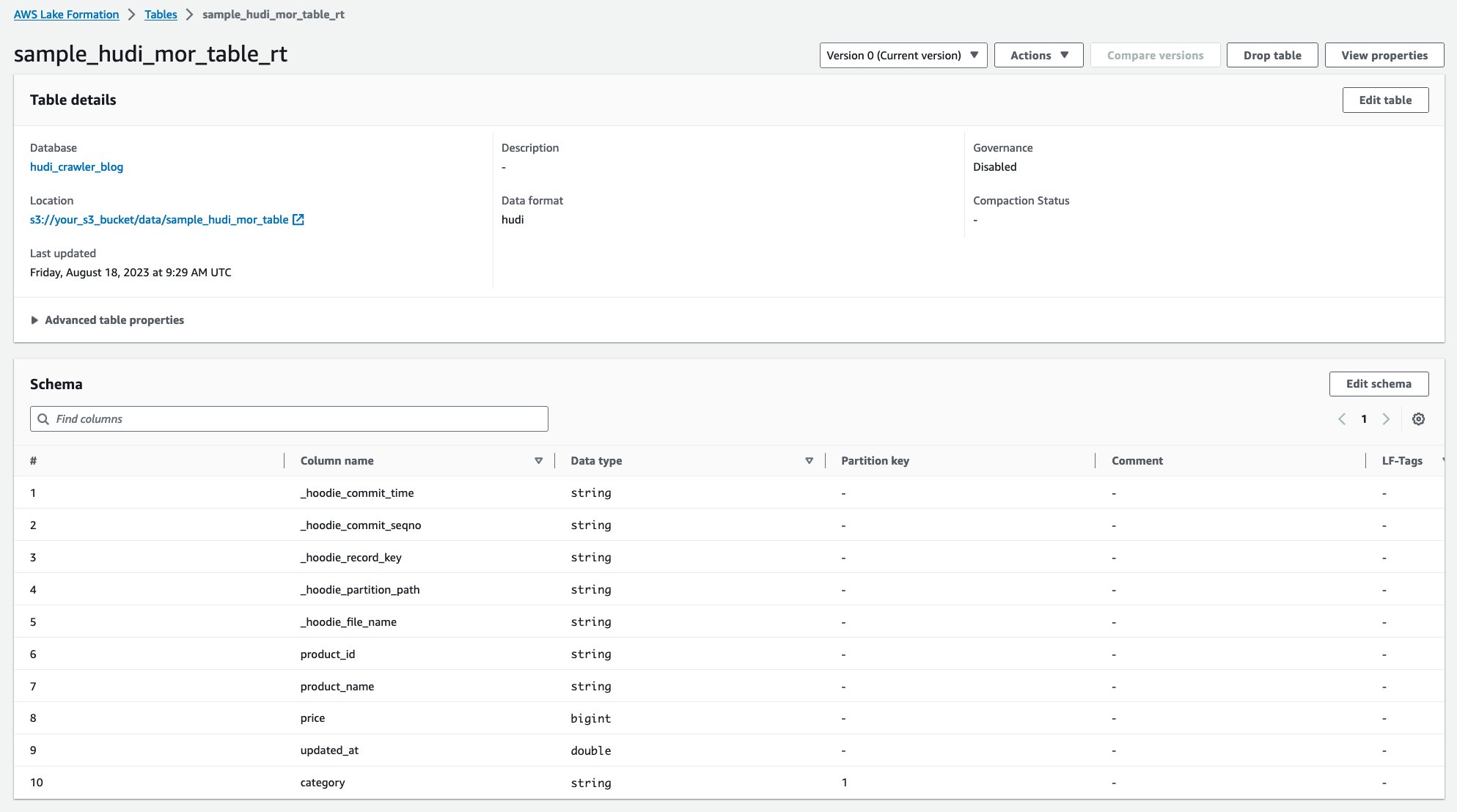
आपने डेटा लेक बकेट को लेक फ़ॉर्मेशन के साथ पंजीकृत किया और लेक फ़ॉर्मेशन अनुमतियों का उपयोग करके डेटा लेक तक क्रॉलिंग एक्सेस सक्षम किया। आपने Amazon S3 पर डेटा के साथ Hudi MoR तालिका को सफलतापूर्वक क्रॉल किया है और स्कीमा पॉपुलेटेड के साथ AWS ग्लू डेटा कैटलॉग तालिका बनाई है। आपके द्वारा AWS ग्लू डेटा कैटलॉग पर तालिका परिभाषाएँ बनाने के बाद, AWS एनालिटिक्स सेवाएँ जैसे Amazon Athena, Hudi तालिका को क्वेरी करने में सक्षम हैं।
एथेना पर प्रश्न पूछने के लिए निम्नलिखित चरणों को पूरा करें:
- अमेज़न एथेना कंसोल खोलें।
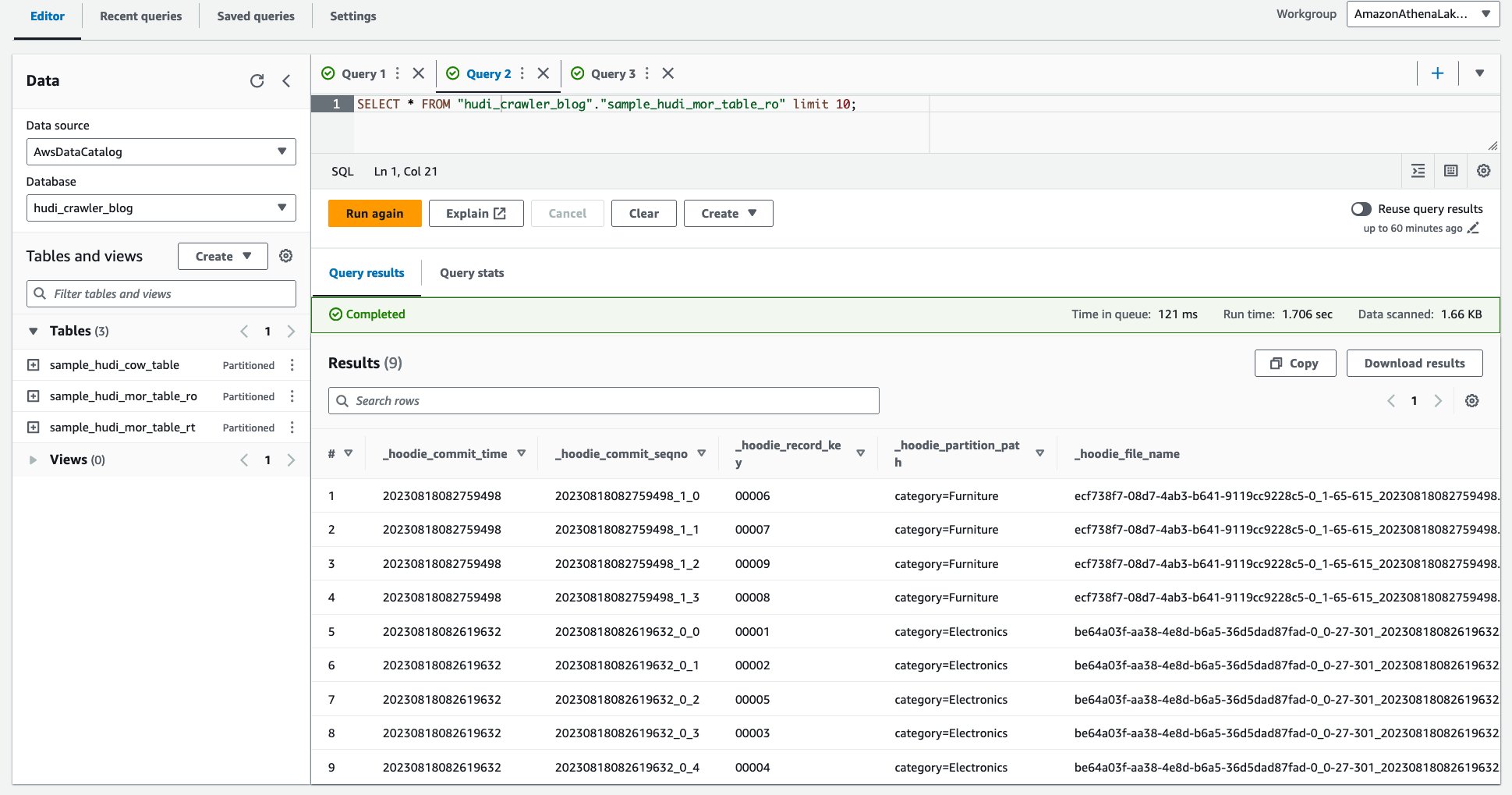
- निम्न क्वेरी चलाएँ।
निम्न स्क्रीनशॉट हमारे आउटपुट को दिखाता है:
- निम्न क्वेरी चलाएँ।
निम्न स्क्रीनशॉट हमारे आउटपुट को दिखाता है:
AWS लेक फॉर्मेशन अनुमतियों का उपयोग करके सूक्ष्म अभिगम नियंत्रण
हुडी टेबल पर बारीक पहुंच नियंत्रण लागू करने के लिए, आप AWS लेक फॉर्मेशन अनुमतियों से लाभ उठा सकते हैं। लेक फॉर्मेशन अनुमतियाँ आपको विशिष्ट तालिकाओं, स्तंभों या पंक्तियों तक पहुंच को प्रतिबंधित करने की अनुमति देती हैं और फिर बढ़िया पहुंच नियंत्रण के साथ अमेज़ॅन एथेना के माध्यम से हुडी तालिकाओं को क्वेरी करती हैं। आइए हुडी एमओआर तालिका के लिए झील निर्माण अनुमति को कॉन्फ़िगर करें।
.. पूर्वापेक्षाएँ
यहां इस ट्यूटोरियल के लिए आवश्यक शर्तें दी गई हैं:
- पिछला भाग पूरा करें AWS लेक फॉर्मेशन डेटा अनुमतियों के साथ AWS ग्लू क्रॉलर का उपयोग करके हुडी MoR तालिका को क्रॉल करें.
- एक IAM उपयोगकर्ता डेटा विश्लेषक बनाएं, जिसके पास AWS प्रबंधित नीति हो अमेज़ॅनएथेनाफुलएक्सेस.
लेक फॉर्मेशन डेटा सेल फ़िल्टर बनाएं
आइए सबसे पहले MoR रीड अनुकूलित तालिका के लिए एक फ़िल्टर सेट करें।
- डेटा लेक प्रशासक के रूप में लेक फॉर्मेशन कंसोल में साइन इन करें।
- चुनें डेटा फ़िल्टर.
- चुनें नया फ़िल्टर बनाएं.
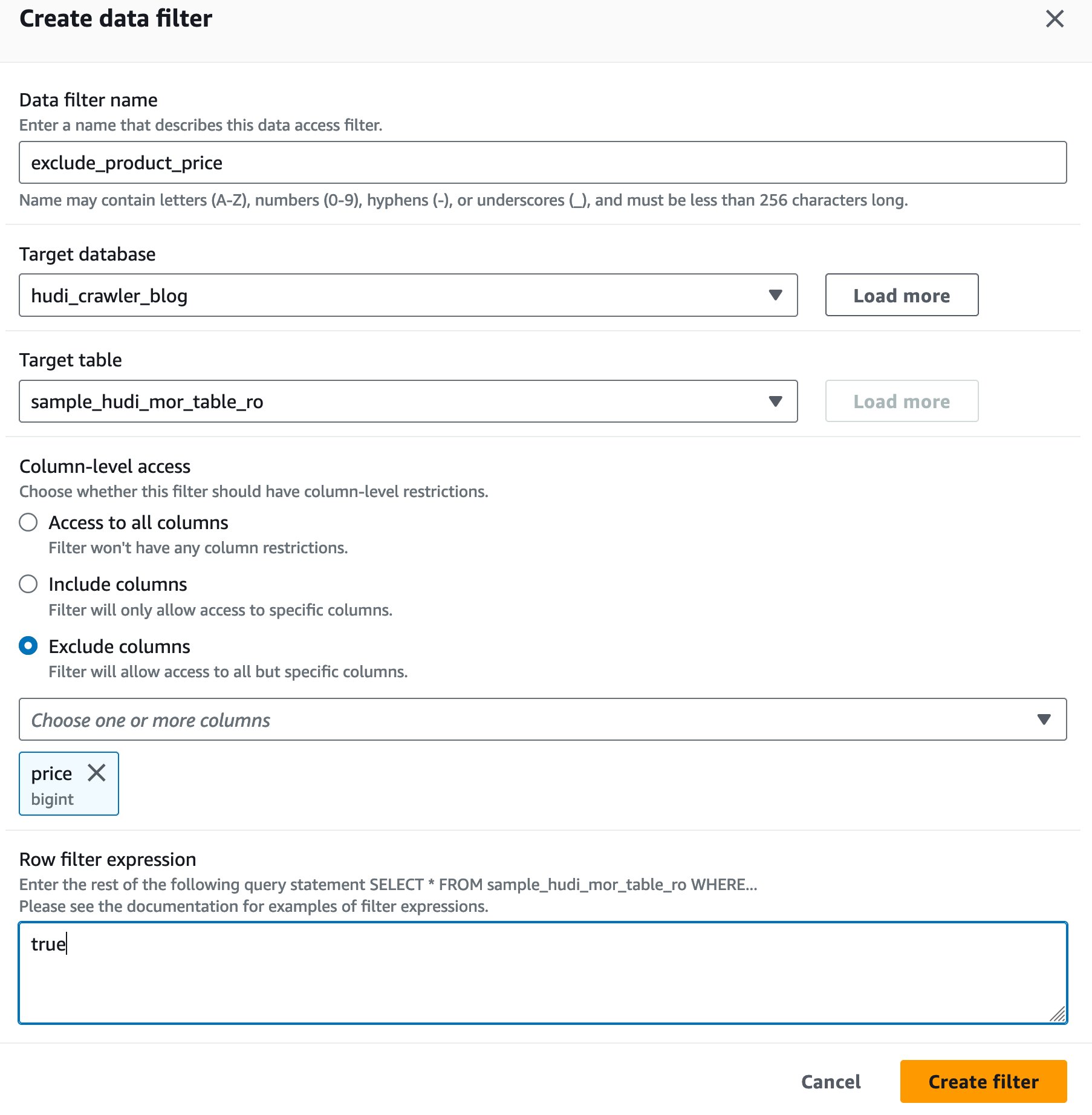
- के लिए डेटा फ़िल्टर नाम, दर्ज
exclude_product_price. - के लिए लक्ष्य डेटाबेस, डेटाबेस चुनें
hudi_crawler_blog. - के लिए लक्ष्य तालिका, टेबल चुनें
sample_hudi_mor_table_ro. - के लिए कॉलम स्तरीय पहुँच, चयन करें कॉलम बहिष्कृत करें, और कॉलम मूल्य चुनें।
- के लिए पंक्ति फ़िल्टर अभिव्यक्ति, दर्ज
true. - चुनें फ़िल्टर बनाएं.
डेटाएनालिस्ट उपयोगकर्ता को लेक फ़ॉर्मेशन अनुमतियाँ प्रदान करें
झील निर्माण की अनुमति देने के लिए निम्नलिखित चरणों को पूरा करें DataAnalyst उपयोगकर्ता
- लेक फॉर्मेशन कंसोल पर, चुनें डेटा लेक अनुमतियाँ.
- चुनें अनुदान.
- के लिए प्रधानाध्यापकों, चुनें IAM उपयोगकर्ता और भूमिकाएँ, और उपयोगकर्ता चुनें
DataAnalyst. - के लिए एलएफ टैग या कैटलॉग संसाधन, चुनें नामित डेटा कैटलॉग संसाधन.
- के लिए डाटाबेस, डेटाबेस चुनें
hudi_crawler_blog. - के लिए तालिका - वैकल्पिक, टेबल चुनें
sample_hudi_mor_table_ro. - के लिए डेटा फ़िल्टर - वैकल्पिक, चुनते हैं
exclude_product_price. - के लिए डेटा फ़िल्टर अनुमतियाँ, चुनते हैं चुनते हैं.
- चुनें अनुदान.
आपने डेटाबेस पर झील निर्माण की अनुमति प्रदान की है hudi_crawler_blog और मेज sample_hudi_mor_table_ro,कॉलम को छोड़कर price डेटा विश्लेषक उपयोगकर्ता के लिए. आइए अब एथेना का उपयोग करके डेटा तक उपयोगकर्ता की पहुंच को सत्यापित करें।
- एथेना कंसोल में डेटाएनालिस्ट उपयोगकर्ता के रूप में साइन इन करें।
- क्वेरी संपादक पर, निम्न क्वेरी चलाएँ:
निम्न स्क्रीनशॉट हमारे आउटपुट को दिखाता है:
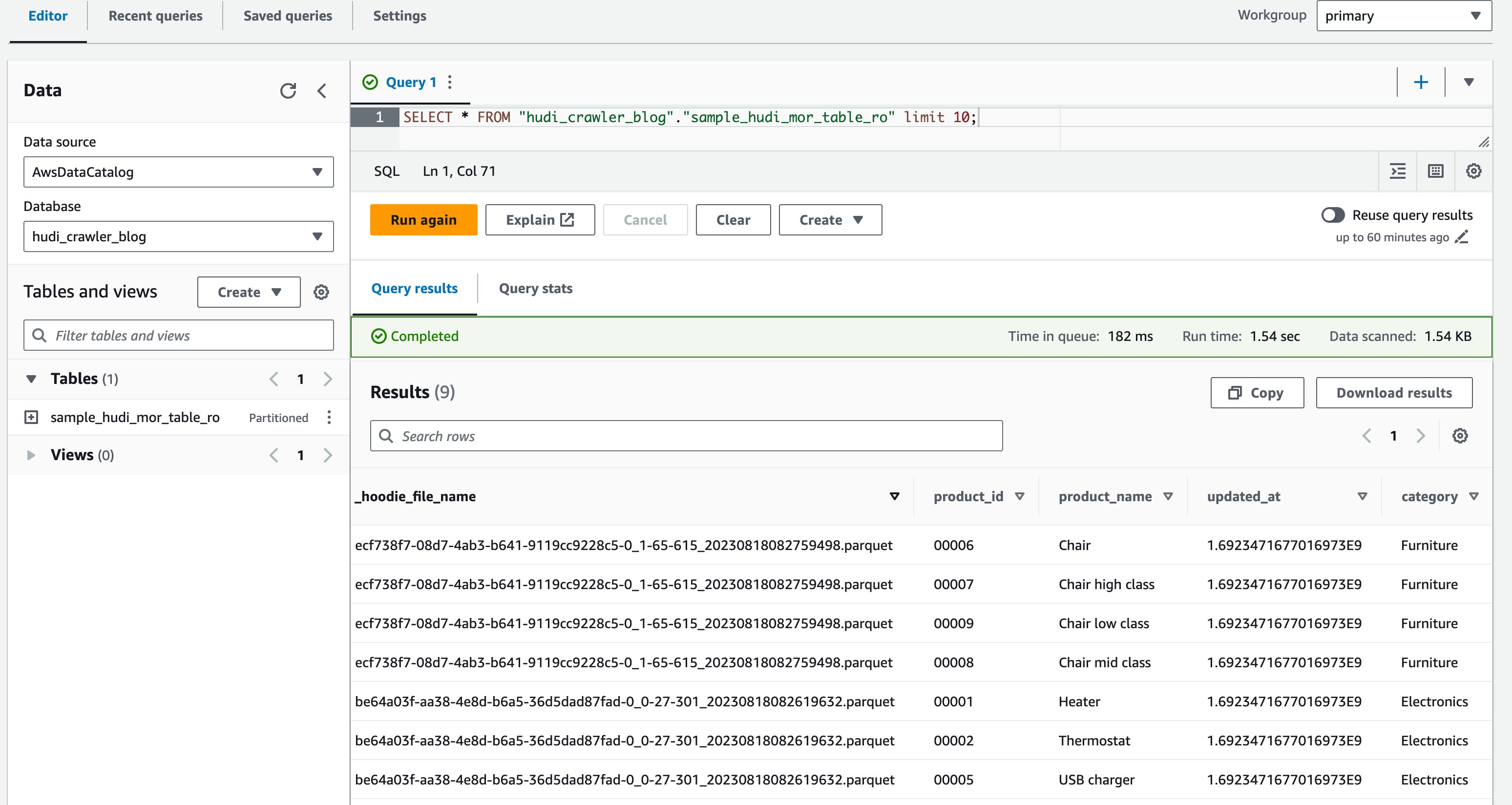
अब आपने उस कॉलम को मान्य कर दिया है price नहीं दिखाया गया है, लेकिन अन्य कॉलम product_id, product_name, update_at, तथा category दिखाए गए हैं।
क्लीन अप
अपने AWS खाते पर अवांछित शुल्कों से बचने के लिए, निम्नलिखित AWS संसाधनों को हटा दें:
- AWS ग्लू डेटाबेस हटाएँ
hudi_crawler_blog. - AWS ग्लू क्रॉलर हटाएँ
hudi_cow_crawlerऔरhudi_mor_crawler. - नीचे Amazon S3 फ़ाइलें हटाएँ
s3://your_s3_bucket/data/sample_hudi_cow_table/औरs3://your_s3_bucket/data/sample_hudi_mor_table/.
निष्कर्ष
इस पोस्ट में दिखाया गया है कि AWS ग्लू क्रॉलर हुडी टेबल के लिए कैसे काम करते हैं। हुडी क्रॉलर के समर्थन के साथ, आप जल्दी से अपने प्राथमिक हुडी टेबल कैटलॉग के रूप में एडब्ल्यूएस ग्लू डेटा कैटलॉग का उपयोग करने के लिए आगे बढ़ सकते हैं। आप AWS विश्लेषणात्मक इंजनों द्वारा समर्थित तालिकाओं और प्रारूपों के लिए AWS ग्लू, AWS ग्लू डेटा कैटलॉग और लेक फॉर्मेशन फाइन-ग्रेन्ड एक्सेस कंट्रोल का उपयोग करके AWS पर Hudi का उपयोग करके अपने सर्वर रहित ट्रांजेक्शनल डेटा लेक का निर्माण शुरू कर सकते हैं।
लेखक के बारे में
 नोरिताका सेकियामा AWS Glue टीम में प्रिंसिपल बिग डेटा आर्किटेक्ट हैं। वह टोक्यो, जापान में स्थित काम करता है। वह ग्राहकों की मदद करने के लिए सॉफ्टवेयर कलाकृतियों के निर्माण के लिए जिम्मेदार है। अपने खाली समय में, वह अपनी सड़क बाइक से साइकिल चलाना पसंद करते हैं।
नोरिताका सेकियामा AWS Glue टीम में प्रिंसिपल बिग डेटा आर्किटेक्ट हैं। वह टोक्यो, जापान में स्थित काम करता है। वह ग्राहकों की मदद करने के लिए सॉफ्टवेयर कलाकृतियों के निर्माण के लिए जिम्मेदार है। अपने खाली समय में, वह अपनी सड़क बाइक से साइकिल चलाना पसंद करते हैं।
 काइल डुओंग AWS ग्लू और लेक फॉर्मेशन टीम में एक सॉफ्टवेयर डेवलपमेंट इंजीनियर है। उन्हें बड़ी डेटा प्रौद्योगिकियों और वितरित प्रणालियों के निर्माण का शौक है।
काइल डुओंग AWS ग्लू और लेक फॉर्मेशन टीम में एक सॉफ्टवेयर डेवलपमेंट इंजीनियर है। उन्हें बड़ी डेटा प्रौद्योगिकियों और वितरित प्रणालियों के निर्माण का शौक है।
 संदीप अडवांकर AWS में वरिष्ठ तकनीकी उत्पाद प्रबंधक हैं। कैलिफ़ोर्निया बे एरिया में स्थित, वह दुनिया भर के ग्राहकों के साथ व्यापार और तकनीकी आवश्यकताओं को उत्पादों में अनुवाद करने के लिए काम करता है जो ग्राहकों को यह सुधारने में सक्षम बनाता है कि वे डेटा को कैसे प्रबंधित, सुरक्षित और एक्सेस करते हैं।
संदीप अडवांकर AWS में वरिष्ठ तकनीकी उत्पाद प्रबंधक हैं। कैलिफ़ोर्निया बे एरिया में स्थित, वह दुनिया भर के ग्राहकों के साथ व्यापार और तकनीकी आवश्यकताओं को उत्पादों में अनुवाद करने के लिए काम करता है जो ग्राहकों को यह सुधारने में सक्षम बनाता है कि वे डेटा को कैसे प्रबंधित, सुरक्षित और एक्सेस करते हैं।
- एसईओ संचालित सामग्री और पीआर वितरण। आज ही प्रवर्धित हो जाओ।
- प्लेटोडेटा.नेटवर्क वर्टिकल जेनरेटिव एआई। स्वयं को शक्तिवान बनाएं। यहां पहुंचें।
- प्लेटोआईस्ट्रीम। Web3 इंटेलिजेंस। ज्ञान प्रवर्धित। यहां पहुंचें।
- प्लेटोईएसजी. कार्बन, क्लीनटेक, ऊर्जा, पर्यावरण, सौर, कचरा प्रबंधन। यहां पहुंचें।
- प्लेटोहेल्थ। बायोटेक और क्लिनिकल परीक्षण इंटेलिजेंस। यहां पहुंचें।
- स्रोत: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- :हैस
- :है
- :नहीं
- :कहाँ
- $यूपी
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- योग्य
- About
- पहुँच
- डेटा तक पहुंच
- तक पहुँचने
- लेखा
- कार्य
- जोड़ना
- जोड़ा
- इसके अलावा
- दत्तक
- दत्तक ग्रहण
- उन्नत
- बाद
- सब
- अनुमति देना
- की अनुमति दे
- की अनुमति देता है
- भी
- वीरांगना
- अमेज़न एथेना
- अमेज़ॅन वेब सेवा
- an
- विश्लेषणात्मक
- विश्लेषिकी
- और
- अन्य
- कोई
- अपाचे
- अपाचे स्पार्क
- एपीआई
- प्रकट होता है
- आवेदन
- अनुप्रयोग विकास
- लागू करें
- हैं
- क्षेत्र
- चारों ओर
- AS
- At
- स्वतः
- से बचने
- एडब्ल्यूएस
- एडब्ल्यूएस गोंद
- AWS झील निर्माण
- आधार
- आधारित
- खाड़ी
- BE
- क्योंकि
- किया गया
- लाभ
- बेहतर
- बड़ा
- बड़ा डेटा
- लाता है
- इमारत
- बनाया गया
- व्यापार
- लेकिन
- by
- कैलिफ़ोर्निया
- कॉल
- कर सकते हैं
- क्षमताओं
- क्षमता
- मामला
- सूची
- कैटलॉग
- श्रेणियाँ
- सेल
- चुनौतियों
- परिवर्तन
- बदल
- परिवर्तन
- प्रभार
- चुनें
- स्तंभ
- स्तंभ
- संयोजन
- करना
- प्रतिबद्ध
- पूरा
- जटिल
- अंग
- विन्यास
- कंसोल
- शामिल हैं
- सामग्री
- लगातार
- नियंत्रण
- नियंत्रण
- सका
- क्रॉलर
- बनाना
- बनाया
- बनाता है
- साख
- ग्राहक
- तिथि
- डेटा एकीकरण
- डेटा लेक
- डाटा गोदाम
- डाटाबेस
- डेटाबेस
- डेटासेट
- परिभाषा
- परिभाषाएँ
- डेल्टा
- साबित
- दर्शाता
- गहराई
- विकास
- सीधे
- अन्य वायरल पोस्ट से
- वितरित
- वितरित प्रणाली
- do
- कर देता है
- दौरान
- से प्रत्येक
- आसान
- आसानी
- संपादक
- प्रभावी रूप से
- कुशल
- सक्षम
- सक्षम
- इंजीनियर
- इंजीनियर्स
- इंजन
- दर्ज
- ईथर (ईटीएच)
- उद्विकासी
- के सिवा
- उद्धरण
- और तेज
- कम
- पट्टिका
- फ़ाइलें
- फ़िल्टर
- फ़िल्टर
- खोज
- प्रथम
- पहली बार
- निम्नलिखित
- के लिए
- प्रारूप
- निर्माण
- अक्सर
- से
- दी
- ग्लोब
- Go
- अनुदान
- दी गई
- मार्गदर्शिकाएँ
- Hadoop
- है
- he
- मदद
- मदद करता है
- उसके
- करंड
- कैसे
- How To
- एचटीएमएल
- HTTPS
- आई ए एम
- if
- निहितार्थ
- में सुधार
- in
- सहित
- वृद्धिशील
- करें-
- बजाय
- एकीकृत
- एकीकरण
- इंटरफेस
- में
- शुरू करने
- IT
- जापान
- जेपीजी
- रखना
- झील
- झीलों
- ताज़ा
- लांच
- जानें
- सीख रहा हूँ
- कम
- सीमा
- लाइन
- सूची
- स्थित
- स्थान
- स्थानों
- लॉग इन
- मशीन
- यंत्र अधिगम
- को बनाए रखने
- बनाना
- बनाता है
- प्रबंधन
- कामयाब
- प्रबंधक
- प्रबंध
- गाइड
- अधिकतम
- विलय
- मेटाडाटा
- ओर पलायन
- प्रवास
- ML
- अधिक
- अधिकांश
- चाल
- विभिन्न
- नाम
- देशी
- आवश्यकता
- जरूरत
- नया
- नए नए
- अगला
- अभी
- of
- on
- ONE
- केवल
- खुला
- खुला स्रोत
- अनुकूलित
- विकल्प
- or
- अन्य
- हमारी
- उत्पादन
- भाग
- आवेशपूर्ण
- पथ
- पथ
- प्रदर्शन
- अनुमति
- अनुमतियाँ
- प्लेटो
- प्लेटो डेटा इंटेलिजेंस
- प्लेटोडाटा
- लोकप्रिय
- आबादी वाले
- पद
- तैयार करना
- आवश्यक शर्तें
- पिछला
- मूल्य
- प्राथमिक
- प्रिंसिपल
- प्रसंस्करण
- एस्ट्रो मॉल
- उत्पादन प्रबंधक
- उत्पाद
- प्रदान करना
- बशर्ते
- प्रदान करता है
- प्रश्नों
- जल्दी से
- पढ़ना
- वास्तविक
- वास्तविक समय
- रियल टाइम
- हाल
- रिकॉर्ड
- रजिस्टर
- पंजीकृत
- की जगह
- आवश्यकताएँ
- उपयुक्त संसाधन चुनें
- जिम्मेदार
- रोकना
- सड़क
- भूमिका
- आरओडब्ल्यू
- रन
- वही
- अनुसूची
- अनुसूचित
- एसडीके
- अनुभाग
- सुरक्षित
- देखना
- चयन
- वरिष्ठ
- serverless
- सेवा
- सेवाएँ
- सेट
- सेटिंग्स
- दिखाया
- दिखाता है
- सरल
- के बाद से
- एक
- टुकड़ा
- आशुचित्र
- So
- सॉफ्टवेयर
- सॉफ्टवेयर विकास
- स्रोत
- सूत्रों का कहना है
- स्पार्क
- विशिष्ट
- प्रारंभ
- राज्य
- कदम
- कदम
- संग्रहित
- स्ट्रीमिंग
- नदियों
- स्टूडियो
- सफलतापूर्वक
- ऐसा
- समर्थन
- समर्थित
- सिंक।
- सिस्टम
- तालिका
- टीम
- तकनीकी
- टेक्नोलॉजीज
- कि
- RSI
- लेकिन हाल ही
- फिर
- वहाँ।
- वे
- इसका
- तीन
- यहाँ
- पहर
- बार
- सेवा मेरे
- टोक्यो
- ऊपर का
- लेन-देन संबंधी
- लेनदेन
- अनुवाद करना
- पार करना
- ट्रिगर
- शुरू हो रहा
- ट्यूटोरियल
- दो
- प्रकार
- ठेठ
- के अंतर्गत
- अवांछित
- अपडेट
- अद्यतन
- अपडेट
- उपयोग
- उदाहरण
- प्रयुक्त
- उपयोगकर्ता
- उपयोगकर्ताओं
- का उपयोग करता है
- का उपयोग
- सत्यापित करें
- मान्य
- मान
- संस्करण
- दृश्य
- गोदाम
- we
- वेब
- वेब सेवाओं
- कुंआ
- कब
- कौन कौन से
- जब
- कौन
- मर्जी
- साथ में
- बिना
- काम
- कार्य
- लिखना
- लिखा हुआ
- इसलिए आप
- आपका
- स्वयं
- जेफिरनेट